↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Personalizing large text-to-image models on resource-constrained devices is challenging due to high memory demands during model fine-tuning. Existing methods focus on reducing training steps or parameters, but these often require additional pre-trained models or still strain memory. This leads to limitations in on-device applications, where both memory and computational resources are severely limited.
The proposed method, Hollowed Net, tackles this memory bottleneck directly. It modifies the architecture of the diffusion U-Net by temporarily removing some deep layers during training. This hollowed structure significantly reduces GPU memory requirements, enabling efficient fine-tuning on-device. The method does not require additional models or extensive pre-training. Hollowed Net achieves performance comparable to or better than existing methods while using substantially less GPU memory (as low as inference memory). The personalized LoRA parameters can be seamlessly transferred back to the original U-Net for inference without increased memory usage.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical memory bottleneck in on-device personalization of large language models. It introduces a novel technique, Hollowed Net, that significantly reduces GPU memory requirements during fine-tuning while maintaining or even improving personalization performance. This opens avenues for efficient on-device AI applications where resources are highly constrained, and potentially addresses privacy concerns by minimizing reliance on cloud computing.
Visual Insights#

This figure illustrates the LoRA personalization process using Hollowed Net, designed for resource-constrained environments. It is divided into two stages: pre-computing and fine-tuning. In the pre-computing stage, a forward pass is performed through the original diffusion U-Net with an input image and text prompt. The intermediate activations (θ1-θ7) are saved for later use. The fine-tuning stage uses a modified version of the U-Net called the ‘Hollowed