↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional image captioning models struggle with precise and detailed descriptions of specific image regions. Existing dense captioning methods have limited expressiveness due to dataset constraints. This limits applications requiring detailed region information, such as visual question answering (VQA).
FlexCap addresses these limitations by generating length-conditioned captions for image regions. Trained on a massive dataset of image region descriptions, FlexCap provides controllable detail levels. The model’s localized descriptions are used as input for a large language model (LLM) enabling zero-shot VQA performance surpassing existing methods. FlexCap demonstrates utility across various tasks including object attribute recognition and visual dialog.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in vision-language and multi-modal learning. FlexCap’s controllable detail generation and strong zero-shot VQA performance offer significant advancements. Its large-scale dataset and novel approach open exciting avenues for future research in open-vocabulary object detection and visual question answering, pushing the boundaries of flexible image captioning.
Visual Insights#

The figure shows the capabilities of FlexCap in generating region-specific descriptions with varying lengths, demonstrating control over detail. The left side illustrates this controllable captioning, ranging from simple object labels to detailed descriptions. The right side showcases how FlexCap’s localized descriptions, combined with large language models (LLMs), achieve state-of-the-art zero-shot visual question answering.

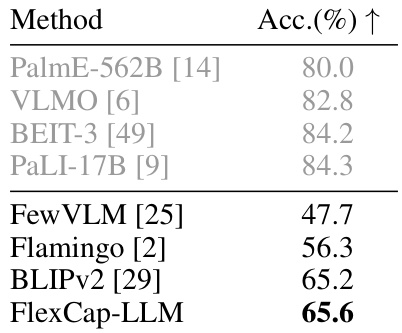
This table presents the results of evaluating FlexCap’s performance on the MS-COCO region classification task and its compliance with generating captions of different lengths. The MS-COCO results demonstrate the model’s accuracy in generating captions for various regions. The compliance metrics show how well the generated captions match the target length.
In-depth insights#
FlexCap: Controllable Captions#
FlexCap’s controllable captioning is a significant advancement in image understanding. It moves beyond simple image captioning by offering region-specific descriptions with adjustable detail levels. This is achieved through length conditioning, allowing users to specify the desired caption length, ranging from concise labels to extensive narratives. The ability to control caption length is crucial for various downstream tasks, enabling fine-grained control over the information extracted from an image. This capability is particularly powerful when combined with large language models (LLMs), enhancing applications like visual question answering (VQA) and visual dialog. Furthermore, FlexCap leverages large-scale datasets of image regions and their descriptions, fostering more robust and semantically rich outputs. The flexibility and control offered by FlexCap represent a substantial improvement in image-to-text generation technology, impacting diverse applications requiring precise and nuanced visual information retrieval.
Localized Captions Dataset#
The creation of a ‘Localized Captions Dataset’ is a crucial contribution, significantly impacting the performance and capabilities of the FlexCap model. The process leverages existing large-scale image-text datasets like WebLI and YFCC100M, cleverly extracting triplets of (image, bounding box, caption) with varying caption lengths. This approach is highly scalable, generating billions of training examples without requiring manual annotation. Careful filtering techniques ensure high-quality data by removing grammatically incorrect or uninformative captions, resulting in a diverse dataset better representing natural language descriptions. The methodology for creating this dataset is novel and addresses the limitations of existing dense captioning datasets that restrict expressiveness. The resulting dataset’s richness and scale directly contribute to FlexCap’s ability to generate detailed and spatially precise descriptions across multiple image regions, exceeding the capabilities of previous models.
FlexCap Architecture#
The FlexCap architecture, designed for controllable image captioning, likely integrates an image encoder and a text decoder. The image encoder, possibly a convolutional neural network (CNN) or Vision Transformer (ViT), processes input images to extract visual features. These features might be region-specific, allowing for localized descriptions. A linear projection likely transforms bounding box coordinates into a compatible feature representation for integration with the visual features. The text decoder, likely a transformer network, generates captions conditioned on both the visual features and a length-control token. This allows FlexCap to produce captions of varying lengths, from concise object labels to detailed descriptions. The architecture’s modularity likely enables the integration of other components, such as object detection or pre-trained language models, for enhanced performance and functionality. The training process would involve optimizing parameters to accurately predict captions given image regions and length constraints. The success of FlexCap hinges on its ability to effectively capture and combine visual and textual information, leading to high-quality, length-controlled image captions.
VQA & Open-Ended Obj. Det.#
The intertwined nature of Visual Question Answering (VQA) and open-ended object detection presents a compelling research area. VQA systems benefit significantly from robust object detection, as identifying and localizing objects within an image is crucial for understanding the context of a question. Conversely, open-ended object detection can leverage the insights gained from VQA. By analyzing the questions posed about an image, the system can learn to focus on the most relevant and informative objects, even those that may not be easily identifiable by typical object detection methods. This synergistic relationship can lead to more comprehensive scene understanding. The challenge lies in developing a unified framework that seamlessly integrates these two tasks, handling the complexities of diverse object types, varied question phrasing, and the inherent ambiguities in visual data. Success hinges on creating models capable of contextual reasoning, efficiently connecting visual features with textual information, and accurately resolving queries across varying levels of complexity.
Future Work & Limitations#
The research paper’s potential future work could involve exploring different length conditioning methods beyond simple word counts to allow for more nuanced control over caption detail. Investigating the impact of alternative visual encoders and exploring cross-modal architectures that more tightly integrate the vision and language components would also be valuable. Addressing limitations such as bias in the training data, which might stem from the use of web-scale data or reliance on alt-text, is crucial. Evaluating performance on datasets with a wider range of visual styles and complexity would strengthen the claims and broaden applicability. Finally, the research could explore the integration of the proposed model into more sophisticated downstream applications, such as more complex visual question answering tasks, or integrating it within a conversational AI system for more engaging visual dialog.
More visual insights#
More on figures

