TL;DR#
Current text-to-image models often struggle to generate images that accurately reflect the input text prompts. This misalignment stems from the models’ failure to fully grasp all the concepts in a prompt (concept ignorance) and from incorrectly mapping those concepts to the generated image (concept mismapping). This paper introduces CoMat, a novel fine-tuning method designed to alleviate both of these issues.
CoMat enhances text-to-image alignment by incorporating a mechanism that matches concepts from the image back to the text prompt. This helps to ensure the model correctly interprets and represents all elements within the prompt. The method also includes a module to concentrate attributes, which strengthens the alignment of concepts with the corresponding regions of the generated image. Results from experiments on three different benchmarks demonstrate that CoMat significantly improves upon existing models, leading to more accurate and high-fidelity image generation.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a critical problem in text-to-image generation: misalignment between text prompts and generated images. By introducing a novel fine-tuning strategy with an image-to-text concept matching mechanism, it significantly improves the quality and accuracy of image generation, paving the way for more realistic and faithful AI art. This is relevant to current research trends focusing on improving the alignment and controllability of generative models and opens new avenues for research into more robust and versatile AI image generation techniques.
Visual Insights#

🔼 This figure shows a comparison of image generation results between the baseline model SDXL and the proposed model CoMat. For several different text prompts, both models generated images. The figure demonstrates that CoMat generates images that are more closely aligned with the text prompt than SDXL. This highlights CoMat’s improved ability to accurately reflect the input text in the generated image.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.
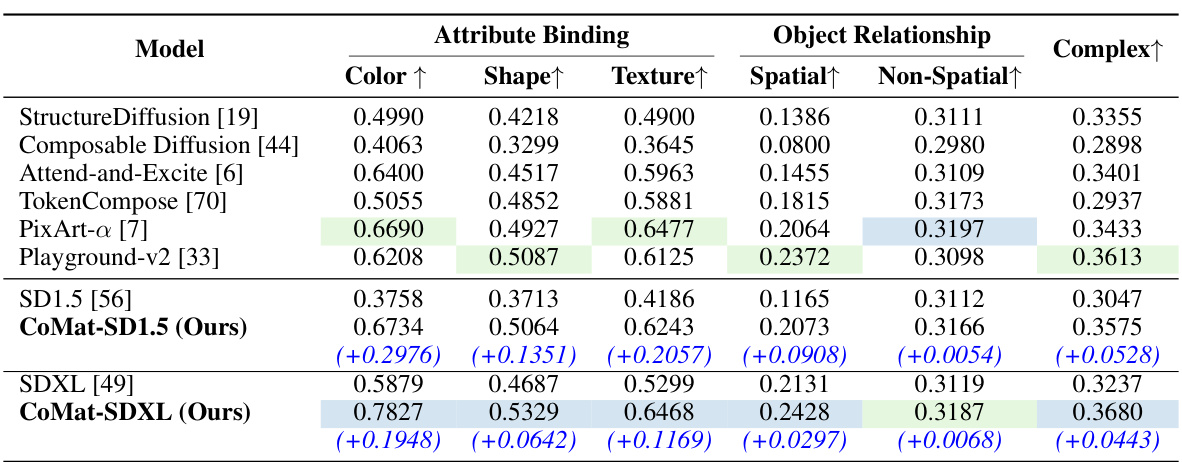
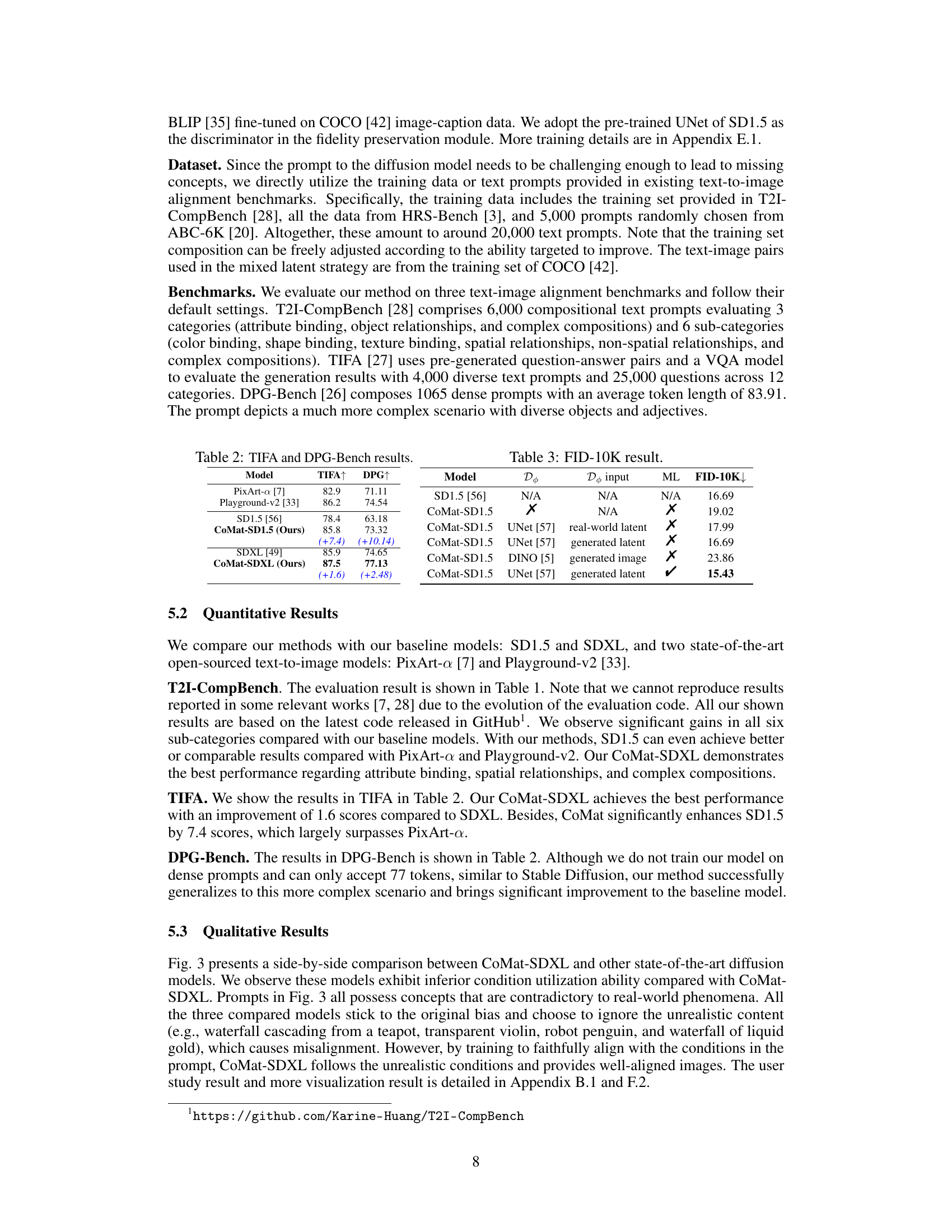
🔼 This table presents the quantitative results of the proposed CoMat model and other state-of-the-art models on the T2I-CompBench benchmark. T2I-CompBench evaluates text-to-image alignment across six sub-categories: color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions. The table shows the performance of each model in each sub-category, highlighting the best and second-best scores. The improvements achieved by CoMat-SD1.5 and CoMat-SDXL over their respective baseline models (SD1.5 and SDXL) are also indicated.
