TL;DR#
Current methods for 3D scene understanding from videos face challenges: limited real-world data, difficulties in finding corresponding frames across different viewpoints, and high computational costs. This paper addresses these limitations by introducing a novel approach.
The proposed approach involves collecting a large-scale dataset of one million 360° videos. A new method efficiently identifies corresponding frames with diverse viewpoints. A diffusion-based model named ODIN is trained on the dataset. ODIN surpasses existing methods in novel view synthesis and 3D scene reconstruction benchmarks. Notably, ODIN handles complex real-world scenes effectively.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces 360-1M, a large-scale real-world multi-view dataset, and ODIN, a diffusion-based model trained on it. This significantly advances novel view synthesis and 3D reconstruction, especially for complex real-world scenes. The availability of 360-1M dataset and open-source model will drive further research and innovation in the field. Researchers can leverage 360-1M and ODIN to develop improved methods for diverse applications, such as AR/VR, robotics, and autonomous driving. The motion masking technique introduced is also novel and applicable to other video-based 3D reconstruction tasks.
Visual Insights#
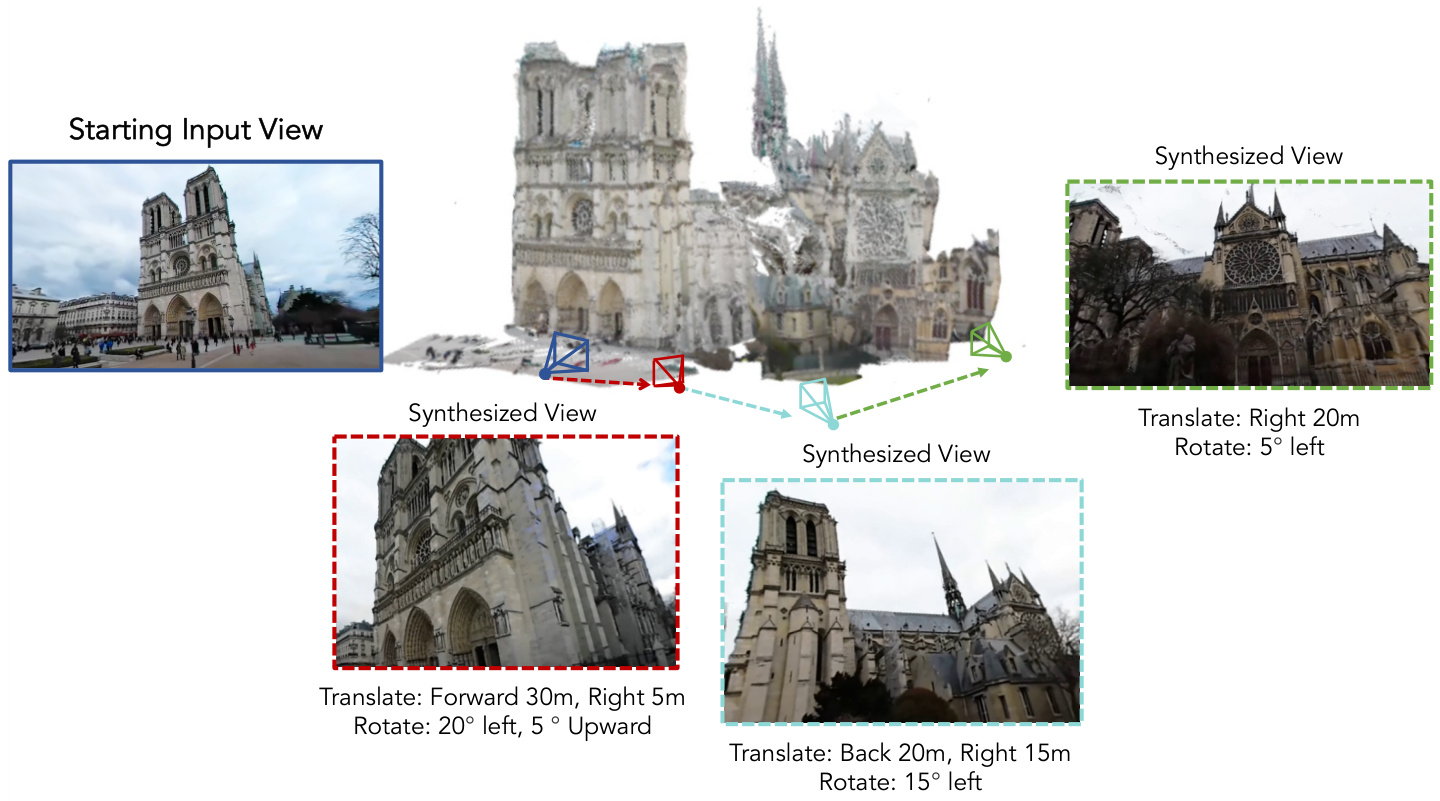
🔼 This figure demonstrates the capabilities of the ODIN model. Given a single input image of a scene (Notre Dame Cathedral), the model generates multiple novel views from different camera positions and orientations. These positions are indicated in the figure. The generated views show consistent geometry and details, demonstrating the model’s ability to understand and reconstruct the 3D scene from a single image.
