TL;DR#
Estimating 3D human poses from images is challenging, especially when parts of the body are hidden (occluded). Traditional methods struggle with these occlusions, producing inaccurate results. Generative models, particularly diffusion models, have shown promise but often require massive datasets and may produce unrealistic poses. This paper addresses these issues.
The authors propose Di²Pose, a new method using a two-stage process: first, it converts 3D poses into a discrete representation using a pose quantization step; then, it employs a discrete diffusion model to refine the pose in latent space. This approach improves the model’s understanding of how occlusions affect poses. Extensive experiments showed that Di²Pose outperforms existing methods, particularly in challenging occlusion scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to 3D human pose estimation that effectively handles occlusions, a persistent challenge in the field. The use of a discrete diffusion model and compositional pose representation offers a new perspective, improving accuracy and robustness, and opening avenues for further research in human pose estimation and generative modeling.
Visual Insights#
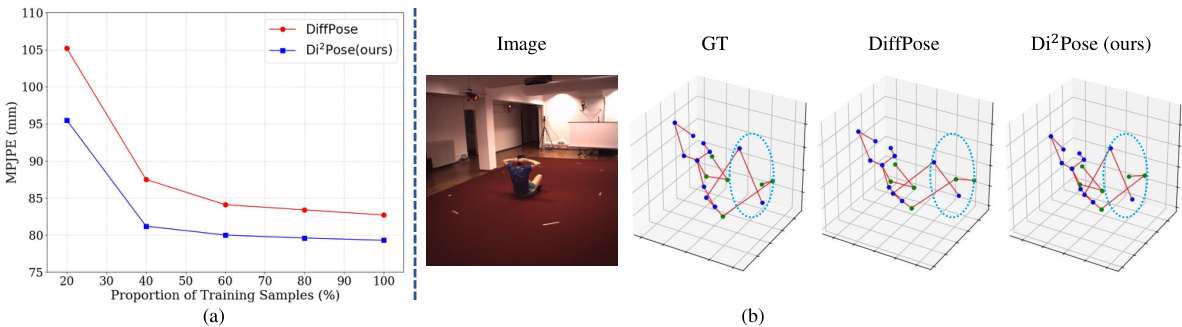
🔼 This figure compares the performance of DiffPose and the proposed Di²Pose method. (a) shows a plot illustrating how the MPJPE (mean per joint position error) changes as the amount of training data varies for both models. The plot demonstrates Di²Pose’s superior performance, particularly when training data is scarce. (b) provides a visual comparison of the 3D pose estimation results of both methods under occlusion scenarios. The images clearly show that Di²Pose generates more realistic and accurate 3D poses in the presence of occlusions compared to DiffPose.
read the caption
Figure 1: (a) Results of DiffPose [22] and Di²Pose in Human3.6M [72] dataset (with MPJPE metric), across varying proportions of training samples. (b) Prediction results of two methods under occlusion.
