↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often generate inaccurate or fabricated information, a problem known as “hallucinations.” Integrating external knowledge sources like knowledge graphs (KGs) is a common approach to mitigate this, but existing methods face challenges like high computational cost and difficulty in designing effective prompts. This paper introduces KnowGPT, a novel framework that leverages deep reinforcement learning to extract the most relevant information from a KG and a multi-armed bandit approach to construct optimal prompts for the LLM.
KnowGPT addresses the limitations of previous approaches by efficiently retrieving the most pertinent facts from the KG and automatically constructing effective prompts for the LLM. Experimental results show that KnowGPT outperforms current state-of-the-art KG-enhanced LLMs, achieving remarkable accuracy on several benchmark datasets, particularly exceeding human-level performance on one. This demonstrates the effectiveness of KnowGPT’s approach in significantly improving the accuracy and reliability of LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with Large Language Models (LLMs) and knowledge graphs. It directly addresses the issue of hallucinations in LLMs, offering a novel solution to enhance their factual accuracy and reliability. By presenting a practical and efficient framework, KnowGPT opens new avenues for improving LLM performance in various domains, making it highly relevant to current trends in KG-augmented LLM research. The demonstrated state-of-the-art performance on multiple benchmarks further highlights its significance.
Visual Insights#

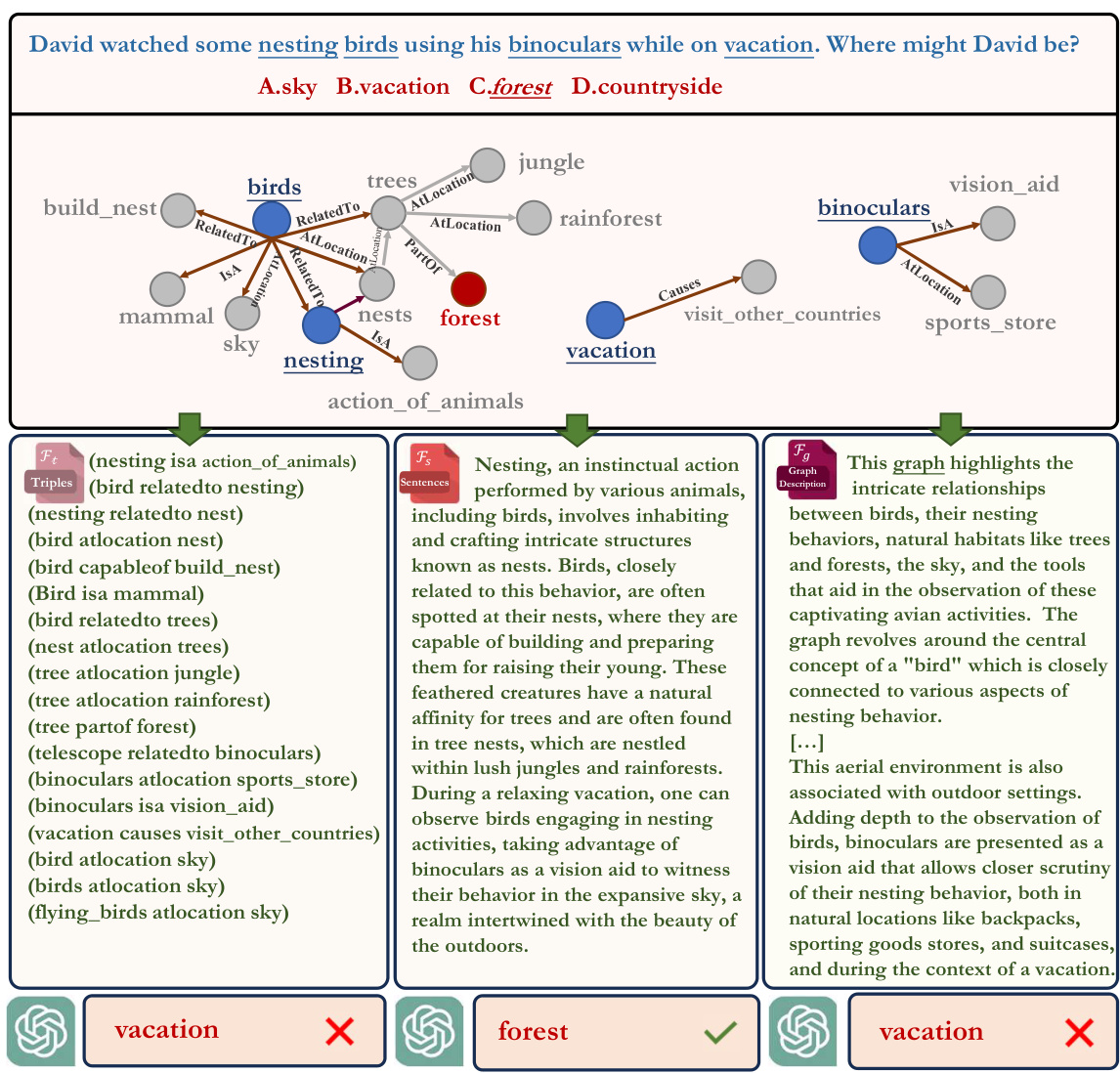
This figure illustrates a question from the OpenBookQA dataset, where an LLM (GPT-3.5) initially provides an incorrect answer. However, by incorporating knowledge from ConceptNet, a knowledge graph, the LLM is able to correct its answer. The figure visually represents the question, the incorrect and correct answers, and the relevant knowledge from ConceptNet used for correction. The color coding helps distinguish between question concepts, correct answers, and external knowledge.
