↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing membership inference attacks (MIAs) against large language models (LLMs) suffer from high false-positive rates and heavily rely on the overfitting of target models. These issues stem from the difficulty of obtaining suitable reference datasets and the unreliable nature of probability-based membership signals. Reference-based MIAs, while promising, often underperform due to the challenge of finding similar reference datasets to the training data.
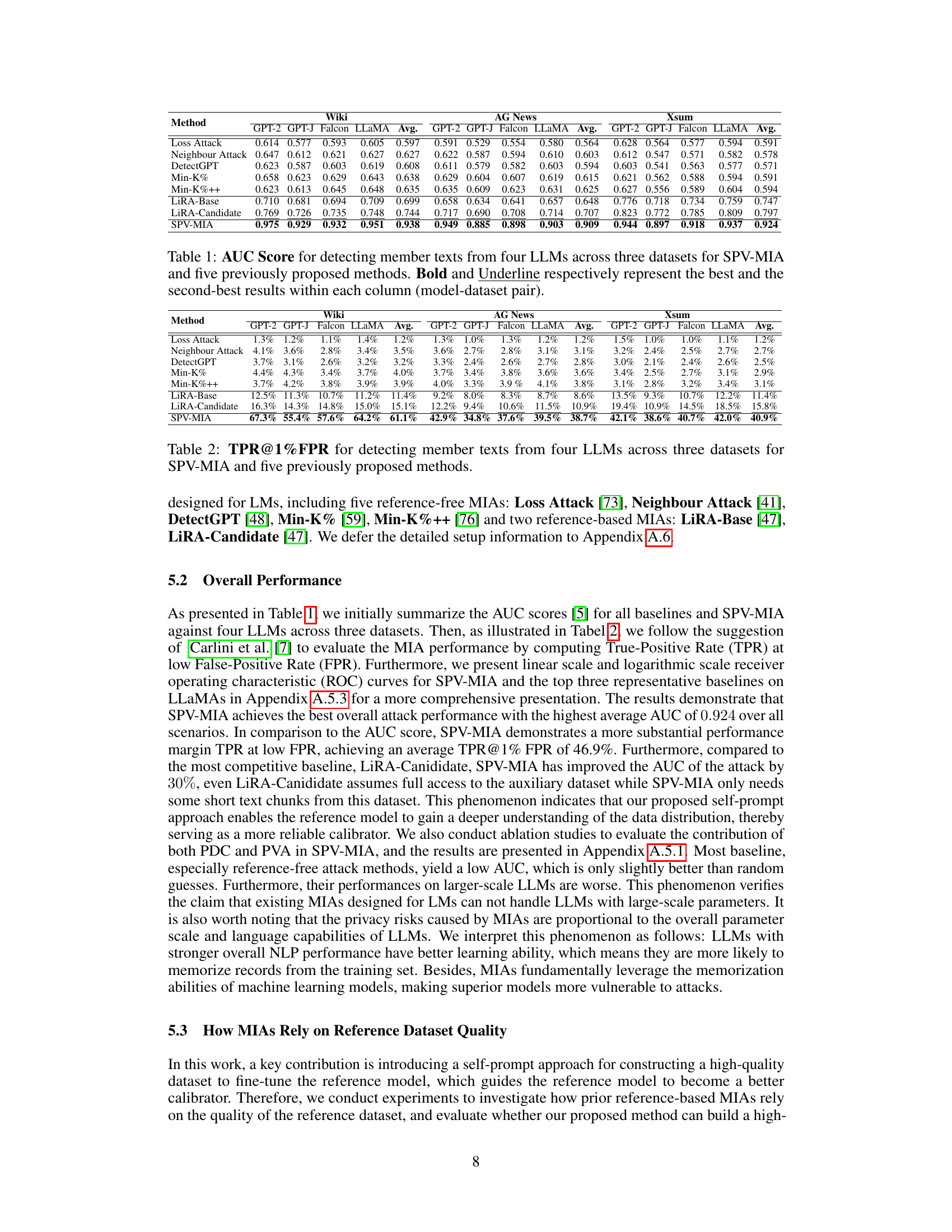
The proposed SPV-MIA addresses these limitations with a two-pronged approach. First, it introduces a self-prompt technique to generate reference datasets directly from the target LLM, eliminating the need for similar external datasets. Second, it utilizes a new probabilistic variation metric based on LLM memorization, which offers a more resilient and reliable membership signal than traditional probability-based approaches. Evaluations across multiple datasets and LLMs demonstrate SPV-MIA’s significantly improved accuracy, surpassing existing MIAs and showcasing its effectiveness in practical scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges existing assumptions in membership inference attacks (MIAs) against large language models (LLMs). By introducing a novel self-prompt calibration technique and focusing on memorization rather than overfitting, it opens new avenues for more effective and realistic privacy risk assessment in LLMs, directly impacting the field’s future research directions.
