TL;DR#
Real-time Human Activity Recognition (HAR) systems are crucial for applications like healthcare and fitness tracking. However, existing methods often compromise accuracy for speed by using shallow neural networks which only use features from the final layer. This leads to suboptimal performance, especially for activities with similar movement patterns. Current approaches attempting to improve accuracy by increasing the network depth face a significant increase in computational costs, making real-time processing infeasible.
This research introduces CALANet, a novel neural network that solves this accuracy-efficiency tradeoff. CALANet cleverly aggregates features from all layers using a cheap all-layer aggregation (CALA) structure, combining learnable channel-wise transformation matrices (LCTMs) and a scalable layer aggregation pool (SLAP). The authors rigorously prove that CALANet maintains the same computational cost as conventional CNNs, regardless of depth, while demonstrating significant accuracy improvements across seven benchmark datasets. This offers a significant improvement for real-time HAR applications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents CALANet, a novel and efficient neural network architecture for human activity recognition (HAR). It addresses the limitations of existing real-time HAR models by achieving high accuracy while maintaining computational efficiency. This work opens up new avenues for research in efficient deep learning architectures for time series data, and its findings have the potential to significantly advance the development of real-time HAR systems across various applications.
Visual Insights#
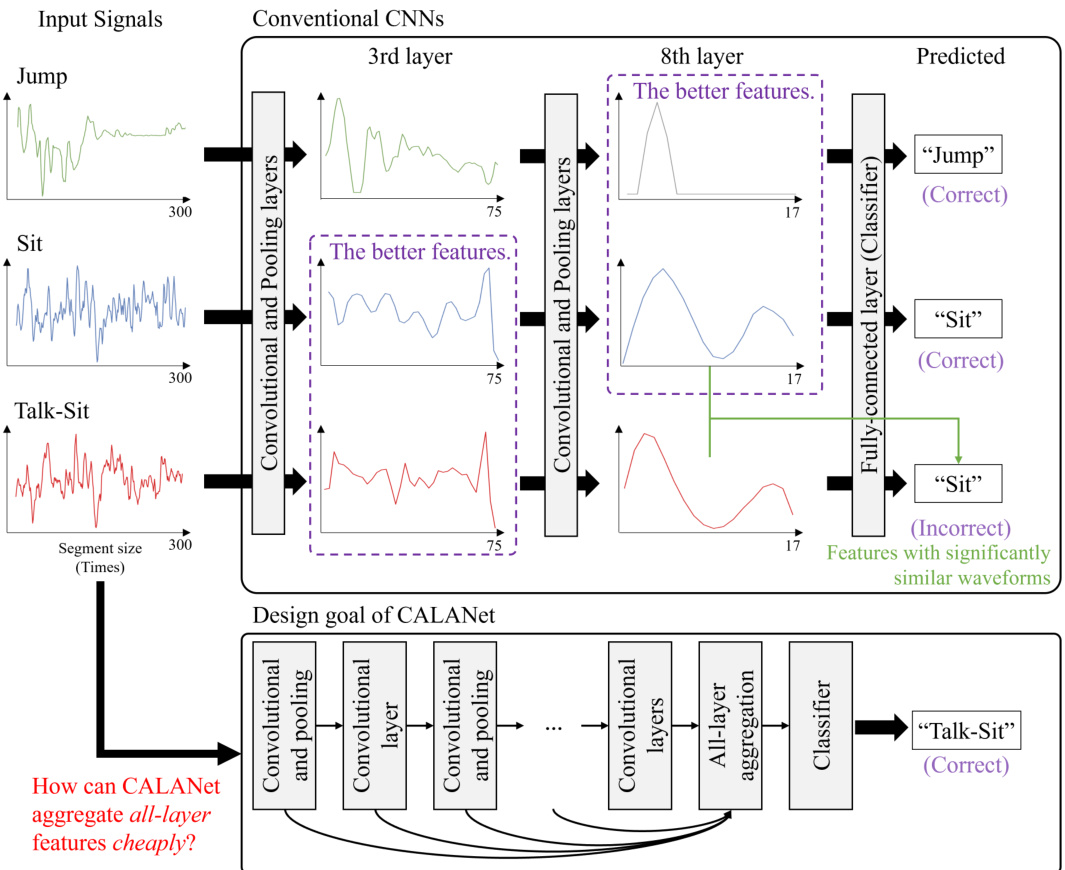
🔼 This figure analyzes feature representations at different layers of a conventional CNN and proposes the design goal of CALANet. It shows that early layers capture detailed signal information, which can be noisy and unhelpful for classification, while later layers provide more semantic but less detailed features, making it difficult to distinguish between similar activities. CALANet aims to leverage features from all layers for improved accuracy without increasing computational cost.
