TL;DR#
Existing video semantic segmentation methods struggle with adverse weather conditions due to their reliance on accurate optical flow, which becomes unreliable in such scenarios. These methods often yield inaccurate predictions due to significant low-level feature degradation caused by adverse weather. This paper aims to solve this problem by developing a more robust method.
The proposed method introduces an end-to-end, optical-flow-free video semantic segmentation model. It uses a novel fusion block to effectively merge feature-level temporal information from adjacent frames, thereby improving temporal consistency. Furthermore, a temporal-spatial teacher-student learning approach is employed to enhance the model’s robustness by training it to handle weather-specific degradations that span across consecutive frames. This method achieves a significant improvement over existing state-of-the-art methods in adverse weather conditions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on video semantic segmentation and unsupervised domain adaptation (UDA), particularly in challenging conditions like adverse weather. It presents a novel end-to-end, optical-flow-free approach that significantly improves accuracy and efficiency, addressing limitations of existing methods. The proposed temporal-spatial teacher-student learning strategy and temporal weather degradation augmentation are valuable contributions that could inspire further research and development of robust and efficient video semantic segmentation models.
Visual Insights#

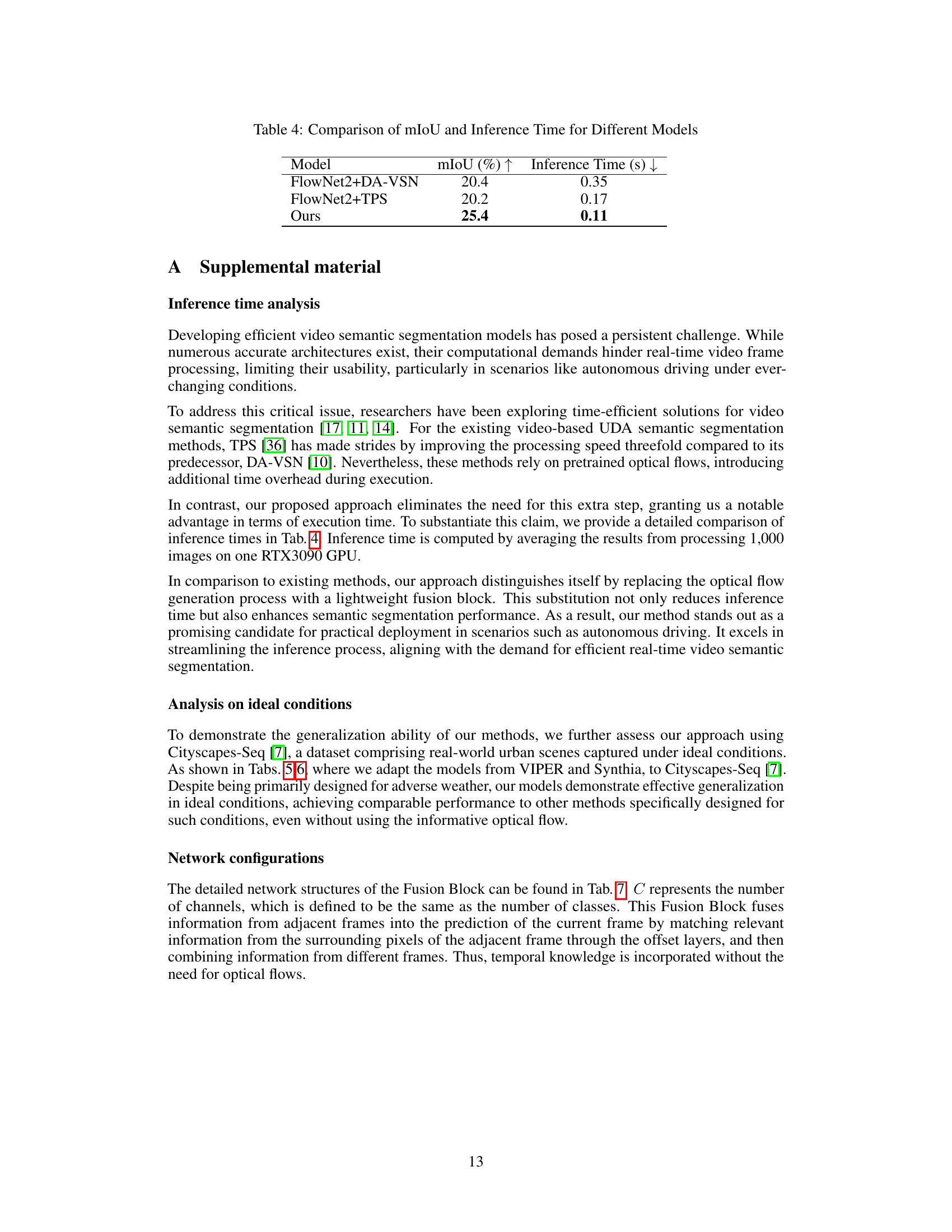
🔼 This figure showcases the results of semantic segmentation under adverse weather conditions (foggy and snowy). It compares the performance of the proposed model against TPS [36], a state-of-the-art method. The images demonstrate that the proposed model significantly improves segmentation accuracy by reducing inaccuracies, especially in challenging weather conditions.