This figure demonstrates FlexCap’s capabilities. The left side showcases its ability to generate region-specific descriptions of varying lengths, from simple object labels to detailed narratives, by controlling caption length. The right side illustrates how FlexCap’s localized descriptions, combined with Large Language Models (LLMs), enable zero-shot Visual Question Answering (VQA), enabling the system to answer questions about specific image regions without explicit training.
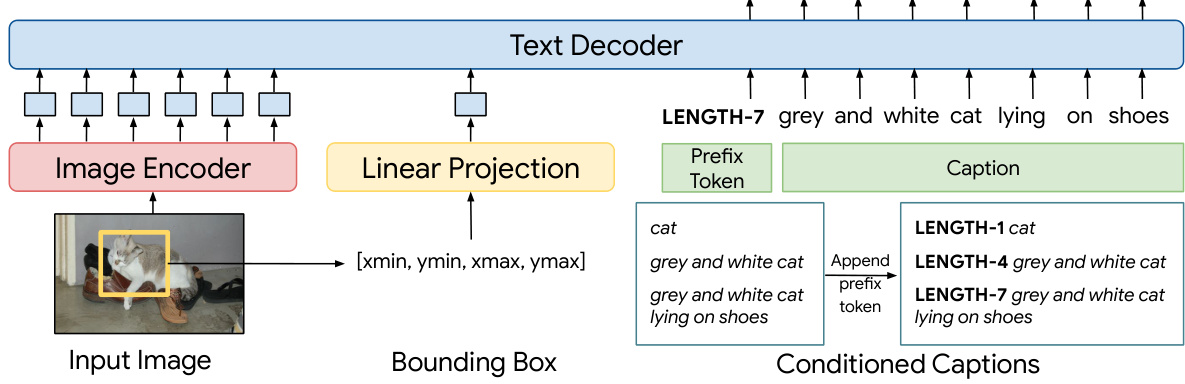
This figure illustrates the architecture and training process of the FlexCap model. The model takes an image, bounding box coordinates, and a length prefix as input. The image encoder processes the image, and a linear projection handles the bounding box coordinates. These are concatenated and fed to a transformer-based text decoder, which generates a caption with the specified length. The training utilizes standard next-word prediction loss to optimize the model’s caption generation.
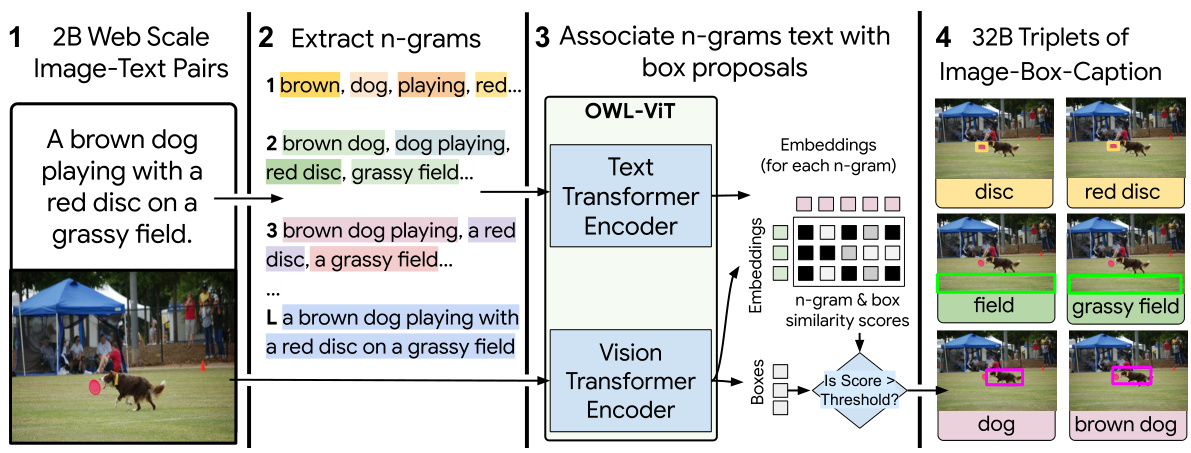
