↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Unsupervised reinforcement learning (URL) struggles with environments containing distracting visual information, leading to biased exploration and poor performance. Existing URL methods often fail to distinguish between relevant and irrelevant information in the environment, hindering effective learning. This paper introduces Separation-assisted eXplorer (SeeX), a novel approach designed to overcome this limitation.
SeeX utilizes a bi-level optimization framework. The inner level trains a separated world model to identify and isolate task-relevant information, thereby reducing the impact of distracting visual elements. The outer level uses this model to train a policy by generating imaginary trajectories within the relevant state space, maximizing task-relevant uncertainty. Evaluations across multiple tasks reveal SeeX’s effectiveness in handling visual distractions and outperforming existing URL methods. This innovative approach of disentangling relevant from irrelevant information offers a significant improvement over current methods and could be pivotal in advancing the performance of URL in real-world scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in unsupervised reinforcement learning: robust exploration in visually cluttered environments. The proposed method, SeeX, offers a novel approach to handling distractions, which is highly relevant to the development of more robust and adaptable AI systems for real-world applications. SeeX’s success in multiple locomotion and manipulation tasks opens new avenues for research in separating task-relevant information, improving sample efficiency, and enhancing the generalization capabilities of RL agents.
Visual Insights#
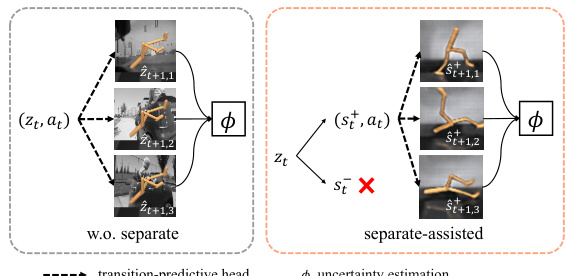
The figure compares traditional unsupervised reinforcement learning (URL) methods with a single world model to the proposed SeeX method with a separated world model. In the traditional approach (left), a single model encodes both task-relevant and task-irrelevant information in the latent space. This can lead to inflated uncertainty estimates due to irrelevant information. In SeeX (right), the world model distinctly separates task-relevant and task-irrelevant information. This allows for more accurate uncertainty estimation, which is crucial for effective exploration in visually distracted environments.
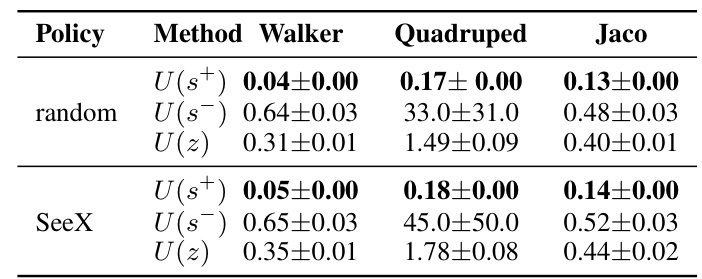
This table presents the uncertainty estimations for the SeeX and Plan2Explore models using two different policies (random and SeeX’s exploration policy) on the Driving-car dataset. It shows the mean and standard deviation of uncertainty for the endogenous state (s+), exogenous state (s-), and the combined latent state (z). The results highlight the difference in uncertainty estimation between SeeX and Plan2Explore, indicating SeeX’s superior accuracy.
In-depth insights#
Separated World Model#
The core idea behind a ‘Separated World Model’ in the context of reinforcement learning within visually cluttered environments is to disentangle relevant from irrelevant information present in the input. Instead of processing all visual data as a single, complex state, this approach proposes separate models for endogenous (task-relevant) and exogenous (distractor) components. This separation enables the agent to focus on task-critical cues, mitigating the negative effects of distracting visual elements on policy learning and exploration. A key benefit is improved uncertainty estimation, allowing the agent to accurately gauge its progress and focus exploration efforts. Effective separation allows for more efficient learning and improved generalization, leading to enhanced performance in visually complex environments without the computational burden of processing the irrelevant elements. The approach is particularly valuable when dealing with high-dimensional visual inputs where distractors significantly increase state space complexity. The ability to filter out distractors results in a more focused and sample-efficient learning process.
Bi-level Optimization#
Bi-level optimization, in the context of the research paper, is a powerful technique for tackling the challenges of unsupervised reinforcement learning in visually cluttered environments. The inner level focuses on refining a separated world model, disentangling task-relevant and irrelevant information to improve robustness against distractions. This is crucial because distractions often inflate uncertainty estimates, hindering effective learning. The outer level then leverages this refined model to optimize a policy, maximizing task-relevant uncertainty which drives efficient exploration. This bi-level approach elegantly addresses the problem of biased exploration caused by distractors by ensuring that the agent’s policy is guided by accurate uncertainty estimations, not those skewed by irrelevant visual noise. The framework is particularly effective because it decouples the learning process into two distinct stages, allowing for a more refined and efficient optimization of both the world model and the policy in complex scenarios. The separation of endogenous and exogenous information is key to success.
