↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Online Continual Learning (OCL) faces challenges beyond catastrophic forgetting. Existing methods often neglect ‘model throughput,’ the speed at which a model processes data – a critical limitation in high-speed data stream scenarios. This paper emphasizes two crucial challenges in OCL: model ignorance (failure to learn effective features within time constraints) and model myopia (overly simplified, task-specific features).
To address these, the authors propose the Non-sparse Classifier Evolution (NsCE) framework. NsCE uses pre-trained models, non-sparse maximum separation regularization, and targeted experience replay to learn globally discriminative features efficiently. Experiments demonstrate that NsCE significantly improves performance, throughput, and real-world applicability compared to existing methods, highlighting the importance of addressing model throughput in OCL research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of model throughput in online continual learning (OCL), a largely overlooked aspect impacting real-world applications. By introducing the Non-sparse Classifier Evolution (NsCE) framework, it significantly improves performance, throughput and practicality. This work is timely given the increasing focus on real-time, data-stream applications, and it opens avenues for investigating effective global discriminative feature learning under minimal time constraints.
Visual Insights#

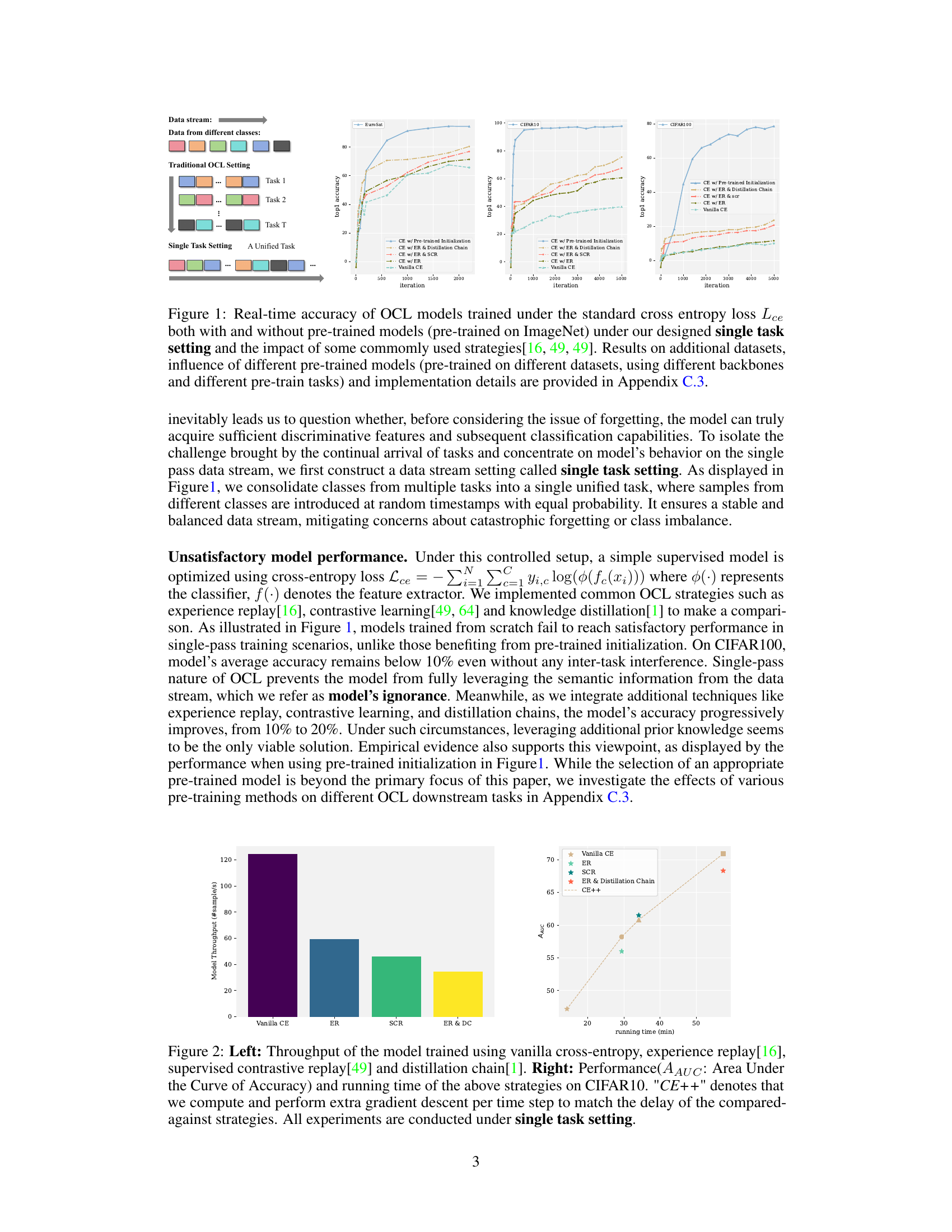
The figure shows the real-time accuracy of online continual learning (OCL) models trained with and without pre-trained models under different settings and strategies. It aims to demonstrate the impact of single-pass training and the effectiveness of common strategies like experience replay, contrastive learning, and knowledge distillation on mitigating model’s ignorance.
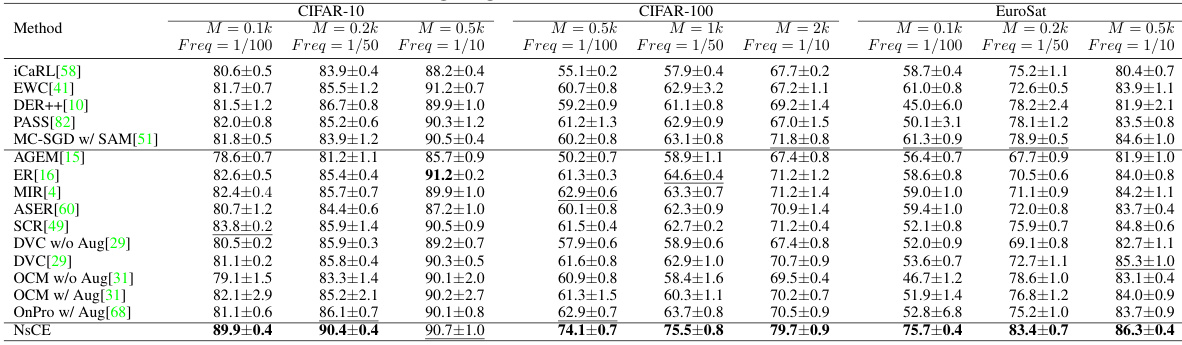
This table presents the Average Area Under the Curve (AAUC) of various continual learning methods on three benchmark datasets (CIFAR-10, CIFAR-100, and EuroSat). Different memory buffer sizes (M) and replay frequencies (Freq) are tested. The best performing method for each setting is shown in bold, with the second best underlined. The results demonstrate how the performance of continual learning methods is influenced by the size of memory buffer and replay frequency.
In-depth insights#
OCL’s Throughput Limit#
Online Continual Learning (OCL) faces a critical bottleneck: the throughput limit. Most existing OCL methods prioritize mitigating catastrophic forgetting, often at the cost of slower model training. This is problematic because real-world data streams don’t pause for slow models; data arrives continuously, and slow processing leads to significant data loss and suboptimal performance. The paper highlights this critical issue, arguing that a model’s ability to process a maximum number of samples per unit of time (throughput) is equally important as classification accuracy. The authors introduce the concept of a model’s ‘ignorance’ (inability to learn effectively from limited single-pass training time) and ‘myopia’ (overly simplified, task-specific feature learning) to further explain performance limitations beyond forgetting. Addressing this throughput constraint requires innovative methods that can achieve effective learning while also maintaining rapid processing speeds, making real-time or high-speed OCL applications truly feasible.
Model Ignorance/Myopia#