Visual Insights#
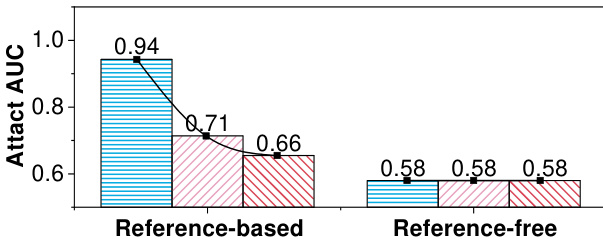
This figure compares the performance of reference-based and reference-free membership inference attacks (MIAs) against large language models (LLMs) under different conditions. It shows that existing MIAs perform poorly when the reference dataset is dissimilar to the training data or when the LLM is in the memorization phase rather than the overfitting phase. The figure highlights the limitations of existing MIAs in practical scenarios.
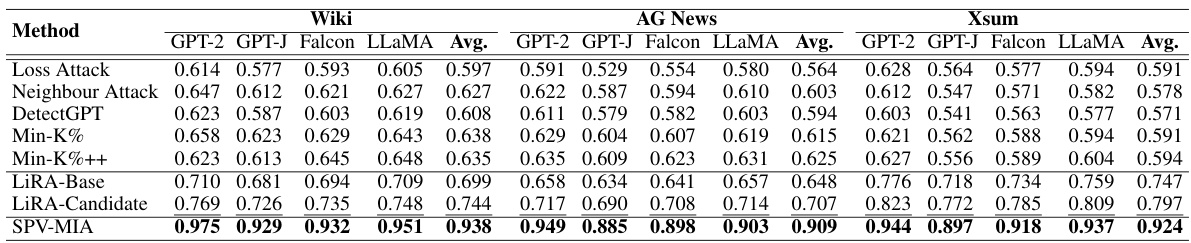
This table presents the Area Under the Curve (AUC) scores for a membership inference attack (MIA) called SPV-MIA and five other MIA methods. The AUC is a metric measuring the performance of the MIAs, with higher scores indicating better performance in distinguishing between data records used in the training dataset (member) and those not used (non-member). The results are broken down by four different Large Language Models (LLMs) and three distinct datasets, showing the AUC for each combination. Bold and underlined values highlight the best and second-best performing MIAs, respectively, for each LLM/dataset pair.
In-depth insights#
Self-Prompt Calibration#
Self-prompt calibration, in the context of membership inference attacks against large language models (LLMs), presents a novel approach to enhance attack efficacy. Instead of relying on external reference datasets, which may not accurately reflect the target model’s training data distribution, self-prompt calibration leverages the LLM itself to generate a synthetic reference dataset. This is achieved by prompting the target LLM to produce text samples, effectively creating a dataset with a distribution more closely aligned to its training data. This technique addresses a major limitation of previous methods, which often suffered from high false-positive rates due to the discrepancy between reference and training data. By using the LLM’s own generation capabilities to create the reference, self-prompt calibration improves the calibration process and increases the accuracy of membership inference. This strategy makes the attack more practical and less reliant on specific, potentially unavailable, datasets. The inherent creativity and fluency of LLMs are cleverly exploited to circumvent the challenges of obtaining suitable reference datasets. However, the reliance on the LLM’s output for calibration might also introduce bias if the LLM’s generation process itself exhibits systematic biases or limitations. Further research should explore the robustness of this technique against various LLM architectures and training methodologies.
