↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual grounding, identifying objects in images based on textual descriptions, is a challenging multi-modal task. Existing DETR-based methods primarily focus on enhancing the decoder, often using randomly initialized or linguistically-embedded queries, which limits performance. This method often overlooks the importance of incorporating multi-level image features. These limitations hinder the model’s ability to accurately pinpoint the target object, increasing learning difficulty.
To address these challenges, the paper proposes RefFormer. This novel approach introduces a ‘query adaption module’ seamlessly integrated into CLIP (Contrastive Language–Image Pre-training), generating referential queries providing prior context to the decoder. RefFormer also incorporates multi-level visual features, enhancing context for the decoder. The results demonstrate RefFormer’s superior performance over existing state-of-the-art approaches on various visual grounding benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to visual grounding, a crucial task in computer vision and natural language processing. The RefFormer method improves accuracy and efficiency by focusing on generating more informative queries, rather than solely focusing on decoder improvements. This opens avenues for future research into query generation techniques, multi-modal fusion strategies, and improving performance on similar vision-language tasks. It also offers a more efficient way to leverage the power of pre-trained models like CLIP, without extensive parameter tuning.
Visual Insights#
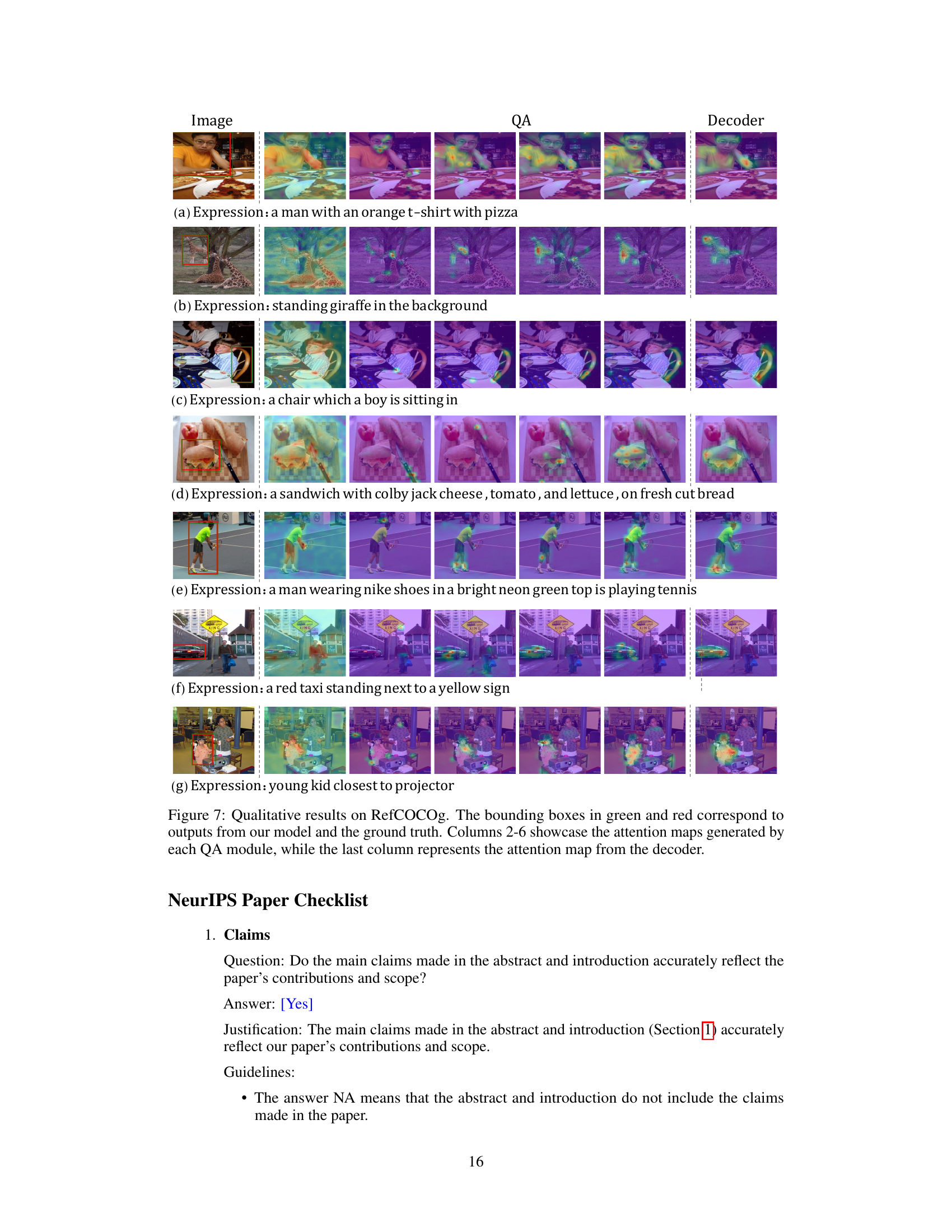
This figure compares a typical DETR-like visual grounding method with the proposed RefFormer method. Panel (a) shows the standard approach, where randomly initialized queries are fed directly to the decoder for object localization. Panel (b) illustrates the RefFormer architecture, which incorporates a query adaptation module (QA). The QA module iteratively refines the decoder’s input by learning context-related information from multiple levels within the CLIP backbone. This refined query provides a valuable prior, allowing the decoder to focus more effectively on the target object. Finally, panel (c) shows attention maps from the last layer of each QA module and the decoder, visually demonstrating the improved focus on the target object by the proposed method.