read the caption
Figure 1: By learning from the largest real-world, multi-view dataset to date, our model ODIN, can synthesize novel views of rich scenes from a single input image with free camera movement throughout the scene. We can then reconstruct the 3D scene geometry from these geometrically consistent generations.
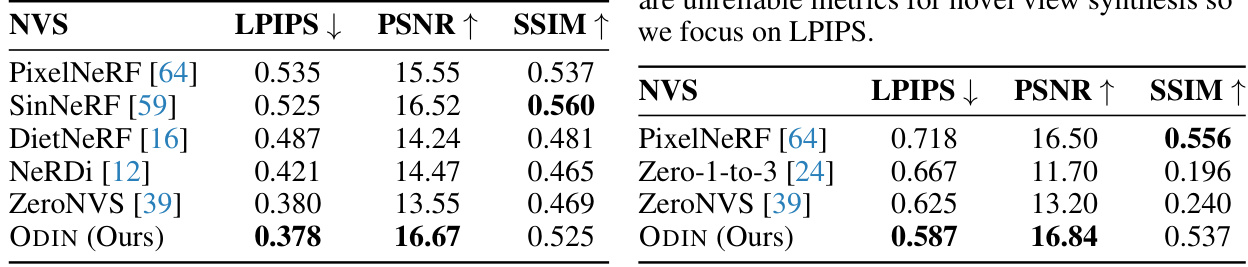
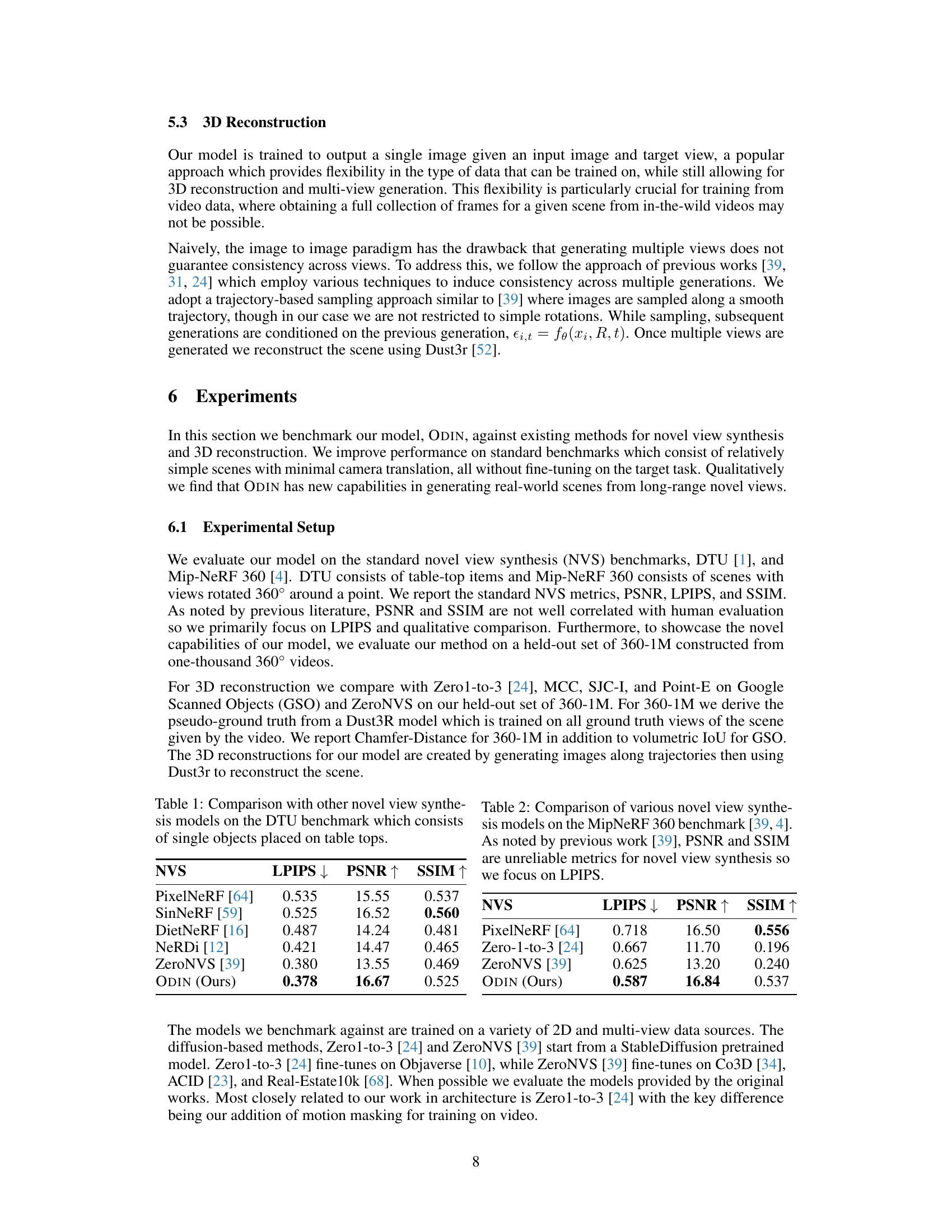
🔼 This table presents a comparison of the performance of various novel view synthesis (NVS) models on the DTU benchmark dataset. The DTU dataset consists of scenes with single objects placed on table tops, providing a relatively simple and controlled setting for evaluation. The table shows the LPIPS (lower is better), PSNR (higher is better), and SSIM (higher is better) scores achieved by each model, offering a quantitative comparison of their ability to generate realistic novel views.
read the caption
Table 1: Comparison with other novel view synthesis models on the DTU benchmark which consists of single objects placed on table tops.
In-depth insights#
360° Video Dataset#
The creation of a large-scale, high-quality 360° video dataset is a significant contribution to the field of computer vision. This dataset addresses the limitations of existing multi-view datasets by offering scalable corresponding frames from diverse viewpoints, which is crucial for training robust 3D understanding models. The use of 360° videos allows for the acquisition of multiple views from a single recording, overcoming the challenges associated with traditional videos that have fixed camera viewpoints. Efficient correspondence search techniques are employed to overcome the computational cost associated with finding corresponding frames across a large dataset. The dataset’s size and diversity are key features, enabling the training of models capable of imagining the world from a multitude of perspectives, going beyond the limitations of existing datasets. The availability of such a dataset allows researchers to improve upon existing novel view synthesis and 3D reconstruction methods. Furthermore, the open-sourcing of this dataset will significantly accelerate research in the field.