read the caption
Figure 1: Analysis of representations in our experiments on KU-HAR dataset [47]. In a conventional CNN, the classifier predicts activities only using the feature representations at the last layer. Features at the early layer include the detailed information of original signals that may confound the classifier. In comparison, features at the later layer are more semantic, but the features (with more compact and short waveforms) make it challenging to classify activities that share similar semantics. Our goal is to design a CALANet that allows the classifier to use features for all layers while maintaining the inference time of conventional CNNS.
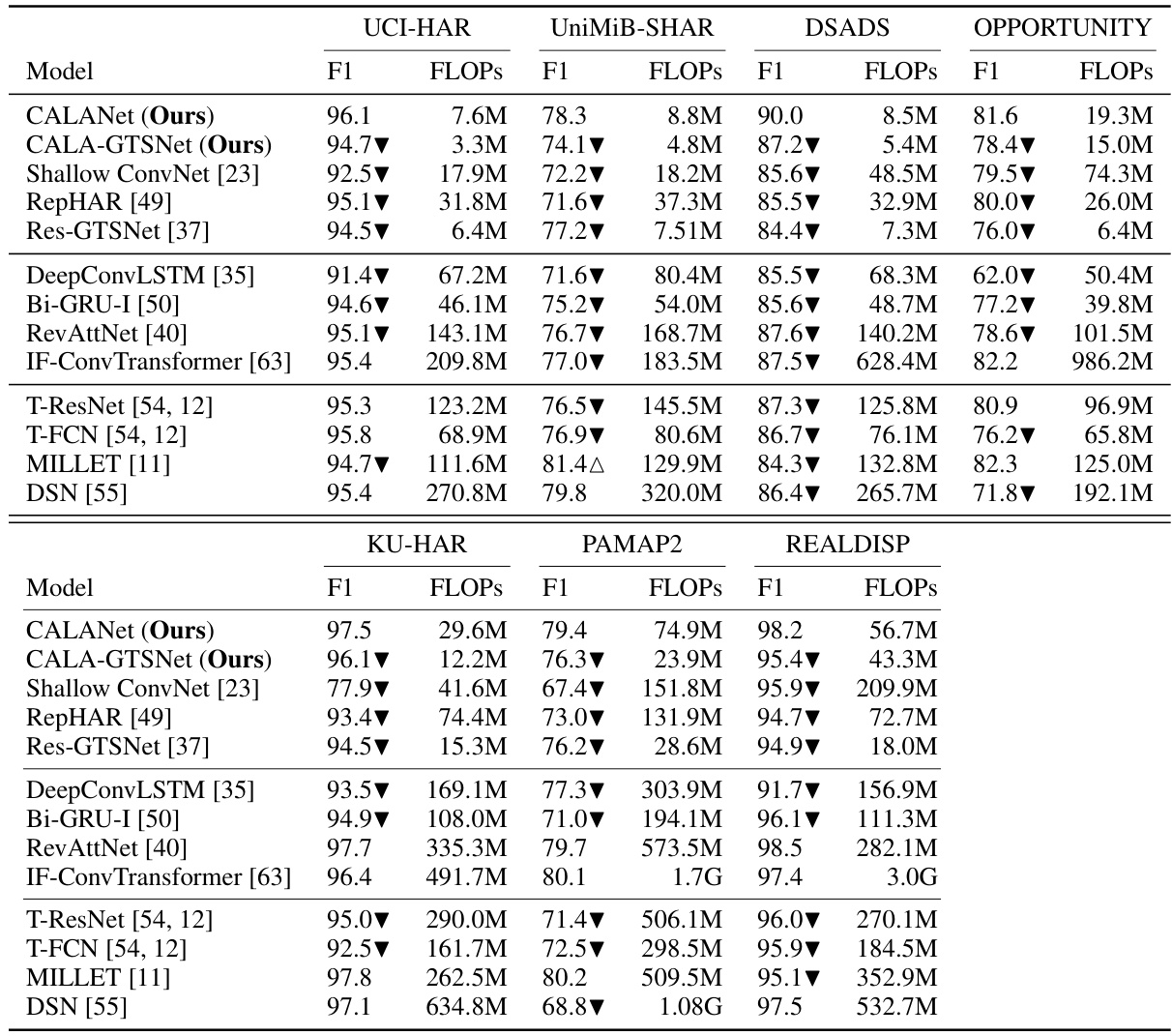
