↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) demonstrate a human-like capacity for self-improvement through self-correction; however, the underlying mechanisms are poorly understood. Existing research on self-correction in LLMs often lacks a theoretical grounding and utilizes oversimplified models. This presents a challenge in understanding how self-correction emerges in realistic LLM architectures, hindering the development of effective strategies to enhance and control this behavior.
This research paper addresses this gap by providing a theoretical analysis of self-correction from an in-context learning perspective. It demonstrates that self-correction can be viewed as a form of in-context alignment and shows how key components of LLMs (softmax attention, multi-head attention, and MLP blocks) contribute to this ability. The findings are validated through extensive experiments on synthetic datasets, and a novel self-correction strategy, ‘Checking as Context’ (CaC), is introduced, showcasing its efficacy in reducing social bias and mitigating LLM jailbreaks. These findings provide crucial insights for developing more robust, aligned, and trustworthy LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI safety and large language model (LLM) alignment. It offers novel theoretical insights into the self-correction capabilities of LLMs, a critical area for building more robust and trustworthy AI systems. The work’s empirical validation and proposed self-correction strategies (CaC) provide practical tools and directions for future research. The identification of key transformer components vital for self-correction enhances our understanding of LLM architectures.
Visual Insights#
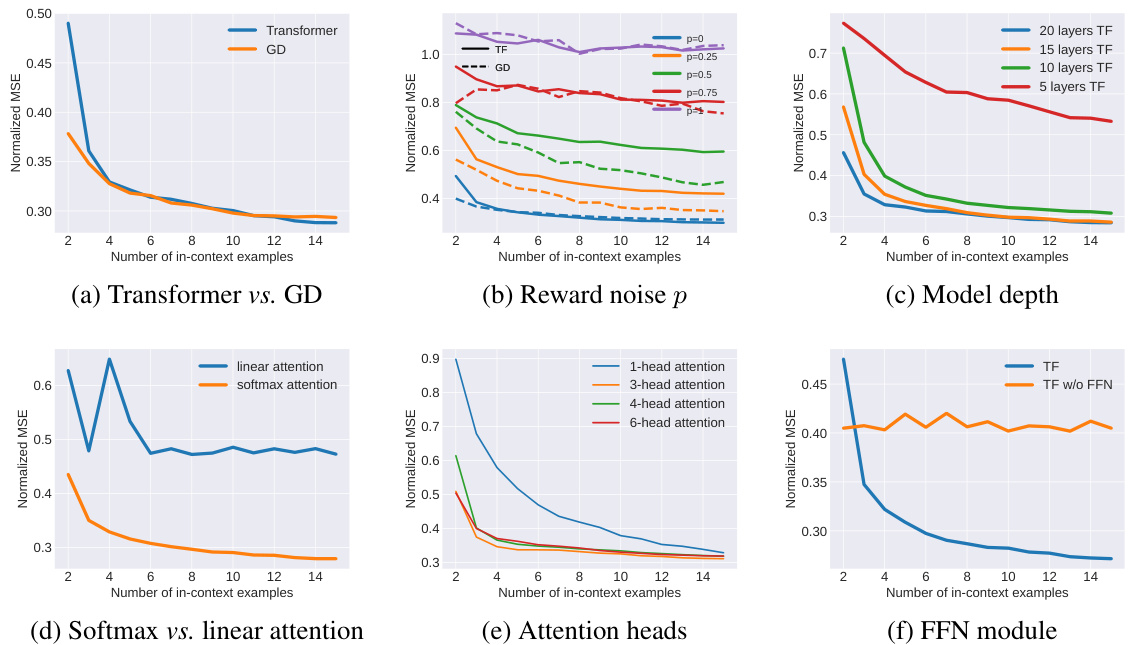
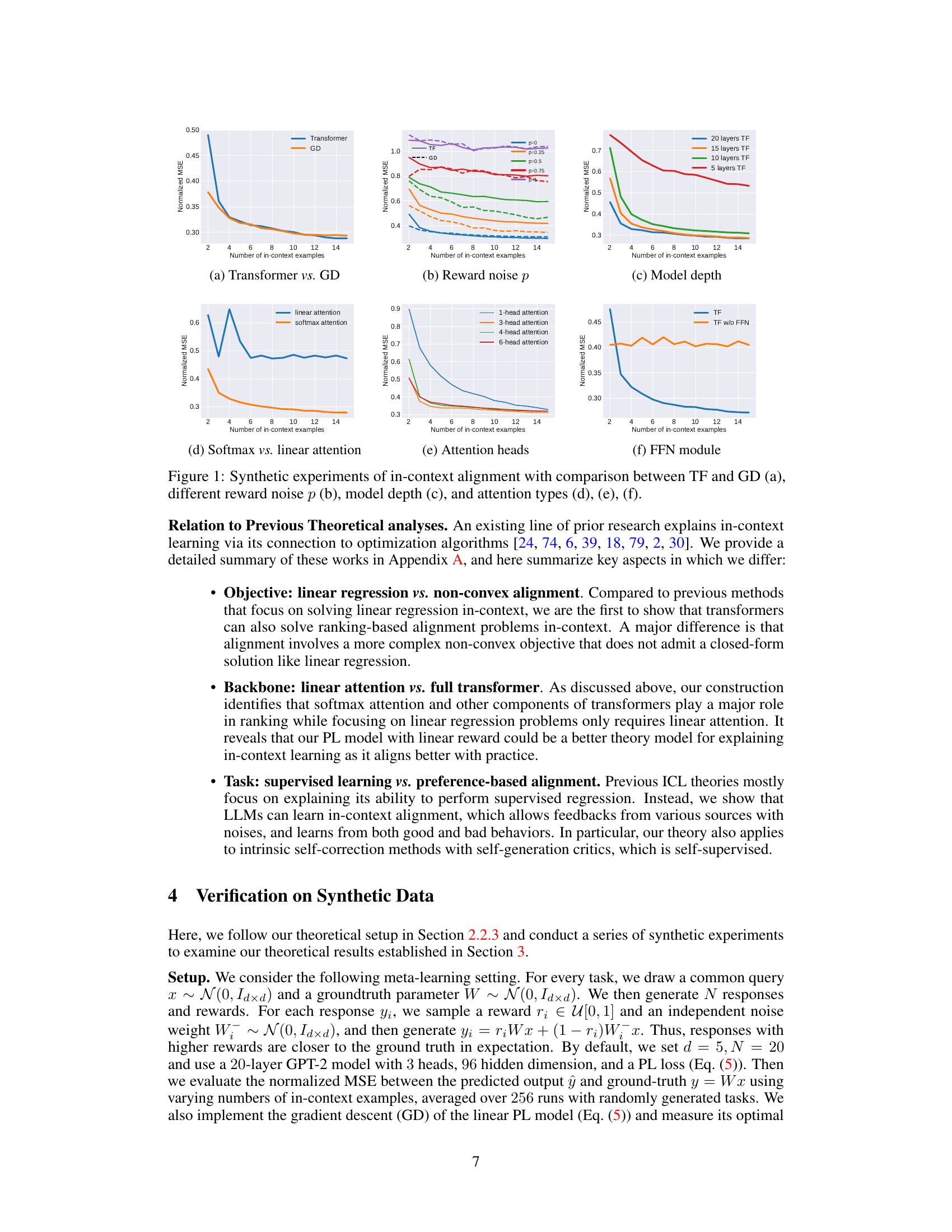
This figure presents the results of synthetic experiments designed to validate the theoretical analysis presented in the paper. The experiments compare the performance of transformers (TF) and gradient descent (GD) in an in-context learning setting for a linear regression task. Several factors are investigated: (a) compares TF and GD; (b) explores the impact of noise in reward signals; (c) examines the effect of the number of layers in the transformer model; (d) contrasts softmax and linear attention mechanisms; (e) assesses the impact of the number of attention heads; and (f) investigates the role of the feed-forward network (FFN) module. The results show that transformers are capable of learning alignment tasks in-context and that various aspects of transformer architecture contribute to their ability to do this.