read the caption
Table 1: T2I-CompBench result. The best score is in blue, with the second-best score in green
In-depth insights#
CoMat Framework#
The CoMat framework presents a novel approach to enhance the alignment between text prompts and generated images in text-to-image diffusion models. It tackles the core issues of concept ignorance and concept mismapping, which often lead to misaligned outputs. CoMat cleverly employs an image-to-text concept activation module to guide the diffusion model toward generating images that fully capture the intended concepts, addressing concept ignorance. Simultaneously, an attribute concentration module ensures that generated image attributes are correctly mapped to their corresponding entities in the image, resolving the concept mismapping problem. This end-to-end fine-tuning strategy avoids additional overhead during inference, making it efficient and practical. Furthermore, the framework incorporates fidelity preservation and mixed latent learning mechanisms to maintain the generation quality of the diffusion model, mitigating issues like catastrophic forgetting. In essence, CoMat offers a comprehensive and holistic solution to improve the accuracy and fidelity of text-to-image generation, demonstrating significant improvements over state-of-the-art models in benchmark evaluations.
Concept Activation#
The core idea behind ‘Concept Activation’ is to mitigate the issue of concept ignorance in text-to-image diffusion models. It directly addresses the problem where the model fails to incorporate all concepts present in the text prompt into the generated image. The proposed solution ingeniously leverages a pre-trained image-to-text model as a supervisory signal. By feeding the generated image back into this image-to-text model, the system can assess the presence and representation of each concept from the initial prompt. This comparison between the prompt and the image caption reveals potential gaps in the model’s understanding. Crucially, this discrepancy guides the training process, forcing the diffusion model to re-examine underrepresented or missed concepts during subsequent image generation iterations. This approach allows the model to dynamically adjust its attention mechanism towards the initially ignored concepts, ultimately fostering a stronger correspondence between the text prompt and the resulting image. It’s a clever feedback loop that uses a second model to enhance the first. The efficacy of this method is demonstrated through attention visualization, clearly showcasing the increased focus on previously overlooked textual elements within the improved image generation process.
