TL;DR#
Fine-tuning large language models often compromises their robustness to distribution shifts. Existing methods mainly focus on preserving pre-trained features, but not all such features are robust. This leads to suboptimal out-of-distribution (OOD) performance, a critical limitation for real-world applications. The paper addresses this challenge by proposing a novel method that better balances model performance and robustness.
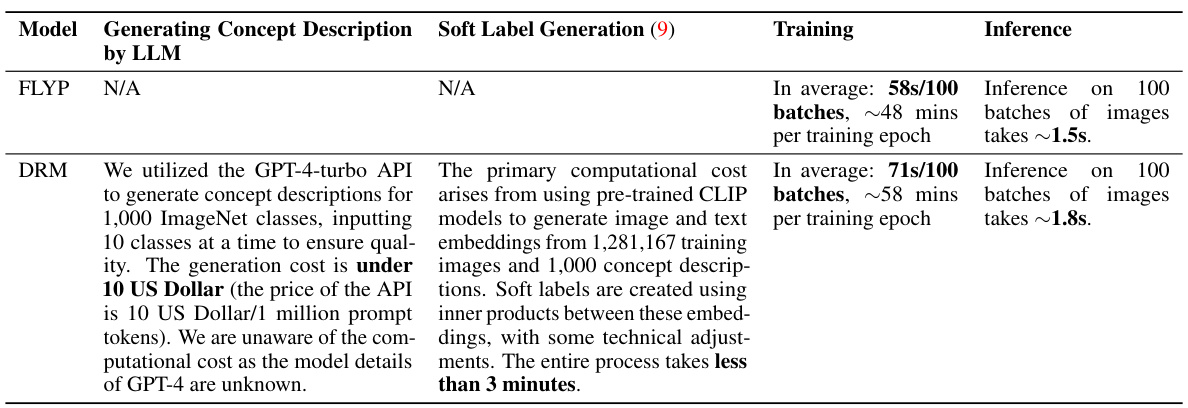
The paper introduces Dual Risk Minimization (DRM), which combines empirical risk minimization (ERM) with worst-case risk minimization (WRM). To estimate the worst-case risk, DRM cleverly uses Large Language Models (LLMs) to generate core-feature descriptions, enabling a more focused and effective preservation of robust features. The empirical results demonstrate that DRM significantly improves OOD performance across various benchmarks, establishing a new state-of-the-art.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on robust fine-tuning of foundation models, especially in zero-shot settings. It introduces a novel approach that directly addresses the common issue of reduced robustness after fine-tuning. The proposed method bridges the gap between expected and worst-case performance, leading to significant improvements in out-of-distribution generalization. This work paves the way for future research on improving the robustness and generalization capabilities of foundation models across diverse applications.
