TL;DR#
Current citation prediction struggles with the varying importance of citations and the massive scale of available papers. Existing methods often rely on simple binary classification, failing to distinguish between foundational and superficial citations. This limits accuracy and scalability.
HLM-Cite tackles these challenges using a two-stage hybrid approach. First, it uses a fine-tuned embedding model for efficient retrieval of high-likelihood citations. Then, an LLM-driven workflow ranks these papers, discerning implicit relationships for improved accuracy. This approach achieves a 17.6% performance gain compared to state-of-the-art methods and scales to 100K candidate papers.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on citation prediction and related fields because it introduces a novel approach to improve accuracy and scalability, addressing limitations of existing methods. The proposed HLM-Cite workflow, combining embedding and generative language models, offers significant performance improvements and the ability to handle vastly larger datasets. This opens new avenues for research in citation analysis, knowledge graph construction, and computational social science.
Visual Insights#
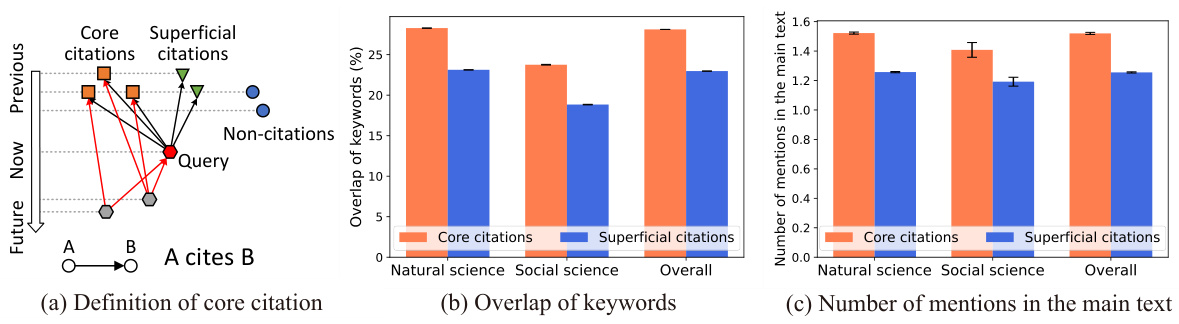
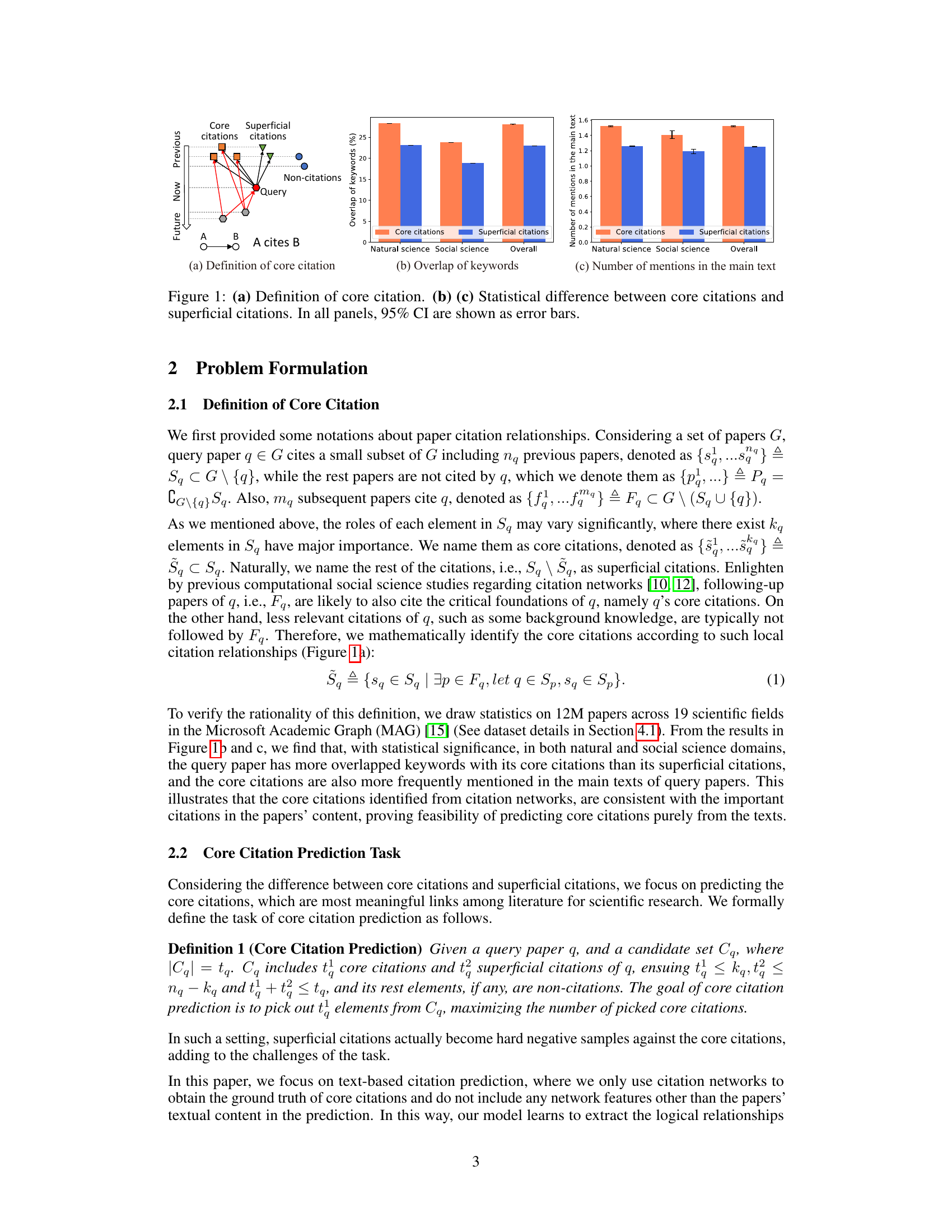
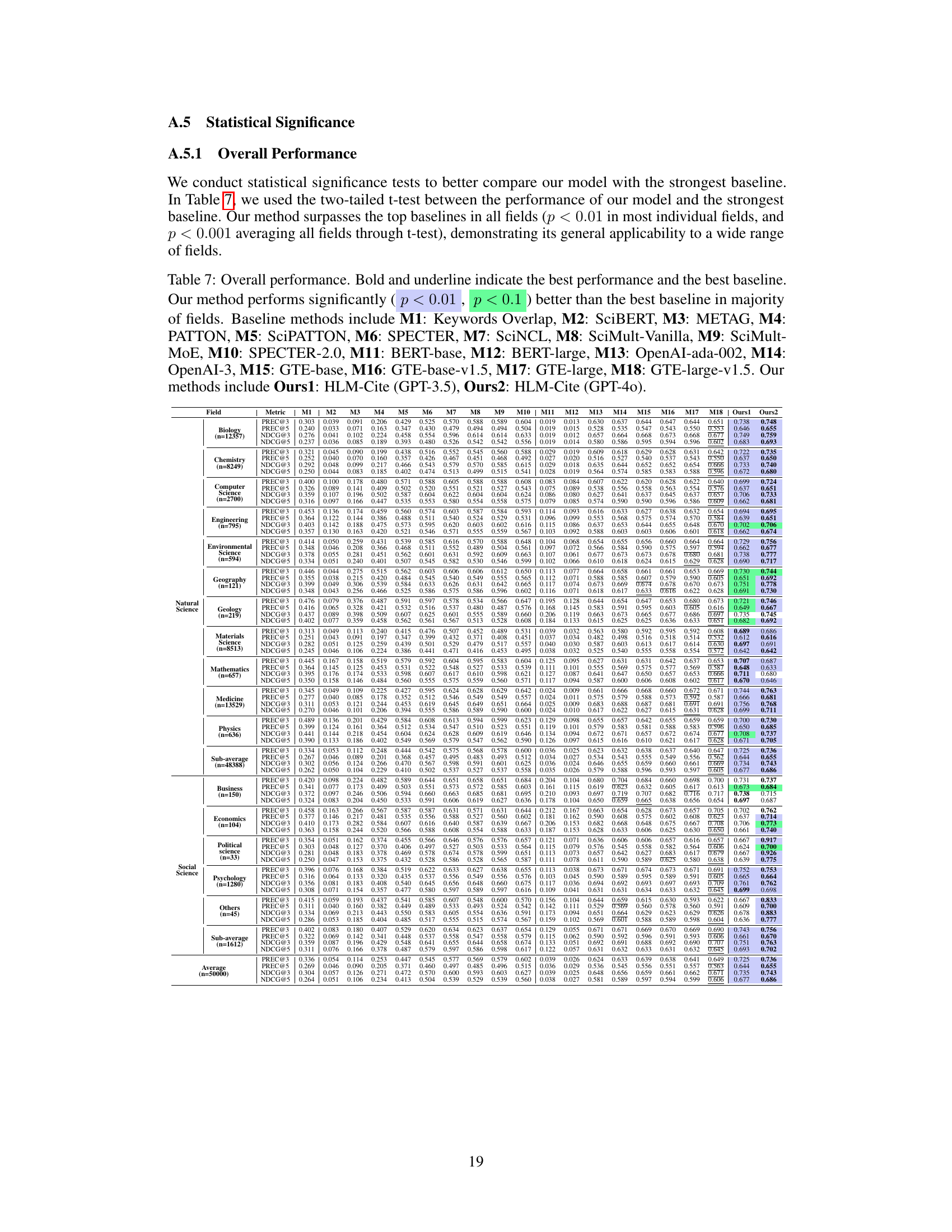
🔼 This figure demonstrates the definition and statistical significance of core citations. Panel (a) visually depicts the concept of a core citation as a citation from a previous paper that is also cited by subsequent papers citing the query paper. Panels (b) and (c) present statistical evidence from 12M papers across 19 scientific fields supporting the concept of core citations, showing that core citations have statistically more keyword overlap (panel (b)) and main text mentions (panel (c)) than superficial citations.
