↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating realistic images from limited viewpoints is challenging. Existing methods often use Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS), but NeRF methods are computationally expensive and 3DGS struggles with sparse data, sometimes needing additional supervision like depth information from pre-trained models which can be noisy and inaccurate. This creates a need for more robust and efficient novel view synthesis techniques, especially when dealing with limited input views.
This paper introduces a novel method that leverages the inherent self-supervision in binocular vision to improve 3DGS, avoiding reliance on external data. The method uses binocular stereo consistency to constrain the depth estimations, improving scene geometry. An additional opacity decay strategy effectively reduces redundant Gaussians, enhancing efficiency and quality. The use of dense point cloud initialization further improves the initial geometry estimation. Experiments on various datasets show significant improvements compared to existing state-of-the-art techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient approach to novel view synthesis from sparse views, a crucial problem in 3D computer vision. Its self-supervised approach avoids reliance on noisy external priors, significantly improving accuracy and efficiency. The method’s potential applications in areas like augmented reality, autonomous navigation, and 3D modeling are significant, thus opening new avenues for research in view synthesis from limited data.
Visual Insights#
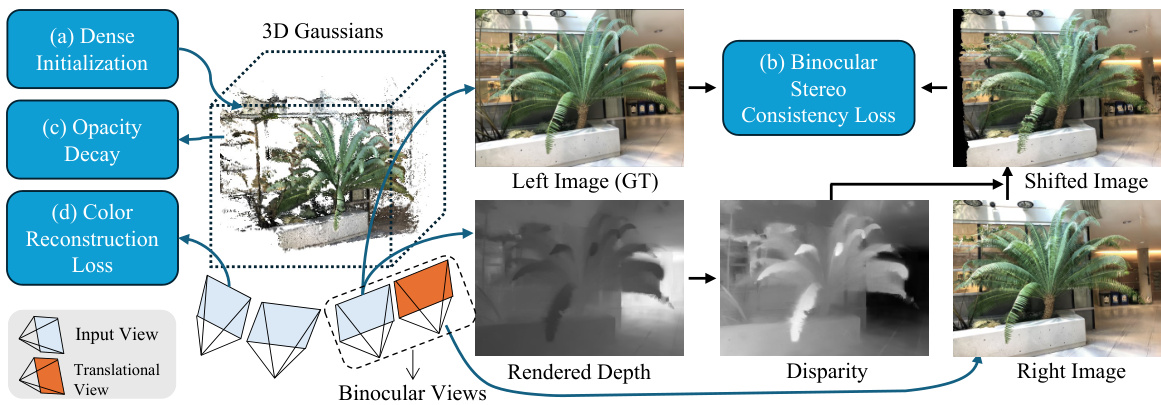
This figure illustrates the proposed method’s pipeline. It shows how dense initialization is used for Gaussian locations, and then these locations and attributes are optimized using three constraints: binocular stereo consistency loss (creating binocular pairs by translating input views), opacity decay strategy (regularizing Gaussians by decaying opacity during training), and color reconstruction loss.
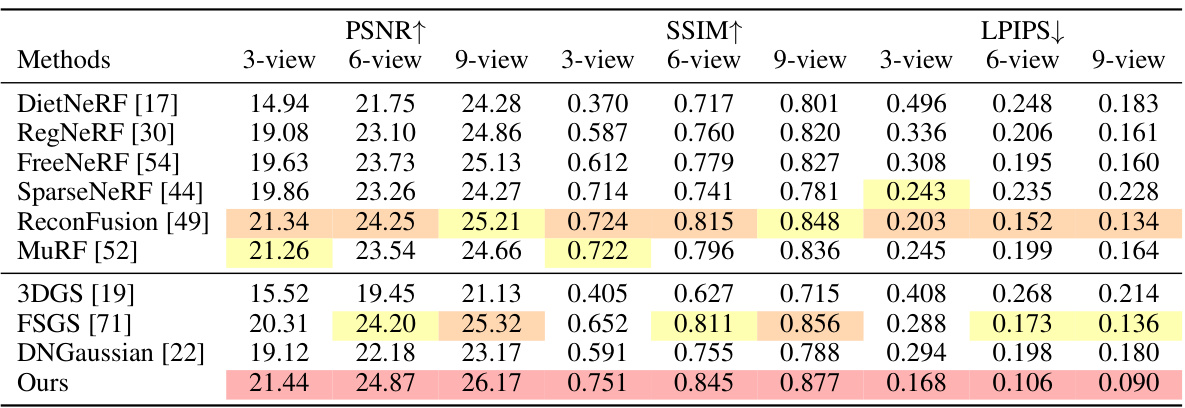
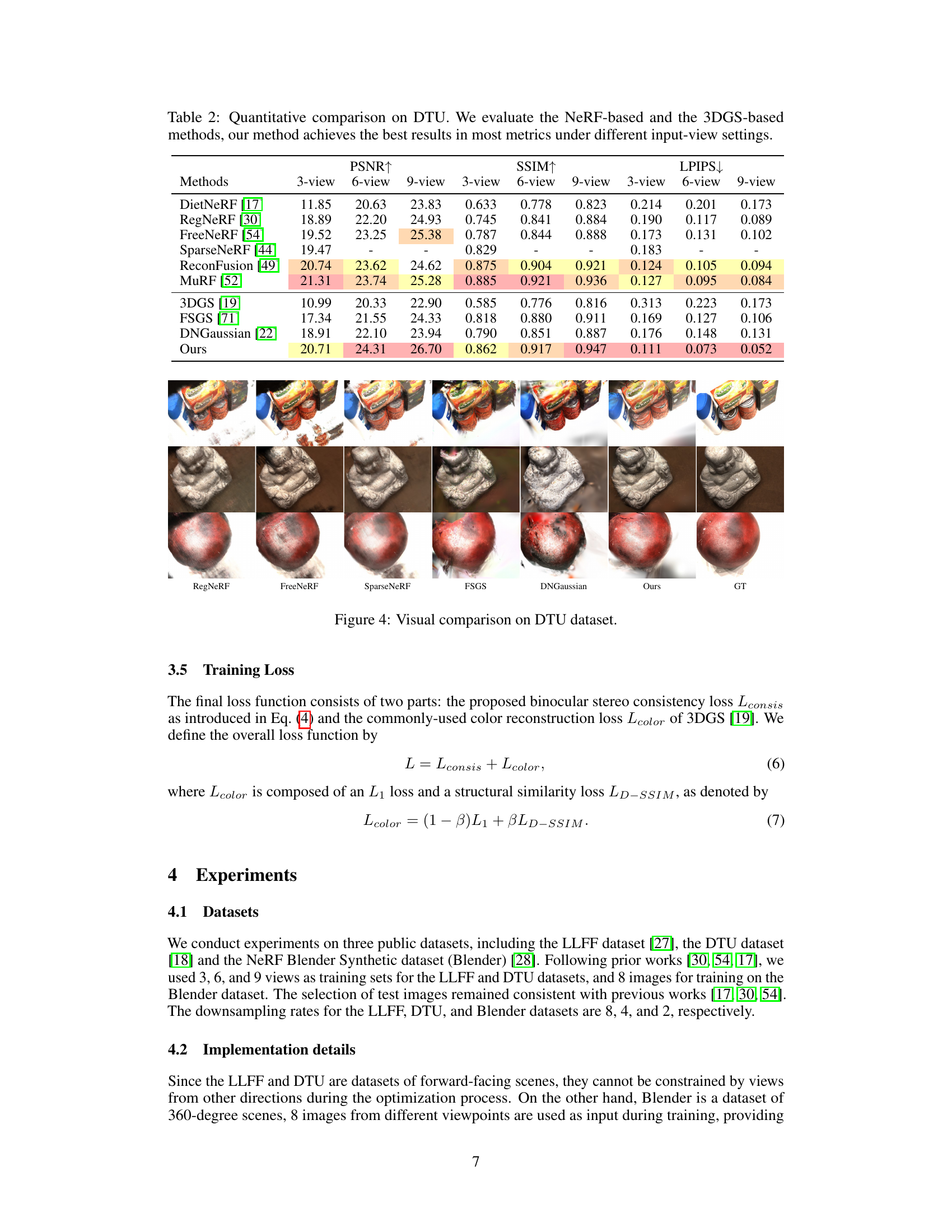
This table presents a quantitative comparison of the proposed method against several state-of-the-art NeRF-based and 3DGS-based methods on the LLFF dataset. The comparison is done across three different input view settings (3, 6, and 9 views) and evaluates performance using three metrics: PSNR, SSIM, and LPIPS. The results show that the proposed method outperforms all other methods across all metrics and view settings.