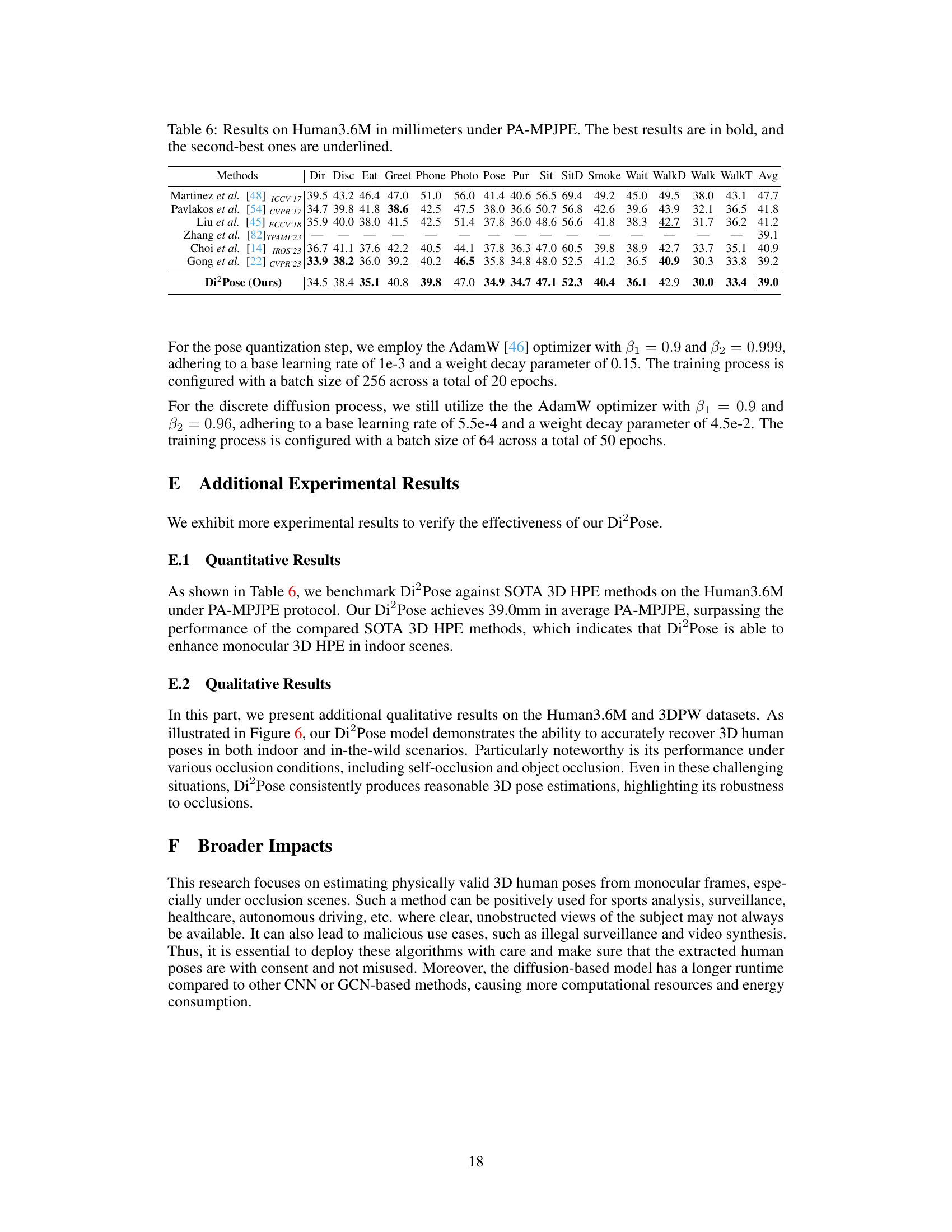
🔼 This table presents a comparison of different methods for 3D human pose estimation on the Human3.6M dataset, using the Mean Per Joint Position Error (MPJPE) metric in millimeters. The results are broken down by different actions (Dir, Disc, Eat, etc.) and show the average MPJPE across all actions. The best performing method for each action and overall is highlighted in bold, while the second-best is underlined. This allows for a detailed comparison of the performance of various approaches on this benchmark dataset.
read the caption
Table 1: Results on Human3.6M in millimeters under MPJPE. The best results are in bold, and the second-best ones are underlined.
In-depth insights#
Discrete Diffusion#
Discrete diffusion models offer a compelling approach to modeling complex data distributions, particularly when dealing with inherent uncertainties and ambiguities. Their strength lies in the ability to navigate high-dimensional spaces efficiently, unlike traditional methods. By discretizing the continuous diffusion process, computational efficiency is improved while maintaining the generative power of the model. The discretization process often involves representing data as tokens or symbols, leveraging the benefits of discrete latent spaces. This approach leads to more manageable training and inference, reducing the need for massive datasets. However, the choice of discretization strategy and token representation significantly impacts the model’s effectiveness, requiring careful consideration and selection. Careful design of the transition matrices in the diffusion process is crucial for directing the model towards physically plausible outputs. The resulting discrete diffusion models offer a balance between the efficiency of discrete methods and the expressiveness of diffusion models, opening new avenues for tasks involving complex, high-dimensional data where traditional techniques falter.
