↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Robot learning struggles with generalization across tasks, hindering the development of truly versatile robots. Current methods often fail to efficiently transfer learned skills to new scenarios, even with large datasets. This is because they lack mechanisms to learn robust, reusable low-level skills which are critical for generalization. This is further complicated by the high cost and time required for collecting large-scale robot demonstration data.
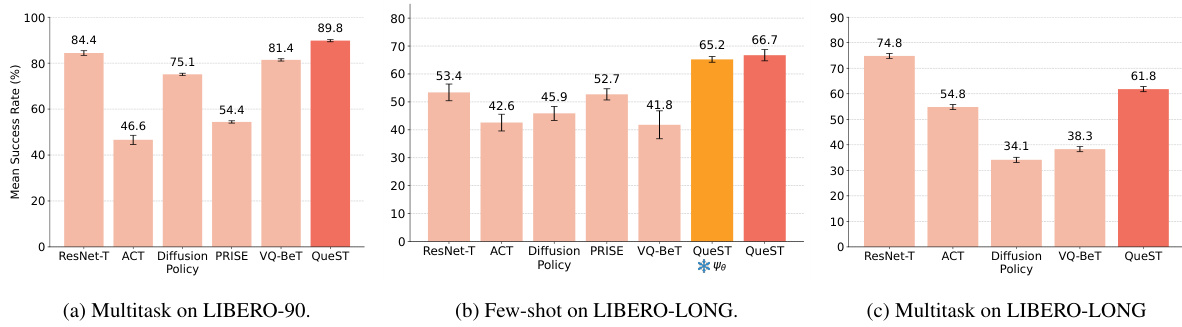
QueST tackles this challenge by introducing a novel self-supervised approach for learning temporal action abstractions, or “skills”, in a discrete latent space. This allows the model to learn shared representations across tasks, promoting generalization and transfer. Their experiments across several robotic manipulation benchmarks show that QueST’s architecture significantly outperforms state-of-the-art baselines for both multi-task and few-shot learning scenarios, demonstrating a substantial improvement over existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in robotics because it tackles the critical problem of generalization in robot learning. By introducing a novel self-supervised method that learns transferable low-level skills, it offers a significant advance in the field. This approach is particularly relevant given the limitations of current methods in achieving efficient cross-task transfer. The findings also open new avenues for research, including further development of skill abstraction techniques and their application to more challenging robotic tasks.
Visual Insights#

This figure provides a visual overview of the Quantized Skill Transformer (QueST) architecture. QueST is composed of two main stages: Stage I, which focuses on self-supervised skill abstraction, and Stage II, which utilizes the learned skills for decision-making in a multi-modal transformer setup. Stage I uses a causal convolutional 1D layer followed by a masked self-attention layer to process sequential action data. A finite scalar quantization (FSQ) layer then transforms these into discrete latent codes (skill tokens). Stage II employs an autoregressive transformer to predict the next token in a sequence of skill tokens, conditioned on the observations and task descriptions.

