TL;DR#
Semi-supervised learning (SSL) aims to improve model performance by utilizing unlabeled data alongside limited labeled data. However, many existing SSL methods struggle with real-world scenarios, particularly those involving a large number of irrelevant instances in unlabeled data that don’t belong to any class in the labeled data. These irrelevant instances often lead to class distribution mismatch, negatively impacting model training and reducing accuracy.
This paper introduces a novel approach called Discriminator-Weighted Diffusion (DWD). DWD uses a diffusion model to generate synthetic data by incorporating both labeled and unlabeled samples, enriching the labeled data and mitigating the impact of irrelevant instances. A key part of DWD is a discriminator that identifies and reduces the impact of irrelevant samples, ensuring that only relevant information is used for data augmentation. Experiments across several datasets show that DWD significantly enhances the performance of SSL methods, especially in cases with class distribution mismatch.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in semi-supervised learning (SSL): handling class distribution mismatch in real-world scenarios. Current SSL methods often struggle when faced with irrelevant data points, and this research offers a novel, data-centric solution. The results show significant performance improvements, particularly when datasets have mismatched class distributions, opening new avenues for more robust and effective SSL applications.
Visual Insights#

🔼 This figure illustrates the process of transforming unlabeled data into labeled data using a diffusion model. The process starts with noisy images from the unlabeled dataset, which may contain classes not present in the labeled data. The diffusion model, conditioned on the desired class from the labeled data, then transforms these noisy images. The resulting images retain the diversity from the unlabeled data while aligning their class labels with the labeled data.
read the caption
Figure 1: Transforming unlabeled data using a diffusion model. Initially, the unlabeled data includes classes like trees, fish, and mountains, which are irrelevant to the labeled data's classes such as trucks, cars, and ships. The reverse process with class conditioning resolves this mismatch while preserving the diversity of the original unlabeled samples. More examples can be found in Appendix H.

