TL;DR#
Generalized Few-Shot Semantic Segmentation (GFSS) aims to classify pixels into both base and novel classes, a more practical but challenging task than classic few-shot semantic segmentation. Current GFSS methods often rely on complex techniques such as customized modules and meta-learning, which can be computationally expensive and difficult to implement. The main challenge lies in achieving high accuracy for novel classes while maintaining the performance of the base-class model. Existing methods struggle to balance these two aspects effectively.
This paper introduces a novel GFSS method called Base-Class Mining (BCM). BCM utilizes a simple rule to identify base classes closely related to novel classes, followed by standard supervised learning. The authors show theoretically that BCM perfectly maintains the performance of the base-class model for a subset of base classes. Their experiments demonstrate that BCM substantially improves novel-class segmentation accuracy compared to existing state-of-the-art methods, particularly in the 1-shot setting, while maintaining good performance on base classes. This is achieved without using complex techniques that can be computationally expensive and difficult to deploy in real-world applications.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a surprisingly simple yet effective solution to a complex problem in semantic segmentation. Its theoretical analysis provides valuable insights into the behavior of base-class models in the generalized few-shot setting and its practical performance improvements demonstrate the potential for significant advancements in this field. The lightweight implementation also makes it easily adoptable and highly relevant for resource-constrained applications. The new theoretical understanding of base-class model performance and the proposed base-class mining methodology open up new avenues of research for improving few-shot learning methods.
