↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current group recommendation methods suffer from two major drawbacks: they rely on pre-defined, fixed user groups unsuitable for dynamic real-world applications, and they require expensive, supervised training with user-group and group-item labels. These limitations hinder the practical applicability and scalability of group recommendation systems. This leads to a need for more efficient and adaptable solutions.
The proposed Identify Then Recommend (ITR) framework addresses these issues by introducing an unsupervised approach. ITR first identifies user groups without pre-defined numbers using adaptive density estimation and a heuristic merge-and-split strategy. Then, it uses self-supervised learning with two pre-text tasks—pull-and-repulsion and pseudo group recommendation—to optimize user-group distribution and improve recommendations. Experimental results demonstrate ITR’s effectiveness and superiority over existing methods on user and group recommendation tasks, further validated by its successful deployment in a large-scale industrial recommender system.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of existing supervised group recommendation models by proposing an unsupervised framework. This addresses the high cost and impracticality of obtaining user-group labels in real-world scenarios. The proposed method’s success in industrial deployment further highlights its practical significance and opens avenues for research in unsupervised group recommendation and related self-supervised learning techniques.
Visual Insights#

This figure presents the results of a motivation experiment conducted on two datasets, Mafengwo and CAMRa2011, to demonstrate the impact of group annotations on group recommendation and user recommendation performance. The experiment compares the performance of ConsRec, both with and without group annotations, across four metrics (HR@5, HR@10, NDCG@5, NDCG@10) for both group and user recommendation tasks. The results highlight the significant performance drop in group recommendation tasks when group annotations are removed, underscoring the critical issue of reliance on such annotations in existing group recommendation models.