Attribute Focus#
An “Attribute Focus” section in a research paper would likely delve into how the model handles and prioritizes different attributes within a description. This is crucial for text-to-image generation, as the success hinges on accurately translating textual attributes (e.g., color, texture, size, shape) into visual elements. The discussion might explore techniques for attribute weighting, where certain attributes are deemed more important than others for image generation. Attention mechanisms, used widely in deep learning, could play a key role, potentially focusing model attention on specific attributes during different stages of image synthesis. Furthermore, the section would likely cover the challenges of attribute conflict—situations where multiple attributes are contradictory—and the methods implemented to resolve such conflicts. Qualitative and quantitative analyses of the model’s performance with respect to various attributes would provide insights into its strengths and weaknesses. Finally, the “Attribute Focus” section might discuss the overall impact of attribute processing on the model’s coherence, fidelity, and diversity of generated images.
Model Fidelity#
Model fidelity, in the context of text-to-image diffusion models, refers to how well the generated image aligns with the user’s textual prompt. A high-fidelity model produces images that accurately reflect the specified objects, attributes, relationships, and overall scene described in the prompt. Low fidelity, conversely, manifests as misalignments, omissions, or hallucinations in the generated image. Factors influencing model fidelity include the quality of the text encoder, the training data’s diversity and quality, and the model’s architecture itself. Addressing low fidelity is a crucial challenge in the field, often tackled through techniques such as fine-tuning, reinforcement learning, or the incorporation of external knowledge sources. The trade-off between fidelity and other desirable properties like diversity and creativity also needs careful consideration. Measuring fidelity requires robust evaluation metrics that go beyond simple visual assessment and capture the nuances of semantic correspondence between the text and image. Research in this area is actively exploring methods to improve both the quantitative and qualitative aspects of model fidelity, aiming for systems that are both accurate and imaginative.
Future Works#
The authors suggest several promising avenues for future research. Extending the model to handle videos is a natural progression, leveraging advancements in multimodal large language models and video segmentation techniques. This would involve adapting the concept activation and attribute concentration modules to the spatiotemporal dynamics of video data. Another critical area is improving the efficiency of the training process. The current training time is considerable; exploring optimization techniques or alternative training paradigms is crucial for broader adoption. Finally, there is a need to address the limitations of the attribute concentration module’s inability to handle multiple same-name objects. This requires more sophisticated object recognition and segmentation methods, possibly incorporating advanced computer vision techniques. Successfully addressing these aspects would strengthen the model’s capabilities and significantly broaden its applicability.
More visual insights#
More on figures

🔼 This figure compares the attention mechanism of the SDXL model and the CoMat-SDXL model. The left panel shows the generated images from SDXL and CoMat-SDXL. The middle panel shows a bar chart illustrating the attention activation values for different tokens (red, cap, gown, guitar) in the text prompt. The right panel displays the attention maps for the token ‘red’ in both models. The results show that CoMat-SDXL improves token activation and better aligns the attention map with the corresponding regions in the generated image.
read the caption
Figure 2: Visualization of token activation and attention map. We compare the tokens' attention activation value and attention map before and after applying our methods. Our method improves token activation and encourages the missing concept 'gown' to appear. Furthermore, the attention map of the attribute token 'red' better aligns with its region in the image.

🔼 This figure compares the image generation results of CoMat-SDXL with three other state-of-the-art text-to-image models (SDXL, Playground v2, PixArt-Alpha) on four different prompts. Each row shows the images generated by each model for the same prompt. The figure demonstrates that CoMat-SDXL consistently generates images that are more aligned with the textual descriptions compared to the other models.
read the caption
Figure 3: We showcase the results of our CoMat-SDXL compared with other state-of-the-art models. CoMat-SDXL consistently generates more faithful images.
