TL;DR#
Multi-modal large language models (MLLMs) show promise for medical applications, but creating a unified model for various visual and linguistic tasks remains challenging. The ’tug-of-war’ problem, where the optimization of one task hinders others, is a major hurdle. Existing solutions mostly focus on improving individual components (LLMs or visual encoders), neglecting the connector between them.
This paper introduces Uni-Med, a medical generalist foundation model addressing this limitation. Uni-Med uses a novel Connector-Mixture-of-Experts (CMoE) module, which efficiently handles multi-task learning by using a mixture of projection experts to align visual and language spaces. Extensive experiments show that Uni-Med achieves significant performance gains (up to 8%) compared to previous state-of-the-art models. It showcases successful multi-task learning in a unified architecture across six medical tasks: question answering, visual question answering, report generation, referring expression comprehension, referring expression generation, and image classification. The open-source availability of Uni-Med further promotes reproducibility and future research.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in medical AI and multi-modal learning. It introduces a novel solution to the multi-task learning problem in medical foundation models, improving performance by up to 8%. The open-source nature of Uni-Med and detailed analysis facilitate further research into efficient multi-modal model development and optimization.
Visual Insights#
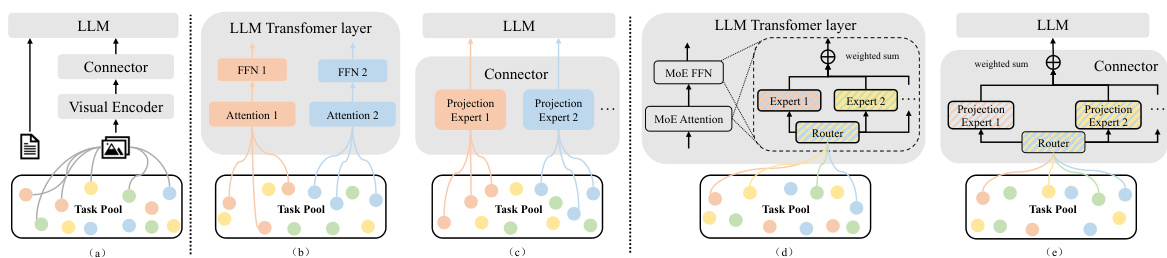
🔼 This figure illustrates three different hypotheses regarding the interaction between multiple tasks in a multi-modal large language model (MLLM) architecture. The first hypothesis suggests synergy, meaning all tasks benefit from shared components. Hypotheses two and three explore different conflict scenarios: one where conflict occurs within the language model (LLM) itself and another where the conflict happens at the connector between the visual encoder and the LLM. The final hypothesis suggests that both synergy and conflict can coexist in an MLLM. Each hypothesis is visually represented by a different architectural diagram showing the interaction between visual encoders, connectors (which bridge the gap between visual and language data), and the LLM.
read the caption
Figure 1: Three hypotheses and corresponding architectural implementations for multi-task learning in MLLMs. (a) Synergy hypothesis. (b)-(c) Conflict hypothesis in LLM and connector, respectively. (d)-(e) Conflict-synergy coexist hypothesis in LLM and connector, respectively.

🔼 This table shows the text-level identifiers used in the Uni-Med model for different medical tasks. These identifiers are used as part of the input prompt for each task to help the model understand and execute the correct task. The tasks include Question Answering, Visual Question Answering, Report Generation, Referring Expression Comprehension, Referring Expression Generation, and Image Classification. Each task is assigned a unique identifier that is included in the input prompt to guide the model’s behavior.
read the caption
Table 1: Text-level special task identifiers for different tasks.
In-depth insights#
Multimodal Med-LLMs#
Multimodal Med-LLMs represent a significant advancement in medical artificial intelligence, integrating visual and linguistic modalities to create powerful diagnostic and treatment tools. The ability to process diverse medical data types, such as images and text reports, simultaneously is a key advantage. This allows for a more holistic understanding of patient conditions than unimodal approaches. However, developing effective multimodal Med-LLMs presents significant challenges. The ’tug-of-war’ problem, where competing tasks interfere with each other during training, is a major hurdle. Advanced techniques, like Mixture-of-Experts (MoE), are being explored to mitigate this issue and improve the efficiency of the model, as evidenced in papers like Uni-Med. Another challenge is ensuring the reliability and safety of these models in clinical settings, necessitating rigorous testing and validation. Furthermore, addressing potential biases in the training data and mitigating risks of misdiagnosis are crucial considerations. The potential benefits of multimodal Med-LLMs are immense, including improved diagnostic accuracy, personalized treatment plans, and more efficient workflows. Nevertheless, careful consideration must be given to addressing the challenges before widespread adoption in healthcare.