This table presents the performance comparison of various group recommendation methods on two datasets (Mafengwo and CAMRa2011). The metrics used are Hit Ratio@5 (HR@5), HR@10, Normalized Discounted Cumulative Gain@5 (NDCG@5), NDCG@10, and the average of these four metrics. The table highlights the best performing method (bold and underlined) and indicates whether a method uses group annotations (using a superscript *) or is unsupervised (°). It shows how the proposed unsupervised method (ITR°) performs compared to existing state-of-the-art supervised and unsupervised methods.
In-depth insights#
Unsupervised GR#
Unsupervised group recommendation (GR) tackles a crucial limitation of existing GR methods: reliance on labeled data. Traditional GR approaches require extensive annotation of user-group memberships and group-item interactions, which is costly and time-consuming. Unsupervised GR aims to address this by learning group structures and making recommendations without explicit supervision. This often involves employing clustering techniques to group users based on their preferences or behavior, followed by recommendation generation tailored to these automatically discovered groups. The challenge lies in effectively capturing underlying user similarities and preferences in an unsupervised manner to create meaningful and accurate groups, ensuring the recommendations are relevant and well-suited to each group’s collective interests. Successful unsupervised GR methods must strike a balance between the accuracy of group discovery and the quality of subsequent recommendations, ideally offering performance comparable to their supervised counterparts.
ITR Framework#
The ITR framework, as described, is an unsupervised group recommendation system addressing limitations of existing supervised methods. Its core innovation lies in its two-stage process: first, it identifies user groups adaptively without predefined group numbers, leveraging density estimation and a merge-and-split algorithm; second, it performs self-supervised group recommendation using pull-and-repulsion and pseudo-group recommendation pretext tasks. This unsupervised nature is crucial for real-world applications where obtaining user-group labels is expensive and dynamic group distributions are common. The adaptive group discovery and self-supervised learning phases allow ITR to handle dynamic user behavior and avoid the limitations of fixed group sizes. The framework’s effectiveness is demonstrated through improved NDCG@5 scores in experiments on various benchmark datasets and industrial applications. However, the heuristic nature of the merge-and-split strategy and the design of the pretext tasks warrant further investigation for robustness and generalizability. Further analysis of the computational complexity and scalability in larger datasets is also needed for a complete evaluation of the framework’s practical applicability.
Adaptive Density#
The concept of “Adaptive Density” in the context of unsupervised group recommendation is intriguing. It suggests a dynamic approach to identifying group centers, moving away from pre-defined or fixed group structures. The method likely estimates density based on the proximity of data points (users), with higher densities indicating potential group centers. This adaptive approach is crucial because real-world user group distributions are unlikely to be static and require a flexible algorithm to react to this dynamic environment. A heuristic merge-and-split strategy, likely guided by density estimations, would refine initial group assignments. This involves combining nearby dense regions and splitting less-dense areas, leading to more accurate and representative user clusters. The self-adjusting nature of the density estimation and the iterative merge/split algorithm is key to handling the dynamic nature of group formation and evolution.
Pre-text Tasks#
Pre-text tasks are crucial in self-supervised learning, and their design significantly impacts model performance. In the context of unsupervised group recommendation, pre-text tasks serve to guide the model towards learning meaningful representations of users and groups without explicit labels. A common approach involves designing tasks that encourage users within the same group to have similar representations (pull), while simultaneously separating users from different groups (repulsion). This pull-and-repulsion strategy helps the model learn the underlying group structure. Another effective pre-text task could involve generating pseudo-labels for group-item interactions. This involves predicting interactions based on the learned representations, thus providing a form of self-supervision. The success of these tasks hinges on their ability to capture relevant information while avoiding trivial solutions or overfitting. Careful design and evaluation are vital to ensure the pre-text tasks effectively guide the learning process, ultimately improving the quality of group recommendations. The choice of pre-text tasks should be driven by the specific characteristics of the data and the desired outcome. In this context, the balance between complexity, effectiveness, and computational cost is a critical consideration.
Future of ITR#
The future of ITR (Identify Then Recommend) hinges on addressing its current limitations and exploring new avenues for improvement. Extending ITR to handle dynamic group structures is crucial, potentially through online clustering algorithms that adapt in real-time to evolving user interactions. Incorporating diverse data sources beyond user-item interactions, such as social networks, contextual information, and user demographics, could greatly enhance group identification and recommendation accuracy. Developing more sophisticated self-supervised learning techniques is another key area; exploring advanced contrastive learning methods or incorporating reinforcement learning could boost performance. Finally, rigorous evaluation on larger, more diverse datasets and industrial applications will be vital to establish ITR’s scalability and real-world impact. Addressing these aspects would solidify ITR’s position as a robust and versatile framework for unsupervised group recommendation.
More visual insights#
More on tables
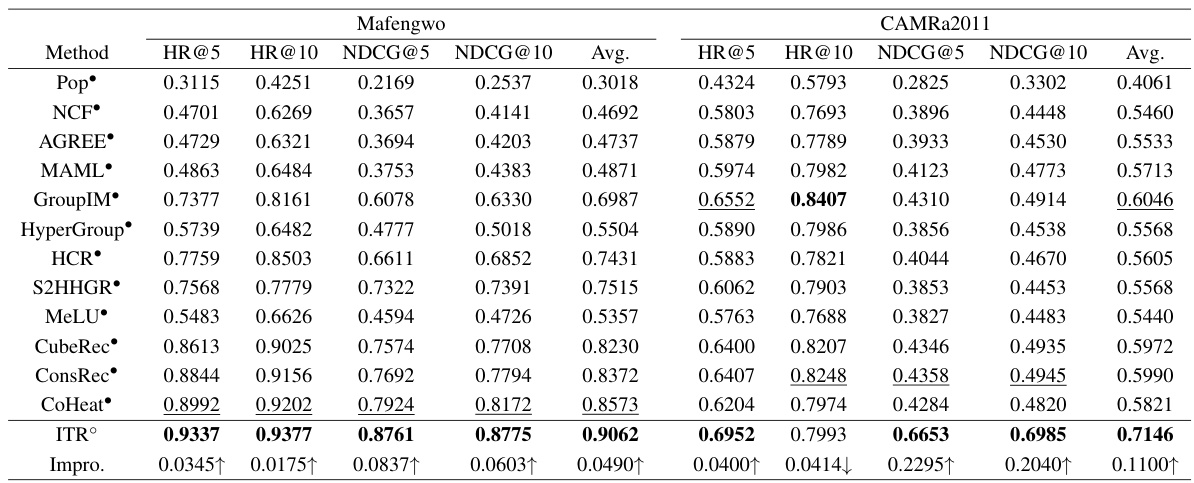
This table presents the performance of various group recommendation methods on two datasets (Mafengwo and CAMRa2011) in terms of HR@5, HR@10, NDCG@5, and NDCG@10. The results highlight the performance difference between models that utilize group annotations and unsupervised models. The ITR model, an unsupervised approach, shows competitive results, particularly on the CAMRa2011 dataset.
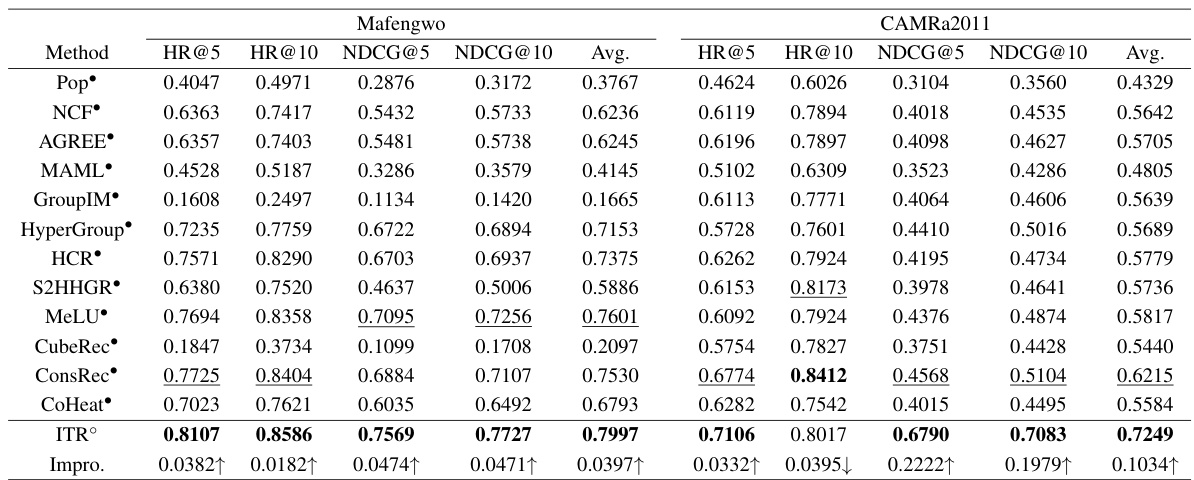
This table presents the performance of various group recommendation models on two datasets (Mafengwo and CAMRa2011). The metrics used are Hit Ratio@5 (HR@5), Hit Ratio@10 (HR@10), Normalized Discounted Cumulative Gain@5 (NDCG@5), and NDCG@10. The table compares supervised and unsupervised models, highlighting the best performing model in each category. The average performance across all metrics is also shown.