The concepts of “Model Ignorance” and “Model Myopia” offer a nuanced perspective on the limitations of online continual learning (OCL). Model ignorance highlights the challenge of learning effective features within the constrained single-pass nature of OCL. The limited exposure to data prevents models from fully understanding the underlying data distributions, hindering the acquisition of robust features. Model myopia, on the other hand, describes the tendency of models to oversimplify and overspecialize, focusing excessively on features relevant to the current task, leading to poor generalization. This results in a trade-off between performance on current tasks and adaptation to new tasks. Addressing these issues requires frameworks that encourage effective global feature learning and minimize the sparsity of classifiers. This can involve using strategies like non-sparse regularization and targeted experience replay to prevent overspecialization and catastrophic forgetting, enabling models to achieve better performance and throughput in dynamic data streams.
NsCE Framework#
The NsCE (Non-sparse Classifier Evolution) framework tackles key challenges in online continual learning (OCL). It addresses the issues of model ignorance and myopia, which are often overlooked in favor of solely focusing on catastrophic forgetting. NsCE uses pre-trained models to provide a strong initialization, enabling quicker learning. A non-sparse regularization helps prevent the classifier from becoming excessively sparse and task-specific, which leads to myopia. The maximum separation criterion promotes more separable features. Finally, targeted experience replay efficiently focuses on addressing confusions between previously learned classes, improving both performance and throughput. This combination allows NsCE to achieve substantial improvements in OCL performance while maintaining real-world practicality.
Pac-Bayes Analysis#
A Pac-Bayes analysis in the context of online continual learning (OCL) offers a valuable theoretical lens for understanding the inherent trade-offs. It provides a framework to mathematically quantify the relationship between model performance (risk), model throughput (samples processed per unit time), and task divergence. The analysis highlights the importance of model throughput, often overlooked in empirical studies. A key insight is that strategies improving model accuracy (reducing empirical risk) may simultaneously reduce throughput, creating a critical balance. The theoretical bound derived often involves a trade-off term representing this tension, and shows how improvements in any one aspect (e.g., accuracy via data augmentation) could negatively affect another (e.g., throughput). Analyzing this bound offers important guidance for algorithm design, emphasizing the need for efficient learning approaches within the constraints of real-time data streams. The inclusion of the task divergence term, linked to model myopia and forgetting, adds depth by suggesting how strategies that focus on model adaptation could potentially further mitigate the inherent limitations in OCL.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of continual learning, this might involve removing regularization terms, replay strategies, or specific architectural components. The goal is to isolate the impact of each part, determining which are essential for performance and which are redundant. A well-designed ablation study provides strong evidence for the claims of the paper, clarifying the effectiveness of each contribution. By showing which parts are critical, the study demonstrates the importance of the framework’s design and how individual components enhance the overall performance. Moreover, the study can highlight unexpected interactions or synergies between different components, revealing valuable insights for future research and model improvement. A thorough ablation study strengthens the paper’s methodology and results, thereby building confidence in its overall contribution to the field.
More visual insights#
More on figures

