↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often produce inaccurate information, hindering their applications. Existing retrieval-augmented generation (RAG) methods have limitations, including the need for frequent retraining and the risk of altering foundational LLM capabilities.
This paper introduces Assistant-based Retrieval-Augmented Generation (ASSISTRAG), which uses an intelligent information assistant to manage memory and knowledge within LLMs. This assistant enhances information retrieval and decision-making through tool usage, action execution, memory building, and plan specification. A two-phase training approach improves the assistant’s abilities, leading to significant performance gains.
Key Takeaways#
Why does it matter?#
This paper is important because it presents ASSISTRAG, a novel approach to improve large language models (LLMs) by integrating an intelligent information assistant. This addresses the critical issue of factual inaccuracies in LLMs, enhancing their reliability and reasoning capabilities. The two-stage training method and the use of an assistant offers a new avenue for improving LLM performance, particularly for less advanced models, and has implications for various NLP tasks.
Visual Insights#
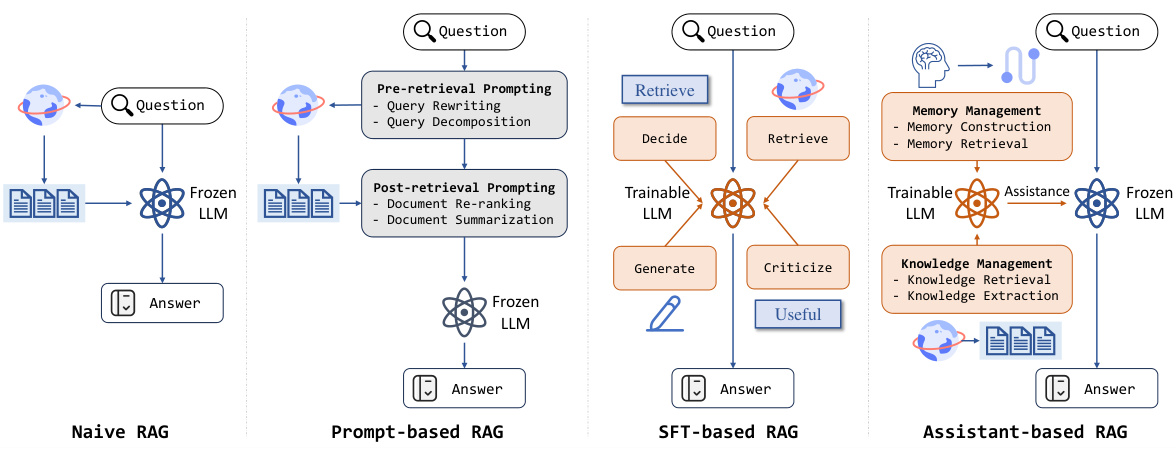
This figure compares four different retrieval-augmented generation (RAG) frameworks. Naive RAG uses a frozen LLM and simple retrieval. Prompt-based RAG adds pre and post retrieval prompting to improve the quality. SFT-based RAG fine-tunes a trainable LLM for RAG tasks. Finally, the proposed Assistant-based RAG uses a separate trainable assistant LLM to manage memory and knowledge, working with a frozen main LLM to improve reasoning and accuracy.