This table presents the performance of various group recommendation methods on two datasets (Mafengwo and CAMRa2011). The metrics used are HR@5, HR@10, NDCG@5, and NDCG@10. The table shows the performance of both supervised (using group annotations) and unsupervised methods. The best and second-best results are highlighted for each metric and dataset.

This table presents the results of user recommendation experiments on two datasets (Mafengwo and CAMRa2011). It compares the performance of the proposed ITR model against twelve state-of-the-art methods across four metrics: HR@5, HR@10, NDCG@5, and NDCG@10. The table highlights the best and second-best performing models for each metric and dataset. The notation indicates methods that utilize group annotations, while ° denotes unsupervised models. The results demonstrate ITR’s performance in the user recommendation task, even without leveraging group information.

This table presents the performance of various group recommendation methods on two datasets (Mafengwo and CAMRa2011) in terms of HR@5, HR@10, NDCG@5, and NDCG@10. It compares the performance of the proposed unsupervised ITR model against twelve state-of-the-art methods, highlighting the superior performance of ITR, especially when group annotations are unavailable.

This table presents the results of A/B testing conducted on a real-time industrial recommender system. It compares the performance of a baseline model (‘Base’) against the same model enhanced with the proposed ITR framework (‘Base+ITR’). The metrics used measure click-through rates (uvctr, pvctr) and trade metrics (uv, pv). Percentage improvements are shown for the ‘Base+ITR’ model compared to the baseline.
Full paper#



















