TL;DR#
Current large language model (LLM) alignment techniques struggle with noisy preferences (NPs) in training data, where human feedback is mistakenly labeled. These NPs hinder alignment and can result in LLMs producing subpar or even harmful content. Existing methods primarily tackle this problem by adjusting the alignment loss function. This paper proposes a different strategy focusing on data correction.
PerpCorrect, the proposed method, directly addresses the data issue. It leverages the perplexity difference (PPLDiff) between correctly and incorrectly labeled responses to identify and correct NPs. By training a surrogate model on clean data, PerpCorrect learns to distinguish between clean and noisy preferences. The paper demonstrates that PerpCorrect significantly improves alignment performance compared to existing methods across various datasets and LLMs, making it a valuable tool for more robust and reliable LLM alignment.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to improve the robustness of large language model alignment against noisy human preferences. This is a critical issue in the field, as noisy data can significantly degrade model performance and even lead to the generation of harmful content. The proposed method, PerpCorrect, offers a practical solution to this problem by effectively identifying and correcting noisy preferences, thereby enabling more reliable and effective LLM alignment. This research is highly relevant to the current trends in LLM alignment and opens new avenues for improving the reliability and safety of LLMs.
Visual Insights#

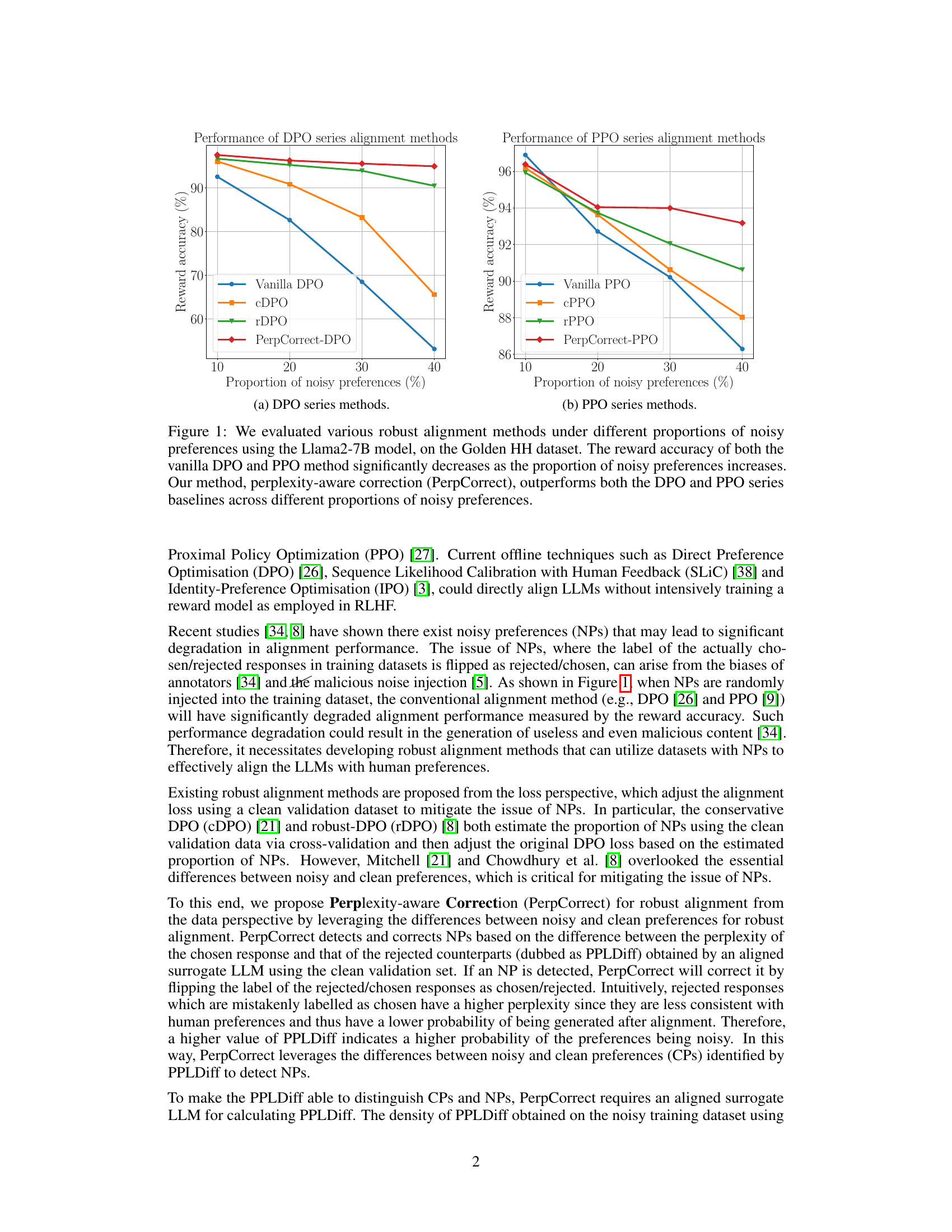
🔼 This figure shows the performance of different robust alignment methods (vanilla DPO, cDPO, rDPO, and PerpCorrect-DPO; vanilla PPO, cPPO, rPPO, and PerpCorrect-PPO) under varying proportions of noisy preferences (NPs). The reward accuracy is used as a metric. As the proportion of NPs increases, the reward accuracy of vanilla DPO and PPO methods decreases significantly. In contrast, PerpCorrect consistently outperforms the baselines across all NP proportions, demonstrating its robustness to noisy preferences.
read the caption
Figure 1: We evaluated various robust alignment methods under different proportions of noisy preferences using the Llama2-7B model, on the Golden HH dataset. The reward accuracy of both