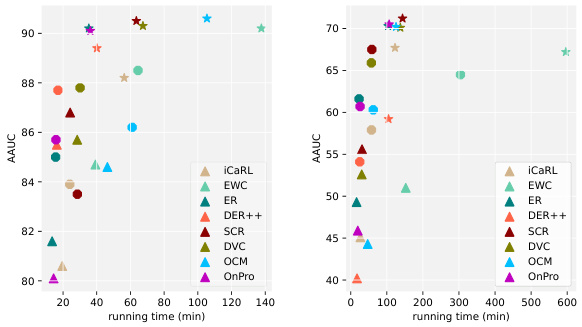
This figure demonstrates the trade-off between model throughput and performance in online continual learning (OCL). The left panel shows that adding techniques like experience replay, supervised contrastive replay, and distillation chains to a vanilla cross-entropy model increases training time, thus reducing throughput. The right panel shows that, while these techniques improve accuracy (measured by Area Under the Curve of Accuracy, AAUC), they still don’t outperform a simple cross-entropy model that is trained multiple times (CE++) to account for the time cost of the other techniques, showcasing the limitations of the standard OCL evaluation.

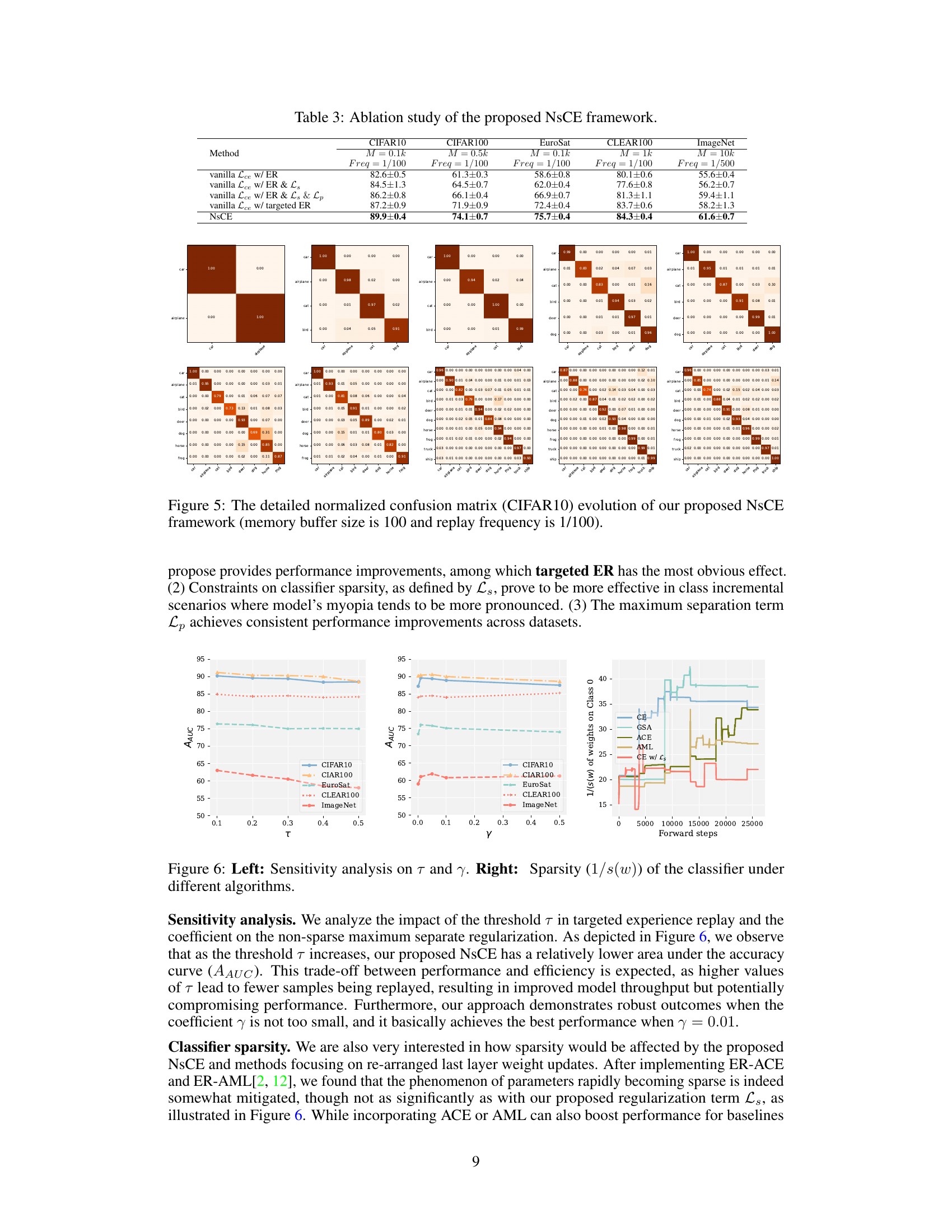
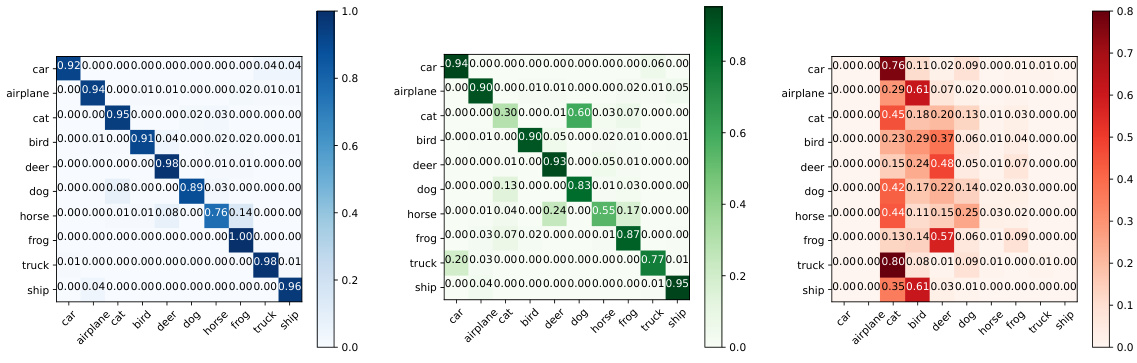
This figure shows the normalized confusion matrices of a Nearest Class Mean (NCM) classifier and a softmax classifier trained on the CIFAR-10 dataset. The matrices are visualized at different stages of the training process. The NCM classifier, shown in green, uses a prototype-based approach, while the softmax classifier is in blue. The confusion matrices illustrate the models’ performance in terms of correct and incorrect classifications for each class. The ImageNet pre-trained initialization is used. The figure highlights that the softmax classifier shows early signs of an excessively sparse classifier that creates confusion between classes.