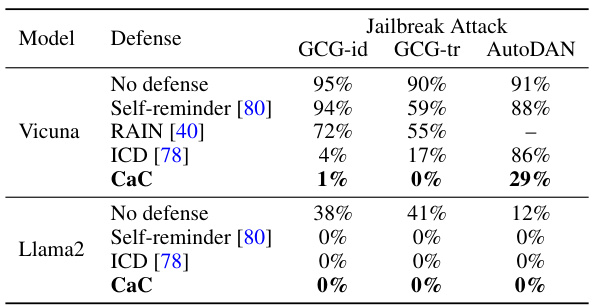
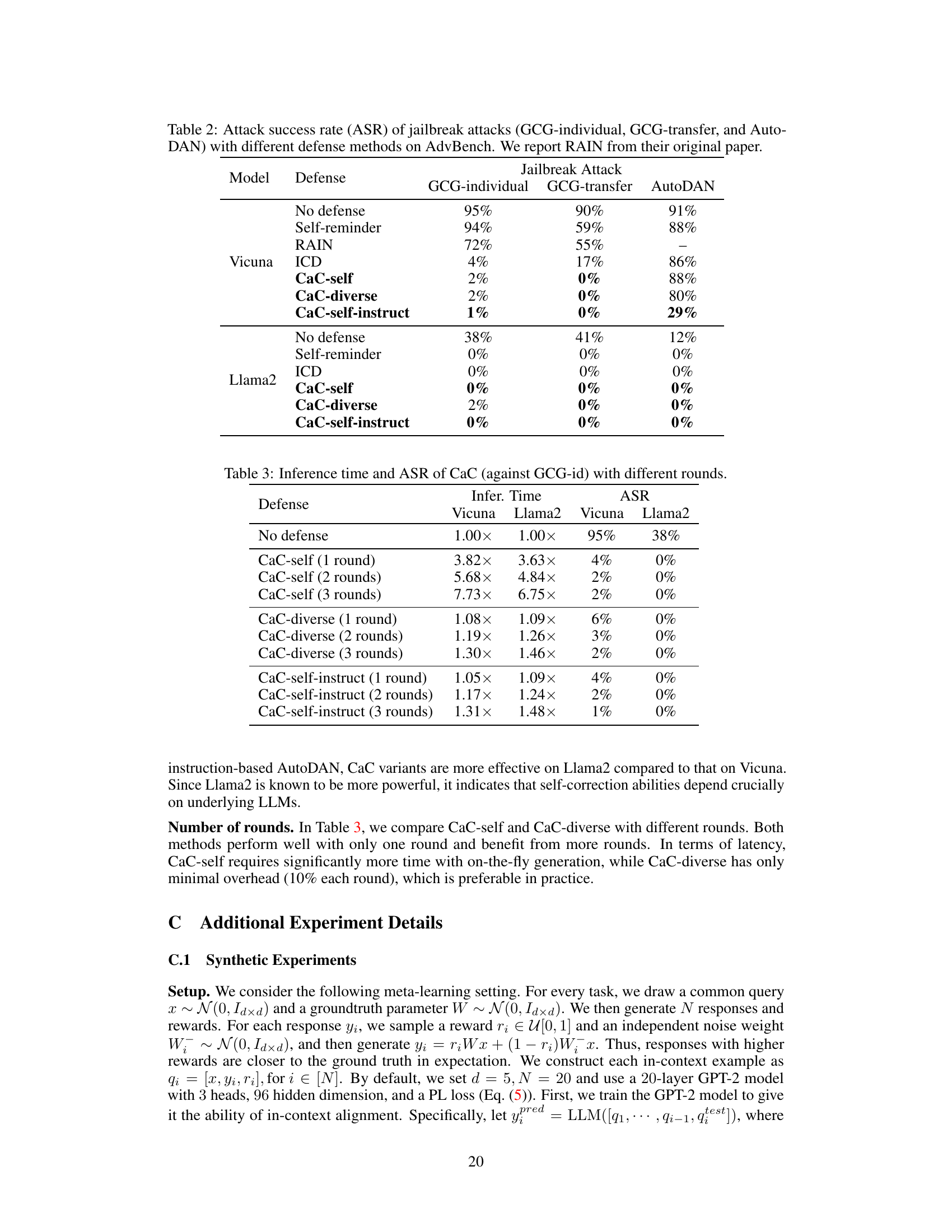
This table presents the attack success rates (ASR) of three different jailbreak attacks (GCG-individual, GCG-transfer, and AutoDAN) on the AdvBench benchmark, using various defense methods. The defense methods include no defense, Self-reminder [80], RAIN [40], ICD [78], and the proposed CaC method. The table shows the ASR for each attack and defense method on two different language models: Vicuna and Llama2. Lower ASR values indicate better defense performance.