Pose Quantization#
Pose quantization, a crucial step in the Di2Pose framework, tackles the challenge of high-dimensional continuous pose data by converting it into a discrete representation. This process, inspired by VQ-VAE, transforms 3D poses into a set of quantized tokens, each representing a sub-structure of the human pose. This compositional approach, using Local-MLP blocks, captures local inter-joint dependencies, resulting in a more robust and physically plausible representation compared to using global feature extraction or coordinate-based methods. Finite scalar quantization (FSQ) is employed to enhance the quality of the codebook and prevent the collapse often seen in traditional VQ-VAE approaches. The choice of using discrete tokens significantly reduces the search space during the subsequent diffusion process, leading to improved efficiency in terms of both computational cost and training data requirements. The effectiveness of this quantization is validated by experimental results demonstrating its contribution to enhanced pose estimation accuracy, especially in challenging occlusion scenarios.
Occlusion Handling#
The paper tackles the problem of occlusion in 3D human pose estimation, a notoriously challenging aspect due to the inherent ambiguities introduced when parts of the body are hidden. The proposed approach, Di²Pose, directly addresses this by strategically incorporating occlusion handling into both the pose quantization and discrete diffusion processes. Pose quantization leverages the compositional nature of human poses, modeling joints’ relationships and implicitly restricting the search space to anatomically plausible configurations, even when occlusions are present. The discrete diffusion model further enhances robustness by implicitly modeling occlusions within the latent space. Instead of explicitly predicting occluded joint locations, the model learns to denoise latent representations of the pose, effectively handling occlusion uncertainty. This two-pronged approach offers a significant improvement over existing methods that primarily rely on occlusion-specific priors or data augmentation, resulting in more accurate and robust pose estimation in the presence of occlusions.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a pose estimation model, this might involve removing or modifying elements such as the pose quantization step, the discrete diffusion process, specific layers within the model architecture, or the occlusion handling mechanism. By observing how performance changes after these removals, researchers can gain valuable insights into the relative importance of each component. For example, removing the pose quantization step might lead to a significant drop in accuracy, indicating its crucial role in constraining the search space and ensuring biomechanically plausible results. Similarly, analyzing the impact of different occlusion handling strategies provides crucial information about the robustness and effectiveness of the model in dealing with incomplete observations. Such detailed analysis is critical for understanding the strengths and limitations of the approach and for guiding future development efforts. The results should ideally highlight which components are most essential for high performance, revealing the architecture’s key features and design principles. Furthermore, ablation studies allow for the identification of potential redundancies or inefficiencies in the model architecture which could guide model simplification or optimization.
Future Work#
Future research directions stemming from the Di²Pose model could explore several promising avenues. Extending Di²Pose to handle more complex occlusion scenarios is a key priority. The current model shows strong performance, but handling highly articulated poses with extensive, irregular occlusions remains a challenge. Investigating advanced occlusion modeling techniques or incorporating other sensor modalities could improve this. Enhancing efficiency is another focus; while Di²Pose is effective, reducing computational cost and memory requirements would broaden its applicability. Optimizing the discrete diffusion process, potentially through model compression or efficient architectural designs, is important. Improving the generalization capabilities of Di²Pose is crucial. Currently, evaluation is conducted on established datasets; extending the evaluation to more diverse and challenging real-world scenarios would provide a more comprehensive assessment of its generalizability. Finally, exploring the potential of Di²Pose for related 3D human pose estimation tasks such as action recognition or human-object interaction could unlock further advancements and create novel applications.