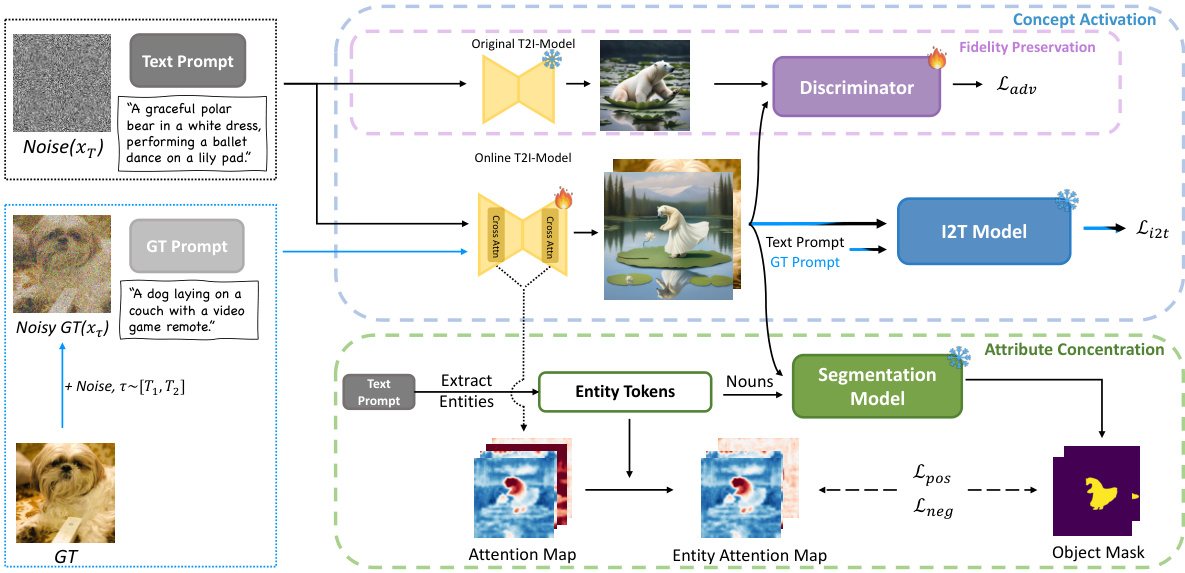
🔼 This figure provides a detailed overview of the CoMat framework, which is an end-to-end diffusion model fine-tuning strategy designed to improve text-to-image alignment. The process starts with a text prompt fed into the original text-to-image diffusion model, which generates an initial image. This image is then processed through two key modules: the concept activation module and the attribute concentration module. The concept activation module leverages an image-to-text model to identify missing or underrepresented concepts in the generated image, allowing the model to refine its understanding. The attribute concentration module helps to correctly map attributes from the text to specific regions within the generated image. The outputs from these modules then guide the fine-tuning of the online text-to-image model, improving its overall alignment with the original text prompt.
read the caption
Figure 4: Overview of CoMat. The text-to-image diffusion model (T2I-Model) first generates an image according to the text prompt. Then the image is sent to the concept activation module and attribute concentration module to compute the loss for fine-tuning the online T2I-Model.
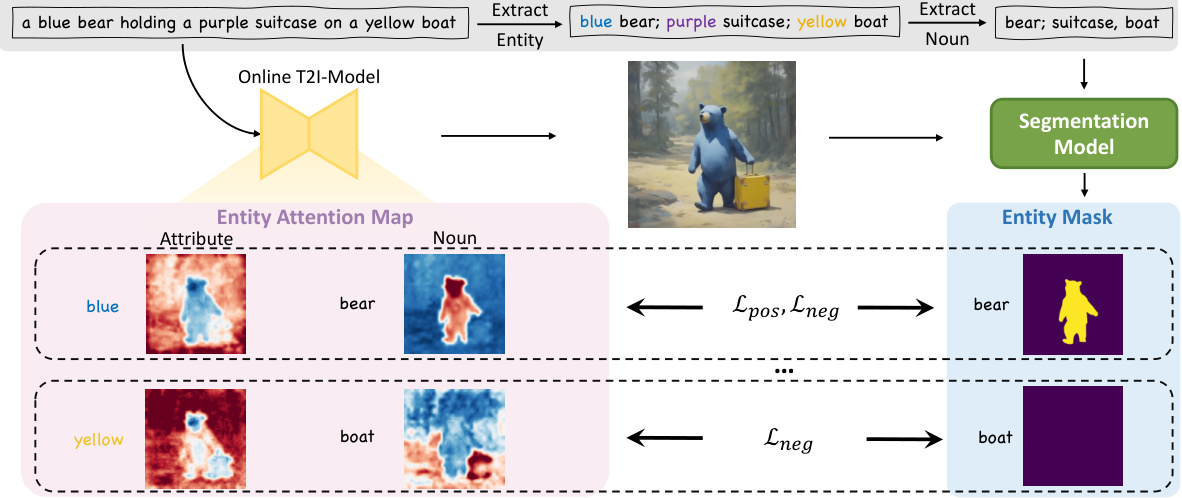
🔼 This figure shows the overall framework of CoMat, a text-to-image diffusion model fine-tuning strategy. It starts with a text prompt that is fed into the original text-to-image diffusion model (T2I-Model). This model generates an image based on the prompt. The generated image then goes through two key modules: the concept activation module and the attribute concentration module. These modules calculate a loss function that is used to fine-tune an online version of the T2I model, improving its ability to accurately reflect the text prompt in the generated image. The figure shows the flow of data through these components and their interactions.
read the caption
Figure 4: Overview of CoMat. The text-to-image diffusion model (T2I-Model) first generates an image according to the text prompt. Then the image is sent to the concept activation module and attribute concentration module to compute the loss for fine-tuning the online T2I-Model.