This table presents the results of ablating the causality in the QueST model. It shows the success rates for LIBERO-90 and few-shot learning experiments, comparing the performance of QueST when different components of the network are not causal (i.e., lack the inductive bias of only attending to past information). The results demonstrate that maintaining causality is crucial for QueST’s performance, particularly in few-shot scenarios.
In-depth insights#
Skill Abstraction#
Skill abstraction in robotics focuses on learning reusable and transferable representations of low-level actions, enabling robots to generalize to new tasks more effectively. The core idea is to distill complex behavior into a smaller set of meaningful primitives or ‘skills’, which can be combined and sequenced to achieve higher-level goals. This approach addresses the limitations of traditional methods that struggle to generalize beyond the training data, by promoting the learning of sharable representations across different tasks. Latent variable models (LVMs) are often employed for their capacity to compress data and discover latent structure in the data. A key challenge lies in faithfully capturing sharable representations that effectively capture the breadth of low-level skills, while simultaneously imparting causal inductive bias to ensure the learned representations are semantically meaningful and transferable. Approaches leveraging discrete latent spaces offer advantages in terms of interpretability and the ability to model multimodal action distributions, which is particularly relevant in robotics due to the inherent ambiguity and variation in real-world scenarios. This area of research is crucial to advancing the field of robotic learning by creating general-purpose robots capable of adapting to new and unseen situations.
QueST Model#
The QueST model, as described in the provided text, presents a novel approach to learning generalizable low-level robotic skills. Its core innovation lies in employing a quantized skill transformer architecture that learns temporal action abstractions within a discrete latent space. This approach contrasts with previous methods, addressing limitations such as the inability to effectively capture variable-length motion primitives or learn genuinely sharable representations across diverse tasks. QueST’s causal inductive bias, achieved through unique encoder-decoder designs and autoregressive modeling, fosters semantically meaningful and transferable representations. The model excels in multitask and few-shot imitation learning benchmarks, significantly outperforming state-of-the-art baselines and demonstrating effective long-horizon control. Flexibility in capturing skill variations and transferability across tasks are key strengths. The use of a discrete latent space, coupled with a transformer-based decoder, is crucial to QueST’s success, particularly when dealing with multimodality and complex, variable-length skills.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a detailed comparison of the proposed method against existing state-of-the-art techniques. This would involve selecting relevant and established benchmarks, clearly defining evaluation metrics (e.g., accuracy, precision, recall, F1-score, runtime), and presenting results in a clear and easily digestible format (e.g., tables, charts). Statistical significance testing should be applied to determine if observed performance differences are meaningful. A thoughtful analysis of the results is crucial, explaining any discrepancies and providing insights into why the proposed method performs better or worse than others in certain scenarios. The discussion should also highlight the limitations of the benchmark itself and address any potential biases. Finally, a summary of the key findings, emphasizing the relative strengths and weaknesses of the different approaches, would conclude the section. The goal is to provide a comprehensive and nuanced evaluation that allows readers to accurately assess the contribution of the new method.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, these studies are crucial for establishing causality and isolating factors affecting model performance. A well-designed ablation study would focus on key architectural choices, such as specific layers, modules, or regularization techniques. By removing these elements one by one and observing changes in performance metrics (e.g., accuracy, precision, recall), researchers can understand which parts are most impactful for the model’s success. A good ablation study should include a control experiment, where nothing is changed to provide a baseline performance comparison. Furthermore, clear visualizations help present the findings effectively. The discussion section of the ablation study should interpret the results, explaining why some components significantly impact performance and others do not. This provides valuable insights into the model’s behavior and can inform future model design improvements.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Improving the scalability of the model to handle even larger datasets and more complex tasks is crucial. This might involve investigating more efficient architectures or leveraging techniques like model parallelism. Enhancing the generalizability of the learned skills is another key area; exploring methods to learn more robust and transferable representations across diverse environments and tasks would be valuable. Furthermore, investigating alternative methods for skill discovery and representation beyond vector quantization is warranted, potentially exploring continuous latent spaces or hybrid approaches. Finally, integrating this skill abstraction framework with higher-level planning and decision-making modules would create a more complete and robust robotic system. This could involve connecting the skill representations to more advanced planning algorithms, such as those based on hierarchical reinforcement learning or model predictive control.
More visual insights#
More on figures
This figure shows the architecture of the Quantized Skill Transformer (QueST) model. QueST consists of two stages. Stage I is a self-supervised skill abstraction stage where a quantized autoencoder learns low-dimensional representations of action sequences. These representations, called ‘skill tokens’, capture temporal action abstractions. Stage II is a decision-making stage using a multi-modal transformer that takes task descriptions and observations as input along with the skill tokens to predict action sequences.

