↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Graph Neural Networks (GNNs) are susceptible to adversarial attacks, particularly graph injection attacks (GIAs). Existing research primarily focuses on embedding-level GIAs, which inject node embeddings rather than actual textual content. This limitation simplifies detection and limits applicability. Moreover, embedding-level attacks are often unrealistic and lack interpretability.
This paper introduces text-level GIAs, injecting textual content instead of embeddings. Three novel attack designs are proposed and analyzed: Vanilla Text-level GIA, Inversion-based Text-level GIA, and Word-frequency-based Text-level GIA. The study demonstrates that text interpretability, previously overlooked, significantly affects attack strength. Word-frequency-based Text-level GIA shows a balance between attack effectiveness and interpretability, but defenses can be enhanced via customized embeddings or LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on graph neural networks (GNNs) and adversarial attacks. It highlights a critical vulnerability in text-attributed graphs, a common type of data in real-world applications. By pioneering the study of text-level attacks, the research opens new avenues for improving GNN robustness and underscores the need for more sophisticated defense mechanisms.
Visual Insights#
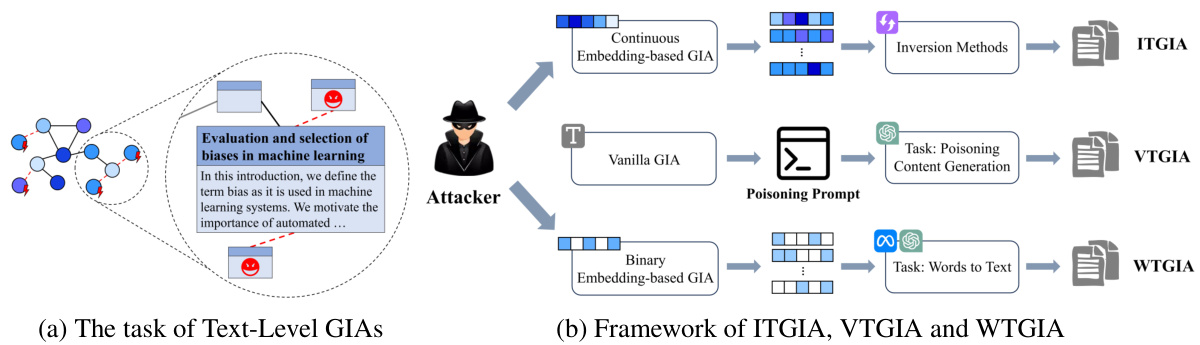
This figure illustrates the process of text-level graph injection attacks (GIAs). It shows three different attack designs: Vanilla Text-level GIA (VTGIA), Inversion-based Text-level GIA (ITGIA), and Word-frequency-based Text-level GIA (WTGIA). Each design involves injecting textual content into a graph, differing in their approach to generating and injecting the textual content. Panel (a) provides a high-level overview of the process and the challenges involved in the text-level GIA. Panel (b) shows detailed frameworks for each attack, highlighting their mechanisms, data flows, and the types of embeddings used.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-level GIAs (ITGIAs). It shows the average accuracy of the GCN on clean data and when attacked using five different ITGIA variants. The ‘Avg. cos’ column indicates the average cosine similarity between the embeddings of the inverted text generated by each ITGIA variant and the original text embeddings. This measure reflects how well the ITGIA is able to recover the original text from the embeddings. The ‘Best Emb.’ column shows the best attack performance achieved at the embedding level, serving as a baseline for comparing text-level attack effectiveness.
In-depth insights#
Word-Level GIA#
Word-level graph injection attacks (GIAs) represent a novel and realistic threat to graph neural networks (GNNs). Unlike embedding-level attacks that manipulate node embeddings, word-level GIAs directly inject malicious textual content, making them harder to detect and more aligned with real-world scenarios. This approach introduces interpretability as a crucial factor, influencing the attack’s success. Word-frequency-based attacks show a good balance between effectiveness and interpretability, leveraging the simplicity of binary word embeddings to ensure that injected text is both meaningful and easily generated by large language models (LLMs). However, the study reveals that defenses can be easily strengthened with customized text embedding methods or LLM-based predictors, suggesting that word-level GIAs face significant challenges in practice. Further research is needed to explore these new attack vectors and develop effective defense mechanisms against this emerging threat.
Interpretability Tradeoffs#
The concept of ‘Interpretability Tradeoffs’ in adversarial attacks against graph neural networks (GNNs) reveals a crucial tension. Higher attack effectiveness often comes at the cost of reduced interpretability, making it challenging to understand why an attack is successful. This is especially true for text-level attacks, where injecting meaningful, human-understandable text is more difficult than injecting carefully crafted embeddings. While methods like those leveraging Large Language Models (LLMs) can generate interpretable text, this often sacrifices attack potency. Conversely, simpler, embedding-based methods might achieve stronger attacks, but the injected data lacks clear semantic meaning, hindering analysis and defense development. The ideal approach would balance both interpretability and effectiveness, allowing for both robust attacks and a better understanding of GNN vulnerabilities, yet this remains a significant research challenge.
LLM-based Defenses#
The emergence of LLMs has revolutionized various NLP tasks, and their application to bolstering graph neural network (GNN) security against injection attacks represents a significant advancement. LLM-based defenses offer a unique advantage by directly processing textual node features, bypassing the need for handcrafted feature engineering often employed in traditional defense mechanisms. LLMs can learn complex relationships between text and graph structure to identify malicious injections. However, this approach introduces new challenges: interpretability and explainability of LLM-based decisions remain critical concerns. Furthermore, the reliance on LLMs shifts the defense strategy towards a black-box model, requiring careful evaluation to ensure robustness against adversarial attacks targeting the LLMs themselves. The performance of LLM-based defenses is highly dependent on the quality and size of the training data used to fine-tune the LLM; therefore, ongoing research is essential to create effective and generalizable solutions for securing GNNs in various applications.
Transferability Limits#
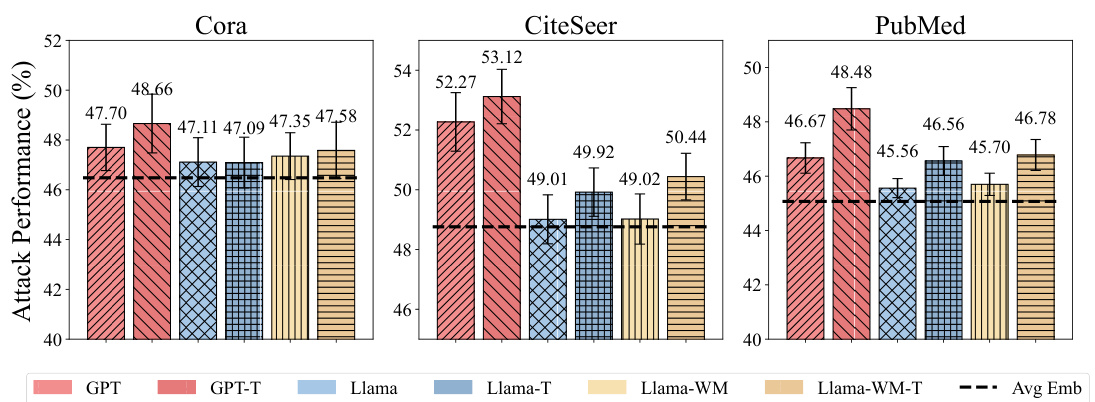
The concept of “Transferability Limits” in the context of adversarial attacks on text-attributed graphs (TAGs) is crucial. Transferability refers to how well an attack designed for one text embedding method (e.g., word frequency) performs when the defender uses a different method (e.g., a pre-trained language model). High transferability is undesirable for defenders, as it means attacks are robust to changes in defense strategies. This paper highlights that text-level attacks often suffer from low transferability. Attacks relying on easily interpretable textual features like word frequency perform better with similar defense embedding methods, but their effectiveness significantly decreases when the defense uses sophisticated methods like PLMs. This is because PLMs capture nuanced semantic information which the simpler methods miss, making the injected text easily detectable. The interpretability-performance trade-off creates a limitation on the practicality of simple text-level attacks as defenders easily adapt and counter such attacks by leveraging more sophisticated techniques. Future work should focus on designing attacks with higher transferability, potentially by using methods which avoid easily identifiable features.
Future Research#
Future research should prioritize enhancing the robustness and generalization of text-level graph injection attacks (GIAs). The current methods struggle with interpretability versus attack effectiveness, and transferability across various embedding techniques remains a significant hurdle. Investigating novel attack strategies that effectively leverage the strengths of large language models (LLMs) while mitigating their limitations is crucial. Furthermore, exploring defensive techniques beyond simple text embedding methods or LLM-based predictors is needed to understand the long-term implications of text-level GIAs. Research into the interaction between text-level attacks and other attack types (e.g., graph modification attacks) could offer valuable insights. Finally, a thorough investigation into the real-world applicability and potential risks of text-level GIAs, including societal impact analysis, is necessary to develop comprehensive mitigation strategies and guide ethical development in this area.
More visual insights#
More on figures
This figure illustrates the framework for text-level Graph Injection Attacks (GIAs). It shows three different attack designs: Vanilla Text-level GIA (VTGIA), Inversion-based Text-level GIA (ITGIA), and Word-frequency-based Text-level GIA (WTGIA). The left panel (a) depicts the task of text-level GIAs, highlighting the injection of raw text into the graph and the challenges involved compared to traditional embedding-based GIAs. The right panel (b) presents the framework for each of the three proposed text-level GIA designs, showing their individual components and the workflow.

