TL;DR#
Training large language models (LLMs) usually relies on massive datasets, but ensuring data quality, particularly in collaborative settings where data cannot be directly shared, poses a significant challenge. Existing methods either rely on manual filtering (which is expensive) or automated filters that are not effective in complex environments. This limits the scalability and generalizability of collaborative LLM training.
CLUES addresses this challenge by focusing on training dynamics. It uses a novel technique that leverages the impact of individual data points on the training process to select high-quality data. By tracing how the model parameters change due to each training example (measured as per-sample gradients), CLUES provides a data quality score and a global threshold to filter the data collaboratively. Experiments demonstrate notable performance improvements of up to 67.3% across diverse domains (medical, multilingual, and financial), showcasing the effectiveness of the proposed data quality control method for collaborative LLM fine-tuning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and federated learning. It presents a novel solution to the critical problem of data quality control in collaborative LLM training, offering significant performance improvements and enhanced privacy. The proposed method is both effective and efficient, making it highly relevant to current research trends and offering promising avenues for future research in data selection and collaborative training of LLMs.
Visual Insights#
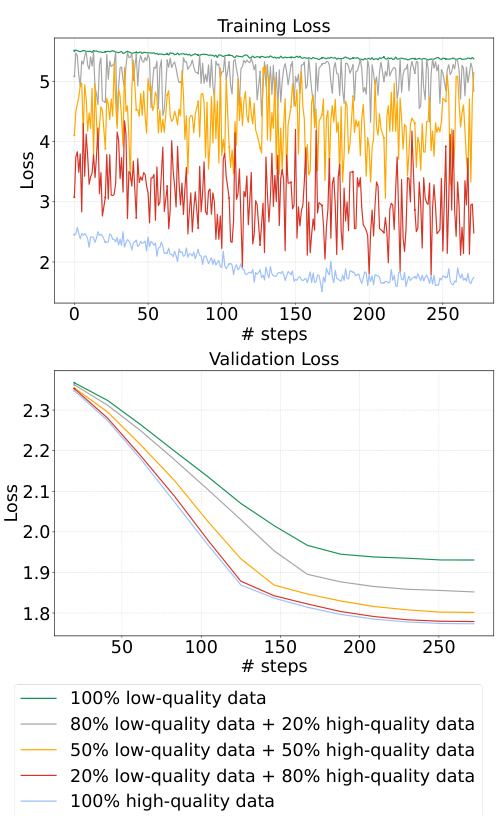
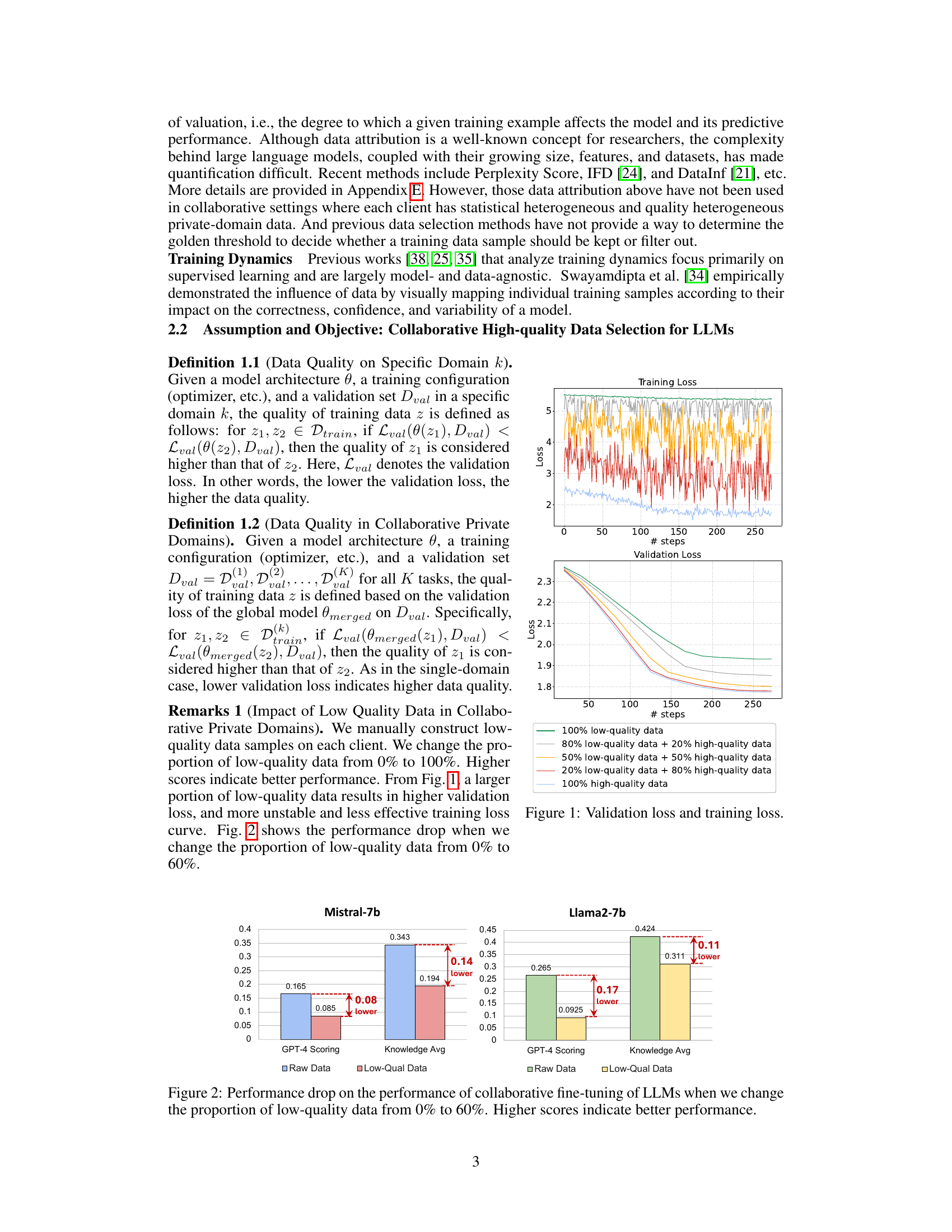
🔼 This figure shows the impact of low-quality data on the training and validation loss during collaborative fine-tuning of LLMs. The x-axis represents the number of training steps, and the y-axis represents the loss. Different lines represent different proportions of low-quality data mixed with high-quality data. As the proportion of low-quality data increases, both the training and validation loss increase, indicating that the presence of low-quality data negatively affects model performance.