read the caption
Figure 1: (a) Definition of core citation. (b) (c) Statistical difference between core citations and superficial citations. In all panels, 95% CI are shown as error bars.
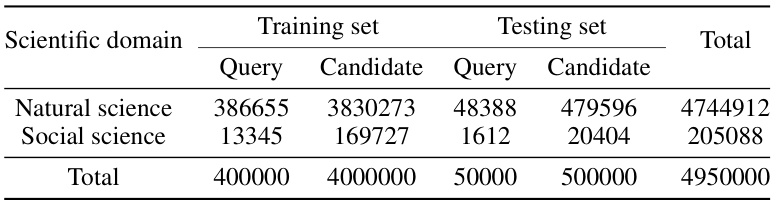
🔼 This table presents the statistical distribution of the dataset used in the paper’s experiments. It breaks down the number of query papers and candidate papers (those that are potential citations) in both the training and testing sets across natural science and social science domains. The total number of queries and candidates for both sets is also given.
read the caption
Table 1: Dataset statistics
In-depth insights#
Hybrid LLM Workflow#
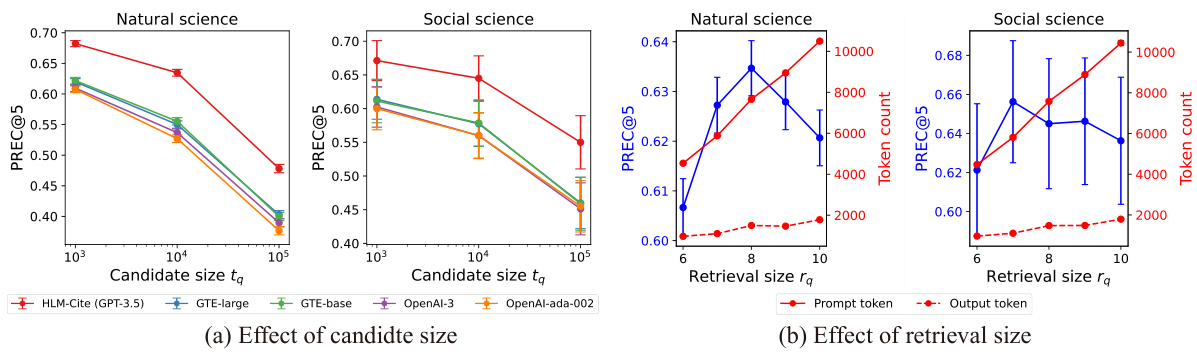
A hybrid LLM workflow for scientific citation prediction cleverly combines the strengths of embedding and generative LLMs. Embedding models efficiently pre-screen vast candidate sets, narrowing down the search space for core citations—those crucial references going beyond superficial mentions. This initial retrieval stage leverages the speed and scalability of embeddings. Subsequently, a generative LLM workflow, acting as an agent, performs in-depth analysis and ranking of the retrieved papers. This two-stage pipeline enables deeper logical reasoning about citation relevance, addressing the limitations of LLMs with restricted context lengths and the challenge of implicit relationships between papers. The curriculum finetuning procedure used to adapt the embedding model further enhances the system’s accuracy and robustness. This approach, therefore, successfully scales citation prediction to significantly larger candidate sets than previous methods, marking a substantial advancement in the field.
