↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are transformative but computationally expensive. Pruning, a model compression technique, introduces sparsity to enhance efficiency. However, traditional global pruning is not scalable for LLMs, while local pruning often yields suboptimal results due to its focus on individual layers rather than holistic optimization. This creates a need for a more efficient and effective method.
SparseLLM overcomes these limitations by redefining the global pruning process into coordinated subproblems, using auxiliary variables for problem decomposition. This allows resource-efficient optimization while maintaining global optimality. Experiments demonstrate that SparseLLM significantly improves performance compared to existing local pruning techniques, particularly when high sparsity levels are desired. The method is adaptable to different LLMs and readily integrates with various pruning algorithms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient large language model training because it introduces SparseLLM, a novel framework that effectively addresses the challenges of global pruning for LLMs. The framework’s versatility and minimal computational overhead make it a valuable tool for enhancing the performance of existing pruning methods, opening new avenues for research in LLM optimization.
Visual Insights#

This figure compares three different pruning methods: global pruning, local pruning, and SparseLLM. Global pruning attempts to prune the entire model at once, which is computationally expensive and impractical for large language models. Local pruning, on the other hand, prunes each layer independently, which can lead to suboptimal performance. SparseLLM addresses the limitations of both global and local pruning by decomposing the global pruning objective into multiple subproblems. Each subproblem can be solved independently, and the results are then combined to achieve a globally optimal solution. The use of auxiliary variables helps to maintain the dependencies between different layers and ensures that the pruning process is efficient and effective.

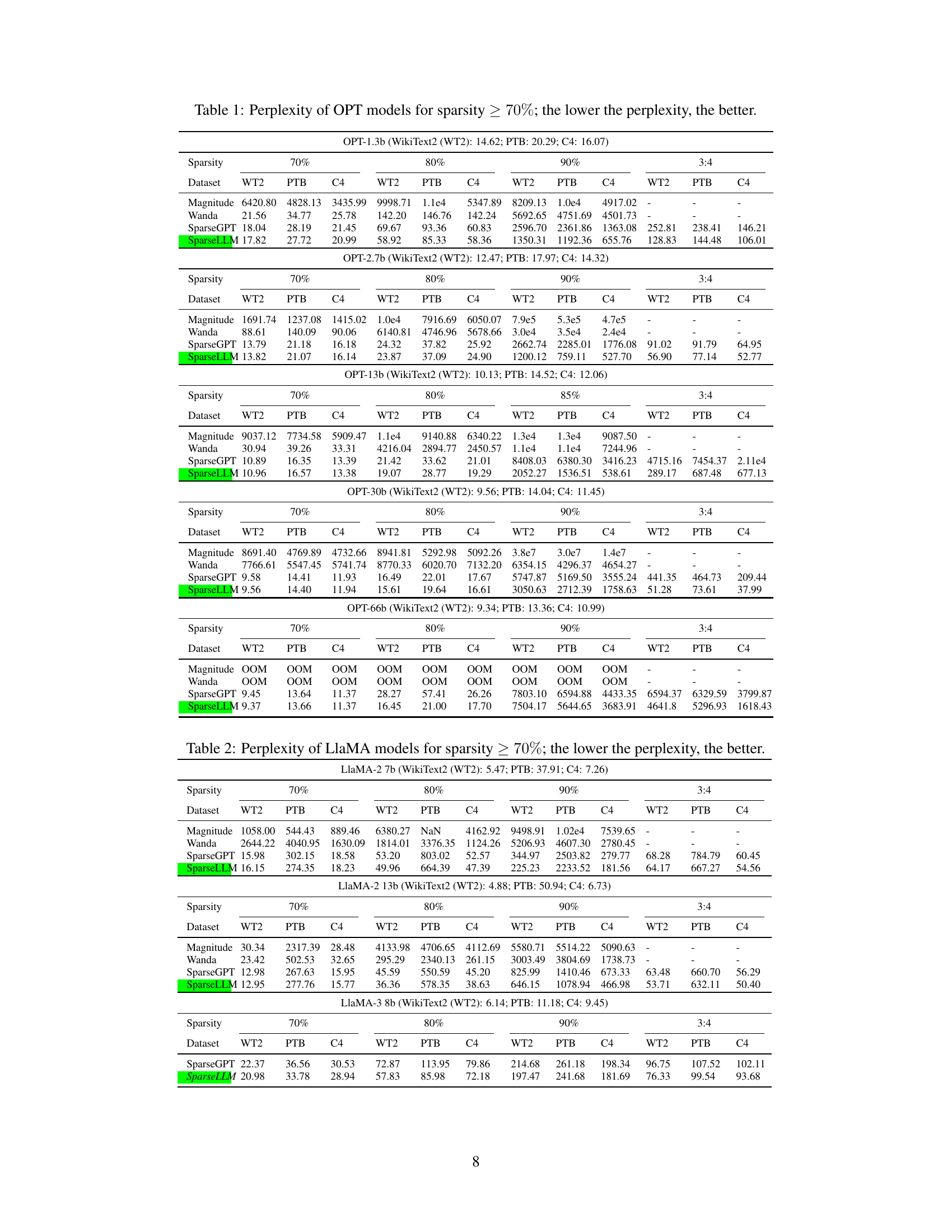
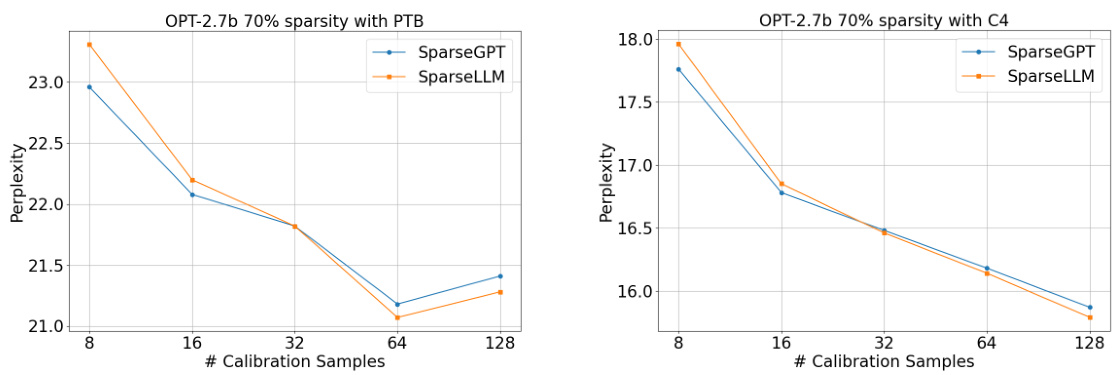
This table presents the perplexity scores achieved by different model pruning methods (Magnitude, Wanda, SparseGPT, and SparseLLM) on various OPT model sizes (1.3B, 2.7B, 13B, and 30B parameters) across three datasets (WikiText2, Penn Treebank, and C4). The results are broken down by sparsity levels (70%, 80%, 90%, and 3:4 semi-structured). Lower perplexity indicates better performance. The table allows for a comparison of the effectiveness of different pruning techniques under various sparsity constraints and model sizes.