This figure illustrates the process of generating a large-scale dataset for training the FlexCap model. It starts with 2 billion image-text pairs from the WebLI dataset. These captions are then broken down into n-grams (sequences of words) of varying lengths. OWL-ViT, an object detection model, is used to identify regions (bounding boxes) within the images that correspond to these n-grams. The result is a massive dataset of 32 billion triplets, each containing an image, a bounding box, and a caption of a specific length. This diverse dataset allows the model to learn to generate captions of varying detail and length for specific image regions.
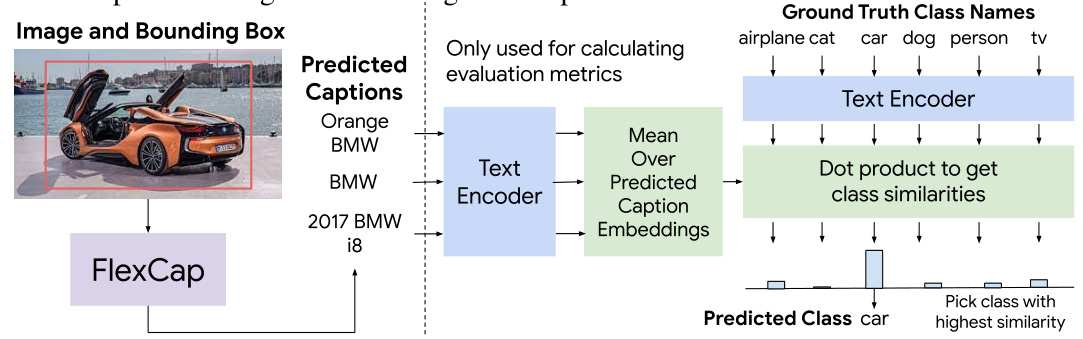
This figure illustrates the process of evaluating open-vocabulary outputs generated by FlexCap using the CLIP text encoder. FlexCap processes the input image and bounding box to generate multiple captions of varying lengths. These captions are then encoded by CLIP’s text encoder, producing text embeddings. By comparing the mean of the predicted caption embeddings with the embeddings of ground-truth class names, the model obtains classification scores. This process allows for evaluating the model’s ability to generate open-vocabulary outputs and provides quantitative metrics to assess its performance.