In-depth insights#
Binocular Stereo Fusion#
Binocular stereo fusion, in the context of 3D scene reconstruction, leverages the inherent consistency between a pair of binocular images to improve the accuracy and robustness of depth estimation. The core idea is to exploit the disparity between the left and right images to infer depth information. This technique offers several advantages over using a single image or other depth cues. By comparing corresponding pixels across the two images, binocular fusion can effectively resolve ambiguities and reduce noise present in individual views. This approach helps to generate more accurate and reliable depth maps, especially in challenging scenarios with low texture or occlusions. The disparity-based depth estimation, however, has limitations. Accurate results depend heavily on proper image registration and calibration. Errors in camera calibration or mismatches between corresponding points can lead to significant inaccuracies in the computed depth. In addition, areas with repetitive patterns or lack of distinct features might challenge the disparity calculation leading to less reliable depth estimates. Despite these challenges, binocular stereo fusion remains a powerful technique, especially when combined with other cues like neural networks or self-supervision strategies. This technique proves particularly useful for sparse view synthesis where a limited number of input views restricts the reliability of other methods. The output of this fusion method generally serves as input for algorithms which generate 3D representations of a scene such as 3D Gaussian Splatting.
Opacity Decay Regularization#
Opacity decay regularization, a technique employed to enhance the efficiency and robustness of 3D Gaussian splatting for novel view synthesis, focuses on mitigating the overfitting and redundancy issues that arise when dealing with sparse input views. The core idea is to progressively reduce the opacity of Gaussians during the training process. This approach intelligently penalizes Gaussians with low opacity gradients, effectively pruning redundant or poorly positioned Gaussians near the surface while retaining those with higher gradients, crucial for accurate scene representation. By enforcing such regularization, the method refines the Gaussian geometry, leading to improved rendering quality and reduced computational costs. Furthermore, the opacity decay strategy acts as a regularizer, enhancing the stability of the overall optimization process and improving the method’s ability to generate high-quality novel views even from limited input data. This intelligent pruning mechanism promotes cleaner, more efficient radiance field reconstruction, resulting in significant gains in both visual quality and rendering speed.
Sparse 3DGS Enhancement#
Enhancing sparse 3D Gaussian Splatting (3DGS) focuses on addressing the limitations of 3DGS when dealing with limited input views. Standard 3DGS can struggle with sparse data, leading to overfitting and inaccurate scene geometry. Effective strategies involve incorporating additional constraints or prior information to guide the learning process. This might include using depth cues from binocular stereo vision, which leverages the consistency between pairs of images to infer depth and improve 3D Gaussian placement. Alternatively, regularization techniques such as applying an opacity decay constraint can filter out redundant or poorly positioned Gaussians, leading to a more efficient and accurate representation. Dense initialization, starting with a high-quality point cloud instead of a sparse one, further enhances robustness and speed. The success of these enhancement methods hinges on balancing the need for accurate scene representation with computational efficiency. The goal is to achieve high-fidelity novel view synthesis from minimal input views by improving the robustness and efficiency of 3D Gaussian inference in challenging, data-sparse scenarios.
Self-Supervised Learning#
Self-supervised learning is a powerful paradigm that leverages intrinsic data properties to train models without explicit human annotations. In the context of 3D scene reconstruction, self-supervision offers a compelling solution for sparse view synthesis, addressing the limitations of traditional methods reliant on dense data. This approach excels by exploiting the inherent redundancy and consistency within a set of sparse views, such as binocular stereo constraints which offer a readily available source of self-supervision. The core principle is to create and enforce consistency between different views or projections of the same scene, enabling the model to learn richer scene representations and improve prediction accuracy. However, the success of self-supervised learning depends critically on the design of suitable pretext tasks and loss functions that effectively capture the relevant underlying structure within the data. Careful consideration of potential limitations such as the inherent noise and ambiguity in image data and the choice of suitable regularization strategies is crucial for achieving optimal results. The challenge lies in crafting sophisticated self-supervision methods capable of robustly learning detailed scene geometry and appearance from limited information. This contrasts sharply with supervised techniques that rely on copious labelled data, thereby reducing reliance on resource-intensive human-in-the-loop annotation processes.
View Consistency Limits#
The concept of ‘View Consistency Limits’ in novel view synthesis using methods like Gaussian Splatting highlights the inherent challenges in enforcing consistent scene geometry across different viewpoints, especially from sparse input views. Limitations arise from the noisy and incomplete nature of depth information derived from sparse data, making it difficult to accurately warp images between viewpoints. Occlusion and depth discontinuities further complicate view consistency, as the rendered views may not accurately reflect occluded regions or abrupt changes in scene depth. Self-supervision techniques, while promising, are not perfect substitutes for ground-truth depth data and are susceptible to error propagation. Therefore, research in this area should focus on robust methods for depth estimation from sparse views, advanced strategies for handling occlusion, and developing more accurate warping algorithms to minimize inconsistencies. Ultimately, understanding the limitations of view consistency is crucial for evaluating the overall quality and reliability of novel view synthesis techniques.