This figure illustrates the framework for text-level Graph Injection Attacks (GIAs) and the three attack designs explored in the paper: Vanilla Text-level GIA (VTGIA), Inversion-based Text-level GIA (ITGIA), and Word-frequency-based Text-level GIA (WTGIA). The left panel (a) shows the general task of text-level GIAs, contrasting it with embedding-based GIAs, highlighting the difference of injecting raw text versus node embeddings. The right panel (b) provides a detailed diagram showing how each of the three proposed methods works, including their individual steps and components.
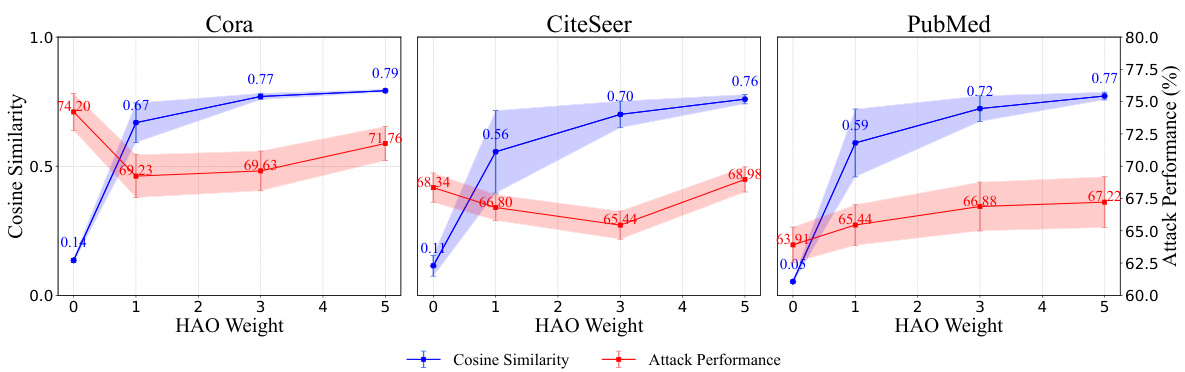
This figure shows how the attack performance of Inversion-based Text-Level GIAs (ITGIAs) changes with different weights of the Harmonious Adversarial Objective (HAO). The x-axis represents the HAO weight, and the y-axis shows the attack performance (lower values indicating better attacks). The figure illustrates that there’s a trade-off between the attack performance and interpretability. Increasing HAO weights improves interpretability but reduces the attack effectiveness, suggesting an optimal balance point needs to be found.
This figure illustrates the framework of the proposed text-level Graph Injection Attacks (GIAs). Panel (a) shows the overall task of text-level GIAs, focusing on injecting raw text into graphs rather than just node embeddings. Panel (b) details the architectures of the three proposed text-level GIA designs: Vanilla Text-level GIA (VTGIA), Inversion-based Text-level GIA (ITGIA), and Word-frequency-based Text-level GIA (WTGIA), highlighting their different approaches to generating and injecting textual content.
This figure illustrates the framework for Text-Level Graph Injection Attacks (GIAs). It shows the three different attack designs explored in the paper: Vanilla Text-level GIA (VTGIA), Inversion-based Text-level GIA (ITGIA), and Word-frequency-based Text-level GIA (WTGIA). The figure highlights the difference between traditional embedding-based GIAs and the proposed text-level GIAs, focusing on the injection of raw text instead of pre-computed embeddings. It also visually represents the process of generating and injecting the adversarial textual content into the target graph.