Visual Insights#
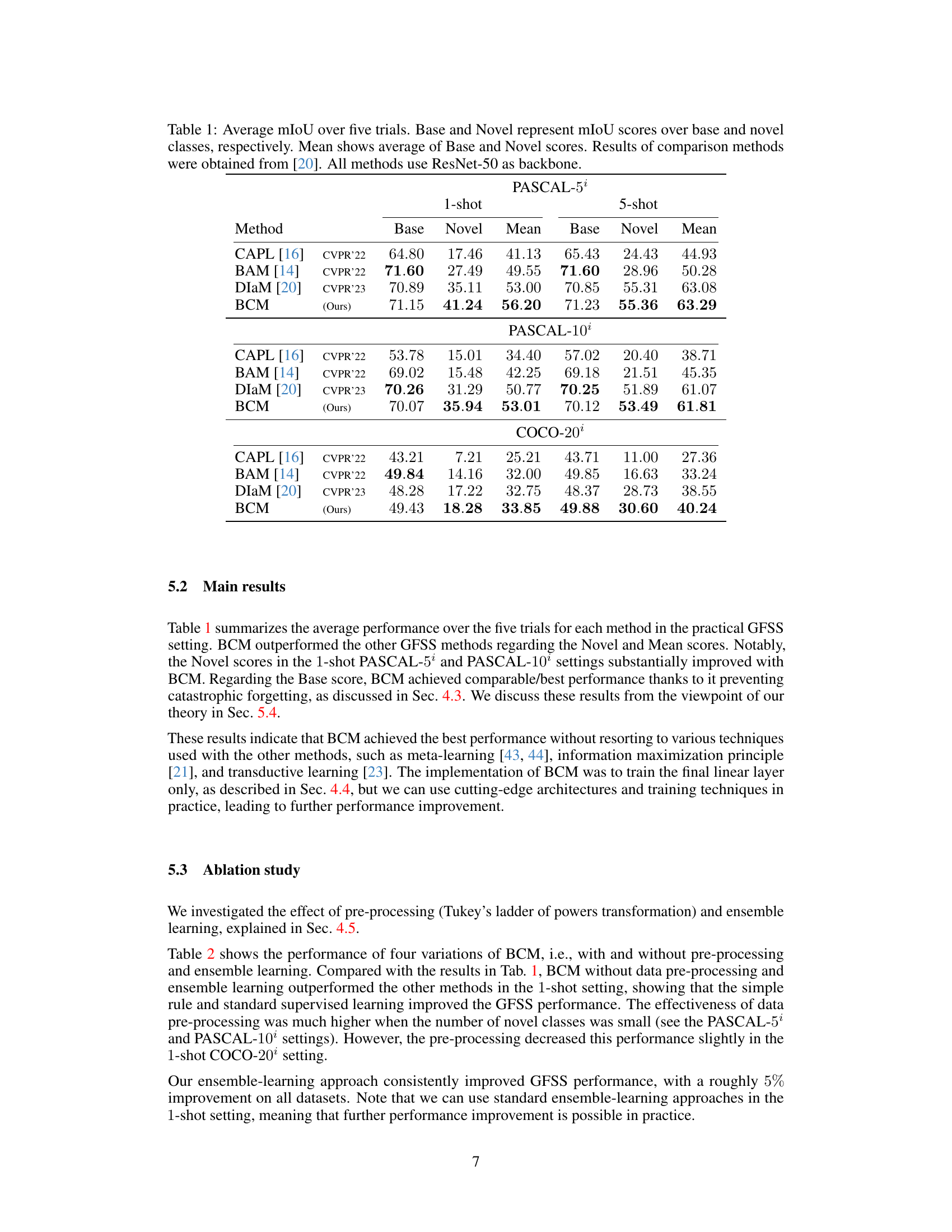
🔼 This figure illustrates the proposed Base-Class Mining (BCM) method for Generalized Few-Shot Semantic Segmentation (GFSS). The input image is first processed by a base-class model, which identifies base-class objects. If a novel class is detected, a simple rule determines which base class it is most closely related to. Then, a specialized model for that base class is used to refine the segmentation for the novel class. Models for each novel class are trained separately with standard supervised learning. This approach aims to maintain good performance on base classes while also effectively segmenting novel classes.
read the caption
Figure 1: Illustration of base-class mining (BCM) with three novel classes: “train”, “tv”, and “couch”. Base-class model first outputs prediction. If prediction is one of chosen base classes, corresponding model outputs prediction. Otherwise, prediction of base-class model is used as it is. Simple rule finds which base class is related to novel classes. Models for novel classes are trained by standard supervised learning.
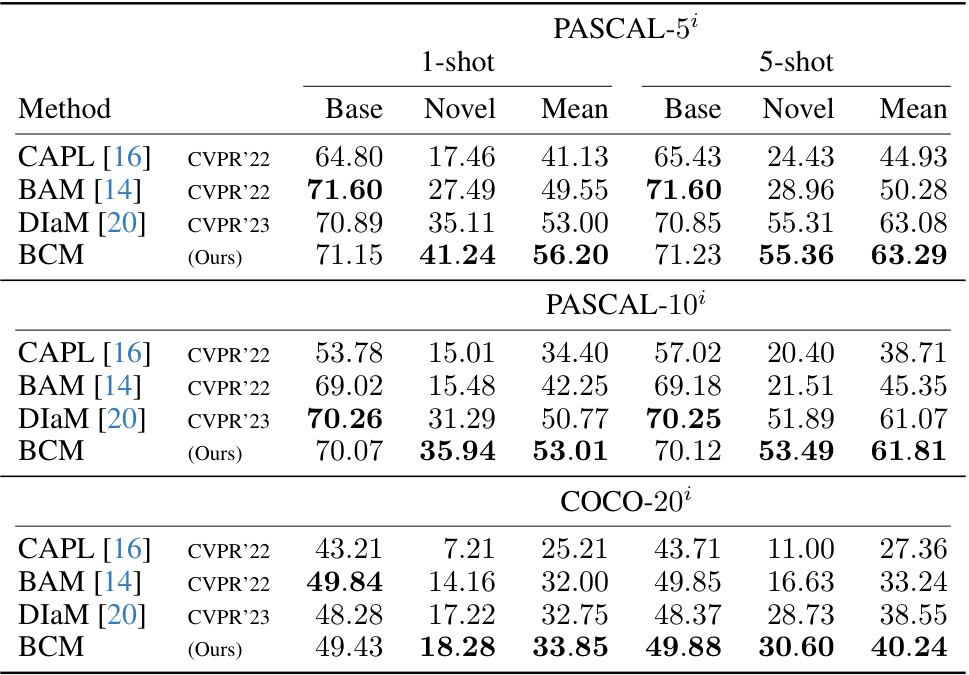
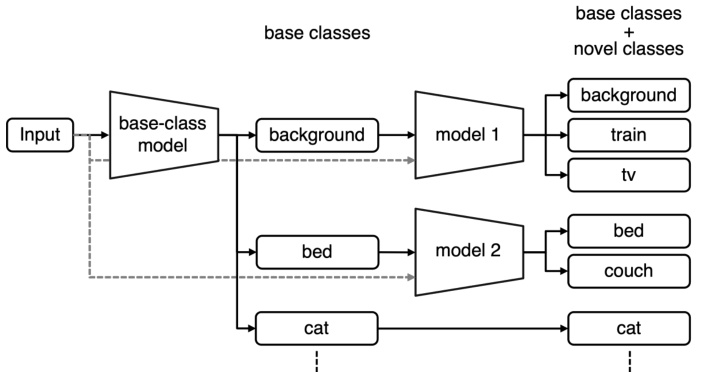
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by different methods (CAPL, BAM, DIaM, and BCM) on three datasets (PASCAL-5i, PASCAL-10i, and COCO-20i) for both base and novel classes in both 1-shot and 5-shot scenarios. The ResNet-50 model is used as the backbone for all methods. The results from CAPL, BAM, and DIaM are taken from a prior publication referenced in the paper.