read the caption
Figure 1: Validation loss and training loss.
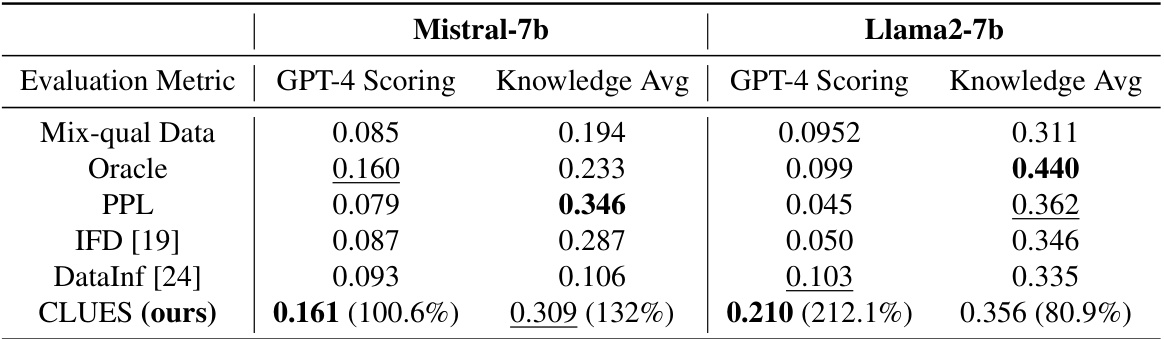
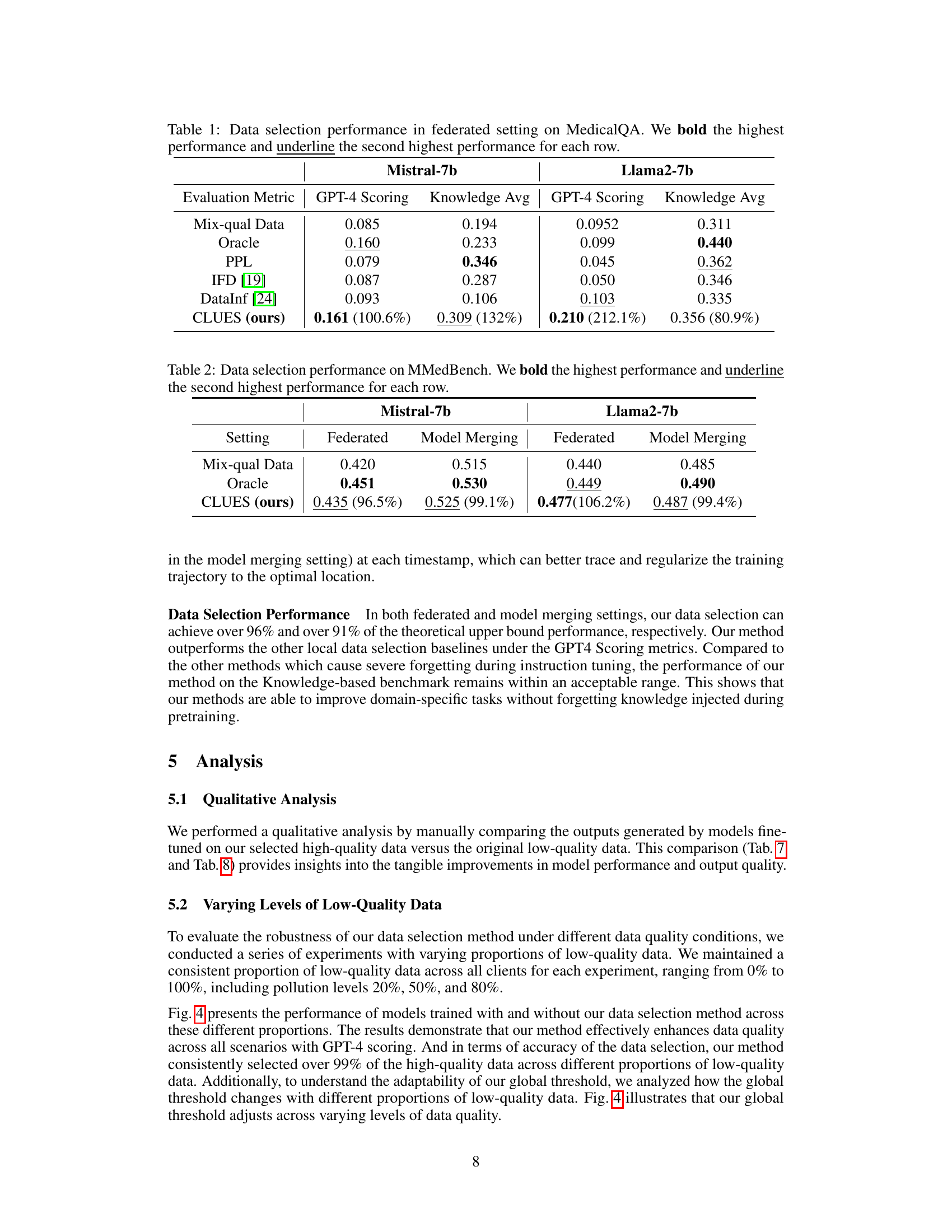
🔼 This table presents the results of data selection methods in a federated learning setting for the Medical QA task. It compares the performance of several methods (Oracle, Perplexity, IFD, DataInf, and CLUES) across two metrics: GPT-4 Scoring and Knowledge Avg, using two different pre-trained models (Mistral-7b and Llama2-7b). The ‘Mix-qual Data’ row shows performance on mixed-quality data, while the ‘Oracle’ row provides an upper bound representing ideal performance with only high-quality data. The numbers in parentheses indicate percentage improvement of CLUES over the Mix-qual Data.
read the caption
Table 1: Data selection performance in federated setting on MedicalQA. We bold the highest performance and underline the second highest performance for each row.
In-depth insights#
CLUES Framework#
The CLUES framework presents a novel approach to collaborative, private-domain high-quality data selection for LLMs. It leverages training dynamics by tracing the influence of each data sample on a shared anchor dataset, thereby identifying high-quality data without direct data sharing. This method addresses the crucial challenge of data heterogeneity and quality discrepancies across private domains in collaborative LLM fine-tuning. A key innovation is the use of per-sample gradients and trace of accumulated inner products to quantify data quality. The framework seamlessly integrates with existing collaborative training paradigms like model merging and federated learning, enhancing scalability and privacy. Experiments across diverse domains (medical, multilingual, financial) demonstrate CLUES’s effectiveness in improving model performance compared to traditional methods, highlighting its potential for practical applications in sensitive data scenarios.
Training Dynamics#
The concept of “Training Dynamics” in the context of large language models (LLMs) is crucial for understanding data quality. Analyzing training dynamics involves observing how the model’s parameters change during training in response to individual data points. This offers insights into the influence each data sample has on the model’s final performance. High-quality data tend to exhibit consistent, predictable training dynamics, while low-quality data can introduce instability or noise. By leveraging this principle, the paper’s method assesses data quality by comparing the training dynamics of individual data samples to a reliable “anchor” dataset. This approach is particularly advantageous in collaborative settings where direct data sharing is restricted, enabling effective data quality control without compromising privacy. The resulting high-quality subset improves the collaborative LLM fine-tuning process significantly, leading to superior model generalization performance across multiple domains.