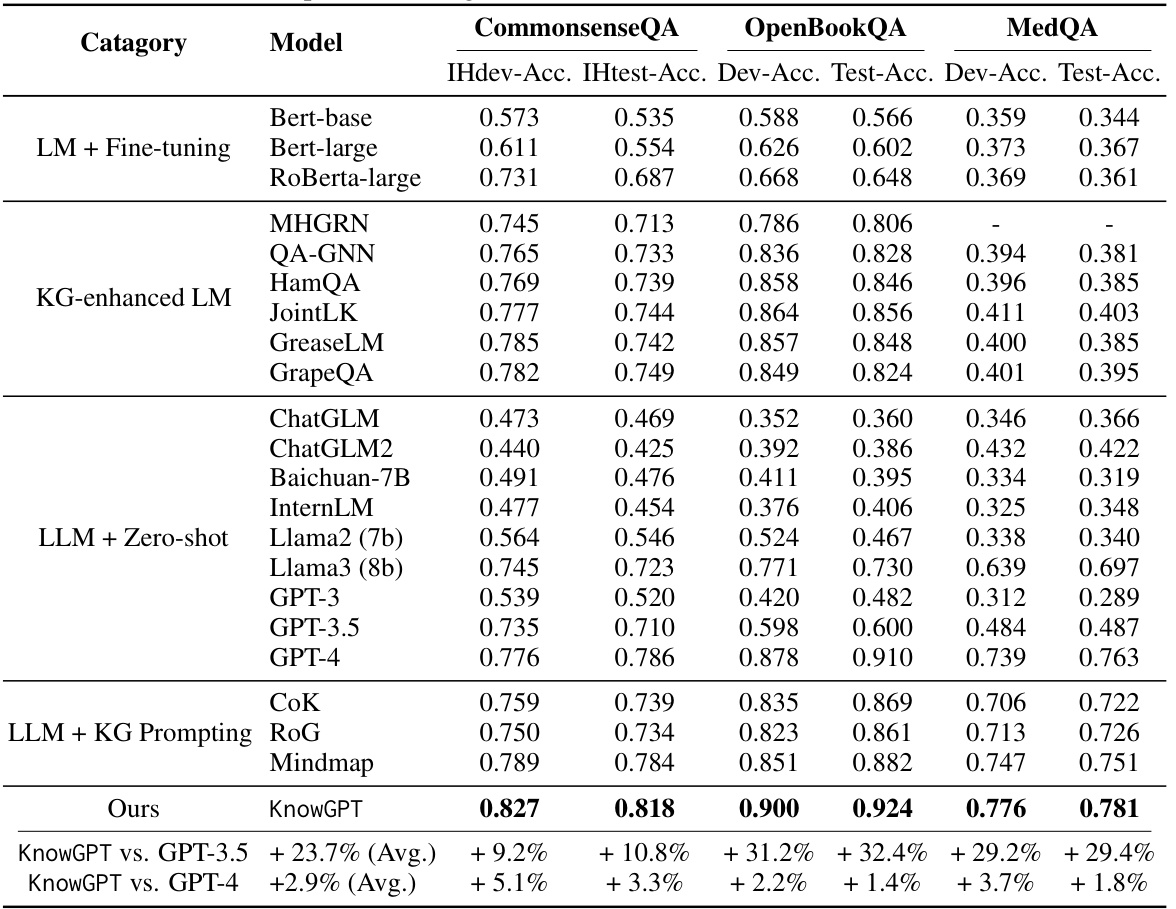
This table presents a comprehensive comparison of KnowGPT’s performance against various baseline models across three benchmark question-answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The baselines represent different approaches, including fine-tuned Language Models (LMs), KG-enhanced LMs, zero-shot LLMs, and other KG prompting methods. The table shows the accuracy achieved by each model on the development and test sets of each dataset, allowing for a thorough evaluation of KnowGPT’s effectiveness compared to state-of-the-art techniques. The bottom rows highlight the percentage improvement of KnowGPT over GPT-3.5 and GPT-4, further emphasizing its superior performance.
