↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Concept-based learning, while promising, lacks a clear understanding of how concept sets impact model performance. Existing concept-bottleneck models (CBMs) suffer from issues like suboptimal concept selection, leading to poor sample efficiency and generalization, especially under data scarcity or distribution shifts. This research directly addresses these critical gaps.
The researchers propose a theoretical framework that defines key concept properties—expressiveness and model-aware inductive bias—linking them to CBM performance. They demonstrate that well-chosen concept sets significantly improve model performance in low-data regimes and under distribution shifts. A novel method for identifying informative and non-redundant concepts is introduced and validated empirically, showcasing the superiority of the designed CBMs over traditional embedding counterparts, particularly in challenging scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with concept-based models. It offers a novel theoretical framework and empirical validation, addressing the critical gap in understanding how concept sets affect model performance. The findings significantly improve model design and pave the way for more robust and efficient concept-based applications, impacting interpretability and generalization, especially in low-data regimes and out-of-distribution settings. This enhances the practical utility of concept bottleneck models across various domains.
Visual Insights#
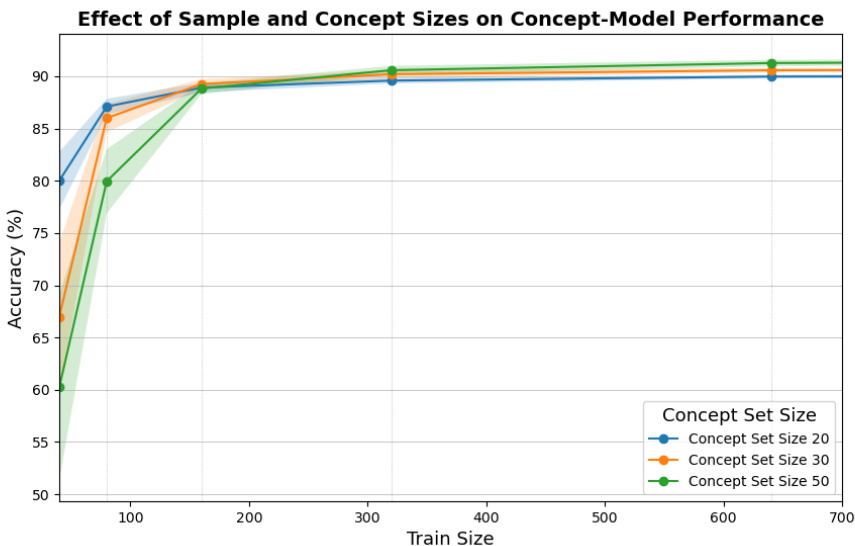
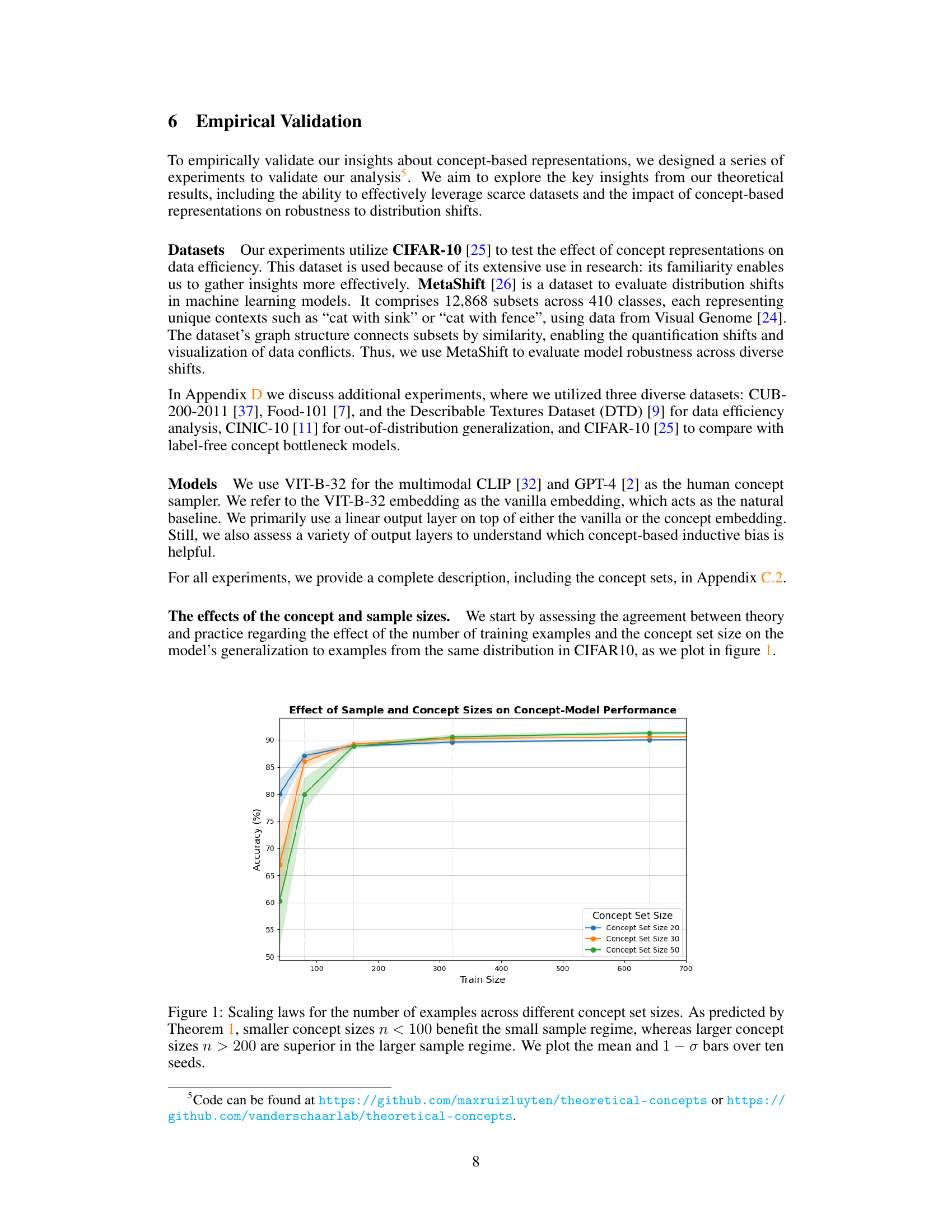
This figure shows how the accuracy of a concept-based model changes with the number of training examples and the size of the concept set. It validates Theorem 1 from the paper, which predicts that smaller concept sets are better in low-data regimes, while larger sets are better with more data. The plot shows the mean accuracy and standard deviation across 10 different random seeds.