This figure illustrates the framework for text-level graph injection attacks (GIAs). It shows three different attack designs: Vanilla Text-level GIA (VTGIA), Inversion-based Text-level GIA (ITGIA), and Word-frequency-based Text-level GIA (WTGIA). The attacker injects textual content into the graph, generating new nodes with attributes derived from this text. The process of text embedding and the effects on the performance of the downstream GNN model are shown. The diagram contrasts the proposed text-level GIA approach with the traditional embedding-level GIA approach, highlighting the advantages of working with raw text data rather than pre-computed embeddings.
More on tables

This table presents the performance of Graph Convolutional Networks (GCNs) when attacked using Vanilla Text-level Graph Injection Attacks (VTGIAs). It shows the attack success rate (lower is better) for three different VTGIA prompt types (Heterophily, Random, Mixing) against a clean GCN baseline. The results are compared to the best-performing embedding-level GIAs, providing a context for evaluating the effectiveness of text-level attacks. The use of GTR (T5-based pretrained transformer) for embedding is consistent across all tests.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs that have undergone Inversion-based Text-Level Graph Injection Attacks (ITGIAs). The results show the average accuracy of the GCNs after the ITGIAs have been applied. The ‘Avg. cos’ column indicates the average cosine similarity between the embeddings of the inverted text (generated from the embeddings injected by the attack) and their original embeddings. This value reflects the similarity between the injected text and the original text at the embedding level, which gives an understanding of how well the attack mimics the original data. The ‘Best Emb.’ column shows the best attack performance that was achieved using traditional embedding-level GIAs (not the text-level GIAs evaluated here), providing a benchmark to compare the performance of the ITGIAs.