the vanilla DPO and PPO method significantly decreases as the proportion of noisy preferences increases. Our method, perplexity-aware correction (PerpCorrect), outperforms both the DPO and PPO series baselines across different proportions of noisy preferences.
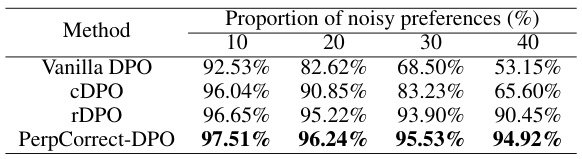
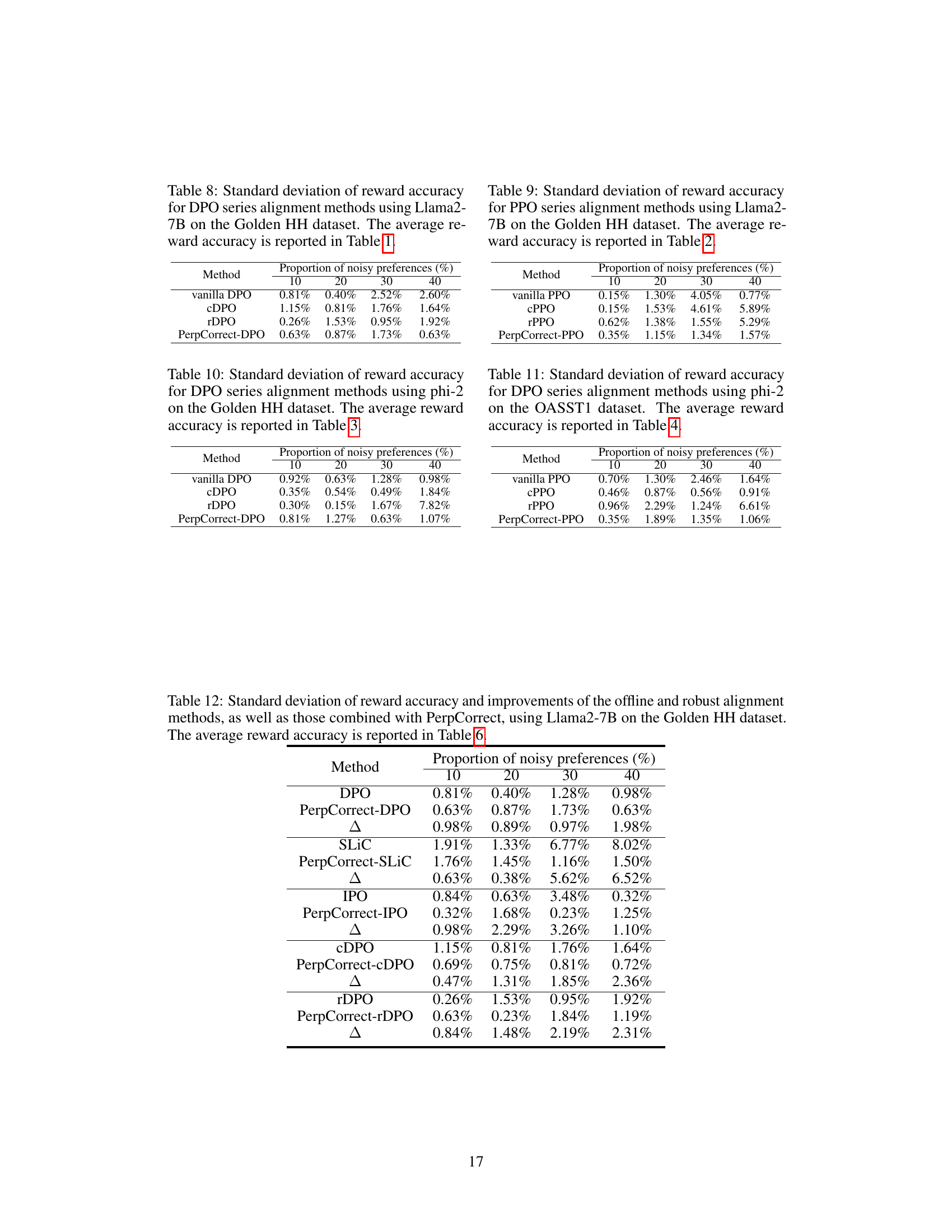
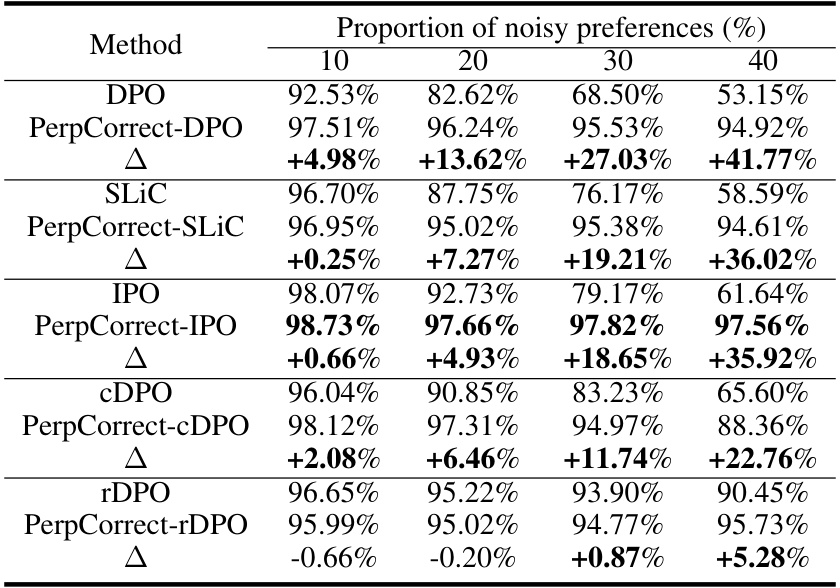
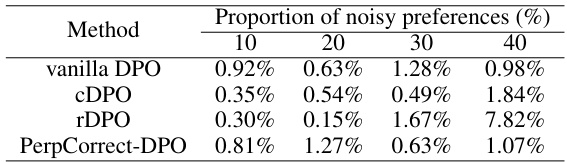
🔼 This table presents the average reward accuracy of four different DPO-based alignment methods (Vanilla DPO, cDPO, rDPO, and PerpCorrect-DPO) on the Golden HH dataset using the Llama2-7B model. The performance is evaluated across four different levels of noisy preferences (10%, 20%, 30%, and 40%). The standard deviation for each data point is available in Table 8 of the same paper. The table demonstrates how the presence of noisy preferences impacts the accuracy of the alignment methods and how PerpCorrect-DPO aims to improve the robustness against such noise.
read the caption
Table 1: Average reward accuracy of DPO series alignment methods using Llama2-7B on the Golden HH dataset. The standard deviation of reward accuracy is reported in Table 8.