More visual insights#
More on figures
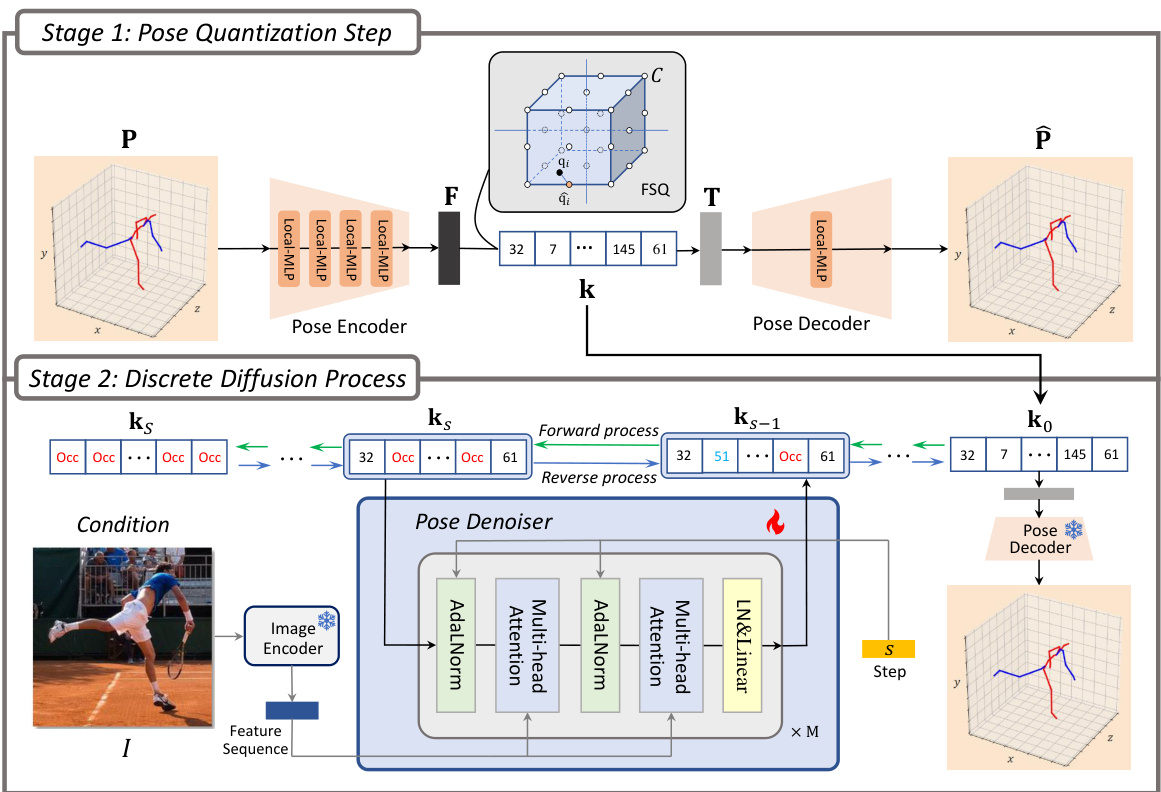
🔼 This figure illustrates the two-stage Di²Pose framework. Stage 1 involves a pose quantization step that converts a 3D pose into discrete tokens. Stage 2 uses a discrete diffusion process to model these tokens, handling occlusions probabilistically in the forward process and reconstructing them from a 2D image in the reverse process. The final output is a recovered 3D pose.
read the caption
Figure 2: Overview of our two-stage Di²Pose framework. In the stage 1, we train a pose quantization step that transforms a 3D pose P into multiple discrete tokens k, each token representing the indices of implied codebook C. In the stage 2, we model k in the discrete space by discrete diffusion process. In the forward process, each token is probabilistically occluded with Occ token or replaced with another available token. In the reverse process, the model leverages an independent image encoder and a pose denoiser to reconstruct all the tokens based on the condition 2D image. These reconstructed tokens are finally decoded by the pose decoder, resulting in the recovered 3D pose. Notably, we only update the parameters of pose denoiser, pose decoder and image encoder are frozen.

🔼 This figure illustrates the Di²Pose framework, which consists of two stages: pose quantization and discrete diffusion. The pose quantization stage converts a 3D pose into discrete tokens, representing sub-structures of the pose. The discrete diffusion stage then models these tokens using a conditional diffusion model, simulating a transition from occluded to recovered poses. The model uses an image encoder and a pose denoiser to handle occlusions and reconstruct the pose.
read the caption
Figure 3: Overview of our two-stage Di²Pose framework. In the stage 1, we train a pose quantization step that transforms a 3D pose P into multiple discrete tokens k, each token representing the indices of implied codebook C. In the stage 2, we model k in the discrete space by discrete diffusion process. In the forward process, each token is probabilistically occluded with Occ token or replaced with another available token. In the reverse process, the model leverages an independent image encoder and a pose denoiser to reconstruct all the tokens based on the condition 2D image. These reconstructed tokens are finally decoded by the pose decoder, resulting in the recovered 3D pose. Notably, we only update the parameters of pose denoiser, pose decoder and image encoder are frozen.