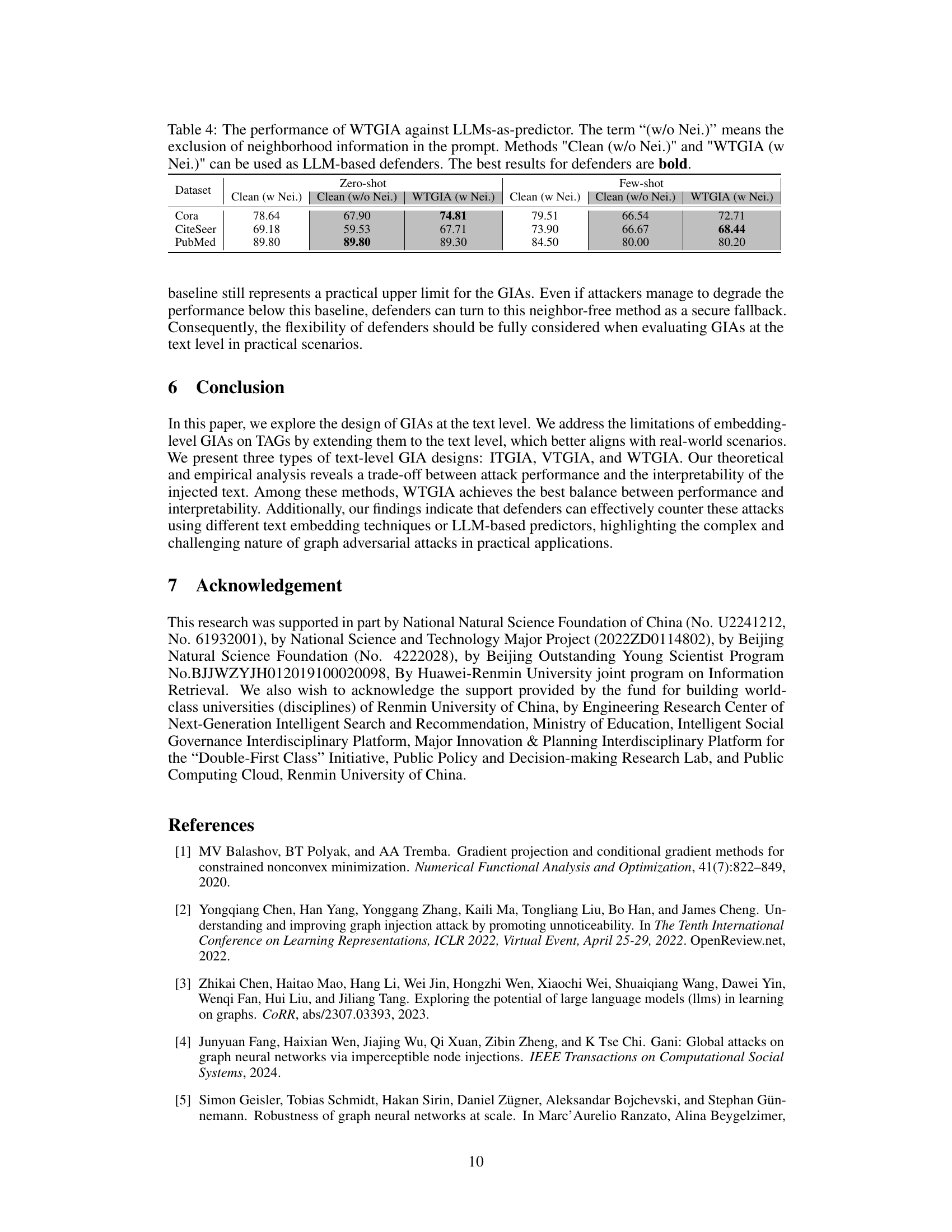
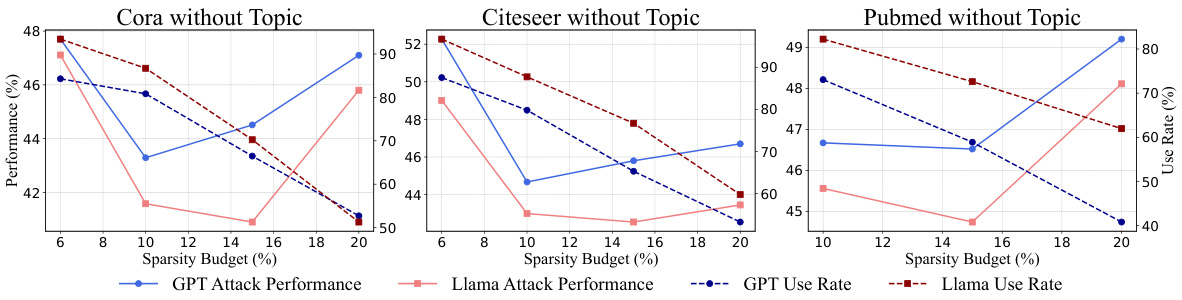
This table presents the performance comparison between different models in node classification tasks using LLMs as predictors with or without neighborhood information. It showcases the effectiveness of WTGIA (Word-frequency-based Text-level GIA) attacks against LLMs in a zero-shot and few-shot learning settings on three different datasets: Cora, CiteSeer, and PubMed. The results highlight the impact of incorporating neighborhood information and the performance of LLMs as defenses against text-level graph injection attacks.

This table presents the statistics of five datasets used in the paper’s experiments: Cora, CiteSeer, PubMed, ogbn-arxiv, and Reddit. For each dataset, it provides the number of nodes, the number of undirected edges, the number of classes, the average node degree, and the average and maximum sparsity of the bag-of-words (BoW) embeddings of the textual features. The sparsity values reflect the percentage of non-zero elements in the BoW vectors, indicating the density of textual features per node.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-Level Graph Injection Attacks (ITGIAs). It shows the accuracy of GCNs after ITGIA attacks using different strategies (SeqGIA, MetaGIA, TDGIA, ATDGIA, AGIA). The average cosine similarity between inverted text embeddings and their original embeddings is also reported to evaluate the quality of text inversion. The ‘Best Emb.’ column shows the best attack performance achieved at the embedding level, serving as a comparison baseline for text-level attacks.

This table shows the attack budgets used in the experiments for five different datasets. For each dataset, the number of injected nodes, the maximum degree of the injected nodes, the percentage of injected nodes relative to the total number of nodes, and the percentage of injected edges relative to the total number of edges are presented. These budgets represent the constraints under which the graph injection attacks were performed.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs injected with Inversion-based Text-level GIAs (ITGIAs). It shows the average accuracy of the GCNs on three datasets (Cora, CiteSeer, PubMed) under different ITGIA variants and compares the performance against the best results achievable by traditional embedding-level GIAs. The average cosine similarity between the inverted text embeddings and original embeddings is also provided, indicating the interpretability of the generated text. Lower accuracy values represent stronger attack performance.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs that have undergone Inversion-based Text-level GIAs (ITGIAs). It shows the average accuracy of the GCNs on clean graphs and graphs attacked using five different ITGIA variants. The ‘Avg. cos’ column indicates the average cosine similarity between the embeddings of the text generated from the inverted embeddings and their original counterparts. The ‘Best Emb.’ column shows the best attack performance achieved at the embedding level (without text inversion). The results are presented for three datasets: Cora, CiteSeer, and PubMed, and whether or not the Harmonious Adversarial Objective (HAO) was used.