The figure demonstrates FlexCap’s ability to generate detailed captions for specific image regions. The left side shows how FlexCap generates captions of varying lengths for the same region, showcasing its control over detail. The right side illustrates how FlexCap’s localized captions, combined with LLMs, enable zero-shot visual question answering.
The figure demonstrates FlexCap’s ability to generate localized image descriptions with varying lengths, controlled by input parameters. The left panel shows how different lengths of captions can be generated for the same image region. The right panel illustrates how FlexCap’s detailed regional descriptions, when combined with a Large Language Model (LLM), enable zero-shot Visual Question Answering (VQA).
This figure demonstrates the capabilities of FlexCap, a vision-language model, in generating region-specific image descriptions with controllable detail. The left side shows how FlexCap produces captions ranging from concise object labels to rich, detailed descriptions for the same image region, simply by adjusting the specified caption length. The right side illustrates how FlexCap’s detailed localized descriptions, when used as input to a large language model (LLM), enable the system to achieve zero-shot visual question answering.

The figure demonstrates FlexCap’s capability to generate region-specific image descriptions of varying length, from concise object labels to detailed captions. The left side shows this controllable detail generation. The right side demonstrates how these rich, localized descriptions, combined with LLMs, enable zero-shot visual question answering, showcasing a key application of the model.
This figure demonstrates the capabilities of FlexCap, a vision-language model, in generating region-specific descriptions with controllable detail. The left side shows how FlexCap can generate captions of varying length for the same image region, ranging from simple object labels to detailed descriptions. The right side illustrates how these localized, detailed descriptions can be used as input for a Large Language Model (LLM) to enable zero-shot Visual Question Answering (VQA). This highlights FlexCap’s ability to bridge the gap between localized image understanding and comprehensive language modeling.
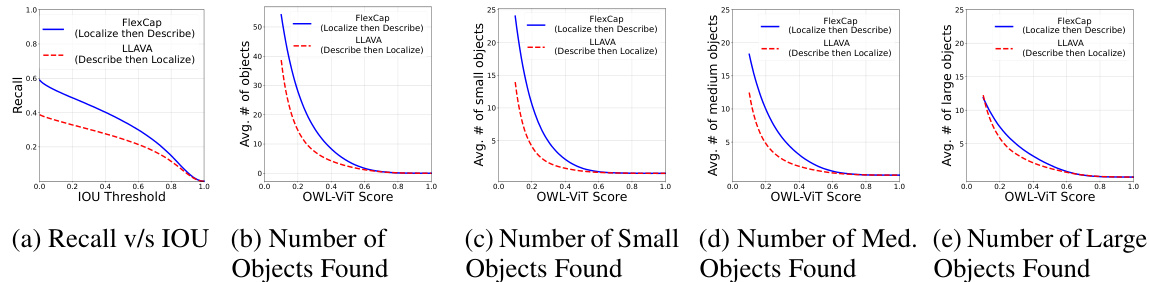
This figure compares the performance of two different approaches for open-ended object detection on the Visual Genome dataset. The first approach, ’localize-then-describe,’ uses FlexCap to describe each detected bounding box individually. The second approach, ‘describe-then-localize,’ first uses a state-of-the-art vision-language model (LLAVA) to generate a comprehensive description of the entire image, and then uses an open-vocabulary object detection method to localize the objects described. The figure shows that the ’localize-then-describe’ approach (using FlexCap) achieves higher recall and identifies more objects, especially small and medium-sized objects, than the ‘describe-then-localize’ approach.
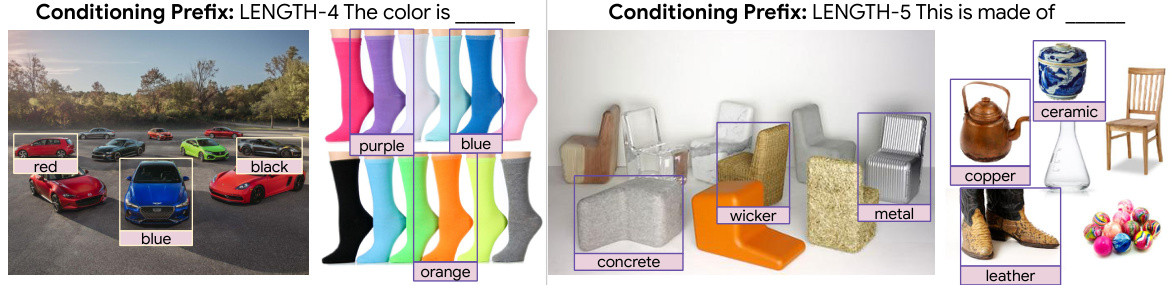
This figure demonstrates the ability of FlexCap, when provided with specific prefixes, to extract particular attributes of objects. Two examples are shown: one where the prefix ‘LENGTH-4 The color is ____’ is used, resulting in color identification (red, blue, purple, black, orange) for various items in the image; and another using the prefix ‘LENGTH-5 This is made of ____’, which successfully identifies materials (concrete, wicker, metal, leather, ceramic, copper) of the objects shown. The key takeaway is that by controlling caption length with prefixes, it is possible to guide the model toward providing specific information, in this case, attributes.

