↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generative Adversarial Networks (GANs) are known for their training instability and reliance on numerous empirical tricks. Existing relativistic GAN losses, while addressing mode collapse, often lack convergence guarantees. This leads to suboptimal performance and hinders wider adoption of GANs in various fields.
This paper introduces R3GAN, a novel GAN architecture that uses a mathematically well-behaved regularized relativistic GAN loss. This loss, unlike previous versions, provides local convergence guarantees. By discarding ad-hoc training tricks and using modern network architectures, R3GAN achieves state-of-the-art performance on several benchmark datasets. This demonstrates that principled design choices can lead to simpler, yet superior, GAN models and improve their scalability and reliability.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the common belief that GANs are difficult to train. By introducing a novel, well-behaved loss function and modern architectures, it provides a simpler, yet superior GAN baseline. This work opens new avenues for GAN research and simplifies the training process, potentially leading to wider adoption of GANs in various applications.
Visual Insights#
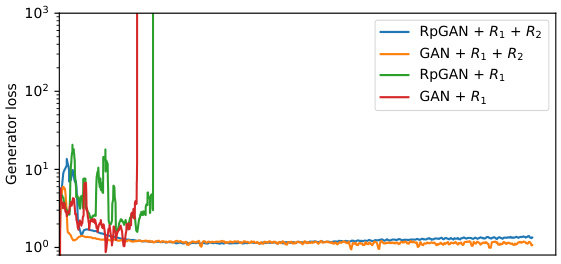
This figure shows the generator loss curves during training for four different GAN loss functions on the StackedMNIST dataset. The four loss functions are combinations of the RpGAN (relativistic pairing GAN) loss and the R1 and R2 gradient penalties. The graph demonstrates that using only R1 leads to training instability and divergence in all cases, while the addition of R2 provides stability and convergence for both RpGAN and standard GAN losses. This highlights the importance of R2 as a regularizer for stable GAN training.
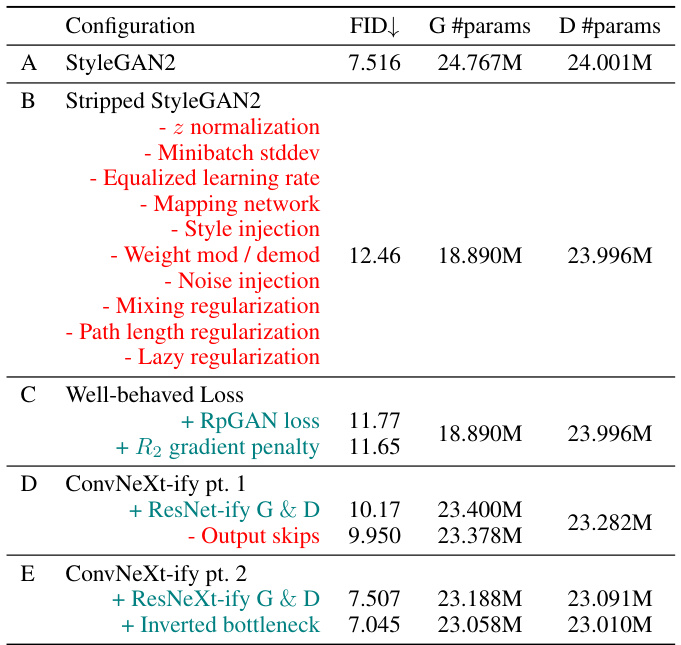
This table shows the FID scores and model parameters (#params) for different configurations of the R3GAN model. It tracks the changes in FID (Frechet Inception Distance) and model size as the authors progressively remove StyleGAN2’s tricks and adopt a more modern architecture. Config A is the StyleGAN2 baseline. Config B removes all StyleGAN2’s tricks, demonstrating the importance of the proposed loss function. Config C incorporates the improved loss. Config D modernizes the network backbone and reduces the number of parameters. Config E further modernizes the architecture by increasing the width with depthwise convolution and inverting the bottleneck, achieving state-of-the-art results.