This table shows the performance of Graph Convolutional Networks (GCNs) on various datasets when attacked using Inversion-based Text-Level GIAs (ITGIAs). It compares the performance of GCNs against five different ITGIA variants and measures the average cosine similarity between the original embeddings and those obtained after text inversion. This similarity serves as an indicator of the interpretability of the attack. The table also provides a baseline performance measure representing the best achievable attack success at the embedding level.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-level GIAs (ITGIAs). It shows the accuracy of the GCNs on various datasets (Cora, CiteSeer, PubMed) when attacked with different ITGIA variants (SeqGIA, MetaGIA, TDGIA, ATDGIA, AGIA). The average cosine similarity between the inverted text embeddings and the original embeddings is also provided, along with the best embedding-level attack performance as a benchmark. The table highlights the trade-off between the effectiveness of text-level attacks and their interpretability, with lower accuracy indicating a stronger attack.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-level GIAs (ITGIAs). It shows the accuracy of GCNs on three datasets (Cora, CiteSeer, and PubMed) when attacked using five different ITGIA variants. The average cosine similarity between the original embeddings and the embeddings generated by inverting text from the ITGIAs is also provided, illustrating the loss of information during the inversion process. This table helps assess the effectiveness of ITGIAs compared to the best-performing embedding-level GIAs.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs that have been attacked using Inversion-based Text-level Graph Injection Attacks (ITGIAs). The table shows the average accuracy of the GCN on clean graphs and graphs modified by five different ITGIA variants. It also includes the average cosine similarity between the embeddings of the inverted text and the original embeddings, providing insights into the interpretability of the attacks. The ‘Best Emb.’ column provides a comparison to the best-performing embedding-level attacks. The results indicate that ITGIAs, while effective at the embedding level, perform poorly at the text level due to challenges in converting embeddings back into meaningful and coherent text.
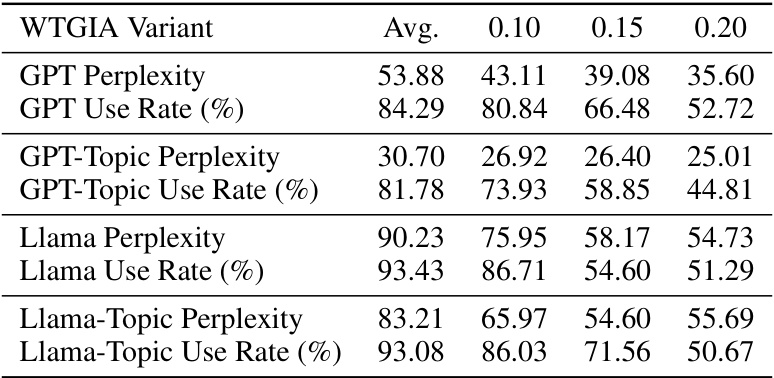
This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs that have undergone Inversion-based Text-Level Graph Injection Attacks (ITGIAs). The table shows the average accuracy of the GCN on clean (unattacked) graphs and on graphs modified by five different ITGIA variants. The average cosine similarity between the original and inverted text embeddings is also shown. This metric helps understand the interpretability of the generated text from the inverted embeddings. Finally, the ‘Best Emb.’ column shows the best attack performance at the embedding level for comparison.

This table shows the performance of Graph Convolutional Networks (GCNs) on graphs that have been attacked using Inversion-based Text-Level GIAs (ITGIAs). The table compares the performance of GCNs on clean graphs to those attacked with five different ITGIA variants. The ‘Avg. cos’ column shows the average cosine similarity between the embeddings of the generated text and the original embeddings. This indicates how well the generated text matches the original in terms of embedding space, which is relevant to the attack’s success. The ‘Best Emb.’ column shows the best attack performance achieved using embedding-level GIAs for comparison, indicating the gap between the effectiveness of the embedding and text-level attacks. Overall, the table demonstrates the tradeoff between attack effectiveness and text interpretability in ITGIAs.
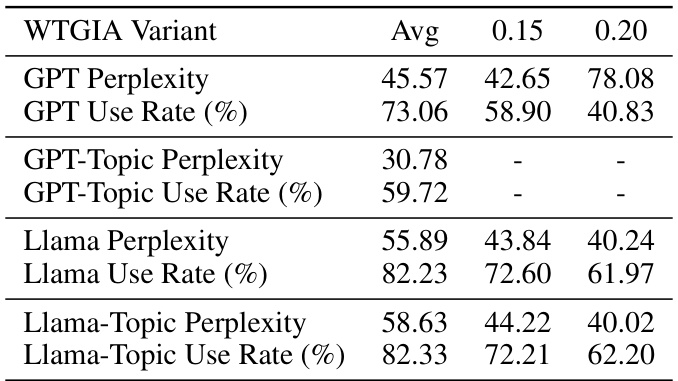
This table shows the performance of Graph Convolutional Networks (GCNs) on graphs attacked using Inversion-based Text-level GIAs (ITGIAs). It compares the average accuracy of the GCN against five different ITGIA variants, using GTR embeddings for the raw text. The average cosine similarity between the original and inverted text embeddings are shown to illustrate the loss of interpretability during the text inversion process. Finally, the table also displays the best attack performance that was achieved using embedding-level GIA methods for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-level GIAs (ITGIAs). It shows the accuracy of the GCNs after the attack, comparing the results of five different ITGIA variants (SeqGIA, MetaGIA, TDGIA, ATDGIA, AGIA). The table also includes the average cosine similarity between the embeddings of the generated text and their original embeddings (Avg. cos), providing insight into the text interpretability, and the best performance achieved at the embedding level (Best Emb.) for comparison. The data is broken down by dataset (Cora, CiteSeer, PubMed).

This table presents the performance of Graph Convolutional Networks (GCNs) when facing Inversion-based Text-Level GIAs (ITGIAs). It shows the accuracy of GCNs on three datasets (Cora, CiteSeer, PubMed) under different attack methods. The average cosine similarity between the inverted text embeddings and their originals is also provided, indicating the quality of the text inversion process. Finally, it compares the performance of ITGIA to the best embedding-level attack.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the accuracy of GCNs after the attacks, and the average cosine similarity between the inverted text embeddings and original embeddings. The ‘Best Emb.’ column indicates the best attack performance achieved using traditional embedding-level GIAs, providing a comparison to the performance of text-level attacks.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs that have been attacked using Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the accuracy of the GCNs on various datasets after ITGIA attacks with different configurations. The ‘Avg. cos’ column shows the average cosine similarity between the inverted text embeddings and the original embeddings, indicating the quality of text reconstruction from embeddings. The ‘Best Emb.’ column indicates the best attack performance achieved by embedding-level GIAs.

