↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current language-image pre-training models underperform with long texts, mainly because they are trained primarily on short captions, making certain tokens get overshadowed. This overshadowing makes it difficult for the models to fully comprehend longer, more detailed descriptions associated with images.
LoTLIP directly addresses this issue by using a massive dataset (100M images) with long captions during pre-training. The model further incorporates ‘corner tokens’ to improve the aggregation of text information. This results in a significant improvement in long-text understanding without compromising performance on short-text tasks. Experiments show that LoTLIP achieves state-of-the-art results in long-text image retrieval, surpassing existing methods by a significant margin.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical challenge of enabling language-image pre-training models to effectively understand long texts, a limitation that hinders many real-world applications. The proposed method, LoTLIP, significantly advances the field by achieving state-of-the-art results in long-text image retrieval while maintaining strong performance in short-text tasks. This opens new avenues for research in multi-modal learning and has broad implications across various applications.
Visual Insights#
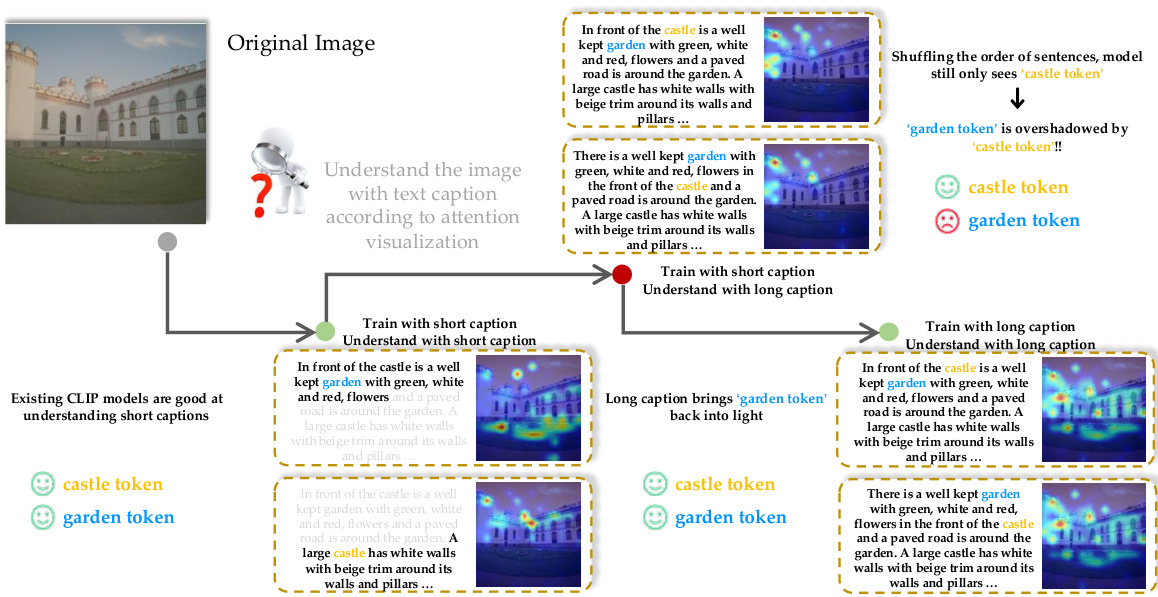
🔼 This figure illustrates how the length of training captions affects the attention mechanism in CLIP (Contrastive Language-Image Pre-training) models. When trained with short captions, the model focuses primarily on salient tokens (like ‘castle’), overshadowing less prominent but still relevant tokens (like ‘garden’). The cross-attention maps visualize this effect. However, when trained with long captions, the model’s attention distributes more evenly, incorporating the previously overshadowed tokens into the overall understanding of the image. This highlights the importance of long captions in enabling more comprehensive image-text representation learning.
read the caption
Figure 1: Illustration of the impacts of long v.s. short captions on image-language pre-training, as observed in the cross-attention maps of CLIP. Training images are usually paired with short captions, leaving certain tokens (e.g., garden token) easily overshadowed by salient tokens (e.g., castle token).
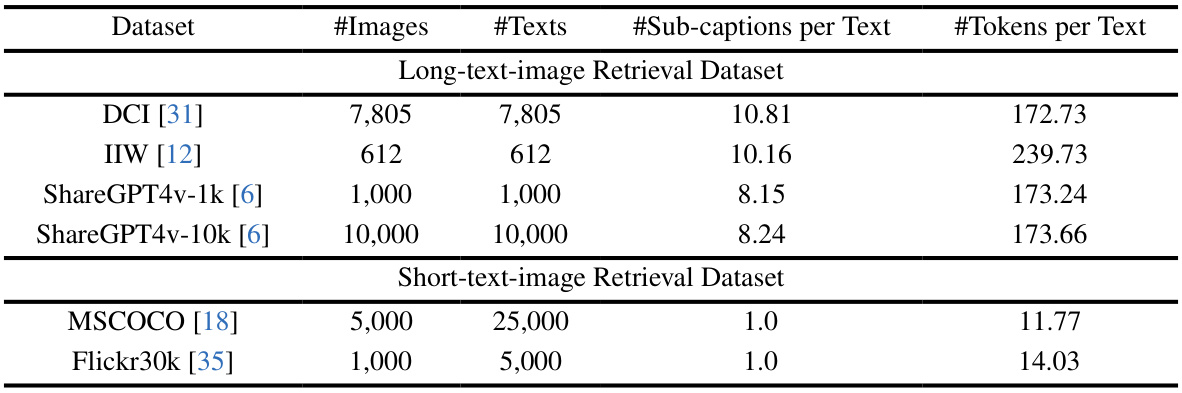
🔼 This table presents the details of datasets used for both long-text and short-text image retrieval tasks. It shows the number of images and texts, the average number of sub-captions per text, and the average number of tokens per text for each dataset. The datasets are categorized into long-text and short-text datasets, highlighting the differences in text length used for training and evaluation. The tokenizer used is BERT.
read the caption
Table 1: Dataset details of long-text-image retrieval and short-text-image retrieval tasks. We use BERT tokenizer for tokenization. ShareGPT4V-1k and 10k are selected from the ShareGPT4V dataset. For DCI and IIW, all images with human-authored long descriptions are used while evaluating.
In-depth insights#
Long-Text LIP#
The concept of “Long-Text LIP” (Language-Image Pre-training) addresses a critical limitation in current multi-modal models: their inability to effectively process and understand long text descriptions paired with images. Existing LIP models predominantly rely on short captions, hindering their capacity to capture nuanced details and complex relationships within lengthy text. This limitation directly impacts applications requiring thorough text understanding, such as detailed image retrieval or generation. A “Long-Text LIP” approach aims to overcome this by utilizing datasets with longer captions during pre-training, thereby enhancing the model’s ability to handle longer texts. However, simply using longer captions can negatively affect performance on short-text tasks. Therefore, sophisticated methods, such as integrating “corner tokens” for feature aggregation, are needed to balance performance across both long and short text comprehension. This focus on long-text handling represents a significant advancement in multi-modal understanding, opening doors to more powerful and versatile applications.