Net’, where the middle layers are temporarily removed. This significantly reduces the memory footprint during training. The pre-computed activations are loaded into the Hollowed Net, and LoRA parameters are fine-tuned. After fine-tuning, these LoRA parameters are seamlessly transferred back to the original U-Net for inference without any additional memory overhead.
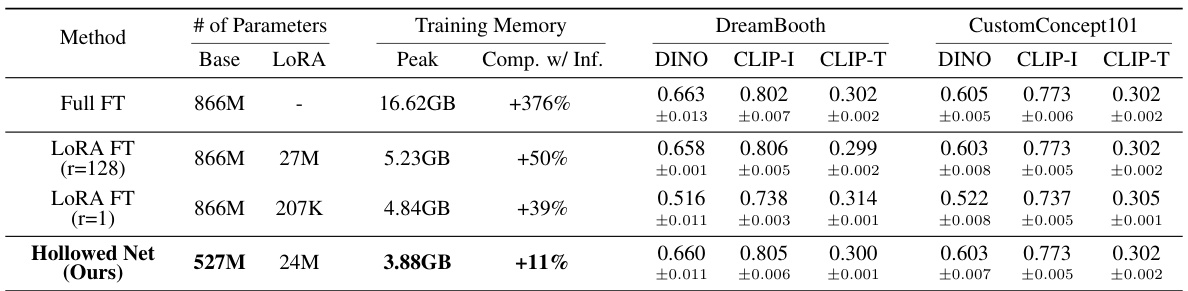
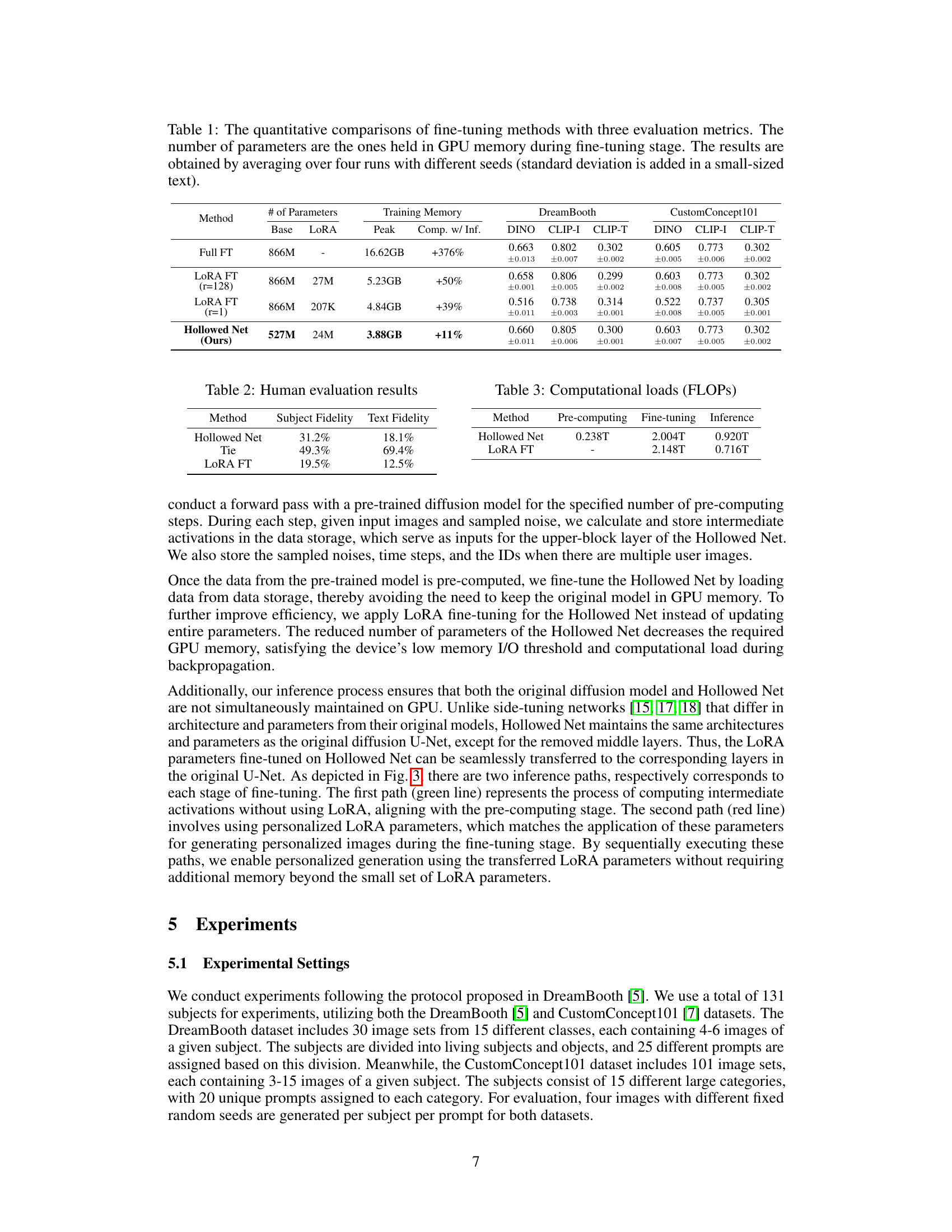
This table presents a quantitative comparison of different fine-tuning methods for text-to-image diffusion models, focusing on three evaluation metrics: DINO, CLIP-I, and CLIP-T. It shows the number of parameters used (both base model and LoRA parameters), the peak GPU memory usage during training, and the performance improvement compared to inference-only memory usage. Results are averaged over four runs with different random seeds to demonstrate robustness. The methods compared are Full Fine-Tuning (Full FT), LoRA Fine-Tuning with ranks of 128 and 1, and the proposed Hollowed Net method.
In-depth insights#
On-Device T2I#
On-device text-to-image (T2I) synthesis presents a compelling vision: personalization and privacy without cloud dependency. However, resource constraints of mobile devices pose significant challenges. Memory limitations are especially critical during the computationally intensive fine-tuning of large diffusion models. Innovative approaches are needed to overcome this, perhaps through techniques such as model compression, efficient training algorithms (like Low-Rank Adaptation), or architectural modifications that minimize memory footprint. A balance between model size, training speed, and personalization quality needs to be carefully struck for successful on-device T2I. Research should explore the use of quantization, pruning, and knowledge distillation to further optimize the tradeoff between performance and resource consumption. The potential benefits, however, are substantial: enhanced user control, faster inference speeds, and robust privacy make on-device T2I an active and important area of research.
