↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Word embeddings in neural language models suffer from skewed distributions, hindering performance. Existing methods implicitly assume uniform word frequencies, ignoring Zipf’s law (the non-uniform distribution of word frequencies). This assumption creates a significant gap between theory and practice, impacting model symmetry and downstream task performance.
This paper introduces Zipfian Whitening, a novel method that addresses this limitation. By weighting PCA whitening by empirical word frequencies, it significantly improves performance on standard NLP tasks. The method is theoretically grounded, showing how it naturally emphasizes informative low-frequency words and aligns with existing techniques. The paper also proposes new metrics for evaluating embedding symmetry, considering word frequencies, revealing a strong correlation with downstream task performance.
Key Takeaways#
Why does it matter?#
This paper is highly important because it offers a novel perspective on word embedding optimization. By addressing the inherent non-uniformity of word frequencies (Zipf’s law), it significantly improves the performance of various NLP tasks and provides a unifying framework for understanding the effectiveness of existing methods. It also introduces new metrics for evaluating embedding symmetry and opens avenues for future research in information geometry and imbalanced classification.
Visual Insights#
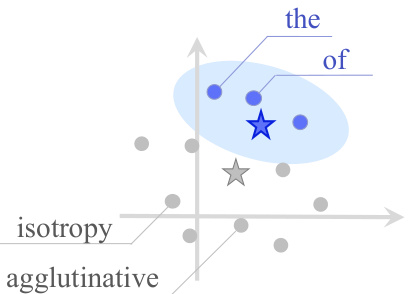
The figure illustrates the uneven distribution of low-frequency and high-frequency words in the embedding space. Low-frequency words are sparsely distributed while high-frequency words cluster together. The unweighted mean (calculated by simply averaging all word vectors) is shown as a gray star, which is far from the true centroid (blue star) that is more representative of the overall distribution. The difference highlights how the standard (unweighted) mean is misleading when word frequencies are non-uniform, which is common in natural language.

This table compares word sampling methods based on types and tokens. Type-based sampling selects words uniformly from the vocabulary, while token-based sampling selects words based on their frequency in a corpus. The table shows that type-based sampling tends to select rare words, while token-based sampling more accurately reflects the distribution of words in typical text.
In-depth insights#
Zipfian Whitening#
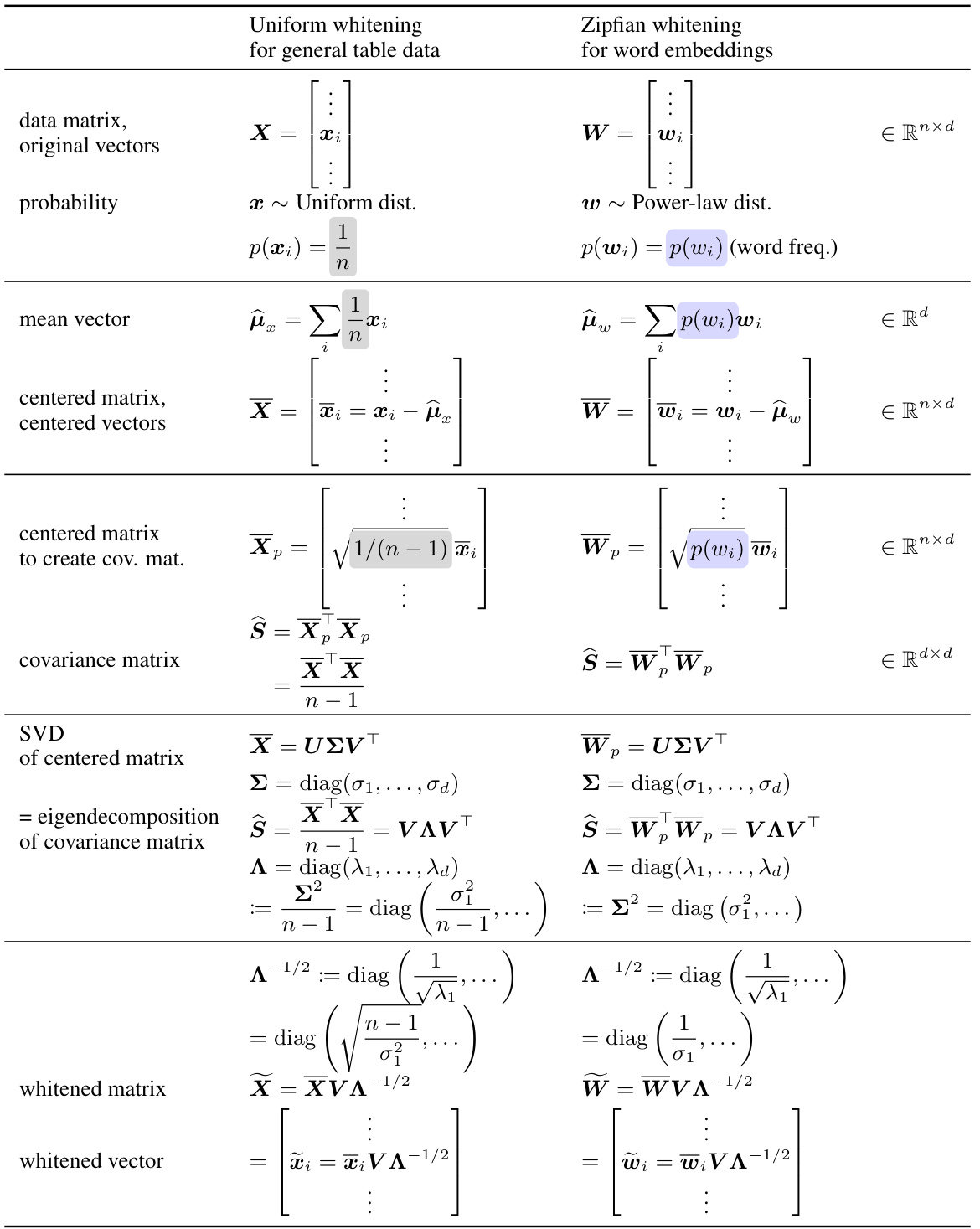
The concept of “Zipfian Whitening” presents a novel approach to address the skew in word embedding spaces by incorporating word frequency distributions following Zipf’s law. Instead of the typical uniform weighting in existing methods like PCA whitening, Zipfian Whitening weights the data by the empirical word frequencies, significantly improving downstream task performance. This weighting naturally emphasizes informative, low-frequency words, which are often underrepresented in standard approaches. The theoretical justification highlights how Zipfian Whitening aligns with the underlying probabilistic models of several popular NLP techniques like skip-gram negative sampling, thereby explaining their effectiveness. It also bridges the gap between type-token distinction in linguistics and the uniform treatment of word vectors in machine learning. Through an information-geometric perspective, the paper clarifies how Zipfian whitening better encodes the information content into the word vector norms.