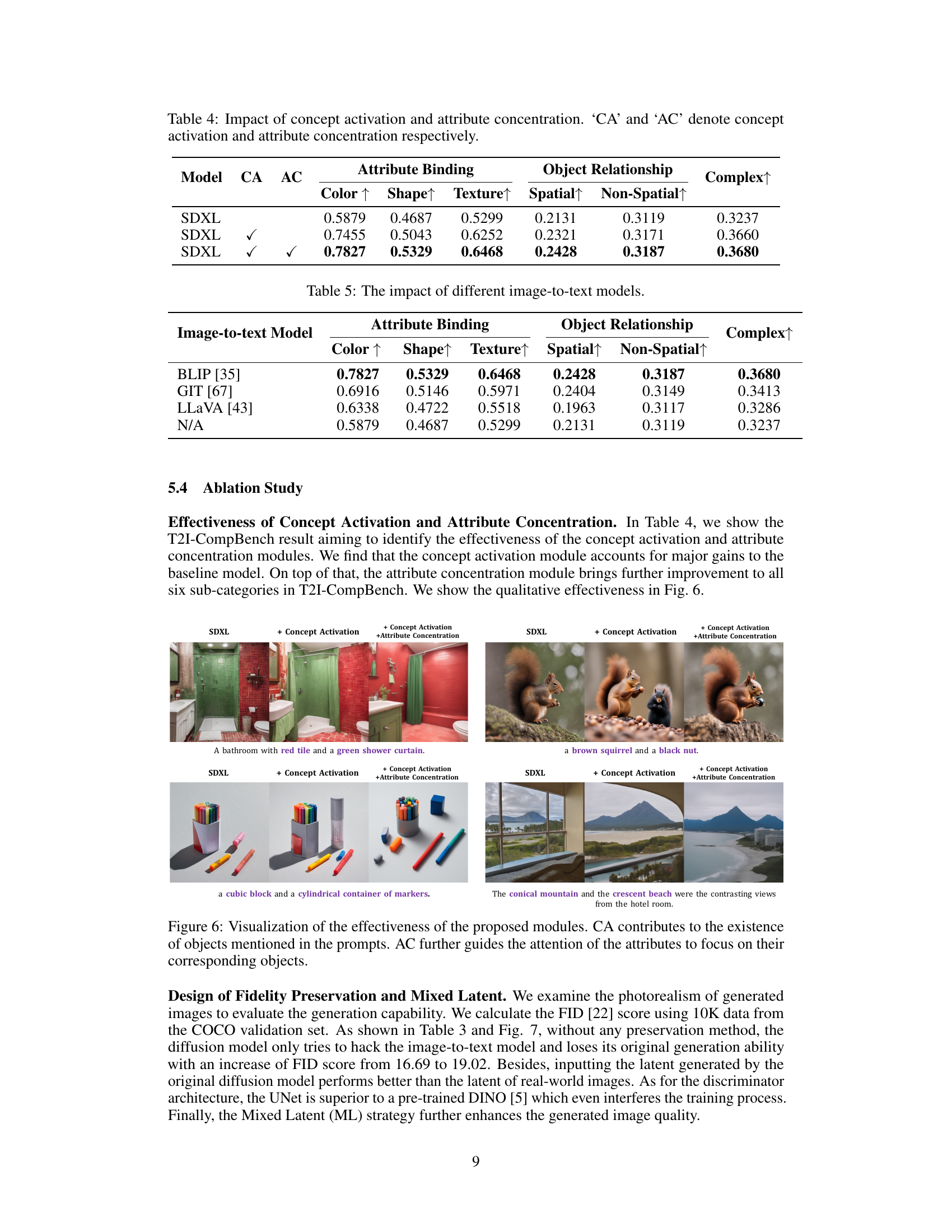
🔼 This figure shows examples of images generated by different models. The first column shows the baseline model, which sometimes misses objects or attributes mentioned in the prompt. The second column shows the model with concept activation, which improves the generation of objects. The third column shows the model with both concept activation and attribute concentration, which further improves the alignment of attributes with their corresponding objects. The results show the effectiveness of the proposed modules for aligning text and image concepts.
read the caption
Figure 6: Visualization of the effectiveness of the proposed modules. CA contributes to the existence of objects mentioned in the prompts. AC further guides the attention of the attributes to focus on their corresponding objects.

🔼 This figure visualizes how the Fidelity Preservation (FP) module and Mixed Latent (ML) strategy in CoMat affect the generated image quality. The left two images show a blue envelope and a white stamp. The images on the right show a black swan and a white lake. In both cases, the model without FP and ML generates misshaped objects, while CoMat with FP and ML generates more aligned images with better quality.
read the caption
Figure 7: Visualization result of the effectiveness of the Fidelity Preservation module (FP) and Mixed Latent (ML) strategy.