Data Quality Metrics#
Effective data quality metrics are crucial for evaluating large language models (LLMs). While traditional metrics like perplexity offer a general sense of model performance, they often fall short in capturing nuances specific to LLMs. Therefore, specialized metrics tailored to LLMs’ unique characteristics are essential. These should encompass aspects like instruction-following ability, factual accuracy, and the model’s response coherence and relevance. Furthermore, data quality metrics should be context-aware, recognizing that high-quality data in one domain might not translate to another. Therefore, domain-specific and task-specific metrics should be considered. Finally, robust evaluation methodologies, encompassing aspects such as the development of well-defined benchmarks and evaluation standards, are critical to reliably assess and compare the performance of different LLMs, thereby fostering progress in the field.
Collaborative Tuning#
Collaborative tuning of large language models (LLMs) presents a powerful paradigm for leveraging diverse private datasets without compromising data privacy. This approach allows multiple parties to jointly fine-tune a shared model, benefiting from the collective knowledge embedded in their respective datasets. Key challenges in collaborative tuning include ensuring data quality across heterogeneous sources, addressing data heterogeneity and differences in quality standards, and efficiently aggregating model updates in a privacy-preserving manner. Effective solutions require robust data quality control mechanisms, potentially employing decentralized data selection methods or innovative aggregation techniques to overcome interference between model updates from different clients. The success of collaborative tuning hinges on careful consideration of these challenges, which requires further research and development of efficient and privacy-preserving strategies for data selection and model aggregation. This collaborative approach offers a significant potential for creating more robust and generalizable LLMs that benefit from a wider range of data than would be possible through traditional centralized methods. However, careful attention must be paid to security and privacy, ensuring that data remains private and secure during the entire collaborative process.