Diffusion Model#
Diffusion models are a powerful class of generative models that have shown remarkable success in image generation. They work by gradually adding noise to an image until it becomes pure noise, then learning to reverse this process to generate new images. The paper leverages a diffusion-based model for novel view synthesis, demonstrating its ability to generate realistic and coherent novel views of real-world scenes from a single input image. This is a significant achievement, as existing methods often struggle with this task, particularly for complex scenes. The use of diffusion models is particularly well-suited to this problem due to their ability to learn complex data distributions. The model’s performance is further enhanced by the use of a large-scale, real-world dataset of 360° videos. This multi-view dataset is crucial for training the model, as it allows the model to learn the 3D geometry of the scene from diverse viewpoints. However, the paper also highlights limitations such as the difficulty of handling dynamic elements in video data. Overall, the use of diffusion models represents a significant advancement in novel view synthesis, paving the way for more realistic and immersive 3D experiences.
Novel View Synth#
Novel View Synthesis (NVS) is a core focus, aiming to generate realistic images from viewpoints unseen during training. The paper highlights the limitations of existing NVS methods, particularly their reliance on limited, often synthetic datasets. The introduction of 360-1M, a massive real-world dataset of 360° videos, is a crucial contribution, enabling training of a diffusion-based model, ODIN, which overcomes prior limitations. ODIN’s ability to freely move the camera and infer scene geometry is a significant advancement, producing more realistic and coherent novel views than previous methods. The approach tackles challenges like scale ambiguity and handling dynamic scenes through innovative techniques, such as motion masking. The results demonstrate superior performance on established benchmarks, showcasing the effectiveness of leveraging large-scale real-world data for training NVS models.