More visual insights#
More on figures
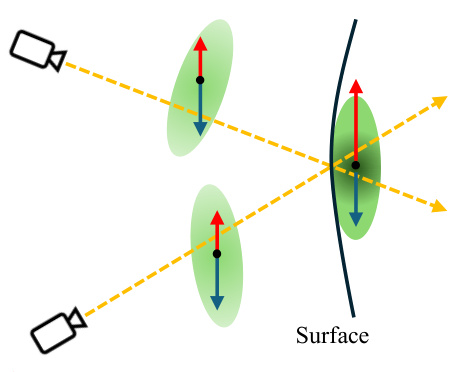
This figure illustrates how the opacity decay strategy works. Initially, all Gaussians have similar opacity. As the training progresses, Gaussians closer to the surface have higher opacity gradients, causing their opacity to increase. However, Gaussians further from the surface have lower opacity gradients, leading to their opacity decreasing and eventually being pruned. This helps to filter out redundant Gaussians and refine the 3D Gaussian representation of the scene.

This figure shows a visual comparison of novel view synthesis and depth rendering results on the LLFF dataset for different methods including RegNeRF, FreeNeRF, SparseNeRF, FSGS, DNGaussian, and the proposed method. The top row displays the rendered images, while the bottom row shows the corresponding depth maps. It highlights the superior quality and accuracy of the proposed method in both image generation and depth estimation compared to existing state-of-the-art techniques.

This figure compares the visual results of novel view synthesis from several state-of-the-art methods on the LLFF dataset. Each row shows a different scene, with various methods presented side-by-side and compared to the ground truth (GT). The goal is to demonstrate the improved rendering quality and fidelity achieved by the proposed ‘Ours’ method compared to existing techniques. This visualization highlights the differences in rendering accuracy, especially in terms of detail preservation, noise reduction, and overall visual realism.
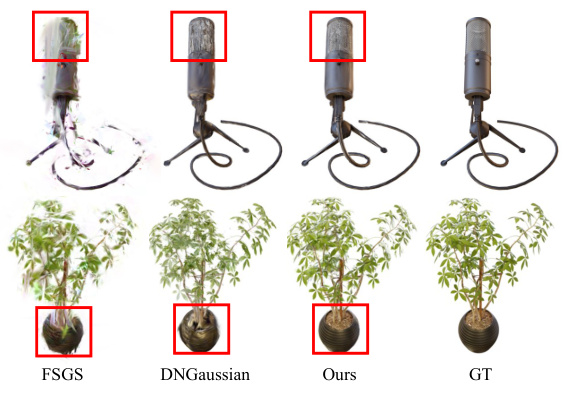
This figure presents a visual comparison of novel view synthesis results on the Blender dataset for four different methods: FSGS, DNGaussian, the proposed method, and the ground truth. The top row shows results for a microphone scene, while the bottom row focuses on a potted plant scene. Red boxes highlight areas where differences between the methods are most apparent. The comparison demonstrates the superior quality and detail preservation achieved by the proposed method compared to the baselines.

This figure compares depth maps generated with and without the view consistency loss. The left two images show depth maps from the ‘orchids’ scene of the LLFF dataset, while the right two images show depth maps from the ’leaves’ scene. In both cases, the images on the right (using view consistency loss) show a significantly improved alignment of the depth values with the actual surfaces of the objects, resulting in a much more accurate representation of the scene’s 3D structure.

This figure shows a comparison of novel view images and Gaussian point clouds generated using different methods. Specifically, it highlights the impact of different initialization strategies (sparse vs. dense), and the use of an opacity decay strategy on the quality of the resulting novel views and the distribution of Gaussian points in the 3D scene. The top row displays the rendered images, while the bottom row shows the distributions of Gaussian points. The red boxes highlight regions of particular interest to illustrate the differences between the methods and the ground truth (GT).

This figure compares the visual results of novel view synthesis and depth rendering for several scenes in the LLFF dataset using different methods: RegNeRF, FreeNeRF, SparseNeRF, FSGS, DNGaussian, and the proposed method. The results highlight the superior quality and depth accuracy of the proposed method compared to the baselines, especially in areas with fine details and complex geometries. The ground truth (GT) images are also provided for comparison.