Connector-MoE#
The proposed Connector-MoE (CMoE) architecture offers a novel approach to address the “tug-of-war” problem inherent in multi-task learning within large language models (LLMs). Instead of focusing solely on LLM improvements, CMoE enhances the connector module, the crucial bridge between visual and linguistic modalities. By employing a Mixture-of-Experts (MoE) mechanism at the connector, CMoE dynamically adapts to the varying feature requirements of different tasks, achieving efficient knowledge sharing while minimizing interference. This contrasts with traditional approaches that utilize a single shared connector for all tasks, often leading to performance degradation. The well-designed router in CMoE plays a pivotal role in determining the contribution of each expert, ensuring effective task-specific alignment. Empirical evaluations demonstrate that CMoE significantly boosts performance across diverse medical tasks, highlighting the effectiveness of this innovative approach to multi-modal multi-task learning. The interpretability analysis further underscores the advantages of CMoE by providing quantitative insights into how it mitigates the tug-of-war problem.
Tug-of-War Effect#
The “Tug-of-War Effect” in multi-task learning describes the phenomenon where the optimization of one task negatively impacts the performance of others. This is particularly problematic in multimodal models where different modalities (e.g., image, text) compete for shared resources like parameters. Uni-Med addresses this by introducing a Connector-MoE (Mixture of Experts) module. This innovative approach alleviates the effect by routing different tasks to specialized expert networks within the connector, instead of relying on a single, shared pathway. The authors present evidence that their method avoids conflicting gradient updates in parameter sharing by allowing for task-specific adaptations at the connector level, ultimately improving overall multi-task performance. Their interpretability analysis focusing on gradient optimization and parameter statistics provides further insight into the effectiveness of CMoE in mitigating the Tug-of-War effect. It demonstrates how Uni-Med’s design facilitates efficient solution to the problem, showing clear advantages over conventional approaches using single connector designs in multi-modal multi-task learning scenarios.
Uni-Med’s Abilities#
Uni-Med demonstrates strong capabilities as a unified medical generalist foundation model. Its key strength lies in addressing the “tug-of-war” problem inherent in multi-task learning within large language models (LLMs). This is achieved through the innovative Connector-MoE (CMoE) module, which efficiently manages the conflict between different tasks by using a mixture of experts to bridge the gap between modalities. Uni-Med showcases proficiency across six diverse medical tasks: question answering, visual question answering, report generation, referring expression comprehension, referring expression generation, and image classification. The model’s performance is competitive or superior to existing open-source medical LLMs, highlighting the effectiveness of the CMoE approach. Furthermore, the inclusion of interpretability analysis provides valuable insights into the model’s optimization processes, particularly in understanding how the tug-of-war problem is mitigated. The availability of Uni-Med as an open-source model promotes further research and development in the field of medical AI.
Future MedAI#
Future MedAI holds immense potential, driven by advancements in multimodal large language models (MLLMs) and the exponential growth of medical data. We can anticipate more sophisticated generalist foundation models capable of handling diverse medical tasks, bridging the gap between visual and linguistic modalities. Improved interpretability will be crucial, allowing clinicians to understand model reasoning and foster trust. Addressing the ’tug-of-war’ problem in multi-task learning will be essential for optimal performance. This will necessitate innovative approaches like Connector-MoE, enabling efficient knowledge sharing between tasks without compromising individual task performance. Future success hinges on responsible development and deployment, carefully considering ethical implications, data privacy, and potential biases. Open-source initiatives like Uni-Med play a pivotal role in fostering collaboration and accelerating progress in this vital field. Ultimately, Future MedAI promises more accurate diagnoses, personalized treatments, and streamlined workflows, improving healthcare outcomes globally.