In-depth insights#
RpGAN Stability#
The RpGAN (Relativistic Pair GAN) stability analysis in the provided research paper is crucial for understanding its practical applicability. The authors demonstrate that the standard RpGAN objective suffers from non-convergence issues, a significant limitation hindering its broader use. This instability arises because the objective function’s landscape can contain regions that prevent gradient descent methods from reaching a global optimum. A key contribution of the paper is the introduction of zero-centered gradient penalties (R1 and R2) to address RpGAN’s instability. By mathematically analyzing the impact of the penalties on the RpGAN’s Jacobian (a matrix showing the local sensitivity of the loss function), they demonstrate that the addition of R1 and R2 guarantees local convergence. This result is particularly important as it offers theoretical support for a solution to a practical problem encountered in training GANs. The proof of convergence addresses the mode dropping issue, showing that under certain assumptions, the RpGAN with the proposed regularization scheme can successfully converge to a true data distribution, avoiding the issue of the generator producing limited diversity of samples. The paper emphasizes that this theoretical stability provided by the addition of the regularization terms is crucial as the unregularized model fails to exhibit global convergence. This adds weight to the practical demonstration in the paper of the regularized RpGAN performing better than the original RpGAN and ultimately leads to a new, more stable, and modern baseline GAN.
Modern GAN Design#
The paper advocates for a modernized GAN architecture that moves beyond the reliance on empirical tricks commonly associated with GAN training. The authors challenge the notion that GANs are inherently difficult to train, arguing that a well-behaved loss function, combined with modern architectural design, can achieve state-of-the-art performance without the need for ad-hoc adjustments. Their proposed R3GAN baseline highlights the significance of choosing a loss that mathematically guarantees local convergence. This allows the use of advanced architectures like ResNets and eliminates the need for many of the previously employed heuristics. The resulting GAN surpasses existing approaches in terms of FID scores, demonstrating the effectiveness of their principled approach. The paper emphasizes that simplicity and stability are key aspects of modern GAN design, proving that high-quality image generation is achievable without over-engineering or reliance on unexplained tricks.
R3GAN: Baseline#
The R3GAN baseline represents a significant departure from previous GAN architectures, emphasizing simplicity and principled design over empirical tricks. Its core innovation lies in the mathematically-derived relativistic GAN loss, augmented with gradient penalties (R1 and R2), which ensures improved stability and local convergence. This well-behaved loss function eliminates the need for ad-hoc training techniques common in prior GANs. By discarding outdated backbones and adopting modern architectures like ResNets and grouped convolutions, R3GAN achieves state-of-the-art performance across multiple datasets, demonstrating the potential of a principled approach to GAN training. The simplification showcases that achieving high-quality image generation does not necessitate complex empirical modifications, providing a solid foundation for future research. The success of R3GAN challenges the widely held belief that GANs are inherently difficult to train, highlighting the importance of theoretical understanding in advancing GAN methodologies.
Empirical Analysis#
An Empirical Analysis section in a research paper would typically present the results of experiments designed to test the paper’s hypotheses or claims. It should meticulously detail the experimental setup, including datasets used, evaluation metrics, and any relevant hyperparameters. A strong analysis would go beyond simply reporting numbers; it would interpret the results in the context of the paper’s theoretical contributions, highlighting both successes and limitations. Visualizations, such as graphs and tables, are crucial for conveying results effectively and should be used extensively. A key aspect is establishing statistical significance to demonstrate whether observed effects are likely due to the proposed methods rather than random chance. Comparative analysis, benchmarking against state-of-the-art approaches, strengthens the paper’s findings by providing context to the results’ impact and implications within the field. Finally, a thorough discussion of limitations and potential sources of bias is essential for maintaining the paper’s integrity and credibility. Reproducibility is key; the methods and data should be fully disclosed to allow others to replicate the findings.
Future GANs#
The heading ‘Future GANs’ prompts reflection on the potential advancements in generative adversarial networks. Building on the paper’s findings, particularly the creation of a stable, minimalist baseline GAN (R3GAN), future research could focus on scalability to higher resolutions and larger datasets, incorporating more sophisticated techniques like attention mechanisms from vision transformers. Furthermore, exploration of adaptive normalization and disentanglement methods within the generator could enable more controllable generation, moving beyond simple image synthesis to tasks such as image editing and manipulation. The well-behaved loss function presented in R3GAN provides a solid foundation for these advancements, while addressing previous issues of mode collapse and instability. However, it is crucial to acknowledge the potential ethical implications associated with more powerful GAN models, especially concerning issues of deepfakes and misinformation. Therefore, future work must carefully consider and address these risks alongside technical progress.