This table compares the performance of the proposed RefFormer model with several state-of-the-art visual grounding methods on three benchmark datasets: RefCOCO, RefCOCO+, and RefCOCOg. The table shows the performance (in terms of Recall@0.5) achieved by each method on the validation and test sets of each benchmark. It also notes which models used additional data beyond the standard RefCOCO datasets and which models simply combined the three datasets. The visual backbone used by each method is also specified.
In-depth insights#
RefQuery grounding#
RefQuery grounding, a novel approach to visual grounding, presents a significant advancement by directly addressing the limitations of traditional methods. The core innovation lies in introducing a ‘referential query’ that leverages the power of pre-trained models like CLIP to provide contextual information to the decoder. Unlike methods relying on randomly initialized or solely linguistically-driven queries, RefQuery grounding generates queries informed by target-relevant image features and language descriptions. This targeted approach significantly reduces the decoder’s learning burden, enabling it to focus more effectively on the target object. The integration of a query adaptation module seamlessly incorporates multi-level image features, enhancing the richness and accuracy of the referential query. This module also acts as an adapter, preserving the knowledge within the pre-trained model without requiring parameter fine-tuning, thus enhancing efficiency. The improved query generation, combined with a task-specific decoder, results in superior performance across various visual grounding benchmarks, demonstrating the effectiveness and efficiency of this novel approach.
CLIP adapter#
A CLIP adapter, in the context of visual grounding, is a module designed to leverage the pre-trained knowledge of CLIP (Contrastive Language–Image Pre-training) without extensive fine-tuning. It acts as a bridge, transferring CLIP’s rich visual-semantic understanding to a task-specific decoder. This approach is crucial because directly fine-tuning CLIP for visual grounding can be computationally expensive and may lead to overfitting or loss of general knowledge. The adapter selectively incorporates information from multiple levels of CLIP’s feature hierarchy, enriching contextual representations for improved accuracy and efficiency. This multi-level integration is key, as it allows the model to capture both fine-grained details and global context. Moreover, a well-designed CLIP adapter allows for seamless integration with different decoder architectures, providing flexibility in model design. By preserving the pre-trained weights of CLIP, the adapter ensures the model benefits from CLIP’s extensive knowledge, leading to faster convergence and better generalization on unseen data.
Multi-level fusion#
Multi-level fusion, in the context of visual grounding or similar multi-modal tasks, refers to the strategy of combining feature representations from different layers of a deep neural network (DNN). Instead of relying solely on the final, high-level DNN layer, which might only capture abstract concepts, multi-level fusion integrates information from earlier layers, which retain finer-grained details and lower-level visual features. This approach is beneficial because different layers encode various levels of abstraction; early layers contain low-level information like edges and textures, while later layers represent more semantic concepts. By combining these diverse layers, the model can achieve a more holistic understanding of the visual input, allowing for richer contextual information during the grounding process. This enhanced representation facilitates better correspondence between the visual scene and the language description. For