Hollowed Net#
The concept of “Hollowed Net” presents a novel approach to on-device personalization of large language models by strategically removing or “hollowing out” specific layers of the pre-trained model during the fine-tuning process. This method directly addresses the memory constraints of on-device learning, a critical bottleneck in previous approaches. By temporarily removing less crucial layers, particularly in the central, deeper sections of the U-Net architecture, Hollowed Net significantly reduces the GPU memory required for training. This contrasts with existing techniques that primarily focus on reducing the number of parameters or training steps. Importantly, the personalized LoRA parameters from the Hollowed Net can be seamlessly transferred back to the original, full U-Net for inference without any additional memory overhead. This innovative strategy not only enhances memory efficiency but also maintains or even improves personalization performance, offering a highly efficient solution for on-device subject-driven image generation.
LoRA Personalization#
LoRA (Low-Rank Adaptation) personalization offers an efficient approach to fine-tuning large text-to-image diffusion models. By updating only a small subset of parameters, it significantly reduces computational costs and memory usage, making it suitable for on-device applications. The core idea is to inject low-rank updates into pre-trained weights, achieving personalization with minimal modification. This technique is particularly effective when combined with other memory optimization strategies, as it avoids the need for backpropagation through the entire model. However, even with LoRA, memory remains a bottleneck, especially on resource-constrained devices. Therefore, focusing solely on parameter reduction might not be sufficient for truly efficient on-device personalization. Further research should explore alternative methods or complementary techniques to address the memory constraints associated with fine-tuning, even with parameter-efficient methods such as LoRA. The effectiveness of LoRA personalization also depends on the quality of the pre-trained model and the size of the personalization dataset. Future research should explore ways to optimize the selection and pre-processing of personalization data to further improve both efficiency and the resulting image quality.
Memory Efficiency#
The research paper emphasizes memory efficiency as a critical factor for on-device personalization of text-to-image diffusion models. Existing methods, while improving personalization speed, often rely on large pre-trained models, increasing memory demands. The proposed Hollowed Net addresses this by strategically modifying the U-Net architecture, temporarily removing layers during fine-tuning to reduce memory consumption without sacrificing performance. This approach is particularly crucial for resource-constrained devices, where memory is a major bottleneck. The paper demonstrates that Hollowed Net significantly lowers memory requirements during training, achieving memory usage comparable to inference. The technique’s effectiveness is demonstrated through quantitative and qualitative analyses, showing comparable or even superior performance to existing methods while significantly reducing memory needs. Further, the personalized LoRA parameters can be seamlessly transferred back to the original U-Net for inference, eliminating additional memory overhead. This approach offers a practical and efficient solution for personalizing diffusion models on resource-limited devices.
Future of T2I#
The future of text-to-image (T2I) models is incredibly promising, driven by several key trends. Improved efficiency and personalization are crucial; on-device solutions like Hollowed Net reduce memory demands, enabling personalized image generation without cloud reliance. Enhanced control and fidelity remain a focus; future models will likely offer more granular control over image details, style, and composition, moving beyond simple text prompts. The integration of multimodal inputs (combining text with other data like sketches or audio) will further expand creative possibilities. Addressing ethical concerns such as bias, copyright, and misuse will be critical for responsible development and deployment. Finally, seamless integration with other AI systems is likely, leading to advanced applications in design, entertainment, and beyond. The evolution of T2I is a journey towards more powerful, responsible, and accessible image creation tools.
More visual insights#
More on figures
This figure illustrates the LoRA personalization process using Hollowed Net, designed for resource-constrained environments. It shows a two-stage process: pre-computing and fine-tuning. In the pre-computing stage, intermediate activations from a pre-trained diffusion U-Net are saved. Then, in the fine-tuning stage, a modified U-Net (Hollowed Net), with some layers temporarily removed, is fine-tuned using the pre-computed activations. The LoRA (Low-Rank Adaptation) parameters are learned only for the trainable parts of Hollowed Net. Finally, these learned parameters are transferred back to the original U-Net, enabling inference with minimal additional memory overhead. The example input image is from the DreamBooth dataset.