read the caption
Table 1: Average mIoU over five trials. Base and Novel represent mIoU scores over base and novel classes, respectively. Mean shows average of Base and Novel scores. Results of comparison methods were obtained from [20]. All methods use ResNet-50 as backbone.
In-depth insights#
Simple GFSS#
The concept of ‘Simple GFSS’ suggests a streamlined approach to Generalized Few-Shot Semantic Segmentation, aiming to reduce complexity without sacrificing performance. This likely involves simplifying existing GFSS methods by eliminating intricate modules or computationally expensive techniques, such as meta-learning or transductive learning. The core idea might center on utilizing a basic rule-based system to connect novel classes to existing base classes, coupled with standard supervised learning for novel class training. This approach, while potentially less flexible, could offer advantages in terms of faster training and inference times, along with reduced resource consumption, making it more practical for real-world applications. Theoretical analysis is likely crucial to demonstrating that this simplified approach maintains adequate base class performance while achieving acceptable novel class segmentation accuracy. The effectiveness of a ‘Simple GFSS’ method would heavily depend on the cleverness of the base class selection strategy and careful tuning of the supervised learning process. Its success would represent a significant advance towards making GFSS more accessible and deployable.
BCM Method#
The BCM (Base-Class Mining) method, as described in the research paper, presents a surprisingly simple yet effective approach to Generalized Few-Shot Semantic Segmentation (GFSS). Its core innovation lies in identifying a close relationship between base and novel classes, rather than relying on complex meta-learning or intricate module designs. By mining base classes strongly correlated with novel classes, BCM leverages the existing base-class model to improve novel-class segmentation, while theoretically maintaining base-class performance. This is achieved through a straightforward rule that maps novel classes to the most closely related base classes, followed by training separate models for novel classes using standard supervised learning. The simplicity of BCM contrasts sharply with prior GFSS methods, which often involve time-consuming customized modules and complex loss functions. This simplicity makes it computationally efficient and easier to implement, offering a strong baseline for future GFSS research. The theoretical analysis further supports its efficacy by demonstrating that base-class performance is largely preserved. Empirical results show a significant improvement in novel-class segmentation, suggesting that BCM offers a practical and effective alternative in few-shot semantic segmentation.
Theoretical Proofs#
A dedicated ‘Theoretical Proofs’ section would significantly enhance a research paper. It should rigorously establish the validity of claims made within the paper. This involves clearly stating all assumptions, providing complete and formally correct proofs for all theorems and lemmas, and meticulously justifying any mathematical derivations. The clarity and rigor of the proofs are crucial for establishing trust and confidence in the paper’s findings. Any reliance on external sources should be explicitly referenced. A well-structured proof section ensures reproducibility and allows readers to understand not only the results but also the underlying theoretical framework. Furthermore, the inclusion of detailed proofs demonstrates a strong understanding of the theoretical underpinnings of the research and contributes to the overall credibility and impact of the paper. The proofs should be presented in a clear, concise, and accessible manner, ideally with illustrative examples to aid comprehension. Finally, the discussion of limitations and potential extensions of the theoretical results within this section would further improve the paper’s quality.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of this research paper, an ablation study concerning the heading, ‘Ablation Study’, would likely involve removing or altering specific elements of the proposed method (BCM) to assess their impact on performance. This would probably involve experiments with and without data preprocessing techniques (like Tukey’s ladder of powers transformation) and experiments using or omitting ensemble learning strategies. The results would illuminate which elements are crucial to BCM’s success and reveal potential areas for improvement or simplification. For example, if removing preprocessing significantly decreases performance, it highlights the preprocessing step’s importance. Conversely, minimal performance changes after removing a component could suggest it’s less vital and potentially removable for a more efficient model. A well-executed ablation study provides valuable insights into the model’s architecture, guiding future research directions by pinpointing which aspects are most critical for achieving optimal performance and robustness. It helps determine which parts to keep, potentially remove, or replace with alternative approaches for enhanced performance. This type of study forms a critical part of validating and understanding any novel method in machine learning.