instance, fine-grained details from lower layers could assist in pinpointing the exact location of an object, while high-level semantic information helps in correctly identifying the object itself. The success of multi-level fusion hinges on effective integration techniques. Methods range from simple concatenation to complex attention mechanisms, choosing the approach that best handles the inherent differences between the feature representations of different layers. Ultimately, multi-level fusion aims to improve the robustness and accuracy of multi-modal tasks, leading to more precise object localization and a more profound understanding of the relationship between the visual data and the associated textual description.
Ablation studies#
Ablation studies systematically assess the contribution of individual components within a model by removing or altering them. In the context of a research paper, this section would detail experiments designed to isolate the effects of specific elements. For instance, if a novel visual grounding model incorporates a new query adaptation module and a multi-modal decoder, ablation studies would investigate the performance impact of removing the adaptation module, using a standard decoder instead, or varying other hyperparameters. The results of ablation studies are crucial in validating the design choices and providing evidence that the proposed components genuinely improve the overall performance. The analysis might also explore the interaction between different parts, such as how the query module affects the decoder’s behavior, to gain a deeper understanding of the model’s inner workings. Ultimately, this section serves to confirm that improvements aren’t due to confounding factors or dataset artifacts, but rather stem directly from the contributions made by each individual component. Well-executed ablation studies rigorously confirm the significance and effectiveness of each part of the model. They are essential for establishing the robustness and credibility of the proposed method.
Future works#
Future research directions stemming from the ReferFormer model could involve several key areas. Extending the model to handle more complex linguistic expressions is crucial, going beyond simple sentences to encompass nuanced descriptions, relative clauses, and potentially even dialog. Improving the model’s robustness to noisy or ambiguous image data would also be beneficial, as this is a common challenge in real-world visual grounding tasks. Another important avenue for future research would be exploring alternative query generation methods, perhaps leveraging techniques from other areas of computer vision or natural language processing, possibly incorporating attention mechanisms more effectively. Further exploration into the trade-offs between model complexity and performance should be investigated, exploring lightweight architectures that might preserve accuracy while reducing computational demands. Finally, rigorous testing on a wider range of datasets and benchmark tasks, including tasks beyond standard visual grounding, would further establish the model’s generalizability and potential applicability.
More visual insights#
More on figures
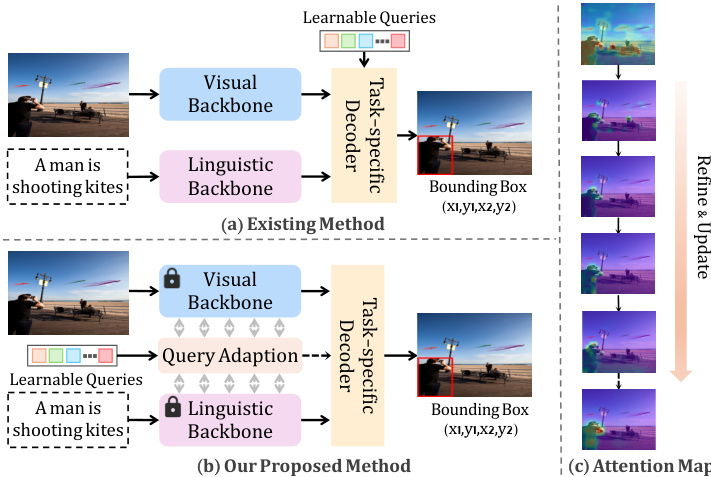
This figure illustrates the architecture of RefFormer, a novel approach for visual grounding. RefFormer uses a DETR-like structure and integrates a Query Adaptation (QA) module into multiple layers of the CLIP model. The QA module refines the target-related context iteratively, generating referential queries that improve the decoder’s performance and accuracy in locating target objects. The figure shows the flow of image and text features through CLIP, the iterative refinement process within the QA modules, and the final prediction by the task-specific decoder.