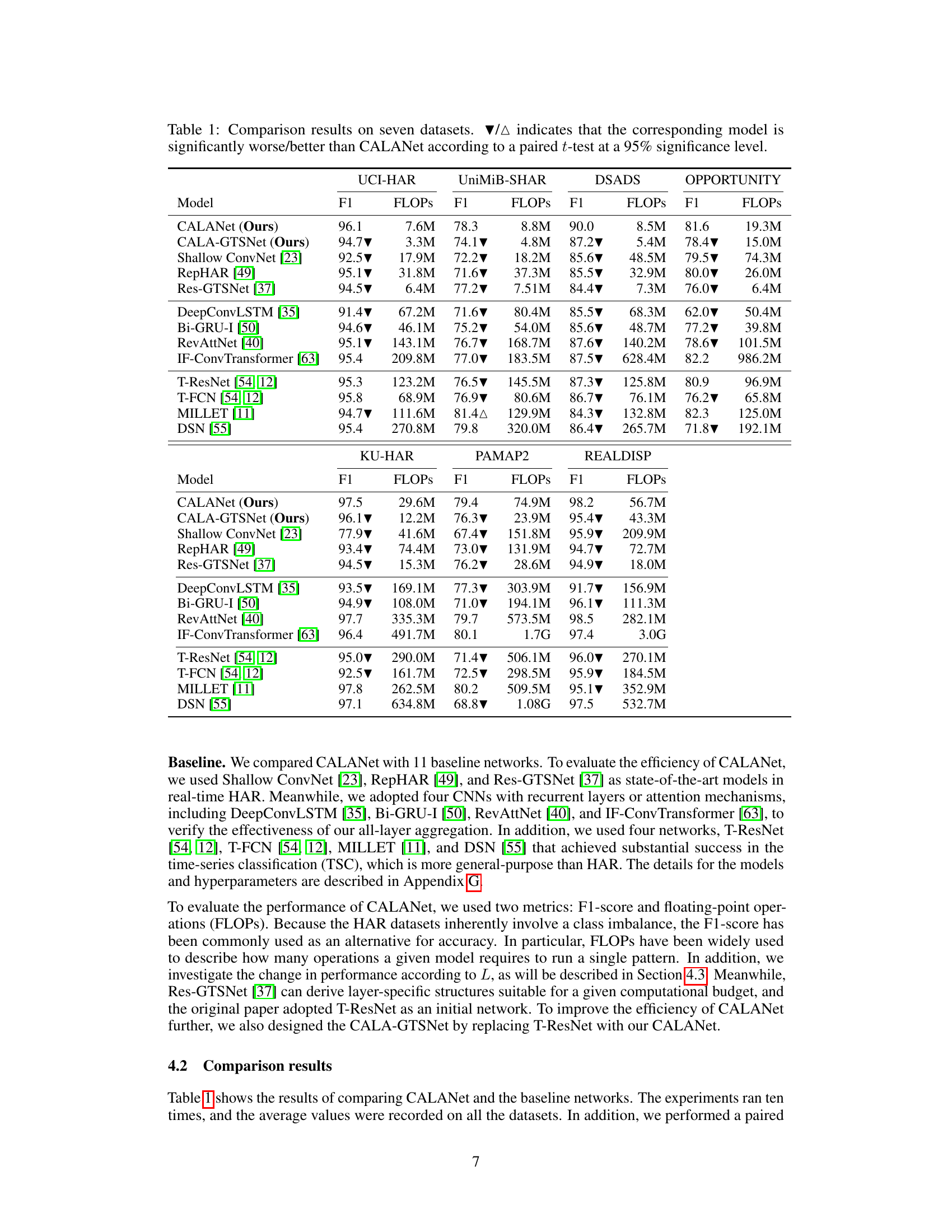
🔼 This table presents a comparison of the performance of CALANet against 11 other state-of-the-art models across seven different datasets. The comparison is based on the F1-score (a metric that balances precision and recall, suitable for imbalanced datasets like those used in human activity recognition) and FLOPS (floating point operations, a measure of computational cost). The table highlights CALANet’s superior performance in terms of F1-score while maintaining competitive computational efficiency. The ▼/▲ symbols indicate statistically significant differences between CALANet and the other models, determined using paired t-tests.
