TL;DR#
Reconstructing 3D hand poses from a single image is challenging due to factors like articulated motion, self-occlusion, and object interaction. Existing methods, mostly based on transformers, struggle with efficiently capturing spatial relationships between hand joints, leading to less robust and accurate reconstructions. These methods also utilize a large number of tokens for processing, leading to computational inefficiency.
To address these challenges, the authors present Hamba, a novel graph-guided Mamba framework that combines graph learning and state-space modeling. Hamba cleverly reformulates Mamba’s scanning process into graph-guided bidirectional scanning, efficiently learning the spatial relations between joints using fewer tokens. The core of Hamba is the Graph-guided State Space (GSS) block, which achieves this efficient learning. Experiments show that Hamba significantly surpasses existing state-of-the-art methods across multiple benchmark datasets and in-the-wild scenarios, setting new standards for accuracy and robustness in 3D hand reconstruction.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in 3D hand reconstruction due to its significant performance improvements over existing state-of-the-art methods. The introduction of the Graph-guided State Space (GSS) block, which leverages graph learning and state-space modeling, is a novel contribution that improves the reconstruction performance significantly. Moreover, the paper’s exploration of Mamba’s potential in the field of 3D vision opens new avenues for research, and its in-the-wild performance establishes it as a strong benchmark for future work. The focus on efficiency and generalizability addresses current limitations in the field, making this research highly relevant to current trends.
Visual Insights#

🔼 This figure shows several examples of 3D hand reconstructions generated by the Hamba model in various challenging real-world scenarios. The scenarios include hands interacting with objects, hands with varying skin tones and poses, and even hands depicted in paintings and animations. The diversity of the scenarios demonstrates the robustness and generalizability of the Hamba model in handling complex real-world situations.
read the caption
Figure 1: In-the-wild visual results of Hamba. Hamba achieves significant performance in various in-the-wild scenarios, including hand interaction with objects or hands, different skin tones, different angles, challenging paintings, and vivid animations.
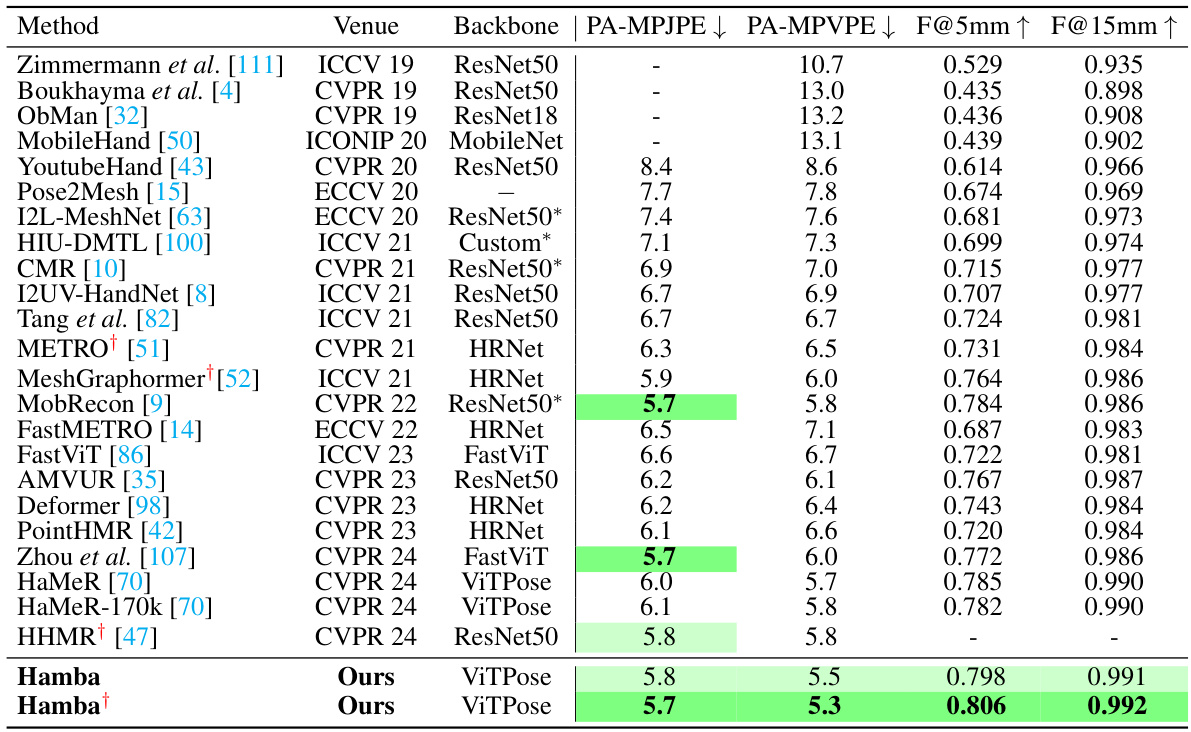
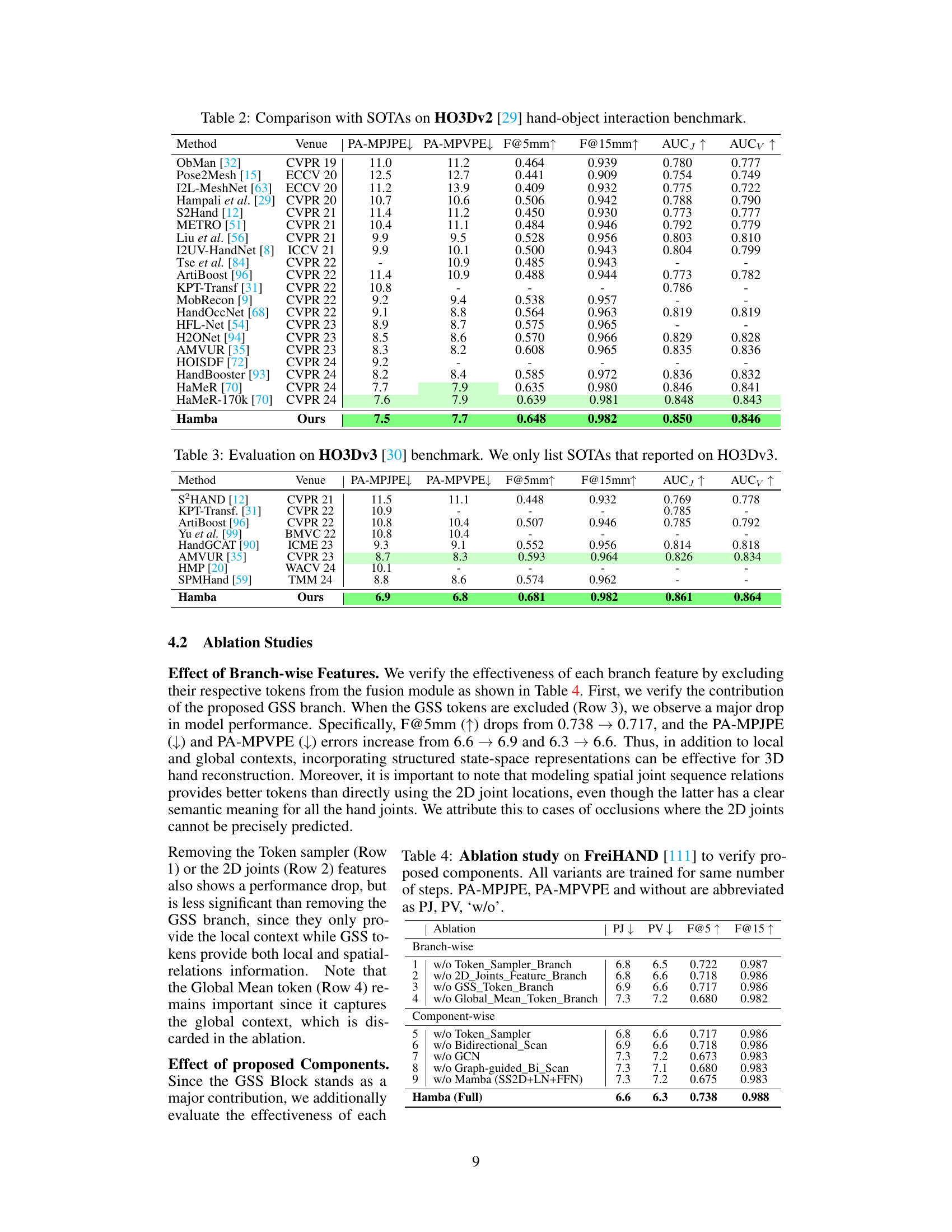
🔼 This table presents a quantitative comparison of the proposed Hamba model with other state-of-the-art 3D hand reconstruction models on the FreiHAND dataset. The table includes metrics such as PA-MPJPE (Procrustes Aligned Mean Per Joint Position Error), PA-MPVPE (Procrustes Aligned Mean Per Vertex Position Error), F@5mm (F-score at 5mm threshold), and F@15mm (F-score at 15mm threshold). The results show Hamba’s superior performance compared to existing methods, with and without test-time augmentation (TTA).