Type-token Issue#
The type-token distinction is crucial for understanding the limitations of standard embedding methods. Word embeddings represent word types (e.g., the word ’the’), not tokens (individual instances of ’the’). Classical methods like centering implicitly assume uniform word frequencies; however, real-world word frequencies are highly skewed, following Zipf’s law. This discrepancy leads to flawed calculations of expected values for word vectors, as the unweighted mean conflates types and tokens, misleadingly emphasizing rare words. Correcting this requires weighting word vector calculations by their empirical frequencies. This approach, which the authors refer to as Zipfian whitening, ensures that common words are appropriately represented, leading to improved downstream task performance and revealing a more accurate geometric structure of the embedding space. The type-token distinction highlights a fundamental mismatch between typical statistical methods and NLP tasks and explains the superiority of empirically-grounded methods.
Symmetry Metrics#
In evaluating the effectiveness of embedding space manipulations, such as those aimed at enhancing symmetry, robust symmetry metrics are crucial. These metrics should move beyond simple visual inspection or correlation with downstream task performance, offering instead a quantifiable measure of spatial uniformity. Existing metrics often implicitly assume a uniform word frequency distribution, which is unrealistic. Therefore, any proposed metric should explicitly address the inherent non-uniformity of word frequencies, likely by incorporating frequency weighting into its calculations. A good metric should capture both low-order (e.g., centering) and higher-order moments of the data distribution, providing a more comprehensive view of spatial symmetry. Furthermore, the relationship between the chosen metric and downstream task performance should be carefully analyzed to demonstrate its practical significance. The ideal approach would combine theoretical grounding in information geometry or similar frameworks with empirical validation across diverse NLP tasks and datasets, establishing a strong link between the observed spatial characteristics and real-world task efficacy.
Generative Models#
Generative models are a powerful class of machine learning models capable of creating new data instances that resemble the training data. In the context of NLP research, these models are particularly valuable for tasks like text generation, machine translation, and question answering. Their ability to learn the underlying probability distribution of the data allows them to generate coherent and contextually relevant text. However, the efficacy of generative models in NLP is intrinsically linked to the quality of the training data and the model’s architecture. Issues like bias amplification and the difficulty in evaluating generated text require careful consideration. Furthermore, the computational cost of training and using large-scale generative models can be substantial. Recent advancements, such as those leveraging transformer architectures, have significantly improved the quality and efficiency of generative models. Nonetheless, ongoing research continues to explore ways to mitigate limitations and improve the robustness of these models, particularly in addressing issues of fairness, bias, and controllability.