More visual insights#
More on figures

This figure shows the training curves for the generator (G) loss using different loss functions on the StackedMNIST dataset. The x-axis represents the wall time, and the y-axis shows the generator’s loss. The plot compares four different loss functions: RpGAN + R1 + R2, GAN + R1 + R2, RpGAN + R1, and GAN + R1. It demonstrates that using both R1 and R2 regularization is crucial for preventing divergence and ensuring convergence during training, unlike using only R1, which leads to training failure. The results highlight the importance of the proposed regularized relativistic GAN loss for stable training.
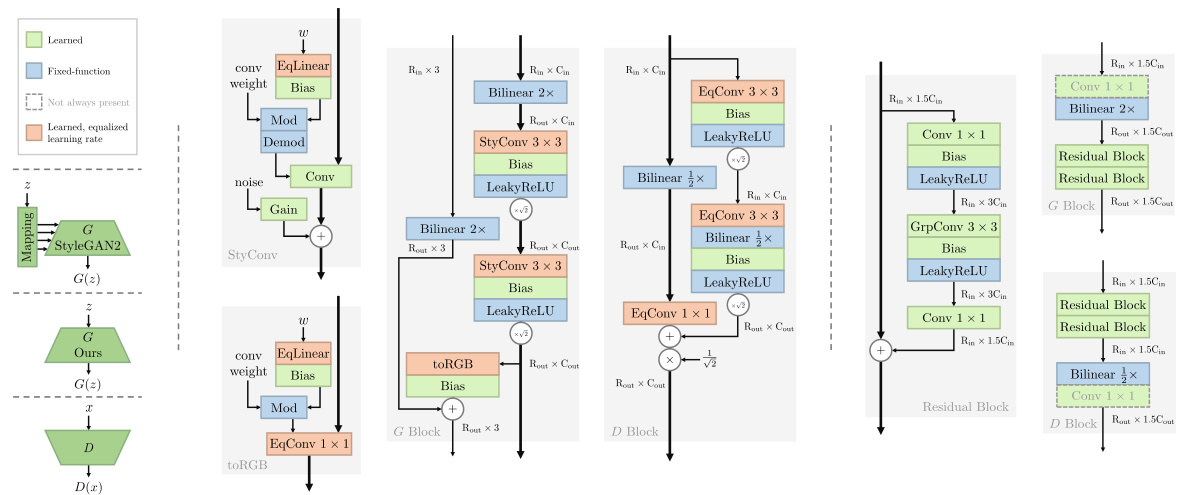
This figure compares the architectures of StyleGAN2 and the proposed R3GAN model. It highlights key differences, showing how R3GAN simplifies the StyleGAN2 architecture by removing unnecessary components while adopting modern convolutional network designs for improved performance and stability. The figure visually depicts the building blocks of each architecture and emphasizes the streamlined design of R3GAN.

This figure compares the performance of various GAN and diffusion models on the CIFAR-10 dataset in terms of FID score and the number of parameters (in millions). It shows that the proposed model (Ours-Config E) achieves a lower FID score with a significantly smaller number of parameters compared to other state-of-the-art models, demonstrating its efficiency and effectiveness.

This figure shows several qualitative examples of images generated by the R3GAN model (Config E) on the FFHQ-256 dataset. The images are arranged in a grid to showcase the model’s ability to generate diverse and realistic-looking faces. The high quality of the generated faces demonstrates the effectiveness of the proposed model and its ability to overcome issues often associated with GAN training, such as mode collapse and lack of diversity.

This figure shows samples generated by the R3GAN model (Config E) on the Stacked-MNIST dataset. Stacked-MNIST is a challenging dataset consisting of 1000 uniformly distributed modes, making it a good test of a GAN’s ability to avoid mode collapse and generate diverse samples. The samples shown in the figure illustrate the variety of digits generated by the R3GAN model, demonstrating its capability to capture the different styles and variations present in the dataset. The color scheme used in the samples likely highlights aspects of the generated images, potentially indicating different features or aspects of the underlying digit representation learned by the GAN.