3D Reconstruction#
The paper’s section on 3D reconstruction highlights a novel approach enabled by its large-scale 360° video dataset. Instead of relying solely on multi-view image datasets, the method leverages the temporal consistency inherent in videos to generate multiple views of a scene. This approach uses a trajectory-based sampling technique, ensuring geometric consistency across generated images, which are then used to perform 3D reconstruction. The model’s performance is compared against existing 3D reconstruction methods on standard benchmark datasets, showcasing improvements particularly for complex real-world scenes. The ability to handle dynamic elements in real-world videos is addressed via a motion masking technique, showing that the model can generate plausible reconstructions of scenes with movement. The success suggests a viable alternative for large-scale, realistic 3D modeling, moving beyond the limitations of static, limited datasets that are common in existing methods.
Motion Masking#
The concept of ‘Motion Masking’ addresses a critical challenge in training novel view synthesis (NVS) models on real-world videos: the presence of dynamic elements. Standard NVS datasets often focus on static scenes, limiting the applicability of trained models to real-world scenarios. Motion masking tackles this by introducing a mechanism to filter out dynamic portions of a scene during training. This is achieved by predicting a dense mask that assigns weights (between 0 and 1) to each pixel, effectively emphasizing static elements in the loss function and mitigating the effects of moving objects. The mask is learned alongside other model parameters, allowing the network to adaptively focus on stable parts of the scene for view synthesis. An auxiliary loss is also introduced to prevent the model from trivially setting the mask to zero, ensuring that a sufficient amount of the scene is still considered. This approach enables training on diverse and complex real-world video data, leading to improved performance on novel view synthesis tasks. The novelty lies in its applicability to in-the-wild videos, overcoming limitations of previous methods that either rely on static datasets or require manual filtering of dynamic content. The result is a more robust and realistic model capable of handling the complexities of real-world scene generation.
More visual insights#
More on figures
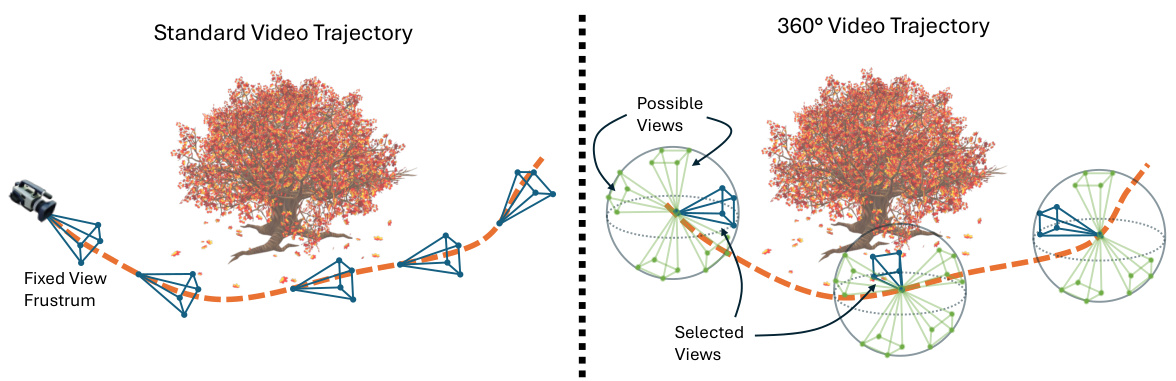
🔼 This figure compares the trajectories of standard video recording and 360° video recording. The left panel shows a standard video, where the camera’s viewpoint is fixed, resulting in a limited range of views and making it difficult to find corresponding frames with significantly different perspectives. The right panel depicts a 360° video, where the camera’s viewpoint is controllable, enabling the capture of a much wider range of views and greatly facilitating the identification of corresponding frames from diverse perspectives. This difference in viewpoint control is highlighted as a key advantage of using 360° video for creating multi-view datasets for novel view synthesis.
read the caption
Figure 2: Left: An illustrative trajectory of standard video with the view point fixed at the time of capture. The fixed view point makes finding corresponding frames challenging. Right: The trajectory of a 360° video through the scene. The controllable camera enables alignment of views at different frames of the video.