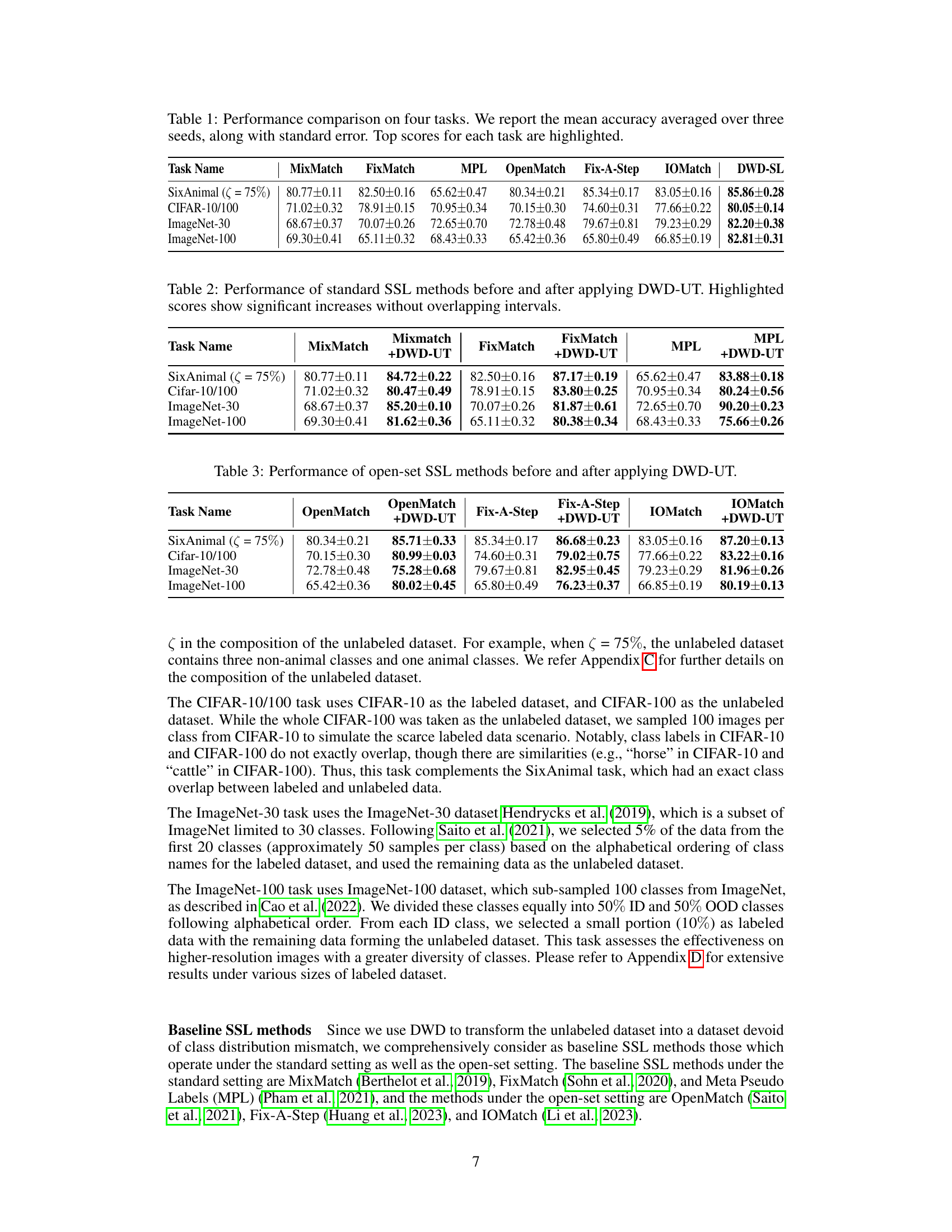
🔼 This table compares the performance of different semi-supervised learning (SSL) methods on four different tasks: SixAnimal, CIFAR-10/100, ImageNet-30, and ImageNet-100. The methods compared are MixMatch, FixMatch, Meta Pseudo Labels (MPL), OpenMatch, Fix-A-Step, IOMatch, and the proposed DWD-SL method. The table shows the mean accuracy and standard error for each method on each task. The highest accuracy for each task is highlighted.
read the caption
Table 1: Performance comparison on four tasks. We report the mean accuracy averaged over three seeds, along with standard error. Top scores for each task are highlighted.
In-depth insights#
Diffusion Augment#
The concept of “Diffusion Augment” in the context of a research paper likely refers to a method leveraging diffusion models for data augmentation. This technique is particularly useful in semi-supervised learning where limited labeled data is a major constraint. Diffusion models excel at generating diverse and realistic synthetic data, which is crucial for enhancing model robustness and generalization performance. The augmentation process likely involves adding noise to existing data (both labeled and unlabeled) and then using the diffusion model to reconstruct the data, thereby creating new, slightly perturbed versions. A key advantage is the ability to generate samples that are similar to the existing data but also exhibit variability, addressing the challenge of data scarcity while maintaining data quality. The effectiveness of “Diffusion Augment” would depend heavily on the choice of diffusion model architecture, training procedures, and parameters, requiring careful experimentation and analysis to determine optimal settings for specific applications. The potential impact lies in improving the accuracy and efficiency of machine learning models trained on limited datasets.
Open-Set SSL#
Open-Set Semi-Supervised Learning (SSL) tackles the challenge of class distribution mismatch between labeled and unlabeled data, a common issue in real-world applications. Unlike standard SSL, which assumes identical distributions, open-set SSL acknowledges the presence of unlabeled data points that don’t belong to any labeled class (out-of-distribution or OOD instances). These OOD instances can significantly hinder model performance if not handled properly. Many strategies address this by filtering OOD instances, but this approach might discard valuable information from unlabeled data. The key challenge lies in leveraging the diversity of unlabeled data while minimizing the negative impact of OOD samples. Generative approaches, such as those employing diffusion models, offer a promising avenue, as they can potentially transform OOD instances into relevant ones, effectively enriching the training data. A discriminator is often integrated to assess the relevance of unlabeled samples. Therefore, open-set SSL represents a more realistic and robust SSL framework, acknowledging data imperfections and demanding more sophisticated handling of unlabeled data compared to its standard counterpart.