Visual Insights#
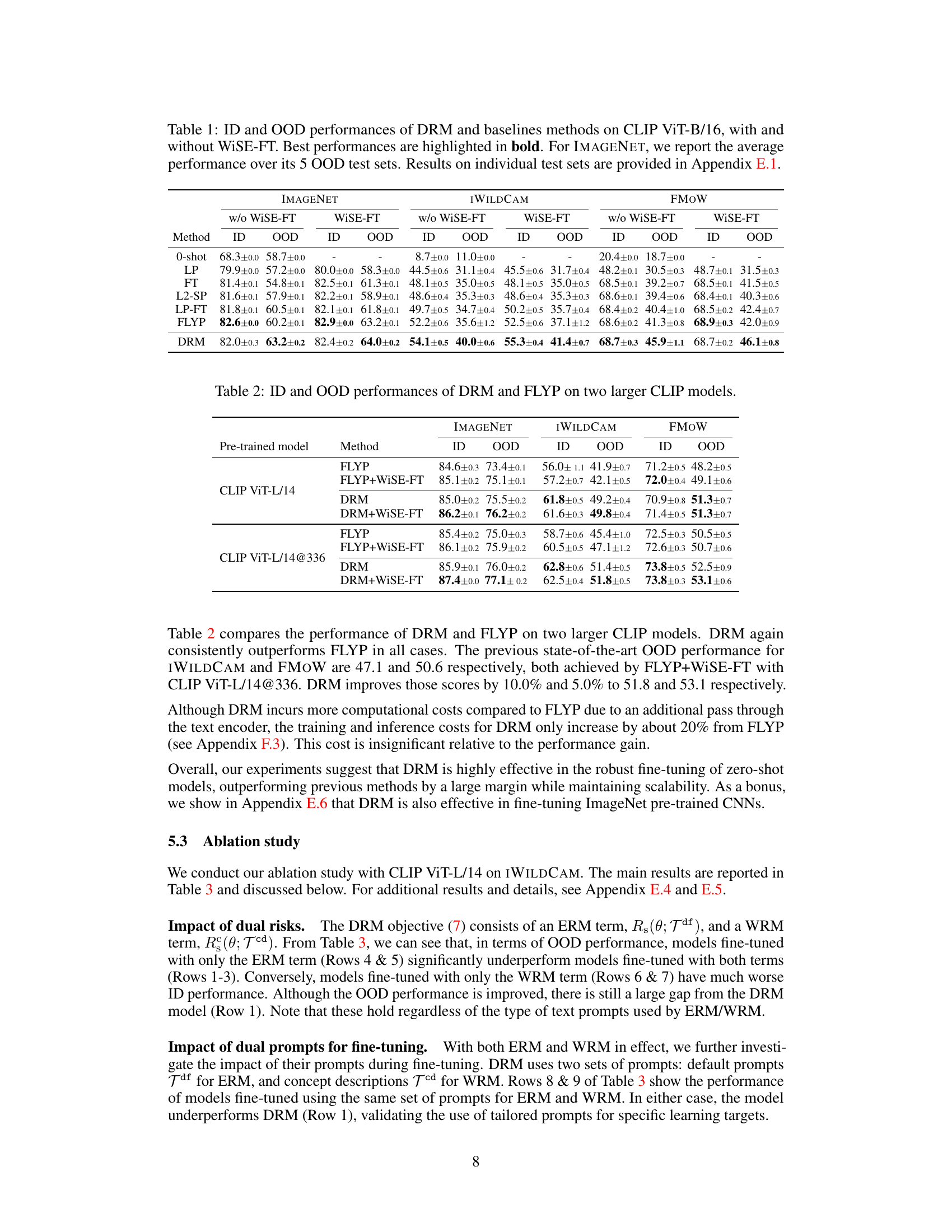
🔼 This figure illustrates the core concept of Dual Risk Minimization (DRM) by comparing it to Empirical Risk Minimization (ERM) and Worst-Case Risk Minimization (WRM). It uses a simple binary classification example (detecting skis in an image) to show how ERM and WRM each fail under specific conditions (clear core features with spurious non-core features for ERM; unclear core features with robust non-core features for WRM). DRM is presented as a superior method that balances the strengths of both ERM and WRM to achieve better robustness in more general settings.
read the caption
Figure 1: Dual risk minimization (DRM) combines empirical risk minimization (ERM) and worst-case risk minimization (WRM) to complement their weaknesses. In this simple binary classification task predicting if there are skis in a given image, (i) ERM underperforms when the core features (the appearance of ski) are clear but the non-core features such as background/context are spurious (i.e., negatively correlated with ski), and (ii) WRM underperforms when the core features are unclear but the non-core features are robust (i.e., positively correlated with ski). DRM outperforms ERM and WRM under mild conditions such that the core features are not always clear and the non-core features are more often robust than not.