Future Work#
The paper’s authors suggest several avenues for future research. Extending the data quality control methods to handle diverse model architectures is crucial, as the current approach assumes a uniform model structure across all collaborating clients. This limitation could hinder broader adoption. Addressing this would involve developing a more generalizable method that can adapt to various architectural designs. Investigating the intrinsic relationship between data selection and model parameters is another promising area. This could lead to a deeper understanding of how data quality affects model behavior and potentially improve the robustness and efficiency of the data selection process. Finally, analyzing the computational efficiency of the proposed algorithm and exploring ways to scale it effectively for larger models and datasets will be important for real-world applications. This involves refining the algorithm or employing more efficient computational methods to handle the high dimensionality of data and model parameters involved in large language model fine-tuning.
More visual insights#
More on figures
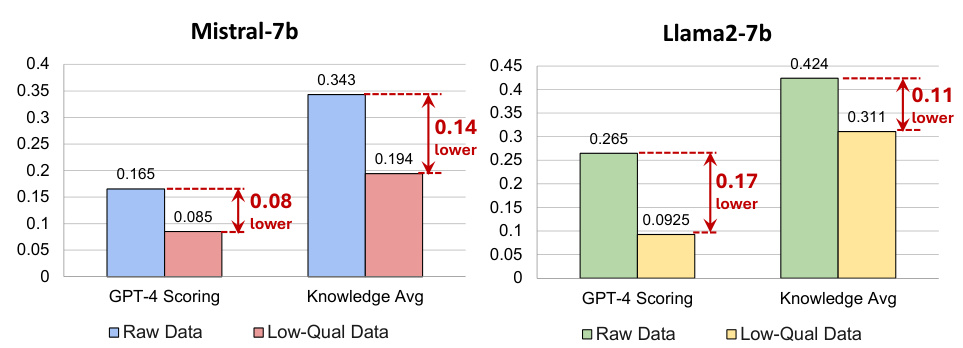
🔼 This figure shows the performance drop when the proportion of low-quality data increases from 0% to 60% during collaborative fine-tuning of LLMs using two different base models (Mistral-7b and Llama2-7b). The performance is measured using GPT-4 scoring and Knowledge Average. The results illustrate a negative correlation between the percentage of low-quality data and model performance, highlighting the importance of high-quality data for effective LLM fine-tuning in collaborative settings.
read the caption
Figure 2: Performance drop on the performance of collaborative fine-tuning of LLMs when we change the proportion of low-quality data from 0% to 60%. Higher scores indicate better performance.
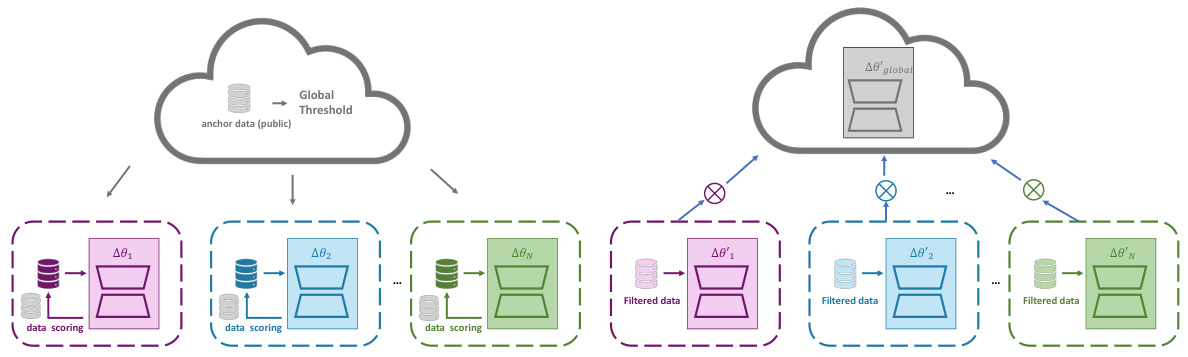
🔼 This figure illustrates the two-phase workflow of the CLUES method. In Step One, each client independently computes a quality score for each data sample using local training and a shared public validation set. These scores are sent to a central server, which uses an ‘anchor’ dataset to determine a global quality threshold. In Step Two, each client filters its data, keeping only the samples above the threshold. Then, collaborative fine-tuning is performed, using a model merging strategy to combine the updated models from each client. This collaborative approach ensures that only high-quality data are used in the training of the global model. Adaptive weights might be used on the server side during merging.
read the caption
Figure 3: Overall workflow diagram consists of two phases: 1) Step One: client-side computes each sample's quality score with scoring functions using the public validation set and global model, then server-side calculates the score of a global threshold by anchor data 2) Step Two: clients filter data according to the global threshold and starts collaborative learning on selected high-quality data with adaptive weights on the model side.