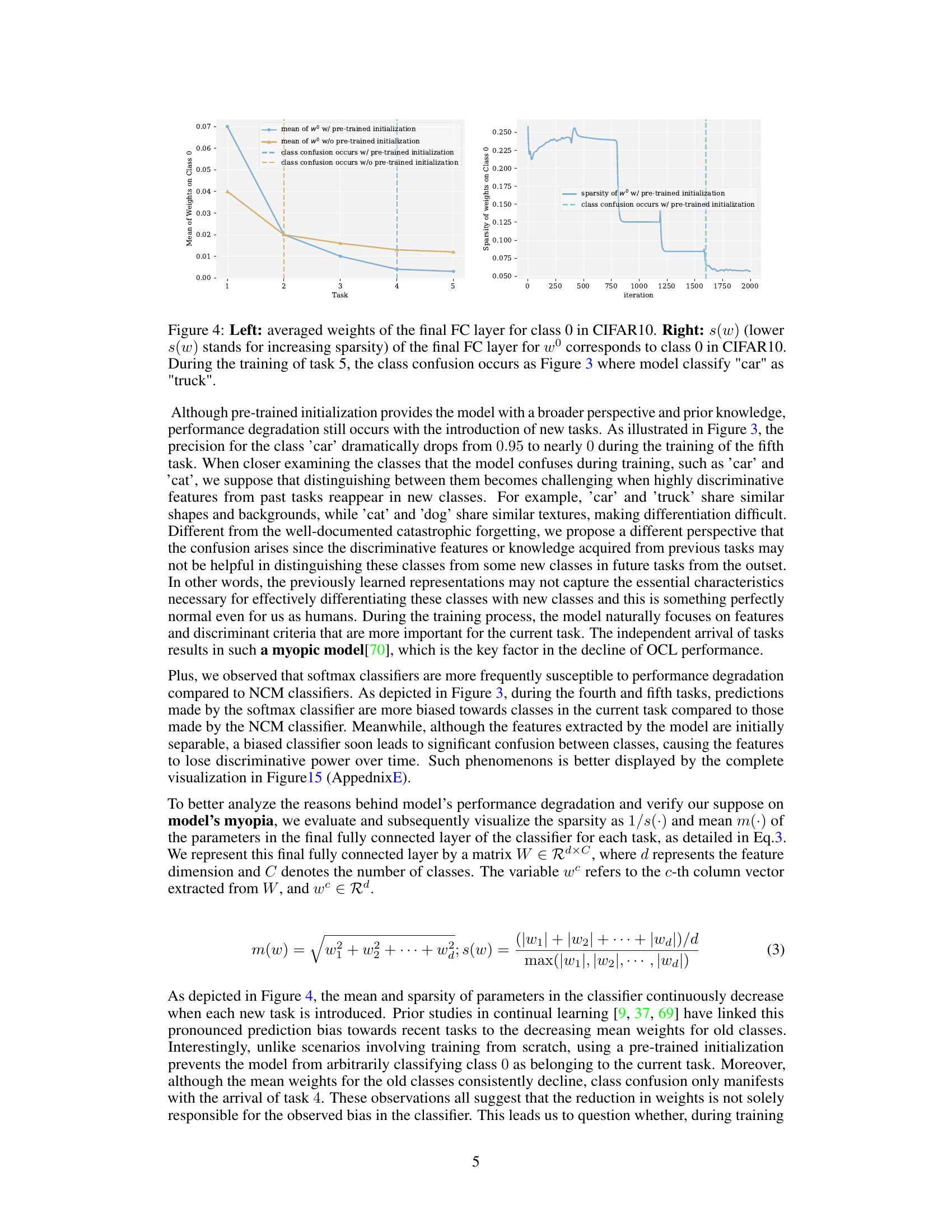
This figure shows two plots. The left plot displays the average weights of the final fully connected (FC) layer for class 0 in the CIFAR-10 dataset across five tasks. The right plot shows the sparsity (inverse of s(w)) of the weights for the same class and layer. Vertical dashed lines indicate the task where the model begins confusing ‘car’ with ’truck’. The plots illustrate how the model’s weights and sparsity change as it learns new tasks, highlighting the increased sparsity of the classifier in later tasks, which is linked to the model’s myopia.
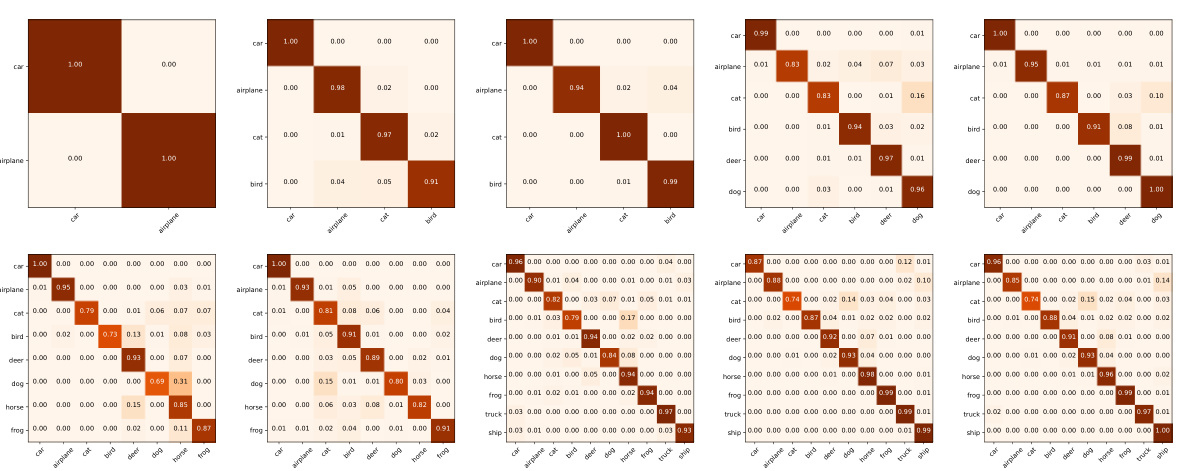
This figure displays the confusion matrices for both NCM and softmax classifiers during the training process. The confusion matrices visualize the model’s ability to correctly classify images and show how this changes over time. The difference between the two classifier types highlights different ways the model handles learning new classes.