In-depth insights#
Global Pruning#
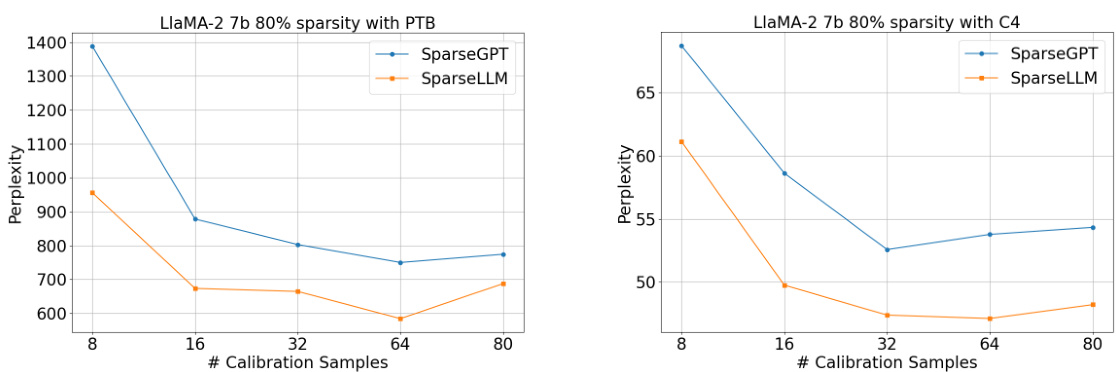
Global pruning, in the context of large language model (LLM) optimization, presents a significant challenge due to its computational demands. Traditional global pruning methods struggle with the sheer size of LLMs, often requiring the entire model to reside in a single GPU’s memory, which is impractical for billion-parameter models. This limitation motivates the exploration of alternative strategies that decompose the global pruning problem into smaller, more manageable subproblems. The core idea revolves around achieving global optimality despite the inherent computational constraints. This often involves reformulating the problem using auxiliary variables, allowing for distributed or iterative optimization approaches that maintain dependencies across layers while keeping memory usage low. The effectiveness of such strategies is often evaluated by measuring improvements in performance metrics (e.g., perplexity) at varying sparsity levels, particularly in high-sparsity regimes where traditional methods falter. SparseLLM exemplifies such an approach, demonstrating improved performance over existing local pruning methods and paving the way for computationally efficient global pruning of LLMs.
SparseLLM Framework#
The SparseLLM framework presents a novel approach to global pruning of large language models (LLMs) by decomposing the problem into manageable subproblems. This decomposition, achieved by conceptualizing LLMs as a chain of modular functions and introducing auxiliary variables, allows for resource-efficient optimization while aiming for global optimality. Unlike traditional global pruning, which is computationally expensive for LLMs, or local pruning, which can lead to suboptimal solutions, SparseLLM offers a balance. The framework’s core innovation lies in its ability to coordinate the solutions of these subproblems, ensuring that the overall pruned model maintains performance while significantly reducing model size and computational costs. A key strength is its adaptability, making it readily applicable to enhance existing local pruning methods. The use of auxiliary variables facilitates a pragmatic application to real-world LLMs, making SparseLLM a valuable tool for future research in model compression and resource-efficient LLM deployment. Its alternating optimization algorithm further contributes to its efficiency, leveraging closed-form solutions for each subproblem to ensure global convergence. The framework showcases promising results, significantly outperforming state-of-the-art methods, particularly in high-sparsity regimes.
OPT & LLAMA Results#
An analysis of OPT and LLAMA model results would likely reveal performance comparisons across different model sizes and sparsity levels. The results section would likely present perplexity scores on standard benchmarks like WikiText2 and PTB, illustrating how well the pruned models maintain language understanding. Zero-shot accuracy on various tasks would be another key metric, showing the impact of pruning on downstream applications. A crucial aspect would be the comparison with baselines—unpruned models, magnitude pruning, SparseGPT, and Wanda—to highlight the effectiveness of the proposed method, especially at high sparsity levels. The discussion might delve into reasons behind performance gains or losses, such as the impact of pruning strategy and the model architecture’s influence on sparsity tolerance. Convergence speed and computational efficiency of the proposed method are further critical factors for analysis.