This figure shows a grid of 64 images generated by the R3GAN model (Config E) trained on the FFHQ-256 dataset. The images are high-quality and diverse, demonstrating the model’s ability to generate realistic and varied facial images. The caption is quite short, so this description provides more detail. This figure supports the paper’s claim of achieving state-of-the-art image generation quality using a simple and modern GAN architecture.

This figure shows several qualitative examples of images generated by the R3GAN model (Config E) on the FFHQ-256 dataset. The images are arranged in a grid to showcase the diversity and quality of the generated faces. The quality and diversity of the generated images demonstrate the effectiveness of the proposed method in generating high-quality and realistic images.

This figure shows a qualitative evaluation of the ImageNet-32 dataset generated samples using the R3GAN model’s Config E. It provides a visual representation of the model’s ability to generate diverse and realistic images from the ImageNet-32 dataset. The image is a grid of many small images, each representing a different sample generated by the model. The quality and diversity of these samples are indicative of the overall performance of the R3GAN model.

This figure shows a grid of 256 images generated by the R3GAN model (Config E) on the ImageNet-32 dataset. Each image is 32x32 pixels and represents a sample from the model’s learned distribution. The variety and quality of the generated images illustrate the model’s ability to produce realistic and diverse samples of various animals and objects from the ImageNet dataset. The image quality is high, demonstrating the effectiveness of the proposed R3GAN architecture and training approach.

This figure shows a grid of 256 images generated by the R3GAN model (Config E) on the ImageNet-32 dataset. Each image is 32x32 pixels and represents a sample from the model’s learned distribution of images. The diversity and quality of the generated images provide a visual assessment of the model’s performance. The caption is short, so this description expands on the figure’s purpose and content.
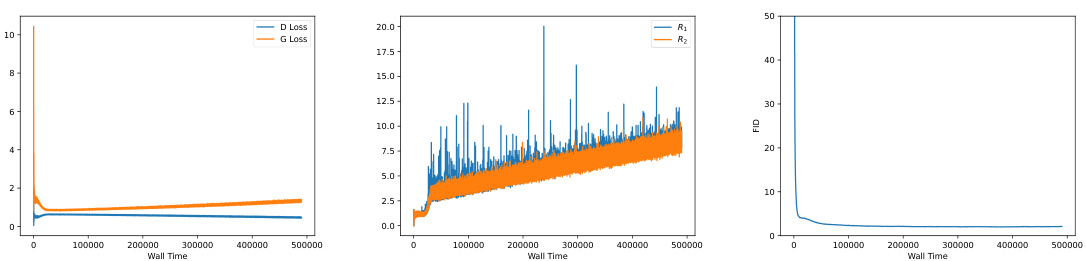
The figure shows the generator loss curves for different GAN training objectives on the StackedMNIST dataset. The objectives compared include the standard GAN loss, the RpGAN loss, and variations with and without R1 and R2 gradient penalties. The key observation is that only the combination of RpGAN and both R1 and R2 penalties produces stable training that avoids divergence and mode dropping. The result highlights the importance of the proposed regularized relativistic GAN loss for stability and achieving full mode coverage.
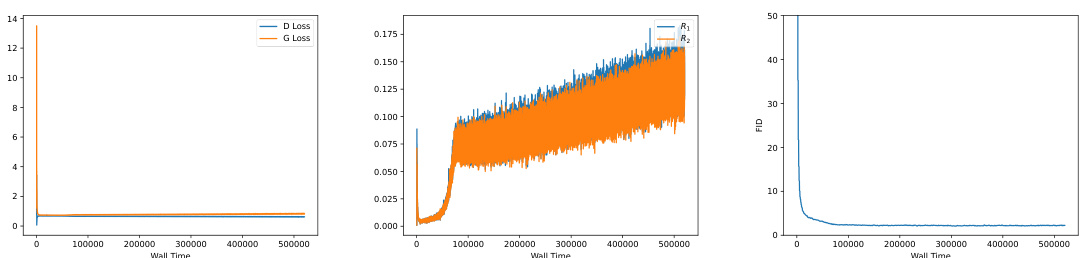
The figure shows the training curves of the generator’s loss for different GAN objectives on the StackedMNIST dataset. The plot demonstrates that using only the R1 regularization results in training divergence for both the standard GAN loss and the RpGAN loss. However, when both R1 and R2 regularizations are used, stable training and convergence are achieved for both losses. This highlights the importance of using both regularizations for training stability in GANs.