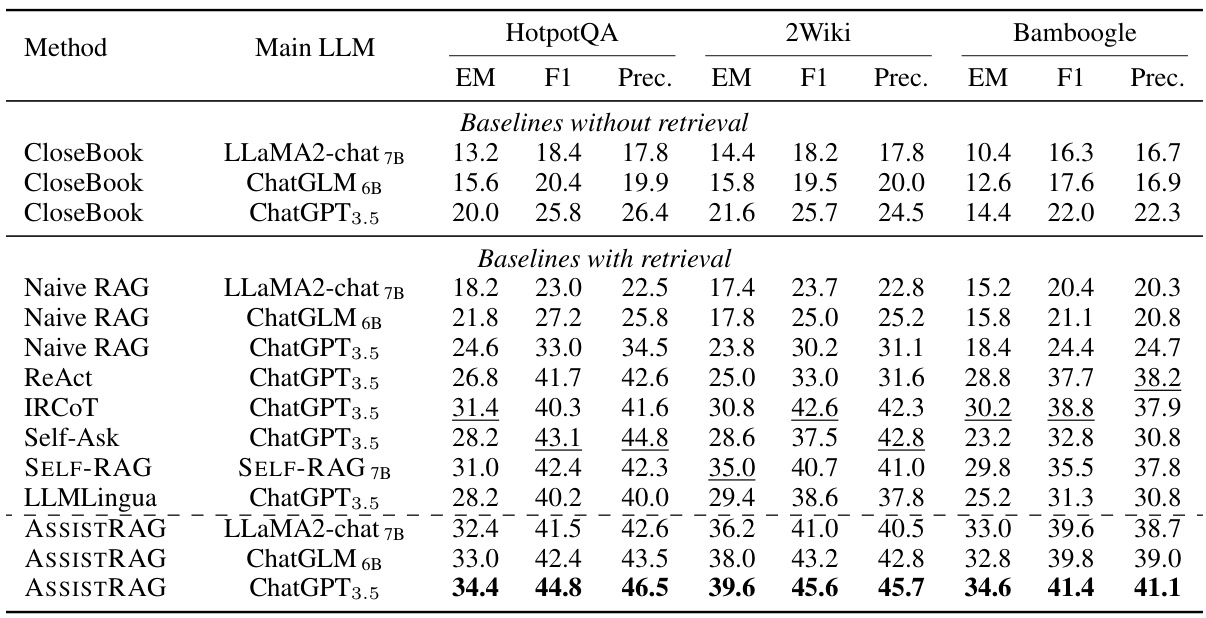
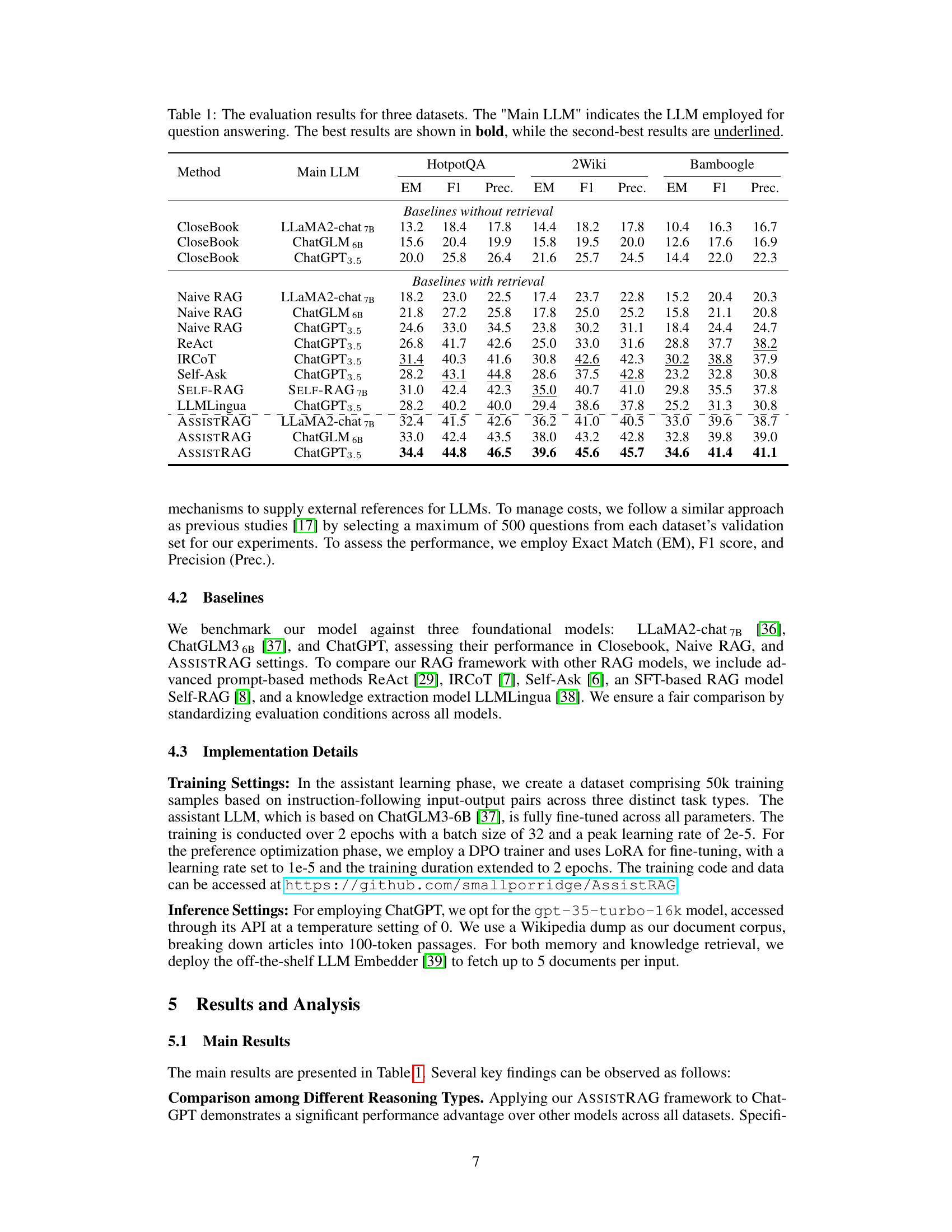
This table presents the performance comparison of different methods (including baselines and the proposed ASSISTRAG) across three question answering datasets: HotpotQA, 2Wiki, and Bamboogle. The performance is measured using Exact Match (EM), F1 score, and Precision (Prec.). It shows the results for different main LLMs (LLaMA2-chat 7B, ChatGLM 6B, and ChatGPT3.5) used in conjunction with each method. The best and second best results are highlighted for easy comparison.
In-depth insights#
LLM Hallucination#
LLM hallucination, the propensity of large language models (LLMs) to generate factually incorrect or nonsensical information, is a significant challenge. This phenomenon arises from the statistical nature of LLMs, which predict the next word in a sequence based on training data patterns, rather than possessing genuine understanding. The lack of grounding in external knowledge makes LLMs susceptible to fabricating details or confidently asserting falsehoods. Addressing this issue is crucial for deploying LLMs reliably, particularly in applications demanding factual accuracy. Solutions explored involve techniques like retrieval-augmented generation (RAG) to incorporate external knowledge sources and improved fine-tuning methods. However, current solutions are not perfect, and ongoing research focuses on improving methods for detecting and mitigating hallucinations to ensure LLM outputs are trustworthy and dependable.
RAG Frameworks#
Retrieval Augmented Generation (RAG) frameworks represent a significant advancement in large language models (LLMs), addressing the issue of factual inaccuracies or hallucinations. Early RAG approaches, like the simple “Retrieve-Read” method, proved insufficient for complex reasoning tasks. Prompt-based RAG strategies emerged, enhancing performance by incorporating