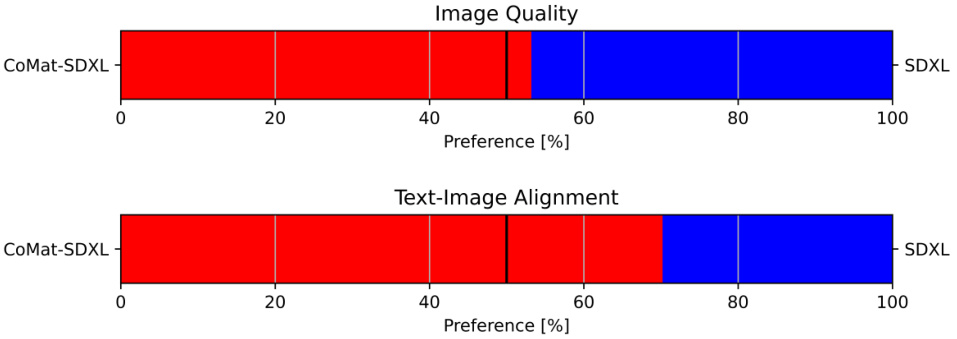
🔼 The figure shows the results of a user preference study comparing SDXL and CoMat-SDXL. Participants were asked to choose which model produced better image quality and better text-image alignment based on a set of prompts. The bar chart visualizes the percentage of participants who preferred each model for each aspect.
read the caption
Figure 8: User preference study results.
🔼 This figure shows a diagram of the CoMat model, highlighting its key components. The text-to-image diffusion model generates an initial image based on the given text prompt. This image is then fed into two modules: the concept activation module and the attribute concentration module. These modules calculate a loss function that is used to fine-tune the online T2I model, improving its ability to generate images that accurately reflect the input text prompt. The diagram visually represents the workflow of CoMat, illustrating how the different components interact and contribute to improved text-to-image alignment.
read the caption
Figure 4: Overview of CoMat. The text-to-image diffusion model (T2I-Model) first generates an image according to the text prompt. Then the image is sent to the concept activation module and attribute concentration module to compute the loss for fine-tuning the online T2I-Model.

🔼 This figure shows image generation results from the SDXL model and the proposed CoMat model. Four text prompts are used, and for each prompt, the image generated by each model is shown side-by-side. The images illustrate the improved alignment between the text prompt and generated image achieved with the CoMat method compared to the SDXL baseline. The superior performance of CoMat in faithfully representing the details and relationships described in the prompts is evident.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure shows a comparison between images generated by the state-of-the-art text-to-image diffusion model SDXL and the proposed model CoMat. Four different text prompts are used, and for each prompt, there are two generated images: one from SDXL and one from CoMat. The purpose is to demonstrate that CoMat produces images that are more closely aligned with the descriptions given in the text prompts. The same random seed was used to generate both pairs to ensure fair comparison.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure shows a comparison of image generation results between the state-of-the-art text-to-image diffusion model SDXL and the proposed method CoMat. Four different text prompts are used, and for each, the images generated by both models are displayed side-by-side. The images generated by CoMat demonstrate a significant improvement in alignment with the text prompts, showing that CoMat successfully addresses the misalignment problem often seen in text-to-image diffusion models. The same random seed was used for all image generations to ensure a fair comparison.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure shows examples of images generated by the state-of-the-art text-to-image diffusion model SDXL and the proposed model CoMat. The images were generated from the same text prompts to highlight the improvement in alignment between the generated image and the input text prompt. CoMat produces images that more closely match the descriptions given in the text prompts than SDXL.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure shows a comparison of images generated by the state-of-the-art text-to-image diffusion model SDXL and the proposed method CoMat. For each of four different text prompts, the figure displays the output of both SDXL and CoMat. The differences highlight CoMat’s improved ability to generate images that accurately reflect the details and relationships described in the text prompt. The use of the same random seed for both models allows for a direct comparison based solely on the models’ abilities to interpret the text instructions.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure presents a comparison of image generation results between the proposed CoMat-SDXL model and three other state-of-the-art text-to-image models (SDXL, Playground v2, and PixArt-Alpha). For each model, four example images are displayed, each generated from a different text prompt. The figure aims to demonstrate that CoMat-SDXL produces images that are more closely aligned with the corresponding text prompts than the other models, indicating a superior ability to generate faithful images.
read the caption
Figure 3: We showcase the results of our CoMat-SDXL compared with other state-of-the-art models. CoMat-SDXL consistently generates more faithful images.

🔼 This figure showcases the results of the SDXL model and the proposed CoMat model when generating images from the same set of text prompts. It visually demonstrates that the CoMat model significantly improves the alignment between the text prompt and the generated image compared to the SDXL model.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure showcases examples of images generated by the state-of-the-art text-to-image diffusion model SDXL and the proposed method CoMat. The top row shows SDXL struggling to correctly interpret and generate images according to the descriptive prompts. The bottom row illustrates CoMat’s improved ability to accurately reflect the textual input in the generated images. The same random seed was used for both models in each pair of images, highlighting CoMat’s superior performance.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.

🔼 This figure shows a comparison of images generated by the baseline text-to-image diffusion model (SDXL) and the proposed method (CoMat). Four different text prompts were used, and for each prompt, both models generated images. The figure demonstrates that CoMat produces images which are more faithful to the descriptions in the text prompts compared to SDXL, highlighting the effectiveness of the proposed method in improving text-image alignment.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.