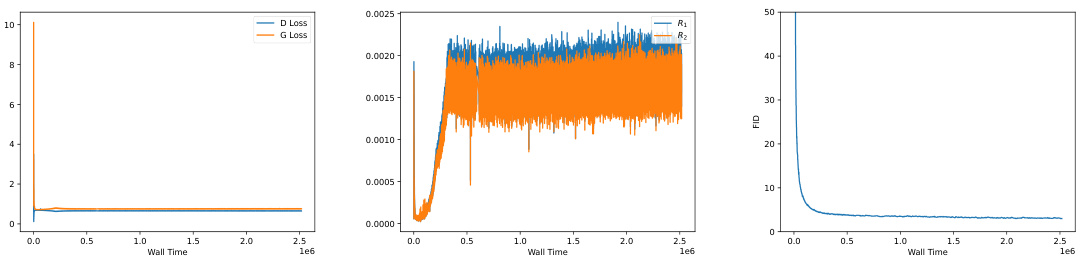
This figure shows the training curves for the generator (G) loss using different loss functions on the StackedMNIST dataset. The x-axis represents the training time (wall time), and the y-axis represents the generator loss. The plot demonstrates that using RpGAN + R1 regularization (orange line) leads to stable training with relatively low loss. Conversely, GAN + R1 (blue line) results in unstable training, with the loss diverging after a certain number of training steps. This highlights the importance of including both R1 and R2 regularizations for stable GAN training.
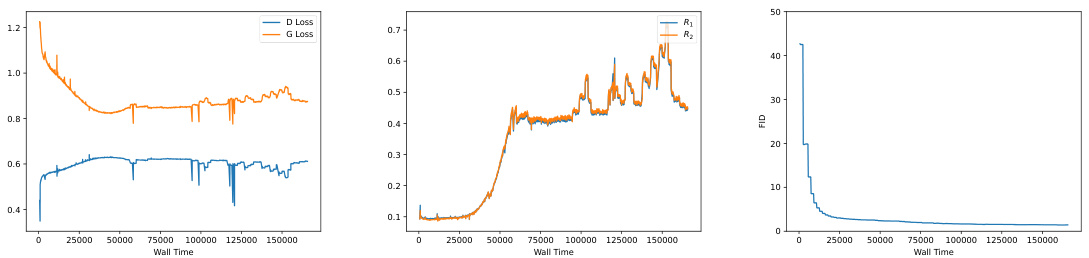
This figure shows the training curves for the generator (G) loss using different objective functions in a GAN setting. It demonstrates the impact of regularization terms (R1 and R2) on training stability. Using only R1 leads to divergence (the loss explodes), whereas the combination of R1 and R2 ensures stable training and convergence. The results support the claim that RpGAN with both R1 and R2 regularization is necessary for stable GAN training.
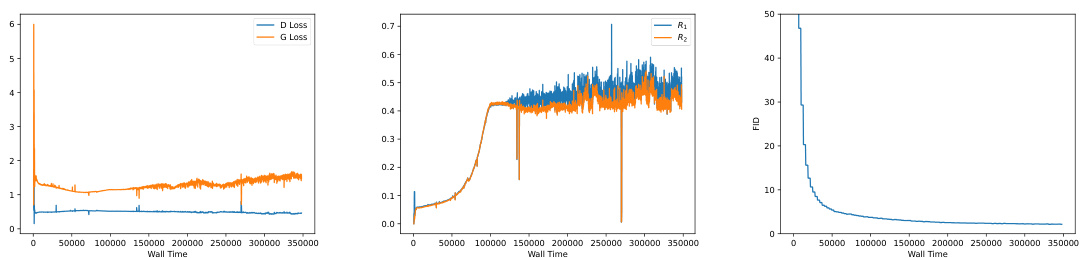
This figure shows the training curves of the generator (G) loss for different GAN objective functions on the StackedMNIST dataset. The x-axis represents training time, and the y-axis represents the generator loss. The different lines represent different objective functions: RpGAN (relativistic pairing GAN) with and without R1 and R2 regularization, as well as the standard GAN loss with and without R1 and R2 regularization. The plot demonstrates that using only R1 regularization leads to training divergence for both RpGAN and the standard GAN loss, while the inclusion of both R1 and R2 regularization ensures stable convergence for both.