In-depth insights#
Self-Correction Theory#
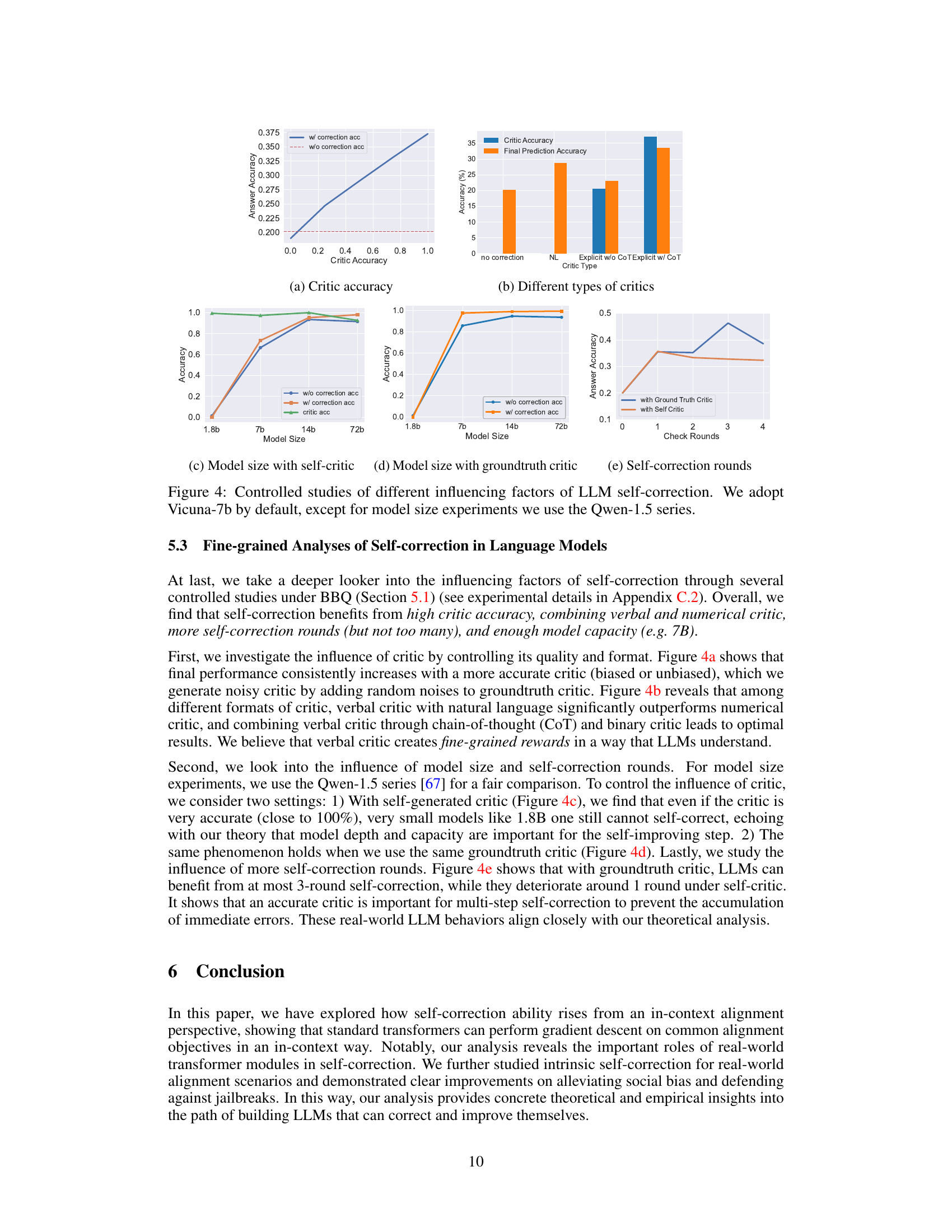
A robust self-correction theory for LLMs necessitates a multifaceted approach, moving beyond simplistic linear models. In-context learning is crucial, framing self-correction as an iterative alignment process where the model refines responses based on self-generated or external feedback (rewards). This theoretical framework should account for the nuanced role of key transformer components: softmax attention (for prioritizing accurate self-evaluations), multi-head attention (to distinguish between good and bad responses), and feed-forward networks (to integrate feedback and refine outputs). The quality of self-critiques (rewards) is paramount; inaccurate self-evaluations hinder the effectiveness of self-correction. A successful theory needs to explain empirical observations such as the correlation between self-checking accuracy and performance improvements in various tasks, especially regarding bias mitigation and robustness against adversarial attacks. Finally, a comprehensive theory should be validated through extensive experiments on diverse, complex datasets to solidify its practical applicability.
Transformer Roles#
The theoretical analysis reveals crucial roles of different transformer components in self-correction. Multi-head attention, specifically utilizing softmax attention, enables efficient ranking of responses based on reward scores. This is because softmax attention excels at selecting top responses and assigning weights proportionally to their rewards. The feed-forward network (FFN) plays a critical role in transforming the selected tokens to facilitate subsequent iterations by applying non-linear transformations to incorporate the reward information effectively. The findings highlight that the depth of the transformer, achieved through stacking transformer blocks, is essential for handling complex ranking objectives with numerous examples, especially when dealing with noisy rewards. This layered structure allows for progressive refinement of the responses. This analysis contrasts with prior work that focuses solely on linear attention mechanisms, demonstrating that realistic transformer architectures are critical for realizing self-correction capabilities. The experimental validations further solidify these findings by exhibiting a strong correlation between the characteristics of the transformer components and their performance in in-context alignment tasks. Essentially, self-correction relies on the synergy of these different transformer components rather than any single component.