pre- and post-retrieval prompts to refine the retrieval and generation processes. However, these methods remain heavily reliant on the LLM’s foundational capabilities, often requiring substantial fine-tuning. Supervised Fine-Tuning (SFT)-based RAG methods aim to improve accuracy, but they encounter challenges in adaptability to new foundational LLMs and potential negative impacts on the model’s overall performance. Advanced RAG systems, therefore, increasingly focus on integrating intelligent information assistants to manage memory and knowledge more effectively, leading to improved reasoning and accuracy. This shift towards assistant-based RAG represents a key advancement, showing potential to improve both accuracy and efficiency in complex tasks while overcoming limitations of previous approaches.
ASSISTRAG Design#
The ASSISTRAG design is centered around integrating an intelligent information assistant within LLMs to overcome limitations of existing RAG methods. This assistant acts as a plugin, managing memory and knowledge via tool usage, action execution, memory building, and plan specification. This two-phased architecture, involving curriculum learning and reinforced preference optimization, is crucial for effective memory and knowledge management. The system’s design prioritizes adaptability by using a trainable assistant alongside a static main LLM. This division of labor allows for effective handling of complex reasoning tasks while maintaining the core capabilities of the main LLM. The three-step inference process (information retrieval and integration, decision making, answer generation and memory updating) enhances information retrieval and decision-making accuracy, especially beneficial for less advanced LLMs. The thoughtful design of ASSISTRAG addresses common RAG shortcomings, aiming to deliver superior reasoning capabilities and accurate responses.