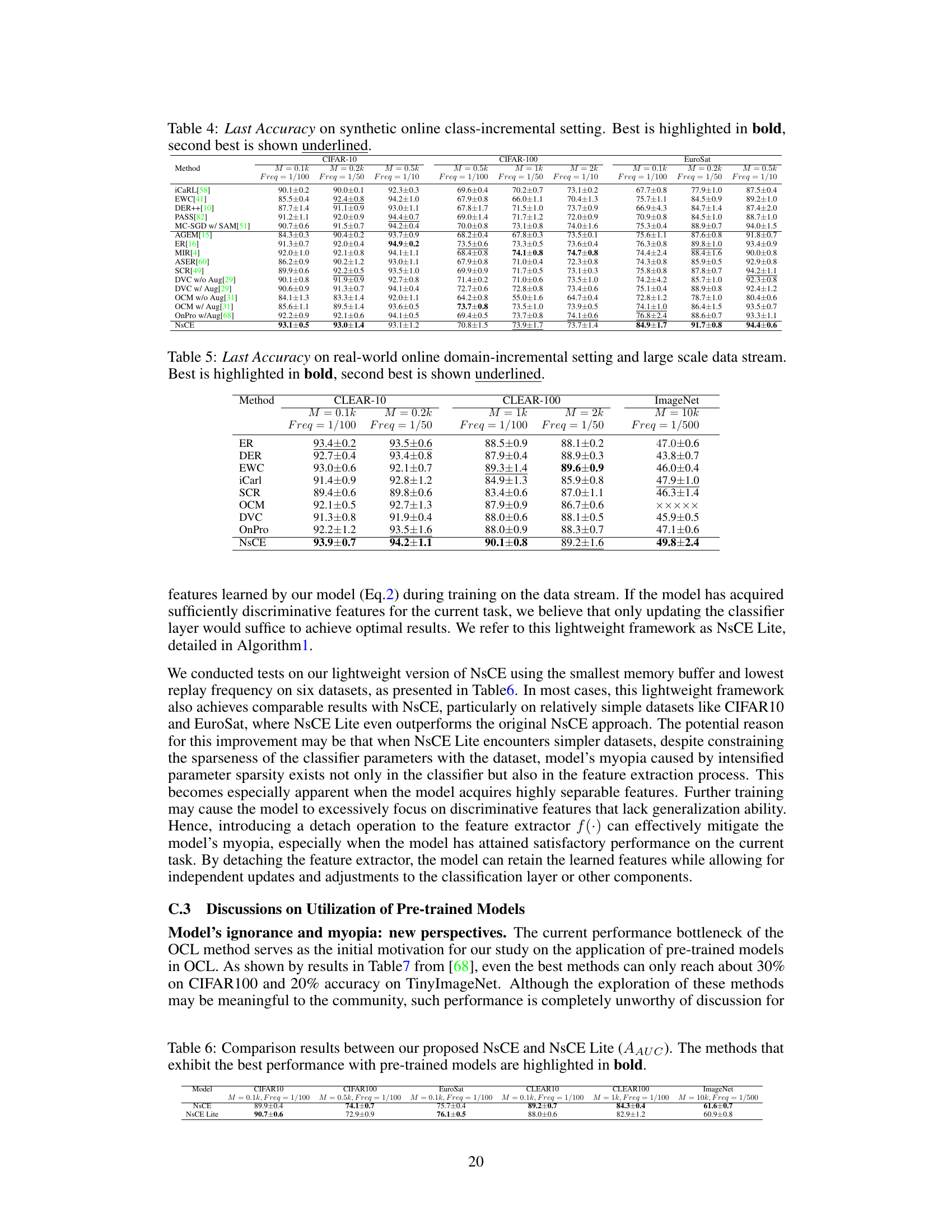
The left panel shows the sensitivity analysis on the threshold τ in targeted experience replay and the coefficient γ on the non-sparse maximum separate regularization. The right panel shows the sparsity of weights in the classifier for different continual learning algorithms, illustrating the effect of the non-sparse regularization on weight sparsity.