In-depth insights#
KnowGPT Framework#
The KnowGPT framework, a novel approach to enhance Large Language Models (LLMs) with domain knowledge, is presented. It tackles the limitations of existing KG prompting methods by addressing three key issues: the extensive search space within real-world knowledge graphs (KGs), the high API costs associated with closed-source LLMs, and the laborious process of prompt engineering. KnowGPT employs a two-stage process. First, a deep reinforcement learning (RL) agent efficiently extracts the most informative and concise knowledge from KGs, maximizing rewards based on reachability, context-relatedness, and conciseness of extracted paths. Second, a multi-armed bandit (MAB) algorithm strategically selects the optimal combination of knowledge extraction methods and prompt templates, ensuring effective knowledge integration. This dual approach ensures both efficient knowledge retrieval and effective prompt generation, resulting in significantly improved LLM performance.
RL Knowledge Extraction#
Reinforcement learning (RL) is leveraged for knowledge extraction in this research, a technique that offers significant advantages over traditional methods. The RL agent dynamically explores the knowledge graph (KG), learning to navigate its structure and select informative paths. This approach contrasts with static, predefined KG traversal strategies, adapting to the nuances of each query. A crucial aspect is the reward mechanism, which guides the agent towards extracting contextually relevant and concise knowledge. This reward function likely incorporates factors such as path length, relevance to the query, and the inclusion of key entities. By using RL, the system can efficiently identify the most pertinent information within the potentially vast KG, thus overcoming the limitations of exhaustive search. The learned policy, resulting from this RL training, would then be used to extract domain-specific knowledge efficiently for the subsequent prompt generation phase. This dynamic, adaptive strategy promises improvements in both accuracy and efficiency when compared to methods that rely on pre-determined knowledge retrieval strategies.
MAB Prompt Tuning#
MAB (Multi-Armed Bandit) prompt tuning represents a novel approach to enhance Large Language Models (LLMs) by dynamically selecting optimal prompts. Unlike static prompt engineering, MAB leverages reinforcement learning to balance exploration and exploitation, iteratively refining the prompt selection strategy based on the LLM’s performance on previous prompts. This adaptive approach addresses the significant challenge of LLM prompt sensitivity, making the process of creating effective prompts more efficient and less laborious. By learning which prompts yield the best results for various question types and knowledge graph structures, MAB prompt tuning aims to improve the accuracy and consistency of LLM-generated responses. The method’s effectiveness hinges on the careful design of the reward function that guides the MAB’s learning process. The key is to define a reward signal that accurately reflects the quality of the LLM’s output, encouraging the algorithm to favor prompts that yield factually accurate and contextually relevant answers. Furthermore, careful consideration must be given to the exploration-exploitation trade-off, ensuring sufficient exploration to discover novel high-performing prompts, while simultaneously prioritizing exploitation to leverage already successful strategies. The success of MAB prompt tuning depends heavily on the quality of the knowledge graph used to generate prompts and the underlying LLM’s capabilities.
KG Prompting Limits#
Knowledge graph (KG) prompting, while offering enhanced factual grounding for large language models (LLMs), faces inherent limitations. Scalability is a major concern; real-world KGs are vast, necessitating efficient retrieval methods to avoid overwhelming the LLM with irrelevant information. Cost-effectiveness is another limitation, particularly when using closed-source LLMs accessed via APIs, where high query costs can hinder widespread adoption. Prompt engineering remains a challenge, as even subtle prompt variations significantly impact LLM responses. Effective KG-based prompting requires careful consideration of knowledge extraction, relevance filtering, and prompt construction to address these challenges. Ultimately, the success of KG prompting hinges on overcoming these limitations to fully leverage the potential of KGs for improving LLM accuracy and reducing hallucinations.