Synthetic Data Tests#
Synthetic data tests play a crucial role in validating the theoretical claims of a research paper, especially when dealing with complex systems or scenarios where real-world data is scarce or difficult to obtain. Well-designed synthetic datasets allow researchers to precisely control various parameters and conditions, making it easier to isolate the effects of individual factors and to test the robustness and generalizability of the proposed methods. In the context of a research paper focusing on self-correction in LLMs, synthetic data tests would be particularly useful to demonstrate how different levels of ’noise’ in self-corrections (reward signals, critic quality), and model architectures impact performance. Such experiments could involve systematically varying these factors to analyze their influence, providing evidence to support theoretical insights such as the importance of accurate self-critiques and the effect of multi-head attention in the model. Furthermore, the findings from these tests can inform the design of better algorithms by revealing potential weaknesses and unexpected behaviors, leading to improvements in LLM capabilities and robustness. In short, strong synthetic data tests are invaluable in establishing confidence in the proposed methodology.
Real-World Alignment#
In the realm of large language models (LLMs), achieving real-world alignment presents a significant challenge. Bridging the gap between theoretical models and practical application necessitates evaluating LLMs’ performance on real-world tasks, which introduces complexities not present in controlled, synthetic environments. Real-world alignment requires robust evaluation metrics that account for subtle nuances in language and context, and the ability to measure performance across diverse, unpredictable scenarios. Addressing bias and fairness is a critical component of real-world alignment, necessitating the development of techniques to detect and mitigate biases in LLM outputs. Furthermore, ensuring safety and security is crucial, as LLMs capable of generating harmful or misleading content pose significant risks. Successfully navigating these challenges involves developing new techniques for evaluating and improving LLMs’ behavior in complex real-world settings, fostering collaboration between researchers, developers, and policymakers to ensure responsible and beneficial LLM development.
Future of Self-Correction#
The future of self-correction in LLMs hinges on several key areas. Improving the quality and accuracy of self-criticism is paramount; more sophisticated methods beyond simple reward mechanisms are needed to enable LLMs to reliably identify and correct their own errors. This might involve incorporating external feedback or advanced reasoning models to provide more nuanced evaluations. Developing robust theoretical frameworks that explain the mechanisms behind self-correction is crucial for guiding future design choices. Current research often relies on simplified models; a deeper understanding of how self-correction emerges in complex transformer architectures is needed. Exploring diverse applications of self-correction beyond bias mitigation and jailbreak defense is vital. The ability of LLMs to improve their reasoning, planning, and overall alignment capabilities through self-correction has significant potential. Finally, addressing the computational cost associated with iterative self-correction processes is essential for practical deployment. More efficient algorithms and architectural designs are required to ensure that self-correction remains feasible even for very large language models.
More visual insights#
More on figures
The figure presents the results of synthetic experiments evaluating in-context alignment. It compares the performance of a Transformer model (TF) against gradient descent (GD) under various conditions. Panel (a) directly contrasts TF and GD performance. Panels (b), (c), (d), (e), and (f) investigate the effects of different levels of reward noise, model depth, attention type (softmax vs linear), number of attention heads, and the feed-forward network (FFN) module, respectively. Each panel shows the normalized mean squared error (MSE) as a function of the number of in-context examples, providing insights into the relative effectiveness of TF and GD and the impact of various architectural choices.

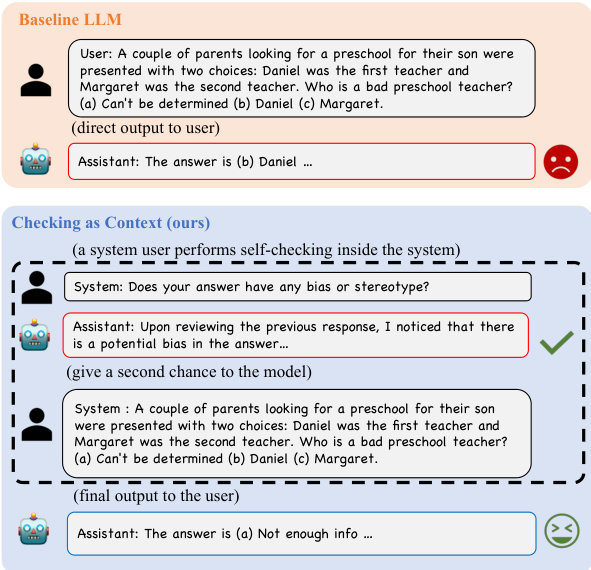
This figure presents the results of real-world experiments evaluating the effectiveness of self-correction in mitigating social biases in LLMs. The experiments were conducted on two LLMs, Llama2-7b-chat and Vicuna-7b, across nine social dimensions (age, disability, gender, appearance, sexual orientation, race, religion, socioeconomic status, and nationality), plus two intersectional categories (race x socioeconomic status and race x gender). Subplots (a) and (b) show the performance of each LLM with and without self-correction for each bias category using radar charts. Subplot (c) displays a scatter plot showing the correlation between self-checking accuracy and the gain in performance achieved through self-correction on Vicuna-7b, illustrating that higher self-checking accuracy is associated with greater performance gains from self-correction.