Probabilistic Variation#
The concept of “Probabilistic Variation” in the context of a machine learning model, specifically a large language model (LLM), focuses on measuring the variability or uncertainty in the model’s predictions for a given input. It attempts to capture the model’s internal uncertainty rather than relying on simple probability scores, which can be misleading due to overfitting or data biases. By analyzing the variation or distribution of probabilities around a specific data point, this technique aims to identify local maxima in the probability distribution which may indicate a data record was memorized by the model during training (a key component of membership inference attacks). This contrasts with existing techniques that directly use prediction probabilities as membership signals which may suffer from high false positives due to factors not directly related to memorization. Therefore, probabilistic variation offers a more robust and reliable signal for determining data membership by focusing on the model’s internal confidence and inherent uncertainty, rather than on simply high or low probability output scores. This is particularly important given that the memorization phenomenon in LLMs tends to persist far beyond the point of overfitting. This approach provides a theoretical grounding and deeper understanding of data memorization within LLMs, offering a more sophisticated approach to membership inference attacks.
MIA on Fine-tuned LLMs#
Membership Inference Attacks (MIAs) on fine-tuned Large Language Models (LLMs) represent a significant privacy risk. Fine-tuning LLMs on private datasets makes them particularly vulnerable, as MIAs can leverage subtle patterns in the model’s output to infer whether specific data points were part of the training set. Existing MIAs, both reference-free and reference-based, often suffer from high false-positive rates and heavy reliance on overfitting. Self-prompt calibration offers a promising mitigation, enabling adversaries to obtain a dataset that better reflects the target model’s training data distribution without relying on access to the private training set. Probabilistic variation, measured via the second-order directional derivative of the probability distribution, provides a more reliable membership signal than simply relying on raw probabilities. Future research should explore how to further strengthen defenses against these advanced MIAs, and investigate the effectiveness of different privacy-preserving techniques in the context of LLM fine-tuning.
Limitations of Existing MIAs#
Existing membership inference attacks (MIAs) against Large Language Models (LLMs) suffer from critical limitations. Reference-based MIAs, while demonstrating high accuracy, heavily rely on the availability of a reference dataset closely matching the target model’s training data, which is unrealistic in practice. Reference-free MIAs, conversely, struggle to achieve high accuracy and often suffer from high false-positive rates. Both approaches are predicated on the hypothesis of consistent higher probabilities for training data, a notion weakened by regularization techniques and the generalization capabilities inherent in modern LLMs. This dependence on overfitting as a membership signal is a major weakness, as LLMs often exhibit memorization effects early in training, before overfitting occurs. Addressing these limitations requires a more robust approach focusing on inherent characteristics of LLMs that don’t depend solely on overfitting, and methods to generate suitable reference datasets without relying on access to private training data.
Future Research#
Future research directions stemming from this paper on membership inference attacks against fine-tuned LLMs could explore more sophisticated methods for generating high-quality reference datasets using self-prompting techniques. This includes investigating different prompting strategies, text lengths, and data sources to enhance the reliability and effectiveness of the attack. Another avenue is improving the robustness of the probabilistic variation metric to handle scenarios with diverse data distributions and noisy or incomplete information. The theoretical underpinnings of LLM memorization require deeper investigation to develop more accurate and reliable membership signal detection mechanisms. Finally, exploring defensive strategies, such as differential privacy techniques or model architectures less susceptible to these attacks, will be crucial to mitigating the privacy risks highlighted in the paper. Investigating the effects of various fine-tuning methods on the success of the attacks will also provide a valuable contribution.