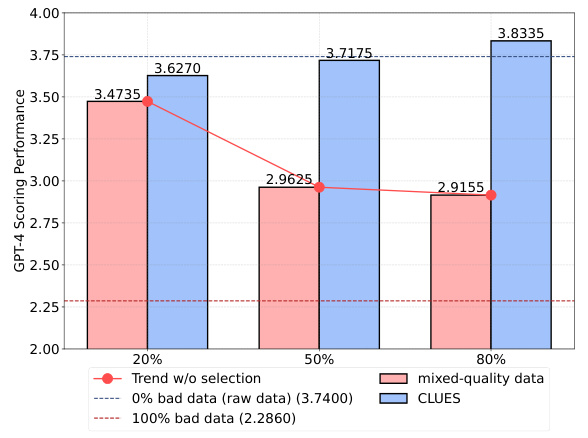
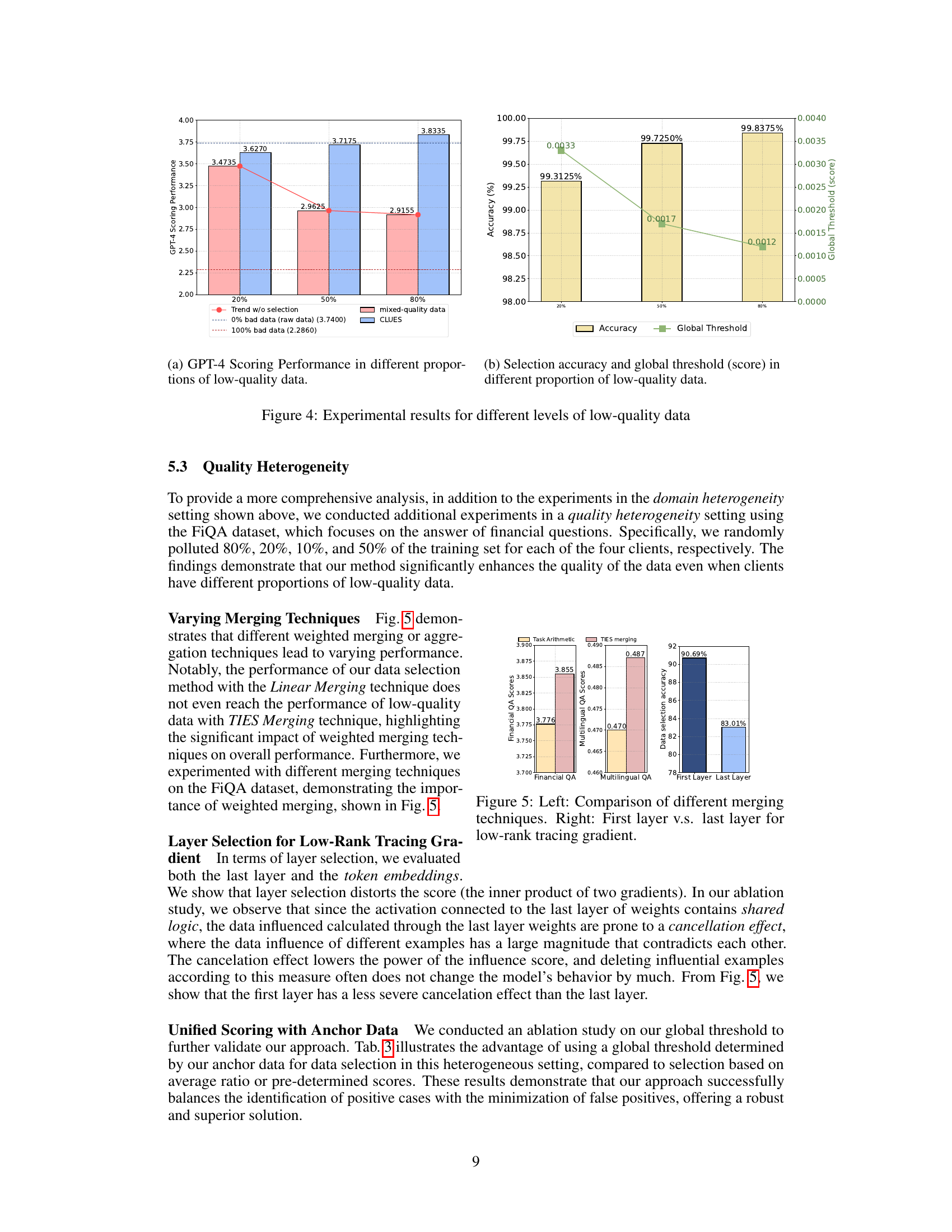
🔼 This figure shows the performance of GPT-4 scoring and the global threshold (score) at different proportions of low-quality data (20%, 50%, 80%). The left graph displays the GPT-4 scoring performance with and without the data selection method applied. The right graph displays the selection accuracy and the global threshold, illustrating how these metrics change with varying levels of low-quality data. The results demonstrate the robustness of the proposed method in handling different proportions of low-quality data.