Future Work#
The paper’s exploration of Zipfian whitening opens several exciting avenues for future research. Extending the theoretical framework to encompass a wider range of language models, particularly dynamic models and causal language models, is crucial. A deeper investigation into the relationship between the generative model and the whitening process is needed to solidify the theoretical foundation. Addressing potential limitations related to numerical instability in the calculations, especially concerning low-frequency words, is vital for practical applications. The impact of word frequency distributions on different NLP tasks requires further investigation. Empirical evaluations on a broader range of datasets and tasks would strengthen the conclusions. Further exploring the use of Zipfian whitening as a regularization technique to improve the performance of next-token prediction models in large language models is also a promising direction. Finally, research on the broader societal impacts of using Zipfian whitening should be pursued to ensure responsible use of the technology and mitigation of potential negative consequences.
More visual insights#
More on figures
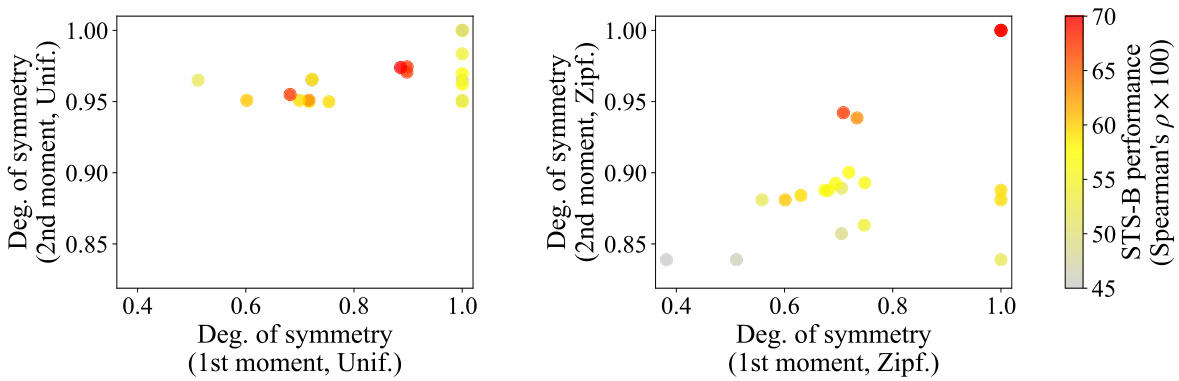
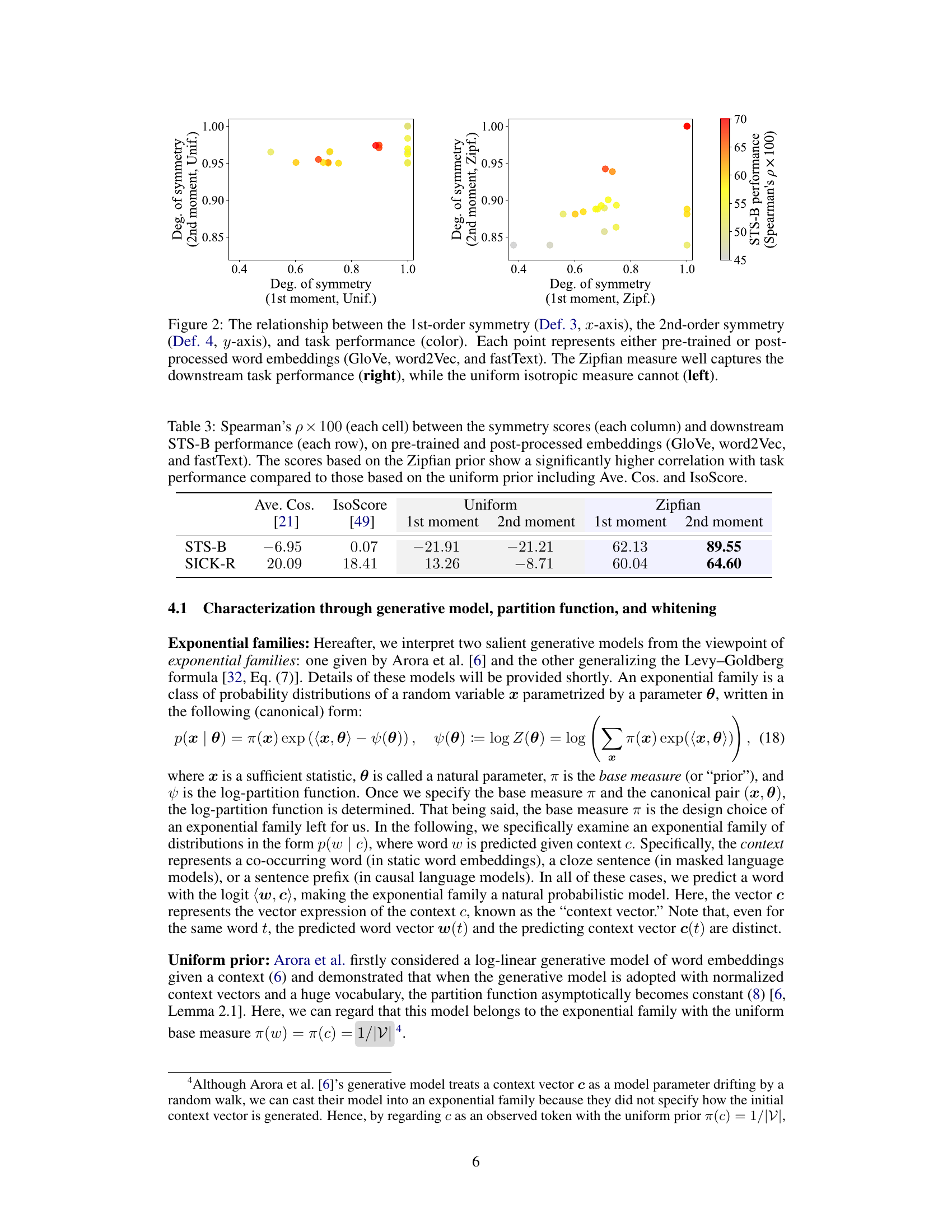