More visual insights#
More on figures
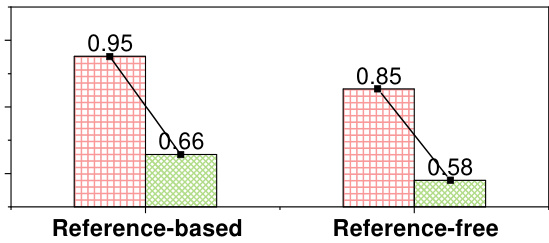
This figure shows the poor performance of existing membership inference attacks (MIAs) against large language models (LLMs), especially when the LLM is in the memorization phase and only a domain-specific reference dataset is available. The left subplot (a) demonstrates how reference-based MIAs significantly underperform when the reference dataset differs from the training data, while the right subplot (b) shows that both reference-based and reference-free MIAs fail to detect privacy leaks during the memorization phase, which typically precedes overfitting.
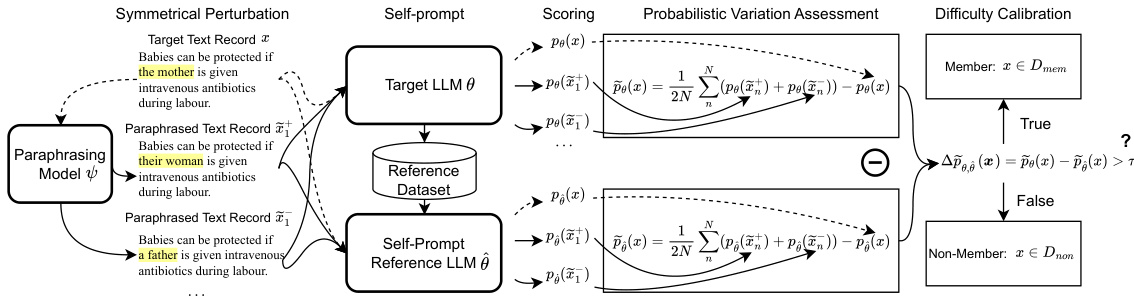
This figure illustrates the workflow of the Self-calibrated Probabilistic Variation Membership Inference Attack (SPV-MIA). It shows how a target LLM is prompted to generate a reference dataset, which is then used to train a reference LLM. The target LLM and reference LLM are used to calculate the probabilistic variation of a target text record. The probabilistic variation, along with a difficulty calibration step, is used to determine if the text record was part of the target LLM’s training data. The figure visually represents the two main components of the attack: self-prompt calibration and probabilistic variation assessment, highlighting their roles in determining membership.
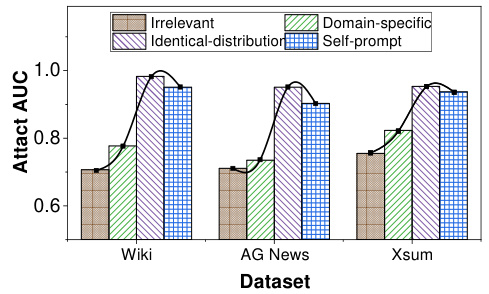
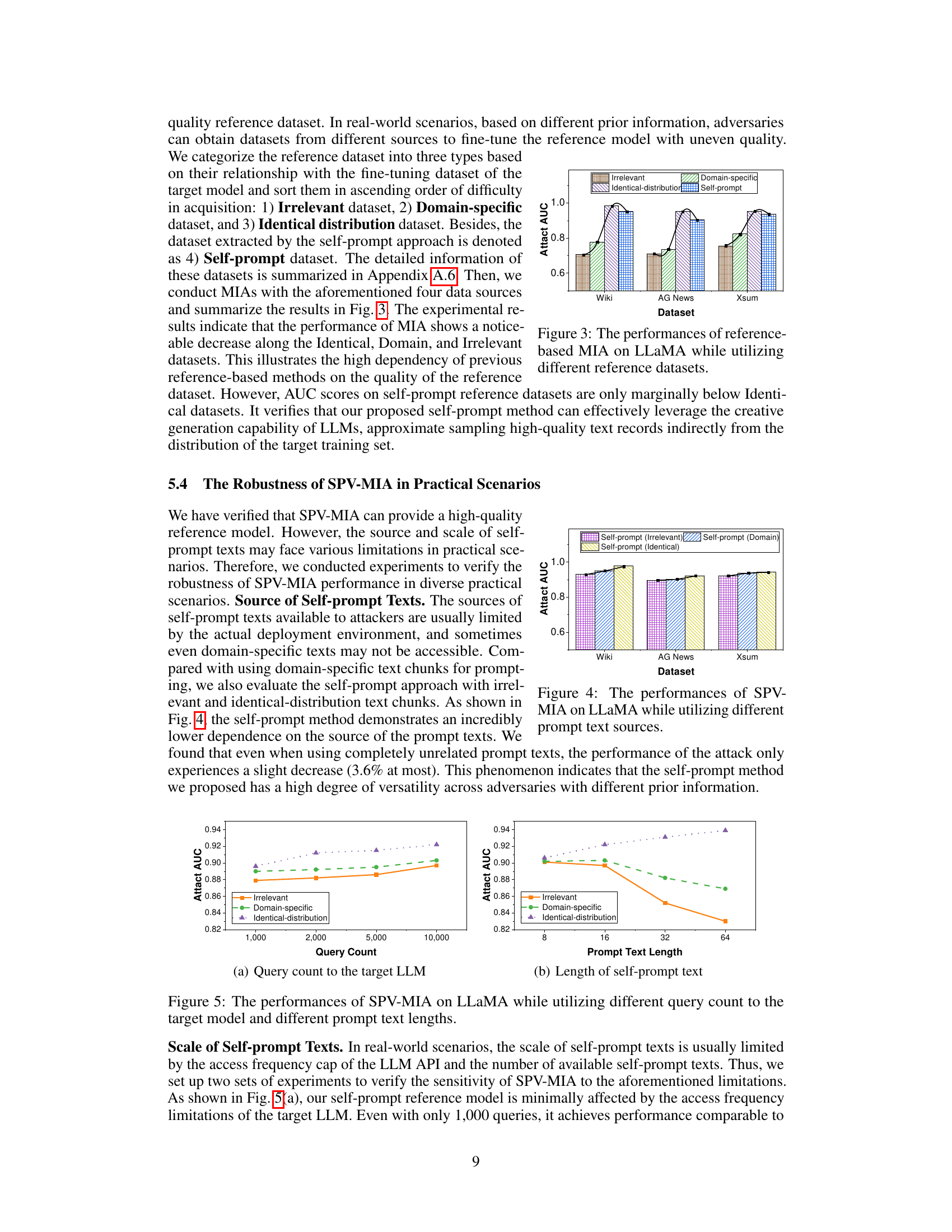