🔼 This figure shows a qualitative comparison of novel view synthesis results on real-world scenes using three different methods: ODIN (the authors’ method), Zero 1-to-3, and ZeroNVS. For each scene, input views from the left and right are given, followed by the synthesized views generated by each method. The figure highlights ODIN’s superior ability to accurately model the geometry and details of complex real-world scenes, even generating unseen parts.
read the caption
Figure 3: Qualitative comparison of novel view synthesis on real-world scenes. The left and right images are conditioned on camera views from the left and right respectively. In the middle scene of the kitchen, ODIN accurately models the geometry of the table counter and chairs as well as unseen parts of the scene such as the living room.
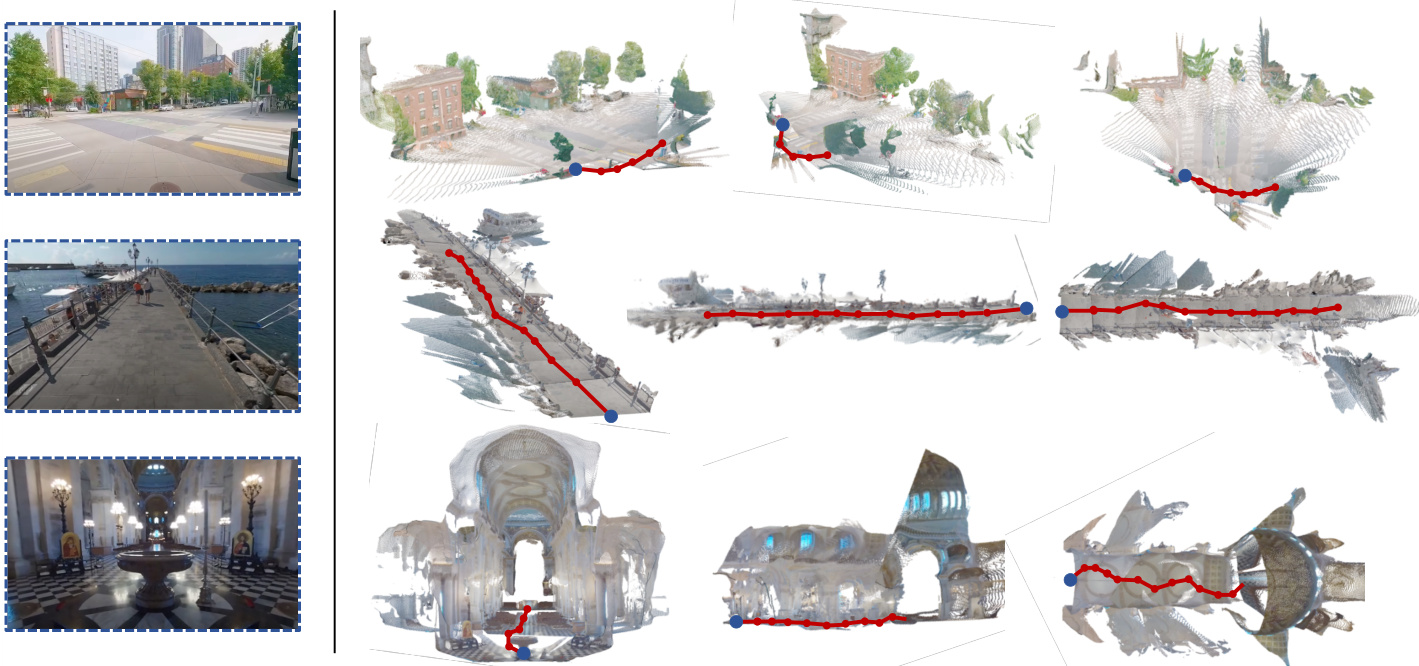
🔼 This figure shows three examples of 3D scenes generated by the ODIN model. Each example starts with a single input image (shown on the left) and then generates a sequence of images from different viewpoints along a trajectory indicated by red lines. The model is able to generate long-range consistent images showing unseen parts of the scenes. In one example, the model is able to accurately infer the geometry of the cathedral ceiling and hallway, even though they are not visible in the original input image.
read the caption
Figure 4: Examples of generated 3D scenes using ODIN. The blue dot indicates the location of the input image and the red lines indicate the trajectory of the camera which generated the images. ODIN is capable of long-range generation of geometrically consistent images. In the bottom scene, we see the model accurately infers the geometry of the unseen cathedral ceiling and the long hallway.