More on tables
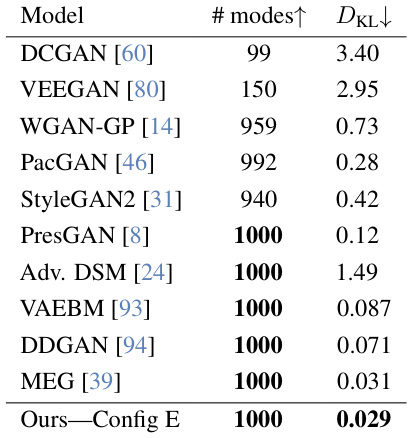
This table shows the mode coverage and reverse KL divergence (DKL) for different generative models on the StackedMNIST dataset. StackedMNIST is a dataset with 1000 uniformly-distributed modes, making it a good benchmark for evaluating a model’s ability to avoid mode collapse (generating only a subset of the possible modes) and generate diverse samples. The table compares several GANs (Generative Adversarial Networks) and likelihood-based models. The ‘# modes ↑’ column indicates how many of the 1000 modes were successfully covered by the model’s generated samples. The ‘DKL ↓’ column shows the reverse KL divergence between the model’s generated sample distribution and the true uniform distribution; lower values indicate better mode coverage.
This table presents a comparison of different generative models on the FFHQ dataset at 256x256 resolution. The models are evaluated using FID (Fréchet Inception Distance), a metric that measures the similarity between the generated images and real images. The NFE (Number of Function Evaluations) column indicates the computational cost of generating a single sample. The asterisk (*) next to some model names indicates that those models used ImageNet features, which may introduce bias. This table highlights the performance of the proposed R3GAN model (Ours-Config E) relative to other state-of-the-art models, emphasizing its efficiency and competitive FID.
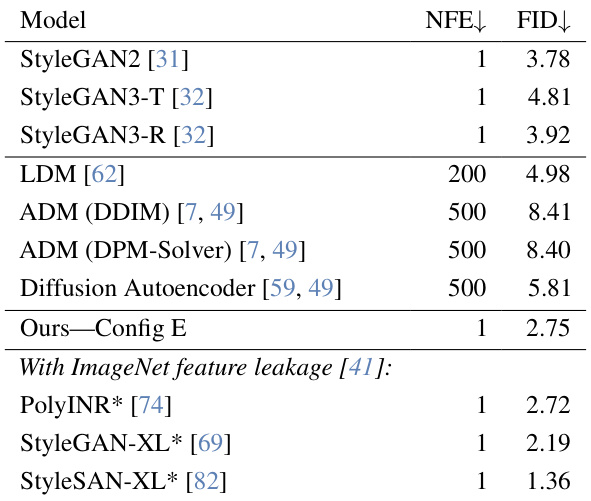
This table presents a comparison of different generative models on the FFHQ-64 dataset. The models are evaluated based on their FID (Fréchet Inception Distance) score and the number of forward passes (NFE) required to generate a sample. The table highlights the performance of the proposed R3GAN model (Ours—Config E) against state-of-the-art GANs and diffusion models. The asterisk (*) indicates models known to leak ImageNet features, meaning their performance may be artificially inflated due to leveraging pre-trained ImageNet knowledge.