This figure shows the Area Under the Curve (AUC) of the Likelihood Ratio Attack (LiRA), a membership inference attack, on the LLaMA large language model. The AUC is shown for four different types of reference datasets: identical-distribution, domain-specific, irrelevant, and self-prompt. The x-axis represents three different datasets (Wiki, AG News, XSum) used for fine-tuning the LLaMA model. The y-axis represents the AUC score, which ranges from 0.6 to 1.0 and indicates the attack’s performance. The figure illustrates that LiRA’s performance drops drastically as the similarity between the reference and training datasets decreases. However, the self-prompt method shows relatively high AUC scores, indicating that the self-generated reference data successfully resembles the training data distribution.
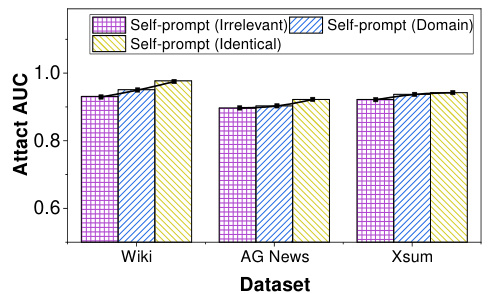
This figure shows the performance of reference-based Membership Inference Attacks (MIAs) on the LLaMA large language model when using reference datasets of varying similarity to the training data. It illustrates how the attack performance degrades as the similarity between the reference and training datasets decreases. The datasets used are categorized as Identical-distribution, Domain-specific, Irrelevant, and Self-prompt. The Self-prompt dataset demonstrates that the proposed self-prompt approach can generate a high-quality reference dataset even when the exact training data is not available, reducing the dependence of the MIA on reference dataset quality.