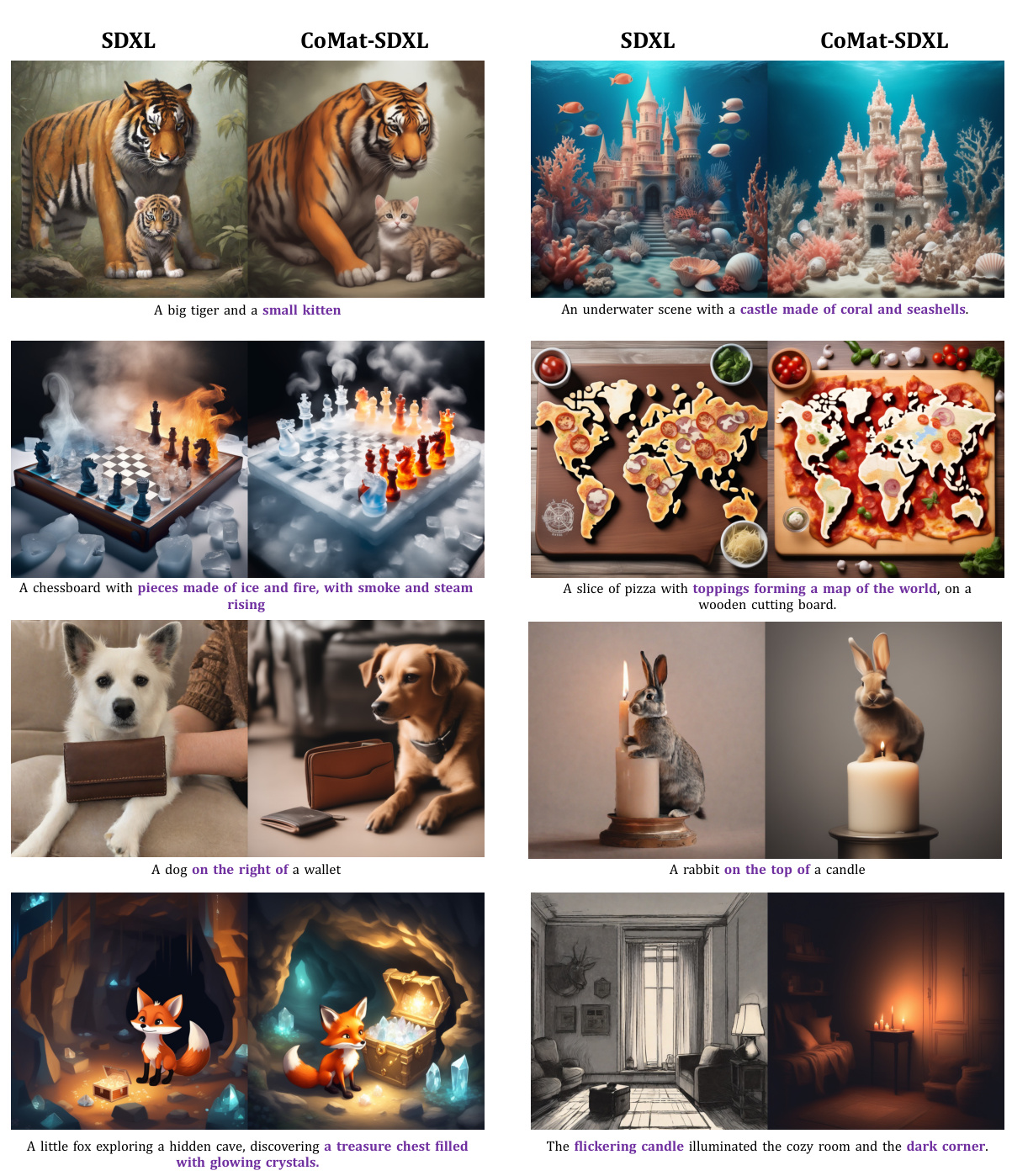
🔼 This figure showcases the limitations of current text-to-image diffusion models in aligning generated images with text prompts. It compares images generated by the SDXL model with those generated by the authors’ proposed CoMat model, using the same random seed for each prompt. The CoMat model produces images that more accurately reflect the content of the text prompts, highlighting its improved ability to align text and image.
read the caption
Figure 1: Current text-to-image diffusion model still struggles to produce images well-aligned with text prompts, as shown in the generated images of SDXL [49]. Our proposed method, CoMat, significantly enhances the baseline model on text condition following, demonstrating superior capability in text-image alignment. All the pairs are generated with the same random seed.