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.
In-depth insights#
Graph-Guided Mamba#
The proposed “Graph-Guided Mamba” framework represents a novel approach to single-view 3D hand reconstruction, addressing limitations of existing methods. It cleverly combines graph learning with the Mamba state space model. This fusion allows for efficient encoding of spatial relationships between hand joints, overcoming challenges like self-occlusion and articulated motion. By reformulating Mamba’s scanning process into a graph-guided bidirectional approach, the method effectively captures both local and global hand joint features using significantly fewer tokens than attention-based methods. The introduction of a Graph-guided State Space (GSS) block is crucial, enhancing the learning of graph-structured relationships and spatial sequences. Further improvements are achieved through a fusion module which integrates state space and global features, leading to more robust and accurate 3D hand mesh reconstruction. The method’s success is demonstrated by its superior performance on benchmark datasets and real-world in-the-wild testing scenarios, highlighting the potential of this innovative approach.
Bidirectional Scanning#
Bidirectional scanning, in the context of 3D hand reconstruction, offers a powerful approach to capture spatial relationships between hand joints more effectively than traditional unidirectional methods. By scanning the input data (e.g., image features, or graph nodes) in both forward and backward directions, it leverages context from both ends of the sequence simultaneously. This approach is particularly useful in handling long-range dependencies, common in articulated structures like hands, where the interaction between distant joints significantly influences the overall hand pose and shape. The bidirectional nature helps to resolve ambiguities and self-occlusions that often plague single-view 3D reconstruction. A major advantage is the potential for reduced computational cost compared to attention-based methods, as the bidirectional scan might require fewer tokens or computations for equivalent performance. This improved efficiency makes it suitable for resource-constrained environments and real-time applications. While the concept is intuitive, designing an effective bidirectional scanning strategy for hand reconstruction is complex and requires careful consideration of the specific data representation and the model architecture. The choice of scan path, token sampling strategy, and the way bidirectional information is fused all play crucial roles in determining the performance of this method.
3D Hand Meshing#
3D hand meshing presents a significant challenge in computer vision due to the complexity of hand anatomy, articulated motion, self-occlusion, and interaction with objects. Accurate reconstruction requires robust methods capable of handling various hand poses, lighting conditions, and viewpoints. Current state-of-the-art techniques often leverage deep learning, particularly transformer networks, but these can be computationally expensive and may struggle with intricate spatial relationships between joints. Graph-based approaches offer a promising alternative, providing an efficient way to model the inherent structural relationships within the hand. They can effectively capture both local and global features, leading to more accurate and robust mesh reconstruction. Furthermore, integrating state-space models offers advantages in handling temporal sequences and long-range dependencies, crucial for smooth and continuous hand motion capture. Future research should focus on developing more efficient and generalizable methods that can handle diverse hand shapes, in-the-wild conditions, and real-time applications. Combining the strengths of graph-based approaches and state-space models appears to be a particularly fruitful avenue for achieving robust, accurate and efficient 3D hand meshing.