Corner Token#
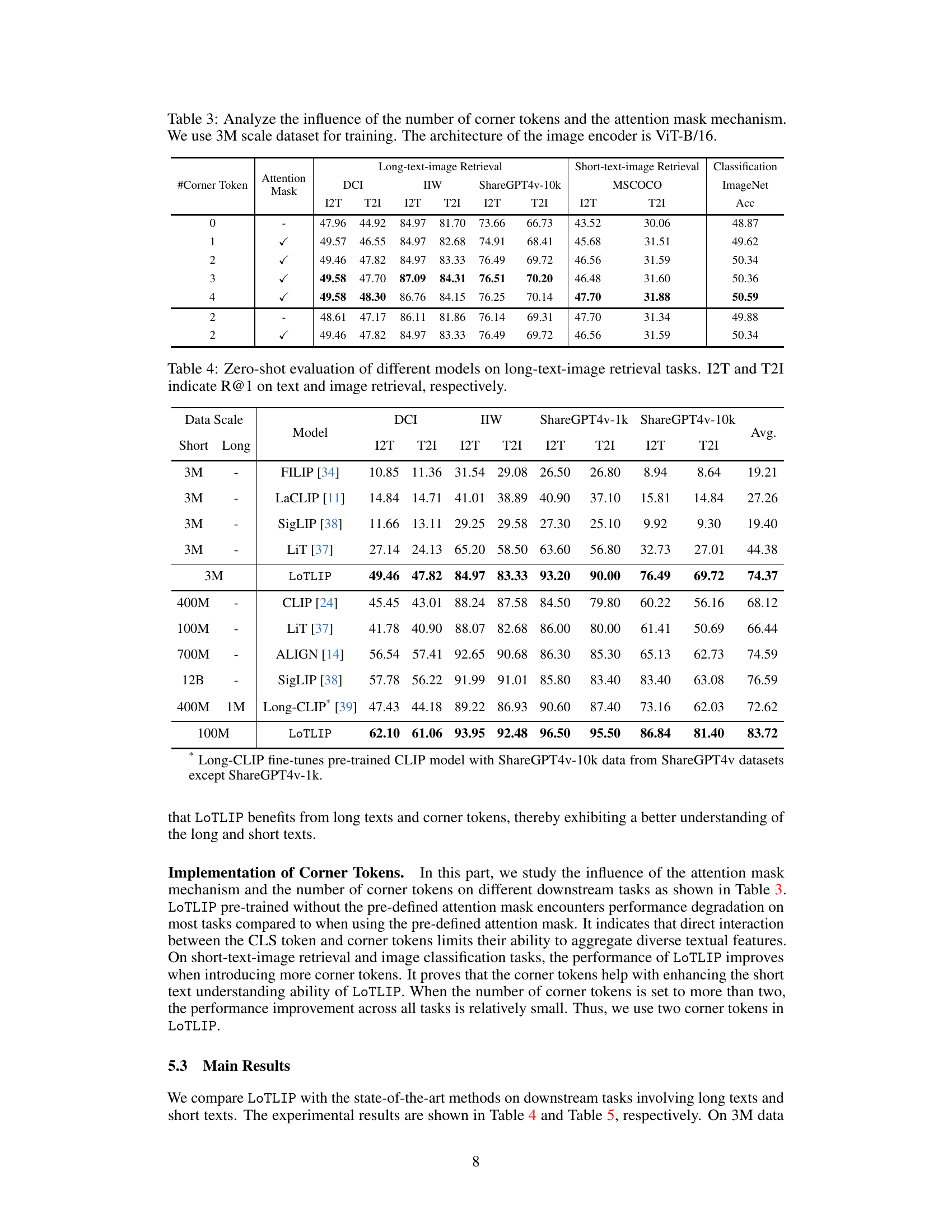
The concept of “Corner Tokens” introduced in the research paper presents a novel approach to enhance the capabilities of language-image pre-training models, particularly in handling long texts. The core idea revolves around strategically placing these learnable tokens within the text encoder architecture, specifically after the [CLS] token. This placement is crucial, as it allows the corner tokens to act as aggregators of diverse textual information. Unlike standard tokens representing individual words, corner tokens aim to capture global contextual cues, improving the model’s ability to interpret complex relationships between words and phrases within long captions. Their effect is particularly pronounced in resolving the issue of salient tokens overshadowing less prominent ones in longer sequences. By incorporating an attention mask mechanism, the researchers further refine the process, ensuring that corner tokens focus on capturing holistic context rather than competing with individual tokens for attention. This method ultimately strikes a balance between improving the model’s long-text understanding and maintaining its performance on short-text tasks. The effectiveness of corner tokens highlights their potential as a valuable enhancement to existing pre-training techniques, suggesting a more nuanced approach to information integration within multimodal models.
Text Length Impact#
The analysis of text length impact reveals a complex interplay between model performance and caption length. While longer captions intuitively offer richer contextual information, directly using them in pre-training leads to performance degradation on short-text tasks. This suggests that models trained solely on long captions struggle to generalize to shorter inputs. The optimal approach, therefore, involves a careful balance. Incorporating strategically selected long captions, perhaps through techniques like aggregating diverse textual information with corner tokens, appears crucial to simultaneously enhance long-text understanding and maintain proficiency on short-text tasks. This highlights the critical need for dataset diversity in language-image pre-training and suggests future research should explore more sophisticated strategies for integrating captions of various lengths effectively.
Ablation Study#
An ablation study systematically removes components of a model or system to determine their individual contribution. In the context of a research paper, this involves assessing the impact of specific design choices or features. A well-designed ablation study helps establish causality, not just correlation, by isolating the effect of each component. This process is crucial for understanding why a model works, which parts are most important, and where improvements can be made. The findings are critical for evaluating the model’s robustness and generalizability, as removing components should reveal degradation proportional to their importance. Furthermore, a well-executed ablation study increases the overall transparency and reproducibility of the research, making it easier for others to validate findings and build upon the work. However, ablation studies need careful planning and execution, ensuring that the removal of components is done methodically, minimizing confounds that might distort the results.
Future Work#
Future work in this research could explore several promising avenues. Extending the dataset to include even more diverse and higher-quality long captions is crucial; the current 100M image-text pairs, while substantial, still represent a sample of the vast available data. Investigating alternative text encoder architectures beyond BERT could potentially improve efficiency and long-text handling. A deeper analysis of the trade-off between caption length and model performance is also warranted; the observed plateau might indicate an optimal length beyond which marginal gains diminish. Finally, exploring the application of LoTLIP to downstream tasks beyond image retrieval is key to demonstrating its broader usefulness. This could encompass tasks like image captioning, visual question answering, and more complex multimodal reasoning scenarios, highlighting the model’s potential for versatility and impact across a range of applications.
More visual insights#
More on figures
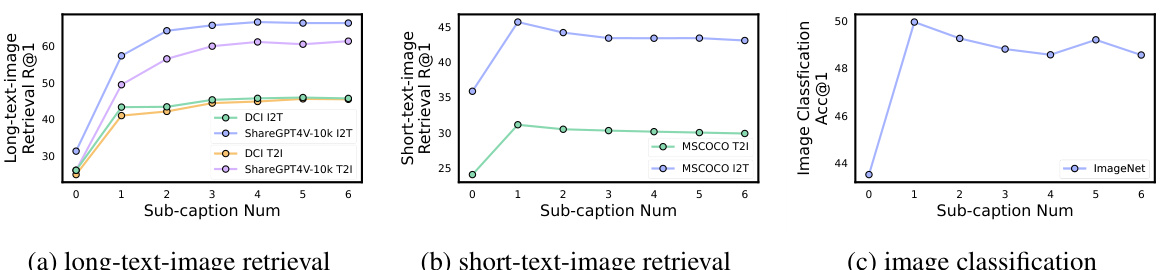
🔼 This figure shows the impact of increasing the length of text captions used during the pre-training phase of a language-image model. The experiment varied the number of sub-captions added to the training data. The results show that adding even one sub-caption leads to significant improvements in long-text image retrieval tasks, and performance continues to improve with additional sub-captions, until it plateaus. However, this improvement comes at the cost of decreased performance on short-text image retrieval (using the MSCOCO dataset) and image classification (using the ImageNet dataset). This indicates a trade-off between the model’s ability to handle long and short texts.
read the caption
Figure 2: The influence of text length. A significant improvement is observed across all tasks when we added one randomly sampled sub-caption from generated texts to the pre-training stage. As the number of sub-captions increases, the performance of the pre-trained model on long-text-image retrieval tasks consistently improves and becomes stable (a). However, there is a performance degradation in MSCOCO retrieval task (b) and ImageNet classification task (c).