Two-Phase Training#
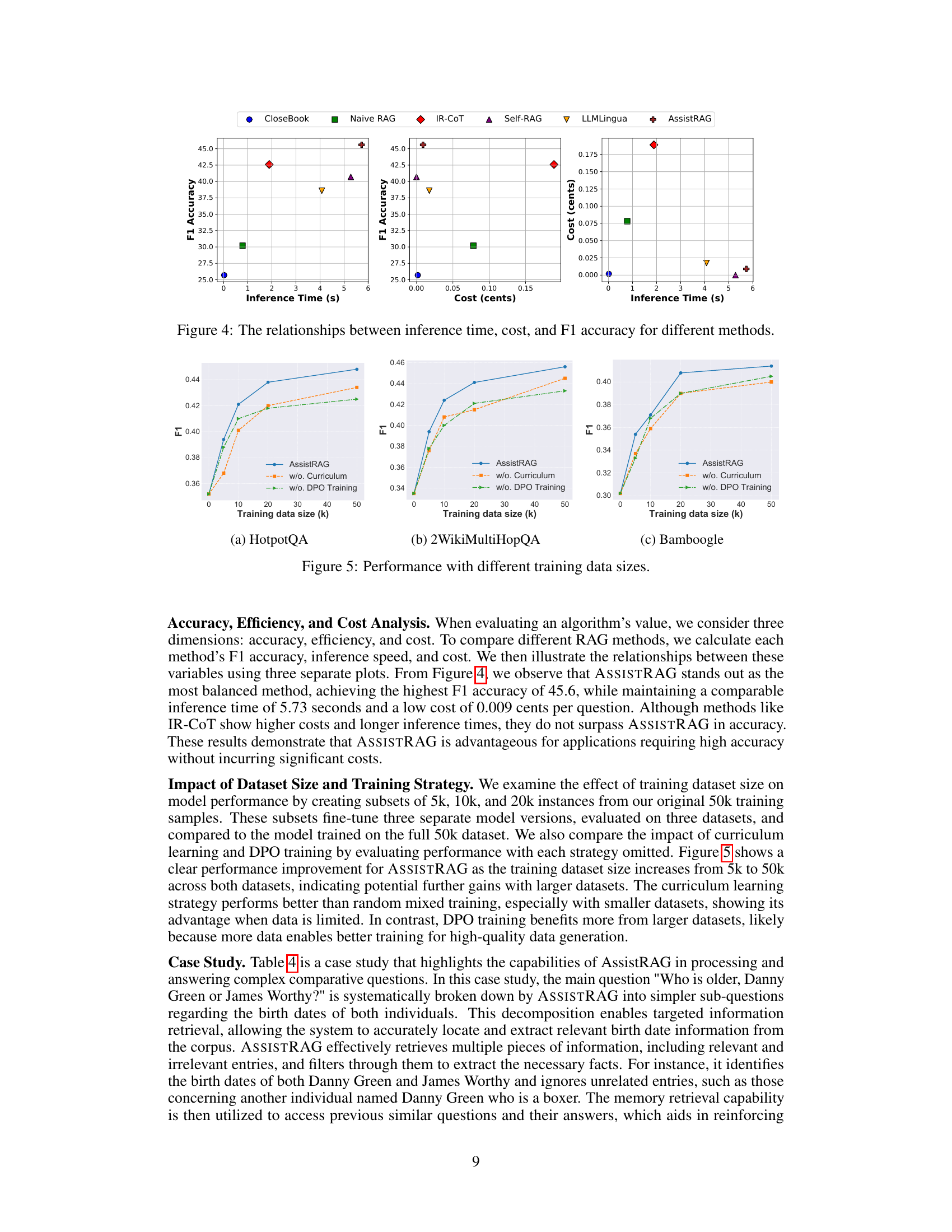
A thoughtful two-phase training approach is crucial for the success of complex AI models. The first phase, often involving curriculum learning, gradually increases the model’s complexity and capabilities, starting with easier tasks and progressively moving towards more difficult ones. This ensures that the model develops a strong foundation before tackling intricate problems. The second phase typically employs reinforcement learning or similar techniques to refine the model’s performance and align it with specific objectives or preferences. Feedback mechanisms play a key role in this phase, enabling the model to learn from its mistakes and improve decision-making. This two-pronged strategy helps create robust and reliable AI models capable of handling complex and nuanced situations, surpassing the performance of models trained using simpler methods.