This table presents the performance of Graph Convolutional Networks (GCNs) on various datasets (Cora, CiteSeer, PubMed) when attacked using Inversion-based Text-level GIAs (ITGIAs). It shows the average accuracy of GCNs on clean graphs and graphs attacked using five different ITGIA variants, along with the average cosine similarity between the inverted text embeddings and original embeddings. The ‘Best Emb.’ column indicates the best attack performance achievable at the embedding level for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) when facing Inversion-based Text-Level GIAs (ITGIAs). It shows the accuracy of the GCN on various datasets (Cora, CiteSeer, PubMed) under different attack strategies. The average cosine similarity between the inverted text embeddings and their originals is provided, indicating the success rate of the text inversion. The table also compares the ITGIA’s performance to the best-performing embedding-level attacks for context.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-Level GIAs (ITGIAs). It shows the attack success rate (lower is better, indicating stronger attack) for five different ITGIA variants against GCNs. The average cosine similarity between the embeddings of inverted text and the original embeddings is also reported, offering insights into the interpretability of the attacks. The ‘Best Emb.’ column shows the best attack performance achieved at the embedding level, providing a benchmark comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the accuracy of GCNs on three benchmark datasets (Cora, CiteSeer, and PubMed) under various ITGIA attack strategies. The average cosine similarity between the inverted text embeddings and their original embeddings is included, indicating the degree of preservation of information during the text inversion process. The table also compares the attack performance of ITGIA with the best-performing embedding-level attack on each dataset, highlighting the relative effectiveness of the proposed text-level attack.

This table presents the performance of Graph Convolutional Networks (GCNs) when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the attack success rate (percentage decrease in GCN accuracy) for different ITGIA variants (SeqGIA, MetaGIA, TDGIA, ATDGIA, AGIA). The average cosine similarity between the inverted text embeddings and their original embeddings is also provided, indicating the degree of information loss during the text inversion process. Finally, it compares the performance of ITGIAs with the best results achieved by traditional embedding-level GIAs.

This table shows the performance of Graph Convolutional Networks (GCNs) on graphs that have been attacked using Inversion-based Text-level GIAs (ITGIAs). The table compares the performance of GCNs on clean graphs versus graphs with injected nodes, where the injected nodes’ text features were created by inverting embeddings (using the Vec2Text method). The average cosine similarity between the inverted text embeddings and the original embeddings is also shown, reflecting the quality of the text inversion process. The ‘Best Emb.’ column provides the best attack performance obtained using existing embedding-level GIAs for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-Level GIAs (ITGIAs). It shows the accuracy of GCNs on three datasets (Cora, CiteSeer, PubMed) when attacked using five different ITGIA variants. The average cosine similarity between the embeddings of the inverted text and the original embeddings is also given, indicating the level of interpretability. The ‘Best Emb.’ column provides the best attack performance achieved by any of the embedding-level GIA methods, offering a comparison to the ITGIA approach.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-Level GIAs (ITGIAs). The raw text data is embedded using the GTR method before being input to the GCN. The table shows the average cosine similarity between the inverted text embeddings and their original embeddings for five different ITGIA variants. It also compares the performance to the best-performing embedding-level attack, indicating the effectiveness and interpretability of the ITGIA attacks.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs that have undergone Inversion-based Text-level GIAs (ITGIAs). The raw text data is embedded using the GTR method before being input to the GCN. The table shows the average cosine similarity between the embeddings of the inverted text and their originals, providing a measure of the attack’s success in maintaining text similarity after the inversion process. The ‘Best Emb.’ column indicates the best attack performance achieved by five different ITGIA variants at the embedding level for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). The attack performance is measured by the average accuracy of the GCN after the ITGIA injection. The table shows the results for three different datasets (Cora, CiteSeer, and PubMed) and includes the average cosine similarity between the inverted text embeddings and their original embeddings, providing an insight into the attack’s interpretability. The ‘Best Emb.’ column provides the attack performance achieved by the best-performing embedding-level GIA as a benchmark for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs that have been attacked using Inversion-based Text-level Graph Injection Attacks (ITGIAs). The table shows the average accuracy of the GCN on clean data, and then under several variations of the ITGIA, each of which generates text from embeddings. The ‘Avg. cos’ column shows how similar the embeddings of the generated text are to the original embeddings, indicating whether the generated text is meaningful. The ‘Best Emb.’ column gives the best attack performance achieved by traditional embedding-level GIAs for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-level GIAs (ITGIAs). The raw text data is embedded using the GTR method before being input to the GCN. The table compares the average cosine similarity between the inverted text embeddings and their original counterparts across five different ITGIA variants. It also shows the best attack performance achieved at the embedding level for comparison.

This table shows the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs that have been attacked using Inversion-based Text-level GIAs (ITGIAs). The table compares the accuracy of GCNs on clean graphs versus graphs modified by five different ITGIA variants. The ‘Avg. cos’ column shows the average cosine similarity between the embeddings of the inverted text produced by the ITGIAs and the original embeddings, giving an indication of how interpretable the generated text is. The ‘Best Emb.’ column shows the best attack performance achieved at the embedding level (without text-based injection) for comparison purposes.

This table presents the performance of Graph Convolutional Networks (GCNs) on various graph datasets when subjected to Inversion-based Text-Level GIAs (ITGIAs). It compares the attack success rate against several baseline attack methods at both the text and embedding levels. The average cosine similarity between the original embeddings and the embeddings generated from the inverted text provides insights into the quality of the inversion process.