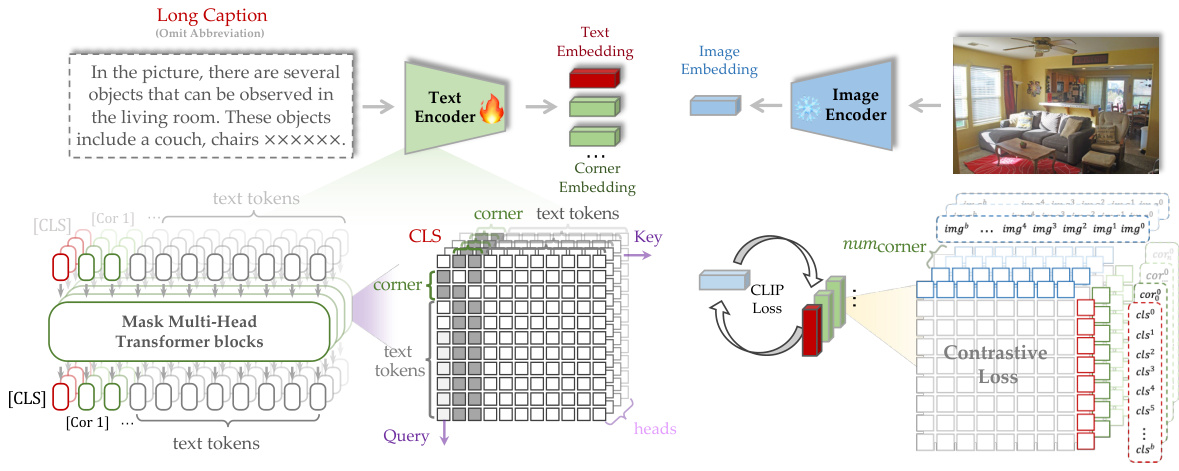
🔼 This figure illustrates the architecture of the proposed LoTLIP model. It highlights the addition of multiple learnable corner tokens after the [CLS] token in the text encoder. These corner tokens are designed to aggregate diverse textual information from different parts of the long caption. A mask mechanism is also employed to control the attention mechanism, preventing the corner tokens from dominating the attention and ensuring a balanced representation of all textual information. This approach helps to improve the model’s ability to understand both short and long texts.
read the caption
Figure 3: Overview of LoTLIP. We add multiple learnable corner tokens ([Cor 1], [Cor 2],.………) after [CLS] token. These corner tokens are initialized differently for aggregating diverse token features. Besides, an attention mask mechanism is used to limit the interaction between [CLS] and corner tokens to ensure the diversity of gathered features.
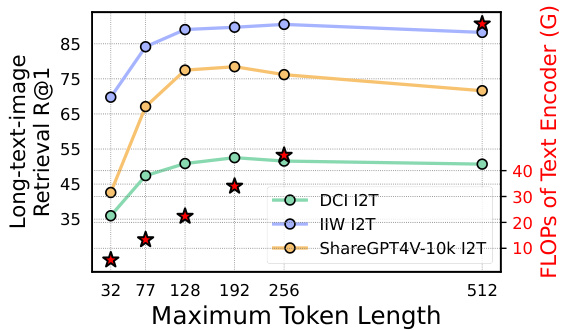
🔼 This figure shows the impact of adjusting the maximum token length in the text encoder on the LoTLIP model’s performance across different tasks (long-text-image retrieval on three datasets: DCI, IIW, ShareGPT4V-10k). It demonstrates that increasing the token limit up to 192 significantly enhances the model’s performance on these tasks; exceeding the standard limit of 77 tokens. However, further increasing the token limit beyond 192 yields diminishing returns. Concurrently, the figure also displays the computational cost (FLOPs of the text encoder) which increases proportionally with the maximum token length.
read the caption
Figure 4: Influence of token number limitation on LoTLIP. The performance of the pre-trained model on different tasks improves when the token number limitation increases up to 192, which exceeds the commonly used 77. Meanwhile, the FLOPs of the text encoder (red stars) rapidly increase with the text token number limitation.
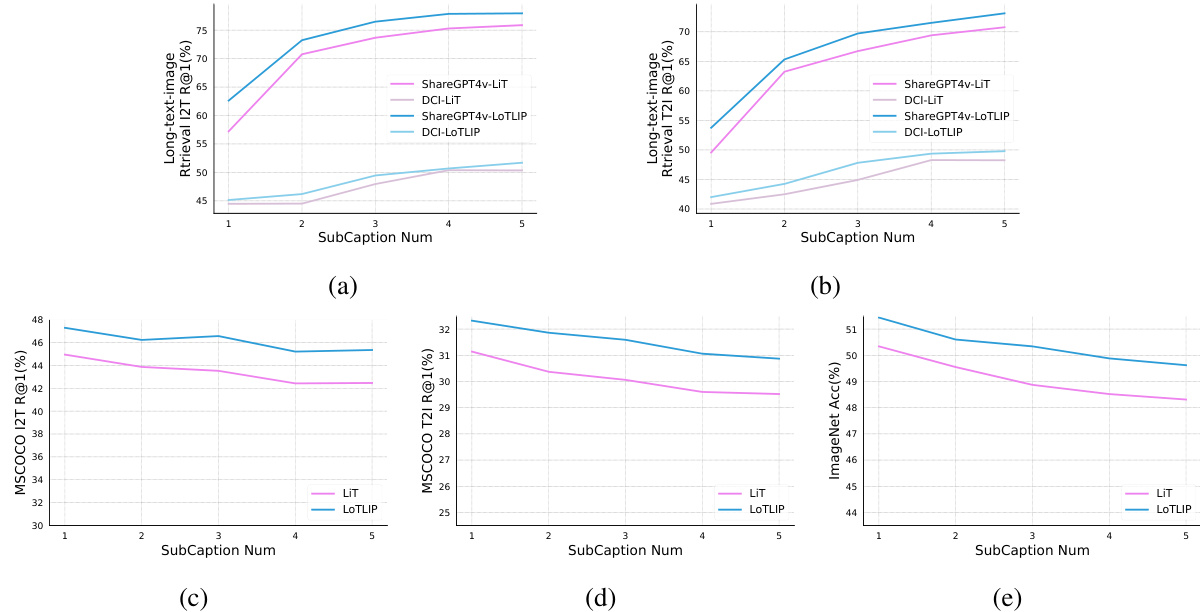
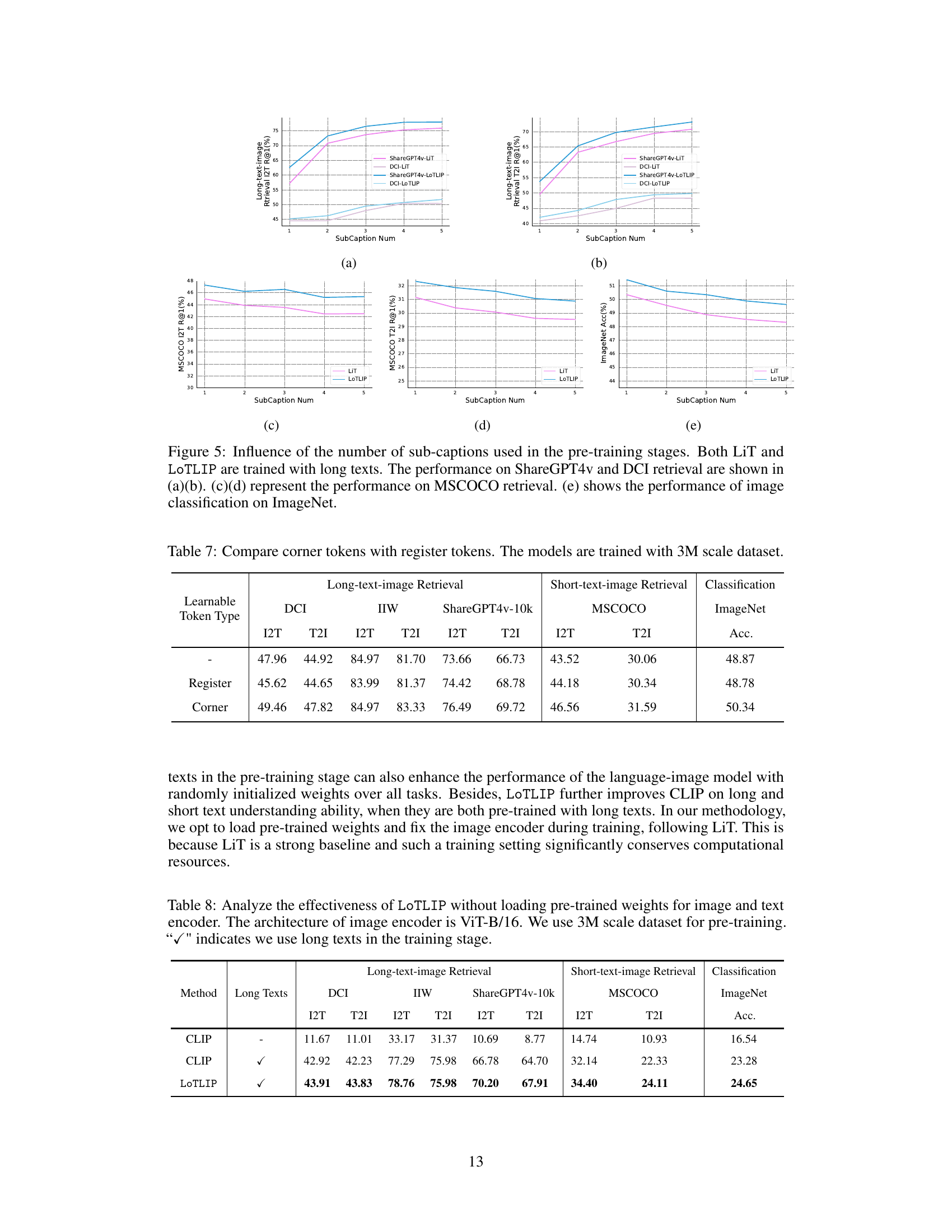
🔼 This figure analyzes the impact of varying the number of sub-captions used during the pre-training phase on the performance of both LiT and LoTLIP models, which were trained using long texts. The results are shown across five different evaluation tasks: ShareGPT4V retrieval (I2T and T2I), DCI retrieval (I2T and T2I), MSCOCO retrieval (I2T and T2I), and ImageNet classification. The x-axis represents the number of sub-captions, and the y-axis shows the performance metric for each task (R@1 for retrieval and accuracy for classification). This visualization helps to understand how increasing the length of training text influences the models’ performance on various downstream tasks. It reveals the optimal length for balancing performance across long and short text understanding tasks.
read the caption