read the caption
Figure 1: Our model demonstrates enhanced robustness compared to TPS [36] in semantic segmentation tasks under foggy and snowy conditions. It notably excels by significantly reducing inaccuracies in the segmented areas.
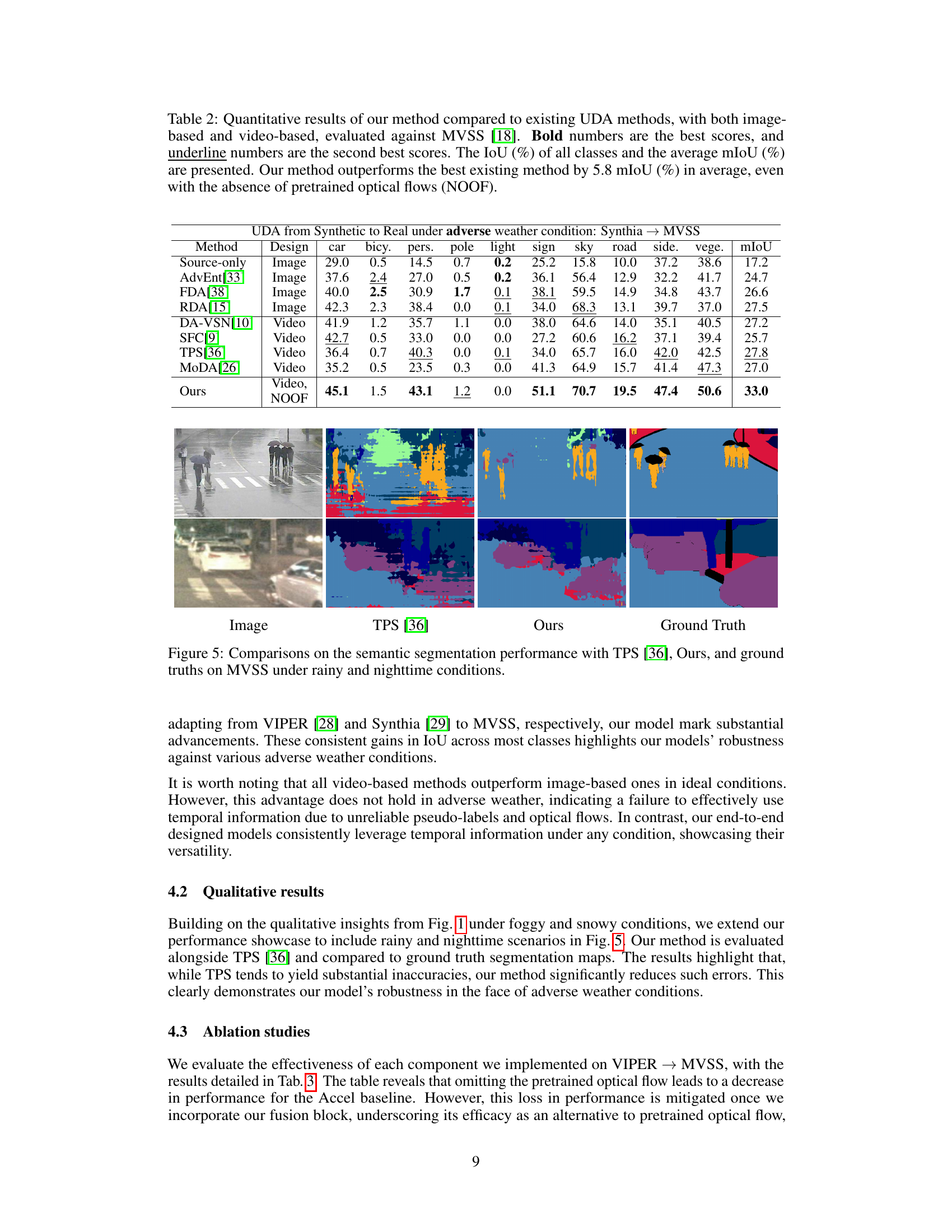
🔼 This table presents a quantitative comparison of the proposed method against several existing unsupervised domain adaptation (UDA) methods for video semantic segmentation. The comparison is made using the MVSS dataset, focusing on performance under adverse weather conditions. The table shows the Intersection over Union (IoU) for individual classes and the mean IoU (mIoU), highlighting the improvements achieved by the proposed method, particularly its ability to perform well without relying on pretrained optical flow.