DWD Framework#
The DWD framework, as a data-centric generative augmentation approach for open-set semi-supervised learning, presents a novel solution to address the challenges of class distribution mismatch. Its core innovation lies in leveraging a diffusion model to transform unlabeled data, enriching the labeled data with synthetic samples while mitigating the negative impact of irrelevant instances. A key component is the discriminator, which identifies and down-weights irrelevant unlabeled data, preventing the introduction of noise and confirmation bias that plague many SSL methods. By combining diffusion model training with this discriminator, DWD generates relevant synthetic data even from initially irrelevant unlabeled examples. The framework shows promise in significantly enhancing SSL performance by addressing the limitations of traditional methods that often struggle with real-world scenarios containing abundant irrelevant unlabeled data. This thoughtful approach enhances the diversity of training data without discarding potentially valuable information, leading to more effective and robust model training.
Mismatch Effects#
Analyzing mismatch effects in a research paper requires a nuanced understanding of the context. It likely refers to situations where the distribution of the training data differs significantly from that of the real-world data the model will ultimately encounter. This could manifest in several ways: class imbalance, where some classes are far more prevalent than others; domain shift, where the characteristics of the data (e.g., image quality, sensor type) change between training and deployment; concept drift, where the underlying relationships between data points evolve over time. Understanding these mismatches is crucial, as they can significantly impact model generalization and real-world performance. The paper likely investigates how different techniques for handling mismatched data, such as data augmentation, weighting, or domain adaptation, influence model robustness. Addressing these mismatches is key for building reliable and effective AI systems that perform well in diverse and dynamic environments. The analysis may delve into the types of errors models make under various mismatch scenarios, possibly quantifying the magnitude of performance degradation. Ultimately, understanding mismatch effects helps researchers devise better strategies for developing more reliable and generalizable AI.