This figure shows examples of how FlexCap can be used to extract specific properties of objects by conditioning the model with prefixes. Different prefixes, such as ‘The color is’ and ‘This is made of’, are used to guide the model to output a single-word answer describing the color or material of an object within a given bounding box. The figure demonstrates this capability across multiple object categories, showcasing the model’s versatility and ability to extract targeted information through controlled prompting.
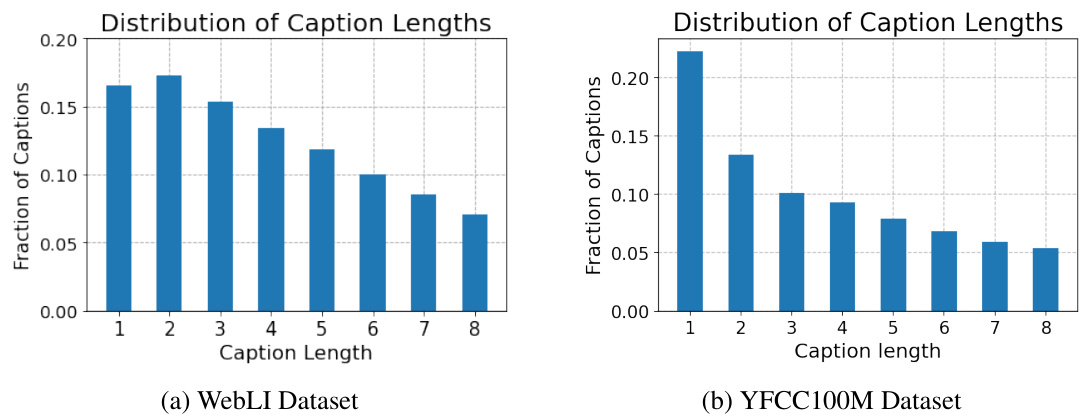
This figure shows the distribution of caption lengths for the localized captions dataset created using two different datasets: WebLI and YFCC100M. Two bar charts are presented, one for each dataset. The x-axis represents the caption length (number of words), and the y-axis represents the fraction of captions with that length. The charts illustrate the frequency distribution of caption lengths in each dataset, which helps to understand the diversity and balance in the data used for training the model.

This figure illustrates the process of generating a large-scale dataset for training the FlexCap model. It starts with web-scale image-text pairs. N-grams (sequences of words) are extracted from the captions and used as text queries for an object detection model (OWL-ViT). This model identifies bounding boxes in the images that correspond to the n-grams. The resulting triplets of (image, bounding box, caption) form the dataset, which contains captions of varying lengths, capturing different levels of detail for each image region. This process leverages existing web data and automates the creation of a large-scale, region-specific caption dataset.

This figure shows some examples where the object detection model LLAVA fails to detect certain objects while FlexCap, combined with OWL-ViT, successfully detects them. The images demonstrate that FlexCap, by using a localize-then-describe approach, is better at detecting small and medium-sized objects. Each image contains labels from FlexCap’s detections, including object class and confidence score.