This table presents the results of an out-of-distribution generalization experiment conducted on the CINIC-10 dataset [11]. The experiment compares the performance of two models: a baseline linear classifier trained using CLIP image embeddings (Vanilla) and a concept bottleneck model (CBM). The table shows the accuracy of each model, reported as mean ± standard deviation. The CBM’s improved performance demonstrates the benefits of using concept embeddings for enhancing the robustness of models against distribution shifts.
In-depth insights#
Concept Set Design#
Concept set design is crucial for the effectiveness of concept bottleneck models (CBMs). A well-designed concept set should balance expressiveness, ensuring concepts capture valuable information, and model-aware inductive bias, aligning concepts with the model’s inherent biases to enhance performance in low-data regimes. The optimal size of the concept set depends on the data regime; smaller sets are preferable in low-data scenarios to avoid overfitting, while larger sets may be advantageous when ample data are available to capture more nuanced information. Misspecification, the discrepancy between the optimal predictor and the concept-based model, should be minimized through careful concept selection. Practical methods for generating effective concept sets involve leveraging language models to propose candidate concepts, followed by a filtering process that prioritizes informative, non-redundant concepts, and evaluates them based on their impact on the model’s predictive power. The entire process should aim for a set of concepts that is both informative and non-redundant, ensuring efficient use of data and reducing the risk of introducing spurious correlations.