Figure 5: Influence of the number of sub-captions used in the pre-training stages. Both LiT and LoTLIP are trained with long texts. The performance on ShareGPT4v and DCI retrieval are shown in (a)(b). (c)(d) represent the performance on MSCOCO retrieval. (e) shows the performance of image classification on ImageNet.

🔼 This figure visualizes the attention maps generated by four different models: LiT (baseline), LiT trained with long texts, Long-CLIP, and LoTLIP. Two example images with their corresponding long captions are shown. Each model’s attention map is displayed alongside the image, highlighting the regions of the image that the model focuses on when processing the caption. The figure demonstrates that LoTLIP, which uses both long texts and corner tokens during training, produces attention maps that are more accurately aligned with the relevant parts of the image described in the long captions, compared to the other models. This highlights the effectiveness of LoTLIP’s approach in improving long-text understanding in language-image models.
read the caption
Figure 6: Visualize the attention map of LiT, LiT trained with long texts (LiT+Long Texts), Long-CLIP, and LoTLIP. Here, both Long-CLIP (our implementation) and LoTLIP are trained with long texts. Benefiting from long texts and corner tokens, the highlighted image regions of LoTLIP are better aligned with the given long caption compared to other methods.
More on tables
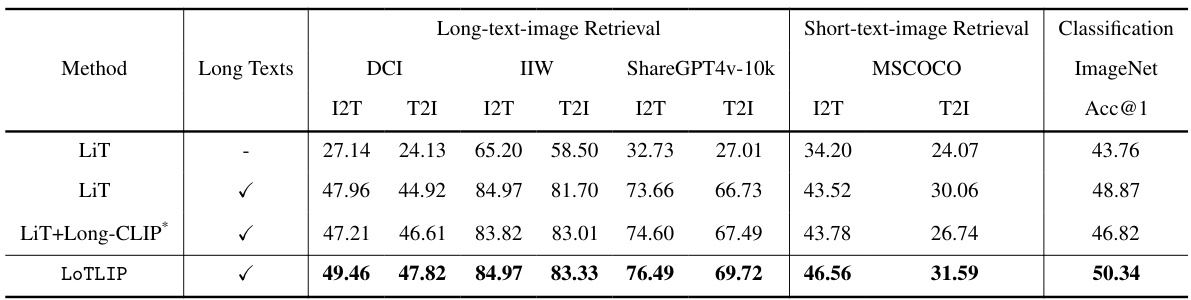
🔼 This table compares the performance of different models on image and text retrieval and image classification tasks. The models are trained with and without long texts. The impact of adding long texts to the pre-training stage on different metrics (I2T and T2I R@1) is evaluated across three different datasets (DCI, IIW, and ShareGPT4v-10k). The results show that using long texts in training improves performance in these tasks, particularly in retrieval tasks, demonstrating the effectiveness of LoTLIP, particularly when compared to other models with and without long texts in their training.
read the caption
Table 2: Analyze the effectiveness of LoTLIP in language-image pre-training with long texts. The architecture of the image encoder is ViT-B/16. I2T and T2I indicate R@1 on text and image retrieval, respectively. We use 3M scale dataset for pre-training. “✓” indicates we add long texts in the training stage.
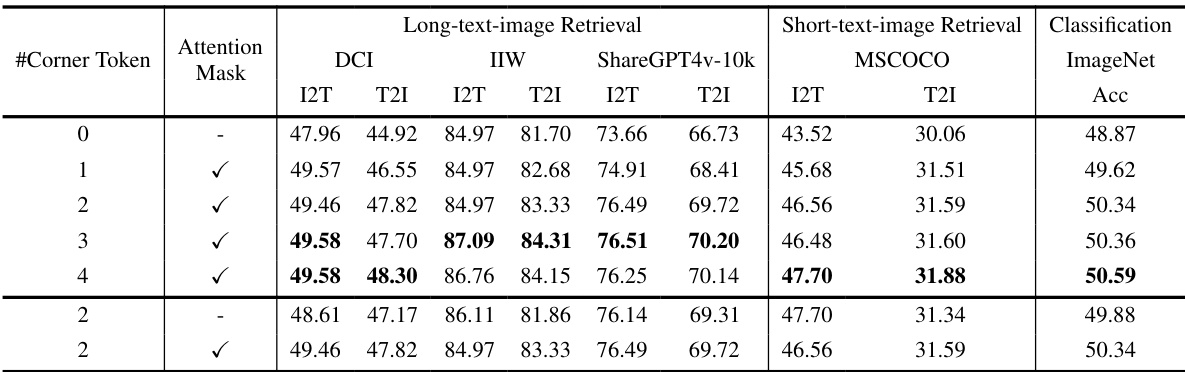
🔼 This table presents an ablation study on the impact of the number of corner tokens and the attention mask mechanism used in the LoTLIP model. It shows the performance of the model on various tasks (long-text-image retrieval, short-text-image retrieval, and image classification) with different configurations of corner tokens and the attention mask. The experiment uses a 3M scale dataset for training, and the image encoder is a ViT-B/16 architecture.
read the caption
Table 3: Analyze the influence of the number of corner tokens and the attention mask mechanism. We use 3M scale dataset for training. The architecture of the image encoder is ViT-B/16.