read the caption
Figure 4: Experimental results for different levels of low-quality data
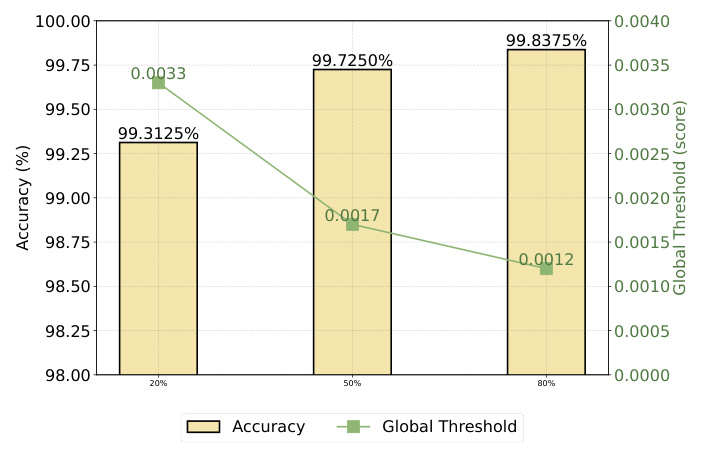
🔼 This figure shows the experimental results obtained with varying proportions of low-quality data. Panel (a) displays the GPT-4 scoring performance, illustrating how performance degrades as the percentage of low-quality data increases. Panel (b) shows the selection accuracy and the global threshold score, demonstrating the robustness of the data selection method even with a significant portion of low-quality data. The global threshold score adjusts dynamically to account for varying levels of data quality.
read the caption
Figure 4: Experimental results for different levels of low-quality data
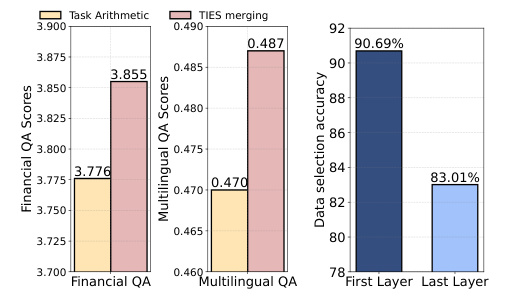
🔼 This figure presents the experimental results showing the impact of varying proportions of low-quality data on model performance. It includes two subfigures: (a) illustrates the GPT-4 scoring performance across different proportions of low-quality data, highlighting the effect of low-quality data on the model’s performance. (b) shows the data selection accuracy and the global threshold score (a unified standard of data quality) for different levels of low-quality data, demonstrating how the global threshold adapts to changing data quality. The results show that the proposed method effectively enhances data quality across all scenarios, even with high proportions of low-quality data.
read the caption
Figure 4: Experimental results for different levels of low-quality data

🔼 This figure illustrates the two-phase workflow of CLUES. In Phase 1 (Local Training for Data Quality Scoring), each client independently scores the quality of their data using a scoring function, leveraging a public validation dataset and a globally shared model. The server aggregates these scores and determines a global quality threshold based on an anchor dataset. In Phase 2 (Collaborative Training with High-Quality Data), clients filter their data based on this threshold, retaining only high-quality samples. They then engage in collaborative training (e.g., via model merging or federated learning), using the selected high-quality data. Adaptive weights can be applied to the model side to further refine performance.
read the caption
Figure 3: Overall workflow diagram consists of two phases: 1) Step One: client-side computes each sample's quality score with scoring functions using the public validation set and global model, then server-side calculates the score of a global threshold by anchor data 2) Step Two: clients filter data according to the global threshold and starts collaborative learning on selected high-quality data with adaptive weights on the model side.