In-the-Wild Results#
An ‘In-the-Wild Results’ section in a research paper would demonstrate the model’s robustness and generalizability beyond controlled laboratory settings. It would showcase performance on challenging, real-world data, such as images with occlusions, varying lighting conditions, unusual viewpoints, and diverse backgrounds. The results would ideally highlight the model’s ability to handle these complexities, showcasing its superiority to existing methods in scenarios more closely mirroring actual applications. A thoughtful presentation would include qualitative examples, such as representative images and reconstructed 3D hand meshes, alongside quantitative metrics demonstrating accuracy and precision. Success in this section is critical for demonstrating the model’s practical utility and establishing its potential for deployment in real-world applications, rather than just academic benchmarks. High-quality visualization and clear communication of results are essential for impacting readers. A comparison with state-of-the-art approaches on the same in-the-wild dataset would strengthen the paper’s overall impact and credibility.
Future Directions#
Future research directions could explore improving Hamba’s robustness to challenging conditions such as extreme lighting, significant occlusions, and unusual hand poses. Investigating the use of alternative neural architectures beyond transformers and exploring techniques like self-supervised learning or unsupervised domain adaptation could improve performance and reduce data dependency. The integration of temporal information to handle video sequences, extending beyond single-frame analysis, is another promising area. Finally, in-depth analysis of failure cases and the development of more sophisticated loss functions are crucial for further enhancing accuracy and generalizability. Benchmarking against a wider variety of datasets and exploring applications beyond single-view hand reconstruction, such as hand-object interaction analysis, are also important avenues for continued work.
More visual insights#
More on figures
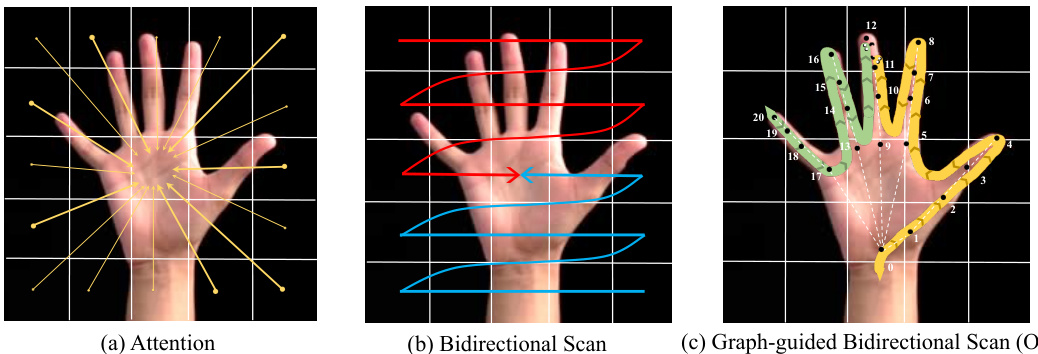
🔼 This figure compares three different scanning methods for hand reconstruction. The first method uses attention, which considers all patches leading to a high number of tokens. The second method uses a bidirectional scan, reducing complexity with two scanning paths. The proposed method uses a graph-guided bidirectional scan, which leverages graph learning to achieve effective state space modeling with only a few tokens. The figure illustrates the difference in complexity and effectiveness among these three methods.
read the caption
Figure 2: Motivation. Visual comparisons of different scanning flows. (a) Attention methods compute the correlation across all patches leading to a very high number of tokens. (b) Bidirectional scans follow two paths, resulting in less complexity. (c) The proposed graph-guided bidirectional scan (GBS) achieves effective state space modeling leveraging graph learning with a few effective tokens (illustrated as scanning by two snakes: forward and backward scanning snakes).