Core Citation Prediction#
Core citation prediction presents a significant advancement in citation analysis by moving beyond simple binary classification. Instead of merely identifying whether a paper cites another, it aims to discern the varying roles of citations, differentiating between foundational contributions (‘core citations’) and superficial mentions. This nuanced approach requires sophisticated methods capable of understanding the implicit logical relationships among papers, moving beyond simple textual similarities. Large language models (LLMs) are ideally suited for this complex task due to their capacity for contextual understanding and reasoning. However, challenges remain, including the scalability of processing vast numbers of candidate papers and the extraction of implicit relationships from potentially lengthy texts. Effective solutions will likely involve hybrid approaches combining LLMs with efficient retrieval techniques, to first narrow down a large pool of candidates and subsequently leverage the LLMs’ power for in-depth analysis and ranking. Success in this domain would have implications for various fields, enabling a deeper understanding of knowledge flow, accelerating scientific discovery, and potentially improving the quality of research by highlighting the most influential prior works.
Curriculum Finetuning#
Curriculum learning, in the context of citation prediction, is a powerful technique to address the challenge of distinguishing core citations from superficial ones and non-citations. A naive approach might treat citation prediction as a simple binary classification problem, leading to suboptimal performance. Curriculum finetuning strategically introduces easier examples, like distinguishing core citations from non-citations, before progressing to the more complex task of distinguishing among core, superficial, and non-citations. This phased approach helps the model learn the subtle differences between citation types, thereby improving its accuracy and robustness. The order in which training data is presented is crucial, allowing the model to gradually develop a nuanced understanding of contextual information and logical relationships. Starting with simpler classification tasks and gradually increasing complexity helps avoid early overfitting to irrelevant features and promotes a more generalizable model that can handle the inherent ambiguity in the task. This approach leverages the power of curriculum learning to enhance performance in a challenging NLP problem by carefully guiding the model’s learning process, mimicking how humans might learn a complex skill, progressing from foundational knowledge to more advanced concepts.
LLM Agentic Ranking#
The concept of ‘LLM Agentic Ranking’ introduces a novel approach to citation prediction, moving beyond simple retrieval methods. It leverages the reasoning capabilities of large language models (LLMs) to analyze and rank retrieved citations, going beyond mere keyword matching. This agentic approach is particularly valuable when dealing with massive datasets of candidate citations exceeding the context window of LLMs. A key strength is its ability to uncover implicit relationships between papers that are not readily apparent from surface-level textual analysis. The system’s modular design, using separate LLMs for guiding, analyzing, and deciding, allows for a more nuanced and robust ranking process. This two-stage pipeline combines the efficiency of embedding models with the reasoning power of LLMs, effectively scaling citation prediction to significantly larger datasets than previous methods. However, this reliance on LLMs introduces potential challenges, including the need to mitigate the limitations of LLMs like hallucinations and biases. Careful prompting and techniques like chain-of-thought prompting are critical for maximizing accuracy and reliability. The success of LLM Agentic Ranking hinges on the quality and diversity of the training data used to fine-tune the models. Further research should focus on addressing these challenges, thereby improving the overall robustness and dependability of the approach.
Scalability and Limits#
A discussion on “Scalability and Limits” in the context of a research paper would explore the practical boundaries of the presented method or model. This involves analyzing the computational resources needed (processing power, memory, time), the data requirements (size, quality, type), and the generalizability to different datasets or scenarios. Limitations in terms of the algorithm’s efficiency, accuracy, and robustness under various conditions would also be addressed. Furthermore, a thoughtful analysis would consider the trade-offs between scalability and accuracy, exploring whether increasing scalability necessitates compromises in accuracy or vice versa. The inherent limitations of the underlying technologies, such as limitations in the size of data that can be processed by specific Language Models, would be crucial to discuss. Finally, future directions could be suggested, focusing on potential improvements or alternative approaches that could overcome the identified limitations and expand the applicability of the research.
More visual insights#
More on figures
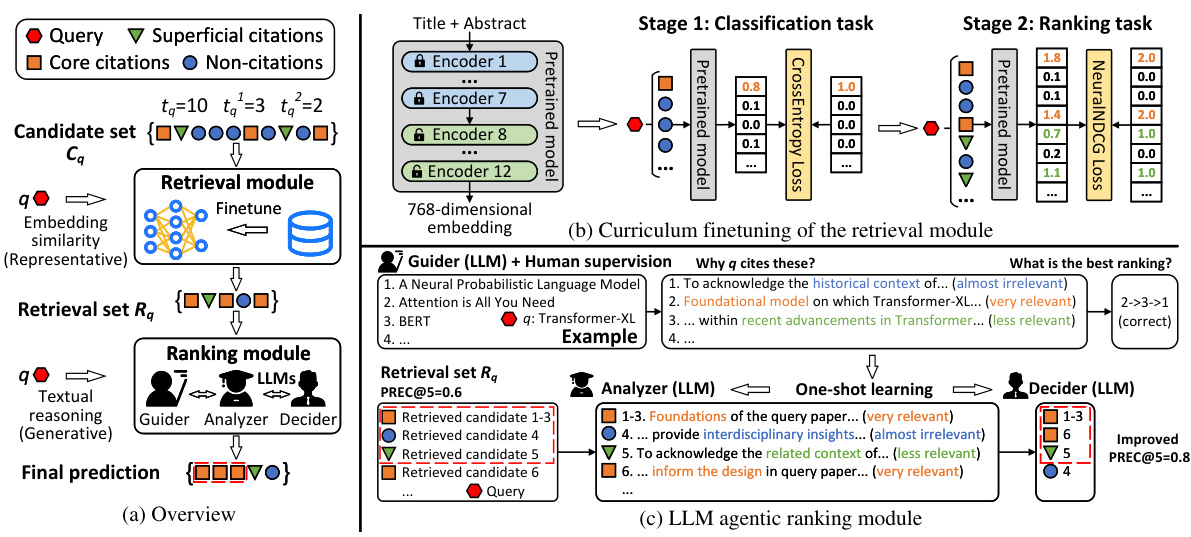
🔼 This figure illustrates the HLM-Cite workflow, a hybrid language model approach for citation prediction. It consists of two main modules: a retrieval module and an LLM agentic ranking module. The retrieval module uses a fine-tuned text embedding model to retrieve high-likelihood core citations. The LLM agentic ranking module employs a three-agent workflow (Guider, Analyzer, Decider) to rank the retrieved papers based on implicit relationships revealed through one-shot reasoning, enhancing accuracy and scalability to 100K candidate papers. The curriculum finetune procedure for the retrieval module is also detailed, showing a two-stage process that starts with distinguishing core citations from non-citations and then progresses to ranking core, superficial, and non-citations.
read the caption
Figure 2: Illustration of the proposed hybrid language model (HLM-Cite) workflow.