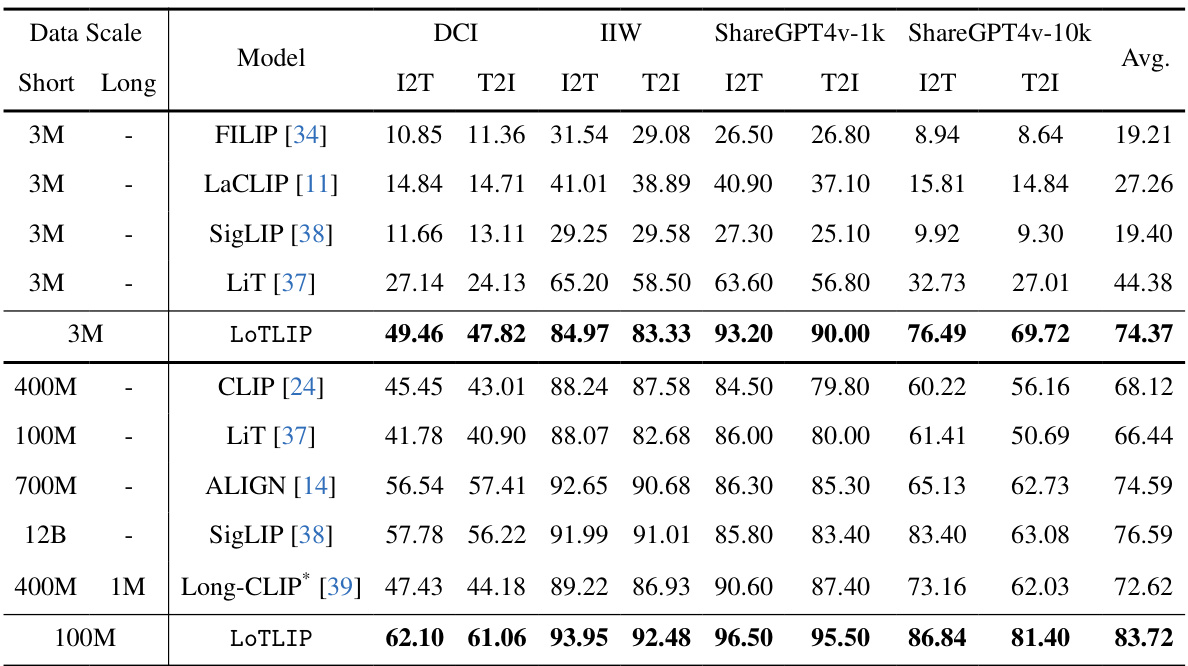
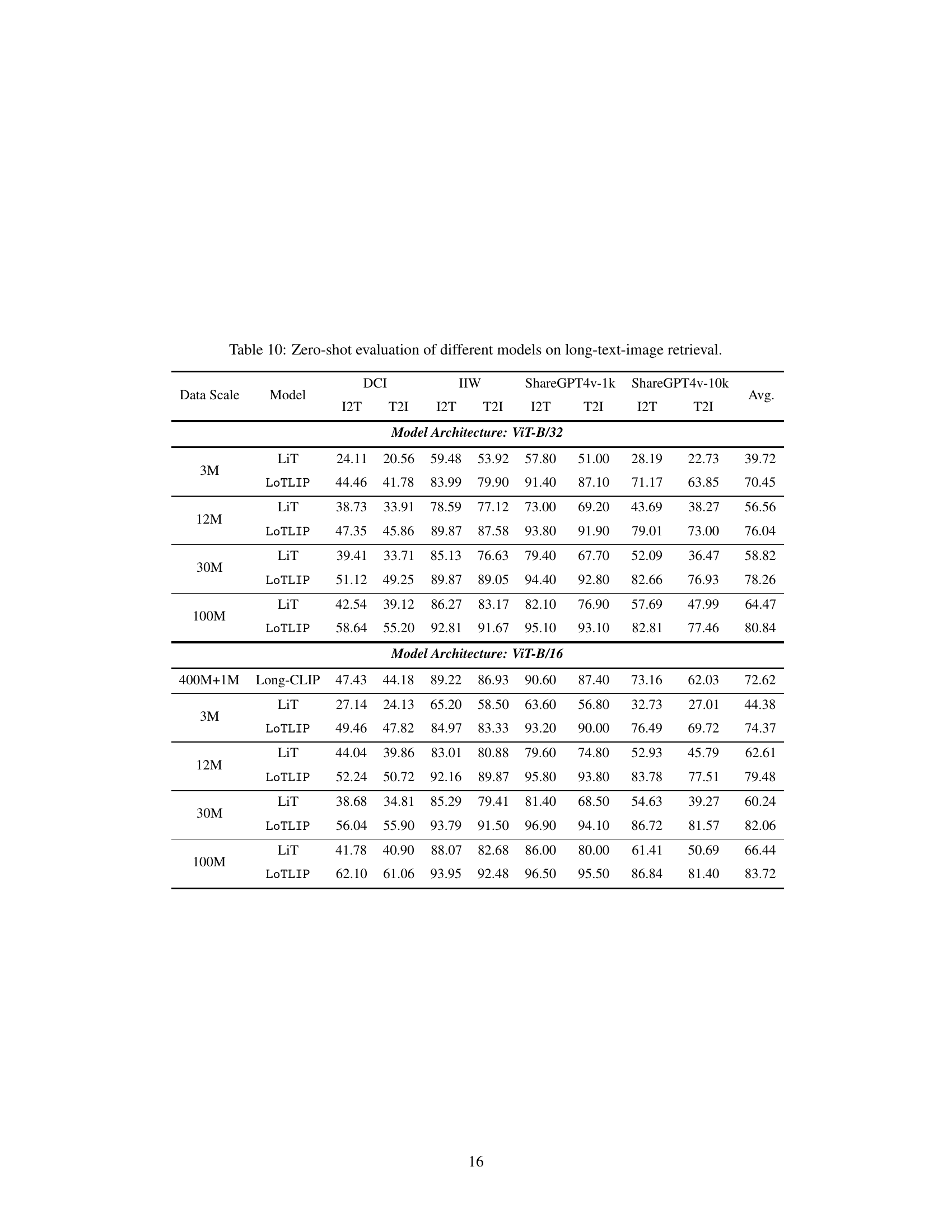
🔼 This table presents the results of a zero-shot evaluation of various models on long-text image retrieval tasks. It compares the performance of different models (FILIP, LaCLIP, SigLIP, LiT, LoTLIP, CLIP, ALIGN, SigLIP, Long-CLIP) across several datasets (DCI, IIW, ShareGPT4V-1k, ShareGPT4V-10k) using two metrics: Recall@1 (R@1) for image-to-text (I2T) retrieval and text-to-image (T2I) retrieval. The datasets vary in size and source, and the models differ in their architecture and training methodologies. The table allows for a comparison of the effectiveness of different models in handling long-text image retrieval tasks.
read the caption
Table 4: Zero-shot evaluation of different models on long-text-image retrieval tasks. I2T and T2I indicate R@1 on text and image retrieval, respectively.