CBM Theory#
The theoretical underpinnings of Concept Bottleneck Models (CBMs) revolve around leveraging high-level representations, or concepts, to enhance model performance and interpretability. Expressiveness, the ability of concepts to capture significant information from input data, is crucial, as it directly influences the model’s ability to generalize. A second key property is model-aware inductive bias, meaning the concept set should align with the model’s assumptions, leading to better performance in low data regimes. The theory establishes a link between these properties and key performance metrics such as sample efficiency and out-of-distribution robustness. A core assumption in CBM theory is that these human-derived concepts translate into predictive power within the machine learning model. This relationship, while compelling, demands further investigation and theoretical refinement. Misspecification, the extent to which the chosen concepts fail to fully capture the underlying signal, is another critical factor influencing model accuracy, particularly in high-data settings.**
Concept ID#
Concept identification (Concept ID) in the context of concept-based learning is crucial for effective model performance. It involves selecting or generating a set of concepts that are both informative and non-redundant. Poor concept selection can lead to models that underperform, especially in low-data scenarios or when faced with distribution shifts. Expressiveness of the chosen concepts is key, ensuring they capture valuable information from the input data. Simultaneously, the concepts must exhibit a model-aware inductive bias, aligning with the model’s inherent assumptions and enabling efficient learning. Various strategies exist for concept ID, including using pre-trained multimodal models like CLIP, which leverage existing knowledge for concept embedding and facilitate more effective concept set generation. This allows for the transition from raw input data to high-level, human-understandable concepts that enhance model interpretability and ultimately improve prediction accuracy and robustness.