Future Works#
Future work could explore several promising directions. Improving the efficiency and scalability of the proposed method, particularly for larger datasets and more complex scenes, is crucial. Investigating alternative strategies for base class selection and incorporating more sophisticated methods to leverage contextual information could further boost performance. A thorough analysis of the model’s robustness to various factors such as data imbalance and noise is also necessary. Finally, exploring applications beyond semantic segmentation such as object detection and instance segmentation, could expand the method’s utility and impact.
More visual insights#
More on figures

🔼 This figure illustrates the process of creating a Base-Novel Mapping (BNM). It starts by counting co-occurrences of base and novel classes in a sample image. These counts are aggregated across all samples to create a co-occurrence count table. Finally, a mapping is generated, associating each novel class with its most frequently co-occurring base class (top-1 strategy). The shaded cell in (b) highlights this most frequent co-occurrence for each novel class.
read the caption
Figure 2: Illustration of BNM creation. For illustration purpose, image of size 3 × 3 is used. (a) Count co-occurrences, i.e., (base class, novel class) pairs. There are three (0,4) and one (2, 4) co-occurrences. (b) Aggregate co-occurrence counts for all samples and create co-occurrence count table. (c) Create BNM from co-occurrence count table, where top-1 strategy finds base class with largest co-occurrences (shaded cell in Fig. 2b) for each novel class.
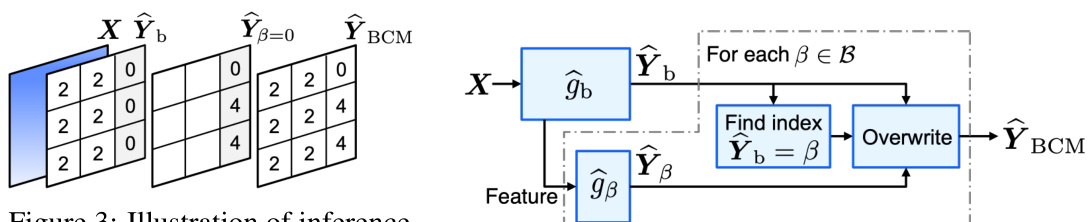
🔼 This figure illustrates the inference process of the Base-Class Mining (BCM) method. It shows that the base-class model’s prediction (Ŷb) is used as input. If the prediction from the base-class model matches a selected base class (β), the corresponding model (ĝβ) is used to generate a new prediction; otherwise, the original prediction is kept. This process occurs for each pixel, resulting in the final BCM prediction (ŶBCM).
read the caption
Figure 3: Illustration of inference. Ŷb, Ŷβ=0, and ŶBCM are predictions of ĝb, ĝβ=0, and BCM, respectively.

🔼 This figure illustrates the proposed Base-Class Mining (BCM) method. It shows how the method uses a base-class model to predict the class of an input image pixel. If the prediction is one of the chosen base classes, the corresponding model for that class is used to make a final prediction. If the prediction is not one of the chosen base classes, the base-class model’s prediction is used as the final prediction. A simple rule determines which base class is most related to the novel classes, and the models for the novel classes are trained with standard supervised learning.
read the caption
Figure 1: Illustration of base-class mining (BCM) with three novel classes: 'train', 'tv', and 'couch'. Base-class model first outputs prediction. If prediction is one of chosen base classes, corresponding model outputs prediction. Otherwise, prediction of base-class model is used as it is. Simple rule finds which base class is related to novel classes. Models for novel classes are trained by standard supervised learning.