More visual insights#
More on figures
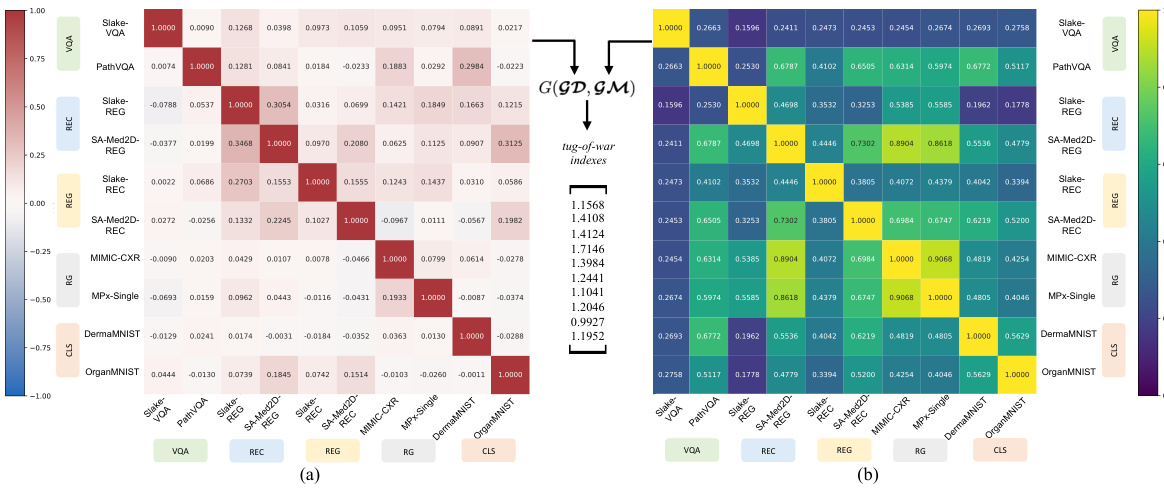
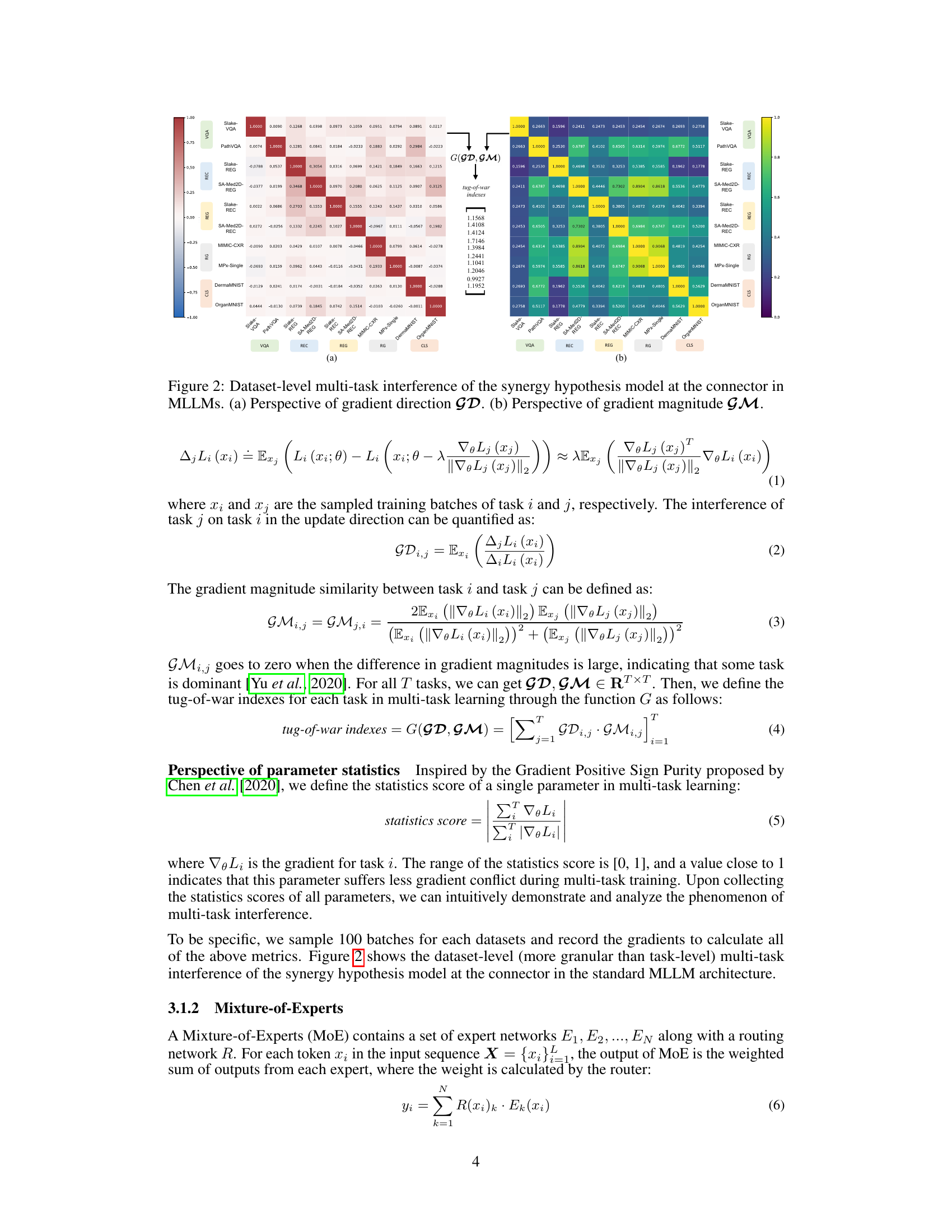
🔼 This figure visualizes the multi-task interference at the connector level within the synergy hypothesis model of Multi-modal Large Language Models (MLLMs). It uses two perspectives to quantify the interference: (a) Perspective of gradient direction (GD), showing the alignment or conflict in update directions for different tasks; (b) Perspective of gradient magnitude (GM), illustrating the similarity or dissimilarity of gradient magnitudes across different tasks. The heatmaps show the correlation between tasks, highlighting where significant interference or synergy occurs.