This figure shows a visual comparison of novel view synthesis results on the LLFF dataset using 3 input views. It compares the results of the proposed method against the DNGaussian method and the ground truth. Each row represents a different scene from the dataset, showcasing the quality of novel view generation for each approach. The differences highlight the improved accuracy and detail preservation in the proposed method compared to the baseline.

This figure shows a visual comparison of novel view images and Gaussian point clouds generated using different initialization methods. The top row shows the results of using sparse initialization, where the Gaussian point clouds are not well-distributed and artifacts are present in the novel views. The middle row shows the results of using opacity decay. The artifacts and noisy points are reduced, resulting in better quality novel views. The bottom row shows the ground truth.

This figure shows a qualitative comparison of novel view synthesis results on the LLFF dataset. The results from different methods (RegNeRF, FreeNeRF, SparseNeRF, FSGS, DNGaussian, and the proposed method) are compared to the ground truth. The images demonstrate the ability of each method to generate realistic novel views from sparse inputs, highlighting the differences in rendering quality and the level of detail preserved.

This figure shows a comparison of warped images and corresponding error maps when different source views are used for the binocular stereo consistency loss. The columns represent different source view types: shifted camera position, unseen view, and an adjacent training view. The rows display the reference image, warped image, and error map. The experiment highlights how using a source view that is too far from the reference view or has a significant rotation, can significantly increase the error due to depth estimation inaccuracies and occlusions.
More on tables
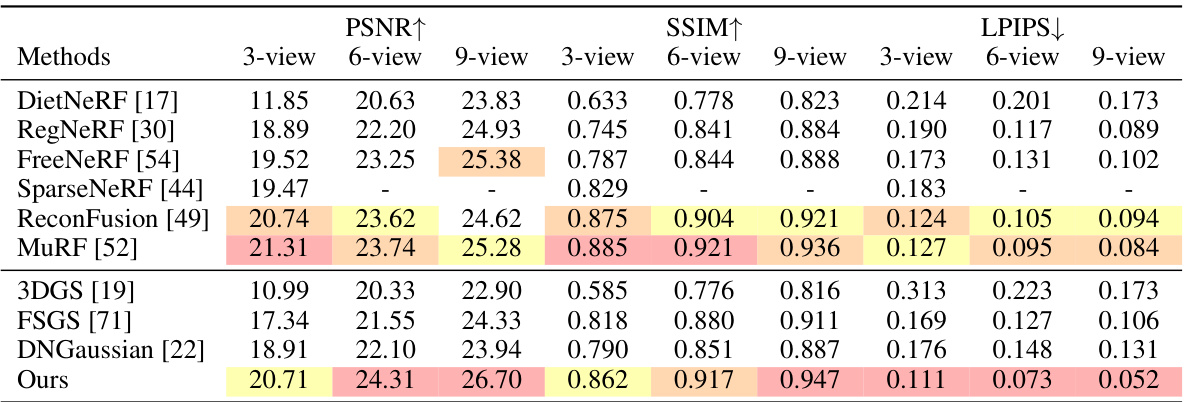
This table presents a quantitative comparison of different novel view synthesis methods on the DTU dataset. The methods are categorized as NeRF-based and 3DGS-based. The table shows the performance of each method across various metrics (PSNR, SSIM, LPIPS) and different numbers of input views (3, 6, 9). The results demonstrate that the proposed method outperforms existing methods.
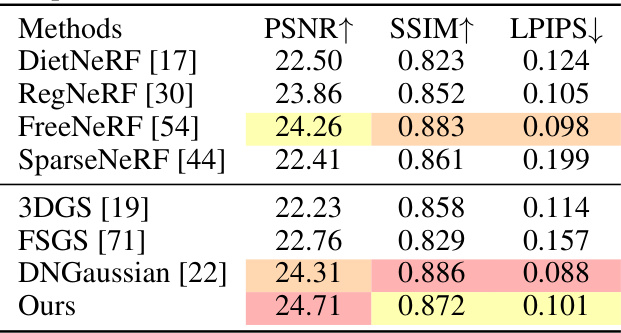
This table presents a quantitative comparison of different novel view synthesis methods on the Blender dataset using 8 input views. The metrics used for comparison are PSNR, SSIM, and LPIPS. The table shows that the proposed method achieves comparable performance to state-of-the-art methods.