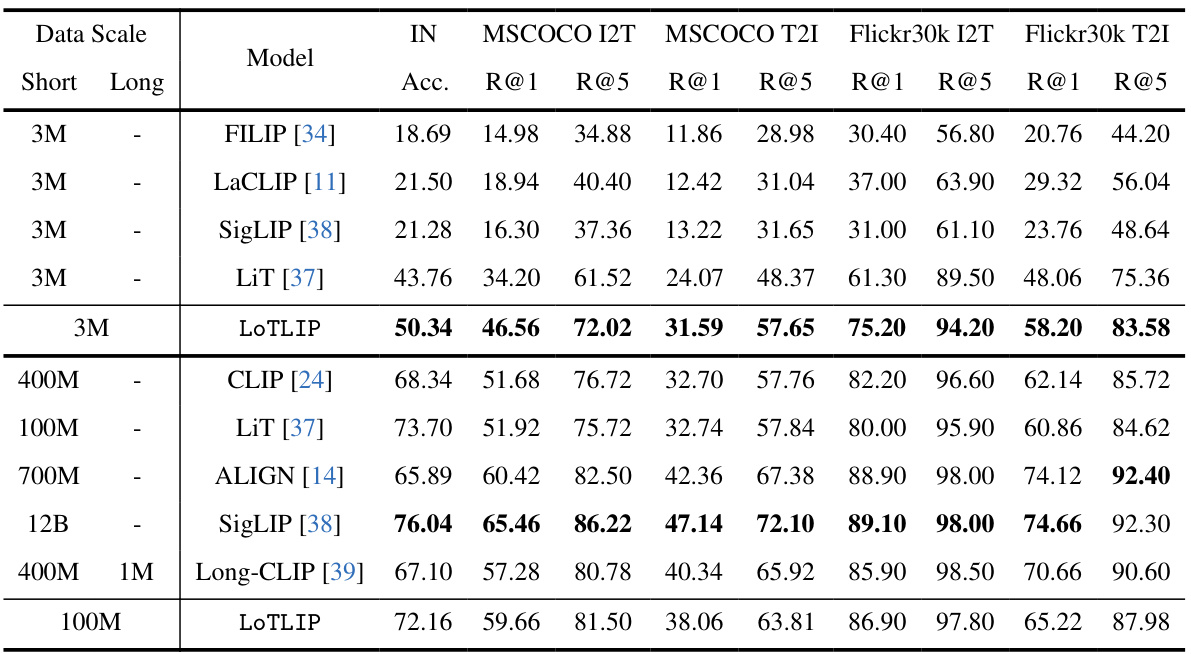
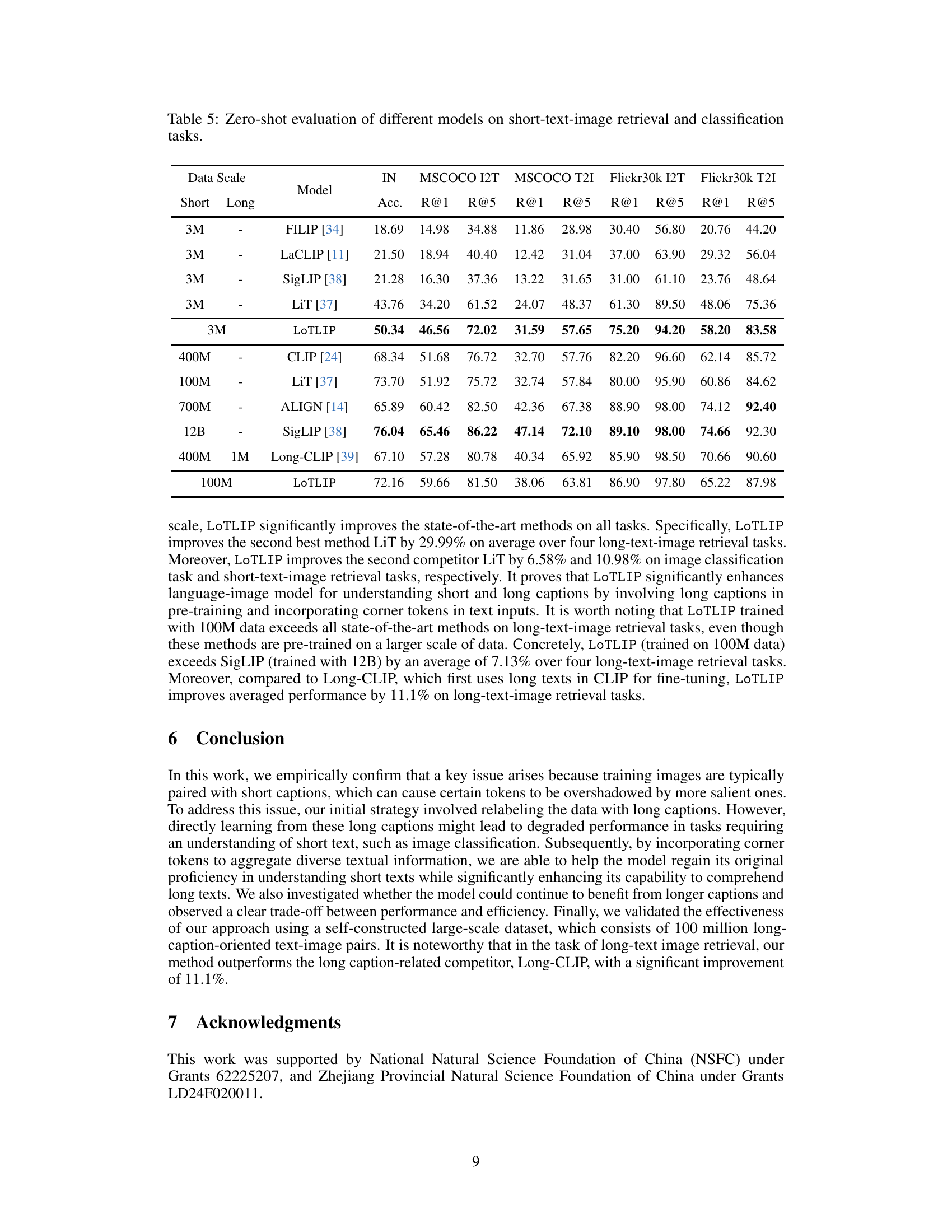
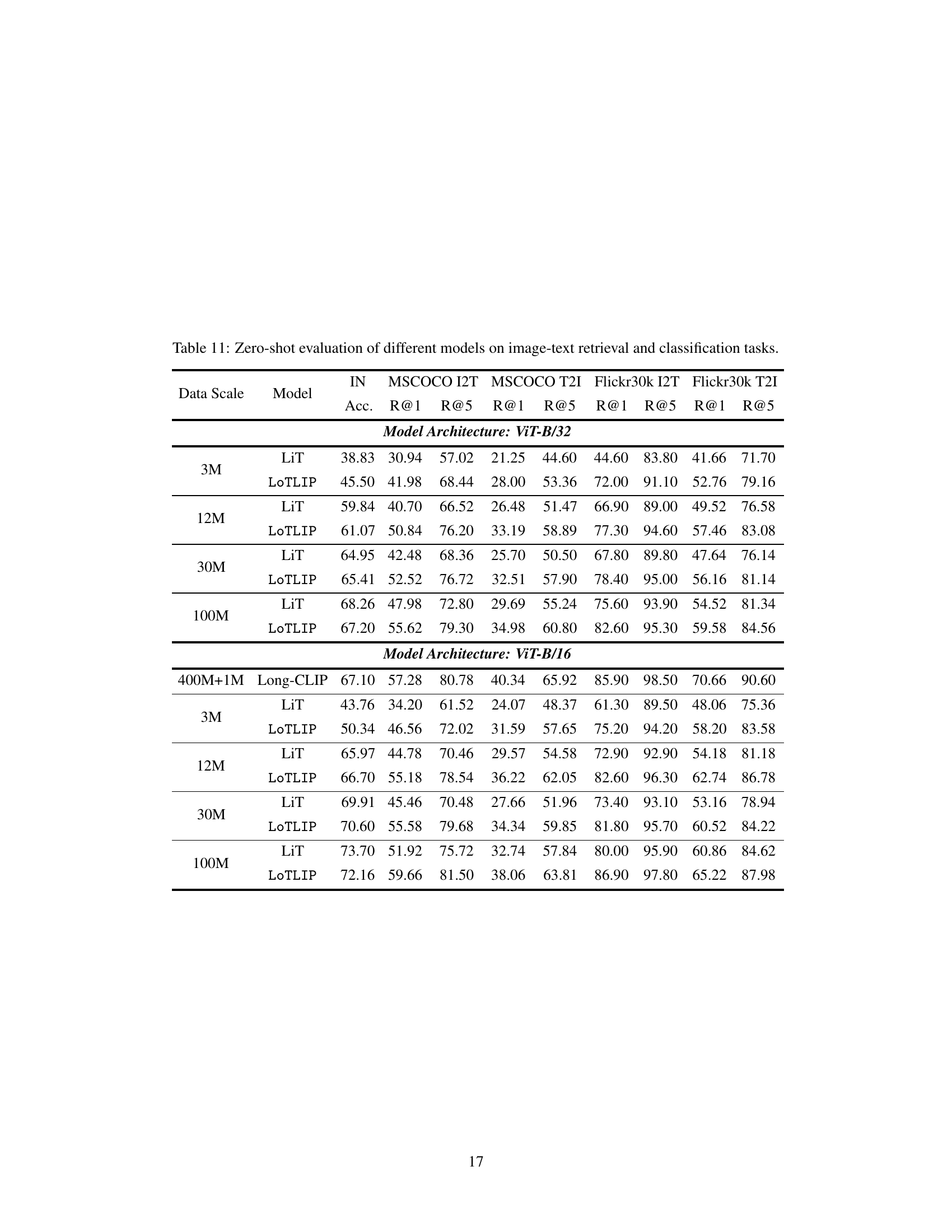
🔼 This table presents the results of a zero-shot evaluation of various models on short-text image retrieval and image classification tasks. It compares the performance of different models (FILIP, LaCLIP, SigLIP, LiT, LoTLIP, CLIP, ALIGN, and Long-CLIP) across different datasets (MSCOCO and Flickr30k) and metrics (R@1, R@5, accuracy). The models were evaluated on both short and long-text inputs to assess their ability to handle different text lengths. The table shows the impact of various models and different amounts of training data on the performance of these tasks.
read the caption