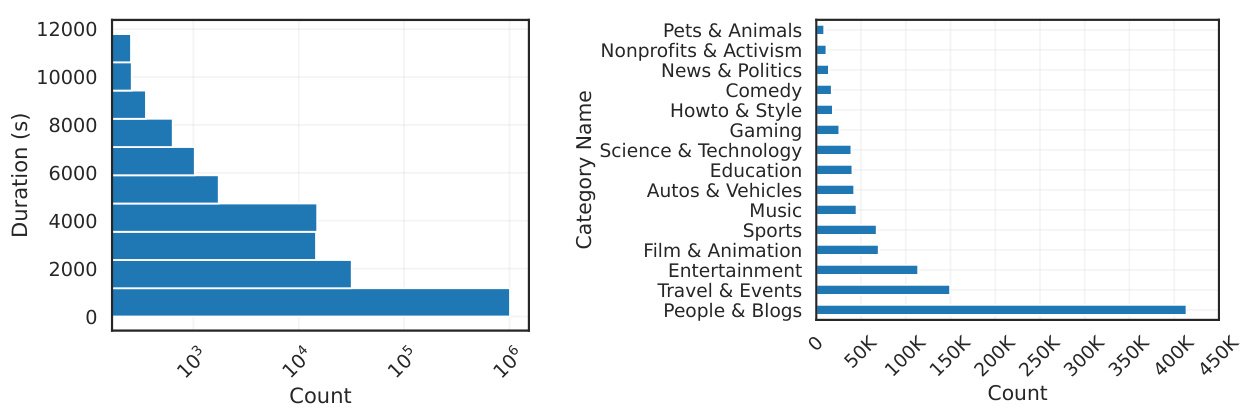
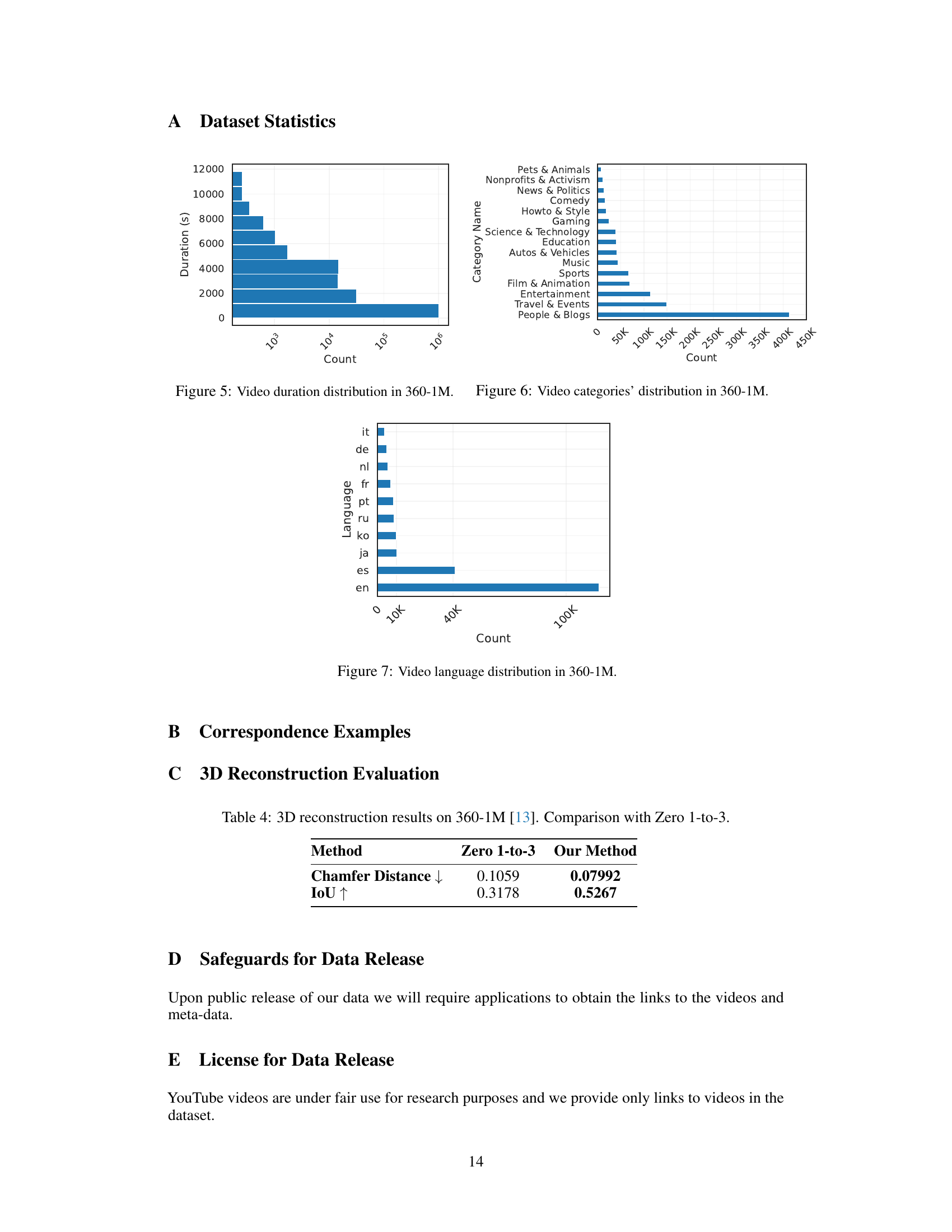
🔼 This figure shows three bar charts visualizing the statistics of the 360-1M dataset. Figure 5 displays the distribution of video durations, showing how many videos fall within specific time ranges. Figure 6 presents the distribution of videos across different categories, indicating the prevalence of each category in the dataset. Figure 7 illustrates the distribution of videos based on their languages.
read the caption
Figure 5: Video duration distribution in 360-1M. Figure 6: Video categories' distribution in 360-1M. Figure 7: Video language distribution in 360-1M.

🔼 This bar chart displays the distribution of languages present in the 360-1M dataset. The x-axis represents the count of videos, while the y-axis lists the different languages. English (’en’) is by far the most prevalent language, followed by Spanish (’es’), with all other languages having significantly fewer videos.
read the caption
Figure 7: Video language distribution in 360-1M.
🔼 This figure showcases the capabilities of the ODIN model in generating 3D scenes from a single input image. It highlights ODIN’s ability to generate geometrically consistent images along a camera trajectory, even inferring unseen parts of the scene (like the cathedral ceiling). The blue dot shows the input image location; red lines trace the camera’s path.
read the caption
Figure 4: Examples of generated 3D scenes using ODIN. The blue dot indicates the location of the input image and the red lines indicate the trajectory of the camera which generated the images. ODIN is capable of long-range generation of geometrically consistent images. In the bottom scene, we see the model accurately infers the geometry of the unseen cathedral ceiling and the long hallway.

🔼 This figure shows examples of 3D scenes generated by the ODIN model. The model takes a single input image (indicated by a blue dot) and generates multiple views of the scene along a trajectory (red lines). The generated scenes demonstrate ODIN’s ability to create geometrically consistent images, even of unseen parts of the scene (e.g., the cathedral ceiling in the bottom example).
read the caption
Figure 4: Examples of generated 3D scenes using ODIN. The blue dot indicates the location of the input image and the red lines indicate the trajectory of the camera which generated the images. ODIN is capable of long-range generation of geometrically consistent images. In the bottom scene, we see the model accurately infers the geometry of the unseen cathedral ceiling and the long hallway.