In-depth insights#
Noisy Preference Handling#
Robust alignment of Large Language Models (LLMs) is challenged by the presence of noisy preferences in training data. Noisy preferences, where human feedback is inaccurate or inconsistent, lead to models that generate suboptimal or even harmful outputs. Addressing this requires sophisticated handling techniques. One approach focuses on loss function modifications; for example, weighting losses based on confidence scores or using robust loss functions to mitigate the impact of outliers. Another strategy is to detect and correct noisy preferences before training. This could involve using validation sets to identify unreliable labels or employing algorithms that filter or re-weight feedback based on consistency or plausibility. Data augmentation techniques can also prove valuable by creating more balanced datasets with cleaner preference signals. Finally, employing more sophisticated reward models that capture nuanced aspects of human preferences and are less susceptible to noise offers significant improvement. The ideal approach likely combines multiple strategies, using a multi-faceted approach to handle noisy preferences effectively.
Perplexity-Based Correction#
The concept of “Perplexity-Based Correction” in the context of aligning large language models (LLMs) with human preferences is a novel approach to handling noisy data. It leverages the inherent ability of perplexity to reflect how well a generated text aligns with the model’s understanding of language. Higher perplexity suggests a lower probability that the LLM would generate a given response, hence indicating a higher likelihood of it being a ’noisy preference’ (mislabeled data). The core idea involves training a surrogate LLM to discern between clean and noisy preferences based on perplexity differences, thereby enabling the identification and correction of noisy labels. This method is particularly effective because it tackles noise directly from a data perspective, rather than relying solely on loss adjustments, which could be limited in their effectiveness when dealing with significant noise. The methodology is data-centric, focusing on enhancing training data quality, and is computationally efficient. However, a limitation lies in its dependence on the aligned surrogate LLM, which still requires considerable computation and sufficient clean data for training. Its effectiveness might also be affected by the nature of noisy data patterns and quality of the initial training data. The strength of this method lies in its potential for broad applicability across various LLM alignment techniques.
Surrogate LLM Training#
The concept of ‘Surrogate LLM Training’ introduces a crucial element in enhancing the robustness of LLM alignment against noisy preferences. A surrogate model, trained on a clean dataset, acts as a reliable proxy for evaluating preferences. This surrogate model is used to calculate a key metric (e.g. PPLDiff) that helps discriminate between genuine human preferences and noisy labels. Its alignment on clean data is essential; without it, the metric wouldn’t effectively distinguish clean and noisy preferences. The process then typically involves iteratively refining this surrogate LLM by incorporating highly reliable (both clean and corrected noisy) data points, improving its ability to discern true preferences from noise. This iterative approach ensures the surrogate LLM is well-suited for the specific task of identifying noisy data points, making the alignment process far more robust and effective. The use of a surrogate LLM adds a layer of resilience to the training process, safeguarding against the negative impact of noisy preferences on the primary LLM’s training, and ultimately yielding a better-aligned, more reliable model.
Robust Alignment Methods#
Robust alignment methods address the challenge of aligning large language models (LLMs) with human preferences despite the presence of noise or inconsistencies in the preference data. These methods are crucial because noisy preferences can lead to unreliable or even harmful LLM outputs. Techniques like conservative DPO (cDPO) and robust DPO (rDPO) aim to mitigate the impact of noisy preferences by adjusting the alignment loss function based on estimates of the noise level, often derived from a separate validation dataset. However, these approaches often overlook the critical differences between clean and noisy preferences. The proposed perplexity-aware correction method offers a different perspective, focusing on identifying and correcting noisy preferences directly from the data, rather than solely relying on loss adjustments. By utilizing the perplexity differences between chosen and rejected responses (PPLDiff), it offers a data-driven approach to enhance the reliability of the training data and improve the robustness of the alignment process. This method demonstrates superior performance and compatibility with various alignment techniques, highlighting its potential as a significant advancement in the field.