Future Enhancements#
Future enhancements for the KnowGPT framework could focus on several key areas. Improving the quality of knowledge graphs (KGs) is crucial, as noisy or incomplete KGs can hinder performance. This might involve incorporating KG refinement techniques or exploring alternative KG sources. Developing more sophisticated prompt construction strategies is another important area. Currently, KnowGPT utilizes a multi-armed bandit approach, but exploring more advanced techniques like reinforcement learning or other machine learning methods could further enhance prompt effectiveness. Expanding the range of supported LLMs would broaden the applicability of KnowGPT. Currently, it primarily uses GPT-3.5, but integrating other large language models would significantly increase its versatility. Addressing the computational cost associated with large-scale KG searches is also critical. More efficient search algorithms or techniques for pruning the search space are needed to improve efficiency. Finally, conducting more extensive evaluations on diverse benchmark datasets across various domains will strengthen the robustness and generalizability of the framework.
More visual insights#
More on figures

This figure illustrates the KnowGPT framework’s architecture. It begins with question context and multiple-choice answers, extracting source and target entities. A question-specific subgraph is retrieved from a knowledge graph (KG). The Knowledge Extraction module uses deep reinforcement learning to find the most informative and concise reasoning background. The Prompt Construction module, using a multi-armed bandit approach, prioritizes combinations of knowledge and formats for optimal LLM input. The final prioritized prompt is then sent to GPT-4 for answering the question.