Limitations#
A critical analysis of the limitations section in a research paper requires careful consideration of several aspects. Firstly, the explicit acknowledgment of limitations demonstrates intellectual honesty and strengthens the paper’s credibility. Secondly, the depth and specificity of the limitations discussed directly impacts the overall assessment of the research’s validity. Superficial statements regarding limitations weaken the argument, whereas a thoughtful exploration of potential flaws, methodological constraints, and scope restrictions shows a thorough understanding of the study’s context. Thirdly, the discussion of limitations should connect directly back to the claims and conclusions made in the paper, indicating a clear understanding of how the identified limitations might influence or affect the overall findings. Finally, a robust limitations section suggests a path towards future research by highlighting areas needing further investigation or improvements to the methodology, strengthening the impact and longevity of the research presented.
Future Work#
Future research directions stemming from SparseLLM could explore several avenues. Extending SparseLLM to handle heterogeneous sparsity patterns, where different layers exhibit varying degrees of sparsity, would enhance its flexibility and potentially improve performance. Currently, SparseLLM primarily focuses on unstructured pruning. Investigating structured pruning methods in conjunction with SparseLLM’s decomposition approach could lead to further efficiency gains and better hardware compatibility. Incorporating SparseLLM into a dynamic inference scheme would allow for adaptive sparsity adjustments during runtime, optimizing resource allocation based on the specific input. Finally, a thorough investigation into the theoretical guarantees and convergence properties of SparseLLM’s alternating optimization algorithm is crucial for establishing its robustness and reliability, paving the way for broader applications and wider adoption.
More visual insights#
More on figures

This figure illustrates how SparseLLM decomposes the global pruning problem of LLMs into smaller, manageable subproblems. It shows the architecture for both OPT and LLaMA models, highlighting the use of auxiliary variables and soft constraints (≈) to maintain dependencies between subproblems while allowing for efficient, parallel optimization. The analytical solvability of these subproblems contributes to the fast convergence of the SparseLLM algorithm.
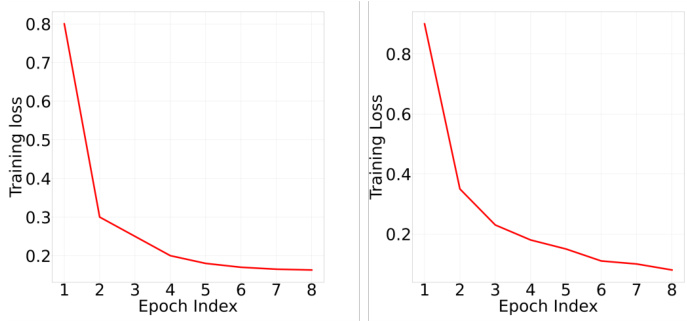
This figure demonstrates the rapid convergence of the SparseLLM algorithm during training. The left panel shows the training loss for pruning layer 3 of the OPT-125m model at 80% sparsity, while the right panel shows the training loss for pruning layer 6 of the LlaMA-2 13b model at 70% sparsity. In both cases, the training loss decreases significantly within the first few epochs, illustrating the algorithm’s efficiency in achieving a global optimal solution quickly.

This figure illustrates how SparseLLM, a novel global pruning framework, handles the decomposition of the global pruning problem into smaller, more manageable subproblems. It showcases how the framework operates on both OPT and LLAMA architectures by leveraging auxiliary variables and soft constraints (represented by the ≈ symbol) to maintain dependencies between subproblems. The use of auxiliary variables allows for an efficient optimization process, resulting in faster convergence and analytically solvable subproblems. This decomposition is crucial for handling the computational challenges posed by large language models (LLMs) and allows for global pruning without the excessive memory requirements of traditional global pruning methods.

This figure compares three different pruning methods: global pruning, local pruning, and the proposed SparseLLM method. Global pruning is shown to be memory-prohibitive due to its need to consider all layers simultaneously. Local pruning, while memory efficient, sacrifices performance by ignoring global relationships between layers. SparseLLM addresses these issues by employing auxiliary variables and soft constraints to decompose the global pruning problem into more manageable subproblems, allowing for both resource efficiency and the preservation of global optimality.