🔼 This figure illustrates the HLM-Cite workflow, which consists of two main modules: a retrieval module and an LLM agentic ranking module. The retrieval module uses a pretrained text embedding model (finetuned via a curriculum procedure) to retrieve high-likelihood core citations from a large candidate set. The LLM agentic ranking module then uses a three-agent workflow (Guider, Analyzer, Decider) leveraging pretrained large language models (LLMs) for one-shot reasoning to rank the retrieved papers, revealing implicit relationships and ultimately predicting the core citations.
read the caption
Figure 2: Illustration of the proposed hybrid language model (HLM-Cite) workflow.
🔼 This figure presents the definition of core citations and provides statistical evidence supporting the validity of the definition. Panel (a) illustrates core citations as a subset of citations also cited by subsequent papers citing the query paper. Panels (b) and (c) use bar charts to show statistically significant differences between core citations and superficial citations based on keyword overlap and number of mentions in the main text, respectively. Error bars represent 95% confidence intervals.
read the caption
Figure 1: (a) Definition of core citation. (b) (c) Statistical difference between core citations and superficial citations. In all panels, 95% CI are shown as error bars.
🔼 This figure presents a definition of core citations and demonstrates the statistical significance of the differences between core citations and superficial citations. Panel (a) visually illustrates the definition, showing the relationships between query papers and their citations in a network. Panels (b) and (c) present statistical evidence, using error bars to represent 95% confidence intervals, that core citations and superficial citations differ significantly in terms of keyword overlap and the number of times they are mentioned in the main text of the query paper. This suggests core citations are more intrinsically linked to the query paper’s core concepts than superficial citations.
read the caption
Figure 1: (a) Definition of core citation. (b) (c) Statistical difference between core citations and superficial citations. In all panels, 95% CI are shown as error bars.
🔼 This figure presents the definition of core citations and shows the statistical differences between core citations and superficial citations in terms of keyword overlap and the number of mentions in the main text of the query paper. The results support the claim that core citations are more closely related to the query paper and play a more significant role compared to superficial citations.
read the caption
Figure 1: (a) Definition of core citation. (b) (c) Statistical difference between core citations and superficial citations. In all panels, 95% CI are shown as error bars.
🔼 This figure visually presents the concept of core citations and their statistical distinctions from superficial citations. Subfigure (a) defines core citations as citations that are subsequently cited by papers citing the query paper, indicating their significance in establishing the query paper’s foundation. Subfigures (b) and (c) display the statistical differences between core and superficial citations in terms of keyword overlap and mentions in the main text, showing core citations demonstrate significantly closer relationships to the query papers.