Empirical Results#
The Empirical Results section of a research paper should present a thorough and well-organized evaluation of the proposed method. It should clearly demonstrate the method’s effectiveness by comparing it against appropriate baselines using relevant metrics. A strong emphasis should be placed on quantitative results, including tables and figures that clearly visualize the performance differences, preferably showing statistical significance where applicable. The discussion should focus on the key findings and their interpretation in the context of the study’s hypotheses. Detailed descriptions of experimental setups and parameters are crucial for reproducibility. Any limitations or unexpected behaviors should be acknowledged and discussed, adding credibility and facilitating further research. Ideally, the results would showcase the method’s benefits across various scenarios and datasets, perhaps highlighting its robustness to different conditions, demonstrating that the results are not limited to specific or ideal circumstances. A comprehensive analysis of these empirical findings will allow readers to form a solid understanding of the method’s strengths and weaknesses.
Future Work#
The “Future Work” section of this research paper suggests several promising avenues for extending the current findings. Transferring concept properties across different model architectures and training paradigms is crucial to understand the generalizability of the inductive bias. Operationalizing concepts using a principled approach, possibly developing methods for generating concept sets in unsupervised settings, is key. Extracting concepts from trained models during a ‘model sleeping’ phase, analyzing their impact on complexity and task performance, offers further insight. Meta-learning and transfer learning enhanced by concept representations hold considerable potential, especially when dealing with diverse input