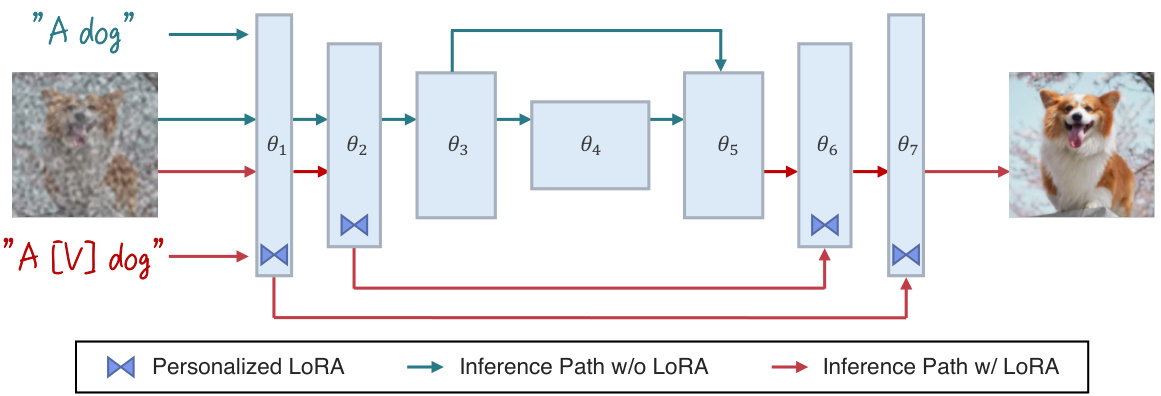
This figure illustrates the LoRA personalization process using Hollowed Net, which is designed for resource-constrained environments. The process is broken down into two stages: pre-computing and fine-tuning. During pre-computing, the original U-Net processes the input image to generate intermediate activations, which are saved to data storage. Then, fine-tuning uses these pre-computed activations to train the Hollowed Net, a modified U-Net with some central layers temporarily removed (the ‘hollowed’ structure). Only the LoRA parameters (small, trainable parameters for efficient fine-tuning) are updated in the Hollowed Net. Finally, the personalized LoRA parameters from the Hollowed Net are transferred back to the original U-Net for inference. This approach drastically reduces the need for large memory during training and maintains the high performance of the original U-Net during inference.
This figure illustrates the LoRA personalization process using Hollowed Net. It shows a two-stage process: pre-computing intermediate activations from the original U-Net, and then fine-tuning LoRA parameters using a ‘hollowed’ version of the U-Net (with some middle layers temporarily removed to save memory). The fine-tuned LoRA parameters are then transferred back to the original U-Net for inference without additional memory overhead. The example image is from the DreamBooth dataset.