This figure demonstrates FlexCap’s ability to generate localized image captions with controllable detail, ranging from concise object labels to rich descriptions. The left side shows examples of captions generated for different regions of an image, highlighting the length control aspect. The right side illustrates how these detailed localized captions, in conjunction with a large language model (LLM), facilitate zero-shot visual question answering. This showcases FlexCap’s application in various tasks beyond simple image captioning.
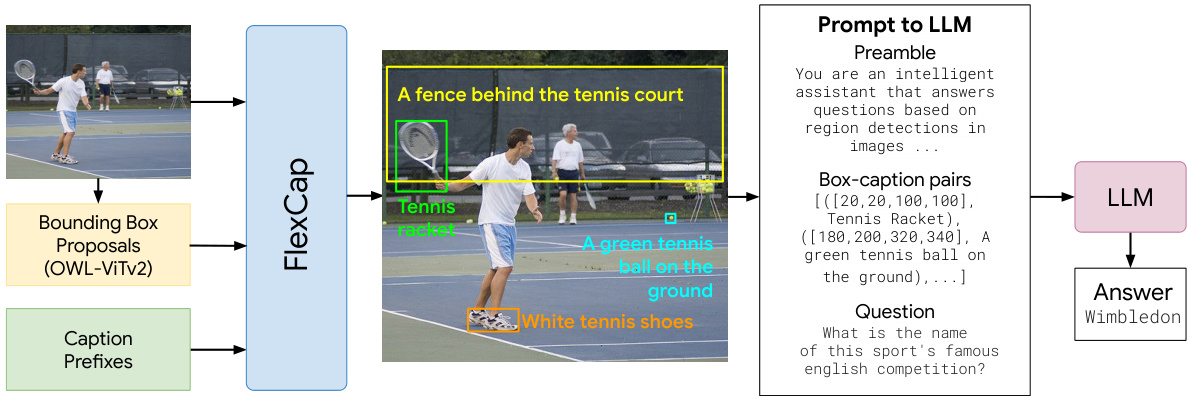
This figure illustrates the architecture of FlexCap used for Visual Question Answering (VQA). FlexCap first uses OWL-ViTv2 to generate bounding box proposals for the input image. Then, it generates captions for each region using length-conditioned captioning. These box-caption pairs are then fed into a large language model (LLM), along with a preamble specifying the task as answering questions based on image regions. Finally, the LLM processes the information and provides an answer to the given question.
More on tables
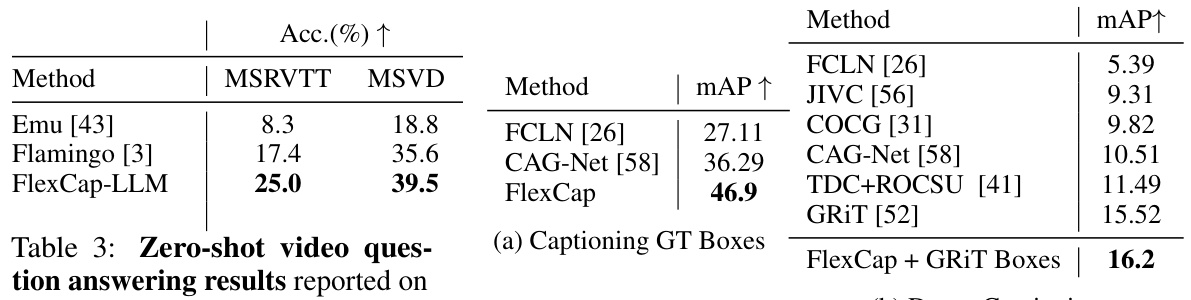
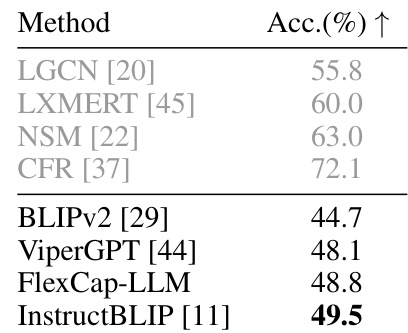
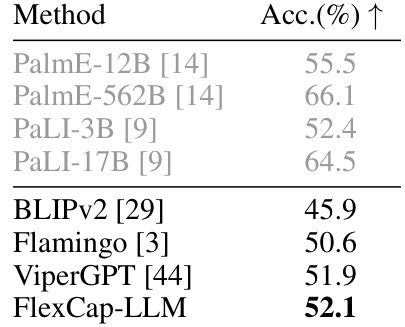
This table presents the results of zero-shot video question answering experiments on two benchmark datasets: MSRVTT-QA and MSVD-QA. The performance metric used is mean Average Precision (mAP) for both datasets. The table compares the performance of FlexCap-LLM to other state-of-the-art zero-shot methods. The results demonstrate that FlexCap-LLM outperforms other zero-shot baselines on both datasets.