The figure illustrates the Quantized Skill Transformer (QueST) architecture, which factorizes the policy into two stages. Stage I involves self-supervised skill abstraction using a quantized autoencoder, learning a sequence of skill tokens from action sequences. Stage II uses a multi-modal transformer for decision making, predicting actions based on the skill tokens, task descriptions, and observations.
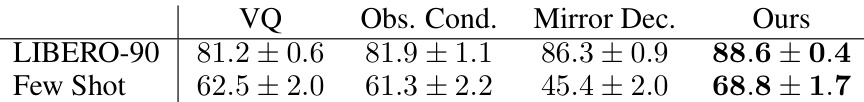
This figure shows the overall architecture of the Quantized Skill Transformer (QueST) model. It is composed of two stages. Stage I is a self-supervised skill abstraction stage that uses a quantized autoencoder to learn a representation of action sequences as a sequence of skill tokens. Stage II is a decision-making stage that uses a multi-modal transformer to predict actions based on the skill tokens and task descriptions. The figure also shows the flow of data through the model, including the input observations, task descriptions, and predicted actions.
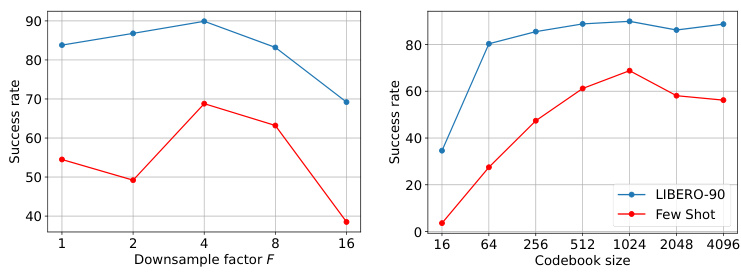
The figure shows two plots that analyze the sensitivity of the model’s performance to the downsampling factor and codebook size hyperparameters. The left plot shows that for LIBERO-90, the success rate generally increases as the downsampling factor increases, peaking at F=4 before declining. For the few-shot setting, the success rate peaks at F=4 but is much more sensitive to changes in this hyperparameter. The right plot demonstrates that for both LIBERO-90 and few-shot settings, the success rate generally increases with codebook size, though it begins to plateau beyond a codebook size of 1024. Overall, the plots suggest that a downsampling factor of 4 and a codebook size of 1024 are optimal choices for the model.

This figure shows the overall architecture of the Quantized Skill Transformer (QueST) model. It is composed of two stages: Stage I, which is a self-supervised skill abstraction module using a quantized autoencoder, and Stage II, which is a decision-making module that uses a multi-modal transformer to predict actions based on task descriptions and observations. The autoencoder learns a sequence of skill tokens from input actions and observation to generate low-dimensional representations of action sequences (skills), while the multi-modal transformer predicts sequences of actions by taking the skill tokens as input and performing next-token prediction. The model is designed to learn generalizable low-level skills from complex multitask demonstration data.
More on tables

This table lists the hyperparameters used in Stage 1 of the Quantized Skill Transformer model, specifically for the self-supervised skill abstraction stage. It details the dimensions of the encoder and decoder, sequence length, number of attention heads and layers in both encoder and decoder, attention dropout rate, FSQ quantization levels, number of convolutional layers, and the downsampling factor used in the encoder.
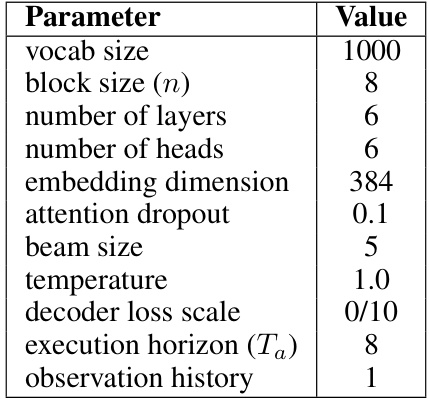
This table lists the hyperparameters used in Stage 2 of the Quantized Skill Transformer model. These hyperparameters govern the autoregressive transformer’s behavior, including aspects like vocabulary size, network architecture depth and width, dropout regularization, and inference-time settings such as temperature and beam search width. The ‘decoder loss scale’ and ‘observation history’ parameters influence the training and the way the model incorporates prior observations.

This table presents the results of ablating different design choices of QueST on the LIBERO benchmark. It compares the performance of QueST with variations where (1) Vector Quantization (VQ) is used instead of Finite Scalar Quantization (FSQ), (2) The decoder is conditioned on observations, and (3) A mirrored decoder is used instead of the proposed decoder. The ‘Ours’ column represents the performance of the original QueST model.

This table shows the results of ablating the causality in the QueST model. It compares the performance of the model with different levels of causality removed from the encoder, decoder, or both, against the fully causal model. The results demonstrate the importance of causality for achieving good performance, particularly in the few-shot learning setting.

This table presents the results of an ablation study on the impact of fine-tuning the decoder in the few-shot imitation learning setting. It compares the success rates achieved with a frozen decoder versus a fine-tuned decoder, using different loss scales (10 and 100). The results indicate the performance improvement obtained by fine-tuning the decoder for this specific setting.