Efficiency and Scalability#
A crucial aspect of any machine learning model, especially large language models (LLMs), is its efficiency and scalability. Efficiency refers to the computational resources (time and memory) required for training and inference. Scalability focuses on the model’s ability to handle increasing amounts of data and maintain performance as the scale grows. In the context of LLM alignment, efficiency and scalability are paramount. Inefficient alignment methods hinder the adoption of LLMs due to high costs. Similarly, if an alignment technique does not scale well with the size of the LLM or dataset, its applicability to advanced models is limited. Therefore, methods that achieve both high accuracy and efficiency, such as those employing perplexity-based techniques, are highly desirable. Investigating tradeoffs between model accuracy and efficiency is essential. A robust approach is needed which doesn’t compromise accuracy while also maintaining scalability, enabling the alignment of ever-larger LLMs with complex and evolving human preferences.
More visual insights#
More on figures
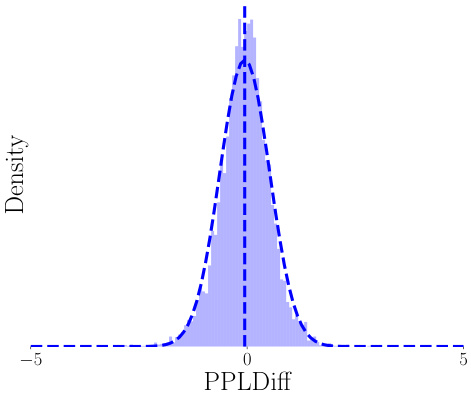
🔼 This figure visualizes how the perplexity difference (PPLDiff) between chosen and rejected responses changes throughout the PerpCorrect process. Initially, the PPLDiff distributions for clean and noisy preferences significantly overlap (Figure 2a), making discrimination difficult. After aligning a surrogate LLM on clean data, the distributions separate somewhat (Figure 2b), but still have considerable overlap. Further iterative alignment using highly reliable clean and noisy data greatly enhances the separability (Figure 2c and 2d), allowing for more accurate identification and correction of noisy preferences based on a threshold.
read the caption
Figure 2: We visualized the PPLDiff under the entire PerpCorrect process using Llama2-7B on Golden HH dataset with 20% noisy preferences. We use the green dotted line to represent the normal distribution formed by clean data, the red dotted line represents the normal distribution formed by noisy data, and the black dotted line represents the threshold.

🔼 This figure visualizes the distribution of PPLDiff (the difference in perplexity between chosen and rejected responses) for clean and noisy preferences throughout the PerpCorrect process. The Llama2-7B model is used on the Golden HH dataset with 20% noisy preferences. It demonstrates how the alignment process separates clean and noisy preferences, allowing for effective detection and correction of noisy preferences based on the PPLDiff threshold.
read the caption
Figure 2: We visualized the PPLDiff under the entire PerpCorrect process using Llama2-7B on Golden HH dataset with 20% noisy preferences. We use the green dotted line to represent the normal distribution formed by clean data, the red dotted line represents the normal distribution formed by noisy data, and the black dotted line represents the threshold.
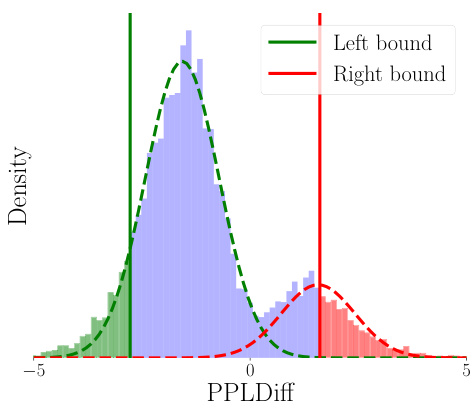
🔼 This figure visualizes the distribution of PPLDiff (perplexity difference between chosen and rejected responses) at different stages of the PerpCorrect process. It shows how aligning a surrogate LLM on clean data helps separate the distributions of PPLDiff for clean preferences (CPs) and noisy preferences (NPs). Further alignment using reliable data (with extremely low and high PPLDiff) improves the separation. Finally, a threshold on PPLDiff is used to detect and correct NPs.
read the caption
Figure 2: We visualized the PPLDiff under the entire PerpCorrect process using Llama2-7B on Golden HH dataset with 20% noisy preferences. We use the green dotted line to represent the normal distribution formed by clean data, the red dotted line represents the normal distribution formed by noisy data, and the black dotted line represents the threshold.