Future of RAG#
The future of Retrieval-Augmented Generation (RAG) hinges on addressing its current limitations and capitalizing on emerging trends. Improved retrieval mechanisms are crucial, moving beyond simple keyword matching to incorporate semantic understanding and context. This includes exploring advanced embedding techniques and more sophisticated query reformulation strategies. Enhanced reasoning capabilities within RAG systems are also necessary to handle complex, multi-hop questions. This may involve integrating more advanced reasoning models or leveraging techniques like chain-of-thought prompting more effectively. Managing hallucinations remains a significant challenge, requiring better methods for verifying and validating information retrieved from external sources. This could involve integrating fact-checking mechanisms or incorporating user feedback loops. Finally, scaling RAG to handle massive datasets while maintaining efficiency and speed will be crucial for broader applications. This might involve developing more efficient indexing and retrieval techniques or exploring distributed RAG architectures. The successful development of these improvements will unlock RAG’s true potential, making it a truly powerful tool for natural language processing tasks requiring external knowledge access.
More visual insights#
More on figures
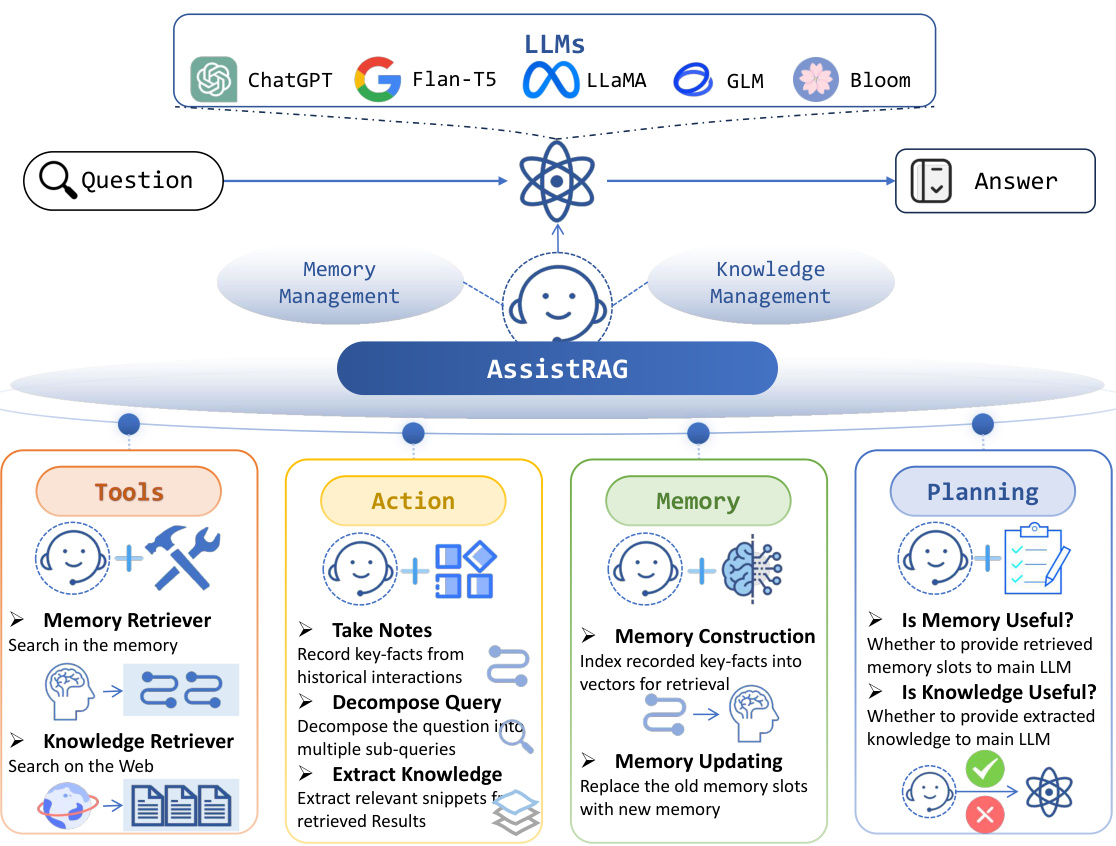
This figure shows a flowchart of the ASSISTRAG architecture, highlighting its key components: the main LLM, the intelligent information assistant, and the tools and functionalities that support its operation. It illustrates how the assistant manages memory and knowledge through tool usage, action execution, memory building, and plan specification to improve the LLM’s reasoning and response generation.