This table presents the success rates of different models on 10 unseen tasks from the LIBERO-LONG dataset. Each model was fine-tuned using only 5 demonstrations per task. The results represent the average success rate across 9 separate random trials, showing the performance variability.
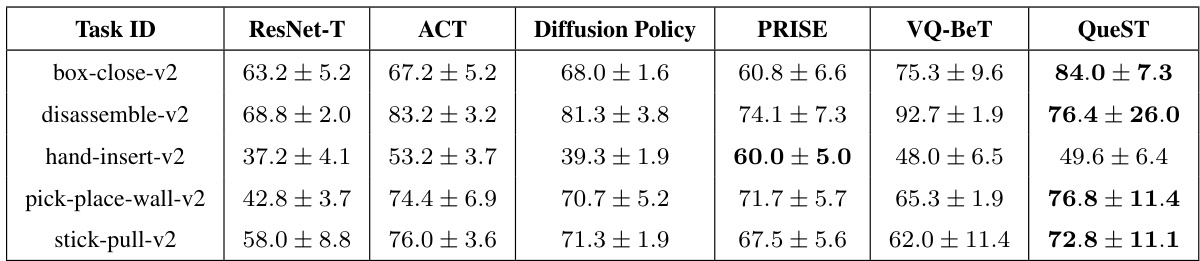
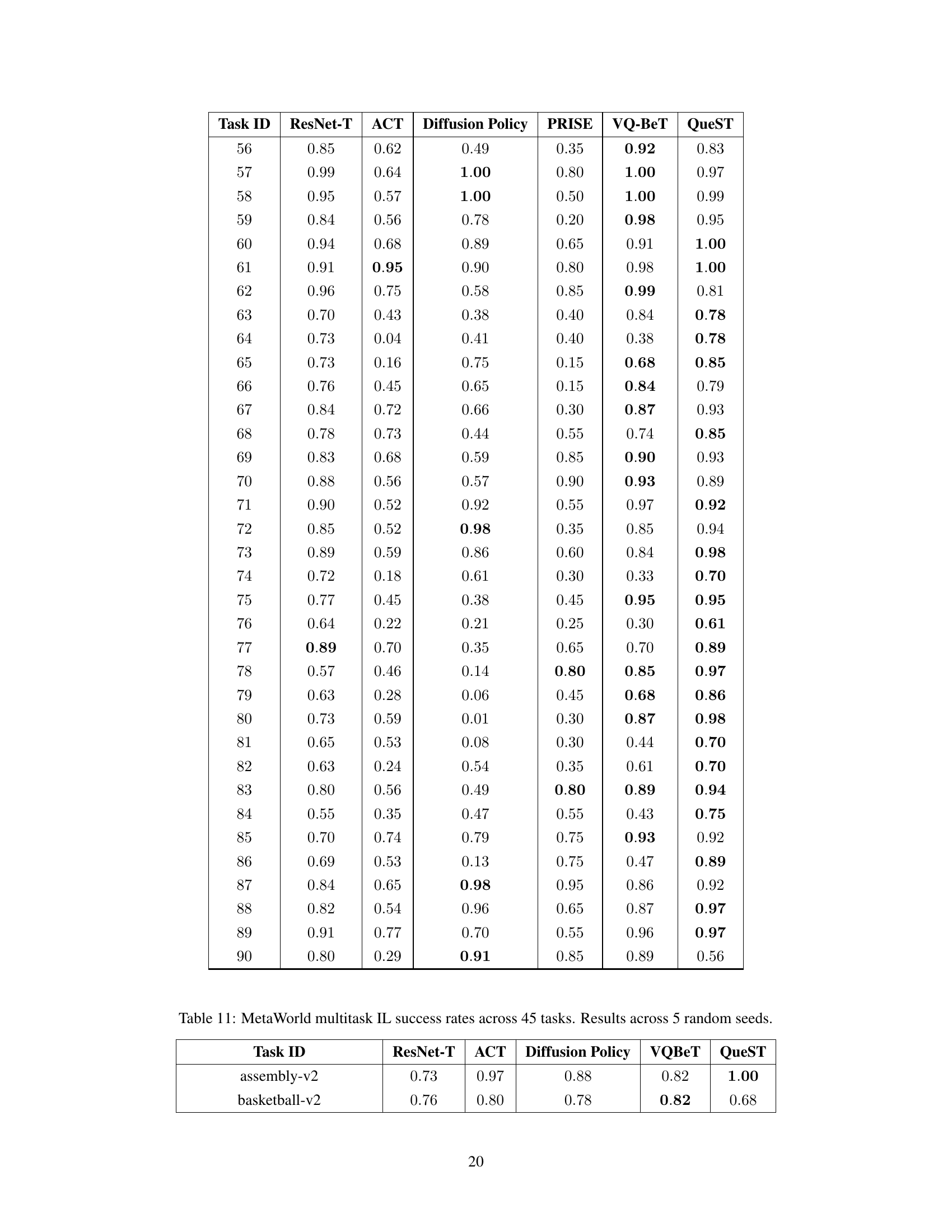
This table presents the results of a few-shot imitation learning experiment on the MetaWorld benchmark. Five unseen tasks were used, and the model was fine-tuned on only five demonstrations from each task. The table shows the average success rate across five random seeds for each of the tasks and for each of the compared methods. The methods compared are ResNet-T, ACT, Diffusion Policy, PRISE, VQ-BeT, and QueST. The success rate is a measure of how often the robot successfully completed the task.
This table presents the success rates achieved by different models (ResNet-T, ACT, Diffusion Policy, PRISE, VQ-BeT, and QueST) on five unseen tasks from the MetaWorld benchmark. The results are based on a 5-shot learning setting, meaning that each model was finetuned using only five demonstrations from each task. The table shows that QueST significantly outperforms the baselines in this setting.