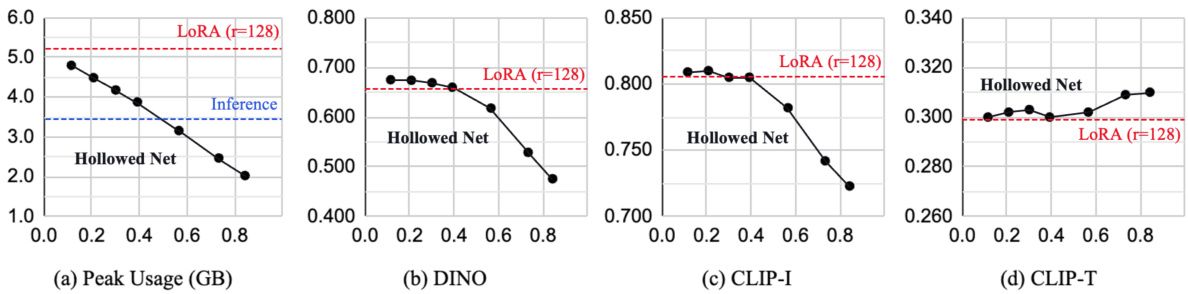
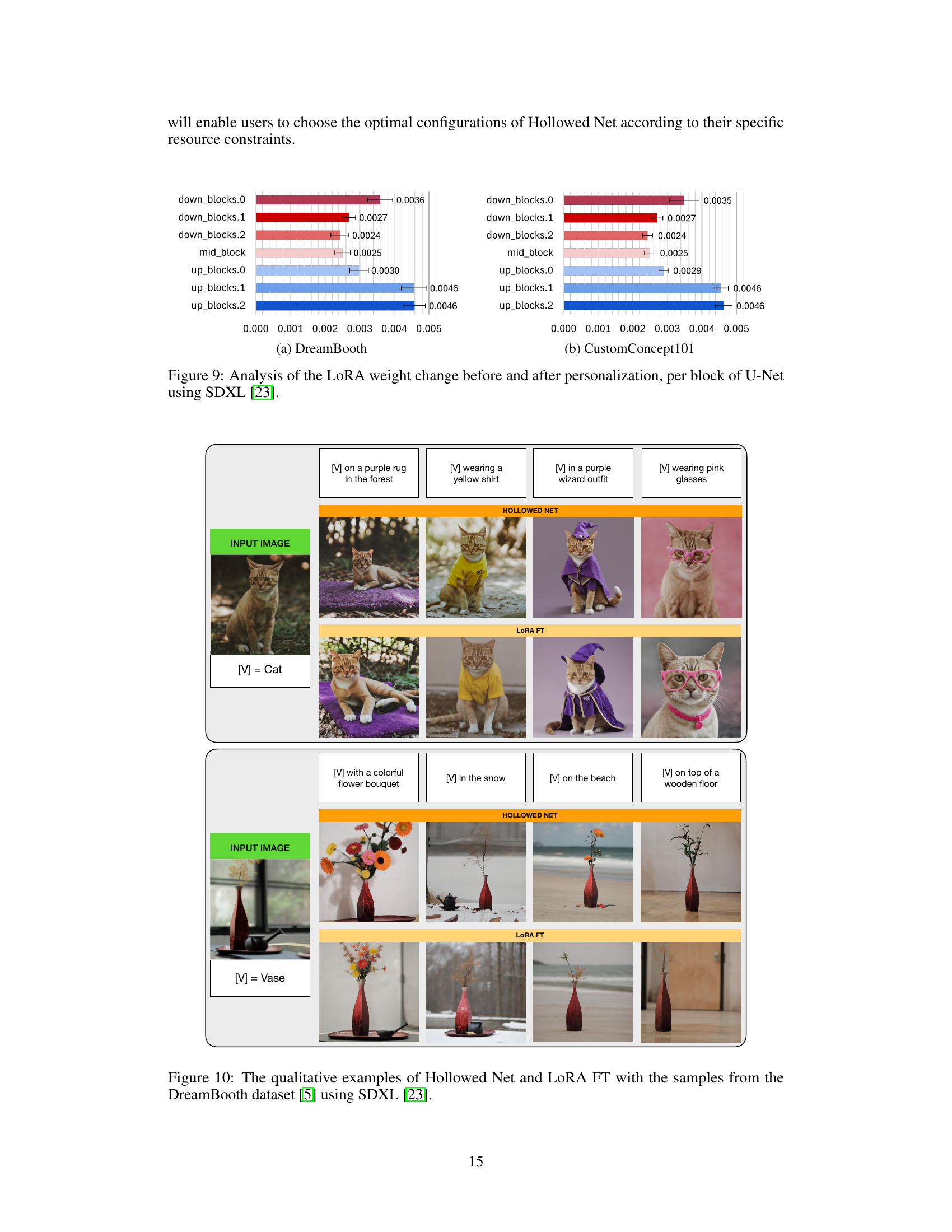
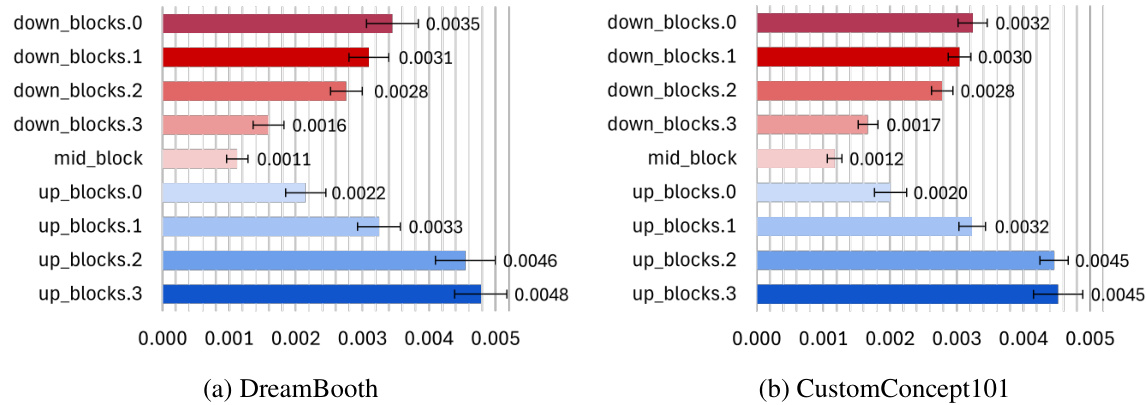
The figure shows the effect of varying the fraction of hollowed layers in Hollowed Net on peak GPU memory usage, DINO score, CLIP-I score, and CLIP-T score. The x-axis represents the percentage of layers removed, while the y-axis shows the performance metric. The results indicate a trade-off between memory efficiency and performance. As the fraction of hollowed layers increases, memory usage decreases, but performance metrics may also decrease, particularly subject fidelity. However, the model maintains relatively good performance even with a significant number of layers removed.

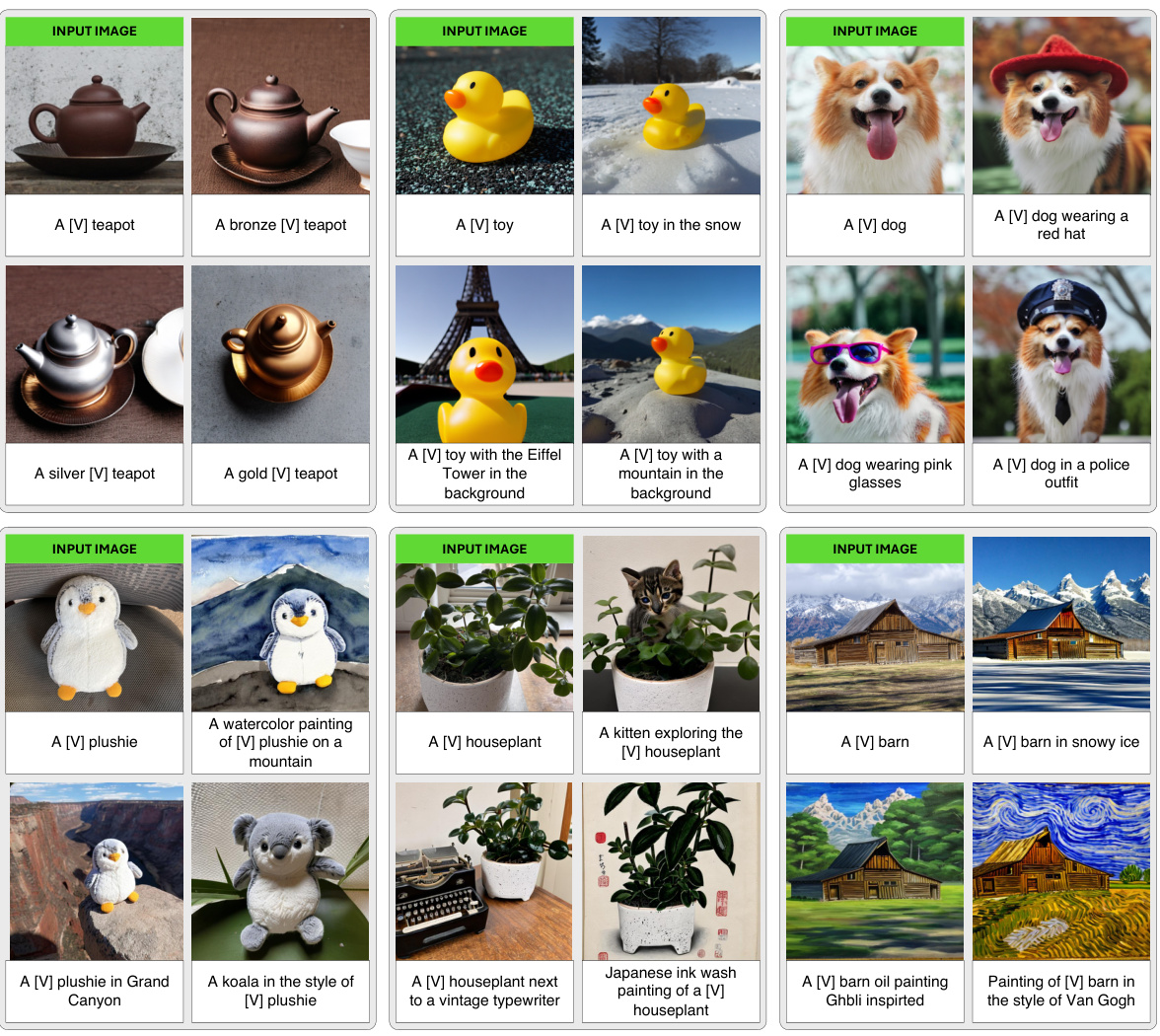
This figure shows the qualitative results of applying Hollowed Net with varying fractions of hollowed layers (from small to large). Three example subjects from the DreamBooth dataset are used. For each subject, the original image and several generated images are shown, each corresponding to a different fraction of hollowed layers. The