Distraction Robustness#
The concept of “Distraction Robustness” in the context of the provided research paper centers on the ability of an agent (likely a reinforcement learning agent) to successfully perform tasks despite the presence of irrelevant or misleading visual information in its environment. The core challenge is that distractors inflate uncertainty estimates, hindering the learning process and potentially leading to suboptimal behavior. The paper tackles this problem by introducing a novel architecture, a separated world model, that explicitly separates task-relevant from task-irrelevant information in the agent’s observations. This separation allows for a more focused learning process, improving robustness by minimizing uncertainty related to task-irrelevant features while maximizing uncertainty relevant to the task. The success of this approach hinges on the efficiency of disentangling task-relevant and irrelevant factors, demonstrating that simply ignoring distractors is insufficient for effective performance in complex visual environments. Evaluating distraction robustness involves comparing the agent’s performance on tasks with and without distractors, showcasing the impact of the separated world model in mitigating the negative effects of irrelevant visual stimuli. The core contribution lies in addressing the limitation of single world models which can’t effectively separate relevant and irrelevant information, thereby creating a more efficient and robust exploration strategy for complex visual environments.
Ablation Studies#
Ablation studies systematically remove or modify components of a model to assess their individual contributions. In this context, they would isolate the impact of different modules (e.g., the separated world model, the exogenous reconstruction module, and the number of predictive heads) and the policy design choices. The results would reveal the relative importance of each component to the overall performance. For instance, removing the