read the caption
Table 1: Comparison results on seven datasets. ▼/▲ indicates that the corresponding model is significantly worse/better than CALANet according to a paired t-test at a 95% significance level.
In-depth insights#
CALANet’s Design#
CALANet’s design cleverly addresses the limitations of existing real-time HAR models by incorporating a cheap all-layer aggregation (CALA) structure. This innovative approach allows the classifier to leverage features from all layers, improving accuracy without significantly increasing computational cost. The key components enabling this are learnable channel-wise transformation matrices (LCTMs), which efficiently reduce the dimensionality of features from each layer, and the scalable layer aggregation pool (SLAP), which allows for flexible stacking of layers without compromising efficiency. By combining these elements, CALANet achieves a superior balance between accuracy and real-time performance, outperforming existing methods on several benchmark datasets. The theoretical proof of computational equivalence to traditional CNNs further solidifies its efficiency. This design showcases a practical and elegant solution to enhance the accuracy of lightweight HAR models, making it suitable for resource-constrained devices.
Aggregation Pool#
The concept of an aggregation pool within the context of a neural network for human activity recognition (HAR) is crucial for effectively combining information from multiple layers of the network. A well-designed aggregation pool can significantly improve the accuracy of the HAR system by allowing the classifier access to a richer set of features that capture both detailed and high-level information from the sensor signals. The challenge lies in creating an efficient aggregation scheme that doesn’t significantly increase computational costs or inference time, which is particularly important for real-time HAR applications. The tradeoff between accuracy and efficiency is a key consideration in designing an aggregation pool. Methods for achieving efficient aggregation might involve techniques such as learnable channel-wise transformation matrices or scalable layer aggregation pools. The selection of the aggregation method will depend heavily on the specific characteristics of the data and the computational resources available. A deeper investigation into the design space of aggregation pools is warranted to further improve performance in HAR.
Efficiency Analysis#
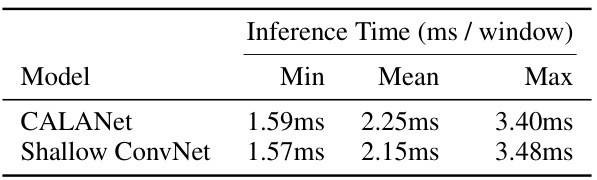
An efficiency analysis of a novel neural network architecture for human activity recognition (HAR) would ideally delve into several key aspects. First, a thorough computational complexity analysis is crucial, comparing the proposed model’s computational cost (FLOPs, memory usage, etc.) to existing state-of-the-art HAR models. This comparison should account for various model parameters and sizes and ideally encompass empirical measurements on representative hardware platforms. Second, the analysis should demonstrate real-time performance through precise inference latency measurements under realistic operational conditions, possibly comparing performance on different hardware to highlight portability and practical applicability. Third, energy efficiency evaluation is important for HAR models, especially when deployed on battery-powered wearable devices. This evaluation would involve measurements of power consumption during inference or training and comparison to other energy-efficient HAR architectures. Finally, the analysis should discuss the trade-offs between accuracy and efficiency, showing how the model balances performance gains with reasonable computational and energy costs. An ideal analysis would present these results in a clear and accessible manner, facilitating direct comparisons and informing future HAR system design.
Real-time HAR#
Real-time Human Activity Recognition (HAR) systems are crucial for applications like healthcare monitoring and fitness tracking, demanding low latency and high accuracy. Many approaches focus on lightweight neural networks, often employing shallow architectures or limiting connections to reduce computational cost. However, this simplification often sacrifices accuracy because the classifier relies solely on features from the final layer. Efficient aggregation of multi-layer features, as explored in CALANet, emerges as a key challenge and opportunity. The optimal balance between model complexity, speed, and performance necessitates innovative techniques. The theoretical cost of multi-layer aggregation must be carefully managed to ensure practical real-time functionality without impacting accuracy. CALANet’s proposed solution of learnable channel-wise transformation matrices and scalable layer aggregation pools demonstrates a promising strategy for achieving this balance.