This figure shows the architecture of the Query Adaption Module (QA) which is a core component of the RefFormer model. The QA module takes image and text features as input and generates referential queries that are then used by the decoder. It consists of two main parts: 1. CAMF (Condition Aggregation and Multi-modal Fusion): This module fuses image and text features with learnable queries to generate a refined representation of the target object. 2. TR (Target-related Context Refinement): This module refines the output from the CAMF module using self-attention to further enhance target-related contextual semantics. The module iteratively refines the target-related context at different layers of the CLIP backbone. The output is a refined referential query and updated image and text features.

This figure shows the convergence curves of the proposed RefFormer method compared to two other visual grounding methods, TransVG and RefTR, on the RefCOCOg dataset. The y-axis represents the Prec@0.5 metric (precision at an IoU threshold of 0.5), indicating the accuracy of object localization. The x-axis represents the number of training epochs. The plot demonstrates that RefFormer achieves comparable or better performance than the other methods, but with significantly fewer training epochs, indicating improved training efficiency.

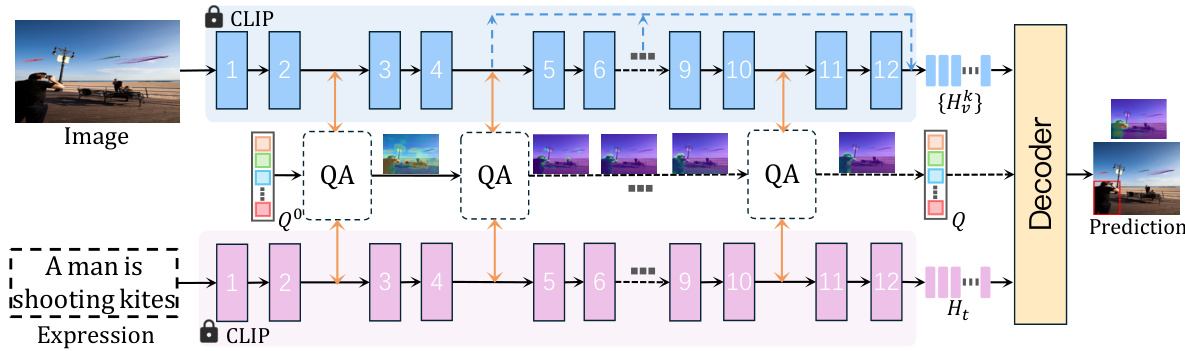
This figure shows several examples of visual grounding results using the RefFormer model. Each row represents a different image and its corresponding natural language expression. The first column shows the input image with a green bounding box indicating the ground truth location of the object mentioned in the expression. The following six columns visualize the attention maps of the query adaptation (QA) module at different layers of the CLIP backbone network. These attention maps highlight the regions of the image that the QA module focuses on at each layer, showcasing the progressive refinement of attention towards the target object. The last column displays the attention map from the decoder, indicating the final prediction made by the model. The attention maps illustrate how the QA module iteratively refines the target-related context and guides the decoder towards a more accurate localization of the object.
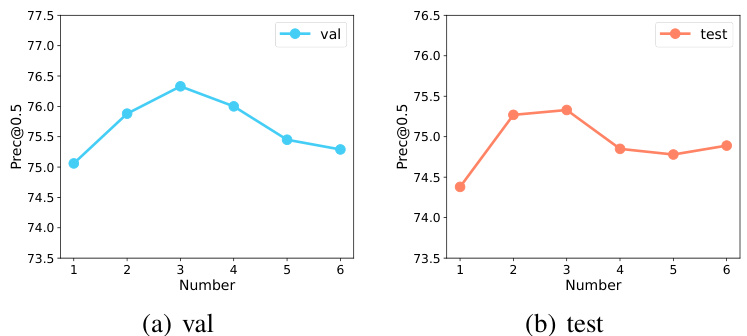
This figure shows the performance (Prec@0.5) of the model on the RefCOCOg dataset as the number of learnable queries is varied from 1 to 6. The left subplot displays the validation performance, while the right subplot shows the test performance. The results indicate an optimal number of learnable queries exists where increasing the number beyond that point does not significantly improve performance.