This figure illustrates the KnowGPT framework’s architecture. It starts with a question and multiple choices, then retrieves a relevant subgraph from a knowledge graph (KG). A knowledge extraction module identifies the most informative and concise reasoning paths within the subgraph. Finally, a prompt construction module creates an effective prompt for an LLM by combining the extracted knowledge with suitable formats based on the question’s context.
More on tables
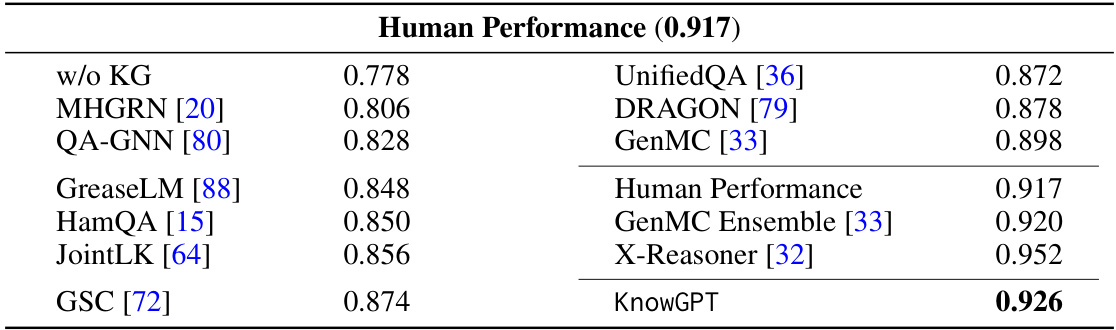
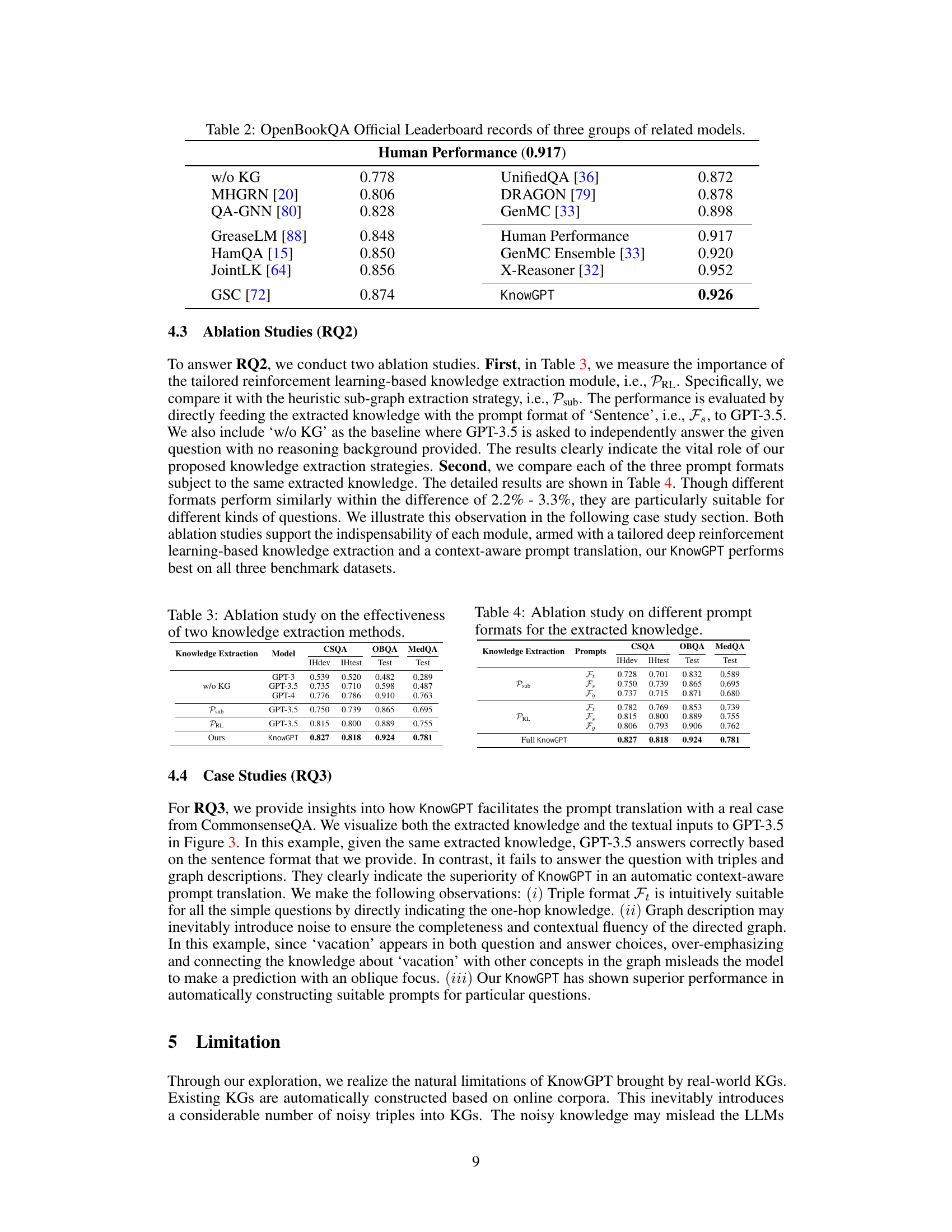
This table presents a comparison of different models’ performance on the OpenBookQA benchmark, categorized into three groups: models without external knowledge graphs (KGs), KG-enhanced language models, and ensemble methods. The table shows the accuracy achieved by each model, highlighting KnowGPT’s competitive performance relative to other state-of-the-art approaches and the human performance baseline.
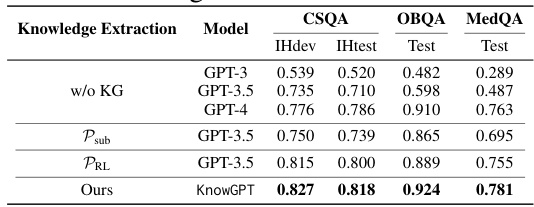
This table compares the performance of KnowGPT against various baseline models across three question answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The baselines are categorized into several groups representing different approaches to question answering, including Language Models (LMs) with fine-tuning, KG-enhanced LMs, LLMs with zero-shot prompting, and LLMs using KG prompting. The table shows the accuracy achieved by each model on the development and test sets of each dataset, demonstrating the superior performance of KnowGPT.
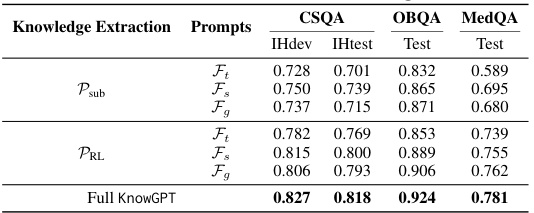
This table presents a comprehensive comparison of KnowGPT’s performance against various baseline models across three question answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The baselines are categorized into several groups: LLMs with fine-tuning, KG-enhanced LLMs, LLMs used in a zero-shot setting, and LLMs with KG prompting. The table shows the accuracy (Dev-Acc and Test-Acc) achieved by each model on each dataset, allowing for a direct comparison of KnowGPT’s performance relative to existing state-of-the-art methods. The results highlight KnowGPT’s significant performance improvements across all datasets.