read the caption
Figure 2: Dataset-level multi-task interference of the synergy hypothesis model at the connector in MLLMs. (a) Perspective of gradient direction GD. (b) Perspective of gradient magnitude GM.

🔼 The figure shows the overall architecture of the Uni-Med model, which is composed of three main modules: a universal vision feature extraction module, a connector-MoE (CMoE) module, and a large language model (LLM). The vision feature extraction module takes multi-modal medical images as input and extracts visual features. The CMoE module aligns the visual space with the language embedding space of the LLM, mitigating the tug-of-war problem in multi-task learning. The LLM then generates responses based on the aligned visual features and textual instructions. Uni-Med is designed to perform six different medical tasks, as indicated in the figure.
read the caption
Figure 3: Overall architecture of Uni-Med, which consists of a universal vision feature extraction module, a connector-MoE module and an LLM. Uni-Med can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification.
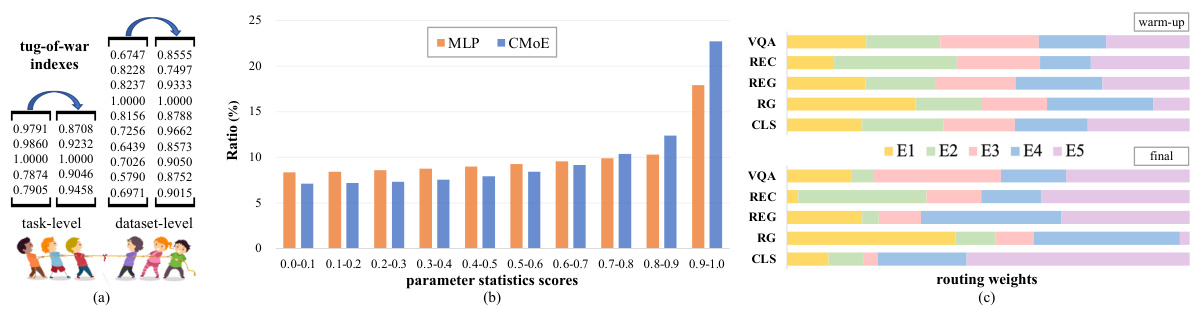
🔼 This figure visualizes the multi-task interference at the connector level within the synergy hypothesis model of Multi-modal Large Language Models (MLLMs). It uses two perspectives to quantify the interference: (a) Perspective of gradient direction (GD), showing the divergence in update directions across tasks; and (b) Perspective of gradient magnitude (GM), illustrating the similarity in gradient magnitudes across tasks. The tug-of-war phenomenon, where tasks negatively impact each other’s optimization, is highlighted by the interference visualized in the heatmaps, offering insights into the multi-task learning dynamics within the model’s architecture.
read the caption
Figure 2: Dataset-level multi-task interference of the synergy hypothesis model at the connector in MLLMs. (a) Perspective of gradient direction GD. (b) Perspective of gradient magnitude GM.