separated world model might severely impair performance, suggesting its crucial role in disentangling task-relevant from irrelevant information. Conversely, a minimal impact from changing the number of predictive heads would indicate its lower contribution. By analyzing the interplay of these components, one can gain valuable insights into the model’s architecture and potentially improve its design by emphasizing key factors or eliminating redundant parts. Furthermore, analyzing the policy design choices (e.g., using only the endogenous state versus both endogenous and exogenous states) helps to understand how different choices affect the model’s generalization ability and the efficiency of exploration.
Future Work#
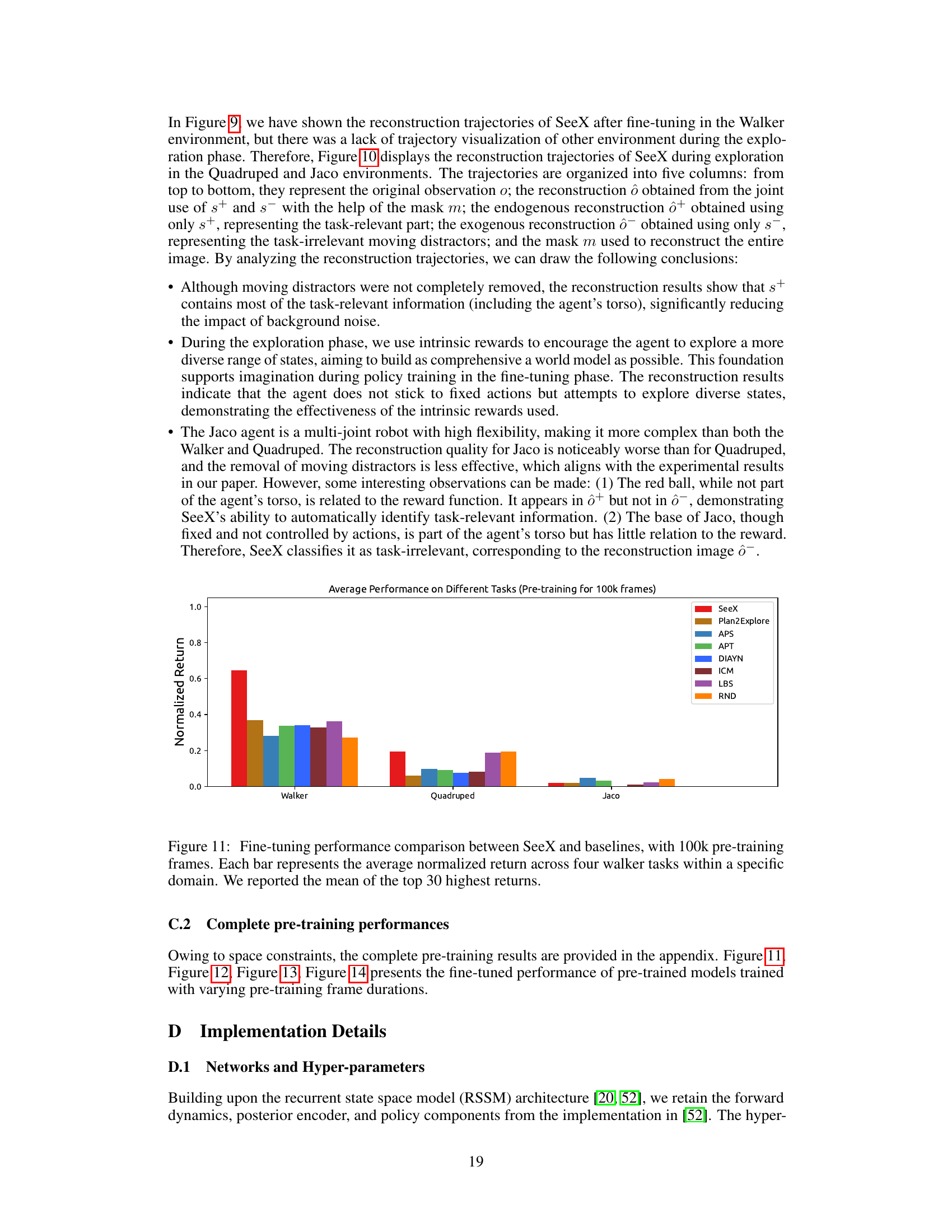
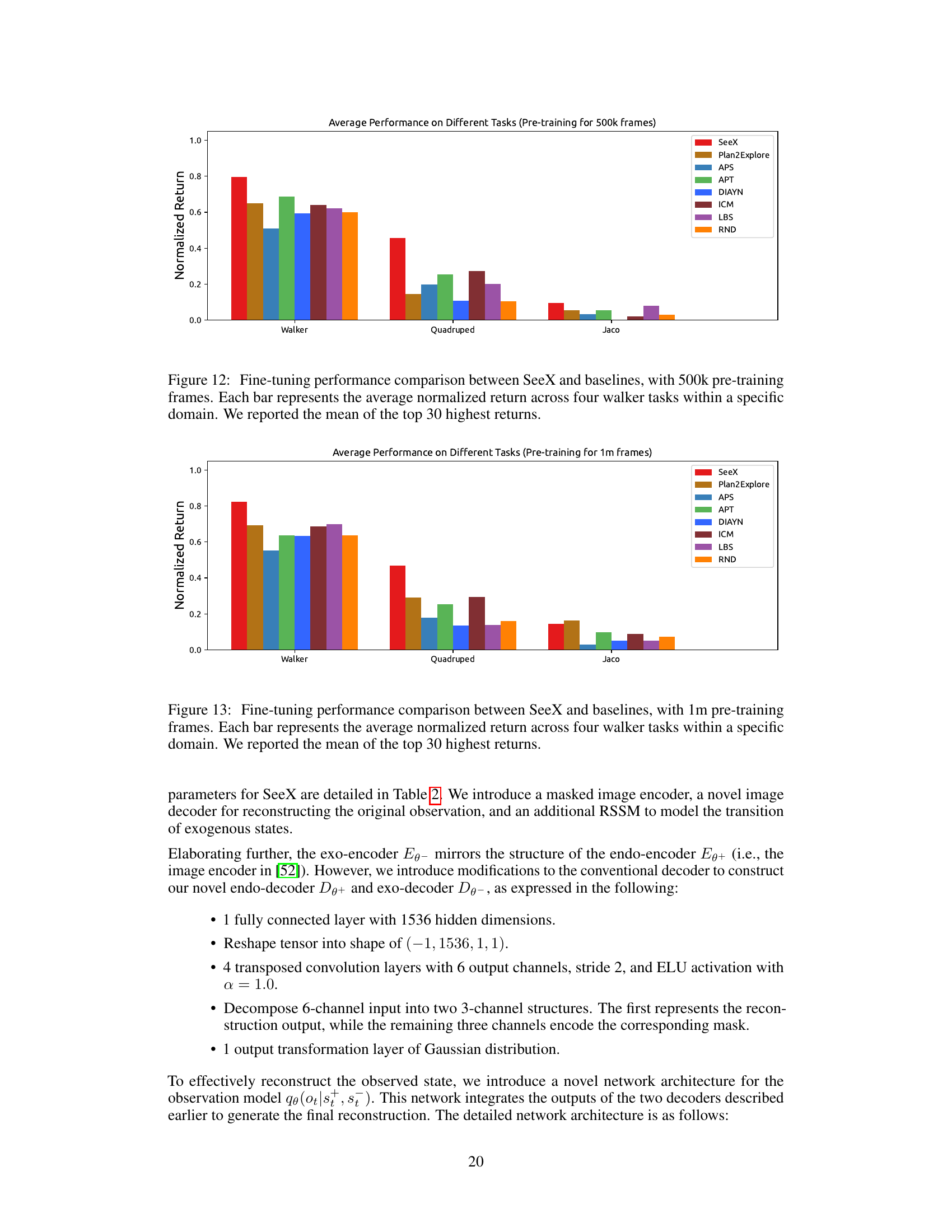
The authors outline several key areas for future investigation. Extending the research beyond the simulated environments (DMC-suite) used in the current study to real-world applications like self-driving and robotic navigation is crucial. This would involve addressing the complexities and challenges of real-world data and interactions. The current work focuses on a specific type of distractor, task-irrelevant and action-independent visual noise. Expanding the research to include other distractor types (task-relevant/action-dependent and task-irrelevant/action-dependent) is a necessary step to enhance the robustness and generalizability of the approach. Further theoretical and empirical analysis is also needed to better understand the effects of the number of predictive heads (K) used in the model and to investigate potential improvements in exploration strategies. Finally, the reliance on only endogenous states (s+) for policy learning is beneficial for the task studied but may be limited. Future research should explore incorporating exogenous information (s-) into policy optimization, particularly for scenarios involving multi-agent systems where interaction and collaboration are essential.