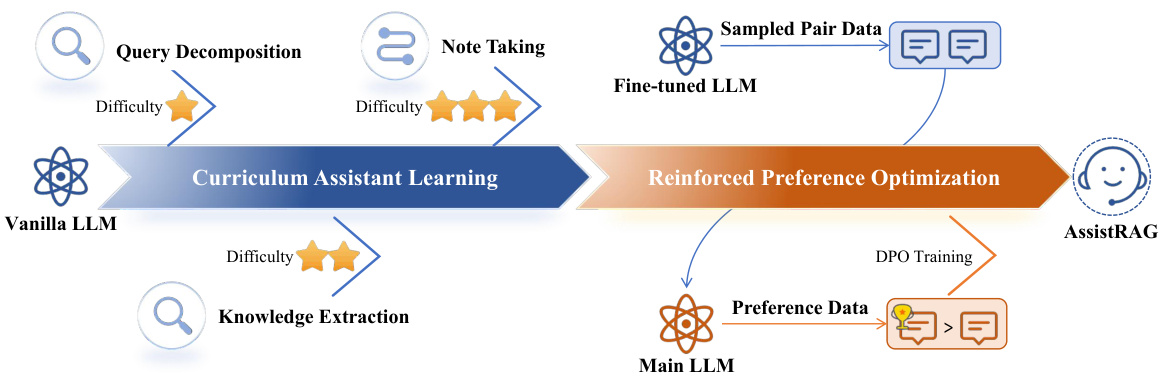
This figure illustrates the two-stage training process for the ASSISTRAG model. The first stage, Curriculum Assistant Learning, focuses on improving the assistant’s abilities in query decomposition, note-taking, and knowledge extraction through a curriculum of progressively complex tasks. The difficulty of the tasks increases with each stage. The second stage, Reinforced Preference Optimization, fine-tunes the assistant based on feedback from the main LLM using a Direct Preference Optimization (DPO) approach. This ensures that the assistant’s output aligns well with the needs of the main LLM. The process uses sampled pair data for training the fine-tuned LLM and generates preference data used for training ASSISTRAG in the reinforced preference optimization stage.

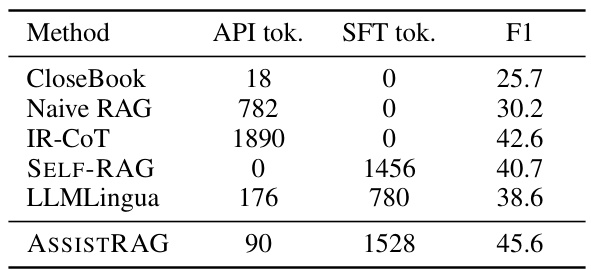
This figure compares different Retrieval-Augmented Generation (RAG) methods across three key aspects: inference time, cost (in cents), and F1 accuracy. Each method is represented by a distinct marker (CloseBook, Naive RAG, IR-CoT, Self-RAG, LLMLingua, and AssistRAG). The plots visually demonstrate the trade-offs between these factors for each approach. AssistRAG achieves the best balance between speed, cost-effectiveness, and accuracy.

This figure shows the training framework of the ASSISTRAG model, which involves two main stages: curriculum assistant learning and reinforced preference optimization. Curriculum assistant learning is a step-wise approach that starts with simpler tasks and gradually moves to more complex ones to improve the assistant’s comprehension of the RAG process. Reinforced preference optimization uses reinforcement learning to fine-tune the assistant’s output based on feedback from the main LLM to improve alignment. The figure illustrates the flow of data and the interaction between the different components of the training process.