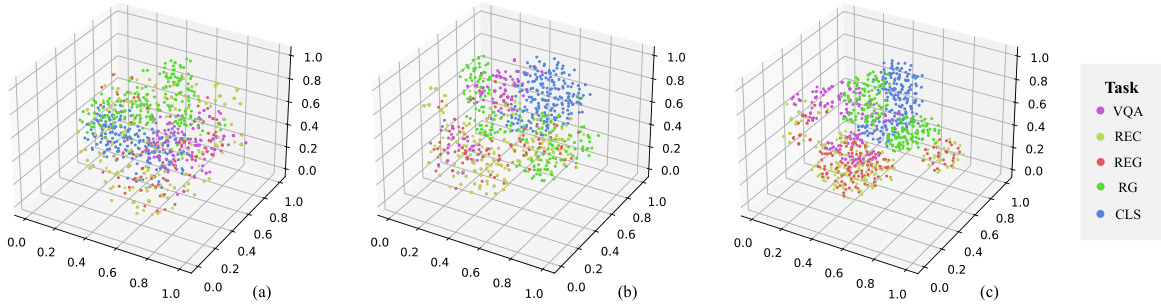
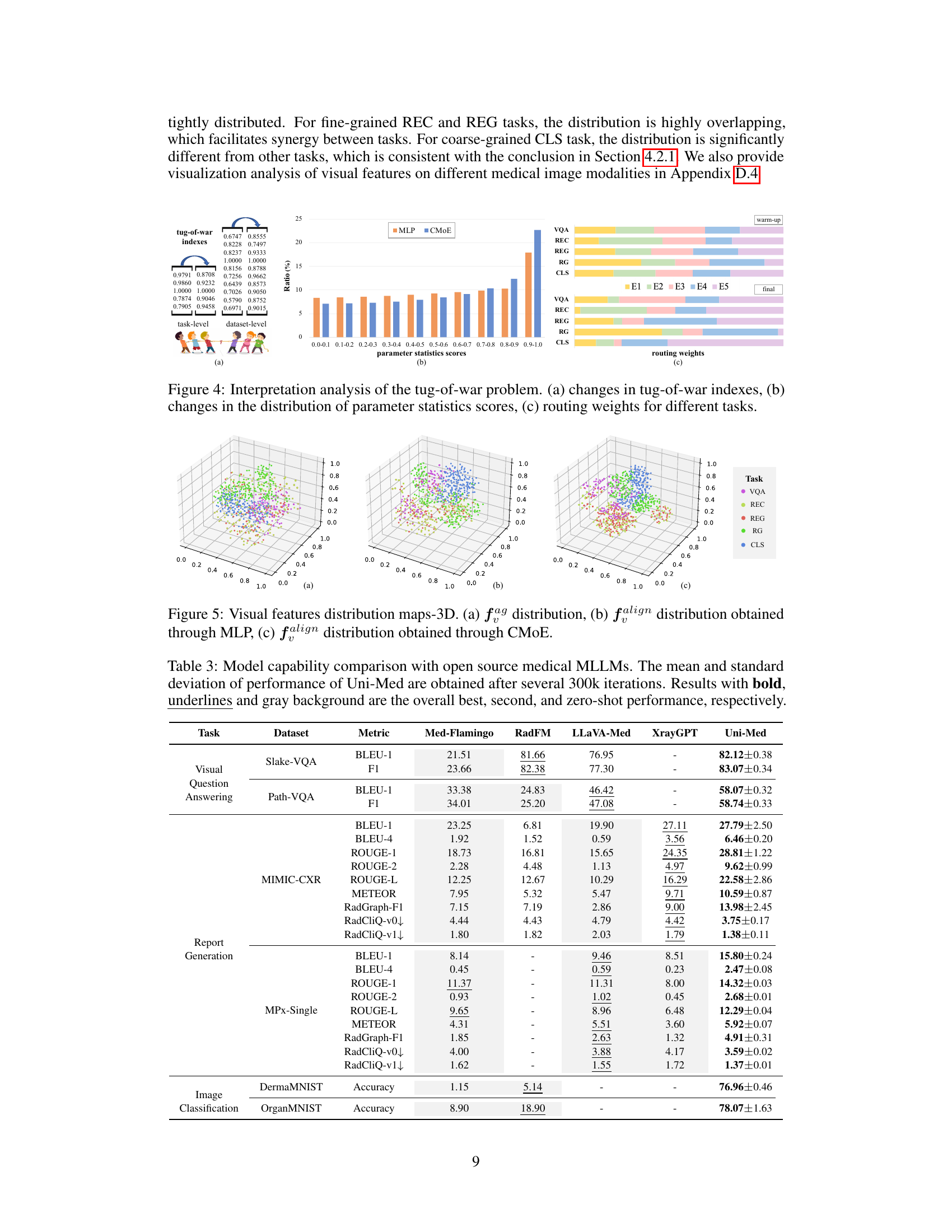
🔼 This figure visualizes the distribution of visual features in a 3D space for different tasks before and after passing through the connector (MLP and CMoE). It shows how the CMoE module improves the separation of visual features for different tasks, enhancing the model’s ability to distinguish between tasks during multi-task learning.
read the caption
Figure 5: Visual features distribution maps-3D. (a) fag distribution, (b) falign distribution obtained through MLP, (c) falign distribution obtained through CMoE.