More visual insights#
More on figures

This figure shows the architecture of the proposed Separation-Assisted Explorer (SeeX) model. (a) illustrates the inner optimization process, where the world model is trained to separate task-relevant (endogenous) and task-irrelevant (exogenous) information. The model uses separate encoders and transition dynamics for each, with multiple predictive heads providing reward signals for uncertainty estimation. (b) shows the outer optimization process, which uses imaginary trajectories generated within the endogenous state space to train a policy that maximizes task-relevant uncertainty, improving sample efficiency by reducing reliance on real-world interactions.
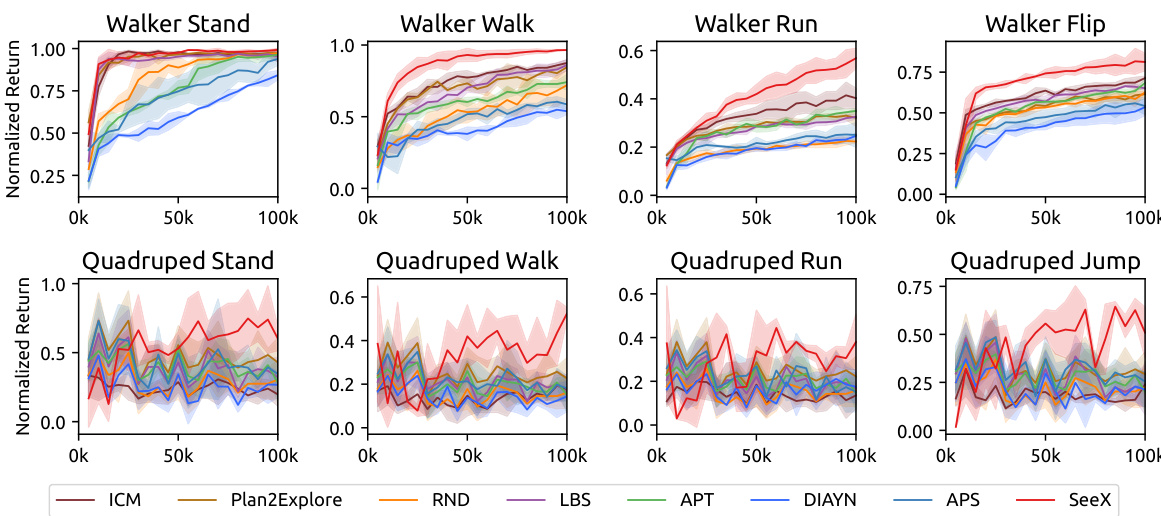
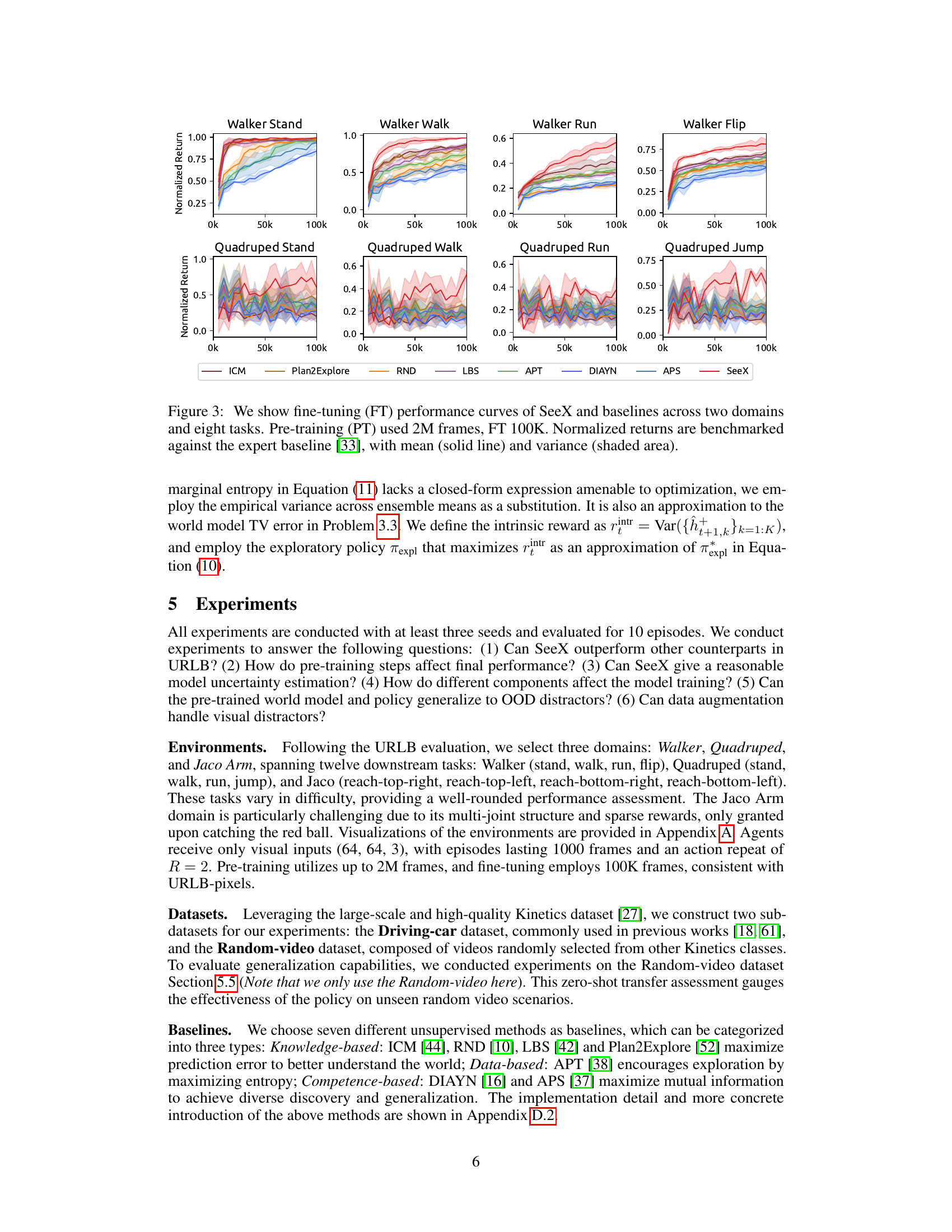
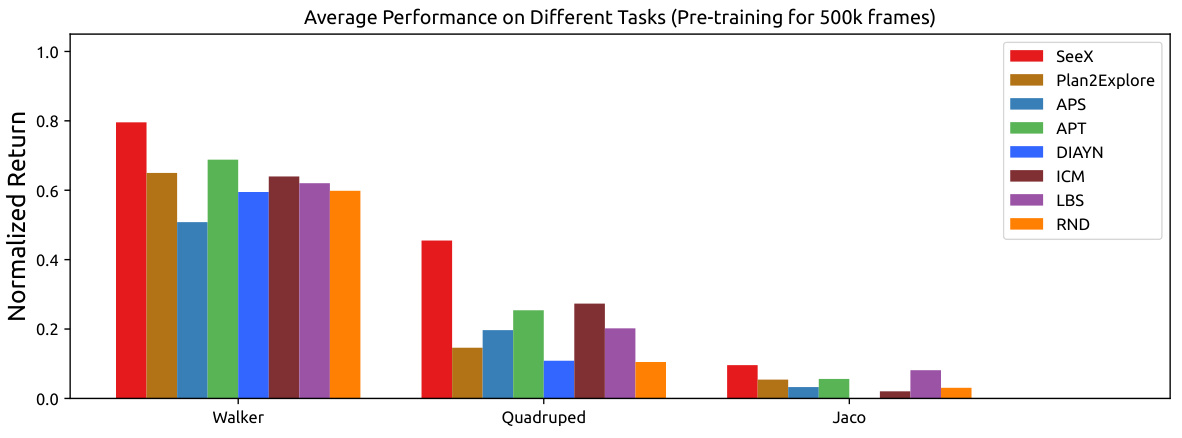
This figure displays the fine-tuning performance results for SeeX and several baseline methods across two domains (Walker and Quadruped) and eight different tasks. The pre-training phase utilized 2 million frames, while the fine-tuning phase used 100,000 frames. The normalized return for each method is plotted against the number of frames used in fine-tuning. Shaded areas represent the variance of the performance, and the solid lines show the mean. The results are benchmarked against an expert baseline, showing SeeX’s competitive performance across various tasks.
This figure displays the fine-tuning performance of SeeX and various baseline methods across two domains (Walker and Quadruped) and their respective eight tasks. The pre-training phase used 2 million frames, while the fine-tuning phase used 100,000 frames. The normalized return for each task is shown, benchmarked against an expert baseline. Solid lines represent the mean performance, while shaded areas indicate the variance.

This figure shows the ablation study on SeeX model. The (a) part shows the ablation study of different modules by removing either separated world model, exo-rec, or reducing the number of predictive heads. The (b) part shows ablation study of different policy design by comparing π(s+) and π(s+, s¯). The (c) part shows ablation study of α (weight of Exo-Rec term) and its impact on three different environments.