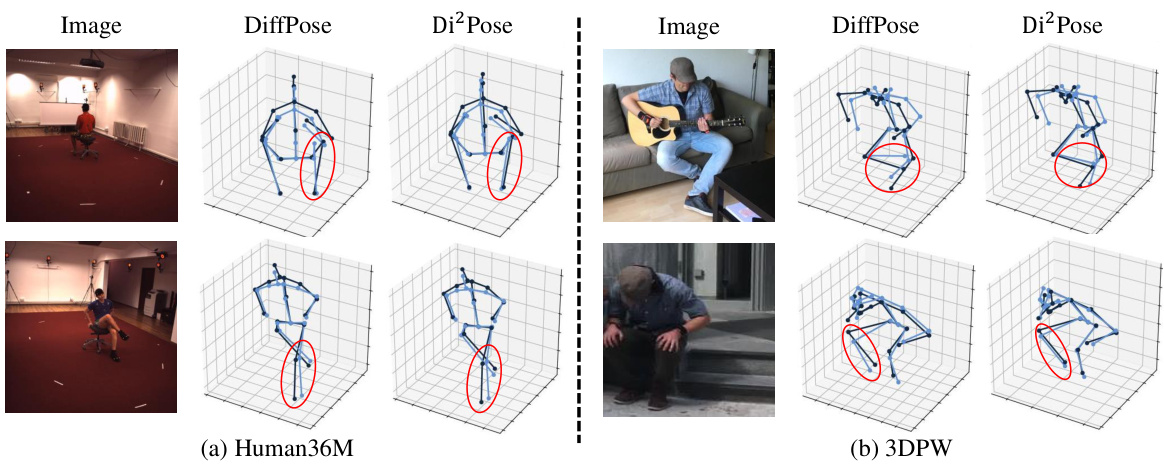
🔼 This figure shows a qualitative comparison of the 3D human pose estimation results between DiffPose and the proposed Di²Pose method on the Human3.6M and 3DPW datasets. For each dataset, two example images are shown, along with the ground truth poses (black lines) and the estimated poses from both DiffPose and Di²Pose (blue lines). The red circles highlight areas where there are noticeable differences in the pose estimation results between the two methods, suggesting that Di²Pose may be more accurate in these particular scenarios, especially when occlusions are present.
read the caption
Figure 4: Qualitative results on two datasets. The black lines represent the ground truth poses and the blue lines are prediction results.

🔼 This figure shows a qualitative comparison of the proposed Di2Pose model’s performance against the DiffPose model on Human3.6M and 3DPW datasets. The images show example input images, ground truth 3D poses (black lines), and the poses estimated by DiffPose (blue lines) and Di2Pose (red lines). The comparison highlights the ability of Di2Pose to improve accuracy of 3D pose estimation, especially in challenging situations such as occlusion. It visually demonstrates the effectiveness of the proposed discrete diffusion model for handling occluded 3D human pose estimation.
read the caption
Figure 4: Qualitative results on two datasets. The black lines represent the ground truth poses and the blue lines are prediction results.

🔼 This figure showcases qualitative results comparing the ground truth 3D human poses (GT) with the predictions of the proposed Di2Pose method. The results are presented for both the Human3.6M and 3DPW datasets. Each row in the figure displays a sequence of poses. The images on the left represent frames from the dataset, while the pose visualizations are provided next to the images. The color-coding helps distinguish between joints: joints that are correctly predicted are shown in blue, and those incorrectly predicted are highlighted in green. This visual representation allows for a direct comparison between the GT and Di2Pose predictions, highlighting the model’s performance on different poses and datasets, including challenging scenarios with occlusions. The figure demonstrates that the model’s predictions show a high degree of agreement with the ground truth data, but there are also cases where there are prediction errors, especially on those challenging scenarios involving occlusions.
read the caption
Figure 6: Qualitative results on two datasets. Joints on the right side are marked in green, while other joints are highlighted in blue.
More on tables

🔼 This table presents a comparison of the proposed Di2Pose model against other state-of-the-art methods on three benchmark datasets: 3DPW, 3DPW-Occ (occluded version of 3DPW), and 3DPW-AdvOcc (adversarial occlusion on 3DPW). The evaluation metrics used are MPJPE (Mean per Joint Position Error) and PA-MPJPE (Procrustes-aligned MPJPE). The results show Di2Pose’s performance under various occlusion scenarios, demonstrating its robustness and accuracy.
read the caption
Table 2: Evaluation on 3DPW, 3DPW-Occ, and 3DPW-AdvOcc. The number 40 and 80 after 3DPW-AdvOcc denote the occluder size. * denotes the results from our implementation. The best results are in bold, and the second-best ones are underlined.