This figure displays the real-time accuracy curves for different continual learning strategies, comparing models trained with and without pre-trained models. The impact of varying experience replay frequency (1/100, 1/50, 1/10) is also shown. The results are presented across six datasets (CIFAR-10, CIFAR-100, EuroSAT, CLEAR-10, CLEAR-100, ImageNet) to showcase the effectiveness of the strategies under different data distributions and model throughput limitations. The single task setting helps isolate the model’s performance in processing the continuous arrival of data within a limited time frame without introducing the confounding effect of catastrophic forgetting from multiple tasks.
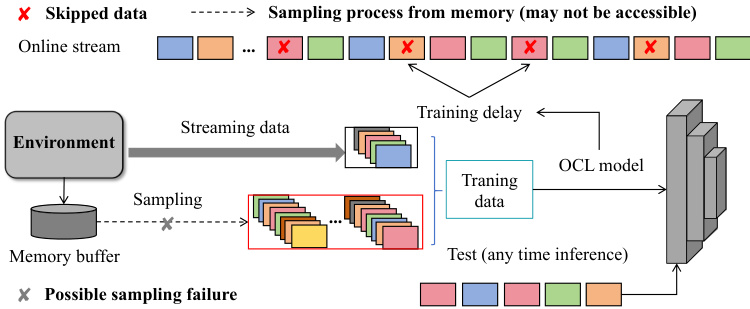
This figure illustrates the common framework of replay-based online continual learning (OCL) methods. It highlights the process of how data streams are sampled, potentially resulting in skipped data due to slow model training speed. The memory buffer is shown, with the process of sampling from it which may not always be successful. This sampling process then leads to the training delay in the OCL model. The figure also indicates that test (any-time inference) happens as a continuous process. The mismatch between training speed and data stream rate introduces two main concerns: possible sampling failure and training delays.
This figure displays the real-time accuracy curves for models trained with and without pre-trained models on various datasets (CIFAR-10, CIFAR-100, EuroSAT, CLEAR-10, CLEAR-100, and ImageNet). It also shows the effect of different experience replay frequencies on the model’s accuracy over time. The results highlight the improvement achieved by using pre-trained models and demonstrate a trade-off between model throughput and performance, where using more sophisticated replay strategies generally increases accuracy but also decreases throughput.
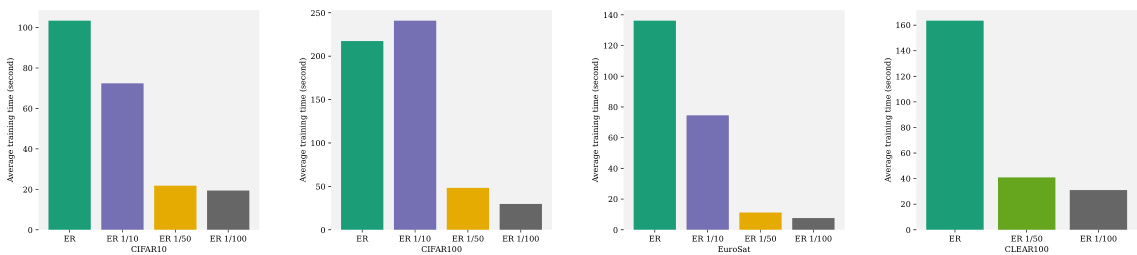
This figure shows the real-time accuracy of online continual learning (OCL) models on several datasets (CIFAR-10, CIFAR-100, EuroSAT, CLEAR-10, CLEAR-100, and ImageNet). It compares models trained with and without pre-trained models and also shows the impact of different experience replay frequencies. The single-task setting isolates model’s ignorance for better evaluation.
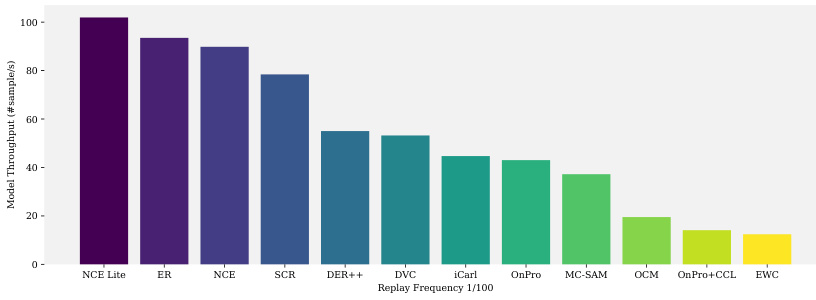
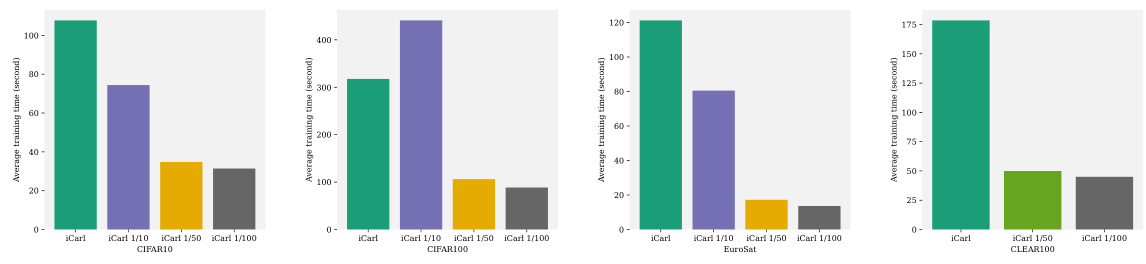
This figure presents a bar chart comparing the average model throughput of eleven different online continual learning (OCL) methods across six datasets. The replay frequency is set to 1/100. The chart visually represents the efficiency of each method in processing data samples per unit of time. Higher bars indicate a higher throughput, suggesting that those OCL methods can handle a larger volume of data in a given time frame.
This figure displays the real-time accuracy of various online continual learning (OCL) models. It compares the performance of models trained with and without pre-trained models (using ImageNet), under both traditional and single-task settings. The impact of different strategies (experience replay, contrastive learning, etc.) is also shown. The figure provides evidence of the ‘model’s ignorance’ phenomenon described in the paper, where models struggle to learn effectively from a single pass of data in a continuous stream.
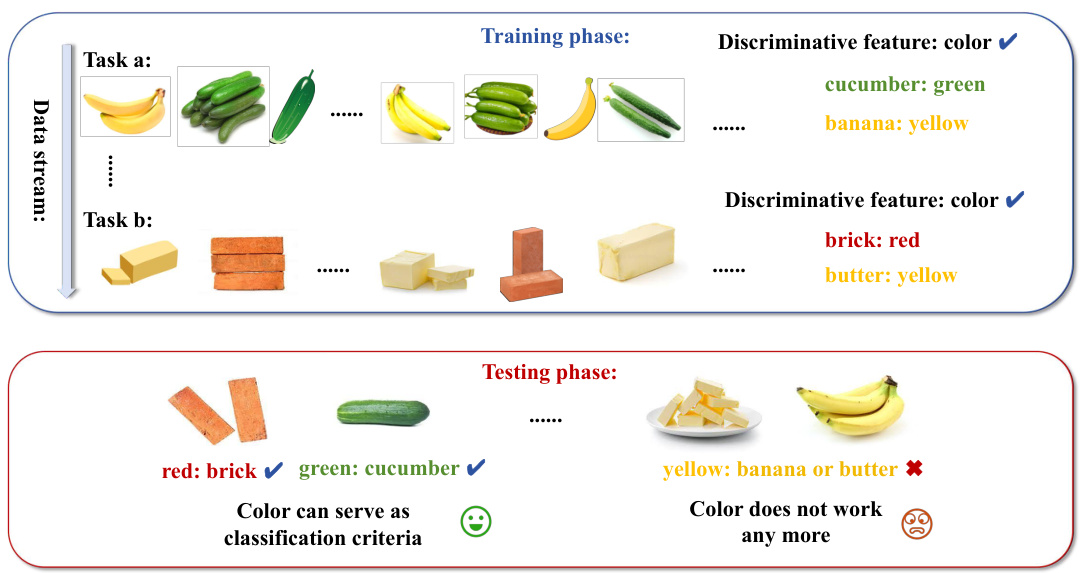
This figure illustrates the concept of ‘model’s myopia’ using a simple example. In the training phase, the model learns to distinguish between bananas and cucumbers based on their color (yellow vs. green). Similarly, it learns to distinguish between bricks and butter based on color (red vs. yellow). However, in the testing phase, the model fails to distinguish between butter and bananas because both are yellow. This shows how focusing on short-term discriminative features (color in this case) can lead to poor generalization and confusion when encountering new tasks or similar features in new classes. The model’s ‘myopia’ prevents it from considering broader features or more robust classification criteria that would have avoided this confusion.
This figure compares the real-time accuracy of various online continual learning (OCL) models trained with and without pre-trained models (ImageNet) under two different settings: traditional OCL and the proposed single-task setting. It illustrates the effect of common OCL strategies (experience replay, contrastive learning, distillation chains) on model accuracy over iterations. The single-task setting isolates the impact of single-pass training from other OCL challenges, revealing that pre-trained initialization is crucial for satisfactory performance.