This ablation study investigates the impact of different factors on the region captioning task using the Visual Genome dataset. It explores three key aspects: 1. Contrastive Pre-training: Compares the performance when using a contrastively pre-trained vision encoder versus training from scratch. 2. Data Scaling: Assesses the effect of varying dataset sizes (0.2B and 32B triplets) on performance. 3. Model Scaling: Evaluates the impact of using different sized models (ViT-B/16 and SO-ViT/14). For all of the above, the Visual Genome dataset is used for performance evaluation, measuring mean average precision (mAP).
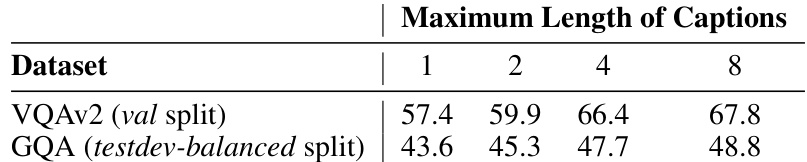
This table shows the impact of using captions with different maximum lengths on the performance of the FlexCap-LLM model on two visual question answering datasets: VQAv2 and GQA. The results demonstrate that increasing the maximum caption length generally improves the accuracy of the model on both datasets.

This table presents the results of evaluating FlexCap’s performance on the MS-COCO Region Classification task. The table shows that FlexCap, using top-1 or top-20 caption choices, achieves high mean Average Precision (mAP) values across different caption lengths, indicating both accuracy and compliance with the desired caption length. The results are compared against existing baselines, showcasing FlexCap’s superiority.

This table presents the results of evaluating FlexCap’s ability to generate accurate and length-compliant captions. It shows that FlexCap achieves high mean Average Precision (mAP) scores for region classification on the MS-COCO dataset across different caption lengths, indicating the model’s accuracy in describing image regions. Additionally, it demonstrates the model’s ability to produce captions of the desired length, highlighting its controllability and compliance.

This table presents the results of evaluating FlexCap’s ability to generate captions of varying lengths. It shows that FlexCap achieves high accuracy (Mean Accuracy and Target Accuracy) across different lengths, demonstrating its ability to generate length-compliant captions. The metrics used are Mean Length of Predicted Captions and Accuracy. Two separate versions of the experiment (a) MS-COCO Region Classification, and (b) Compliance metrics are presented.

This table presents the results of evaluating FlexCap’s performance on the MS-COCO region classification task. It demonstrates FlexCap’s accuracy in generating captions of different lengths. The table shows that FlexCap achieves high accuracy (mAP) and that the generated captions closely match the desired lengths.

This table presents the results of evaluating FlexCap’s accuracy and compliance with desired caption lengths in the MS-COCO Region Classification task. It shows that FlexCap achieves high mean Average Precision (mAP) across different target caption lengths, demonstrating its ability to generate accurate and length-compliant captions. The compliance metrics illustrate that the generated captions closely match the specified lengths.

This table presents the results of the experiment evaluating the accuracy and length compliance of FlexCap’s generated captions. The experiment used the MS-COCO Region Classification task, measuring mean Average Precision (mAP) for different caption lengths (1-8 words). The results show FlexCap achieving high accuracy in producing captions with the specified number of words.
Full paper#



