Future Works#
Future research directions stemming from this work on data augmentation with diffusion models for open-set semi-supervised learning could explore several promising avenues. Improving the discriminator is crucial; a more robust discriminator could better identify and weight irrelevant instances, further enhancing the quality of synthetic data. Investigating alternative diffusion model architectures beyond the conditional diffusion model used here could unlock further performance gains. Exploring the effect of different noise schedules and hyperparameter optimization strategies could also significantly impact the results. Extending the approach to other modalities, such as text or time series data, would be another exciting direction. Finally, a detailed analysis of the generalizability of the method across different datasets and types of class imbalance is needed to assess its practical applicability more broadly. More comprehensive evaluation on larger-scale datasets with diverse characteristics would also solidify the findings.
More visual insights#
More on figures
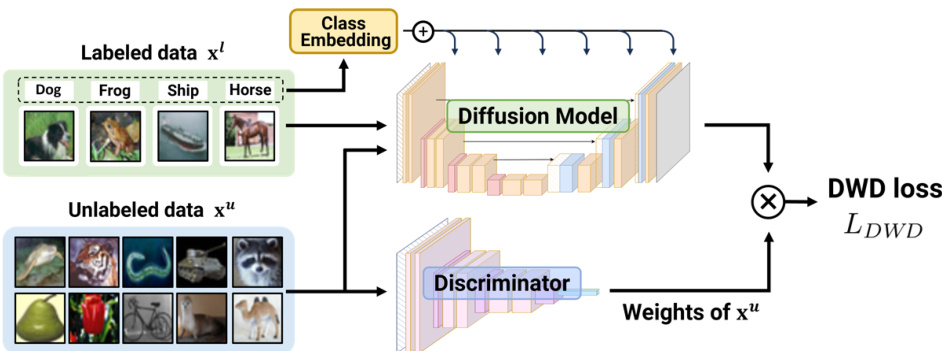
🔼 This figure illustrates the architecture of the Discriminator-Weighted Diffusion (DWD) model. It shows how both labeled and unlabeled data are used to train a conditional diffusion model. A discriminator is used to assign weights to the unlabeled data points, reducing the negative impact of out-of-distribution (OOD) samples during training. The final output is the DWD loss, used to optimize the model.
read the caption
Figure 2: Schematic diagram of Discriminator-Weighted Diffusion (DWD). The conditional diffusion model is trained using both labeled and unlabeled data. The unlabeled data is utilized for unconditional training without class conditions. The pre-trained discriminator assigns weights to each unlabeled data sample to mitigate the potential negative impact of OOD samples.
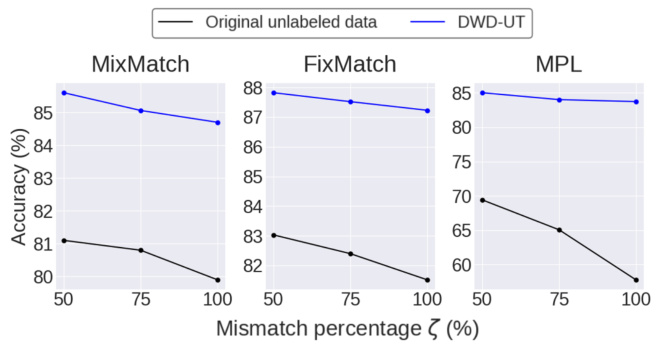
🔼 This figure displays the performance of three standard semi-supervised learning (SSL) methods (MixMatch, FixMatch, and MPL) under varying levels of class distribution mismatch (ζ). The x-axis represents the percentage of mismatch, and the y-axis shows the accuracy achieved by each method. The black line represents the accuracy without the proposed data augmentation method (DWD-UT), while the blue line shows the accuracy with DWD-UT applied. The figure demonstrates the robustness of SSL methods to class distribution mismatch when using DWD-UT, as the performance remains high even with significant mismatch.
read the caption
Figure 3: Standard SSL performance with varying ζ.