This figure shows the confusion matrices of a softmax classifier and a nearest class mean (NCM) classifier trained on CIFAR10 with and without ImageNet pre-trained initialization. The matrices visualize the model’s classification performance at different stages of training, highlighting the impact of pre-trained initialization and the difference in performance between softmax and NCM classifiers.
More on tables
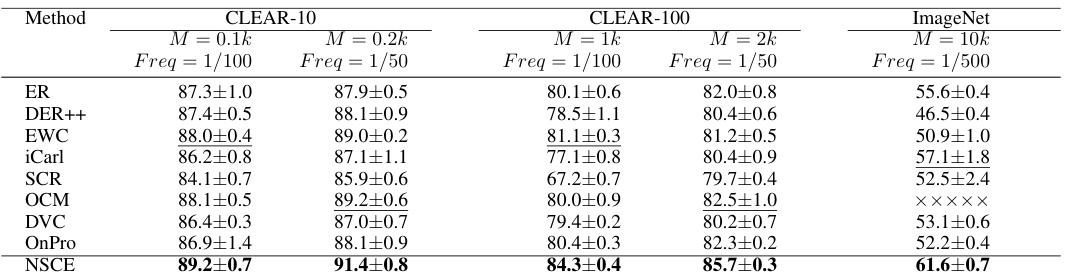
This table presents the Area Under the Curve of Accuracy (AAUC) results for several continual learning methods on three large-scale real-world online domain-incremental datasets (CLEAR-10, CLEAR-100, and ImageNet). The results are shown for different memory buffer sizes (M) and replay frequencies (Freq). The OCM method is excluded for ImageNet because of its high computational cost. The table demonstrates the performance of various methods under different data stream conditions and resource constraints.