This figure shows the qualitative results of the proposed RefFormer model on the RefCOCOg dataset. Each row represents a different image and its corresponding caption. The first column displays the original image with the ground truth bounding box (green) and the model’s prediction (red). The following columns visualize the attention maps at different layers of the Query Adaption Modules (QA) and the final decoder. These attention maps illustrate how the model focuses its attention on the target object throughout the process. The progression from noisy attention maps to focused attention demonstrates the effectiveness of the model in refining its understanding of the target object based on textual information and multi-level visual features.

This figure shows qualitative results of the RefFormer model on the RefCOCOg dataset. For each image, the green bounding box indicates the ground truth location of the target object, while the red box represents the model’s prediction. The columns between the image and the final decoder output show the attention maps from the intermediate query adaptation (QA) modules at different layers of the CLIP backbone. These attention maps visualize how the model focuses on the relevant areas of the image as it refines the target-related context in each layer. The final column displays the attention map of the decoder, demonstrating the model’s final attention to the target.

This figure shows qualitative results of the RefFormer model on the RefCOCOg dataset. Each row represents a different image and its corresponding caption. The first column shows the original image with the ground truth bounding box (green) and the model’s prediction (red). The next six columns visualize the attention maps from each of the six query adaptation (QA) modules within the RefFormer, illustrating how the model focuses on the target object across different layers. The final column displays the attention map from the decoder, highlighting where the model ultimately focuses its attention for object localization.

This figure compares a standard DETR-like visual grounding method with the proposed RefFormer method. Panel (a) shows the existing method which uses randomly initialized queries fed directly into the decoder to predict the target object’s bounding box. Panel (b) illustrates the RefFormer method, which incorporates a Query Adaption Module (QA). The QA module learns target-related context iteratively, refining it layer by layer and providing more informative prior knowledge to the decoder. This leads to improved accuracy in locating the target object. Panel (c) displays the attention maps of the final layer within both the QA module and the decoder, visualizing where the models focus their attention during the prediction process.

This figure displays several examples of visual grounding results. Each row shows an image, the ground truth bounding box (red), the model’s prediction (green), and attention maps from each query adaptation module (QA) and the decoder. The attention maps visualize where the model focuses its attention during the process of localizing the target object, illustrating the iterative refinement process of the QA module and the decoder’s final focus on the target.

This figure shows example results of the RefFormer model on the RefCOCOg dataset. For each example, it displays the input image with a bounding box highlighting the target object specified by the language expression. Then, it shows the attention maps generated by each Query Adaptation (QA) module within the RefFormer model. These attention maps visualize which parts of the image the model is focusing on at each stage of processing. Finally, it displays the attention map generated by the decoder of the model, which shows where the model predicts the object is located. The sequence of attention maps demonstrates how the model progressively refines its focus on the target object throughout the QA modules and the decoder.

This figure shows the qualitative results of the RefFormer model on the RefCOCOg dataset. For each example, it displays the input image, the ground truth bounding box (red), the model’s predicted bounding box (green), and a series of attention maps. The attention maps visualize the model’s focus at different stages of processing, showing how the query adaptation (QA) modules and the decoder attend to different parts of the image. The QA modules progressively refine the attention to the target object, ultimately leading to a more accurate prediction by the decoder.
More on tables