🔼 This figure illustrates the process of transforming unlabeled data using a diffusion model. The unlabeled data contains irrelevant classes (trees, fish, mountains), while the labeled data contains different classes (trucks, cars, ships). The diffusion model, through a reverse process with class conditioning, transforms the irrelevant unlabeled data into relevant data points, maintaining diversity within the original unlabeled data.
read the caption
Figure 1: Transforming unlabeled data using a diffusion model. Initially, the unlabeled data includes classes like trees, fish, and mountains, which are irrelevant to the labeled data's classes such as trucks, cars, and ships. The reverse process with class conditioning resolves this mismatch while preserving the diversity of the original unlabeled samples. More examples can be found in Appendix H.

🔼 This figure visualizes examples of unlabeled samples from the SixAnimal and ImageNet-30 datasets, categorized by their discriminator scores. High-score samples are those deemed relevant to the labeled data distribution, while low-score samples are considered irrelevant or out-of-distribution. The figure shows how the discriminator effectively identifies and separates relevant and irrelevant instances from the unlabeled data, which is crucial for the DWD method to enhance data augmentation quality.
read the caption
Figure 5: Selected unlabeled samples based on discriminator's output on the SixAnimal (a, b) and ImageNet-30 (c, d).

🔼 This figure illustrates the process of transforming unlabeled data using a diffusion model. The left side shows unlabeled images containing classes (trees, fish, mountains) not present in the labeled data (trucks, cars, ships). A noise process is applied, followed by a reverse diffusion process with class conditioning. The right side shows how the model transforms the irrelevant unlabeled images into relevant labeled images while maintaining the diversity of the original unlabeled samples. The process is used to address class distribution mismatch in semi-supervised learning.
read the caption
Figure 1: Transforming unlabeled data using a diffusion model. Initially, the unlabeled data includes classes like trees, fish, and mountains, which are irrelevant to the labeled data's classes such as trucks, cars, and ships. The reverse process with class conditioning resolves this mismatch while preserving the diversity of the original unlabeled samples. More examples can be found in Appendix H.
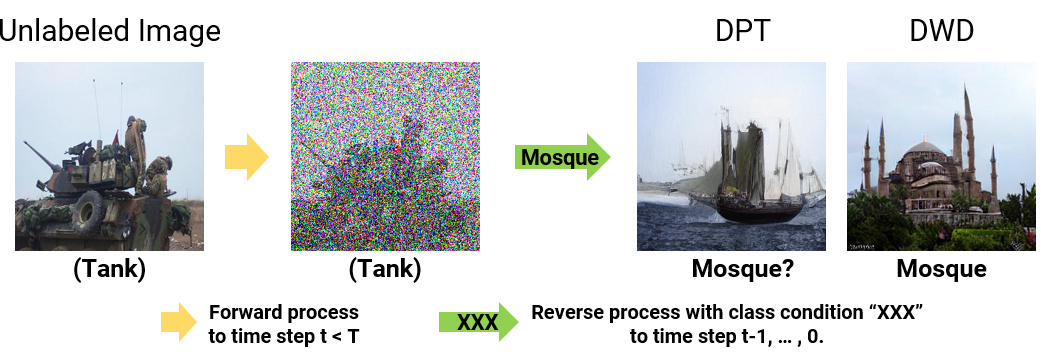
🔼 The figure compares the image generation process of DPT and DWD methods using an example of a noisy tank image as input. DPT generates an image that is incorrectly labeled as a mosque, while DWD generates a correct mosque image. This demonstrates DWD’s superiority in handling out-of-distribution (OOD) samples during image generation.
read the caption
Figure 7: Generated images from DPT and DWD. DPT sometimes generates incorrectly labeled samples (e.g., an image of a schooner, which is an OOD class, labeled as a mosque). Note that while DPT originally samples images from scratch, we applied our data generation algorithm to DPT for comparison.

🔼 This figure shows the results of applying the DA-Fusion data augmentation method to a mosque image. DA-Fusion, unlike the proposed DWD method, only generates subtle variations of the input image, maintaining the original image’s content and style. It does not generate entirely new images from unlabeled data as DWD does, hence showing a limitation when there’s a class distribution mismatch.
read the caption
Figure 8: Generated images from DA-Fusion. DA-Fusion only augments given labeled images with subtle visual details.
More on tables

🔼 This table compares the performance of standard semi-supervised learning (SSL) methods before and after applying the proposed Discriminator-Weighted Diffusion (DWD-UT) method. It highlights the improvements achieved by DWD-UT in enhancing the performance of these SSL methods, focusing on cases where the improvement is statistically significant (i.e., not overlapping confidence intervals). The results are presented for four different tasks, showcasing the method’s effectiveness across various scenarios.
read the caption
Table 2: Performance of standard SSL methods before and after applying DWD-UT. Highlighted scores show significant increases without overlapping intervals.

🔼 This table compares the performance of several open-set semi-supervised learning (SSL) methods before and after applying the proposed Discriminator-Weighted Diffusion (DWD-UT) technique. It shows the mean accuracy and standard deviation across three different seeds for four tasks: SixAnimal, CIFAR-10/100, ImageNet-30, and ImageNet-100. The results demonstrate the improvement in accuracy achieved by incorporating DWD-UT, highlighting its effectiveness in enhancing the performance of open-set SSL methods.
read the caption
Table 3: Performance of open-set SSL methods before and after applying DWD-UT.