Future works#
Future research directions stemming from this work on CALANet could explore several promising avenues. Improving computational efficiency remains crucial, especially for deployment on resource-constrained devices. This could involve exploring more efficient aggregation techniques beyond the proposed CALA method, or investigating hardware-accelerated implementations. Addressing class imbalance in HAR datasets is another key area, potentially through data augmentation, cost-sensitive learning, or novel loss functions. Expanding the scope to more complex HAR scenarios, incorporating multiple sensor modalities (e.g., vision, audio), and handling noisy or incomplete data would significantly enhance real-world applicability. Finally, generalizing the CALANet architecture to other time-series classification problems could further broaden its impact across various domains. Investigating adaptive learning strategies to automatically adjust to different data characteristics and computationally efficient alternatives to LCTMs would ensure maintainability and adaptability.
More visual insights#
More on figures
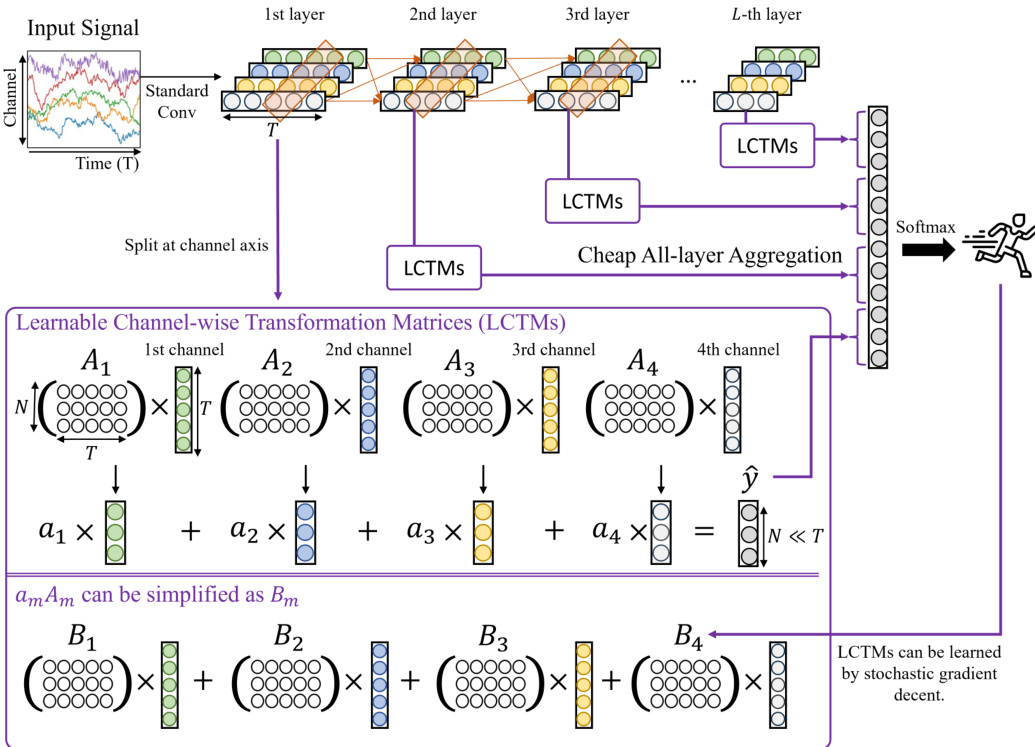