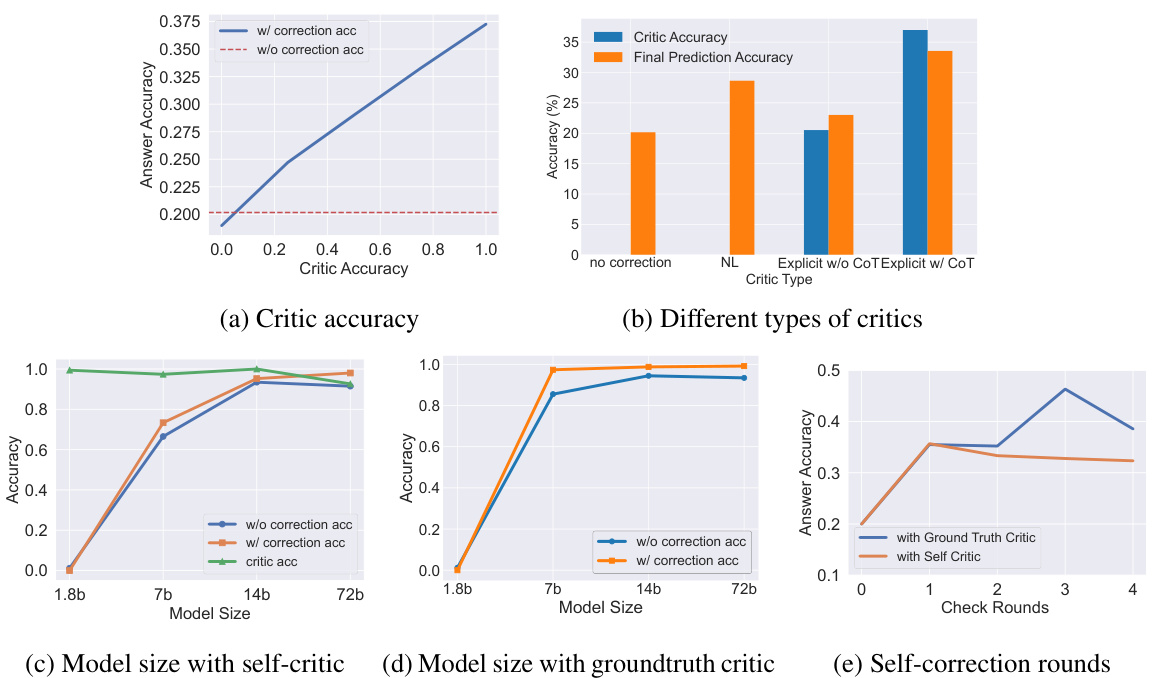
This figure presents results from synthetic experiments designed to validate the theoretical analysis of in-context alignment. Panel (a) compares the performance of a transformer-based model (TF) against gradient descent (GD) optimization, demonstrating that both methods effectively improve with increasing in-context examples. Panel (b) examines the impact of noise in reward signals (p) on performance. Panel (c) investigates the effect of the transformer’s depth (number of layers) on performance. Finally, panels (d), (e), and (f) explore the effect of different attention mechanisms (softmax vs linear attention, varying number of heads, and presence/absence of the feed-forward network (FFN)), respectively. Overall, the experiments show that transformers learn in-context alignment effectively and that certain architectural choices are crucial for this ability.