This table presents the performance of Graph Convolutional Networks (GCNs) when attacked using Inversion-based Text-Level GIAs (ITGIAs). It shows the average accuracy of the GCNs on three datasets (Cora, CiteSeer, PubMed) after injecting nodes with text generated by inverting embeddings. The average cosine similarity between the original embeddings and the inverted text embeddings is also provided, which reflects the interpretability of the generated text. The table also indicates the best performance achieved by embedding-level GIAs for comparison.
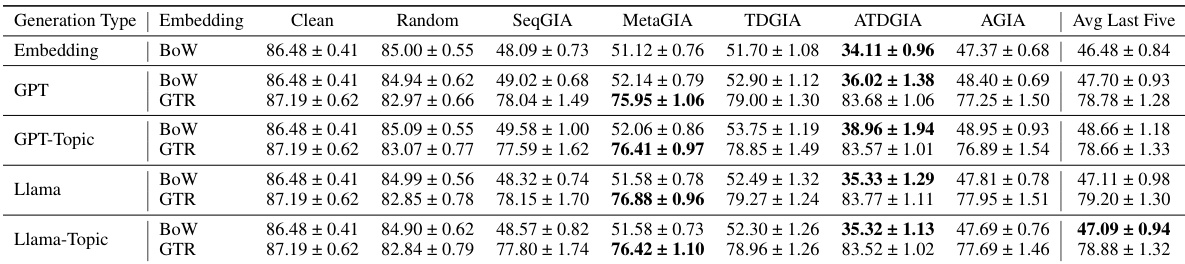
This table presents the performance of Graph Convolutional Networks (GCNs) on graphs subjected to Inversion-based Text-level GIAs (ITGIAs). It shows the accuracy of the GCN on clean data and when attacked using different variations of ITGIA, where the injected text is generated via an inversion of embeddings. The average cosine similarity between the inverted text embeddings and the original embeddings is also provided, along with the best attack performance achieved at the embedding level for comparison.
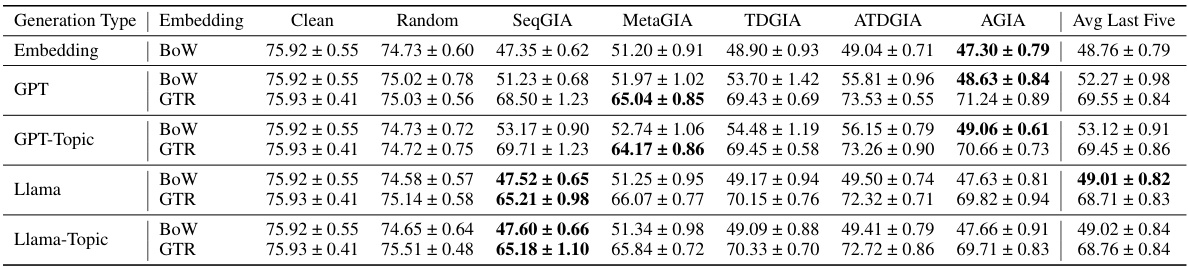
This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs (TAGs) when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the average accuracy of the GCN on the clean graph and graphs attacked using five different ITGIA variants (SeqGIA, MetaGIA, TDGIA, ATDGIA, AGIA). The table also includes the average cosine similarity between the inverted text embeddings and the original embeddings, reflecting the interpretability of the attack, and a comparison to the best-performing embedding-level attack.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs injected with Inversion-based Text-Level GIAs (ITGIAs). It shows the accuracy of GCNs after applying five different ITGIA variants, comparing results using both Bag-of-Words (BoW) and GTR embeddings. The ‘Avg. cos’ column indicates the average cosine similarity between the inverted text embeddings and their originals, measuring the quality of the inversion process. ‘Best Emb.’ provides the best attack performance achieved at the embedding level (without text inversion), serving as a baseline for comparison.
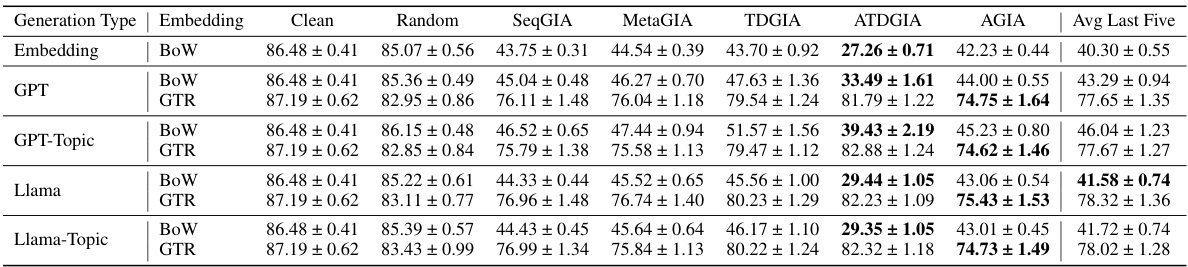
This table presents the performance of Graph Convolutional Networks (GCNs) on text-attributed graphs (TAGs) when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the average attack success rate (lower is better, indicating stronger attack) for various ITGIA methods, comparing their performance against a baseline (clean) GCN. The average cosine similarity between the original and inverted text embeddings is also provided, measuring the quality of text reconstruction from embeddings. The ‘Best Emb.’ column highlights the best results achieved using existing embedding-level GIAs for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) on graphs attacked using Inversion-based Text-level GIAs (ITGIAs). It shows the average accuracy of the GCN on several datasets (Cora, CiteSeer, PubMed) after ITGIA attacks with different strategies. The table also provides the average cosine similarity between the inverted text embeddings and the original embeddings, as well as a comparison to the best embedding-level attack performance for each dataset.
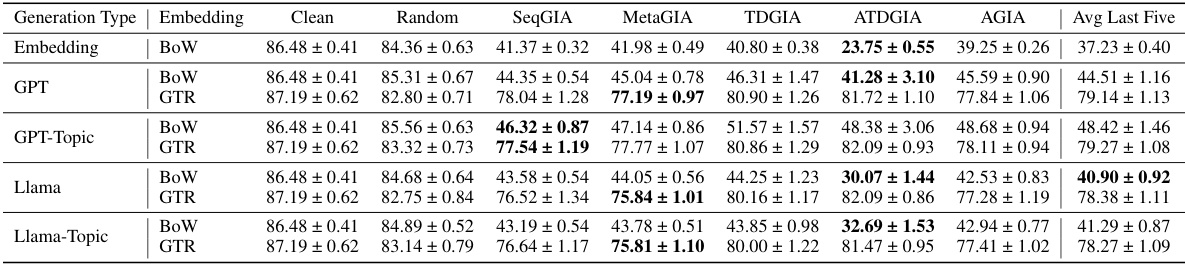
This table presents the performance of Graph Convolutional Networks (GCNs) when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the accuracy of GCNs on three datasets (Cora, CiteSeer, PubMed) under different attack strategies. The average cosine similarity between the inverted text embeddings and their original embeddings are also reported, indicating the quality of the text inversion process. Finally, it includes a comparison with the best embedding-level attack for each dataset.