This figure illustrates how SparseLLM, a novel global pruning framework, decomposes the global pruning problem into smaller, manageable subproblems for both OPT and LLAMA architectures. It uses auxiliary variables and soft constraints (represented by ≈) to maintain dependencies between these subproblems, allowing for efficient optimization. The method is designed to be analytically solvable, leading to faster convergence compared to traditional global pruning approaches which suffer from scalability issues and suboptimal performance.
This figure illustrates the SparseLLM framework applied to both OPT and LLAMA models. It highlights how auxiliary variables and soft constraints are used to break down the global pruning problem into smaller, more manageable subproblems. This decomposition allows for efficient optimization, maintaining the dependencies between the subproblems. The figure emphasizes that the resulting subproblems have analytically solvable solutions, leading to faster convergence during the optimization process.
More on tables

This table presents the perplexity scores achieved by different LLM pruning methods (Magnitude, Wanda, SparseGPT, and SparseLLM) on various LlaMA model sizes (7B, 13B) across different sparsity levels (70%, 80%, 90%, and 3:4). The perplexity is a metric used to evaluate the performance of language models, and lower scores indicate better performance. The table allows for a comparison of the different methods’ effectiveness in reducing model size while maintaining performance, particularly at high sparsity levels.

This table presents the perplexity scores for various OPT and LLAMA models at a 2:4 sparsity level. Lower perplexity indicates better performance. The results are compared across different datasets (WT2, PTB, C4) and methods (Magnitude, Wanda, SparseGPT, SparseLLM). It shows how SparseLLM compares to other state-of-the-art local pruning methods at a lower sparsity level.

This table presents the perplexity scores achieved by different model pruning methods (Magnitude, Wanda, SparseGPT, and SparseLLM) on various OPT models (OPT-1.3B, OPT-2.7B, OPT-13B, OPT-30B, OPT-66B) with different sparsity levels (70%, 80%, 90%, and 3:4 semi-structured sparsity). The perplexity is a measure of how well the model predicts the next word in a sequence, with lower scores indicating better performance. The results are shown for three datasets: WikiText2 (WT2), Penn Treebank (PTB), and C4.
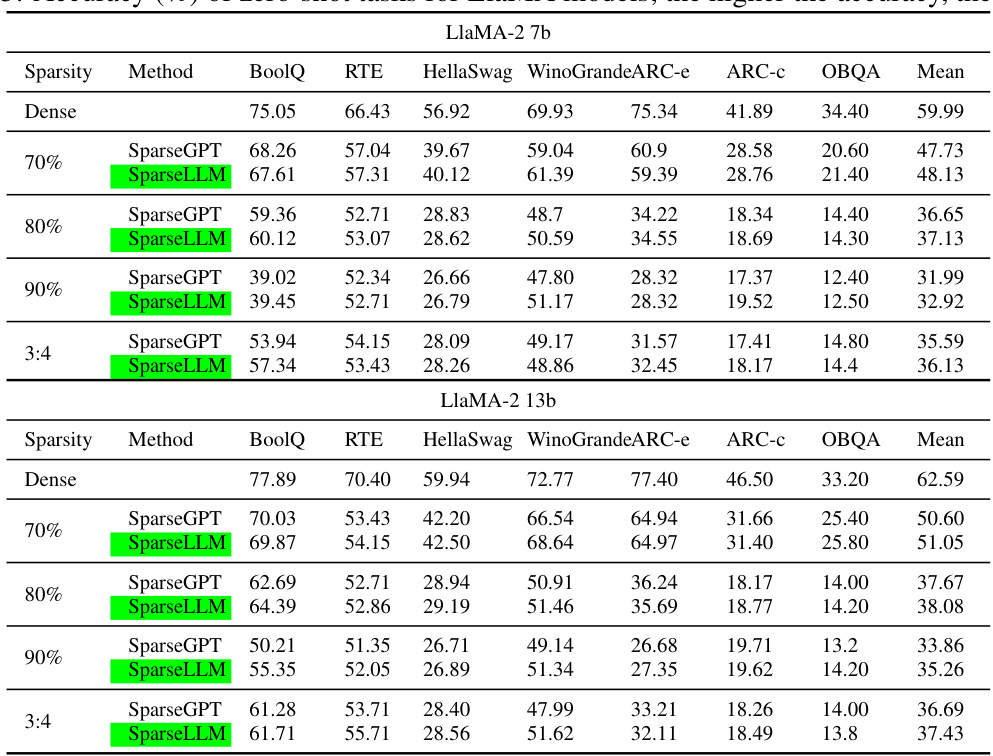
This table presents the perplexity scores achieved by different model pruning methods (Magnitude, Wanda, SparseGPT, and SparseLLM) on various LlaMA models (7B, 13B) at different sparsity levels (70%, 80%, 90%, and 3:4). The perplexity is a metric used to evaluate the performance of language models. Lower perplexity indicates better performance. The table allows for a comparison of the effectiveness of different pruning techniques in maintaining model performance while reducing model size.