🔼 This figure shows the distribution of PPLDiff (the difference in perplexity between chosen and rejected responses) for clean and noisy preferences at different stages of the PerpCorrect process. Initially, the distributions overlap significantly, making it hard to distinguish clean from noisy preferences. After aligning the surrogate LLM with clean data, the distributions separate somewhat but still overlap. Finally, after further alignment using both reliable clean and noisy data, the distributions are clearly separated, enabling effective identification of noisy preferences.
read the caption
Figure 2: We visualized the PPLDiff under the entire PerpCorrect process using Llama2-7B on Golden HH dataset with 20% noisy preferences. We use the green dotted line to represent the normal distribution formed by clean data, the red dotted line represents the normal distribution formed by noisy data, and the black dotted line represents the threshold.
More on tables
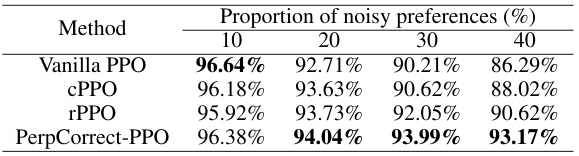
🔼 This table presents the average reward accuracy of four different PPO-based alignment methods (Vanilla PPO, cPPO, rPPO, and PerpCorrect-PPO) when training a Llama2-7B language model on the Golden HH dataset. The results are shown for four different proportions of noisy preferences in the training data (10%, 20%, 30%, and 40%). The standard deviation of the reward accuracy for each method and noise level is provided in a separate table (Table 9). The table demonstrates how the different methods perform under varying levels of noise in the preference data.
read the caption
Table 2: Average reward accuracy of PPO series alignment methods using Llama2-7B on the Golden HH dataset. The standard deviation of reward accuracy is reported in Table 9.

🔼 This table presents the average reward accuracy of several DPO-based alignment methods (Vanilla DPO, cDPO, rDPO, and PerpCorrect-DPO) when using the phi-2 language model on the Golden HH dataset. The results are shown for different proportions of noisy preferences (10%, 20%, 30%, and 40%). The standard deviation of these reward accuracies can be found in Table 10 of the paper.
read the caption
Table 3: Average reward accuracy of DPO series alignment methods using phi-2 on the Golden HH dataset. The standard deviation of reward accuracy is reported in Table 10.

🔼 This table shows how the reward accuracy of the PerpCorrect method changes with different amounts of clean validation data used in the experiment. The experiment was conducted on the Golden HH dataset using the Llama2-7B model with 40% noisy preferences.
read the caption
Table 5: Impact of the number of clean validation data evaluated on the Golden HH dataset using Llama2-7B with a proportion of NPs ε = 40%.
🔼 This table presents the average reward accuracy of several offline and robust alignment methods, both with and without the proposed PerpCorrect method. The results are shown for different proportions of noisy preferences in the dataset (10%, 20%, 30%, and 40%). The table also shows the improvement in reward accuracy achieved by incorporating PerpCorrect into each of the base methods. The standard deviations of these results are provided in a separate table.
read the caption
Table 6: Average reward accuracy and improvements of the offline and robust alignment methods, as well as those combined with PerpCorrect, using Llama2-7B on the Golden HH dataset. The standard deviation of reward accuracy and improvements is reported in Table 12.