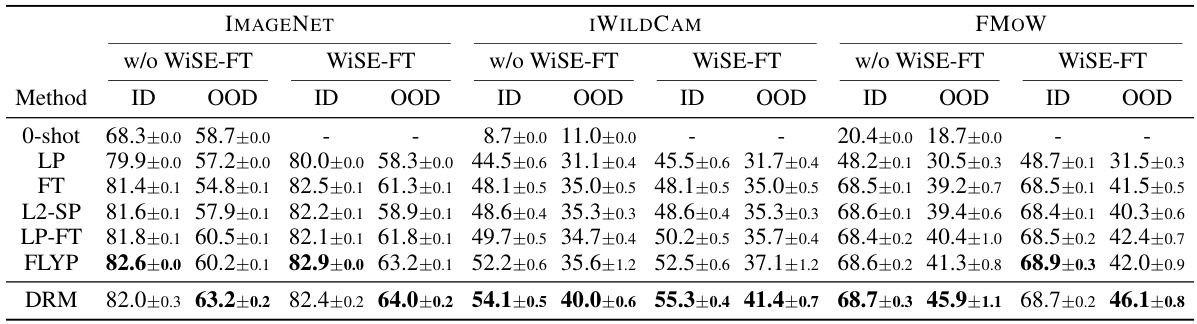
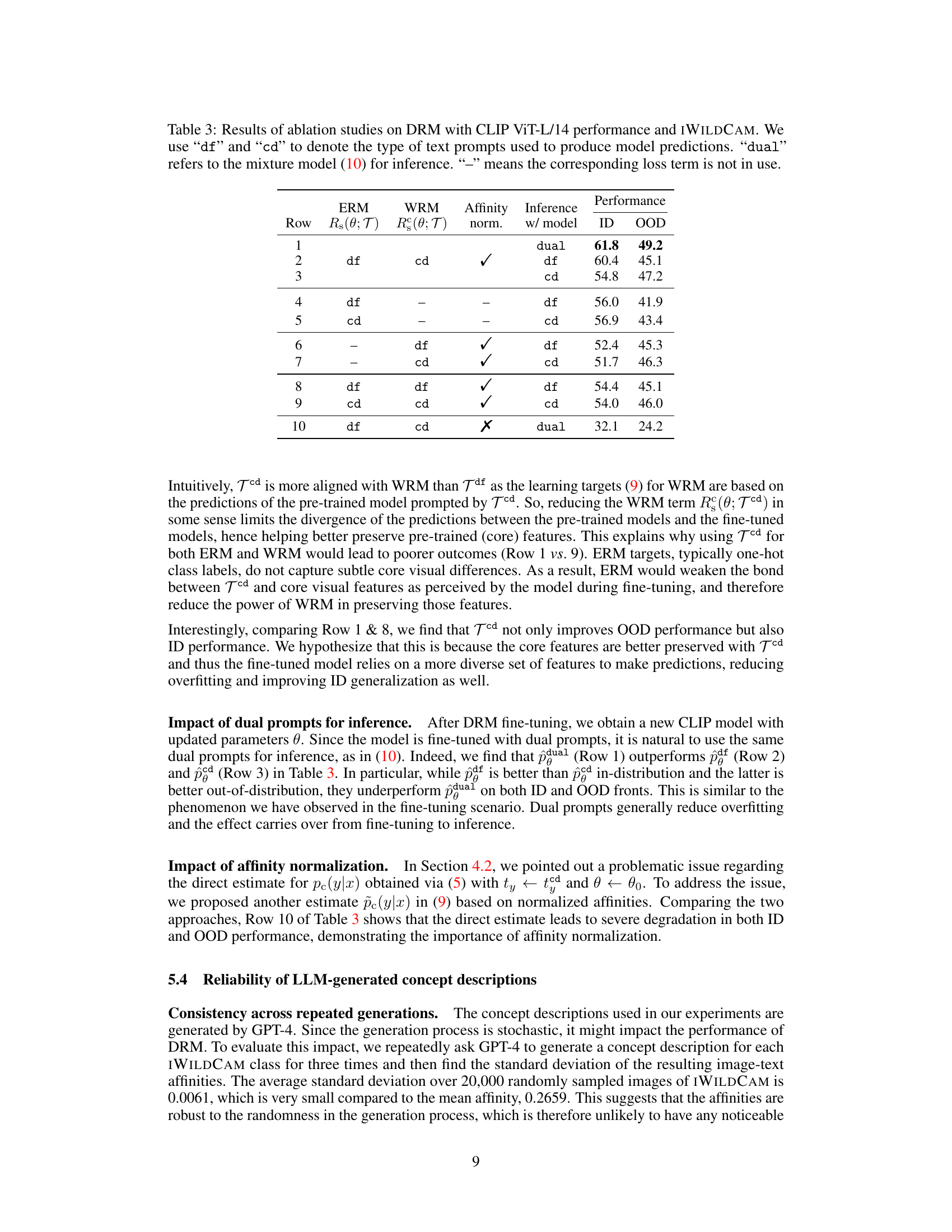
🔼 This table presents the in-distribution (ID) and out-of-distribution (OOD) performance of the Dual Risk Minimization (DRM) method and several baseline methods on the CLIP ViT-B/16 model. The results are shown for the ImageNet dataset (with five OOD variations) and two WILDS datasets: iWildCam and FMoW. WiSE-FT (weight-space averaging) is also applied as a post-processing step, and results are reported both with and without its application. The best performing method for each metric is highlighted in bold.
read the caption
Table 1: ID and OOD performances of DRM and baselines methods on CLIP ViT-B/16, with and without WiSE-FT. Best performances are highlighted in bold. For IMAGENET, we report the average performance over its 5 OOD test sets. Results on individual test sets are provided in Appendix E.1.