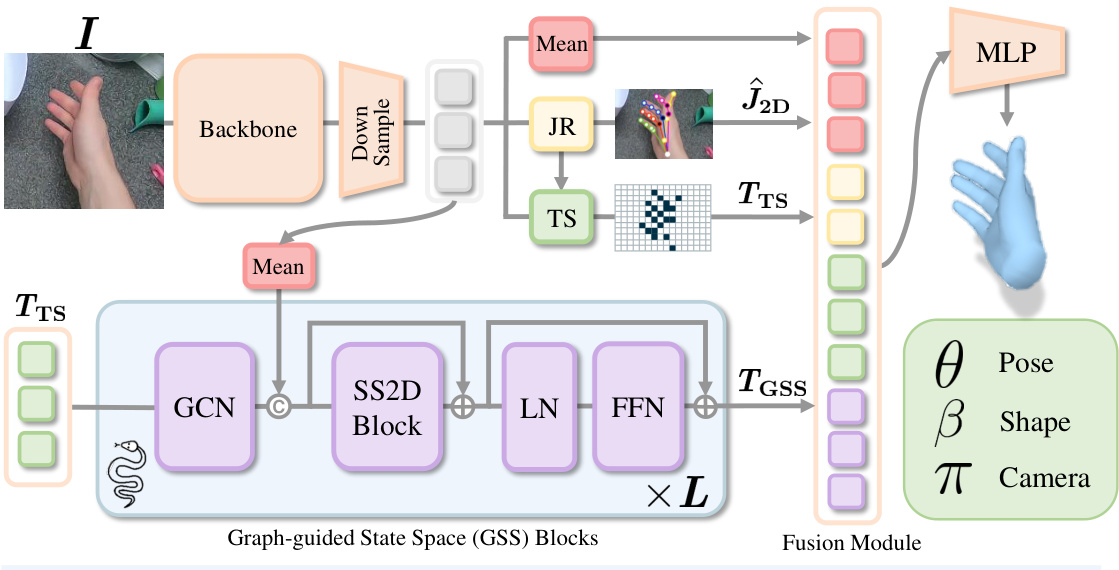
🔼 This figure shows the architecture of the Hamba model, which consists of a backbone to extract image tokens, a joints regressor to predict 2D hand joints, a token sampler to select relevant tokens, and graph-guided state space blocks to learn joint spatial relations. The output is then fused to regress the final MANO parameters.
read the caption
Figure 3: Overview of Hamba's architecture. Given a hand image I, tokens are extracted via a trainable backbone model and downsampled. We design a graph-guided SSM as a decoder to regress hand parameters. The hand joints (J2D) are regressed by Joints Regressor (JR) and fed into the Token Sampler (TS) to sample tokens (Trs). The joint spatial sequence tokens (TGss) are learned by the Graph-guided State Space (GSS) blocks. Inside each GSS block, the GCN network takes Trs as input and its output is concatenated with the mean down-sampled tokens. GSS leverages graph learning and state space modeling to capture the joint spatial relations to achieve robust 3D reconstruction.

🔼 This figure compares three different blocks: the Mamba block, the VSS block, and the proposed GSS block. The Mamba block is a basic state space model. The VSS block extends this with a 2D selective scan. The GSS block adds a graph convolutional network (GCN) to incorporate graph-structured relationships between hand joints, enhancing the representation by considering the intricate hand joint relations. It leverages graph learning and state space modeling to model the joint spatial sequence. The GSS block is the core innovation in the Hamba model, enabling it to model spatial relationships more effectively.
read the caption
Figure 4: The illustration of the proposed Graph-guided State Space (GSS) block.