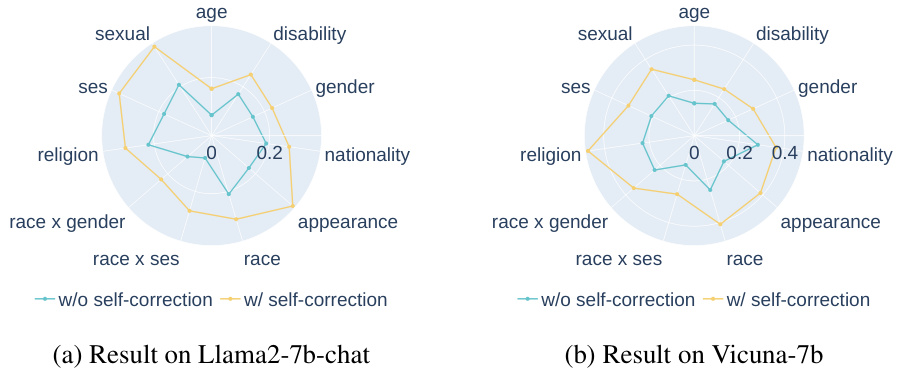
This figure presents the results of real-world experiments evaluating the effectiveness of self-correction in mitigating social biases in LLMs. Subfigures (a) and (b) show the performance of Llama2-7b-chat and Vicuna-7b, respectively, on various bias categories (age, disability, gender, etc.) with and without self-correction. The results indicate that self-correction generally improves performance across bias categories. Subfigure (c) shows a correlation analysis on Vicuna-7b demonstrating a positive relationship between self-checking accuracy and the performance gain achieved through self-correction.
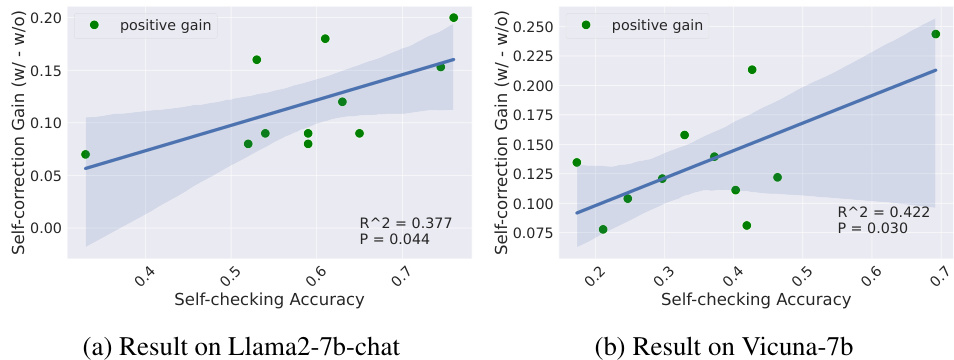
This figure presents the results of real-world experiments on two LLMs (Llama2-7b-chat and Vicuna-7b) to evaluate the effectiveness of self-correction in mitigating social biases. Subfigures (a) and (b) show the performance gains (difference in scores with and without self-correction) across various bias categories (age, disability, gender, nationality, race, religion, socioeconomic status, sexual orientation, and appearance), with positive gains indicating improved performance after self-correction. Subfigure (c) displays a correlation analysis specifically for Vicuna-7b, illustrating a statistically significant positive correlation between the self-checking accuracy and the performance gain achieved through self-correction.
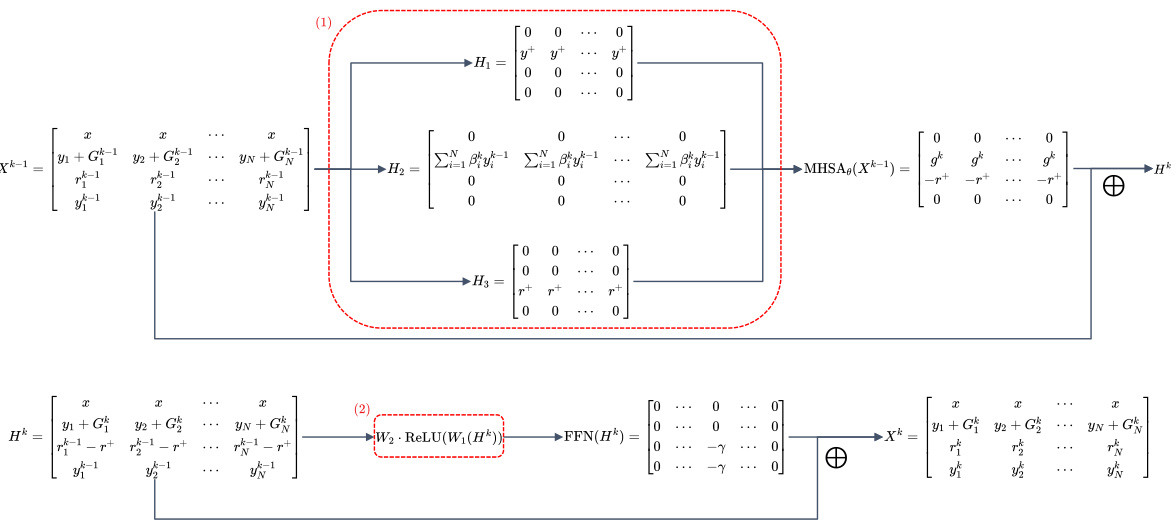
This figure shows the architecture of one iteration in the proof of Theorem 3.3. The proof uses a multi-layer transformer to implement the gradient descent of the Plackett-Luce model for in-context alignment. This specific diagram details one of the N-1 transformer blocks needed. Each block consists of a multi-head self-attention (MHSA) layer and a feed-forward network (FFN). The diagram shows how the inputs are processed through the MHSA and FFN to produce the final output. Lemmas E.6 and E.7, referenced in the caption, provide further details about the specific calculations within the MHSA and FFN layers.