spaces. Hierarchical concept structures promise more nuanced data representation, mirroring human cognitive processes. Finally, the paper rightly emphasizes the need to consider the broader implications and ethical considerations of using concept-based models, including mitigating biases, ensuring fairness, and evaluating their impact in real-world applications.
More visual insights#
More on figures

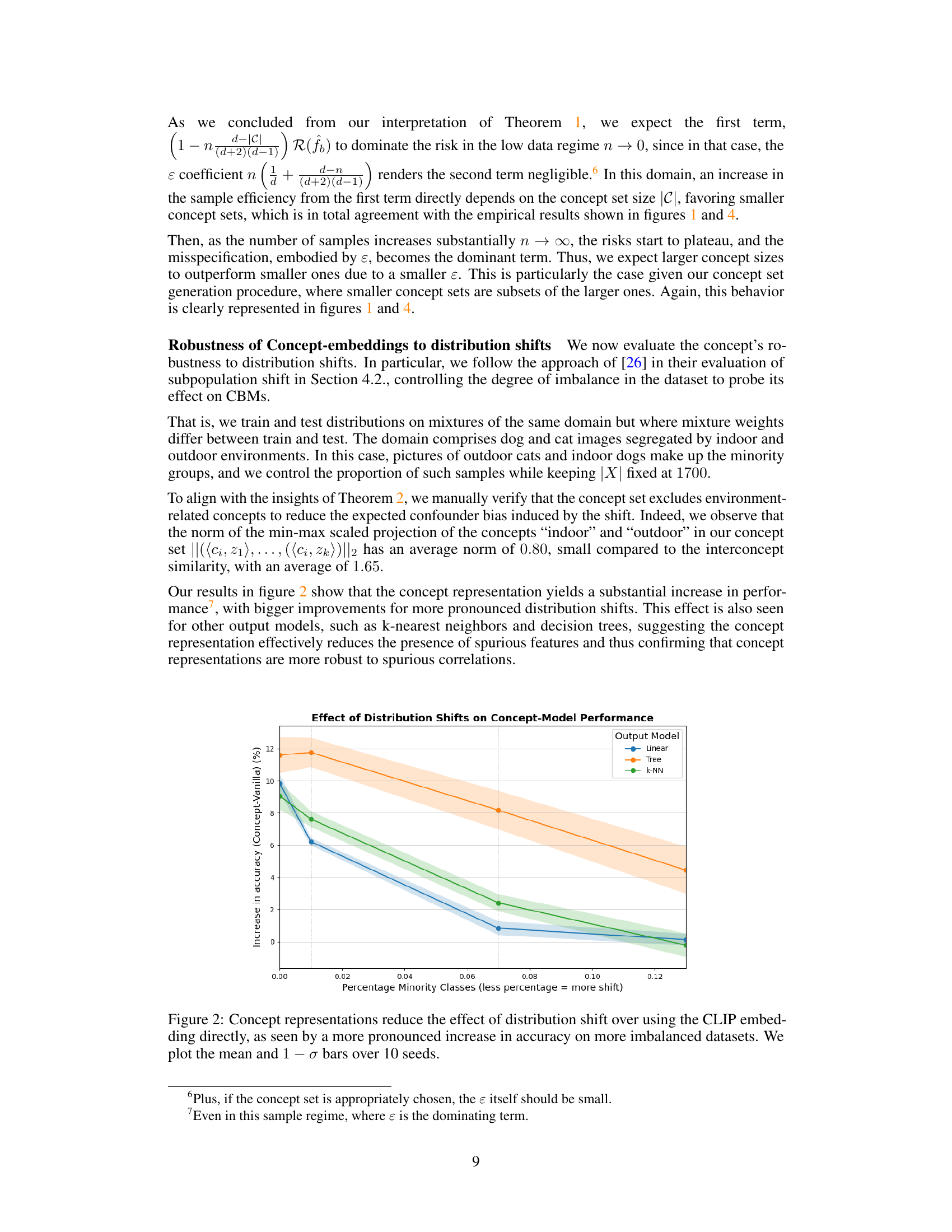
This figure shows the impact of concept-based representations on model robustness to distribution shifts. The experiment uses a dataset with varying degrees of class imbalance, simulating a shift in data distribution. Three different output model types (linear, tree, and k-NN) were tested. The y-axis shows the increase in accuracy achieved by the concept-based model compared to a baseline model using the CLIP embeddings directly. The x-axis shows the percentage of minority classes, with a smaller percentage indicating a larger distribution shift. The shaded areas represent the standard deviation across ten different random seeds. The results show that concept-based representations significantly improve model accuracy in the presence of distribution shifts, particularly for larger shifts (smaller percentage of minority classes). This improvement holds across the different output model types.
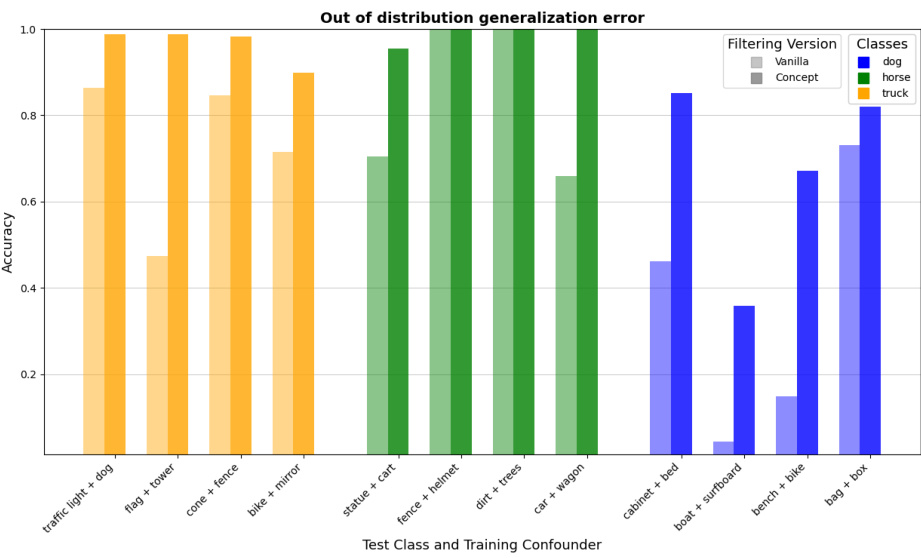
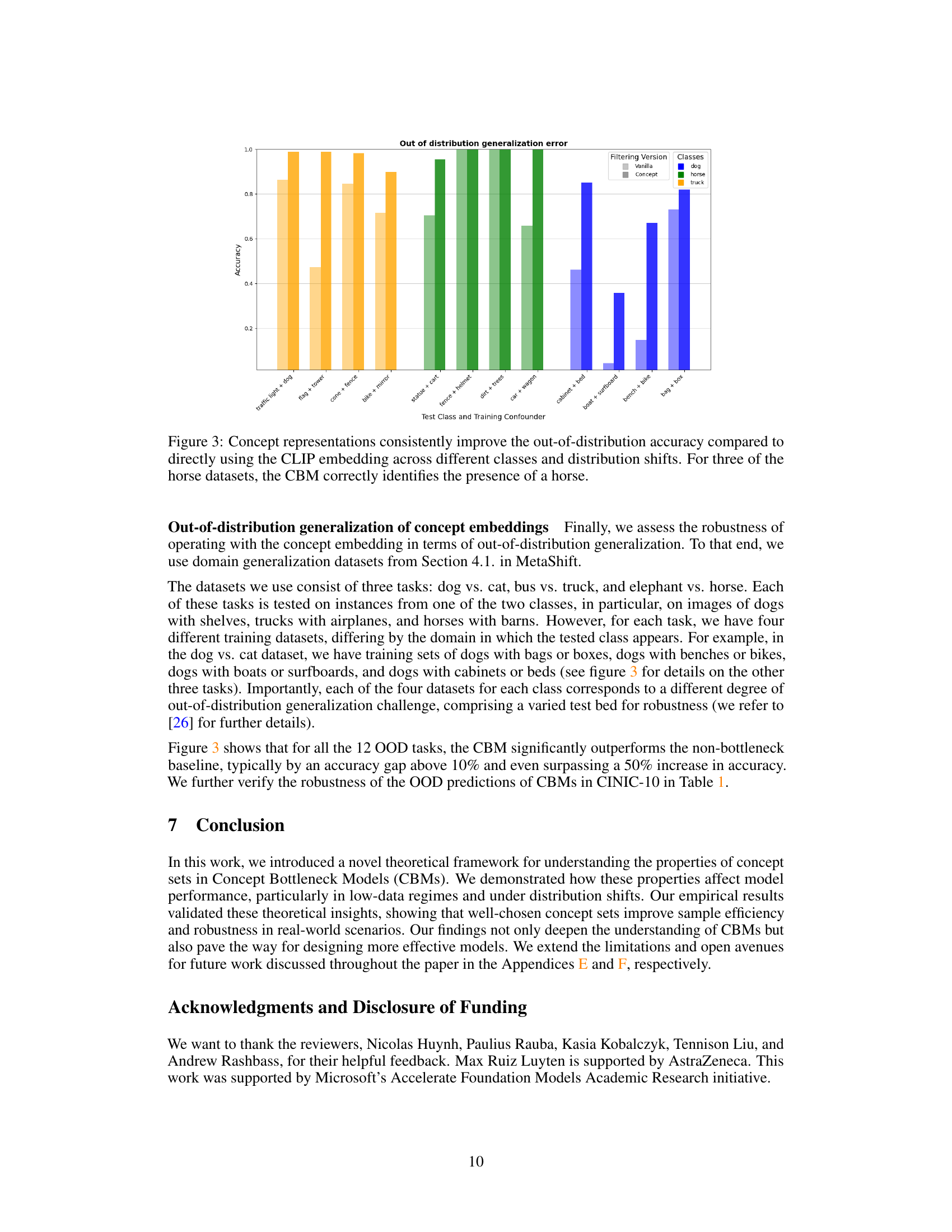
This figure displays the results of an out-of-distribution generalization experiment. The experiment uses three different tasks (dog vs. cat, bus vs. truck, and elephant vs. horse) with four different training datasets for each task, where the testing data represents various levels of distribution shifts. The bars show the accuracy of the concept-based model (CBM) and the vanilla model (using CLIP embedding directly). The results indicate that the CBM substantially outperforms the vanilla model in almost all cases, highlighting the robustness of the concept-based approach to distribution shifts.