In-depth insights#
Dual Risk Minimization#
The concept of “Dual Risk Minimization” presents a novel approach to enhance the robustness of fine-tuned zero-shot models. It cleverly combines empirical risk minimization (ERM), focusing on average performance, with worst-case risk minimization (WRM), which addresses potential failures under distribution shifts. This dual approach acknowledges that robustness requires optimizing both expected and worst-case performance, unlike traditional ERM-only methods. The key innovation lies in estimating the WRM component using Large Language Model (LLM)-generated concept descriptions, which serve as proxies for core feature representations. These descriptions capture the essence of target classes, enabling the model to prioritize the preservation of robust, class-defining features even during fine-tuning. This approach is particularly effective for addressing challenges associated with out-of-distribution (OOD) generalization, demonstrating significant improvements over state-of-the-art methods across various real-world benchmarks. The practical implementation of DRM offers a balanced approach, preventing the overfitting often observed with ERM while maintaining competitive in-distribution performance.
Core Feature Focus#
The concept of ‘Core Feature Focus’ in the context of robust fine-tuning for zero-shot models is crucial. It highlights the importance of identifying and preserving the most essential features learned during pre-training, which are vital for downstream task performance even under distribution shifts. Methods that indiscriminately preserve all pre-trained features risk incorporating spurious correlations, leading to overfitting and poor generalization. A core feature focus strategy, therefore, should prioritize the identification of truly robust and generalizable features, potentially using techniques like those based on large language models (LLMs) to describe core concepts. By emphasizing these core features, fine-tuning can maintain robustness, improve out-of-distribution performance, and reduce the negative impact of distribution shifts. Effective identification of core features is a key challenge, requiring careful consideration of feature representation, model architecture, and the task itself. The success of this approach hinges on the capability to reliably distinguish between core and non-core features, paving the way for more robust and reliable zero-shot model adaptation.
Prompt Engineering#
Prompt engineering plays a crucial role in leveraging the full potential of large language models (LLMs) like GPT-4. Effective prompts guide the LLM towards generating desired outputs, whether it’s concept descriptions for robust feature extraction or crafting targeted queries for specific downstream tasks. The choice of prompting strategy significantly impacts the model’s performance, particularly its robustness to out-of-distribution data. Default prompts often fail to isolate core features, leading to reliance on spurious correlations and reduced generalization. In contrast, carefully designed prompts, particularly those generated by LLMs themselves, can elicit more robust feature representations. This is evidenced by the study’s use of concept descriptions obtained from GPT-4 to identify core visual features and enhance model robustness during fine-tuning. The process is iterative; prompt design requires careful consideration and experimentation to find the optimal balance between expected and worst-case performance. This necessitates a balance between utilizing pre-trained features and adapting to specific downstream tasks, where concept descriptions aid in preserving core features for enhanced robustness.
Robustness Tradeoffs#
The concept of ‘Robustness Tradeoffs’ in the context of machine learning models is crucial. It highlights the inherent tension between a model’s performance on the training data and its generalization ability to unseen data, especially when distribution shifts occur. Improving a model’s robustness to one type of distribution shift might inadvertently compromise its resilience to others. This tradeoff often arises because methods enhancing robustness, like those preserving pre-trained features, can restrict the model’s capacity to adapt optimally to new tasks. The ideal scenario involves finding an optimal balance between maximizing accuracy on known distributions and ensuring reasonable performance under diverse, unexpected conditions. This requires careful consideration of various factors, including the choice of training data, regularization techniques, and the specific metrics used to assess robustness. The ‘fine-tune like you pre-train’ (FLYP) approach attempts to maintain this balance by limiting the alteration of pre-trained features. However, even FLYP might not fully address the robustness tradeoffs, hence, novel methods like Dual Risk Minimization (DRM) strive to improve robustness while minimizing the performance decrease in expected scenarios. Ultimately, navigating these tradeoffs is essential for creating reliable and robust AI systems.