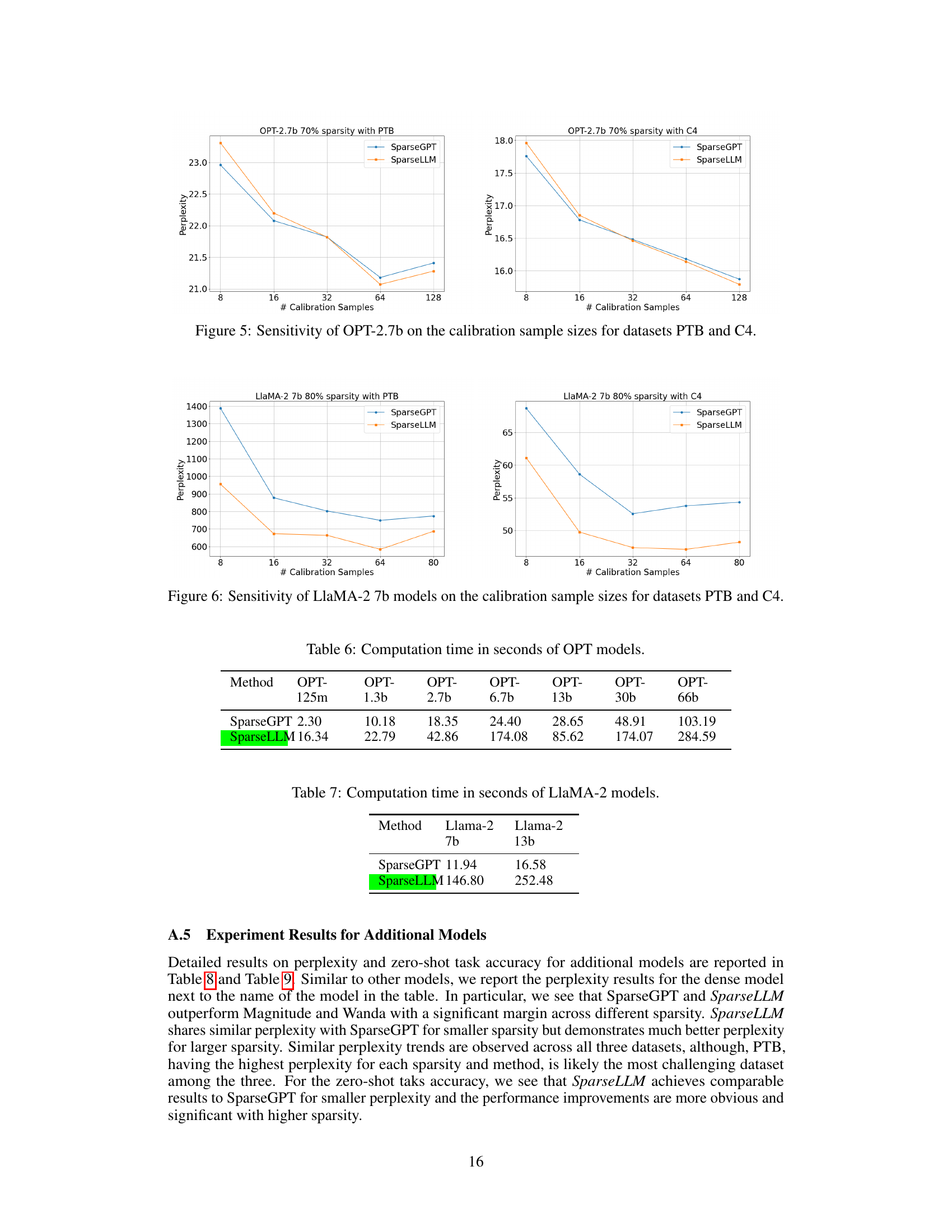
This table presents the computation time, in seconds, required for different OPT models using SparseGPT and SparseLLM methods. It shows how the computation time increases with model size for both methods.