This figure shows the relationship between the number of training examples and the performance of concept bottleneck models (CBMs) with varying concept set sizes on the CIFAR-10 dataset. The results are consistent with Theorem 1 in the paper. For smaller training sets, smaller concept sets perform better because they avoid overfitting. As the amount of training data increases, larger concept sets are preferred because they capture more of the underlying data distribution, which leads to improved generalization.
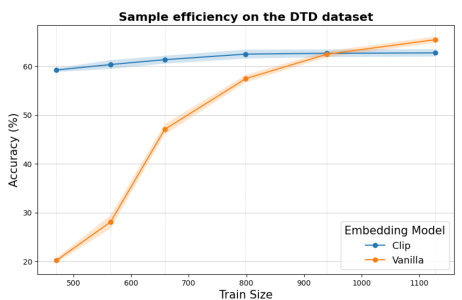
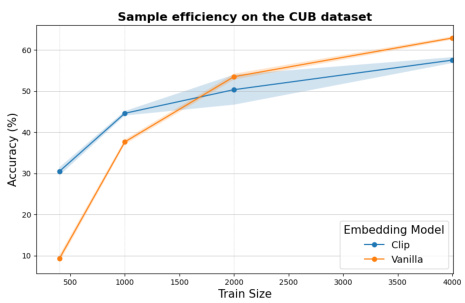
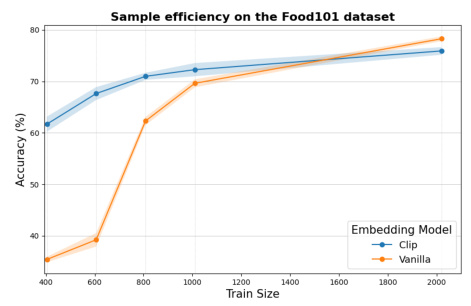
This figure compares the performance of a linear probe on CLIP embeddings against the proposed CBM across different training sizes for three datasets (CUB-200-2011, Food-101, and DTD). It demonstrates the improved sample efficiency of CBMs in low-data regimes and the impact of misspecification in larger datasets, aligning with Theorem 1’s predictions.
This figure shows the accuracy of the concept bottleneck model (CBM) and the baseline model on the CIFAR-10 dataset as a function of the number of training examples and the size of the concept set. The results demonstrate that smaller concept sets are more effective in low-data regimes, while larger concept sets perform better when more data is available. This aligns with the theoretical predictions of Theorem 1 in the paper, which suggests a trade-off between sample efficiency and misspecification error in the CBM.
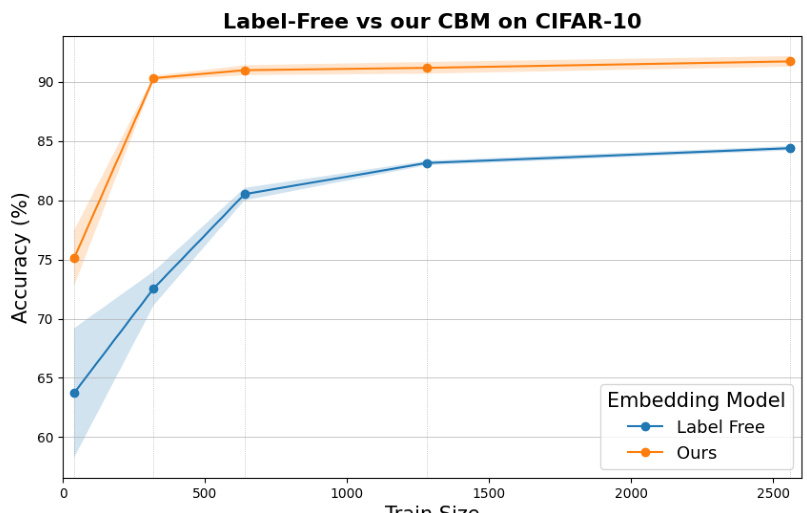
This figure compares the performance of the proposed concept set curation method with the Label-Free Concept Bottleneck Model on CIFAR-10. The results show that the proposed method consistently outperforms the Label-Free model across various training set sizes, highlighting the importance of careful concept selection for improved model performance. The performance gap is quite substantial, indicating a significant benefit from the proposed concept set generation process. This empirical result supports the paper’s theoretical findings regarding concept set properties and their influence on model accuracy.
Full paper#