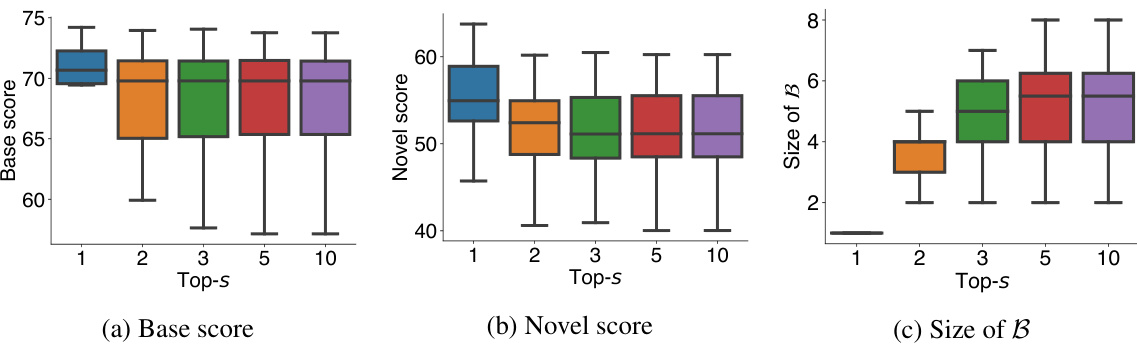
🔼 This figure shows the effect of varying the parameter ’s’ in the top-s strategy on the performance of the BCM method in a 5-shot scenario using the PASCAL-52 dataset. The top-s strategy determines how many base classes are selected to be associated with novel classes. The figure presents box plots illustrating the base score (mIoU over base classes), novel score (mIoU over novel classes), and the size of the set B (number of chosen base classes) for different values of ’s’ (1, 2, 3, 5, 10). The box plots show the median, quartiles, and outliers of the results over multiple trials, providing a clear visualization of the impact of s on the algorithm’s performance and the number of base classes used. The results suggest that increasing ’s’ does not always improve performance and may increase computation time.
read the caption
Figure 8: Effect of s in top-s strategy in 5-shot PASCAL-52 setting
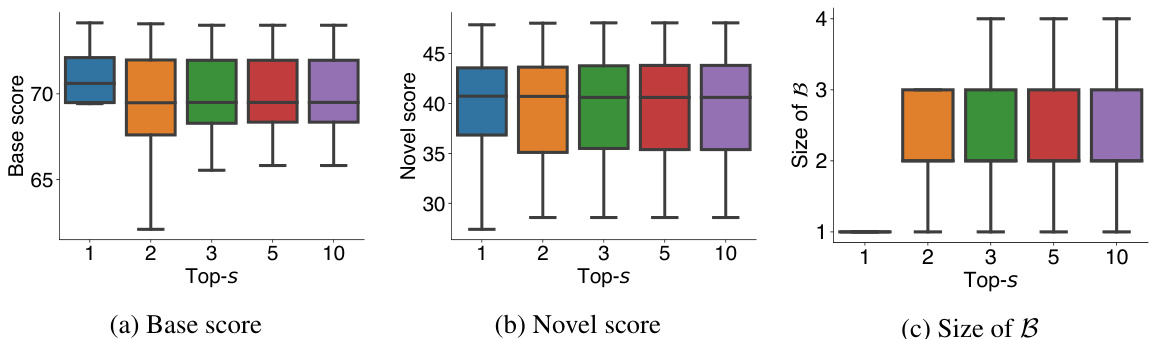
🔼 This figure shows the effect of varying the parameter ’s’ in the top-’s’ strategy on the performance of the proposed Base Class Mining (BCM) method for generalized few-shot semantic segmentation. The experiment was conducted using the PASCAL-52 dataset in a 5-shot setting. The box plots display the Base score (mIoU on base classes), Novel score (mIoU on novel classes), and the size of the set ‘B’ (number of base classes selected for training novel class models) for different values of ’s’ (1, 2, 3, 5, 10). The results show how changing ’s’ affects both base class and novel class segmentation performance and the number of base classes involved in the BCM process.
read the caption
Figure 8: Effect of s in top-s strategy in 5-shot PASCAL-52 setting

🔼 This figure shows the box plots of Base score, Novel score and the size of B (number of chosen base classes) for different values of ’s’ in the top-s strategy used in the proposed BCM method. The experiment was performed on the PASCAL-52 dataset with 5-shot setting. The box plot shows the median, 25th and 75th percentiles, and the whiskers extend to the most extreme data points not considered outliers. The figure demonstrates the impact of parameter ’s’ on the model performance and the number of base classes selected for novel class classification.
read the caption
Figure 8: Effect of s in top-s strategy in 5-shot PASCAL-52 setting
Full paper#