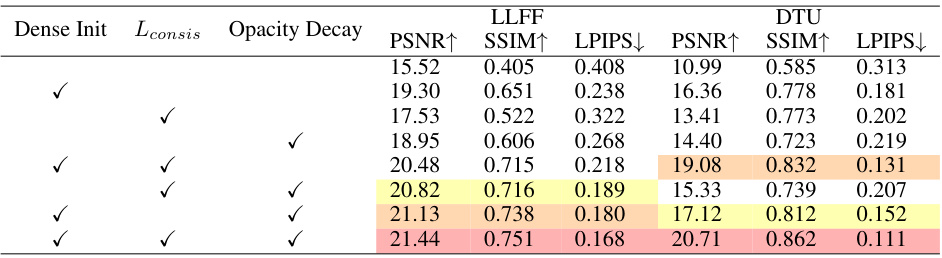
This table presents the results of ablation studies conducted on the LLFF and DTU datasets using 3 input views. It shows the impact of three key components of the proposed method: dense initialization, binocular stereo consistency loss (Lconsis), and opacity decay strategy. Each row represents a different combination of these components, with a checkmark (✓) indicating inclusion and a blank indicating exclusion. The table reports the PSNR, SSIM, and LPIPS metrics for both the LLFF and DTU datasets for each configuration, allowing for a quantitative assessment of the contribution of each component.
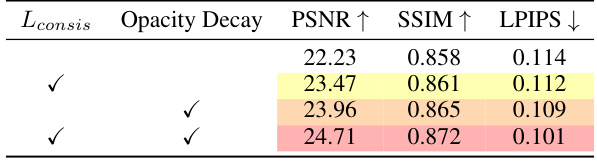
This table presents the ablation study results on the Blender dataset using 3 input views. It shows the impact of different components of the proposed method on the performance, measured by PSNR, SSIM, and LPIPS. The components evaluated are the binocular stereo consistency loss (Lconsis) and the opacity decay strategy. The results demonstrate that both components contribute positively to the performance, with the combination achieving the best results.

This table presents a quantitative comparison of the performance of two different opacity regularization methods: Opacity Entropy Regularization and Opacity Decay. The metrics used for comparison are PSNR, SSIM, and LPIPS, which are common image quality assessment metrics. The results show that Opacity Decay significantly outperforms Opacity Entropy Regularization across all three metrics.
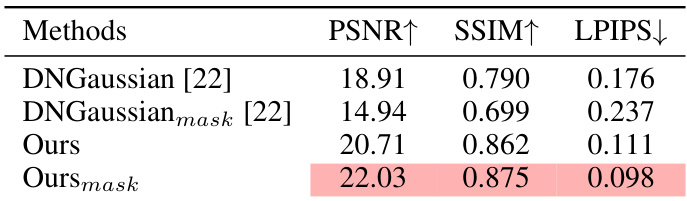