🔼 This table compares the theoretical and practical running times for the PerpCorrect method and the baseline methods. The theoretical running time for PerpCorrect is approximately T/3 times the running time of the baseline methods, where T is the number of epochs. The practical running time for PerpCorrect is approximately 24 hours, while the practical running time for the baseline methods is approximately 12 hours. This shows that the practical running time for PerpCorrect is about twice as long as the running time for the baseline methods.
read the caption
Table 7: Comparison of theoretical and practical running times for PerpCorrect and baselines.

🔼 This table presents the standard deviation of reward accuracy for four different DPO-based alignment methods (vanilla DPO, cDPO, rDPO, and PerpCorrect-DPO) across four different levels of noisy preferences (10%, 20%, 30%, and 40%). It supplements Table 1, which shows the average reward accuracy for the same methods and conditions. The standard deviation provides a measure of the variability or uncertainty in the reward accuracy results.
read the caption
Table 8: Standard deviation of reward accuracy for DPO series alignment methods using Llama2-7B on the Golden HH dataset. The average reward accuracy is reported in Table 1.
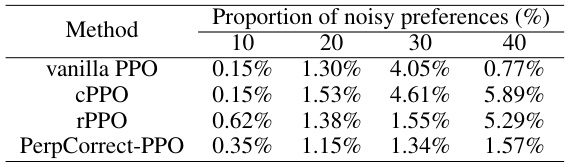
🔼 This table presents the standard deviations of the reward accuracy for various PPO-based alignment methods, including vanilla PPO, conservative PPO (cPPO), robust PPO (rPPO), and the proposed PerpCorrect-PPO, across different proportions of noisy preferences in the Golden HH dataset. It complements Table 2, which shows the average reward accuracy for the same methods and conditions. The standard deviations provide a measure of the variability or uncertainty in the reward accuracy results.
read the caption
Table 9: Standard deviation of reward accuracy for PPO series alignment methods using Llama2-7B on the Golden HH dataset. The average reward accuracy is reported in Table 2.
🔼 This table shows the standard deviation of the reward accuracy for four different DPO-series alignment methods (vanilla DPO, cDPO, rDPO, and PerpCorrect-DPO) using the Llama2-7B model on the Golden HH dataset. The results are broken down by the proportion of noisy preferences (10%, 20%, 30%, and 40%). Table 1 in the paper provides the corresponding average reward accuracy values for these methods and noise levels.
read the caption
Table 8: Standard deviation of reward accuracy for DPO series alignment methods using Llama2-7B on the Golden HH dataset. The average reward accuracy is reported in Table 1.

🔼 This table presents the standard deviation of reward accuracy for different PPO series alignment methods (vanilla PPO, cPPO, rPPO, and PerpCorrect-PPO) using the Llama2-7B model on the Golden HH dataset. The results are broken down by the proportion of noisy preferences (10%, 20%, 30%, and 40%). It complements Table 2, which shows the average reward accuracy for the same methods and conditions.
read the caption
Table 9: Standard deviation of reward accuracy for PPO series alignment methods using Llama2-7B on the Golden HH dataset. The average reward accuracy is reported in Table 2.

🔼 This table presents the standard deviations of the reward accuracy values shown in Table 6. It compares the performance of several offline and robust alignment methods, both with and without the proposed PerpCorrect method, across different proportions of noisy preferences in the dataset. The improvement percentages are calculated based on the average reward accuracy.
read the caption
Table 12: Standard deviation of reward accuracy and improvements of the offline and robust alignment methods, as well as those combined with PerpCorrect, using Llama2-7B on the Golden HH dataset. The average reward accuracy is reported in Table 6.

🔼 This table presents the average perplexity difference (PPLDiff) values computed for randomly selected data points from various datasets using different language models (LLMs). PPLDiff measures the difference in perplexity between the chosen and rejected responses in a preference dataset, with a higher PPLDiff suggesting a higher likelihood of a noisy preference. The table shows the average PPLDiff for each dataset and LLM, as well as the overall average across all datasets. This data is used in the PerpCorrect algorithm to distinguish between clean and noisy preferences.
read the caption
Table 13: Average PPLDiff values of randomly selected data points across datasets calculated by different LLMs. 'Avg.' refers to the average PPLDiff value over all the datasets.
Full paper#