This table compares the performance of KnowGPT against various baseline models across three question answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The baselines represent different approaches, including fine-tuned language models, KG-enhanced language models, zero-shot LLMs, and other KG prompting methods. The table shows the accuracy achieved by each model on the development and test sets of each dataset, allowing for a comprehensive comparison of KnowGPT’s effectiveness.

This table compares the performance of several fine-tuned large language models (LLMs) against the KnowGPT model on three benchmark question answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The LLMs used were ChatGLM, ChatGLM2, LLaMA-7B, Baichuan-7B, Alpaca-7B, Vicuna-7B, and InternLM-7B. The table shows the accuracy achieved by each model on each dataset. It highlights that KnowGPT, despite not being fine-tuned, significantly outperforms all the fine-tuned LLMs across all three datasets.

This table presents the accuracy of three different prompt formats (Triples, Sentences, and Graph Description) on three categories of questions from the CommonsenseQA dataset: Simple, Multi-hop, and Graph reasoning questions. The accuracy varies across the different prompt formats and question types, indicating the suitability of certain formats for specific reasoning complexities.
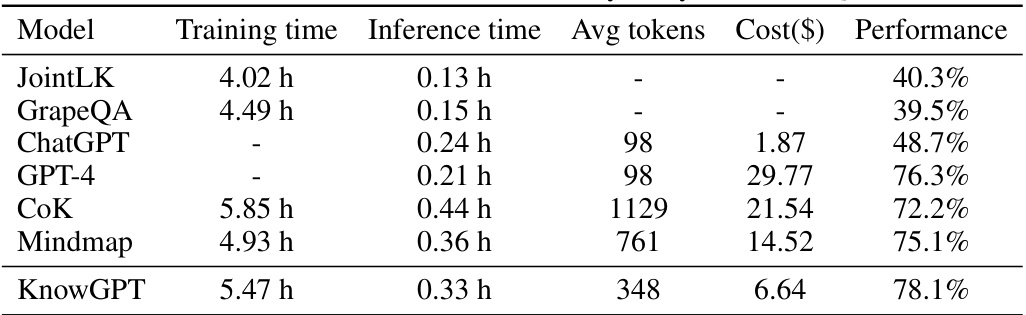
This table compares the API cost and model efficiency of KnowGPT against several baseline models on the MedQA dataset. It shows the training time, inference time, average number of tokens used, cost in dollars, and performance (accuracy) for each model. The baselines represent different approaches to question answering, including those that use fine-tuning, zero-shot methods, and other KG-prompting techniques. The table highlights KnowGPT’s efficiency in terms of API cost while achieving competitive performance.
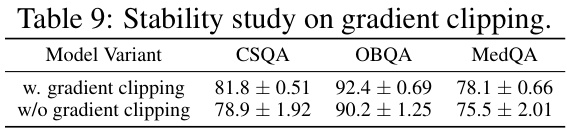
This table presents a comprehensive comparison of KnowGPT’s performance against various baseline models across three question answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The baseline models are categorized into four groups: LLMs with fine-tuning, KG-enhanced LLMs, LLMs with zero-shot prompting, and LLMs with KG prompting. The table displays the development and test accuracy for each model on each dataset, allowing for a direct comparison of KnowGPT’s effectiveness in improving the accuracy of large language models through knowledge graph prompting.
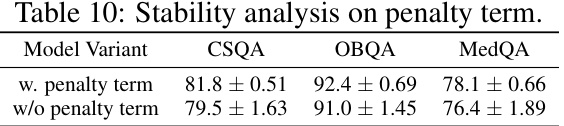
This table compares the performance of KnowGPT against various baseline models across three question answering datasets: CommonsenseQA, OpenBookQA, and MedQA. The baselines represent different approaches, including fine-tuned Language Models (LM), KG-enhanced LMs, zero-shot LLMs, and other KG prompting methods. The table shows the accuracy achieved by each model on the development and test sets of each dataset. This allows for a comprehensive evaluation of KnowGPT’s performance relative to existing state-of-the-art techniques.
Full paper#