read the caption
Table 1: Quantitative results of our method compared to existing UDA methods, with both image-based and video-based, evaluated against MVSS [18]. Bold numbers are the best scores, and underline numbers are the second best scores. The IoU (%) of all classes and the average mIoU (%) are presented. Our method outperforms the best existing method by 4.3 mIoU (%) in average, even with the absence of pretrained optical flows (NOOF).
In-depth insights#
Adverse Weather UDA#
The research area of “Adverse Weather UDA” (Unsupervised Domain Adaptation) in video semantic segmentation presents a significant challenge. Existing UDA methods often struggle under adverse weather conditions due to the degradation of low-level image features (noise, glare, occlusion). This impacts the reliability of optical flow estimations, a crucial component in many existing approaches, and also affects the accuracy of pseudo-labels used for training in the unlabeled target domain. The core issue is the domain gap created by these adverse weather effects between synthetic datasets (often used for source domains due to readily available annotations) and real-world, adverse-weather imagery. Therefore, novel approaches are needed that either explicitly address these low-level degradations or avoid the reliance on optical flow altogether. End-to-end trainable methods, potentially incorporating techniques like temporal fusion blocks, and robust training strategies that leverage temporal information, are key to improving performance in this challenging area.
Fusion Block Design#
The effective design of a fusion block is crucial for the success of the proposed video semantic segmentation method. The core idea revolves around intelligently merging feature-level information from adjacent frames to enhance the model’s understanding of temporal context. Avoiding reliance on optical flow, a common source of error in adverse weather conditions, is a key advantage. The fusion block directly integrates information from consecutive frames using a series of deformable convolutional and standard convolutional layers, enabling flexible pixel matching and merging. This allows the model to learn relevant correspondences across frames effectively and is trained end-to-end for optimal performance, achieving efficient feature integration without pre-trained flow estimation. This novel approach makes the model more robust to adverse weather degradations and enhances the model’s ability to obtain accurate segmentations in challenging conditions. A strength is the ability to integrate temporal information from adjacent frames directly into the semantic segmentation task improving accuracy. The fusion block’s architecture and training approach are critical elements of the end-to-end video semantic segmentation method. Its success underscores the power of learning effective temporal relationships within the video data itself.
Teacher-Student Models#
Teacher-student learning is a powerful paradigm in deep learning, particularly effective in scenarios with limited labeled data. The core idea involves a teacher model, typically a more advanced or well-trained network, guiding a student model, often a simpler or less computationally expensive architecture. The teacher provides supervisory signals to the student, often in the form of pseudo-labels or knowledge distillation, enabling the student to learn effectively from unlabeled or weakly-labeled data. This setup offers advantages including improved generalization, robustness, and efficiency. A key advantage is leveraging the knowledge of a well-trained teacher to accelerate and stabilize the learning process of the student model. However, the effectiveness of teacher-student methods depends significantly on careful design of the teacher and student networks and the strategy for knowledge transfer. Challenges include ensuring that the student doesn’t simply mimic the teacher’s biases and effectively learning from the teacher’s insights. Furthermore, the choice of loss function and hyperparameter tuning play a crucial role in the success of this approach. Despite these challenges, teacher-student models offer a promising avenue for semi-supervised and unsupervised learning, continuously advancing the field of deep learning.