Table 5: Zero-shot evaluation of different models on short-text-image retrieval and classification tasks.

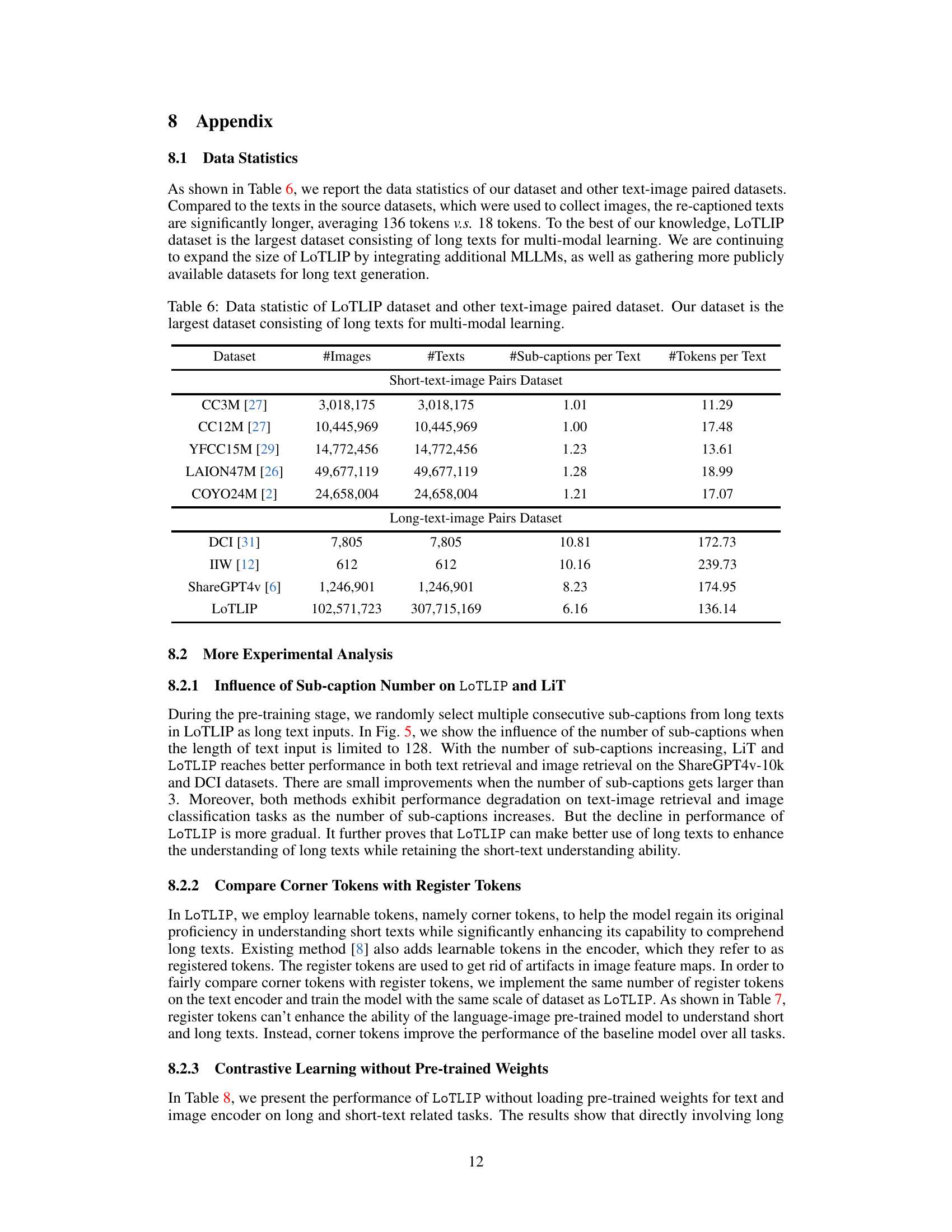
🔼 This table presents a comparison of the LoTLIP dataset with other publicly available image-text datasets. It shows the number of images and texts, the average number of sub-captions per text, and the average number of tokens per text. The table highlights that LoTLIP is significantly larger than other datasets and contains substantially longer texts, making it unique for multi-modal learning involving long text understanding.
read the caption
Table 6: Data statistic of LoTLIP dataset and other text-image paired dataset. Our dataset is the largest dataset consisting of long texts for multi-modal learning.