This table presents the performance of Graph Convolutional Networks (GCNs) on various datasets when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the average accuracy of the GCNs on clean graphs and graphs attacked using five different ITGIA variants. The table also includes the average cosine similarity between the embeddings of the inverted text (generated by the attack) and their corresponding original embeddings, providing a measure of the attack’s ability to generate realistic-looking text. Finally, it lists the best attack performance (lowest accuracy) achieved at the embedding level, serving as a baseline for comparison.

This table presents the performance of Graph Convolutional Networks (GCNs) when subjected to Inversion-based Text-level Graph Injection Attacks (ITGIAs). It shows the accuracy of the GCN on various datasets (Cora, CiteSeer, PubMed) under different ITGIA variants. The ‘Avg. cos’ column indicates the average cosine similarity between the inverted text embeddings and their original counterparts, reflecting the quality of text inversion. The ‘Best Emb.’ column provides the best attack performance achievable using embedding-level methods for comparison.
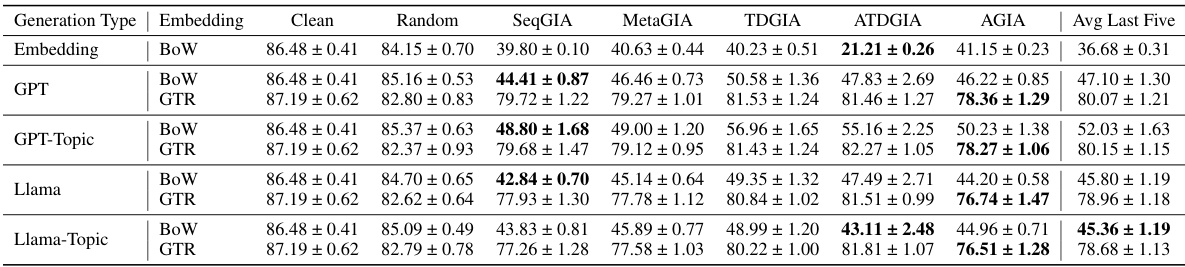
This table presents the performance of Graph Convolutional Networks (GCNs) on various datasets (Cora, CiteSeer, PubMed) when subjected to Inversion-based Text-Level Graph Injection Attacks (ITGIAs). It shows the average accuracy of the GCNs on clean graphs and graphs attacked by different ITGIA variants. The ‘Avg. cos’ column indicates the average cosine similarity between the embeddings of the inverted text produced by ITGIA and their corresponding original embeddings. This measures the interpretability of the generated text. The ‘Best Emb.’ column shows the best attack performance achieved at the embedding level (without text inversion) for comparison.
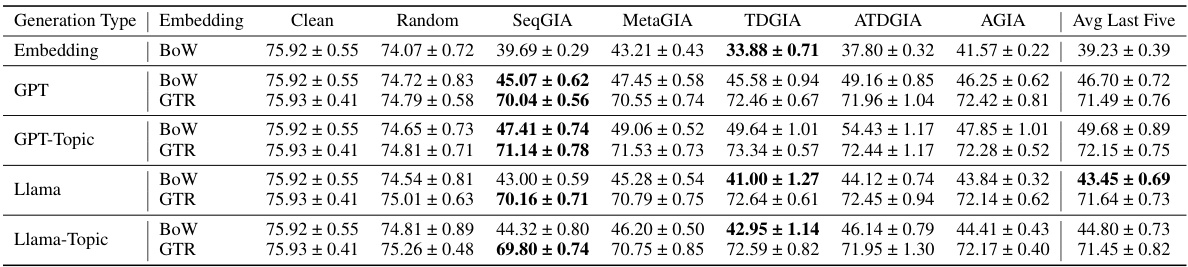
This table shows the performance of Graph Convolutional Networks (GCNs) on graphs attacked using Inversion-based Text-level GIAs (ITGIAs). The raw text is embedded using the GTR method before being fed to the GCN. The table compares the performance of GCNs against five different ITGIA variants, along with a measure of cosine similarity between the inverted text embeddings and their original embeddings. The ‘Best Emb.’ column indicates the best attack performance achieved at the embedding level (as a baseline for comparison with the text-level attack results).

This table presents the performance of Graph Convolutional Networks (GCNs) when subjected to Inversion-based Text-level GIAs (ITGIAs). It shows the accuracy of the GCN on various datasets (Cora, CiteSeer, PubMed) under different ITGIA attack variants. The ‘Avg. cos’ column indicates the average cosine similarity between the embeddings of the text generated from the inverted embeddings and the original embeddings. The ‘Best Emb.’ column provides the best attack performance achieved at the embedding level for comparison.
Full paper#