This figure shows example frames from the three simulated environments used in the paper: Walker, Quadruped, and Jaco. Each environment has driving-car distractors added in the background. The caption notes a key difference in how distractors were added to the Quadruped environment versus the Walker environment due to the floor being a significant part of the Quadruped’s observation space.

This figure shows examples of videos from the Driving-car dataset, the Random-video dataset, and also the DMC (DeepMind Control Suite) environments with those videos as distractors. The Driving-car dataset shows driving-related scenes. The Random-video dataset contains more general scenes. The DMC examples show simulated environments with these video distractors added as backgrounds. The figure highlights the difference in visual characteristics between these datasets, illustrating the visual diversity used in experiments to test model robustness to distraction.
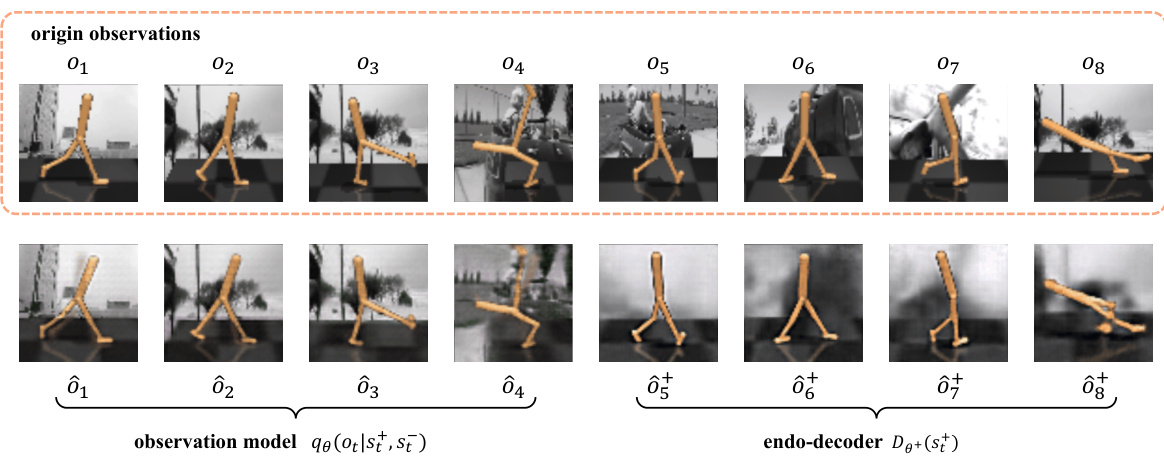
This figure visualizes the reconstruction results from the observation model and endo-decoder of the SeeX model. The top row displays the original observations, while the bottom row shows the reconstructions. Each pair of corresponding images (one original, one reconstructed) demonstrates the model’s ability to reconstruct the observations. This visualization helps to understand how well the model captures the relevant information from the observations, separating out task-relevant features from distracting information.

This figure visualizes the results of the separated world model in SeeX. It shows the original observation, the reconstruction using both endogenous and exogenous information, the reconstruction using only endogenous information, the reconstruction using only exogenous information, and the mask used in the reconstruction process. The purpose is to demonstrate SeeX’s ability to separate task-relevant (endogenous) and task-irrelevant (exogenous) information from the observations, allowing it to make decisions without being influenced by irrelevant factors. The left-hand side shows results from the Walker environment while the right-hand side shows results from the driving-car environment.

This figure compares the fine-tuning performance of SeeX and several baseline algorithms across various locomotion and manipulation tasks. The results are shown as curves illustrating the normalized return (performance) over the fine-tuning phase (100,000 frames), following a pre-training phase of 2 million frames. Shaded areas represent the variance, providing a measure of uncertainty in the results. The performance of each algorithm is benchmarked against an expert baseline.
This figure presents the fine-tuning performance results of SeeX and several baseline methods across two domains (Walker and Quadruped) and eight tasks. The pre-training phase used 2 million frames, and the fine-tuning phase used 100,000 frames. The performance is normalized and shown relative to an expert baseline. The solid lines represent the mean performance, while the shaded areas represent the variance across multiple trials.