This figure shows the relationship between the degree of symmetry (1st and 2nd moments) and the performance on downstream tasks for different word embedding models. The left panel shows the results using uniform word frequency, while the right panel uses Zipfian word frequency. The color of each point represents the task performance, showing that Zipfian weighting correlates better with downstream performance than uniform weighting.
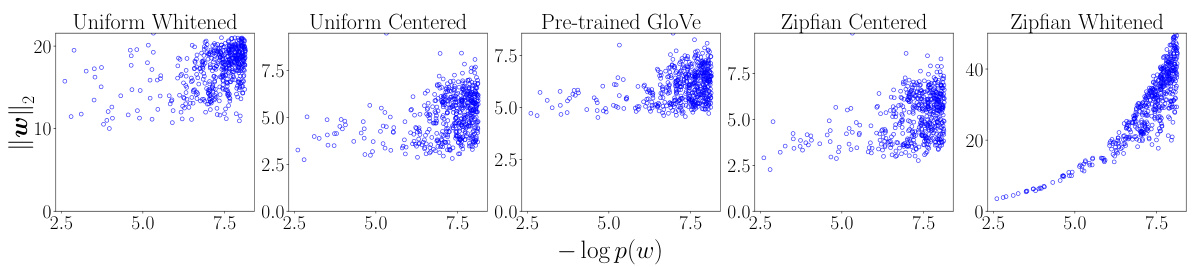
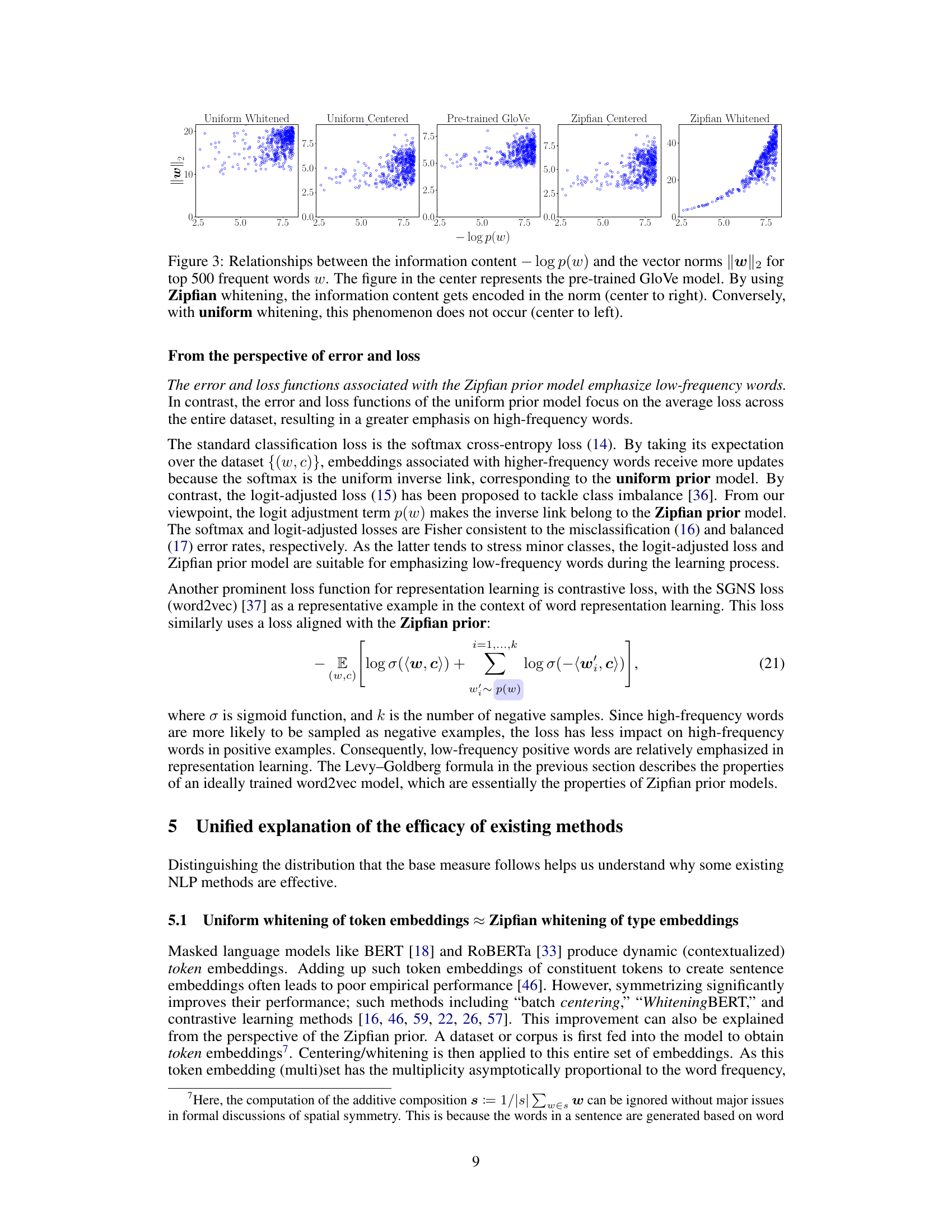
This figure compares the relationship between information content (-log p(w)) and vector norms (||w||²) for the top 500 frequent words using different word embedding methods. The leftmost panel shows the results of uniform whitening; the middle left panel shows the results of uniform centering. The middle panel shows the results of a pre-trained GloVe model. The middle right panel shows the results of Zipfian centering, and the rightmost panel shows the results of Zipfian whitening. The figure demonstrates how Zipfian whitening encodes information content into vector norms, unlike uniform whitening.
More on tables

This table presents the results of the STS-B task using different word embedding models (GloVe, Word2Vec) and preprocessing techniques. It shows that applying Zipfian whitening, a method that incorporates word frequency into the whitening process, consistently achieves better results than standard methods (centering and whitening) and other baselines (ABTT, SIF + CCR).