More on tables

🔼 This table presents the results of data selection methods on the MMedBench dataset, comparing the performance of different methods against an oracle (training only on high-quality data) in both federated and model merging settings. The metrics used are GPT-4 scoring and knowledge average, reflecting performance improvements achieved by selecting high-quality data using the proposed CLUES method.
read the caption
Table 2: Data selection performance on MMedBench. We bold the highest performance and underline the second highest performance for each row.

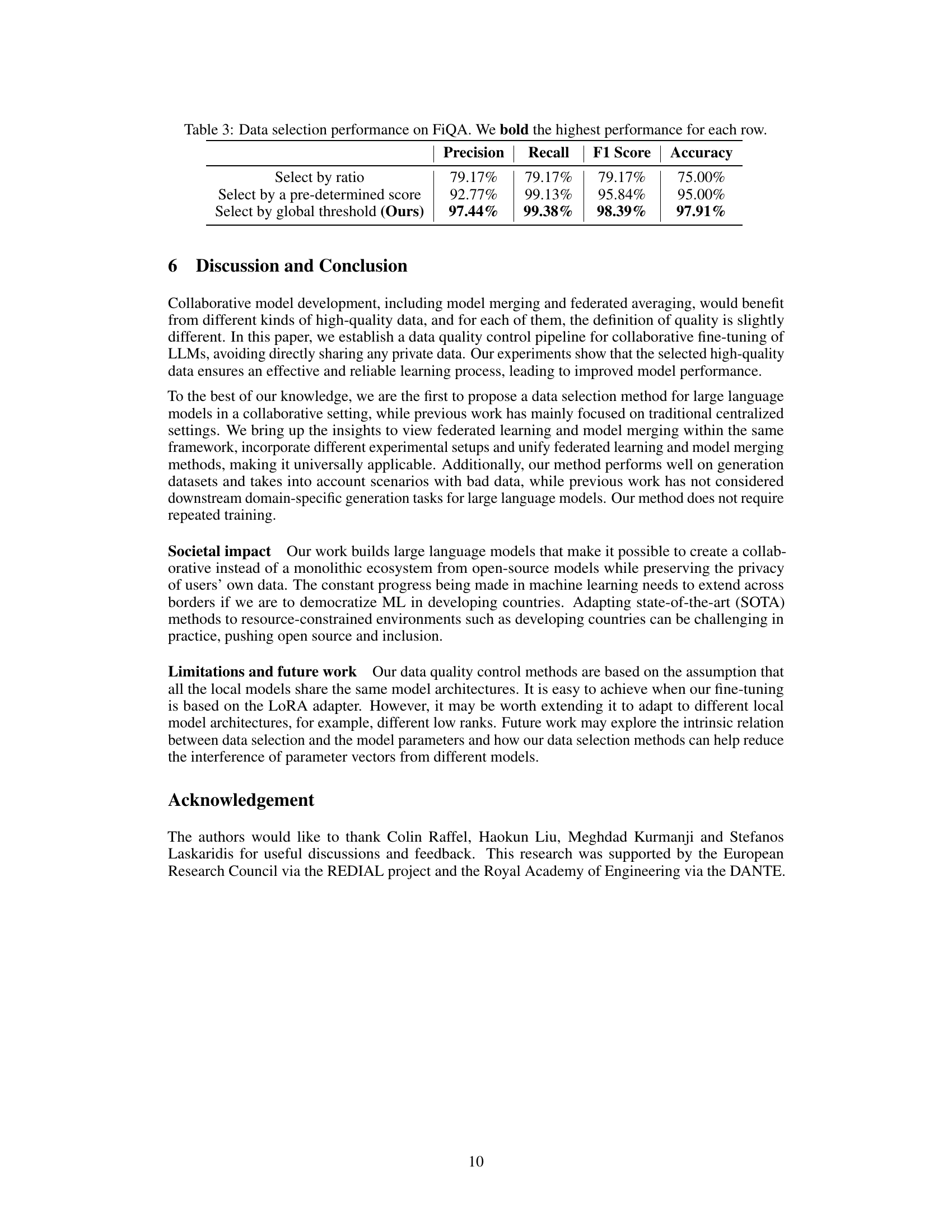
🔼 This table presents the performance of three different data selection methods on the FiQA dataset. The methods are: selecting data by a fixed ratio, selecting data based on a predetermined score, and the authors’ proposed method which uses a global threshold determined by anchor data. The evaluation metrics used are Precision, Recall, F1-Score, and Accuracy. The results demonstrate that the authors’ method significantly outperforms the other methods in terms of all four metrics.
read the caption
Table 3: Data selection performance on FiQA. We bold the highest performance for each row.
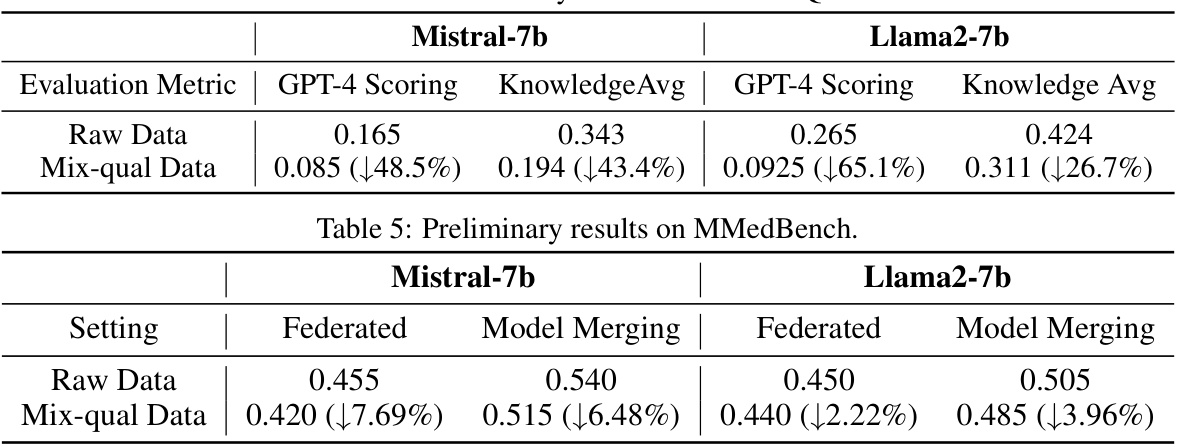
🔼 This table presents the preliminary results of the proposed CLUES method on the MMedBench dataset. It compares the performance of two pre-trained models (Mistral-7b and Llama2-7b) under two conditions: using the original raw data and using data after applying the CLUES data selection method. The performance metrics used are GPT-4 Scoring and KnowledgeAvg. The table shows that the CLUES method significantly improves the performance for both models, especially for the GPT-4 scoring metric.
read the caption
Table 5: Preliminary results on MMedBench.
🔼 This table presents the results of data selection methods in a federated learning setting for the MedicalQA task. It compares several methods (Oracle, PPL, IFD, DataInf, and the proposed CLUES method) in terms of their performance on two metrics: GPT-4 scoring and knowledge average. The best performing method for each metric is bolded, while the second-best is underlined. This helps to illustrate the effectiveness of the CLUES method for selecting high-quality data in this collaborative setting.
read the caption
Table 1: Data selection performance in federated setting on MedicalQA. We bold the highest performance and underline the second highest performance for each row.