Future Directions#
The research paper on Dual Risk Minimization (DRM) for robust fine-tuning of zero-shot models opens exciting avenues for future work. A deeper theoretical investigation into DRM’s underlying principles and its connection to other robustness frameworks like Invariant Risk Minimization (IRM) is crucial. This will involve exploring the conditions under which the duality gap between the ideal and practical DRM formulations is small, and developing more efficient algorithms for solving the dual optimization problem. Improving the scalability of DRM to handle even larger models and datasets, potentially through distributed optimization techniques or model-parallel training strategies, is essential for real-world applications. Extending DRM to other model architectures beyond CLIP and CNNs, such as large language models and diffusion models, will broaden its impact. Furthermore, research into alternative methods for estimating worst-case risk, perhaps by leveraging more advanced LLMs or incorporating uncertainty quantification techniques, can improve DRM’s effectiveness. Finally, a more comprehensive empirical evaluation across a wider range of downstream tasks and datasets, especially those with different types of distribution shifts, will be critical to further demonstrate the robustness and generalizability of DRM.
More visual insights#
More on figures

🔼 This figure shows that using concept descriptions as prompts for image classification is more robust to changes in background (non-core features) and more sensitive to changes in foreground (core features) than using default prompts. The results suggest that concept descriptions are better at identifying core features, which are essential for robust classification.
read the caption
Figure 2: Concept descriptions better capture core features than default prompts. The affinities between images and default prompts (df) are not stable w.r.t. changes in image background (BG) containing non-core features and are insensitive to changes in image foreground (FG) containing core features, as indicated by the relative changes (gray numbers in parentheses) w.r.t. the affinities of the original images. In contrast, the affinities between images and concept descriptions (cd) are stable w.r.t. to changes in BG while being highly responsive to changes in FG, making them a good detector for core features. See Appendix D.1 for more examples and a full quantitative study on this.

🔼 This figure illustrates the strengths and weaknesses of three different risk minimization approaches for a binary classification task: ERM, WRM, and DRM. ERM performs poorly when there are spurious features (features that correlate negatively with the target). WRM underperforms when core features are unclear but non-core features are robust (features that correlate positively with the target). DRM, by combining ERM and WRM, aims to overcome these limitations and achieve better performance by striking a balance between expected performance and worst-case performance.
read the caption
Figure 1: Dual risk minimization (DRM) combines empirical risk minimization (ERM) and worst-case risk minimization (WRM) to complement their weaknesses. In this simple binary classification task predicting if there are skis in a given image, (i) ERM underperforms when the core features (the appearance of ski) are clear but the non-core features such as background/context are spurious (i.e. negatively correlated with ski), and (ii) WRM underperforms when the core features are unclear but the non-core features are robust (i.e. positively correlated with ski). DRM outperforms ERM and WRM under mild conditions such that the core features are not always clear and the non-core features are more often robust than not.
More on tables
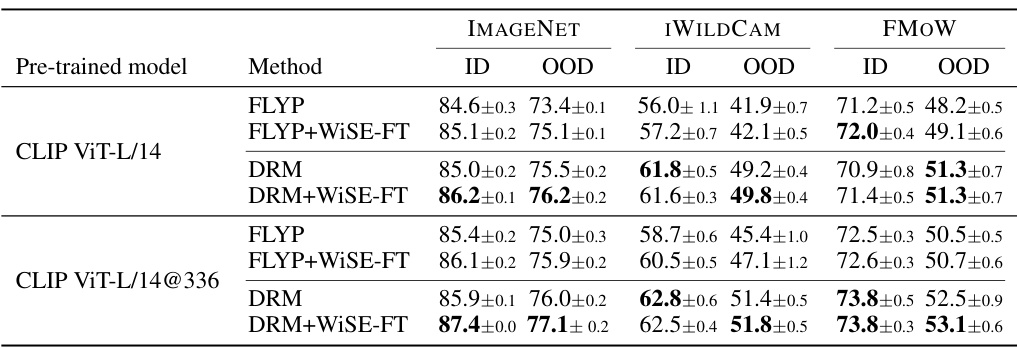
🔼 This table presents the in-distribution (ID) and out-of-distribution (OOD) performance results for two larger CLIP models (ViT-L/14 and ViT-L/14@336) using two methods: FLYP and DRM. The performance is evaluated across three benchmark datasets: ImageNet, iWildCam, and FMoW. For each dataset, the ID and OOD accuracy (or macro F1 score) are reported for both methods. This allows comparison of the relative performance improvements provided by DRM over FLYP on larger models.
read the caption
Table 2: ID and OOD performances of DRM and FLYP on two larger CLIP models.