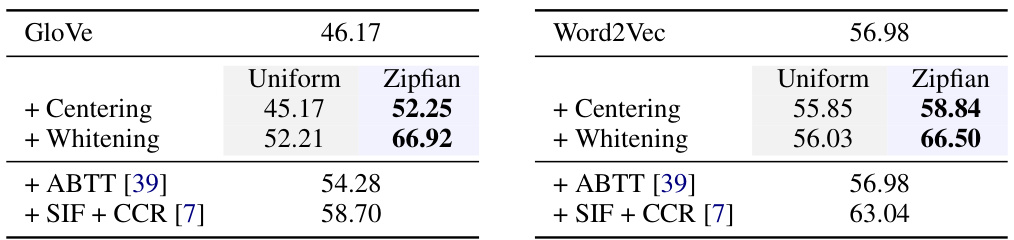
This table presents the results of an empirical evaluation comparing the performance of Zipfian whitening against several baselines on the STS-B benchmark. The STS-B score (semantic textual similarity) is presented, showing the improvement achieved by using Zipfian whitening. The table highlights the consistent superior performance of Zipfian whitening across various baseline methods.
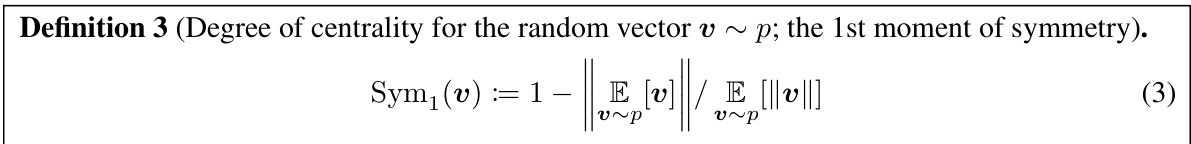
This table shows the results of the STS-B benchmark for different word embedding models (GloVe, Word2Vec) using various methods for embedding symmetry enhancement. It compares the performance of standard centering and whitening against ABTT [39] and SIF + CCR [7] baselines, with and without the use of Zipfian weighting based on empirical word frequencies. The results demonstrate that Zipfian whitening consistently outperforms the other methods.

This table shows the results of an empirical evaluation of Zipfian whitening on the STS-B benchmark dataset. It compares the performance of Zipfian whitening against several baselines (GloVe + various methods, Word2Vec + various methods). Each entry represents the STS-B score (×100), a measure of semantic textual similarity. The table demonstrates that Zipfian whitening consistently outperforms the baselines.