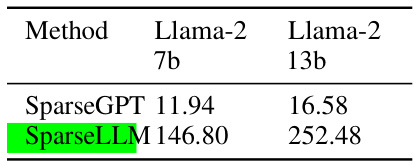
This table shows the computation time, in seconds, for SparseGPT and SparseLLM methods applied to Llama-2 models with 7 billion and 13 billion parameters. It provides a comparison of the computational efficiency of the two methods across different model sizes.

This table presents the perplexity scores achieved by different model pruning methods (Magnitude, Wanda, SparseGPT, and SparseLLM) on various OPT model sizes (1.3B, 2.7B, 13B, 30B, and 66B parameters) at different sparsity levels (70%, 80%, 90%, and 3:4). The perplexity is a metric measuring how well the model predicts the next word in a sequence, with lower scores indicating better performance. The table allows comparison of the effectiveness of these methods in reducing model size while preserving performance.
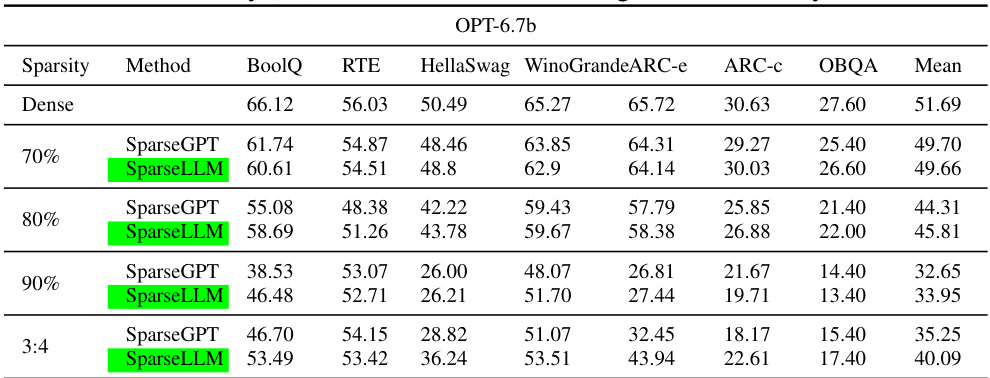
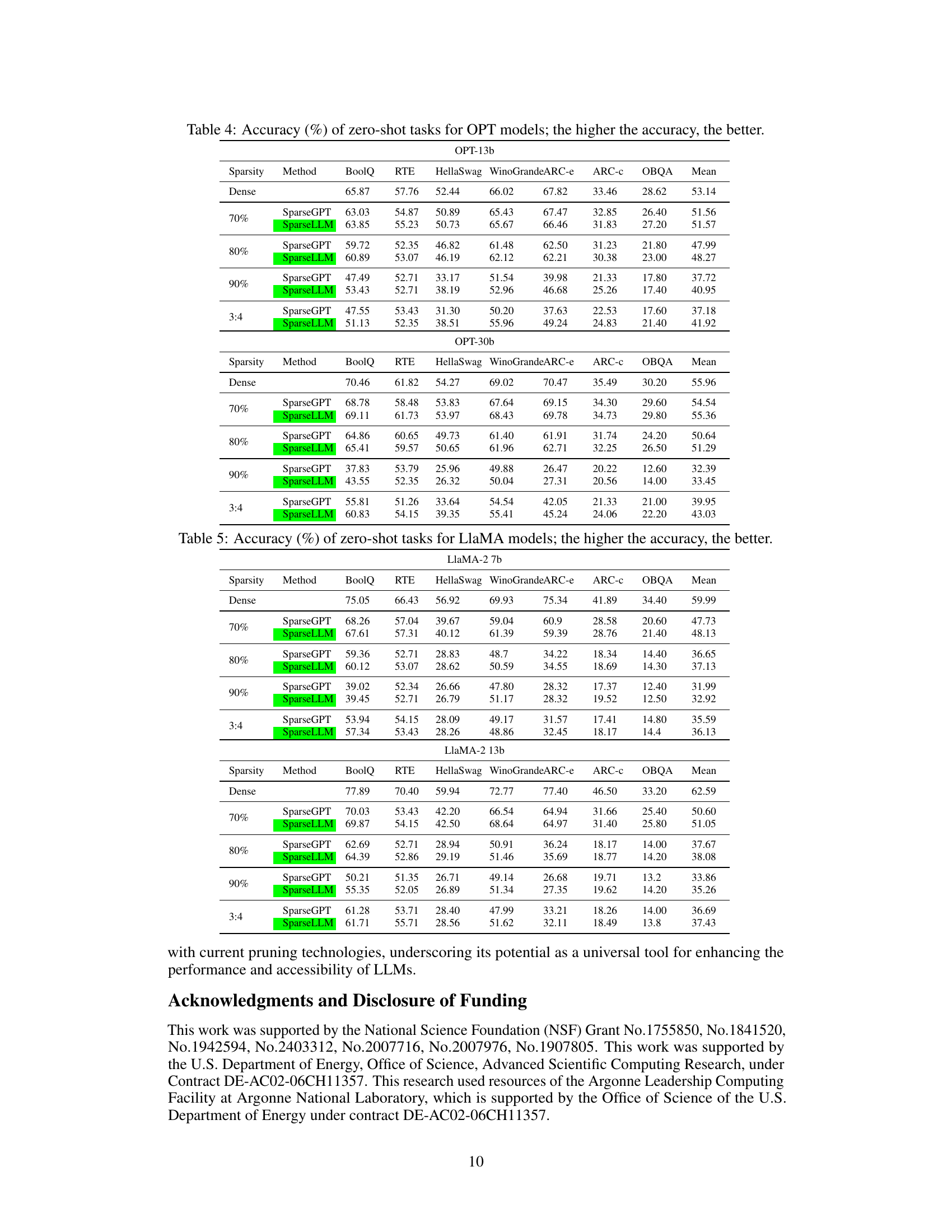
This table presents the zero-shot accuracy results for various OPT models with different sparsity levels (70%, 80%, 90%, and 3:4). The accuracy is evaluated across multiple tasks including BoolQ, RTE, HellaSwag, WinoGrande, ARC-e, ARC-c, and OBQA. The ‘Dense’ row shows the performance of the original, unpruned model. The table allows comparison of the SparseLLM method’s performance against other methods like SparseGPT for various sparsity levels. Lower perplexity indicates better performance.

This table presents the results of an ablation study on the hyperparameters α and β used in the SparseLLM model. The study was conducted on the OPT-1.3b model with 70% sparsity. Different combinations of α and β values were tested (0.01, 0.1, 1, 5, 10, 100) to assess their impact on model performance, measured by perplexity. The lowest perplexity value achieved is highlighted in bold, indicating the optimal combination of hyperparameters for this specific model and sparsity level.
Full paper#