goal is to demonstrate how the removal of layers (creating the ‘hollow’ in Hollowed Net) impacts the quality of the generated images, showing that too much removal significantly degrades the results but a moderate removal yields good results with reduced memory usage.

This figure illustrates the LoRA personalization method using Hollowed Net for resource-constrained environments. The process is divided into two stages: pre-computing and fine-tuning. In the pre-computing stage, intermediate activations from a pre-trained diffusion U-Net are saved. Then, the fine-tuning stage uses a modified U-Net (Hollowed Net), where some layers are temporarily removed, to train LoRA parameters using the pre-computed activations. Finally, the trained LoRA parameters are transferred back to the original U-Net for inference, significantly reducing memory requirements. An example input image from the DreamBooth dataset is shown to demonstrate the personalization process.

This figure analyzes the impact of varying the fraction of hollowed layers in the Hollowed Net model. It shows the relationship between the percentage of layers removed from the U-Net and four different metrics: peak GPU memory usage (GB), DINO score, CLIP-I score, and CLIP-T score. Each metric assesses a different aspect of model performance after personalization. The results demonstrate the trade-off between memory efficiency and model performance as more layers are removed. The findings help determine an optimal balance, where sufficient layers are maintained for acceptable performance while maximizing memory savings.

This figure illustrates the LoRA personalization process using Hollowed Net, designed for resource-constrained environments. It shows a two-stage process: (1) pre-computing, where intermediate activations from a pre-trained diffusion U-Net are saved; and (2) fine-tuning, where a layer-pruned version of the U-Net (Hollowed Net) is trained using the pre-computed activations to learn LoRA parameters. The LoRA parameters are then transferred to the original U-Net for inference, requiring minimal additional memory. The input image example is from the DreamBooth dataset.