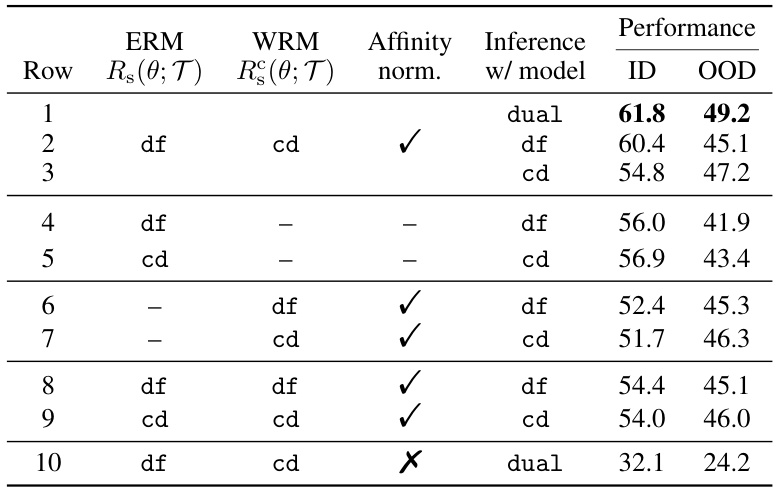
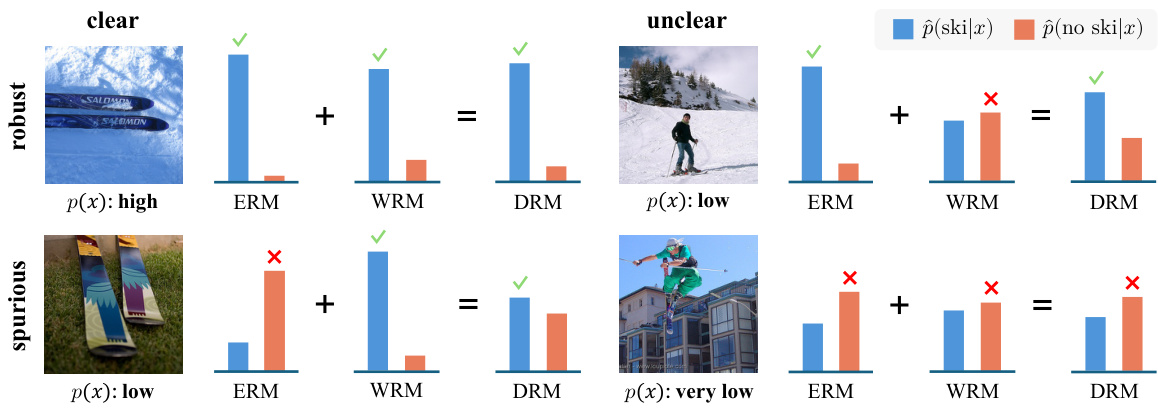
🔼 This table presents the ablation study results performed on the iWildCam dataset using the CLIP ViT-L/14 model without WiSE-FT. It systematically investigates the impact of different design choices within the Dual Risk Minimization (DRM) framework on both In-distribution (ID) and Out-of-distribution (OOD) performance. The table explores variations in using dual prompts for ERM and WRM, and also evaluates the effects of including affinity normalization, testing individual loss terms (ERM or WRM only), and comparing different inference strategies (using a combination of ERM and WRM outputs or using only one).
read the caption
Table 3: Results of ablation studies on DRM with CLIP ViT-L/14 performance and IWILDCAM. We use 'df' and 'cd' to denote the type of text prompts used to produce model predictions. 'dual' refers to the mixture model (10) for inference. “–” means the corresponding loss term is not in use.
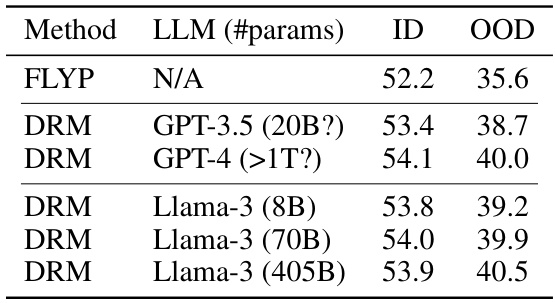
🔼 This table shows the ID and OOD performance of fine-tuned CLIP ViT-L/14 model on the IWILDCAM dataset. The model is fine-tuned using concept descriptions generated by different LLMs with varying sizes (parameters). The results are compared against the FLYP baseline. It demonstrates how the performance of DRM varies with different large language models.
read the caption
Table 4: Performance of fine-tuned CLIP ViT-L/14 on IWILDCAM with concept descriptions generated by different LLMs of various sizes.