This table presents the success rates of different models on five unseen tasks from the MetaWorld benchmark using a 5-shot learning approach. The results are averaged across five random seeds, providing a measure of performance variability and reliability.
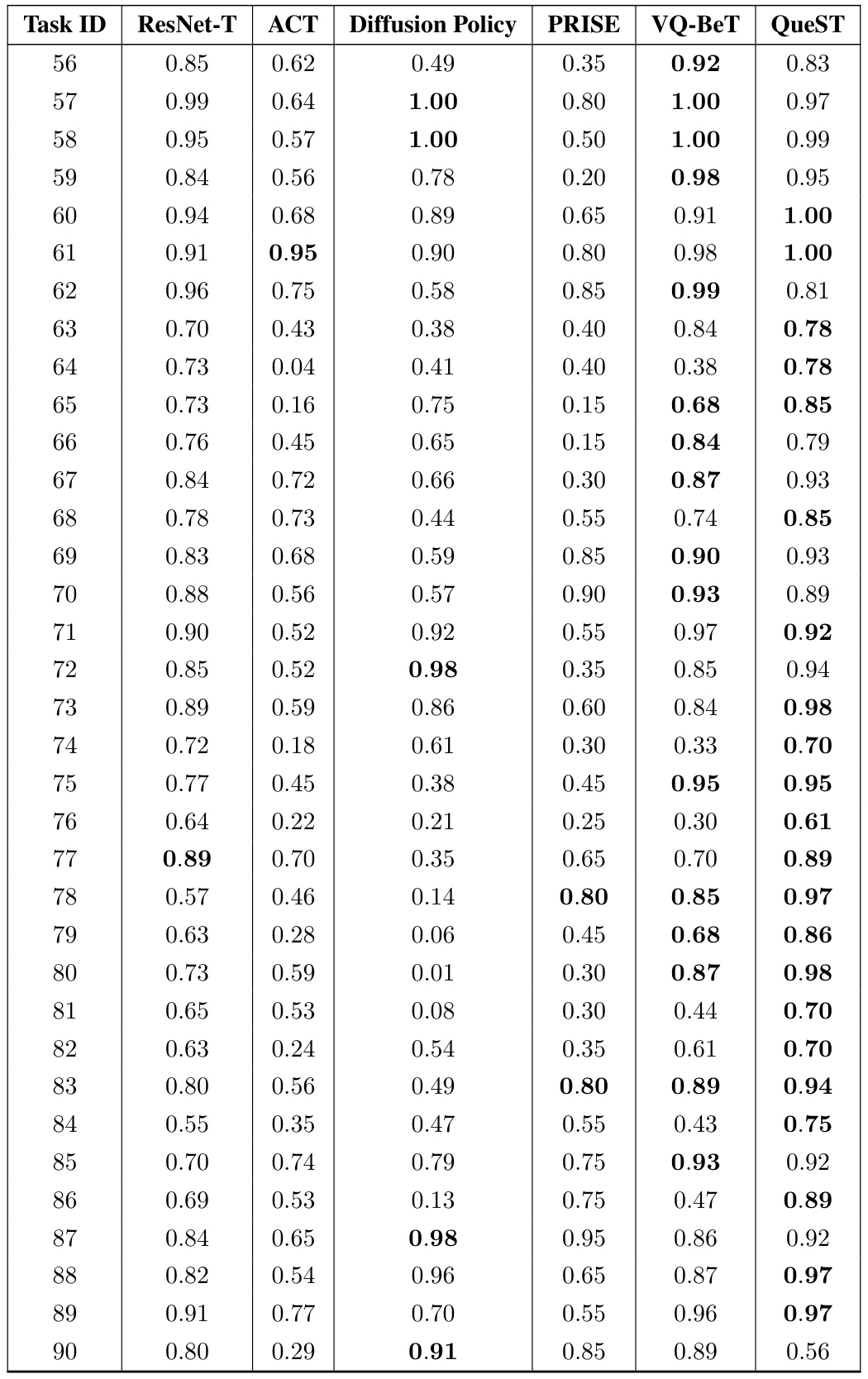
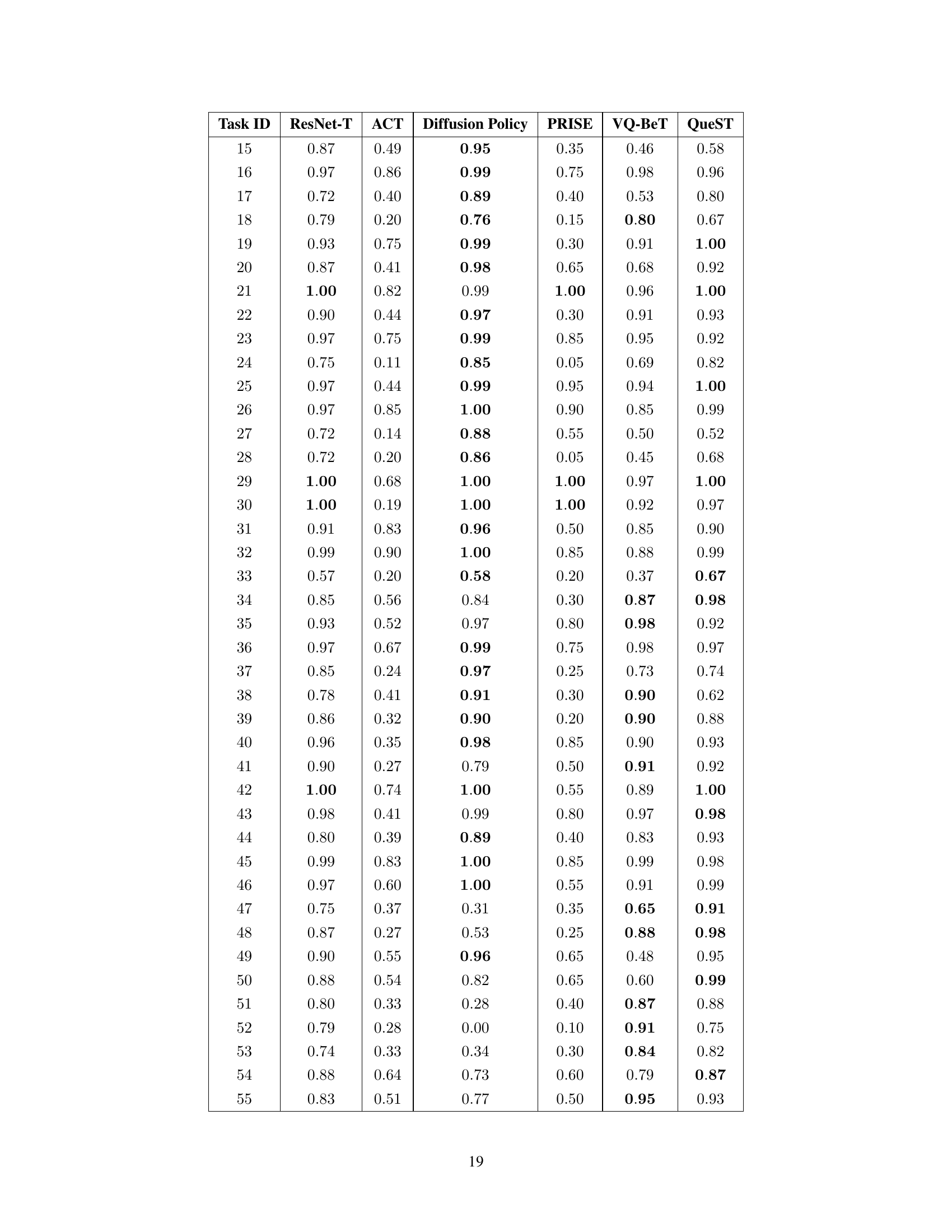
This table presents the success rates of different models (ResNet-T, ACT, Diffusion Policy, PRISE, VQ-BeT, and QueST) on 45 multi-task imitation learning tasks from the MetaWorld benchmark. The results are averaged across five random seeds, providing a measure of the model’s performance and its robustness to variations due to random initialization. Higher success rates indicate better performance on these manipulation tasks.