More on tables
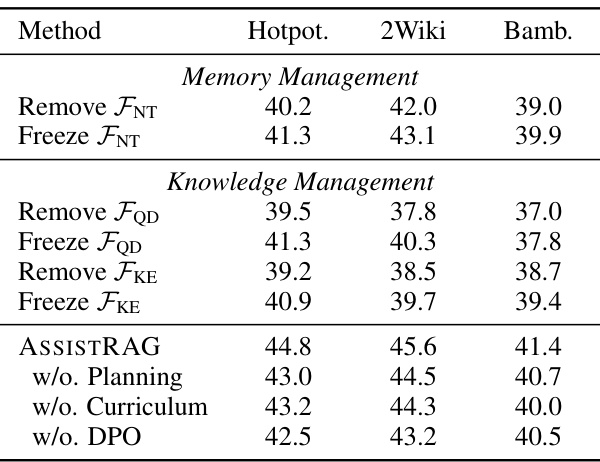
This table presents the results of ablation studies conducted on the ASSISTRAG model. It shows the impact of removing or freezing different components of the model, including memory management (FNT), and knowledge management (FQD, FKE). It also shows the effect of removing the planning, curriculum, and DPO training phases. The results are presented as F1 scores for three different datasets: HotpotQA, 2Wiki, and Bamboogle.
This table presents the performance comparison of different methods on three question answering datasets: HotpotQA, 2Wiki, and Bamboogle. The methods include baselines (without and with retrieval), state-of-the-art RAG methods, and the proposed ASSISTRAG. For each dataset and method, the Exact Match (EM), F1-score, and precision (Prec.) are reported, allowing for a comprehensive evaluation of accuracy. The ‘Main LLM’ column specifies the large language model used for final answer generation in each method.

This table presents the performance of different methods across three question answering datasets: HotpotQA, 2WikiMultiHopQA, and Bamboogle. The methods compared include various baselines (without and with retrieval), advanced prompt-based methods, and the proposed ASSISTRAG. The evaluation metrics used are Exact Match (EM), F1 score, and Precision (Prec.). The results highlight the performance gains achieved by ASSISTRAG, particularly when compared to simpler retrieval-augmented generation (RAG) methods and when using less-advanced LLMs as the main language model.

This table presents the performance of various methods across three question answering datasets (HotpotQA, 2Wiki, Bamboogle). It compares baselines (without and with retrieval), several state-of-the-art RAG methods, and the proposed ASSISTRAG method. The performance is evaluated using Exact Match (EM), F1-score, and Precision (Prec.) for each method and dataset, showing the effectiveness of ASSISTRAG, especially when using less powerful LLMs.

This table presents the performance comparison of different methods (including baselines and the proposed ASSISTRAG) on three question answering datasets (HotpotQA, 2Wiki, and Bamboogle). The metrics used for comparison are Exact Match (EM), F1-score, and Precision (Prec.). The ‘Main LLM’ column specifies the large language model used for answering the questions. The table highlights the best-performing method for each dataset and metric.

This table presents the performance of different methods (baselines and ASSISTRAG) on three question answering datasets (HotpotQA, 2Wiki, Bamboogle). It compares exact match (EM) accuracy, F1 score, and precision across various LLMs (LLaMA2-chat 7B, ChatGLM 6B, ChatGPT 3.5) and different retrieval-augmented generation (RAG) approaches. The best and second-best results are highlighted for easier comparison.

This table presents the performance comparison of different methods on three question answering datasets (HotpotQA, 2Wiki, Bamboogle). It shows the Exact Match (EM), F1 score, and Precision (Prec.) achieved by various methods, including baselines (without and with retrieval) and several state-of-the-art Retrieval Augmented Generation (RAG) approaches. The ‘Main LLM’ column specifies the large language model used for generating the final answers. The table helps to illustrate the effectiveness of the proposed Assistant-based Retrieval-Augmented Generation (ASSISTRAG) method compared to other approaches.
Full paper#