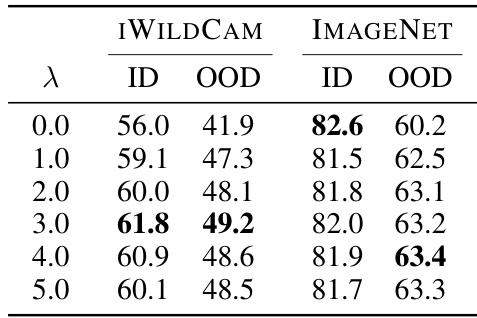
🔼 This table presents the ID and OOD performance of the Dual Risk Minimization (DRM) method under different values of the hyperparameter λ. The results are shown for two datasets, IWILDCAM and IMAGENET, using two different CLIP models (ViT-L/14 and ViT-B/16). The table helps to illustrate how the balance between empirical risk minimization and worst-case risk minimization (controlled by λ) affects both in-distribution and out-of-distribution performance.
read the caption
Table 5: Performance of DRM under different λ on IWILDCAM and IMAGENET with CLIP ViT-L/14 and CLIP ViT-B/16 respectively.

🔼 This table presents a quantitative analysis comparing the reliability of concept descriptions and default prompts in capturing core visual features. It demonstrates that concept descriptions are more sensitive to changes in foreground (core features) and less affected by changes in background (non-core features) compared to default prompts.
read the caption
Table 6: Quantitative study on the reliability of concept descriptions verse default prompts. The affinities to concept descriptions are sensitive to changes in the core features of image foregrounds (FG) and remain relatively stable against changes in the non-core features of backgrounds (BG).
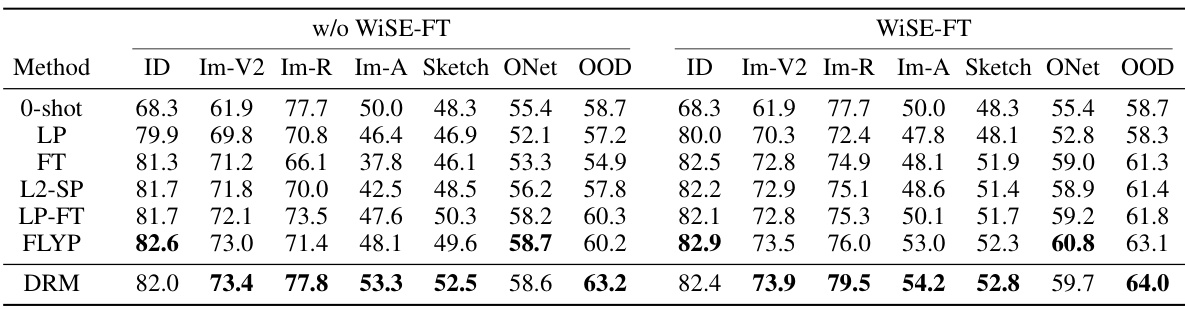
🔼 This table presents the detailed performance of different methods on various ImageNet Out-of-Distribution (OOD) datasets using the CLIP ViT-B/16 model. It shows ID (in-distribution) accuracy along with OOD accuracy for each of the five OOD datasets. The results show the performance with and without WiSE-FT (Weight-space averaging fine-tuning) applied. The table allows for a direct comparison of the methods’ performance on both in-distribution and out-of-distribution data.
read the caption
Table 7: Performance on ImageNet OOD variants with CLIP ViT-B/16. “OOD” stands for the average performance over the OOD datasets.