This table presents the Spearman’s rank correlation coefficients (multiplied by 100) between different symmetry scores and the downstream STS-B task performance. The symmetry scores are calculated using both uniform and Zipfian priors for pre-trained and post-processed word embeddings from GloVe, word2Vec, and fastText. The results show a much stronger correlation between the Zipfian-based symmetry scores and task performance compared to the uniform-based scores, including those from established methods like Average Cosine Similarity and IsoScore.

This table compares the performance of two different methods for enhancing the symmetry of word embeddings: uniform whitening and Zipfian whitening. It shows that applying uniform whitening to token embeddings (which implicitly incorporates a Zipfian distribution at the type level) outperforms applying uniform whitening directly to type embeddings. The results are presented using the STS-B (Semantic Textual Similarity Benchmark) score.
This table presents the results of the STS-B benchmark task, comparing the performance of various word embedding methods, with a focus on Zipfian whitening and its impact on performance.
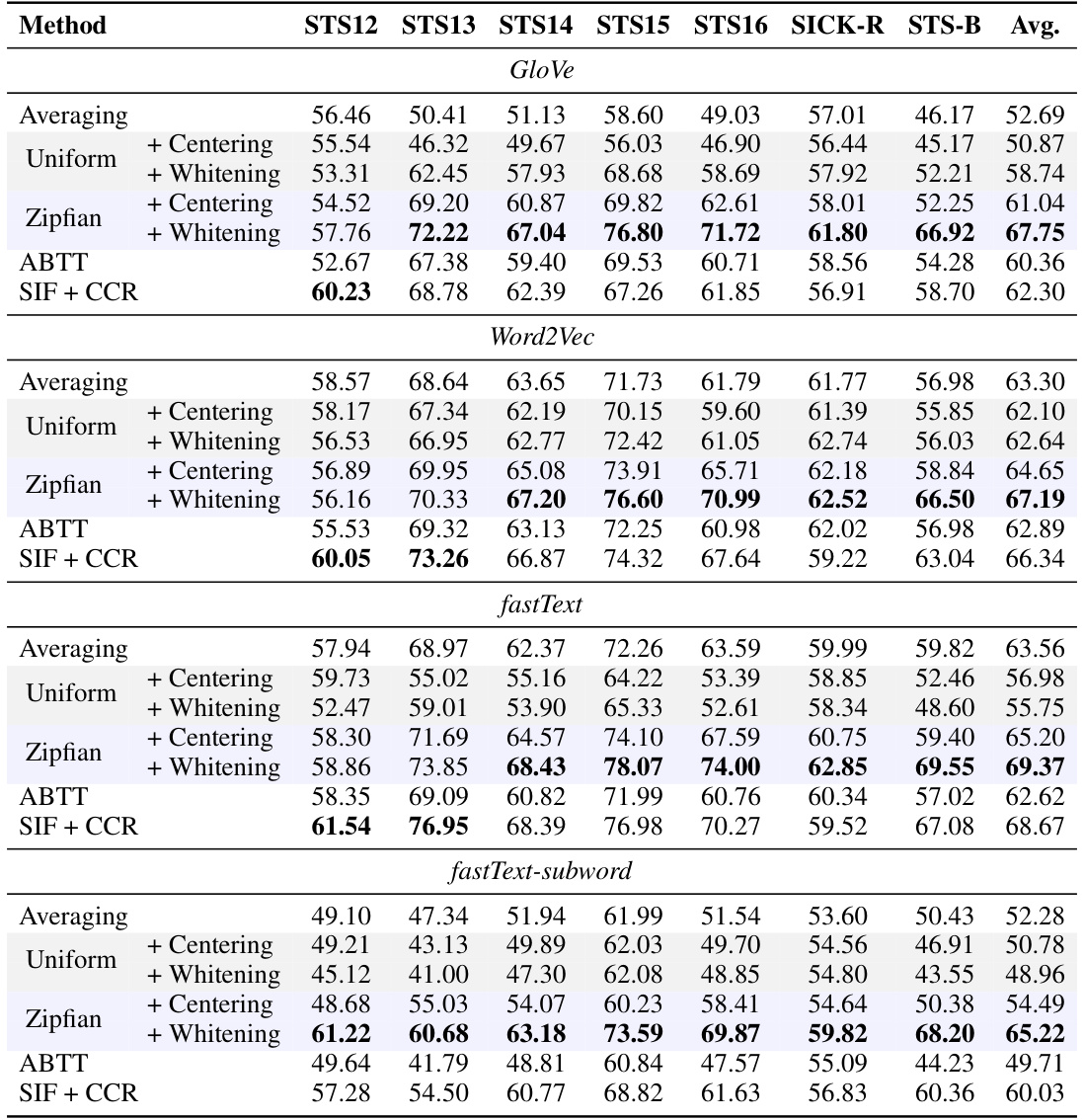
This table presents the results of the empirical performance evaluation of Zipfian whitening on various sentence similarity tasks (STS). The results are broken down by word embedding model (GloVe, Word2Vec, fastText, and fastText-subword), and by different methods for processing the word embeddings (Averaging, Centering, Whitening, ABTT, and SIF+CCR). For each model and method, the STS scores are reported, showing the effectiveness of Zipfian whitening compared to standard techniques. The empirical word frequency used was derived from the enwiki dataset.