🔼 This table presents the ablation study results on the Human3.6M dataset. It shows the impact of different hyperparameters on the model’s performance, measured by MPJPE and PA-MPJPE. The hyperparameters varied include the number of local joints considered in the Joint Shift operation of the Local-MLP block, the number of levels per channel in the finite scalar quantization process, the occlusion rate used during training, and the number of training and inference steps. The results indicate the optimal hyperparameter settings for achieving the best performance.
read the caption
Table 3: Ablations on Human3.6M. P-1 and P-2 represent MPJPE and PA-MPJPE, respectively.
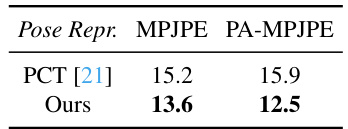
🔼 This table compares different methods for representing 3D human poses in the context of 3D Human Pose Estimation (HPE). It shows the MPJPE and PA-MPJPE metrics for the original 3D poses and those reconstructed using PCT [21] and the proposed Di²Pose method. The results demonstrate that the proposed pose quantization step in Di²Pose achieves more accurate reconstruction of 3D poses compared to the baseline.
read the caption
Table 4: Different representation methods for 3D HPE.
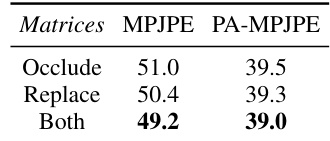
🔼 This table presents the ablation study results on the impact of different transition matrices used in the discrete diffusion process of the Di2Pose model. The three matrices compared are the ‘Occlude’ matrix (only simulating occlusion), the ‘Replace’ matrix (only replacing tokens), and the ‘Both’ matrix (simulating both occlusion and replacement). The results are measured using MPJPE and PA-MPJPE metrics, showing that the ‘Both’ matrix yields the best results, indicating the importance of modeling both occlusion and the uncertainty involved in occluded regions.
read the caption
Table 5: Different transition matrices for discrete diffusion model.

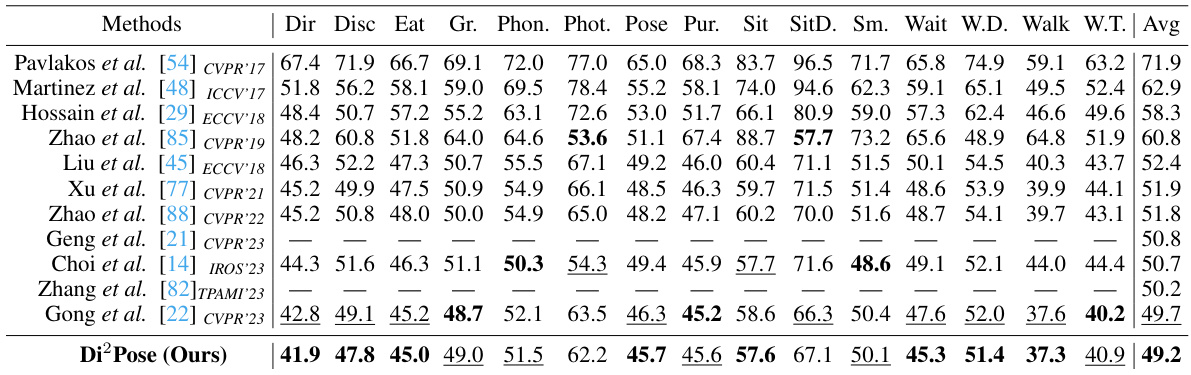
🔼 This table presents a comparison of different methods for 3D human pose estimation on three datasets: 3DPW, 3DPW-Occ (occluded), and 3DPW-AdvOcc (adversarial occlusion). The metrics used are MPJPE and PA-MPJPE, which measure the error in joint position prediction. The table shows that Di²Pose outperforms other state-of-the-art methods, especially in the more challenging occluded scenarios.
read the caption
Table 2: Evaluation on 3DPW, 3DPW-Occ, and 3DPW-AdvOcc. The number 40 and 80 after 3DPW-AdvOcc denote the occluder size. * denotes the results from our implementation. The best results are in bold, and the second-best ones are underlined.
Full paper#