Temporal Augmentation#
The concept of “Temporal Augmentation” in the context of video semantic segmentation in adverse weather conditions is a powerful technique. By applying correlated augmentations to consecutive frames with gradual intensity variations, it effectively captures the dynamic nature of adverse weather degradations. This is a significant improvement over existing methods which often fail to consider the temporal aspect of weather effects. The key is the correlated nature of the augmentations, ensuring the changes in consecutive frames realistically reflect weather patterns. This approach addresses a critical limitation of other video semantic segmentation techniques that rely on frame-by-frame processing or on static representations of weather effects. The enhanced realism of the augmentation improves the model’s robustness to real-world adverse weather conditions and consequently leads to better accuracy. Furthermore, this augmentation strategy is particularly useful when training on synthetic datasets and adapting to real-world scenarios. It helps to bridge the domain gap by providing a more comprehensive and realistic representation of the challenges posed by varying adverse weather conditions in time.
Optical Flow-Free UDA#
The concept of ‘Optical Flow-Free UDA’ presents a significant advancement in unsupervised domain adaptation (UDA) for video semantic segmentation. Traditional UDA methods heavily rely on accurate optical flow estimations to warp features between frames, a process that becomes unreliable under adverse weather conditions. By eliminating the reliance on optical flow, this approach offers enhanced robustness and accuracy, particularly in challenging scenarios like nighttime or foggy conditions where optical flow often fails. This innovative method likely employs alternative strategies to leverage temporal information, potentially through advanced fusion mechanisms that directly integrate features from consecutive frames. This approach may involve sophisticated attention mechanisms or recurrent neural network architectures that model temporal dependencies without explicit flow computation, leading to more reliable and consistent results across various weather conditions. The benefit of an optical flow free approach is that it reduces computation complexity and the sensitivity to noise and motion inaccuracies often found in optical flow, leading to improved efficiency and generalization capabilities.
More visual insights#
More on figures
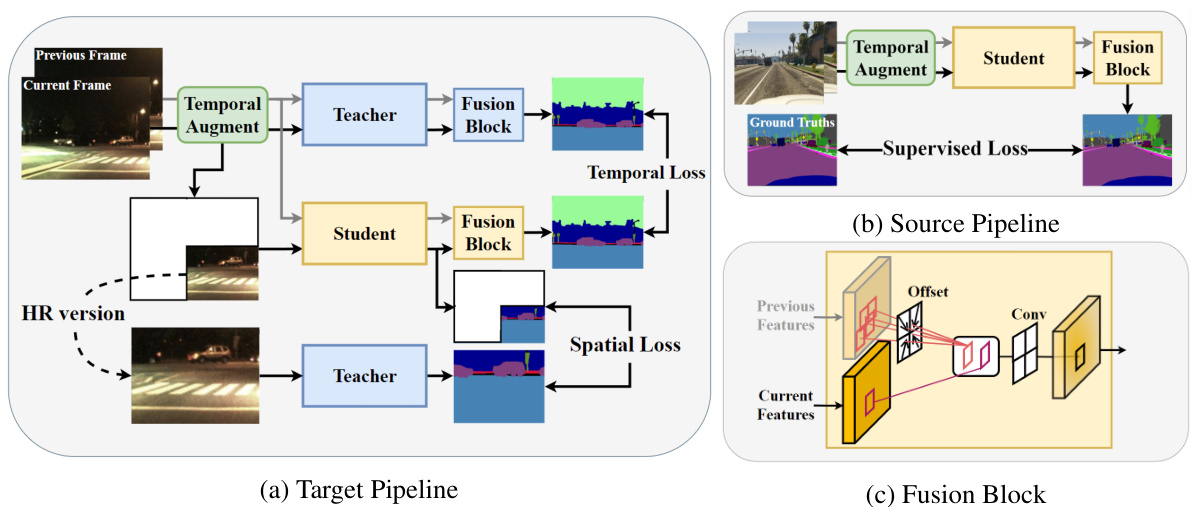
🔼 This figure illustrates the architecture of the proposed method, which consists of two pipelines: the source pipeline and the target pipeline. The source pipeline is used for supervised training on synthetic data, while the target pipeline is used for unsupervised domain adaptation on real-world data. The fusion block is a key component of the proposed method, which merges information from adjacent frames to improve the accuracy of semantic segmentation. The temporal-spatial teacher-student learning framework further enhances the performance of the proposed method.