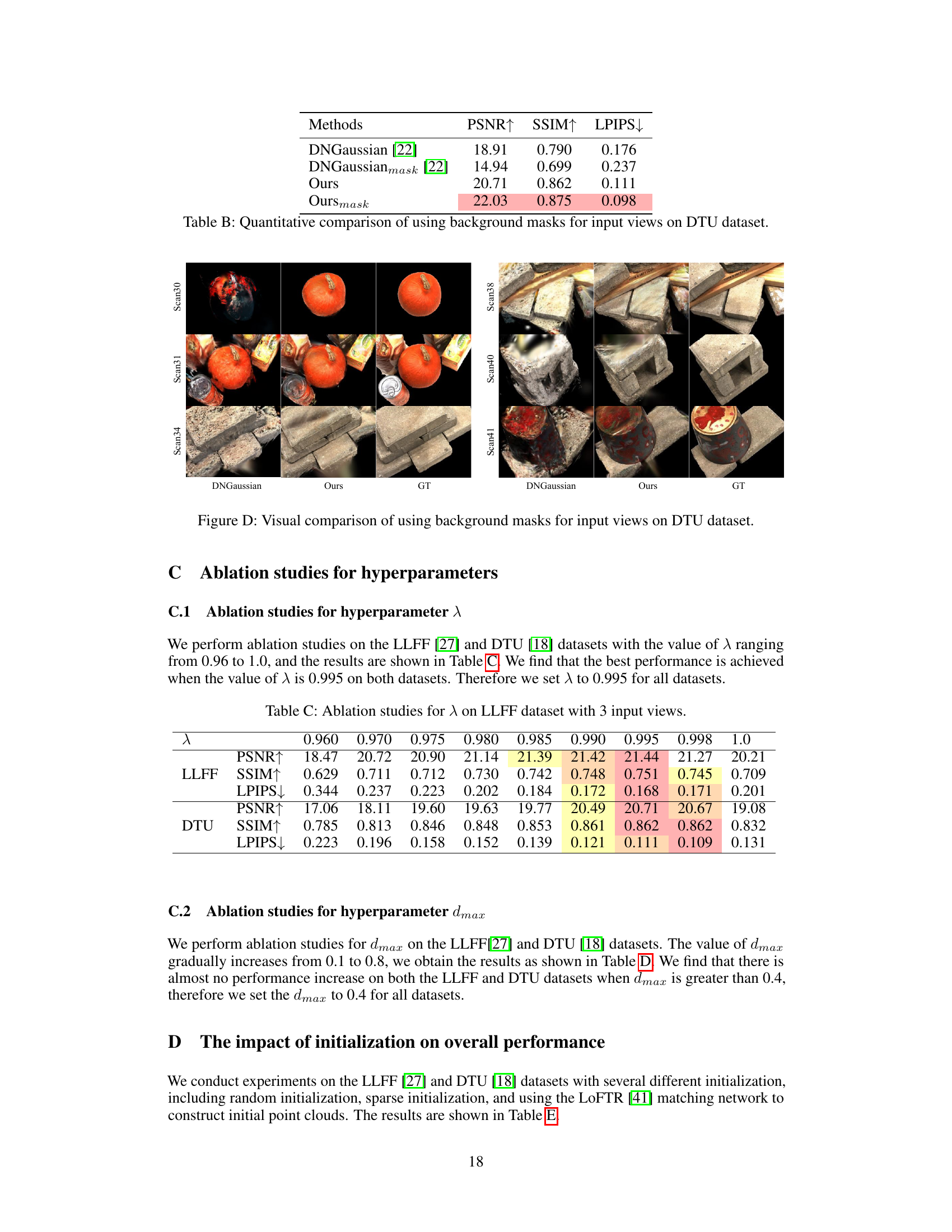
This table presents a quantitative comparison of different methods for novel view synthesis on the DTU dataset, specifically focusing on the impact of using background masks for input views. It compares the performance of DNGaussian with and without masks, and the proposed method (Ours) with and without masks, in terms of PSNR, SSIM, and LPIPS. The results show that using masks significantly improves the performance of the proposed method.
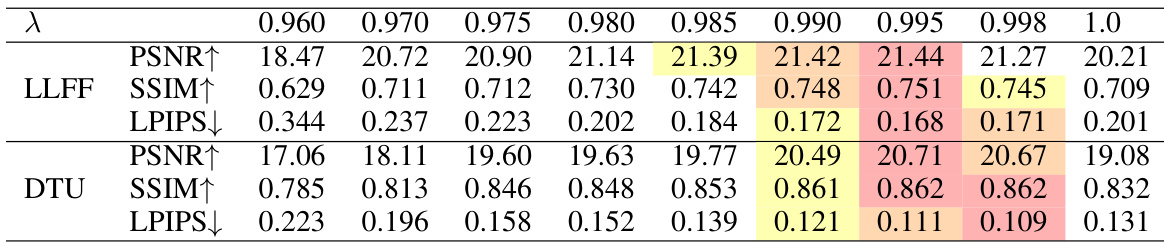
This table presents the ablation study results, showing the impact of each component of the proposed method on the LLFF and DTU datasets. The components evaluated are dense initialization, binocular stereo consistency loss, and opacity decay. Each row represents a different combination of these components, with a checkmark indicating its inclusion and a blank indicating its exclusion. The table shows the resulting PSNR, SSIM, and LPIPS scores for each configuration. This allows for a quantitative assessment of the contribution of each proposed component.
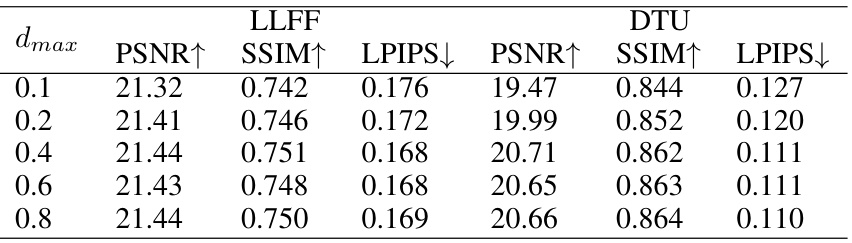
This table presents the ablation study results on the impact of the hyperparameter dmax (the maximum distance of camera shift) on the performance of the proposed method. The results are shown for the LLFF and DTU datasets, each with 3 input views. The PSNR, SSIM, and LPIPS metrics are reported for different values of dmax, allowing for an analysis of how this parameter affects the quality of novel view synthesis.