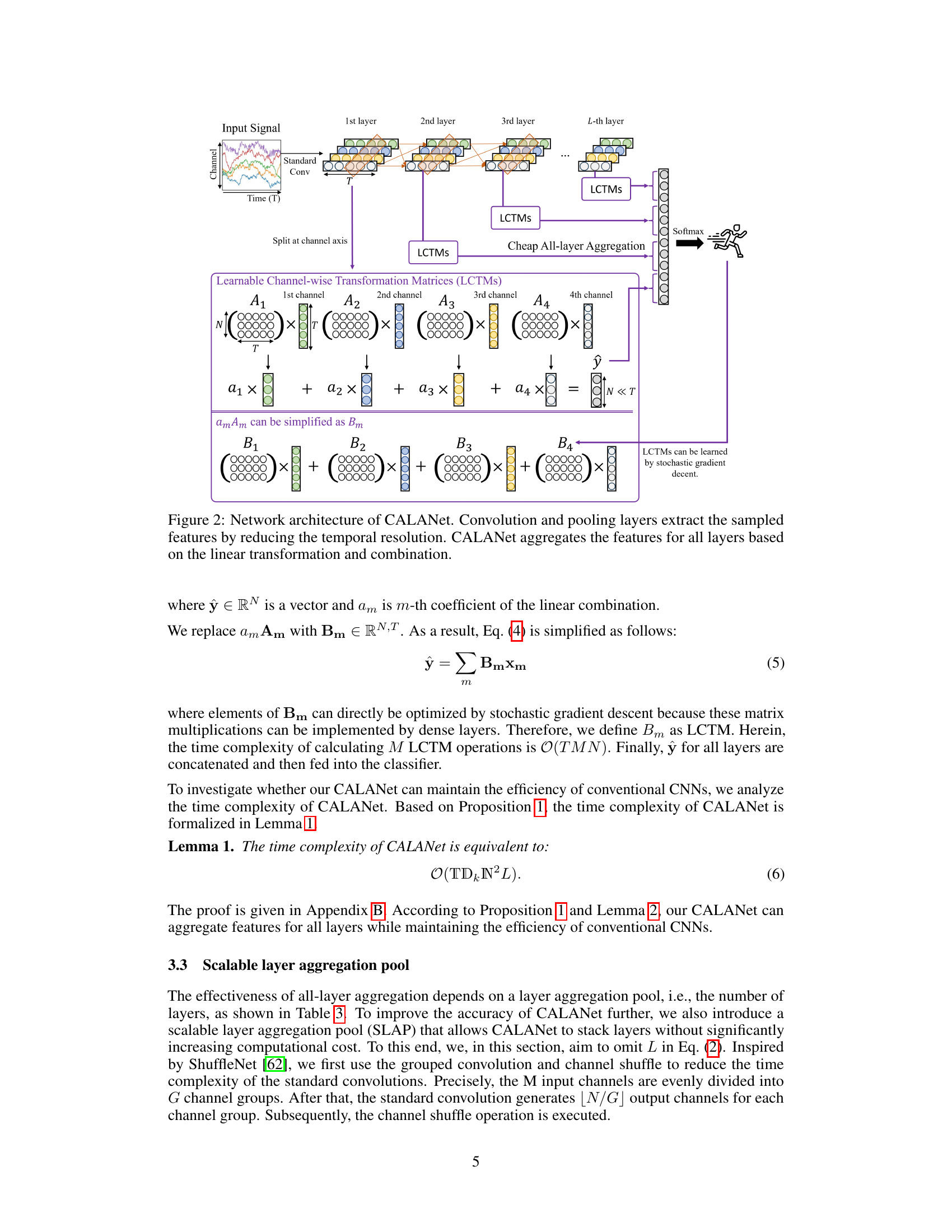
🔼 The figure illustrates the architecture of CALANet, a novel network designed for human activity recognition (HAR). It starts with input signals that go through a series of convolutional and pooling layers, reducing the temporal resolution. This part is standard in convolutional neural networks (CNNs). The novel aspect is the ‘cheap all-layer aggregation’ module. In this module, features from all layers are aggregated before going to the classifier. This aggregation is achieved by using learnable channel-wise transformation matrices (LCTMs) and a scalable layer aggregation pool (SLAP). LCTMs reduce the computational cost, while SLAP allows for stacking layers without dramatically increasing the cost. The classifier then predicts the activity based on these aggregated features. The diagram shows the flow of data through the network and highlights the key components of CALANet.
read the caption
Figure 2: Network architecture of CALANet. Convolution and pooling layers extract the sampled features by reducing the temporal resolution. CALANet aggregates the features for all layers based on the linear transformation and combination.