The figure shows the AUC scores of the reference-based MIA (LiRA) on the LLaMA model using four different types of reference datasets: identical-distribution, domain-specific, irrelevant, and self-prompt. The results demonstrate that the performance of LiRA decreases as the similarity between the reference dataset and the training dataset decreases. However, the self-prompt approach achieves comparable performance to the identical-distribution dataset, indicating its ability to generate high-quality reference datasets.
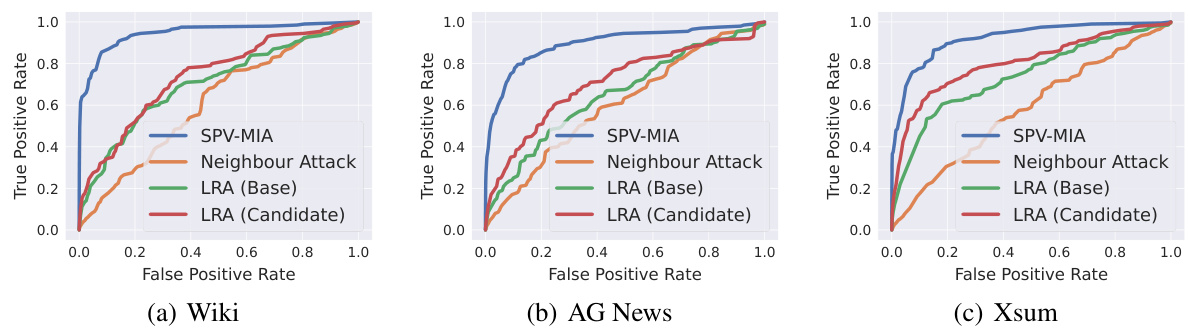
This figure shows the Receiver Operating Characteristic (ROC) curves for several membership inference attack (MIA) methods on three different datasets. The linear scale on the y-axis emphasizes the performance differences, particularly at lower false positive rates. SPV-MIA consistently outperforms the other methods across all three datasets. The results visually support the claim made in the paper that SPV-MIA significantly improves the AUC of MIAs.

This figure shows the receiver operating characteristic (ROC) curves for SPV-MIA and three other membership inference attack methods (Neighbour Attack, LiRA (Base), and LiRA (Candidate)). The ROC curves illustrate the performance of each method across three different datasets (Wiki, AG News, and Xsum). The x-axis represents the false positive rate, and the y-axis represents the true positive rate. The curves visually compare the trade-off between true positives and false positives for each method across different datasets.
More on tables

This table presents the Area Under the Curve (AUC) scores achieved by seven different membership inference attack (MIA) methods on four different large language models (LLMs) across three distinct datasets. The AUC score reflects the performance of each MIA method in correctly identifying whether a data point was part of the training dataset for a given LLM. The table highlights the superior performance of the proposed SPV-MIA method compared to existing techniques.
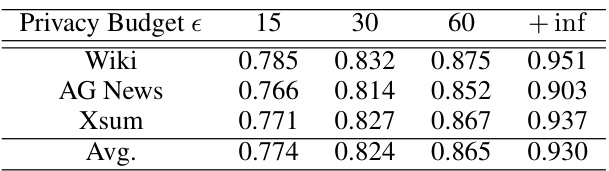
This table shows the AUC (Area Under the Curve) scores achieved by the SPV-MIA attack against the LLaMA language model. The LLaMA model was fine-tuned using DP-SGD (Differentially Private Stochastic Gradient Descent) with varying privacy budgets (epsilon). The AUC represents the performance of the attack at different levels of privacy protection. Higher AUC values indicate a more successful attack, while lower values indicate a less successful attack, suggesting better privacy protection.

This table shows the Area Under the Curve (AUC) scores achieved by the Self-calibrated Probabilistic Variation Membership Inference Attack (SPV-MIA) when using different Parameter-Efficient Fine-Tuning (PEFT) techniques on three different datasets (Wiki, AG News, and XSum). It compares the performance across four PEFT methods: LoRA, Prefix Tuning, P-Tuning, and (IA)³, highlighting the impact of the number of trainable parameters on the attack’s effectiveness.