read the caption
Figure 2: Our network comprises two pipelines: the source and the target. (a) Target Pipeline: The upper teacher (temporal) takes both the current and adjacent frames to create temporal pseudo-labels. The student, on the other hand, receives a cropped segment of the current frame and a complete adjacent frame, with a loss function enforcing its predictions align with the temporal teacher. The lower teacher (spatial) uses the same segment as the student, but from the original image and at a higher resolution. Similarly, a consistency loss is applied to make the student’s predictions consistent with the spatial teacher’s pseudo-labels. (b) Source Pipeline: The student model undergoes supervised learning with consecutive frames as inputs. (c) Fusion Block: This component integrates multiple offset layers, which adjust pixels from adjacent frames relative to the current frame, and convolutional layers to merge these pixels.

🔼 This figure compares optical flow predictions from the FlowNet2 model under ideal and adverse weather conditions. The left side shows accurate optical flow under good conditions, clearly showing movement of vehicles and other objects. The right side shows inaccurate and incomplete optical flow under adverse (nighttime) conditions, demonstrating the unreliability of optical flow in such scenarios, motivating the paper’s optical-flow-free approach.
read the caption
Figure 3: An illustration of optical flows generated using a pretrained FlowNet2 model [27]. The optical flows are generated by utilizing information from the corresponding frame and its previous frame. The left two columns display frames and optical flows under ideal conditions, while the right two columns depict frames and optical flows under adverse weather conditions, with nighttime as an illustrative example. Under ideal conditions, the optical flows accurately capture vehicle details, traffic signs, and poles. In contrast, optical flows under nighttime conditions exhibit significant failures, with missed detection of the middle poles, and erroneous predictions for the bus.

🔼 This figure shows an example of the temporal weather degradation augmentation technique used in the paper. It uses Cityscapes-Seq dataset to illustrate how the augmentation affects consecutive frames, simulating realistic adverse weather conditions like fog, glare, and varying illumination. Frames (a) and (c) show original frames, while frames (b) and (d) depict the same frames after applying the augmentations.
read the caption