read the caption
Figure 1: (a) Definition of core citation. (b) (c) Statistical difference between core citations and superficial citations. In all panels, 95% CI are shown as error bars.
More on tables
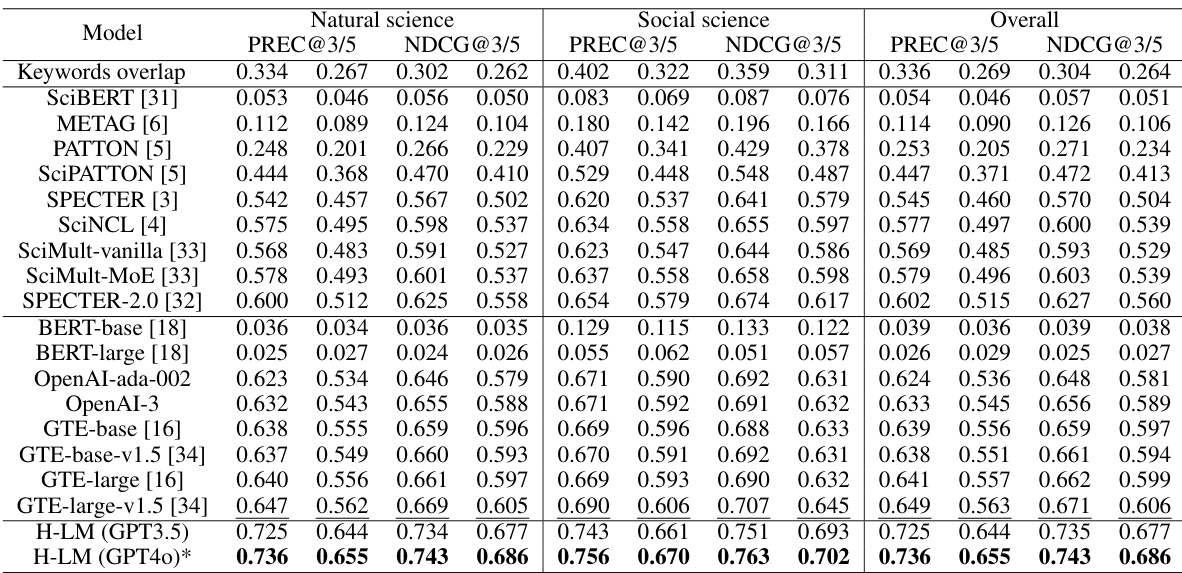
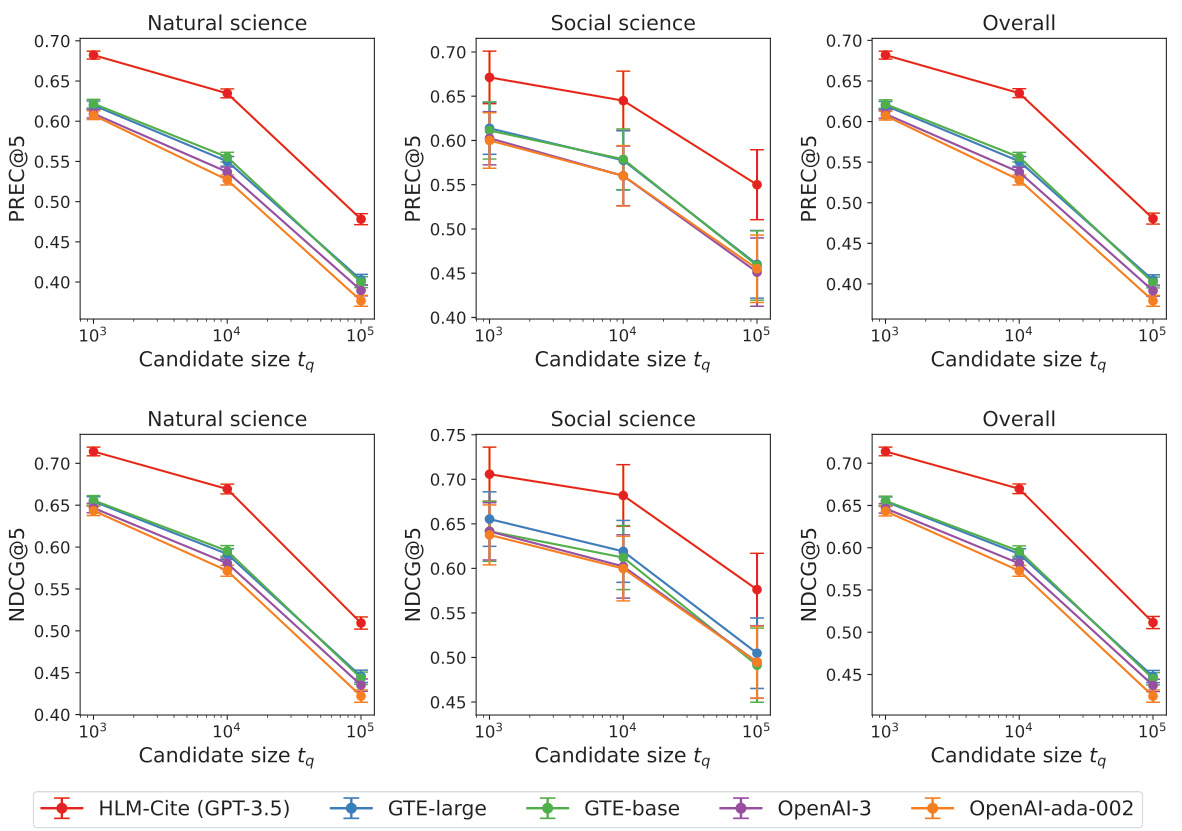
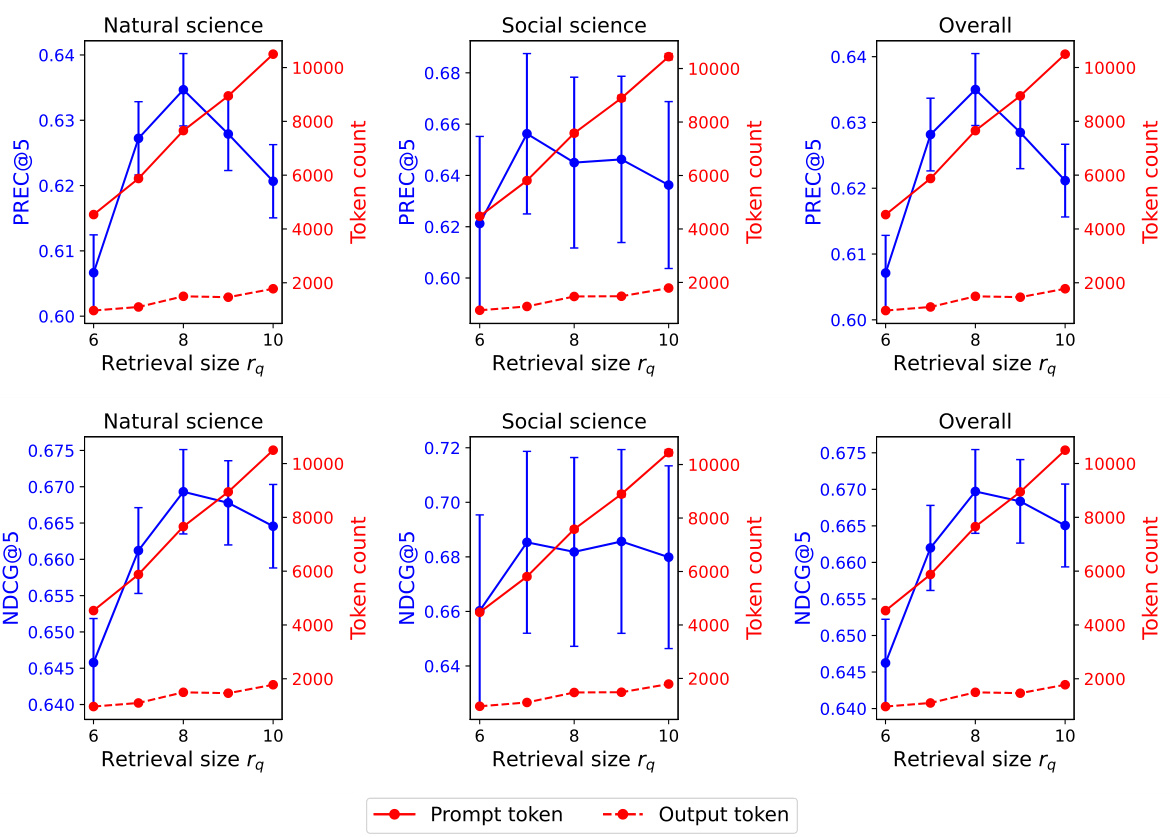
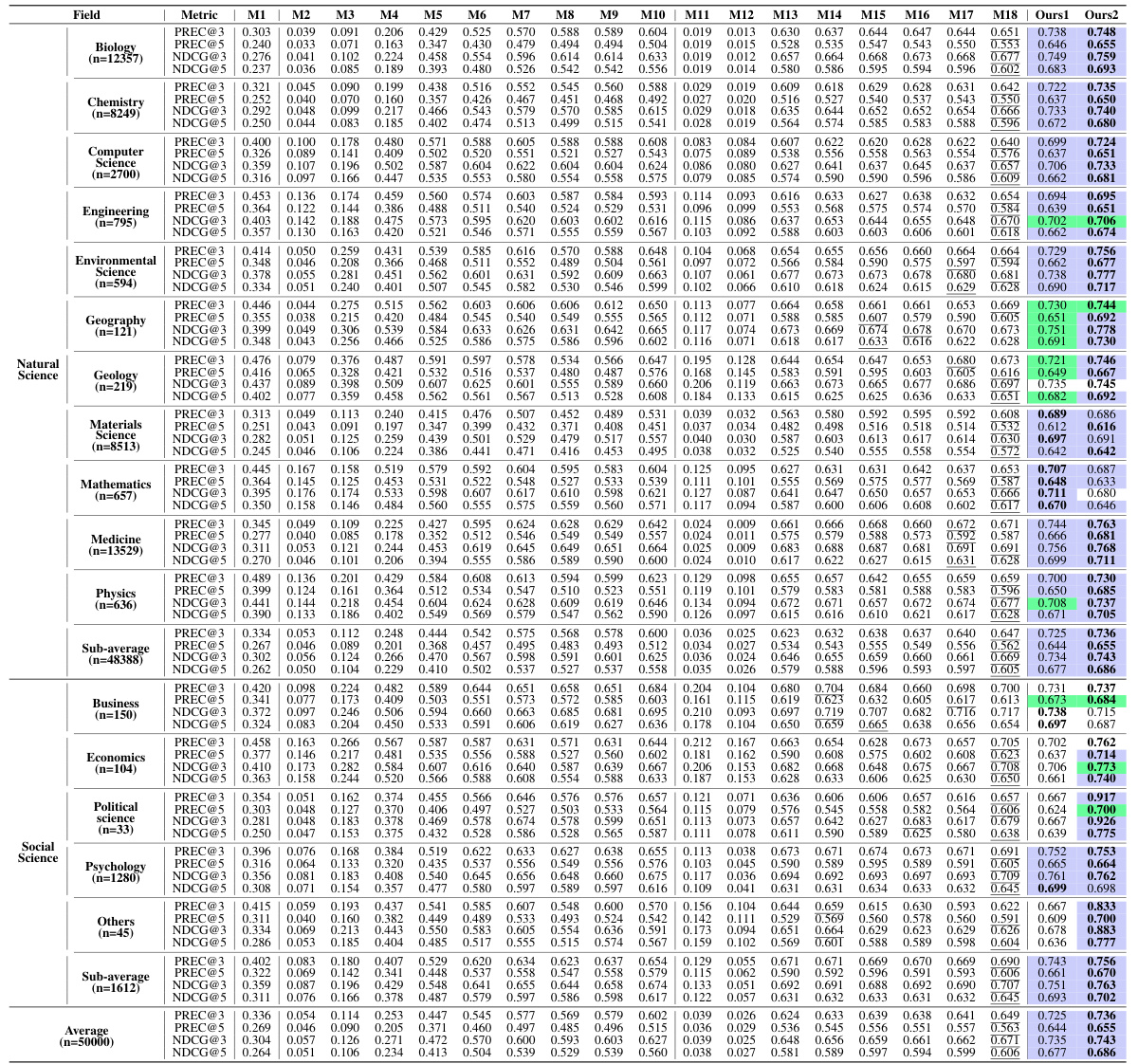
🔼 This table presents the overall performance of the proposed HLM-Cite model and various baseline models across three categories: simple rule-based methods, LMs specifically designed for scientific texts, and pretrained LMs for general-purpose tasks. The performance is evaluated using PREC@3/5 and NDCG@3/5 metrics for both natural science and social science datasets, as well as overall performance across both domains. The results show a significant performance improvement of the HLM-Cite model in comparison to other methods.
read the caption
Table 2: Overall performance. Bold and underline indicate the best and second best performance.
🔼 This table presents the statistics of the dataset used in the paper’s experiments. It shows the number of query papers and candidate papers in both the training and testing sets, categorized by scientific domain (natural science and social science). The total number of papers used for training and testing is also provided.
read the caption
Table 1: Dataset statistics