🔼 This figure shows the architecture of CALANet, a novel network proposed in the paper for human activity recognition. The input is sensor signals. These signals pass through a series of convolutional and pooling layers to extract features. Crucially, unlike traditional CNNs which only use the final layer’s features for classification, CALANet aggregates features from all layers. This aggregation is done using learnable channel-wise transformation matrices (LCTMs) and a scalable layer aggregation pool (SLAP), designed to minimize the increase in computational cost associated with using all-layer features. The combined features are then fed into a classifier to predict the activity.
read the caption
Figure 2: Network architecture of CALANet. Convolution and pooling layers extract the sampled features by reducing the temporal resolution. CALANet aggregates the features for all layers based on the linear transformation and combination.
🔼 The figure illustrates the architecture of CALANet, a novel network for human activity recognition. It shows how convolutional and pooling layers initially extract features from input signals. A key innovation is the ‘cheap all-layer aggregation’ method, where learnable channel-wise transformation matrices (LCTMs) and a scalable layer aggregation pool (SLAP) efficiently combine features from all layers before feeding them into a final classifier. This contrasts with conventional CNNs, which only use the last layer’s features.
read the caption
Figure 2: Network architecture of CALANet. Convolution and pooling layers extract the sampled features by reducing the temporal resolution. CALANet aggregates the features for all layers based on the linear transformation and combination.

🔼 This figure illustrates the architecture of the CALANet model. It shows how convolutional and pooling layers process the input signal, reducing temporal resolution and extracting high-level features. The key innovation is the ‘Cheap All-layer Aggregation’ module, which uses learnable channel-wise transformation matrices (LCTMs) to efficiently aggregate features from all layers before classification. This allows for more comprehensive feature utilization while controlling the computational cost.
read the caption
Figure 2: Network architecture of CALANet. Convolution and pooling layers extract the sampled features by reducing the temporal resolution. CALANet aggregates the features for all layers based on the linear transformation and combination.

🔼 The figure shows the architecture of CALANet, a novel network for human activity recognition. It highlights the use of learnable channel-wise transformation matrices (LCTMs) and a scalable layer aggregation pool (SLAP) for efficient all-layer feature aggregation. Convolutional and pooling layers initially process input signals, reducing temporal resolution. Then, LCTMs transform features from each layer into a common representation, enabling their combination via SLAP for final classification. This architecture achieves improved accuracy without increasing computational cost compared to conventional CNNs.
read the caption
Figure 2: Network architecture of CALANet. Convolution and pooling layers extract the sampled features by reducing the temporal resolution. CALANet aggregates the features for all layers based on the linear transformation and combination.
🔼 This figure shows the architecture of CALANet, a novel network for human activity recognition. It uses convolutional and pooling layers to extract features from input signals, reducing temporal resolution. A key innovation is the ‘cheap all-layer aggregation’ method. This involves using learnable channel-wise transformation matrices (LCTMs) and a scalable layer aggregation pool (SLAP) to efficiently combine features from all layers without significantly increasing computational cost. The combined features are then fed into a classifier for activity prediction. This design allows CALANet to achieve better accuracy than methods using only the last layer’s features.
read the caption
Figure 2: Network architecture of CALANet. Convolution and pooling layers extract the sampled features by reducing the temporal resolution. CALANet aggregates the features for all layers based on the linear transformation and combination.
More on tables
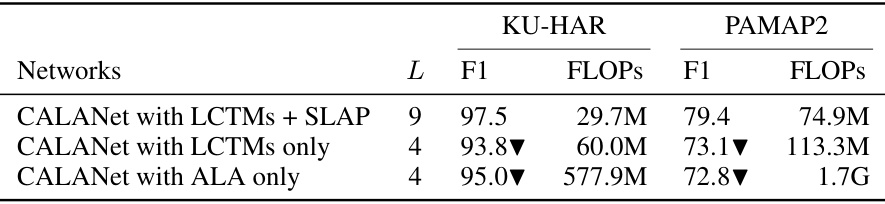
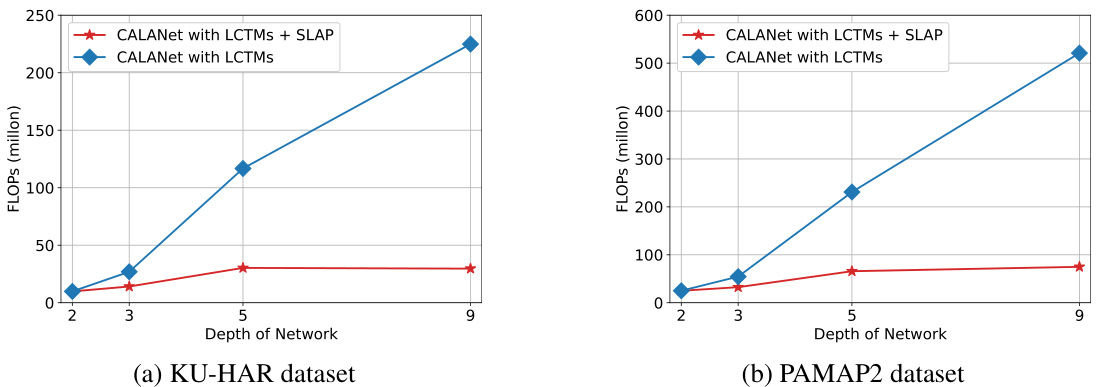
🔼 This ablation study investigates the impact of the different components of CALANet on the performance. It compares the full CALANet model (with LCTMs and SLAP) against versions that remove either the LCTMs, the SLAP, or both, using two datasets (KU-HAR and PAMAP2). The results show the tradeoff between model complexity (measured by FLOPs) and accuracy (F1-score). This table helps to understand the individual contributions of each component towards the overall performance gain.