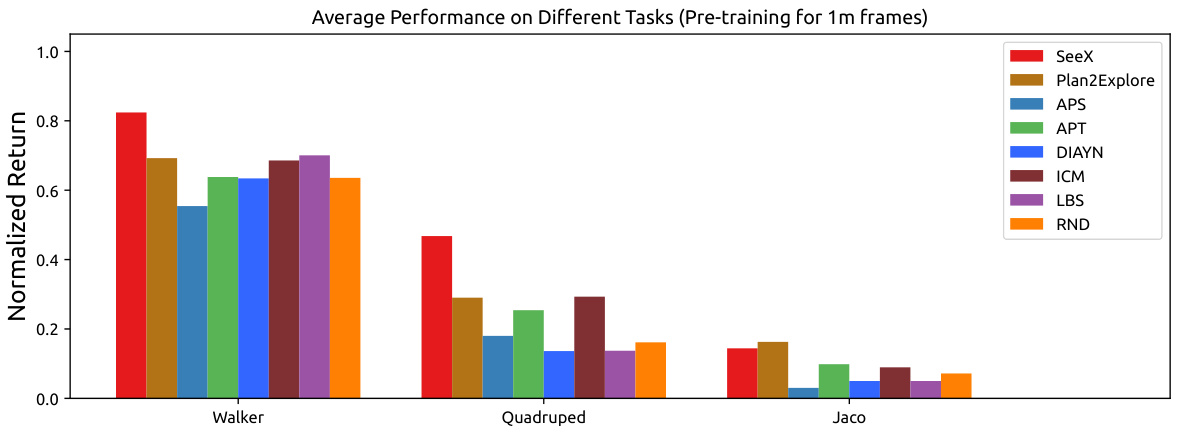
This figure compares the fine-tuning performance of SeeX against several baseline methods across eight different tasks in two domains (walker and quadruped). The x-axis represents the number of frames used in the fine-tuning phase (100,000 frames), and the y-axis shows the normalized return, which is a measure of performance relative to an expert agent. The solid line indicates the average performance, and the shaded area represents the variance across multiple runs. The pre-training phase used 2 million frames for all methods.

This figure displays the fine-tuning performance curves for SeeX and seven baseline methods across two domains (Walker and Quadruped) and eight tasks. The pre-training phase used 2 million frames, while the fine-tuning phase used 100,000 frames. The normalized returns are benchmarked against an expert baseline, showing SeeX’s superior performance and lower variance, indicating higher consistency across multiple trials.
More on tables
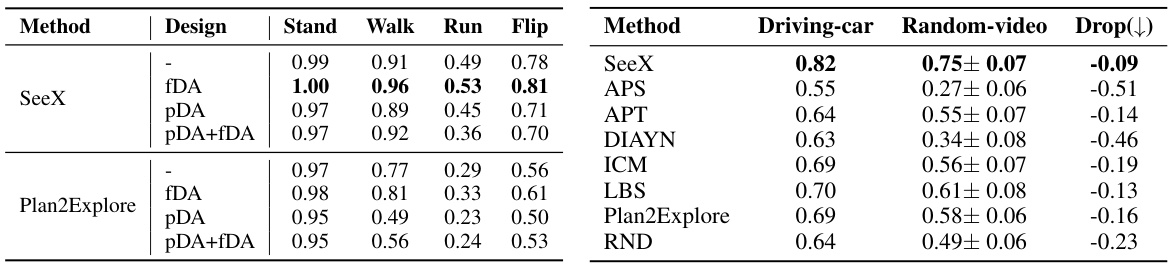
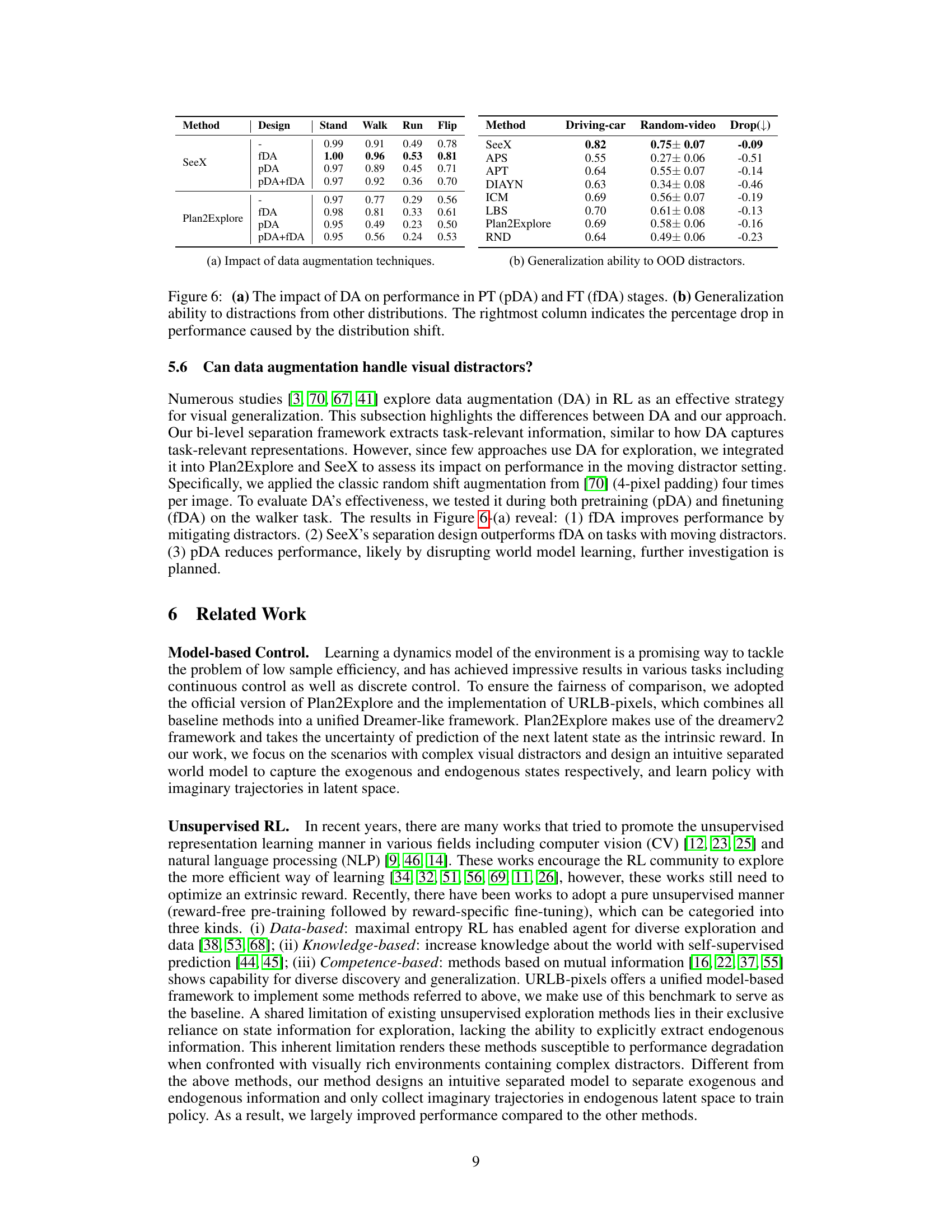
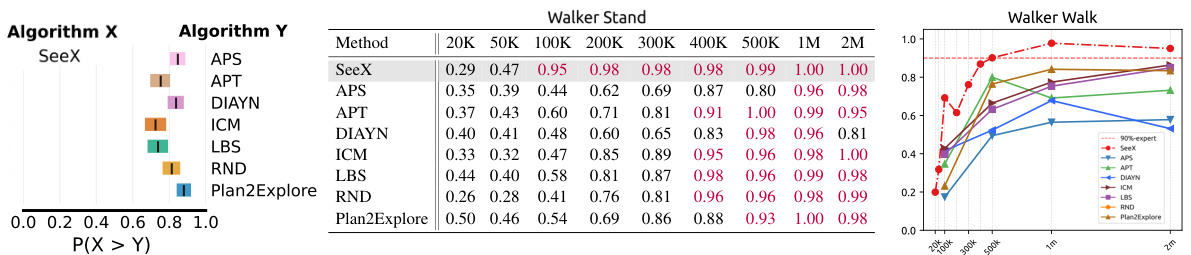