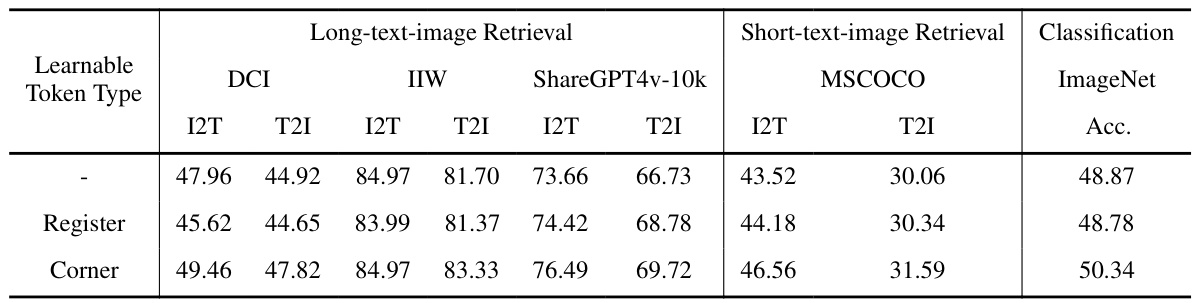
🔼 This table compares the performance of using corner tokens versus register tokens in the LoTLIP model. Both types of tokens are added to the text encoder to improve the handling of long and short texts. The table shows the Recall@1 (R@1) scores for image-to-text (I2T) and text-to-image (T2I) retrieval tasks on four datasets (DCI, IIW, ShareGPT4v-10k, MSCOCO), as well as the accuracy (Acc.) of ImageNet classification. The results demonstrate the superior performance of corner tokens compared to register tokens across all tasks and metrics.
read the caption
Table 7: Compare corner tokens with register tokens. The models are trained with 3M scale dataset.

🔼 This table presents the results of zero-shot evaluations performed on three different downstream tasks: short-text image retrieval using MSCOCO and Flickr30k datasets, and image classification using the ImageNet dataset. The table compares the performance of various models (CLIP, LiT, LOTLIP and others) across these tasks, showing Recall@1 and Recall@5 for retrieval tasks and accuracy for classification. The data scale used for training the models (3M, 12M, 30M, 100M) is also shown, highlighting the impact of training data size on model performance. The ‘Long Texts’ column indicates whether long texts were used during the pre-training phase. This allows for a comparison of model performance with and without long-text pre-training.
read the caption
Table 5: Zero-shot evaluation of different models on short-text-image retrieval and classification tasks.

🔼 This table presents the results of experiments using three different large multi-modal language models (MLLMs) to generate long captions for images in the language-image pre-training process. It compares the performance of the LoTLIP model when trained with captions generated by each of the three MLLMs individually and when trained using captions from all three MLLMs. The metrics evaluated include I2T and T2I Recall@1 for several datasets, and accuracy on an ImageNet classification task. The goal was to assess the impact of MLLM diversity on the overall effectiveness of long-caption-based training.
read the caption
Table 9: Utilizing long captions generated by different MLLMs in the training stage.
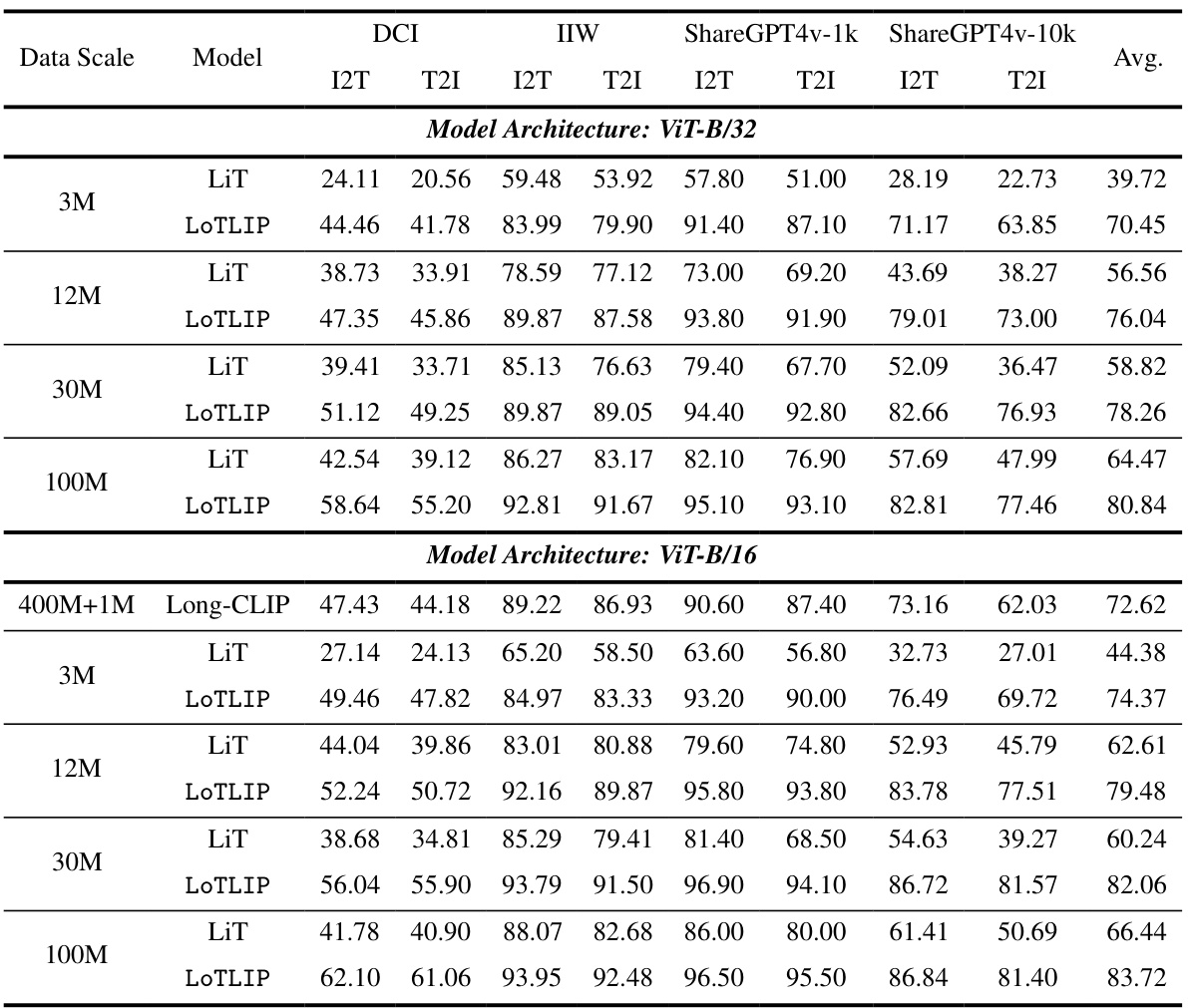
🔼 This table compares the performance of different models on image and text retrieval tasks, with and without the use of long texts in pre-training. The models are evaluated on three datasets (DCI, IIW, and ShareGPT4V-10k) for long-text image retrieval and MSCOCO for short-text image retrieval. ImageNet classification accuracy is also reported. The table shows that incorporating long texts in the pre-training stage, as done in LoTLIP, significantly improves performance on long-text retrieval tasks, but may slightly reduce performance on short-text retrieval and image classification tasks.
read the caption
Table 2: Analyze the effectiveness of LoTLIP in language-image pre-training with long texts. The architecture of the image encoder is ViT-B/16. I2T and T2I indicate R@1 on text and image retrieval, respectively. We use 3M scale dataset for pre-training. “✓” indicates we add long texts in the training stage.

🔼 This table compares the performance of different methods on image classification, short-text image retrieval, and long-text image retrieval tasks. The methods include LiT (a baseline), LiT with Long-CLIP (a competitor method that fine-tunes a pre-trained model with long texts), and LoTLIP (the proposed method). The results show the Recall@1 (R@1) metric for image-to-text (I2T) and text-to-image (T2I) retrieval, and Accuracy@1 (Acc@1) for image classification. The impact of adding long texts to the training process is also demonstrated, highlighting the effectiveness of the proposed LoTLIP approach.
read the caption
Table 2: Analyze the effectiveness of LoTLIP in language-image pre-training with long texts. The architecture of the image encoder is ViT-B/16. I2T and T2I indicate R@1 on text and image retrieval, respectively. We use 3M scale dataset for pre-training. “✓” indicates we add long texts in the training stage.
Full paper#