This table compares the performance of the proposed method against state-of-the-art approaches on two visual grounding benchmarks: Flickr30K Entities and ReferItGame. It shows the test set performance (Prec@0.5) for each method, highlighting the superiority of the proposed approach.
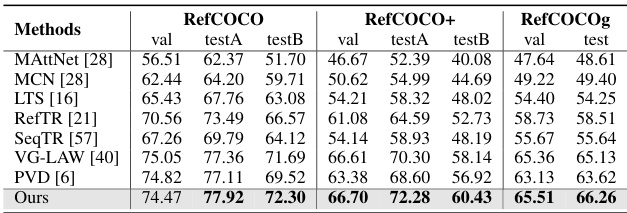
This table compares the proposed method’s performance against other state-of-the-art visual grounding methods on three benchmark datasets: RefCOCO, RefCOCO+, and RefCOCOg. The table shows the performance (in terms of accuracy) on validation and test sets, categorized by the type of visual grounding method (two-stage, one-stage, transformer-based) and the backbone network used. It also notes which methods used additional datasets beyond the standard RefCOCO datasets and which methods simply combined the three RefCOCO datasets. The results demonstrate the superiority of the proposed method.
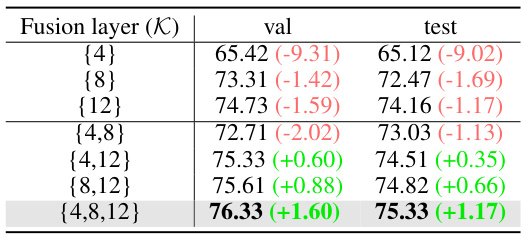
This table presents the ablation study on the position of the Query Adaption module (QA) in the RefFormer model. It shows the performance (in terms of Prec@0.5) on the RefCOCOg dataset for different QA positions (fusion layer K). The results demonstrate the impact of adding the QA module at various layers of the CLIP backbone on the overall accuracy. The best performance is achieved when QA is inserted at multiple layers ({4, 6, 8, 10, 12}).
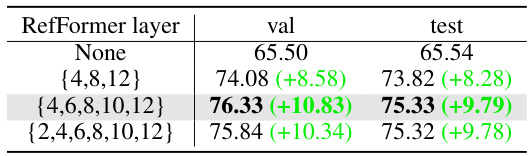
This table presents the ablation study results on the RefCOCOg dataset, focusing on the impact of the Query Adaption (QA) module’s position within the CLIP model. Different combinations of layers in the CLIP model where the QA module is inserted are tested, showing the effect on the model’s performance. The results demonstrate that strategically placing the QA module across multiple layers significantly improves the model’s performance, highlighting the effectiveness of this approach in leveraging multi-level contextual information.
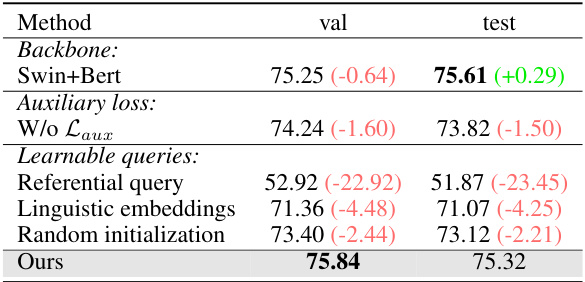
This table presents the ablation study results on the RefCOCOg dataset, assessing the impact of different components of the proposed RefFormer model. It shows the performance (measured by validation and test Prec@0.5) when using different backbones (Swin+Bert vs. the default), excluding the auxiliary loss (Laux), and using different query generation methods (referential query, linguistic embeddings, and random initialization). The results highlight the contribution of each component to the overall performance improvement.

This table presents the ablation study results focusing on the direction of the feature flow from the Query Adaption Module (QA) in the RefFormer model. The experiment was conducted on the RefCOCOg benchmark. The table compares the performance (measured in terms of ‘val’ and ’test’ scores) of four different configurations: ‘None’ (no feature flow from QA), ‘Only text’ (textual features only), ‘Only image’ (image features only), and ‘Image & Text’ (both image and text features). The numbers in parentheses show the performance improvement relative to the ‘None’ configuration, highlighting the effect of bidirectional feature flow.
Full paper#