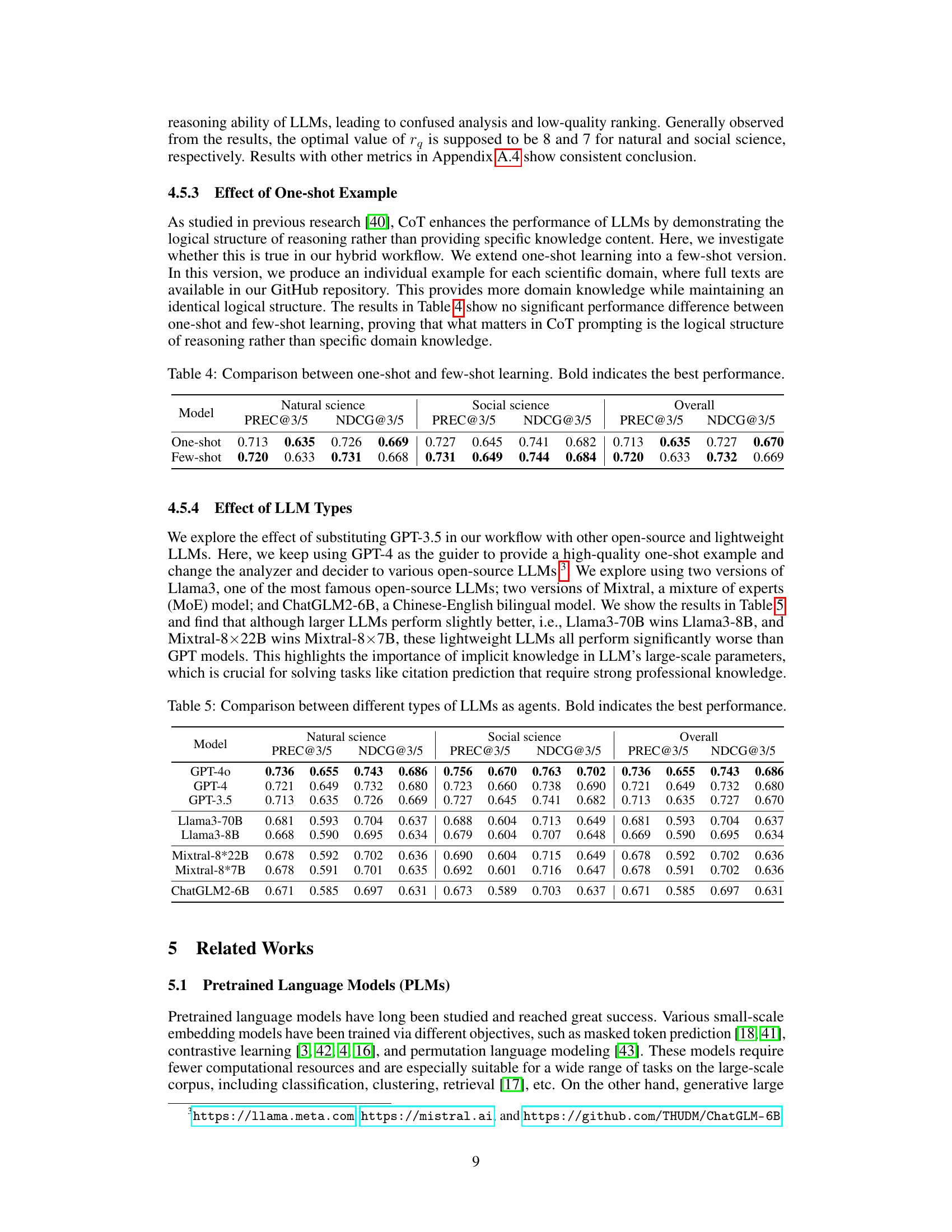
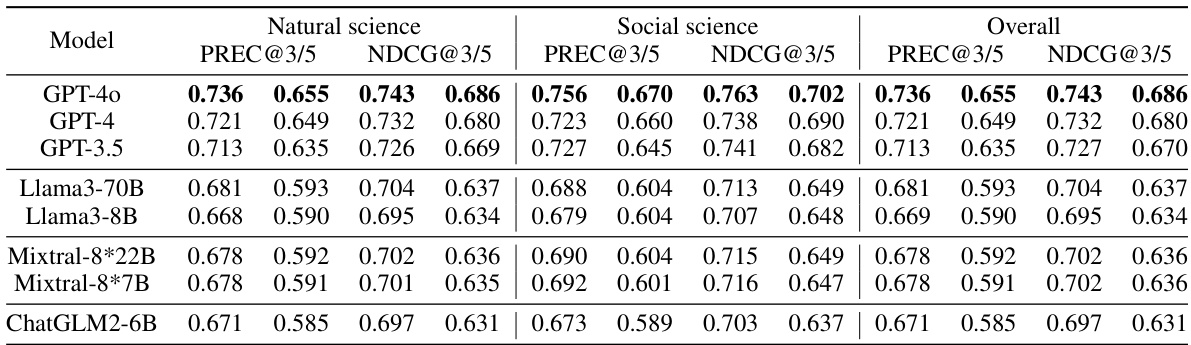
🔼 This table compares the performance of the HLM-Cite model using one-shot learning versus few-shot learning. The results are broken down by scientific domain (natural science and social science) and overall performance, showing PREC@3/5 and NDCG@3/5 scores. The bold values indicate the best performance for each metric and category, demonstrating the minimal impact of transitioning from one-shot to few-shot learning on the model’s accuracy.
read the caption
Table 4: Comparison between one-shot and few-shot learning. Bold indicates the best performance.
🔼 This table presents the overall performance of the proposed HLM-Cite method and several baseline methods across three categories: simple rule-based methods, Language Models specifically designed for scientific texts, and pretrained Language Models for general-purpose tasks. The performance is evaluated using PREC@3/5 and NDCG@3/5 metrics, for both natural and social science domains, as well as overall. The results show that the HLM-Cite method significantly outperforms all baselines.
read the caption
Table 2: Overall performance. Bold and underline indicate the best and second best performance.
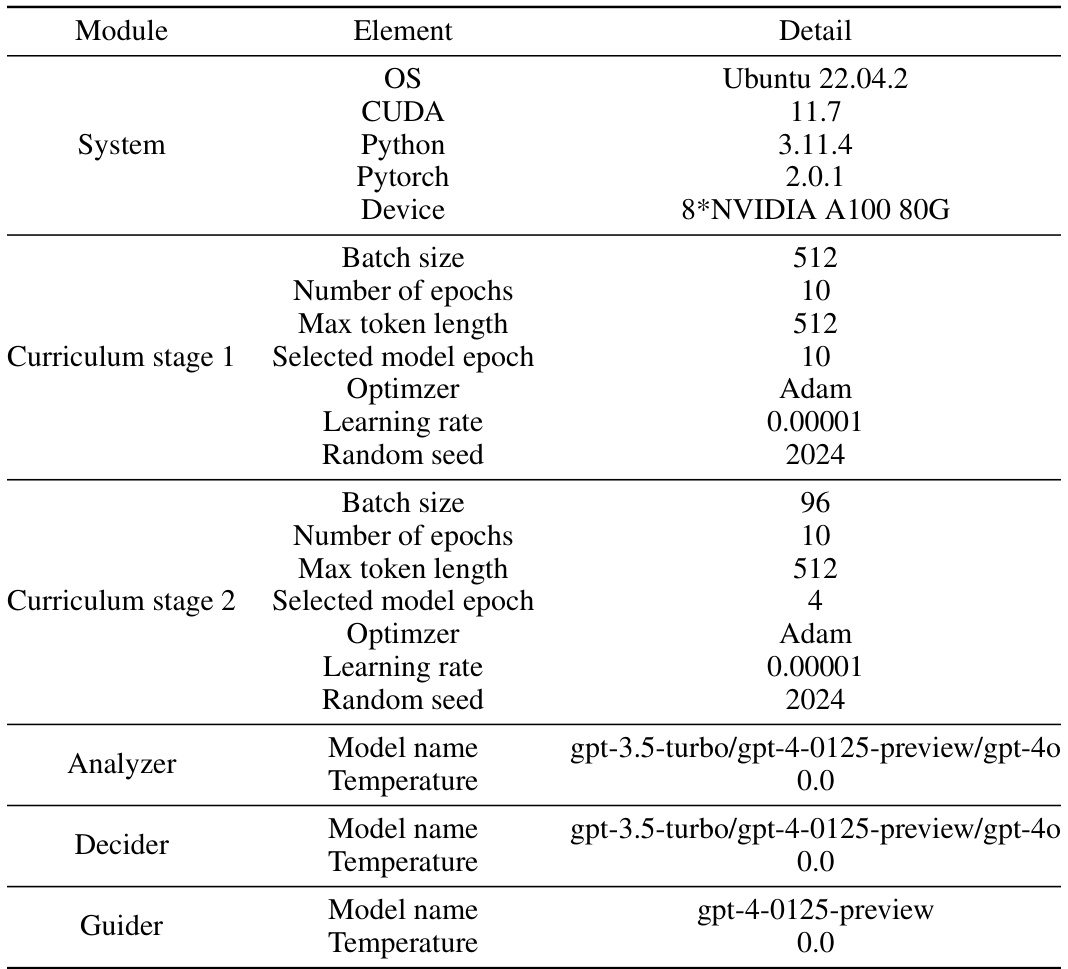
🔼 This table provides detailed information about the experimental setup and hyperparameters used in the study. It covers the operating system, software versions, hardware specifications, and the settings for each stage of the curriculum finetuning process, as well as the parameters for the LLM agents used in the ranking module.