Figure 4: This illustration demonstrates the temporal weather degradation augmentation technique. For enhanced visualization, we have utilized Cityscapes-Seq as an example. Frames (a) and (b) are consecutive frames captured from a real-world scene under ideal conditions. Frames (c) and (d) show the same frames, but with applied augmentation, including random noise, a moving glare, a rectangle 'foggy' area with intensity change, and a changing illumination.
More on tables
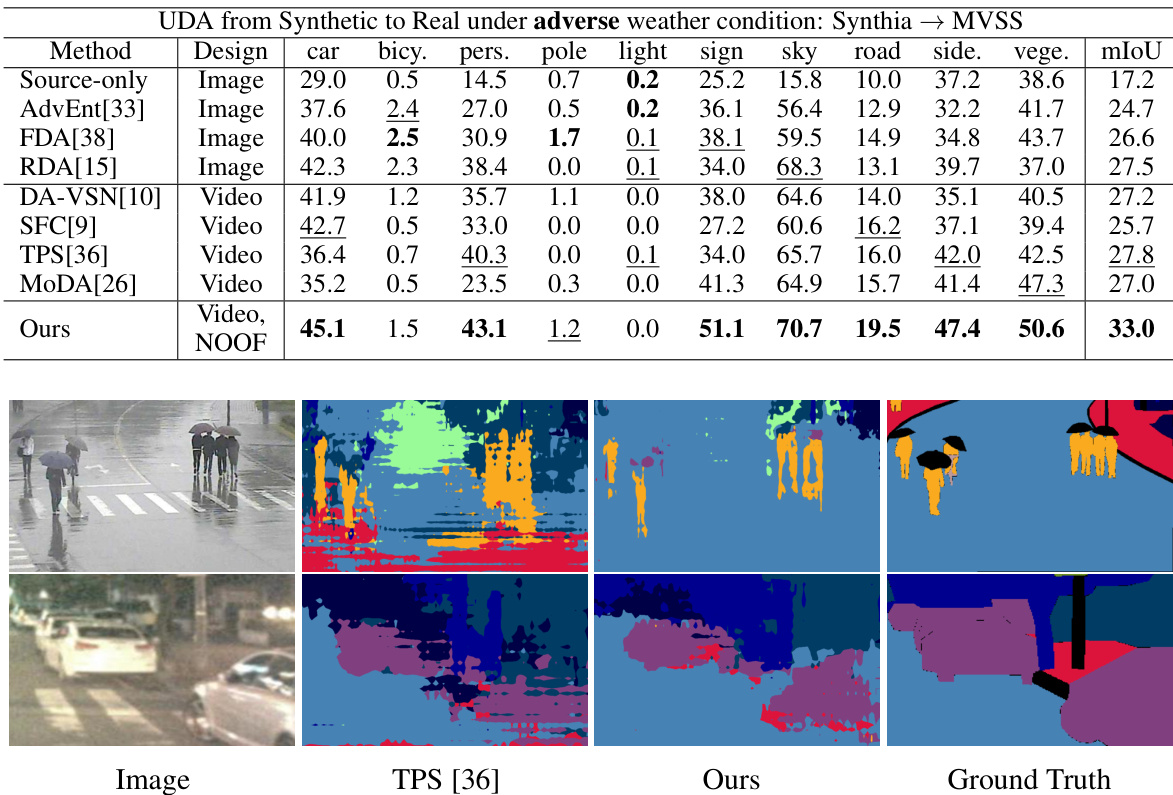
🔼 This table presents a quantitative comparison of the proposed method against existing unsupervised domain adaptation (UDA) methods for video semantic segmentation. The comparison uses the MVSS dataset and considers both image-based and video-based approaches. The key metric is mean Intersection over Union (mIoU), showing performance improvement with the proposed method, particularly in its superior performance compared to other methods without needing pre-trained optical flow.
read the caption
Table 2: Quantitative results of our method compared to existing UDA methods, with both image-based and video-based, evaluated against MVSS [18]. Bold numbers are the best scores, and underline numbers are the second best scores. The IoU (%) of all classes and the average mIoU (%) are presented. Our method outperforms the best existing method by 5.8 mIoU (%) in average, even with the absence of pretrained optical flows (NOOF).
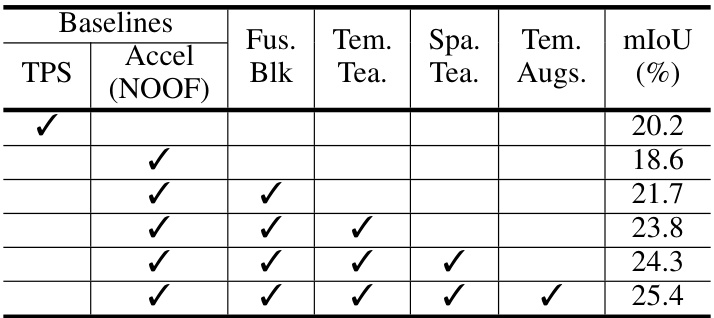
🔼 This table presents the results of ablation studies conducted to evaluate the individual contribution of each component of the proposed method. It shows the mIoU achieved by different combinations of the fusion block, temporal teacher, spatial teacher, and temporal augmentation on the VIPER to MVSS adaptation task. The baseline is the Accel model without any of the proposed components. Each row adds one or more of the proposed components to assess their effect on the overall performance.
read the caption
Table 3: Ablation studies of our proposed techniques. We can observe that each component independently contributes to the overall improvement in performance.

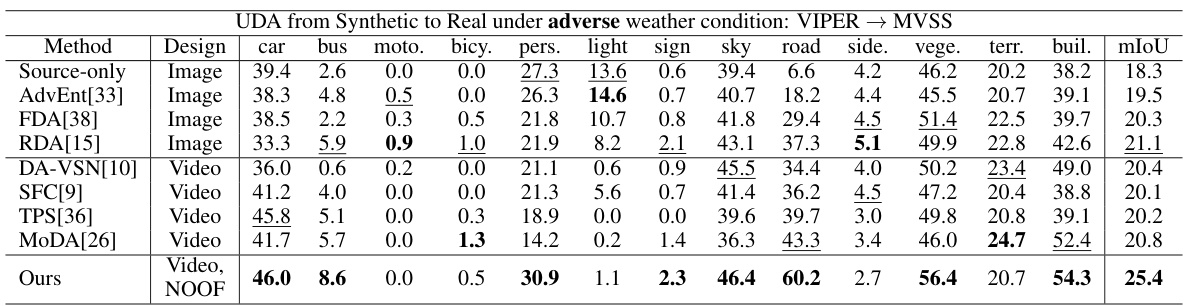
🔼 This table presents a quantitative comparison of the proposed method’s performance against existing Unsupervised Domain Adaptation (UDA) methods for video semantic segmentation. The comparison uses the MVSS dataset and includes both image-based and video-based UDA techniques. The key metrics are Intersection over Union (IoU) for each class and mean IoU (mIoU) across all classes. The table highlights that the proposed method achieves superior performance compared to state-of-the-art methods, even without relying on pretrained optical flow.