This table presents a comparison of the performance of the proposed method using different initialization strategies for the 3D Gaussian splatting. It compares using random initialization, a sparse initialization from SfM, and dense initializations created using LoFTR and PDCNet+. The results are broken down by PSNR, SSIM, and LPIPS metrics for both the LLFF and DTU datasets. The table highlights the significant impact of the chosen initialization method on the final performance of novel view synthesis.

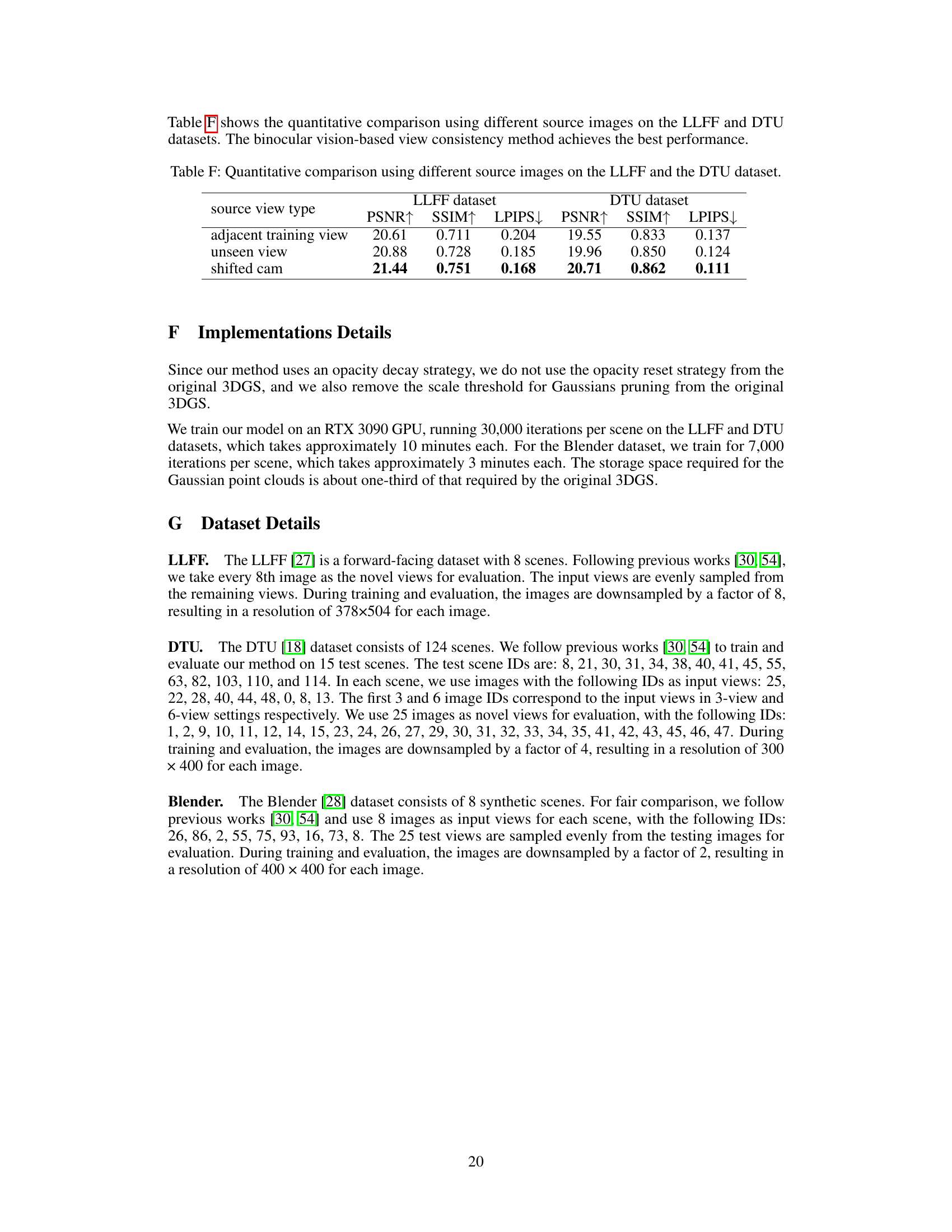
This table compares the performance of the proposed method using different source images for binocular stereo consistency. It shows PSNR, SSIM, and LPIPS scores for the LLFF and DTU datasets, broken down by whether the source view was an adjacent training view, an unseen view, or a view generated by shifting the camera. The ‘shifted cam’ approach represents the proposed method’s self-supervised approach.
Full paper#