🔼 The figure shows the overall architecture of the Uni-Med model, which is composed of three main modules: a universal vision feature extraction module, a connector-MoE (CMoE) module, and a large language model (LLM). The vision feature extraction module processes the input medical images, and the CMoE module acts as an efficient connector between the visual and language modalities, enabling efficient multi-task learning. The LLM module generates the final responses based on the processed visual and text information. The Uni-Med model can perform a wide range of medical tasks, including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation, and image classification.
read the caption
Figure 3: Overall architecture of Uni-Med, which consists of a universal vision feature extraction module, a connector-MoE module and an LLM. Uni-Med can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification.

🔼 The figure shows the architecture of Uni-Med, a unified medical generalist foundation model. It consists of three main modules: a universal vision feature extraction module, a connector-MoE (mixture-of-experts) module, and a large language model (LLM). The CMoE module is designed to efficiently handle multiple tasks and modalities, improving performance over a standard architecture. The model takes in both vision data (medical images) and text data (instructions) and outputs a response, performing six different medical tasks.
read the caption
Figure 3: Overall architecture of Uni-Med, which consists of a universal vision feature extraction module, a connector-MoE module and an LLM. Uni-Med can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification.

🔼 The figure shows the overall architecture of Uni-Med, a unified medical generalist foundation model. It’s composed of three main modules: a universal vision feature extraction module (processing medical images from various modalities), a connector-MoE module (acting as a bridge between the vision and language modules, and mitigating the ’tug-of-war’ problem in multi-task learning), and a large language model (LLM, for generating responses to various medical tasks). The architecture is designed to handle six different medical tasks.
read the caption
Figure 3: Overall architecture of Uni-Med, which consists of a universal vision feature extraction module, a connector-MoE module and an LLM. Uni-Med can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification.

🔼 This figure shows the overall architecture of the Uni-Med model, which is composed of three main modules: a universal vision feature extraction module, a connector-MoE (CMoE) module, and a large language model (LLM). The visual feature extraction module processes medical images from various modalities (X-ray, CT, MRI, fundus, PET, ultrasound, endoscopy, microscopy, dermoscopy, and histopathology). The CMoE module acts as a connector between the visual and textual modalities, efficiently handling the multi-task learning aspect. Finally, the LLM generates the model’s response. The model is designed to perform six medical tasks.