read the caption
Table 1: Quantitative results of our method compared to existing UDA methods, with both image-based and video-based, evaluated against MVSS [18]. Bold numbers are the best scores, and underline numbers are the second best scores. The IoU (%) of all classes and the average mIoU (%) are presented. Our method outperforms the best existing method by 4.3 mIoU (%) in average, even with the absence of pretrained optical flows (NOOF).
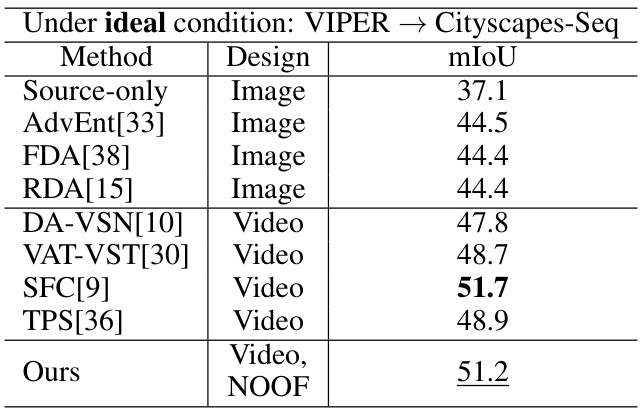
🔼 This table presents a quantitative comparison of the proposed method against existing unsupervised domain adaptation (UDA) methods for video semantic segmentation. The evaluation is performed on the Cityscapes-Seq dataset under ideal weather conditions. Both image-based and video-based UDA methods are included in the comparison. The table shows the Intersection over Union (IoU) scores for each class and the mean IoU (mIoU), highlighting the superior performance of the proposed method.
read the caption
Table 5: Quantitative results of our method compared to existing UDA methods, with both image-based and video-based, evaluated against Cityscapes-Seq [7]. Bold numbers are the best scores, and underline numbers are the second best scores. The IoU (%) of all classes and the average mIoU (%) are presented.
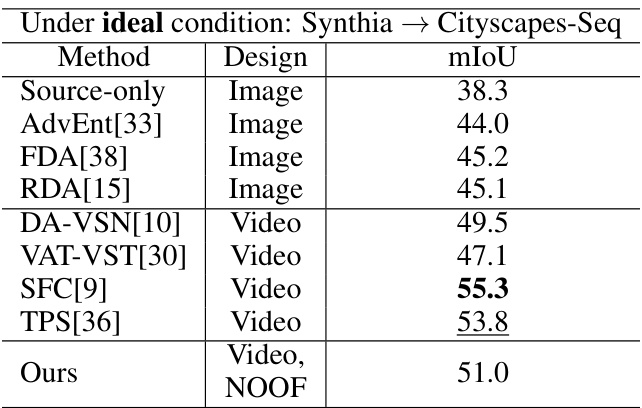
🔼 This table presents a comparison of the proposed method’s performance against other state-of-the-art unsupervised domain adaptation (UDA) methods for video semantic segmentation. The comparison is made using the MVSS dataset, and the metrics used are Intersection over Union (IoU) for each class and mean IoU (mIoU) overall. The table highlights that the proposed method surpasses existing methods even without relying on pre-trained optical flow information.
read the caption
Table 2: Quantitative results of our method compared to existing UDA methods, with both image-based and video-based, evaluated against MVSS [18]. Bold numbers are the best scores, and underline numbers are the second best scores. The IoU (%) of all classes and the average mIoU (%) are presented. Our method outperforms the best existing method by 5.8 mIoU (%) in average, even with the absence of pretrained optical flows (NOOF).

🔼 This table details the architecture of the Fusion Block, a key component of the proposed model. It shows the sequence of convolutional layers (Conv), deformable convolutional layers (DeformConv), and activation functions (Sigmoid) used for merging feature information from adjacent frames. The number of channels (C) is a variable depending on the number of classes in the segmentation task.
read the caption
Table 7: Network Structure of Fusion Block
Full paper#