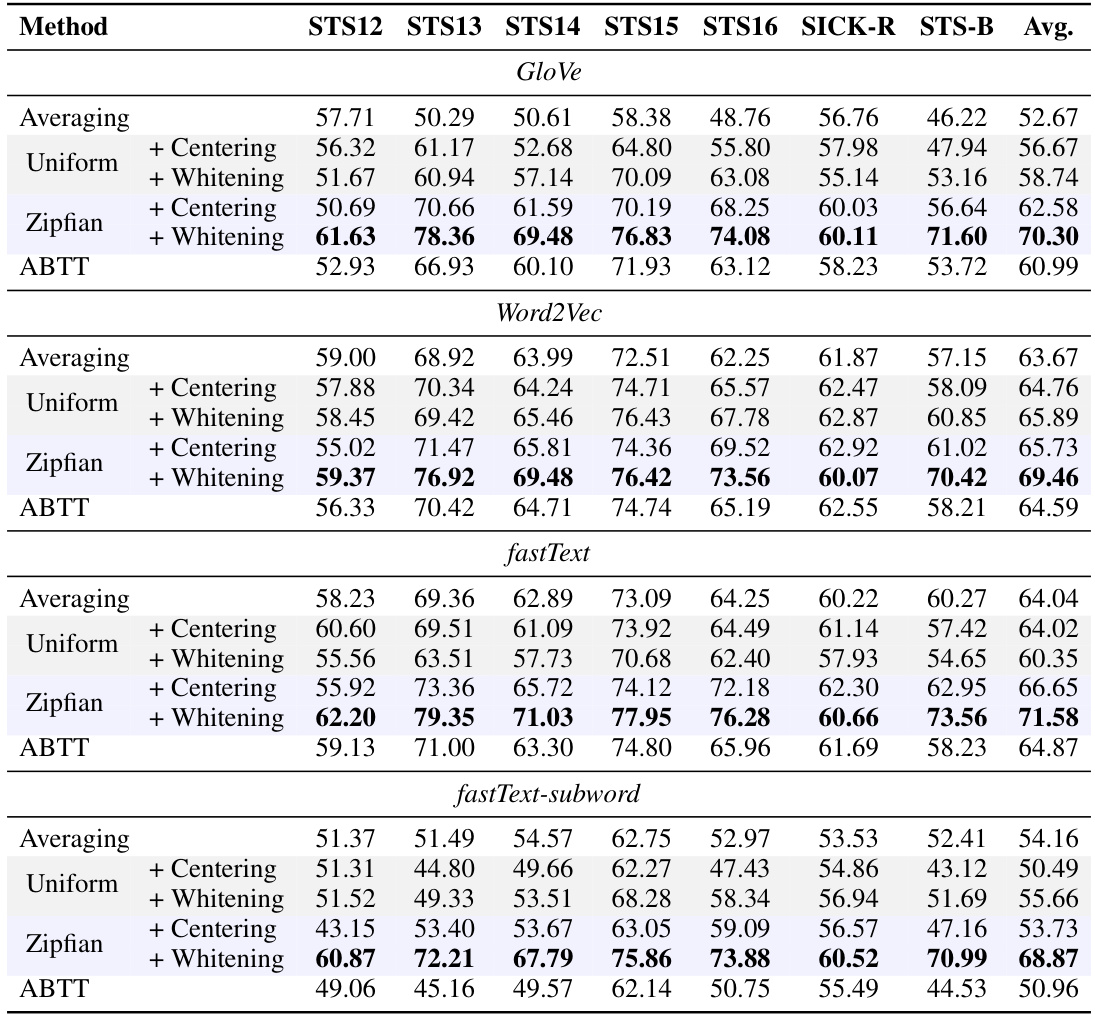
This table presents the results of applying Zipfian whitening to word embeddings on various sentence similarity tasks (STS). It compares the performance of Zipfian whitening against several baselines, including averaging, uniform centering and whitening, and ABTT (all-but-the-top). The empirical word frequency used is derived from the enwiki dataset. The table shows that across all models and tasks tested, Zipfian whitening consistently outperforms the other methods.