read the caption
Table 2: Ablation study of CALANet on two datasets; LCTMs: Learnable channel-wise transformation matrices, SLAP: Scalable layer aggregation pool, ALA: All-layer aggregation
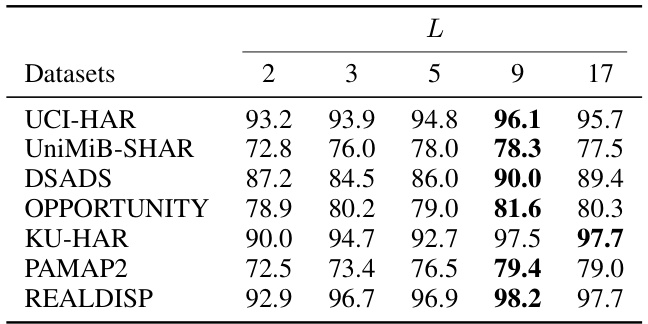
🔼 This table shows the performance (F1-score) of the CALANet model on seven different datasets with varying numbers of layers in the layer aggregation pool (L). The best F1-score for each dataset is highlighted in bold. The table demonstrates how the model’s accuracy changes as the depth of the network is increased, showing the optimal depth for different datasets.
read the caption
Table 3: F1-score of CALANet on different layer aggregation pool, i.e., network depth L

🔼 This table compares the performance of SqueezeNet, both with and without the proposed CALA (Cheap All-Layer Aggregation) structure, across seven different datasets. It shows the F1-score and FLOPs (floating point operations) for each model and dataset, demonstrating the impact of adding CALA to SqueezeNet in terms of accuracy and computational efficiency. Lower FLOPs indicate improved efficiency.
read the caption
Table 4: Comparison results of SqueezeNet with/without CALA structure on seven datasets.
🔼 This table compares the performance of CALANet against 11 other state-of-the-art models on seven different datasets. The comparison is done using two metrics: F1-score (a measure of accuracy that considers class imbalances) and FLOPS (floating-point operations, indicating computational cost). The table shows that CALANet achieves superior performance (higher F1-scores) with comparable or lower computational cost (FLOPS) than the other models in most cases. The symbols ▼ and ▲ indicate statistically significant differences between CALANet and the compared model based on a paired t-test.
read the caption
Table 1: Comparison results on seven datasets. ▼/▲ indicates that the corresponding model is significantly worse/better than CALANet according to a paired t-test at a 95% significance level.

🔼 This table presents the comparison results of CALANet against 11 other state-of-the-art methods across seven publicly available HAR datasets. The comparison is done using two metrics: F1-score (a metric suitable for imbalanced datasets) and FLOPS (floating-point operations, a measure of computational cost). The table highlights the superior performance of CALANet in terms of F1-score, indicating improved accuracy, and often with lower FLOPS indicating increased efficiency. The symbols ▼ and ▲ indicate statistically significant differences between CALANet and the other methods, based on a paired t-test.
read the caption
Table 1: Comparison results on seven datasets. ▼/▲ indicates that the corresponding model is significantly worse/better than CALANet according to a paired t-test at a 95% significance level.
Full paper#