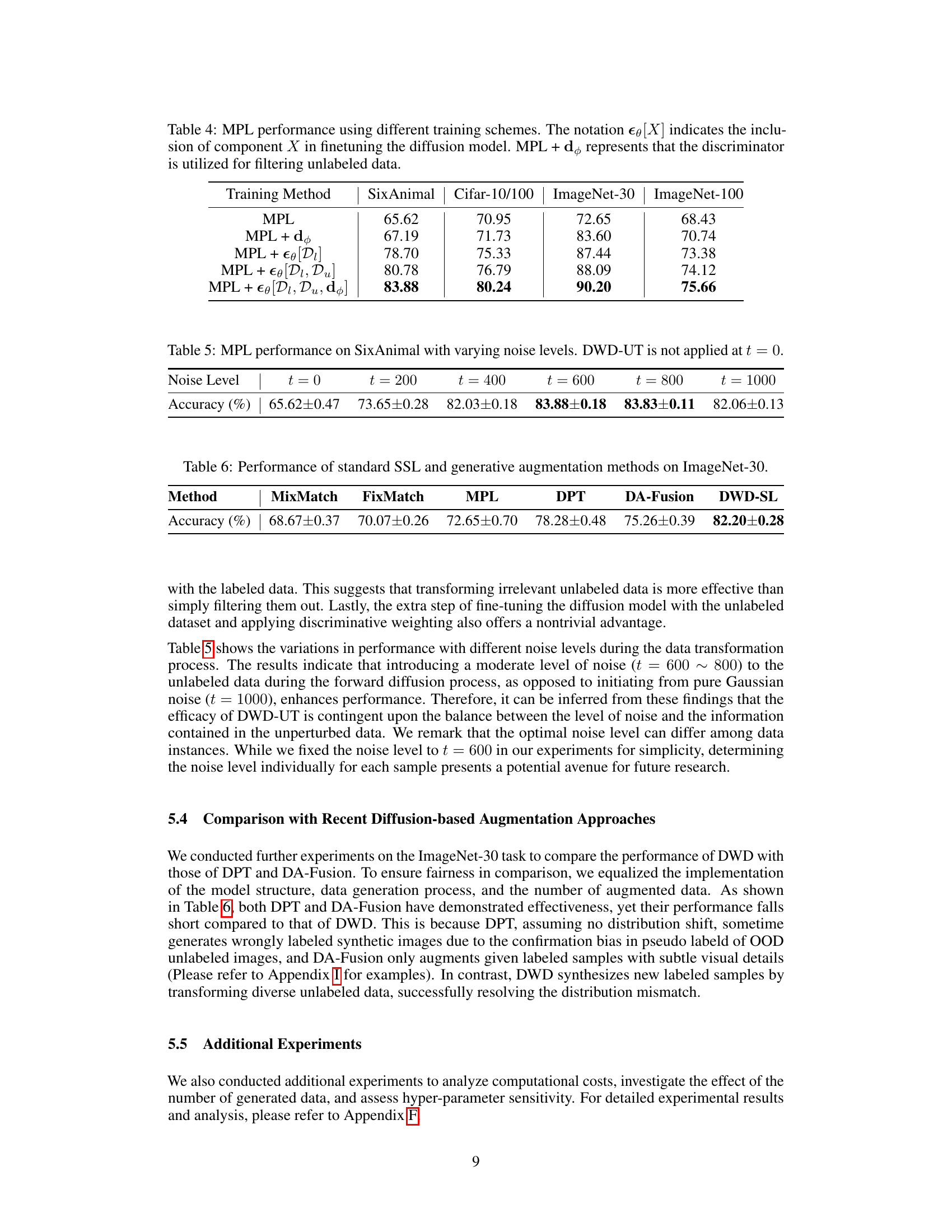
🔼 This table presents the performance of the MPL (Meta Pseudo Labels) method under different training schemes for the diffusion model. It shows how incorporating different components (discriminator, labeled data, unlabeled data) affects performance. The best performing model includes all three components.
read the caption
Table 4: MPL performance using different training schemes. The notation €θ[X] indicates the inclusion of component X in finetuning the diffusion model. MPL + dφ represents that the discriminator is utilized for filtering unlabeled data.

🔼 This table presents the performance of the MixMatch Pseudo-Label (MPL) method on the SixAnimal dataset with varying noise levels during the data transformation process. The noise level is represented by the time step (t) in the diffusion process, ranging from 0 to 1000. The accuracy is reported with the standard error for each noise level, demonstrating how the accuracy changes with different levels of added noise before applying the discriminator-weighted diffusion technique (DWD-UT). The result at t=0 serves as a baseline to compare against when DWD-UT is applied.
read the caption
Table 5: MPL performance on SixAnimal with varying noise levels. DWD-UT is not applied at t = 0.