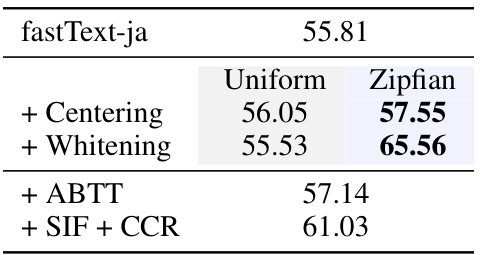
This table presents the results of experiments using Japanese fastText embeddings. It compares the performance of various methods (averaging, centering, whitening, ABTT, SIF+CCR) using both uniform and Zipfian whitening approaches on the Japanese Sentence Textual Similarity (JSTS) benchmark. The results demonstrate that Zipfian whitening consistently outperforms baseline methods in a multilingual setting.
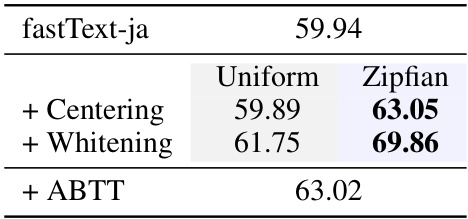
This table presents the results of the JSTS (Japanese Semantic Textual Similarity) benchmark using Japanese fastText word embeddings. The results are broken down by different preprocessing methods (averaging, centering, whitening, ABTT, and SIF+CCR) using both uniform and Zipfian whitening approaches. The table highlights that Zipfian whitening consistently achieves superior performance across all methods tested, demonstrating the effectiveness of this approach even in multilingual settings.
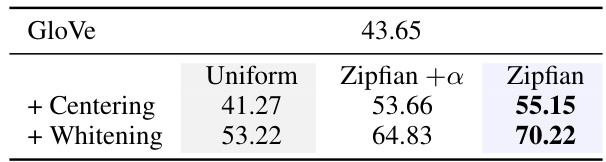
This table presents the results of an experiment comparing different methods for improving word embeddings. The core comparison is between uniform and Zipfian whitening, with an additional condition of applying uniform whitening first, followed by rescaling norms using Zipfian whitening. This experiment aimed to see the effect of solely applying Zipfian whitening versus applying uniform whitening followed by Zipfian norm rescaling.
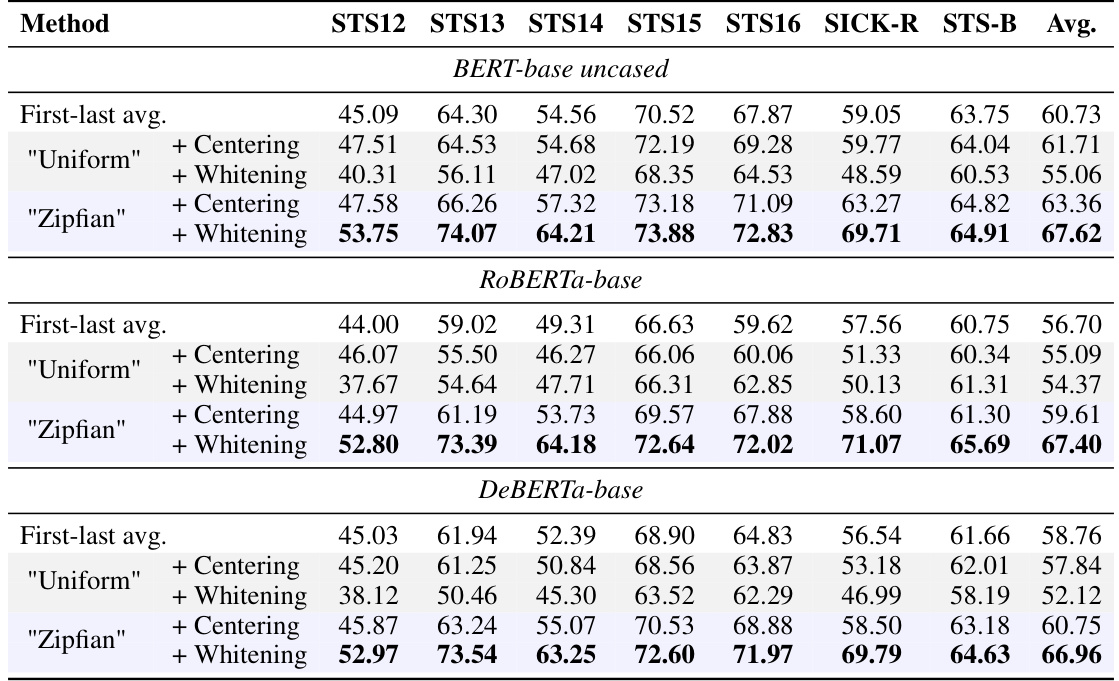
This table presents the results of applying uniform and Zipfian whitening methods to dynamic word embeddings on several sentence similarity tasks (STS). The results show that applying Zipfian whitening, which accounts for the non-uniform distribution of word frequencies (Zipf’s law), consistently leads to better performance than uniform whitening.
Full paper#