read the caption
Figure 3: Overall architecture of Uni-Med, which consists of a universal vision feature extraction module, a connector-MoE module and an LLM. Uni-Med can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification.
More on tables
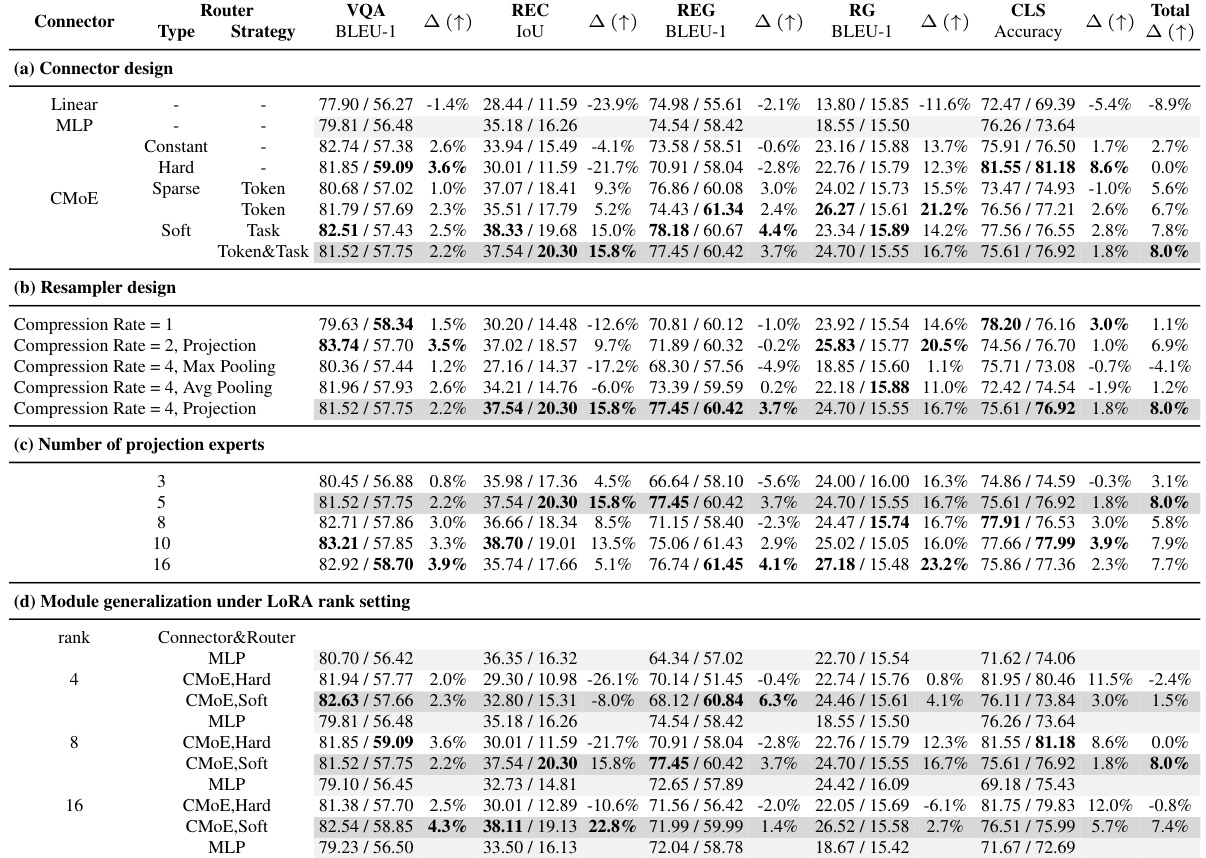
🔼 This table presents the results of ablation studies conducted on the Uni-Med model. It shows how different design choices for the connector module (e.g., type of router, resampling method, number of projection experts) and LLM fine-tuning (e.g., LoRA rank) impact the performance across five different medical tasks (VQA, REC, REG, RG, and CLS) and two datasets for each task. The performance metrics reported depend on the task and include BLEU scores, IoU, and accuracy. The Δ column shows the percentage change in performance compared to a baseline model.
read the caption
Table 2: Experiments of ablation study. Metrics are reported on 'Slake-VQA/Path-VQA', 'Slake-REC/SA-Med2D-REC', 'Slake-REG/SA-Med2D-REG', 'MIMIC-CXR/MPx-Single', 'DermaMNIST/OrganSMNIST' for the task of VQA, REC, REG, RG, and CLS, respectively.

🔼 This table presents the results of ablation experiments conducted to evaluate the impact of different design choices on the Uni-Med model’s performance. It shows the performance across five tasks (VQA, REC, REG, RG, CLS) and various model configurations focusing on connector design, resampler design, the number of projection experts, and the effects of LoRA rank and LoRA-MoE. Each row represents a specific model configuration, and each column shows the performance metric and percentage change (△) compared to the baseline.
read the caption
Table 2: Experiments of ablation study. Metrics are reported on 'Slake-VQA/Path-VQA', 'Slake-REC/SA-Med2D-REC', 'Slake-REG/SA-Med2D-REG', 'MIMIC-CXR/MPx-Single', 'DermaMNIST/OrganSMNIST' for the task of VQA, REC, REG, RG, and CLS, respectively.
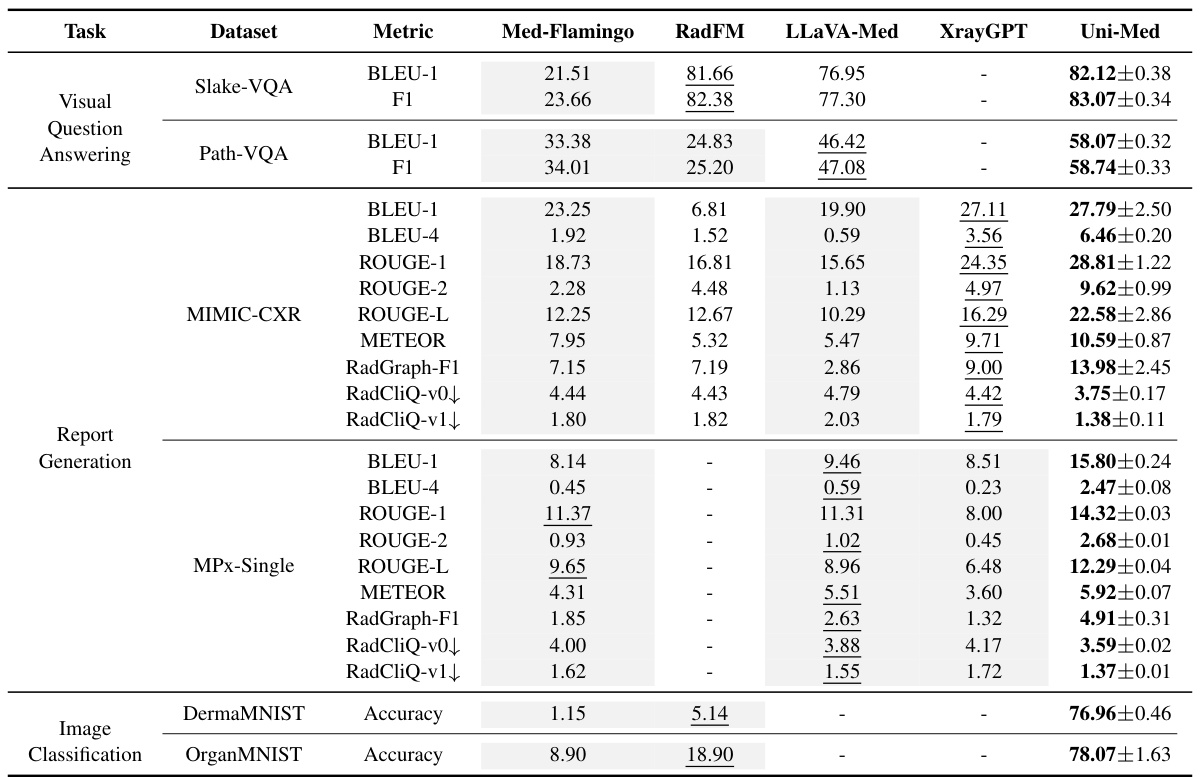
🔼 This table compares the performance of Uni-Med against other state-of-the-art open-source medical multi-modal large language models (MLLMs) across six different medical tasks. The metrics used for comparison vary depending on the specific task and include BLEU scores, F1 scores, ROUGE scores, METEOR, RadGraph F1, RadCliQ, and accuracy. The table highlights Uni-Med’s competitive or superior performance on various tasks and datasets.
read the caption
Table 3: Model capability comparison with open source medical MLLMs. The mean and standard deviation of performance of Uni-Med are obtained after several 300k iterations. Results with bold, underlines and gray background are the overall best, second, and zero-shot performance, respectively.