🔼 This table compares the performance of DWD-SL against various baseline SSL methods across four different tasks: ImageNet-30, SixAnimal, CIFAR-10/100, and ImageNet-100. The mean accuracy and standard error are reported for each method on each task. Top performing methods for each task are highlighted.
read the caption
Table 1: Performance comparison on four tasks. We report the mean accuracy averaged over three seeds, along with standard error. Top scores for each task are highlighted.
🔼 This table presents a comparison of the performance of various semi-supervised learning (SSL) methods on four different tasks: ImageNet-30, SixAnimal (with 75% class mismatch), CIFAR-10/100, and ImageNet-100. The methods compared include MixMatch, FixMatch, Mean-Teacher (MPL), OpenMatch, Fix-A-Step, IOMatch, and the proposed DWD-SL method. The table shows the mean accuracy and standard error for each method on each task, highlighting the top-performing method for each task. The results demonstrate the effectiveness of the proposed method, particularly in the presence of class distribution mismatch.
read the caption
Table 1: Performance comparison on four tasks. We report the mean accuracy averaged over three seeds, along with standard error. Top scores for each task are highlighted.

🔼 This table compares the performance of several standard semi-supervised learning (SSL) methods before and after applying the Discriminator-Weighted Diffusion (DWD-UT) technique. The results show that DWD-UT consistently improves the accuracy of the SSL methods, especially in tasks with significant class distribution mismatch. The highlighted scores indicate statistically significant improvements with 95% confidence.
read the caption
Table 2: Performance of standard SSL methods before and after applying DWD-UT. Highlighted scores show significant increases without overlapping intervals.

🔼 This table compares the performance of various semi-supervised learning (SSL) methods on four different tasks: ImageNet-30, SixAnimal, CIFAR-10/100, and ImageNet-100. The results show the mean accuracy and standard error across three random seeds for each method. The highest accuracy for each task is highlighted.
read the caption
Table 1: Performance comparison on four tasks. We report the mean accuracy averaged over three seeds, along with standard error. Top scores for each task are highlighted.