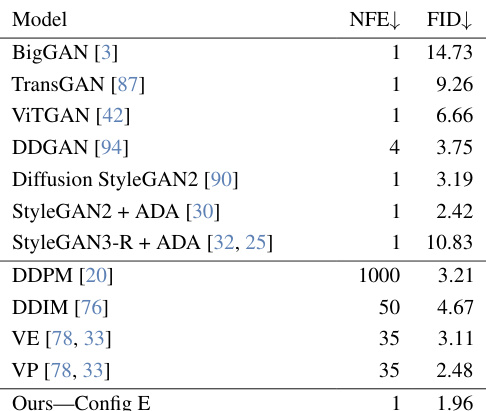
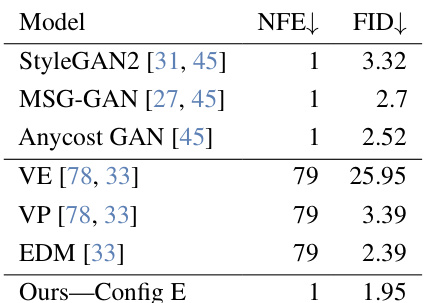
This table presents the Fréchet Inception Distance (FID) scores achieved by various GAN models and diffusion models on the CIFAR-10 dataset. The FID score is a measure of the quality of generated images, with lower scores indicating better image quality. The table also shows the number of function evaluations (NFEs) required for each model, which is a measure of the computational cost of generating images. The results show that R3GAN (Ours-Config E) achieves a very competitive FID score compared to other leading models, especially considering the significantly lower number of NFEs. This highlights its efficient and high-quality image generation capabilities.
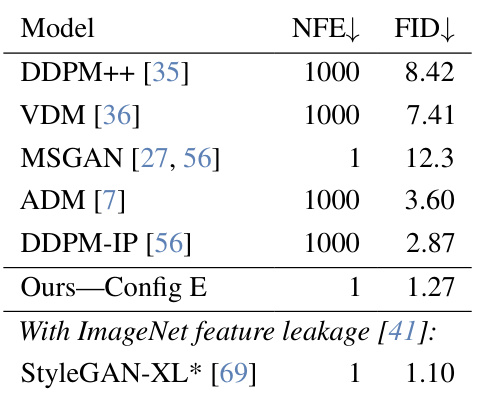
This table presents the Fréchet Inception Distance (FID) scores achieved by various generative models on the ImageNet-32 dataset. The models include both GANs (Generative Adversarial Networks) and diffusion models. The Number of Function Evaluations (NFE) required for sample generation is also listed. The results highlight the performance of the proposed R3GAN model (Ours—Config E) compared to other state-of-the-art models. Notably, it shows the superior performance of R3GAN, even when compared to models that leverage ImageNet feature leakage. This demonstrates the effectiveness of the proposed method in generating high-quality images without relying on external information or tricks.
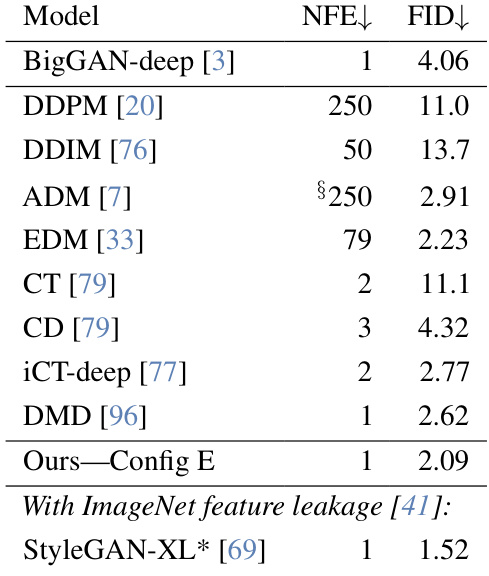
This table presents the Fréchet Inception Distance (FID) scores and number of function evaluations (NFEs) for various generative models on the ImageNet-64 dataset. The models compared include several state-of-the-art GANs and diffusion models. The FID score is a common metric for evaluating the quality of generated images, with lower scores indicating better image quality. The NFE (Number of Function Evaluations) represents the computational cost for generating a single sample. The table highlights the performance of the proposed R3GAN model (Ours-Config E) in comparison to other models. Notably, a subset of the compared models are indicated as having used ImageNet feature leakage, which may influence their FID scores.

This table presents a comparison of different configurations of the R3GAN model, showing their FID scores and model sizes. The configurations are progressive modifications of StyleGAN2, starting from a fully featured version and gradually removing tricks and modernizing the architecture. Each step in the modifications aims at demonstrating the impact of specific changes on the model’s performance. The table illustrates how a minimalist baseline (Config B) can be improved by various techniques, such as a well-behaved loss function (Config C), a modern architecture inspired by ResNet (Config D), and further refinements using ConvNeXt principles (Config E). The results showcase how simplification and modernization can lead to comparable or even better FID scores compared to StyleGAN2 with fewer parameters.
Full paper#