This figure illustrates the LoRA personalization process using Hollowed Net, a method designed for resource-constrained environments. It shows a two-stage process: pre-computing and fine-tuning. In pre-computing, intermediate activations from the original diffusion U-Net are saved for later use in fine-tuning. During fine-tuning, a modified U-Net (Hollowed Net), where some middle layers are temporarily removed, is trained using these pre-computed activations. This reduces memory consumption during training. Finally, the learned LoRA (Low-Rank Adaptation) parameters are transferred back to the original U-Net, allowing inference without additional memory overhead. The input image is an example from the DreamBooth dataset, a popular dataset for subject-driven image generation.
More on tables

This table presents the results of a human evaluation comparing the subject and text fidelity of images generated using Hollowed Net and LoRA FT. The evaluation was conducted using a pairwise comparison task where human participants judged the quality of images generated by each method. The results show that Hollowed Net performs comparably to LoRA FT, achieving a higher subject fidelity but a lower text fidelity. The ‘Tie’ row indicates results when participants couldn’t distinguish between the two methods.

This table presents a quantitative comparison of different fine-tuning methods for text-to-image diffusion models. It compares full fine-tuning (Full FT), LoRA fine-tuning with rank 128 and rank 1 (LORA FT), and the proposed Hollowed Net method. For each method, the table shows the number of parameters, the peak GPU memory usage during training, and the percentage increase in memory usage compared to inference. It also includes three evaluation metrics (DINO, CLIP-I, CLIP-T) and their standard deviation across four runs with different random seeds.

This table presents quantitative results obtained using BK-SDM (a layer-pruned Stable Diffusion model) on the DreamBooth dataset. It compares the performance metrics of two different BK-SDM models: BK-SDM-Base and BK-SDM-Small, showing the number of parameters, training memory usage, and the scores for DINO (subject fidelity), CLIP-I (subject fidelity), and CLIP-T (text fidelity) metrics. The results highlight a tradeoff between model size, memory consumption, and performance.

This table presents a quantitative comparison of the performance of LoRA fine-tuning (LORA FT) and Hollowed Net with different ranks (4 and 16) using the DreamBooth dataset. The table shows the number of parameters, training memory used, and evaluation metrics (DINO, CLIP-I, CLIP-T). The results demonstrate the impact of the rank on performance and memory efficiency of both methods, highlighting Hollowed Net’s ability to achieve comparable performance with significantly less memory.
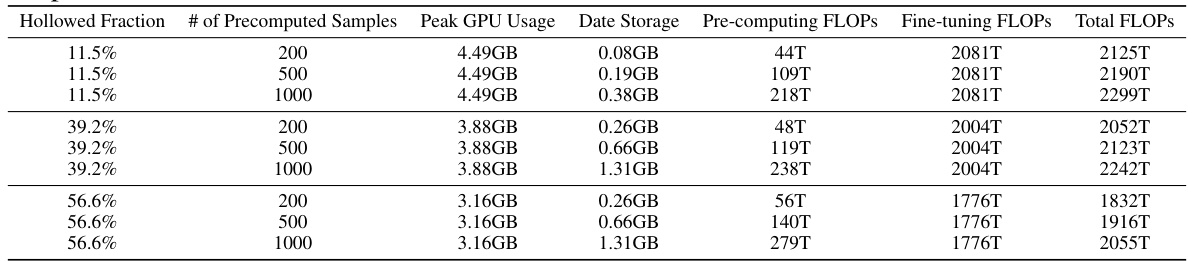
This table presents a quantitative comparison of different fine-tuning methods for text-to-image diffusion models. It shows the number of parameters, GPU memory usage during training, and three evaluation metrics (DINO, CLIP-I, CLIP-T) for each method. The methods compared include full fine-tuning, LoRA fine-tuning with different ranks (r=128 and r=1), and the proposed Hollowed Net method. The results are averaged over four runs with different random seeds, with standard deviations included.
Full paper#