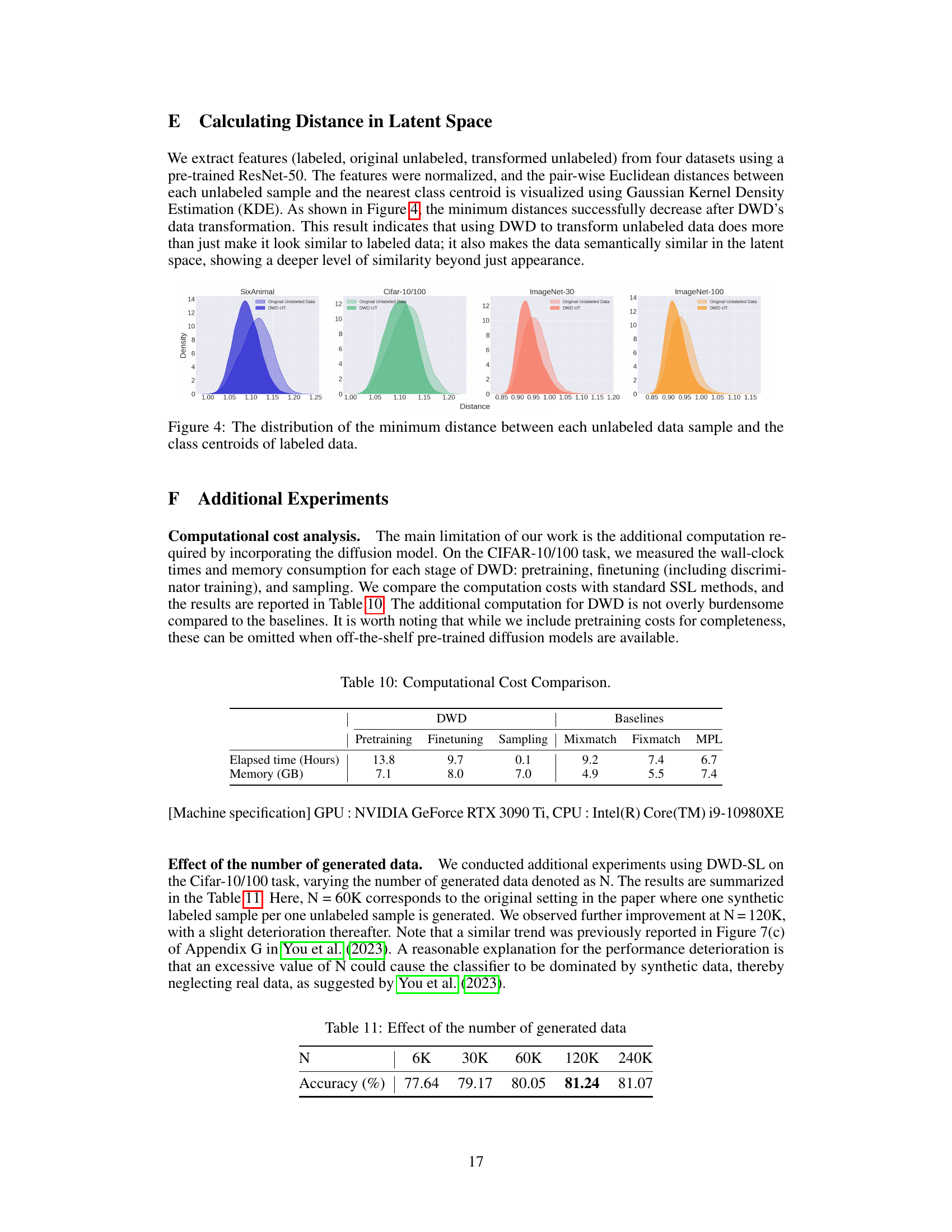
🔼 This table compares the computational cost (elapsed time and memory usage) of the proposed Discriminator-Weighted Diffusion (DWD) method with three baseline semi-supervised learning (SSL) methods (MixMatch, FixMatch, and MPL) on the CIFAR-10/100 dataset. The DWD method involves three stages: pretraining, finetuning, and sampling. The table shows that while DWD has a higher computational cost overall, it is comparable to the baselines, especially when pre-trained models are utilized.
read the caption
Table 10: Computational Cost Comparison.

🔼 This table compares the performance of different semi-supervised learning (SSL) methods on four image classification tasks: ImageNet-30, SixAnimal, CIFAR-10/100, and ImageNet-100. The methods compared include MixMatch, FixMatch, Meta Pseudo Labels (MPL), OpenMatch, Fix-A-Step, IOMatch, and the proposed DWD-SL method. The table shows the mean accuracy and standard error for each method on each task, highlighting the top-performing method for each task. The results demonstrate the effectiveness of the proposed DWD-SL method, especially in comparison to other state-of-the-art SSL techniques.
read the caption
Table 1: Performance comparison on four tasks. We report the mean accuracy averaged over three seeds, along with standard error. Top scores for each task are highlighted.

🔼 This table shows the impact of different values for the hyperparameter α on the performance of the DWD method. α controls the balance between labeled and unlabeled data in the training process. The results indicate that a value of 3 yields the best performance.
read the caption
Table 12: Performance of DWD with various α.

🔼 This table shows the performance of the Discriminator-Weighted Diffusion (DWD) method with different values of the hyperparameter μ. The hyperparameter μ represents the ratio of positive samples among unlabeled samples. The table shows that the optimal value of μ is around 0.25, which corresponds to a 75% ratio of positive samples, achieving the highest accuracy of 85.86%. This suggests that the discriminator’s performance is highly sensitive to this hyperparameter, and that appropriate tuning is crucial for optimal performance.
read the caption
Table 13: Performance of DWD with various μ.
Full paper#