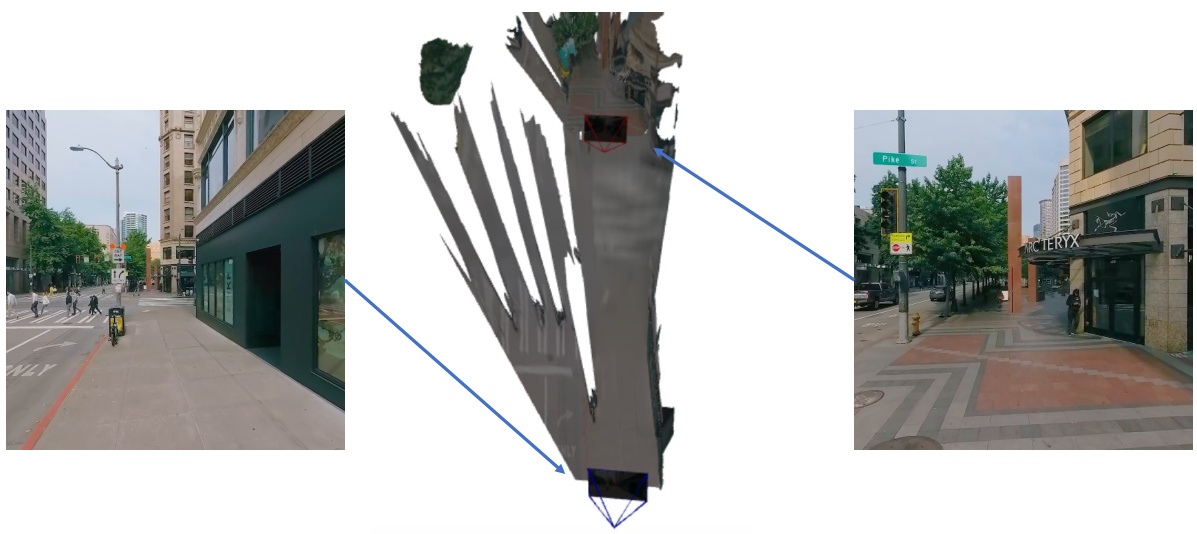
🔼 This figure displays examples of correspondences from the MVImageNet dataset, which was previously considered the largest multi-view dataset. It showcases pairs of images depicting various objects (toy mouse, ladder, toy tiger, ceiling lamp, toy rabbit, and light switch) from different viewpoints, highlighting the challenge of finding such correspondences in real-world data. The images show various aspects of the objects to illustrate the diversity of views captured.
read the caption
Figure 10: General example of correspondences from MVImageNet. Previously the largest multi-view dataset.
More on tables

🔼 This table presents a comparison of 3D reconstruction performance on the Google Scanned Objects dataset. It shows the Chamfer Distance and IoU (Intersection over Union) metrics for five different methods: MCC, SJC-I, Point-E, Zero-1-to-3, and the authors’ proposed method, ODIN. Lower Chamfer Distance and higher IoU indicate better reconstruction performance.
read the caption
Table 3: 3D reconstruction results on Google Scanned Objects [13].
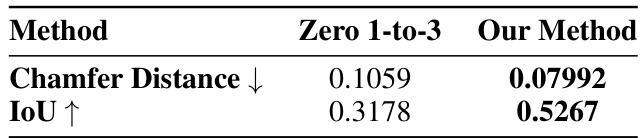
🔼 This table presents a comparison of 3D reconstruction performance between the proposed method (Our Method) and the Zero 1-to-3 method on the 360-1M dataset. The metrics used for comparison are Chamfer Distance (lower is better) and IoU (Intersection over Union, higher is better). The results show that the proposed method significantly outperforms Zero 1-to-3 in terms of both metrics, indicating improved accuracy in 3D scene reconstruction.
read the caption
Table 4: 3D reconstruction results on 360-1M [13]. Comparison with Zero 1-to-3.
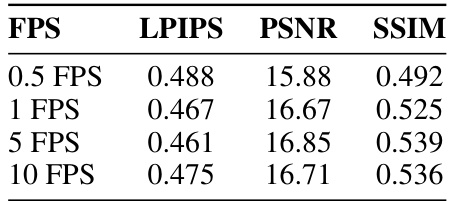
🔼 This table shows the impact of different frame rates (FPS) when sampling video frames on the quality of novel view synthesis. The metrics used to assess the quality are LPIPS (Learned Perceptual Image Patch Similarity), PSNR (Peak Signal-to-Noise Ratio), and SSIM (Structural Similarity Index). Lower LPIPS values indicate better perceptual similarity, while higher PSNR and SSIM values indicate better overall image quality. The table helps determine the optimal balance between computational cost (higher FPS means more computation) and model performance.
read the caption
Table 5: Evaluation of LPIPS, PSNR, and SSIM at different frame rates (FPS) of sampling.
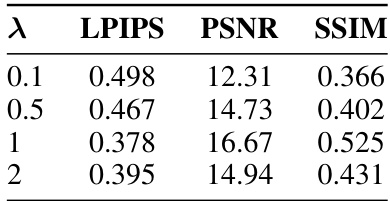
🔼 This table presents the results of an ablation study on the hyperparameter λ, which controls the strength of motion masking in the novel view synthesis model. The study varied λ and measured the impact on the LPIPS, PSNR, and SSIM metrics, which are common evaluation metrics for image quality in novel view synthesis. Lower LPIPS values indicate better perceptual similarity, while higher PSNR and SSIM values indicate better overall image quality.
read the caption
Table 6: Ablation study over λ values for motion masking with novel view synthesis metrics.
Full paper#