🔼 This table compares the performance of Uni-Med with four other open-source medical multi-modal large language models (MLLMs) across six medical tasks. The metrics used vary depending on the task (e.g., BLEU for report generation, F1 for VQA, Accuracy for image classification). Uni-Med’s performance is presented as mean ± standard deviation, highlighting its superior or competitive performance across most tasks. Bold, underlined, and gray values indicate the best overall, second-best, and zero-shot performance, respectively.
read the caption
Table 3: Model capability comparison with open source medical MLLMs. The mean and standard deviation of performance of Uni-Med are obtained after several 300k iterations. Results with bold, underlines and gray background are the overall best, second, and zero-shot performance, respectively.

🔼 This table presents the ablation study results, comparing the performance of different connector designs (MLP vs. CMoE with various router strategies) and different configurations (resampler, number of projection experts). The performance metrics (BLEU-1, IoU, Accuracy) are reported for five tasks (VQA, REC, REG, RG, CLS) across multiple datasets, showing the impact of each design choice on overall multi-task performance and highlighting the effectiveness of the proposed CMoE module.
read the caption
Table 2: Experiments of ablation study. Metrics are reported on 'Slake-VQA/Path-VQA', 'Slake-REC/SA-Med2D-REC', 'Slake-REG/SA-Med2D-REG', 'MIMIC-CXR/MPx-Single', 'DermaMNIST/OrganSMNIST' for the task of VQA, REC, REG, RG, and CLS, respectively.

🔼 This table presents the performance of the Uni-Med model on Referring Expression Comprehension (REC) and Referring Expression Generation (REG) tasks. The metrics reported are IoU, R@0.5 (recall at IoU threshold of 0.5), BLEU-1, F1 score, and Accuracy. Results are shown separately for the Slake and SA-Med2D datasets for both REC and REG tasks. The mean and standard deviation are reported.
read the caption
Table 6: Performance of Uni-Med on REC and REG tasks.

🔼 This table compares the performance of Uni-Med against four other open-source medical multi-modal large language models (MLLMs) across six different medical tasks. For each task, several metrics are provided to assess model performance. The best, second-best, and zero-shot results are highlighted for easier comparison.
read the caption
Table 3: Model capability comparison with open source medical MLLMs. The mean and standard deviation of performance of Uni-Med are obtained after several 300k iterations. Results with bold, underlines and gray background are the overall best, second, and zero-shot performance, respectively.
Full paper#