read the caption
Table 6: Implementation details

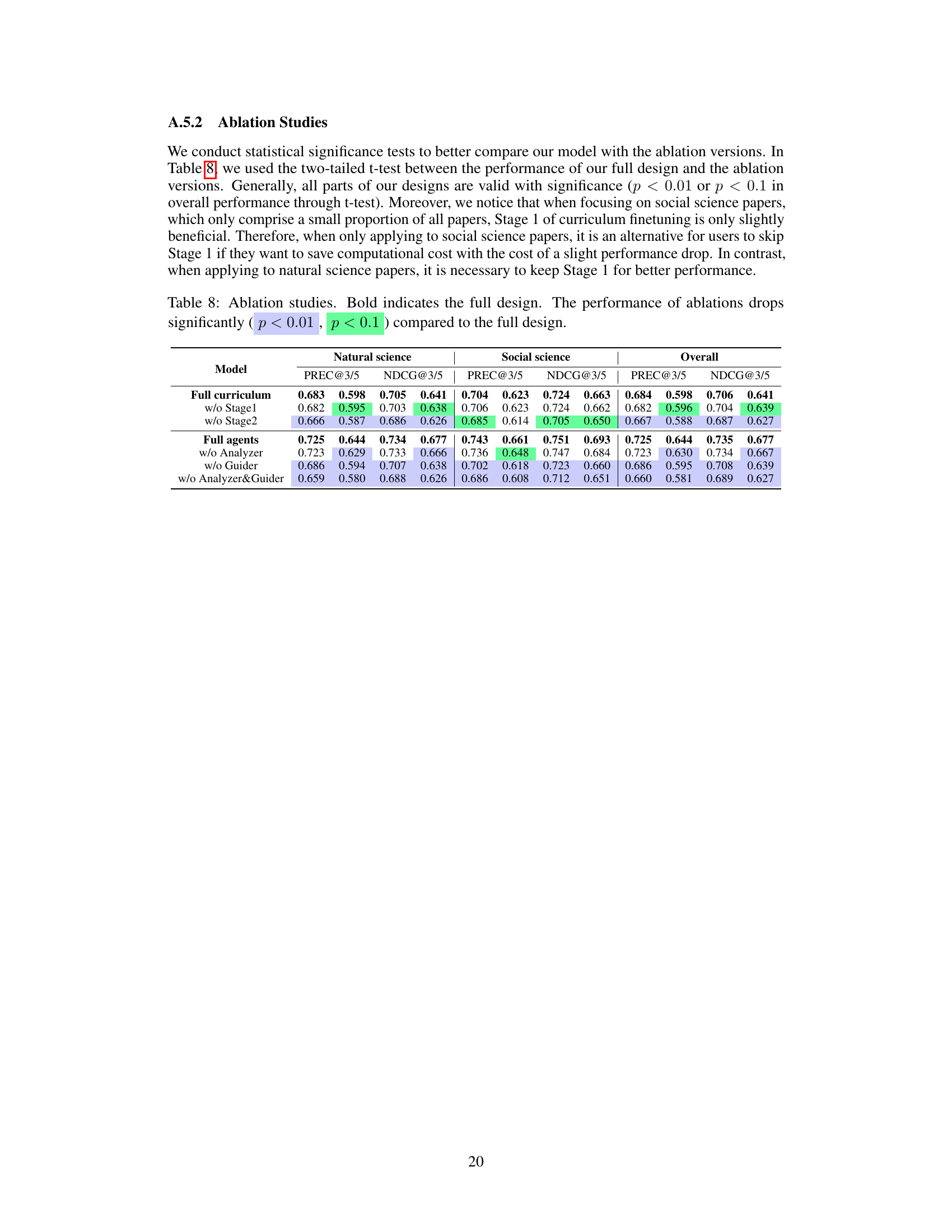
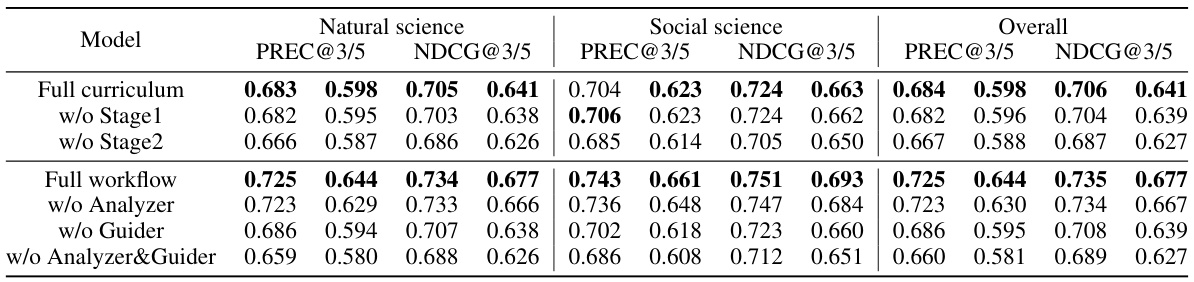
🔼 This table presents the results of ablation studies conducted to evaluate the impact of different components of the proposed HLM-Cite workflow. The ‘Full curriculum’ row shows the performance of the complete model. Subsequent rows show performance when either stage 1 or stage 2 of the curriculum finetuning is removed, or when the LLM agents (Analyzer, Decider, or Guider) are removed. The results demonstrate the contribution of each component to the overall performance.
read the caption
Table 3: Ablation studies. Bold indicates the best performance.
Full paper#