This table presents the results of a few-shot imitation learning experiment on five unseen tasks from the MetaWorld benchmark. The model was pre-trained and then fine-tuned on a small number of demonstrations (5) for each new task. The table shows the average success rate across five random seeds for each task, comparing the performance of QueST against several baseline methods (ResNet-T, ACT, Diffusion Policy, PRISE, VQ-BeT). The success rate is a measure of how well the model was able to successfully complete each task after few-shot learning. The table helps to evaluate the generalization ability of different models in a low-data setting.

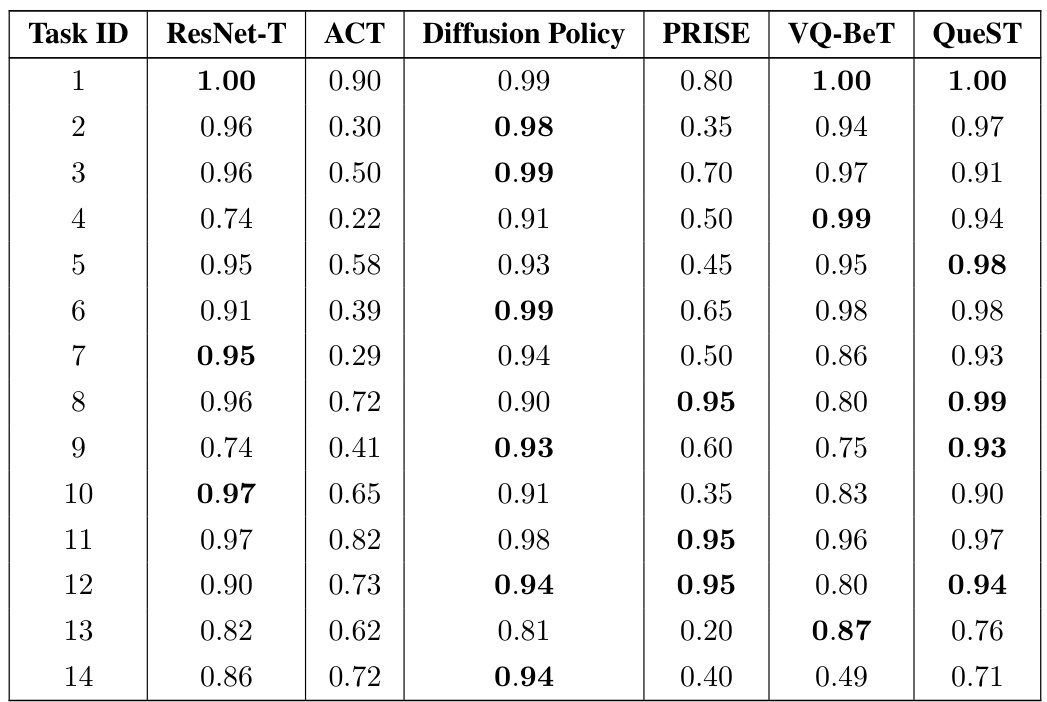
This table presents the success rates achieved by different models on 90 multitask imitation learning tasks from the LIBERO-90 benchmark. The results are averages across four random seeds, providing a measure of the model’s robustness and performance consistency across different runs. Each row represents a single task, and the columns display the success rates for each of the compared models (ResNet-T, ACT, Diffusion Policy, PRISE, VQ-BeT, and QueST). The table allows for a direct comparison of the models’ performance on each task and overall multitask performance.

This table presents the results of a multitask imitation learning experiment on the LIBERO-90 benchmark. It shows the success rates achieved by QueST and several baseline methods across 90 different manipulation tasks. The results are averaged across four random seeds to assess the stability and reliability of the performance.
Full paper#