This ablation study analyzes the contribution of each component in the NsCE framework by evaluating the performance on six different datasets with different memory buffer sizes and replay frequencies. The results show the individual and combined effects of the non-sparse regularization (Ls), maximum separation (Lp), and targeted experience replay on the model’s accuracy. It demonstrates the importance of each component and their synergistic interaction in improving performance.

This table presents the last accuracy results for various continual learning methods on three benchmark datasets (CIFAR-10, CIFAR-100, and EuroSat) under different memory buffer sizes and replay frequencies. The results are displayed to compare the performance of different methods and analyze the impact of memory buffer and replay frequency on the model’s performance.

This table shows the results of Area Under the Accuracy Curve (AAUC) on several large-scale real-world online domain-incremental data streams. The results compare the performance of NsCE against several existing continual learning methods. Note that OCM on ImageNet is excluded due to its high computational cost. The table includes results using varying memory buffer sizes (M) and data replay frequencies (Freq).

This table compares the Area Under the Curve of Accuracy (AAUC) achieved by the proposed NsCE and its lightweight version, NsCE Lite, across six different image classification datasets (CIFAR10, CIFAR100, EuroSat, CLEAR10, CLEAR100, and ImageNet). Different memory buffer sizes and replay frequencies are used for each dataset to simulate real-world scenarios. The results show that NsCE and NsCE Lite achieve comparable performance, especially on less complex datasets. The table highlights the best performance obtained using pre-trained models for each dataset.

This table presents the Average Area Under the Curve (AAUC) of various continual learning methods across three benchmark datasets (CIFAR-10, CIFAR-100, EuroSat). The results are shown for different memory buffer sizes (M) and experience replay frequencies. The best and second-best performing methods for each configuration are highlighted to facilitate comparison and analysis of the methods’ performance.

This table presents the Area Under the Curve of Accuracy (AAUC) for different model architectures (ViT-T and ViT-S) with and without pre-training on ImageNet using Masked Autoencoder. The results are shown for five datasets: CIFAR10, CIFAR100, EuroSat, SVHN, and TissueMNIST. The difference in performance (Δ) between models with and without pre-training is also provided, highlighting the significant improvement achieved through pre-training.
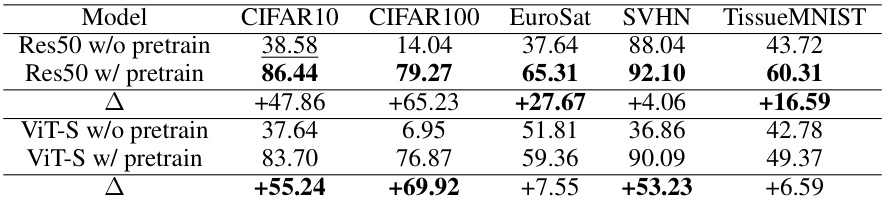
This table presents the Area Under the Curve of Accuracy (AAUC) for different model architectures (ViT-T and ViT-S) with and without pre-training on ImageNet using Masked Autoencoder. The results are shown for five different datasets: CIFAR10, CIFAR100, EuroSat, SVHN, and TissueMNIST. The table highlights the improvement in performance achieved by using pre-trained models. The difference (Δ) in AAUC between models with and without pre-training is also provided.

This table shows the Area Under the Curve of Accuracy (AAUC) for different models (ResNet18, ResNet50, WRN28-2, WRN28-8, ViT-T, ViT-S) with and without pre-training on ImageNet using Masked Autoencoder. The results are presented for six datasets: CIFAR10, CIFAR100, EuroSat, SVHN, and TissueMNIST. The bold values indicate the best performance achieved with pre-training, while underlined values highlight the best without pre-training. The table demonstrates how pre-training affects performance on different network architectures and datasets.

This table compares the inference time of the proposed NsCE method with three popular continual learning methods: ER, iCaRL, and OnPro, across three datasets: CIFAR10, EuroSat, and ImageNet. The results show that the proposed NsCE method achieves comparable inference speed to ER, while iCaRL and OnPro exhibit slower inference speeds, likely due to additional computations required for feature similarity or extra projectors.

This table compares the performance of several anti-forgetting techniques (EWC, AGEM, SCR, OnPro) and the proposed NSCE method on six different datasets (CIFAR10 with/without experience replay, CIFAR100 with/without experience replay, EuroSat with/without experience replay). The baseline performance is also shown. The results highlight the relative effectiveness of each method in mitigating catastrophic forgetting in continual learning. Note that ‘w/ ER’ means ‘with experience replay’ and ‘w/o ER’ means ‘without experience replay’.
Full paper#