More on tables
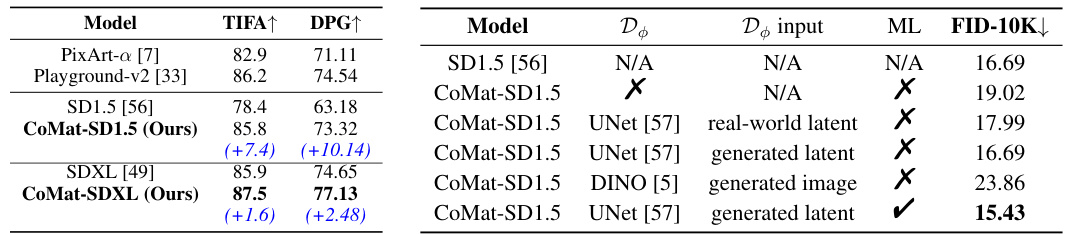
🔼 This table presents a comparison of the performance of different models on two benchmarks: TIFA (Text-to-Image Faithfulness Assessment) and DPG-Bench (Dense Prompt Generation Benchmark). The TIFA benchmark evaluates the alignment between generated images and textual descriptions, while DPG-Bench focuses on complex and detailed prompts. The table shows the scores achieved by each model on both benchmarks, illustrating the relative performance of each model in generating images that accurately reflect the given text instructions, particularly in the context of complex scenes and descriptions.
read the caption
Table 2: TIFA and DPG-Bench results.

🔼 This table presents the ablation study results focusing on the impact of concept activation (CA) and attribute concentration (AC) modules on the text-to-image alignment performance. It shows the performance improvement on six sub-categories of the T2I-CompBench benchmark (color, shape, texture, spatial, non-spatial, and complex) when either CA or AC module is added, or when both are combined. The baseline model is SDXL. The results demonstrate that both CA and AC contribute to improved alignment, with the combination yielding the best results.
read the caption
Table 4: Impact of concept activation and attribute concentration. 'CA' and 'AC' denote concept activation and attribute concentration respectively.
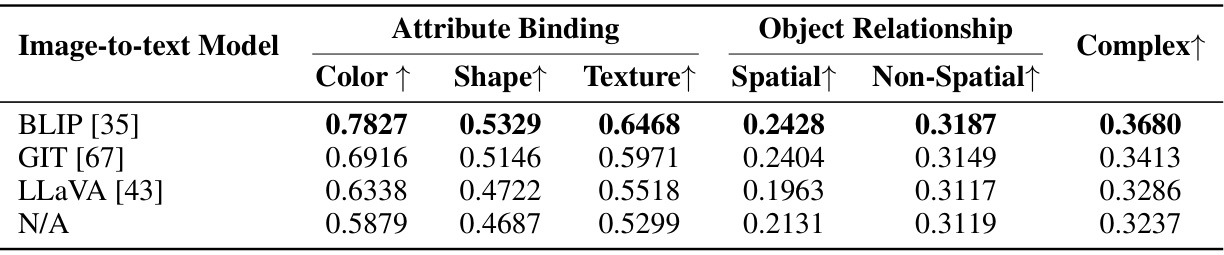
🔼 This table shows the impact of using different image-to-text models on the performance of the CoMat model. Specifically, it presents the results of the CoMat model on the T2I-CompBench benchmark, broken down by sub-categories (Color, Shape, Texture, Spatial, Non-Spatial) for Attribute Binding and Object Relationship, and an overall Complex score. The table compares results obtained when using the BLIP, GIT, and LLaVA image-to-text models with a baseline (N/A) that does not use an image-to-text model. The higher the score, the better the performance.
read the caption
Table 5: The impact of different image-to-text models.

🔼 This table presents the success rate of a prompt attack on two models: SD1.5 and CoMat-SD1.5. The attack method aims to generate misaligned images by crafting adversarial prompts. The success rate is defined as the percentage of generated images that are mistakenly classified by a visual classifier. Results are shown for both short and long prompts.
read the caption
Table 6: Success rate of prompt attack.
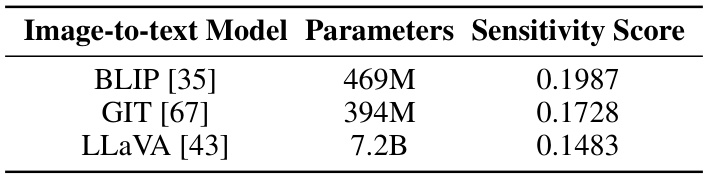
🔼 This table presents the number of parameters and sensitivity scores for three different image-to-text models: BLIP, GIT, and LLaVA. The sensitivity score reflects the models’ ability to distinguish between correct and incorrect image captions, indicating their suitability for use in the concept activation module of the CoMat model. Higher sensitivity scores suggest better performance.
read the caption
Table 7: Statistics of image-to-text models.
🔼 This table presents the results of the T2I-CompBench benchmark, a comprehensive evaluation of text-to-image alignment capabilities. It compares different models across six sub-categories of text-to-image alignment: color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions. The best and second-best scores for each sub-category are highlighted in blue and green respectively, offering a clear comparison of model performance across various aspects of alignment.
read the caption
Table 1: T2I-CompBench result. The best score is in blue, with the second-best score in green
Full paper#