This table shows the results of experiments evaluating the impact of data augmentation (DA) on the performance of different methods in both pre-training (PT) and fine-tuning (FT) stages. It also presents a comparison of the generalization ability of SeeX and several baseline methods when tested on out-of-distribution (OOD) distractors. The left half of the table shows the performance of SeeX and Plan2Explore with different DA strategies (pDA, fDA, pDA+fDA, and no DA) across four Walker tasks. The right half shows a comparison of generalization ability between SeeX and other methods by comparing performance on Driving-car and Random-video datasets, highlighting the percentage drop in performance due to the distribution shift.
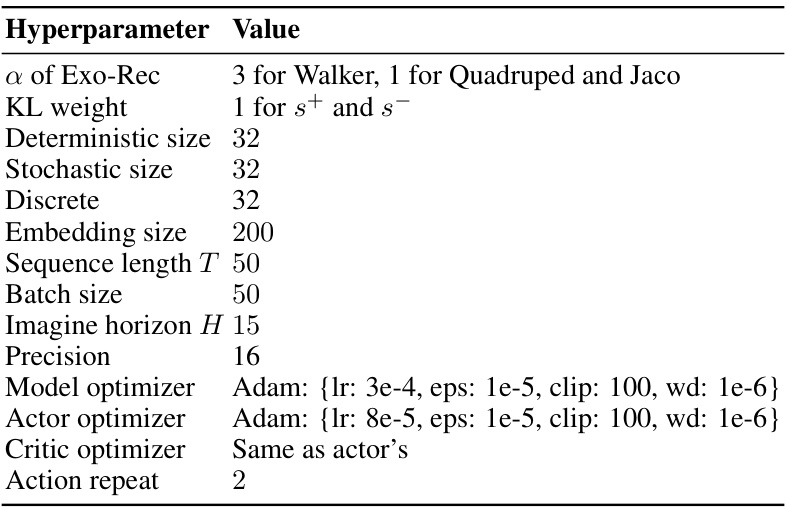
This table presents the uncertainty estimation results for SeeX and Plan2Explore on the Driving-car dataset. Two different policies (a random policy and SeeX’s exploration policy) were used to collect 1000 distinct states. The table shows the mean and standard deviation of uncertainty estimations for the endogenous states (U(s+)), exogenous states (U(s-)), and latent belief states (U(z)). The results highlight the difference in uncertainty estimation between the two models.
Full paper#