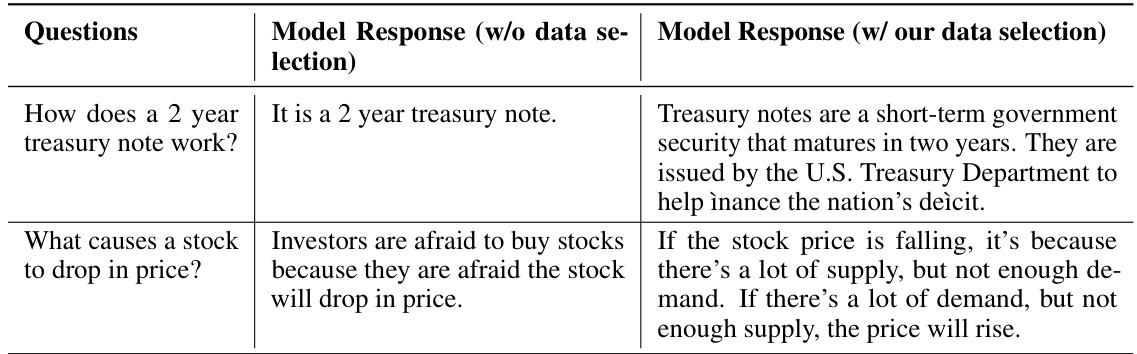
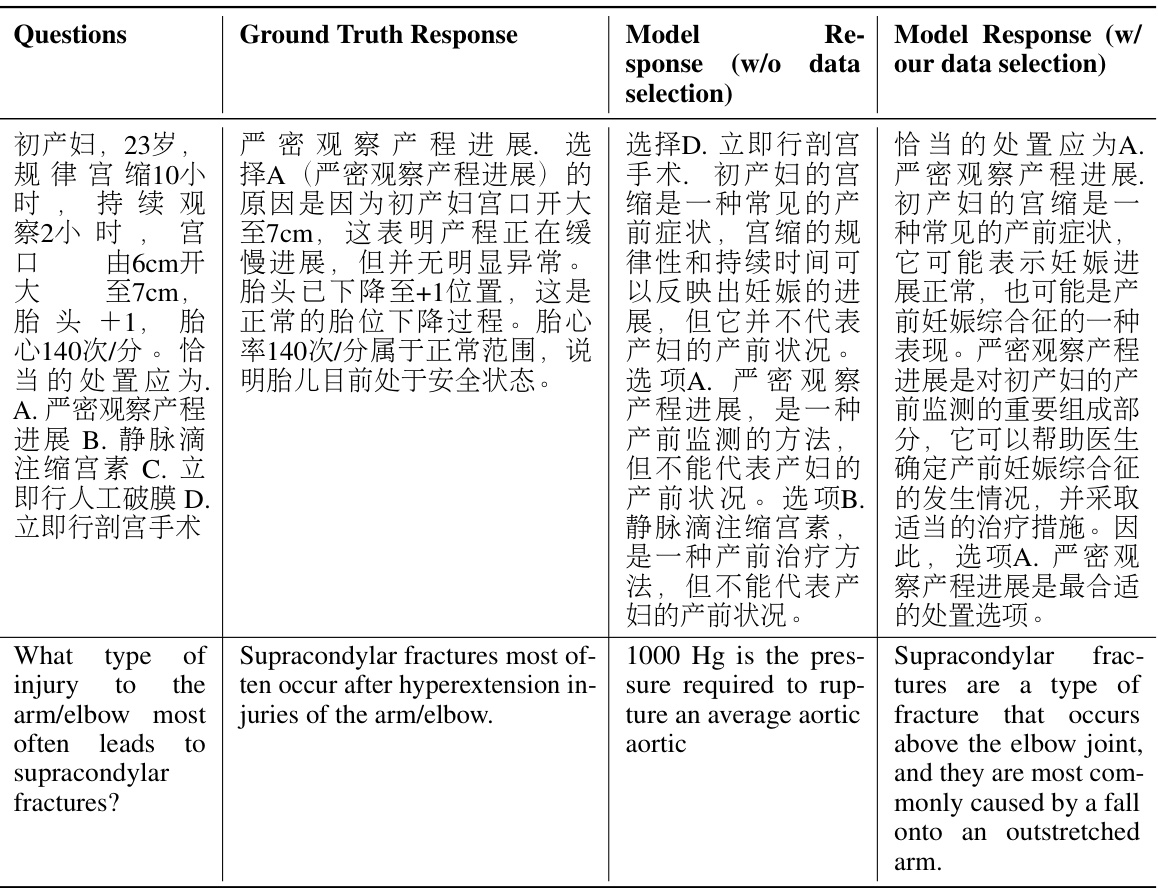
🔼 This table shows examples of questions and the model’s responses with and without the proposed data selection method. The responses highlight the improvements in accuracy and completeness after applying the data selection technique on the Financial Question Answering (FiQA) dataset.
read the caption
Table 8: Samples of the output of merged models on FiQA dataset.
Full paper#