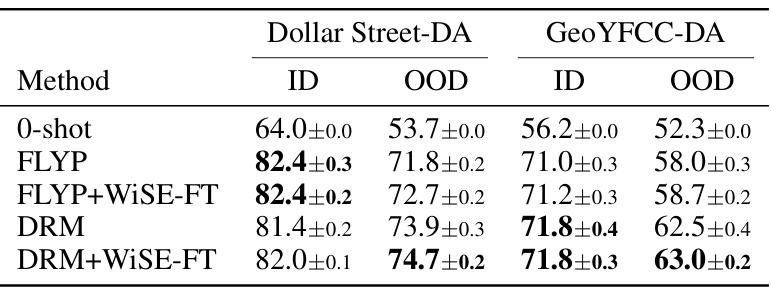
🔼 This table presents the in-distribution (ID) and out-of-distribution (OOD) performance results of different fine-tuning methods on two datasets: Dollar Street-DA and GeoYFCC-DA. The ID performance is measured using images from specific geographic locations (North America and Europe), while the OOD performance is evaluated using images from other continents. The methods compared include a zero-shot baseline, FLYP (a fine-tuning method), FLYP combined with WiSE-FT (a weight-averaging technique), DRM (the proposed method), and DRM combined with WiSE-FT.
read the caption
Table 8: ID and OOD performance on Dollar Street-DA and GeoYFCC-DA with CLIP ViT-B/16.

🔼 This table presents the in-distribution (ID) and out-of-distribution (OOD) performance of different methods on the CLIP ViT-B/16 model. The methods include several baselines and the proposed DRM (Dual Risk Minimization) method. The performance is evaluated across multiple datasets, including ImageNet and its OOD variants (ImageNet-V2, ImageNet-R, ImageNet-A, ImageNet-Sketch, ObjectNet) as well as iWildCam and fMoW from the WILDS benchmark. The table also shows the impact of using WiSE-FT (Weight-space averaging) with each method. Best performances are highlighted in bold. Note that for ImageNet, the OOD performance is an average over 5 test sets, and individual results for each are given in Appendix E.1.
read the caption
Table 1: ID and OOD performances of DRM and baselines methods on CLIP ViT-B/16, with and without WiSE-FT. Best performances are highlighted in bold. For IMAGENET, we report the average performance over its 5 OOD test sets. Results on individual test sets are provided in Appendix E.1.

🔼 This ablation study investigates the impact of various design choices in the Dual Risk Minimization (DRM) framework on the robustness of CLIP ViT-L/14 fine-tuned on the iWildCam dataset. The table explores different combinations of Empirical Risk Minimization (ERM) and Worst-case Risk Minimization (WRM) with various prompt types and classifier combinations. It assesses the performance of using a single risk for training, as well as different methods for combining the two classifiers after training, including ensemble and weighted average methods. Results are reported in terms of ID and OOD performance.
read the caption
Table 10: Ablation study on DRM with CLIP ViT-L/14 (w/o WiSE-FT) on iWildCam.

🔼 This table presents the results of applying DRM under various settings by comparing the ID and OOD performance when using FLYP, LP-FT, and DRM. Row 1 shows the baseline performance with FLYP. Row 2 demonstrates DRM without FLYP or LP-FT. Row 3 shows the performance with both LP-FT and DRM. Lastly, Row 4 shows the result when combining FLYP and DRM. The combination of FLYP and DRM yielded the best results among the different settings.
read the caption
Table 11: Results of applying DRM under different settings.
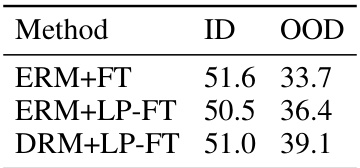
🔼 This table presents the In-distribution (ID) and Out-of-distribution (OOD) performance results of applying Dual Risk Minimization (DRM) on ImageNet pre-trained ResNet50 model, fine-tuned on the iWildCam dataset. The results are compared to the standard Empirical Risk Minimization (ERM) with full fine-tuning (ERM+FT) and linear probing followed by fine-tuning (ERM+LP-FT). It shows the effectiveness of DRM in improving the OOD performance of a pre-trained CNN model.
read the caption
Table 12: Results of applying DRM on fine-tuning ImageNet pre-trained ResNet50 on iWildCam.
🔼 This table presents a comparison of the In-distribution (ID) and Out-of-distribution (OOD) performance of the Dual Risk Minimization (DRM) method against several baseline methods. The comparison is made using the CLIP ViT-B/16 model on three datasets: ImageNet, iWildCam, and FMoW. The results are shown with and without the WiSE-FT method. ImageNet’s OOD performance is averaged across five different OOD test sets. The best-performing method for each metric is bolded.
read the caption
Table 1: ID and OOD performances of DRM and baselines methods on CLIP ViT-B/16, with and without WiSE-FT. Best performances are highlighted in bold. For IMAGENET, we report the average performance over its 5 OOD test sets. Results on individual test sets are provided in Appendix E.1.
Full paper#