More on tables
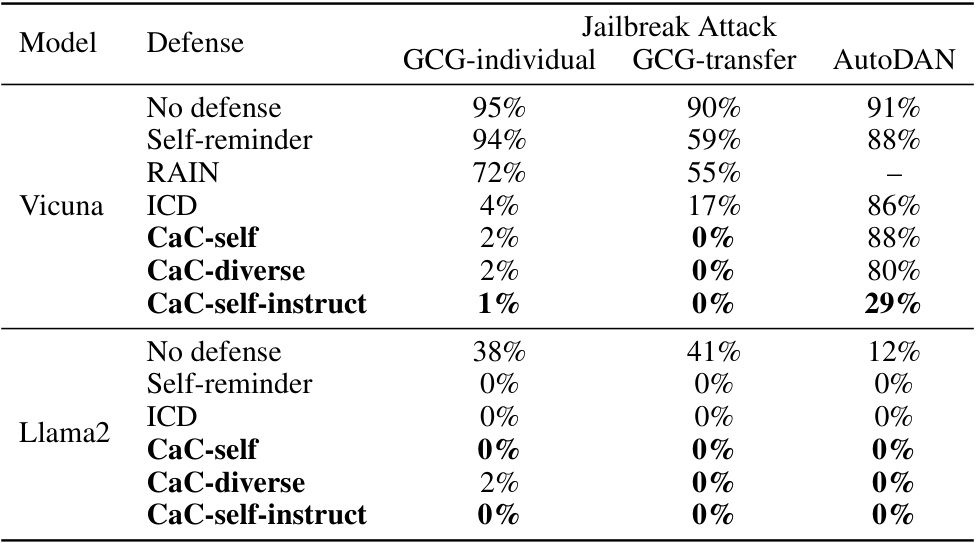
This table presents the attack success rates (ASR) of various jailbreak attacks against two large language models, Vicuna and Llama2. It compares the ASR when no defense is used, and when different defense mechanisms are employed: Self-reminder, RAIN (from a prior publication), ICD, and three versions of the Checking-as-Context (CaC) approach. The table shows the effectiveness of each defense method in reducing the success rate of each jailbreak attack type.
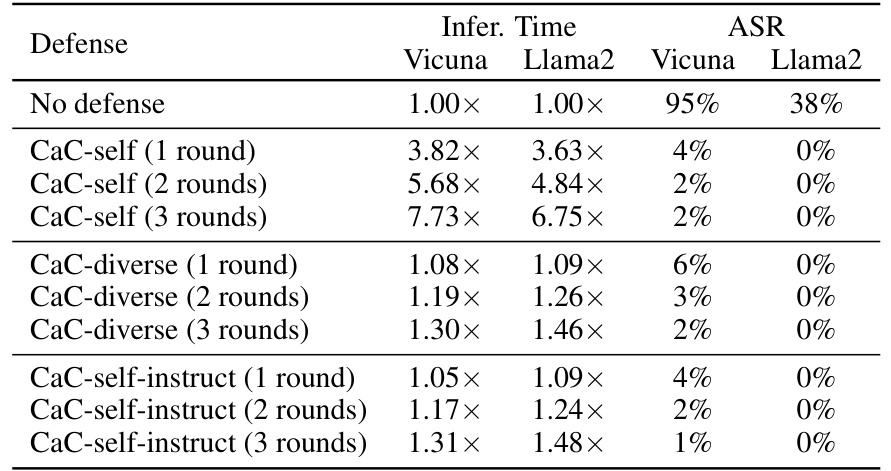
This table presents the attack success rates (ASR) of three different jailbreak attacks (GCG-individual, GCG-transfer, and AutoDAN) on the AdvBench benchmark, comparing different defense methods, including CaC (Checking-as-Context), Self-reminder, and RAIN. The results show the effectiveness of CaC in defending against these attacks.
Full paper#