This table presents the Area Under the Curve (AUC) scores for several membership inference attack (MIA) methods, including the proposed SPV-MIA, on four different Large Language Models (LLMs) and three datasets. The AUC score measures the ability of each MIA to distinguish between data records that were and were not part of the LLM’s training data. Bold and underlined entries highlight the best and second-best performing methods for each LLM-dataset combination.
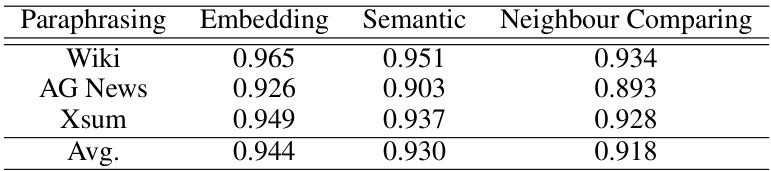
This table presents the performance of the SPV-MIA attack using different paraphrasing methods (embedding, semantic, and neighbour comparing). The results are broken down by dataset (Wiki, AG News, Xsum) and show the average AUC score across all three datasets. The table helps to evaluate the effectiveness of different paraphrasing techniques in improving the performance of the membership inference attack.

This table presents the results of an ablation study conducted to evaluate the individual contributions of the two modules proposed in the SPV-MIA model: Practical Difficulty Calibration (PDC) and Probabilistic Variation Assessment (PVA). The study compares the Area Under the Curve (AUC) scores achieved by the full SPV-MIA model against versions that exclude either PDC or PVA. Results are shown for two different LLMs (GPT-J and LLaMA) and three datasets (Wiki, AG News, XSum). This allows for assessment of the relative importance of each module in achieving the overall performance improvement.

This table presents the Area Under the Curve (AUC) scores achieved by several membership inference attack (MIA) methods, including the proposed SPV-MIA, when applied to four different large language models (LLMs) across three different datasets. The AUC score is a metric measuring the performance of the MIAs in distinguishing between data records that were part of the training dataset and those that weren’t. Higher AUC scores indicate better performance. The table highlights the superior performance of SPV-MIA compared to the existing MIAs.

This table shows the perplexity (PPL) scores for four different large language models (LLMs) fine-tuned on three different datasets. Perplexity is a measure of how well a probability model predicts a sample. Lower perplexity indicates better performance. The table is divided into training and test set perplexities for each LLM and dataset combination.

This table shows the perplexity scores achieved by four different LLMs (GPT-2, GPT-J, Falcon, and LLaMA) when fine-tuned on three datasets (Wiki, AG News, and XSum) under varying privacy budget levels (15, 30, 60, and +inf). Lower perplexity scores indicate better model performance. The table allows for comparison of model performance across different LLMs and datasets while highlighting the effect of differential privacy on model perplexity.
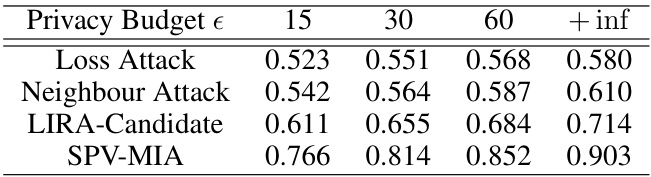
This table shows the Area Under the Curve (AUC) scores for the SPV-MIA attack against the LLaMA language model. The LLaMA model was fine-tuned using differentially private stochastic gradient descent (DP-SGD) with varying privacy budgets (epsilon). The AUC scores indicate the attack’s performance at distinguishing between data points that were and were not part of the training set. Higher AUC scores represent better attack performance, and the results show how the attack’s effectiveness changes depending on the level of privacy protection applied during fine-tuning.

This table presents the Area Under the Curve (AUC) scores achieved by seven different membership inference attack (MIA) methods on four different large language models (LLMs) across three distinct datasets. SPV-MIA is compared to five existing MIA techniques. The AUC score reflects the ability of each method to correctly identify whether a data record was used in the training of the LLM. Bold and underlined values highlight the best and second-best performing methods in each column.
Full paper#