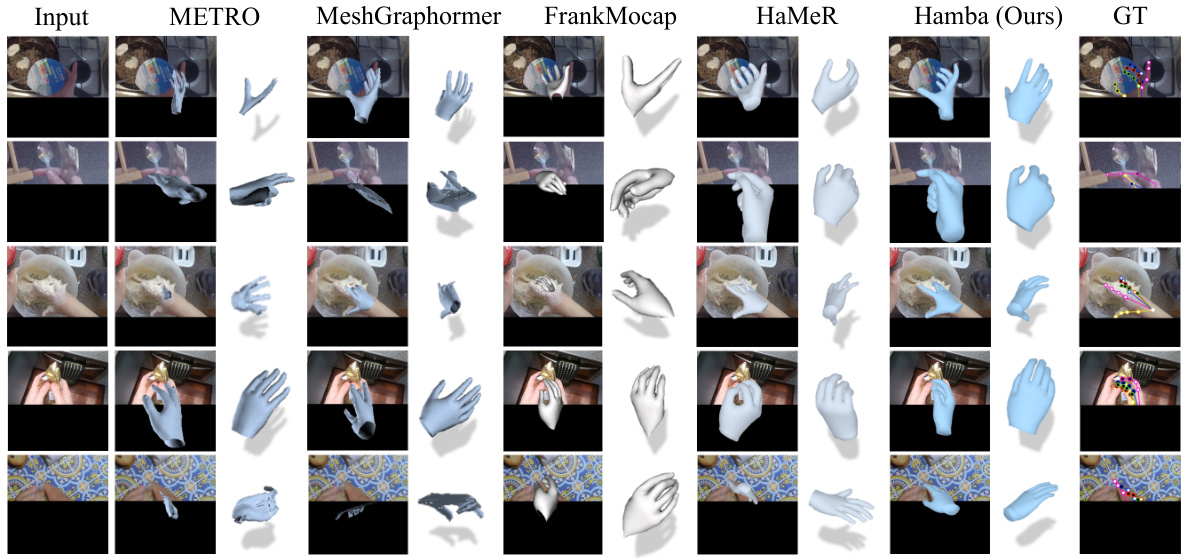
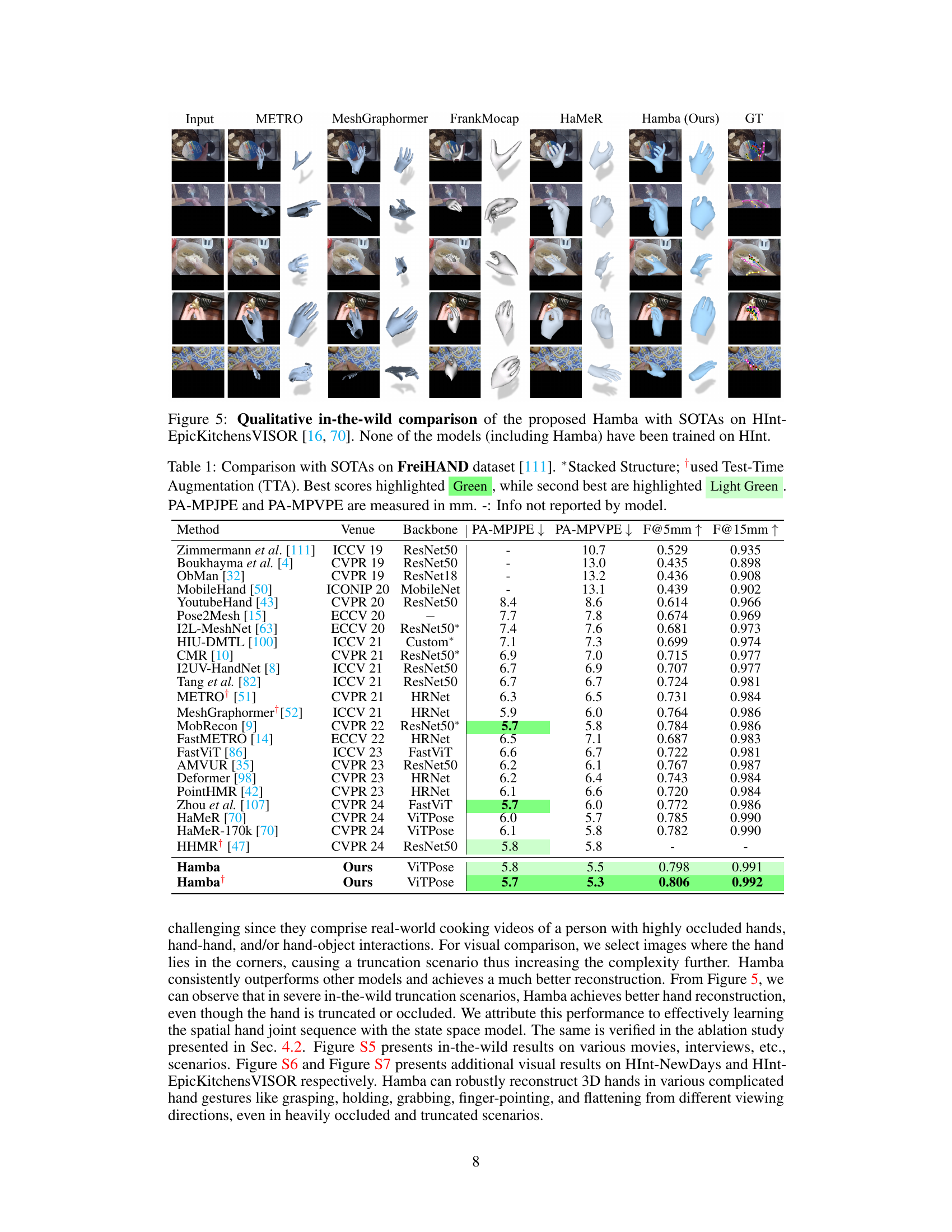
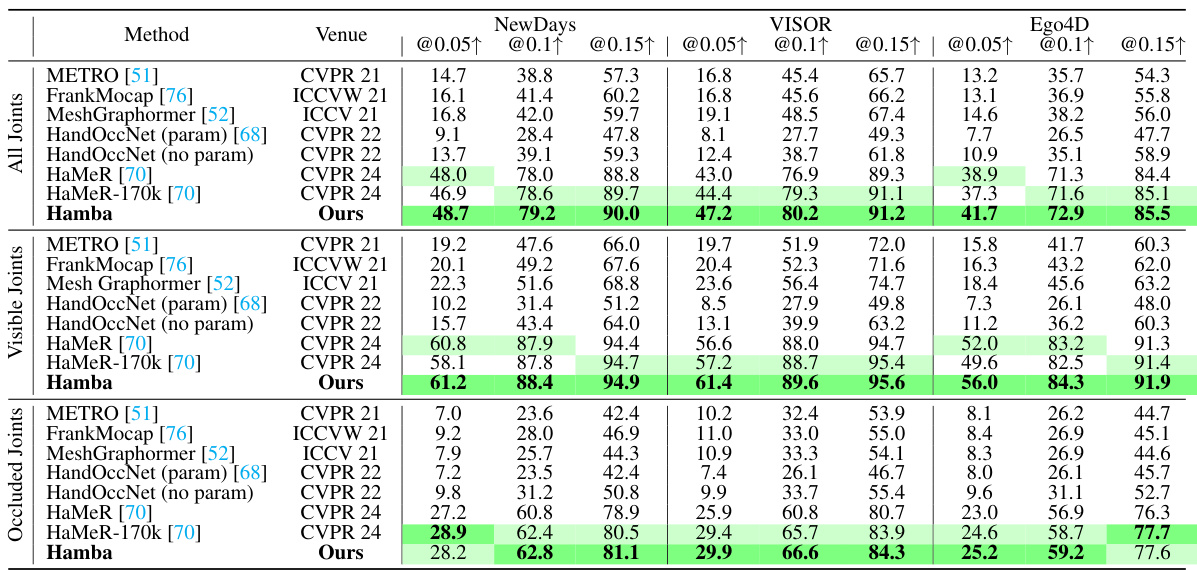
🔼 This figure shows a qualitative comparison of Hamba’s 3D hand mesh reconstruction performance against other state-of-the-art methods on the challenging HInt-EpicKitchensVISOR dataset. The images illustrate various in-the-wild scenarios involving occlusions, hand-object interactions, different viewpoints and lighting conditions. Importantly, none of the models were trained using data from this specific dataset, highlighting the generalization capabilities of the approaches. The comparison demonstrates Hamba’s superior reconstruction accuracy compared to other methods even in these very difficult scenarios.
read the caption
Figure 5: Qualitative in-the-wild comparison of the proposed Hamba with SOTAs on HInt-Epic Kitchens VISOR [16, 70]. None of the models (including Hamba) have been trained on HInt.
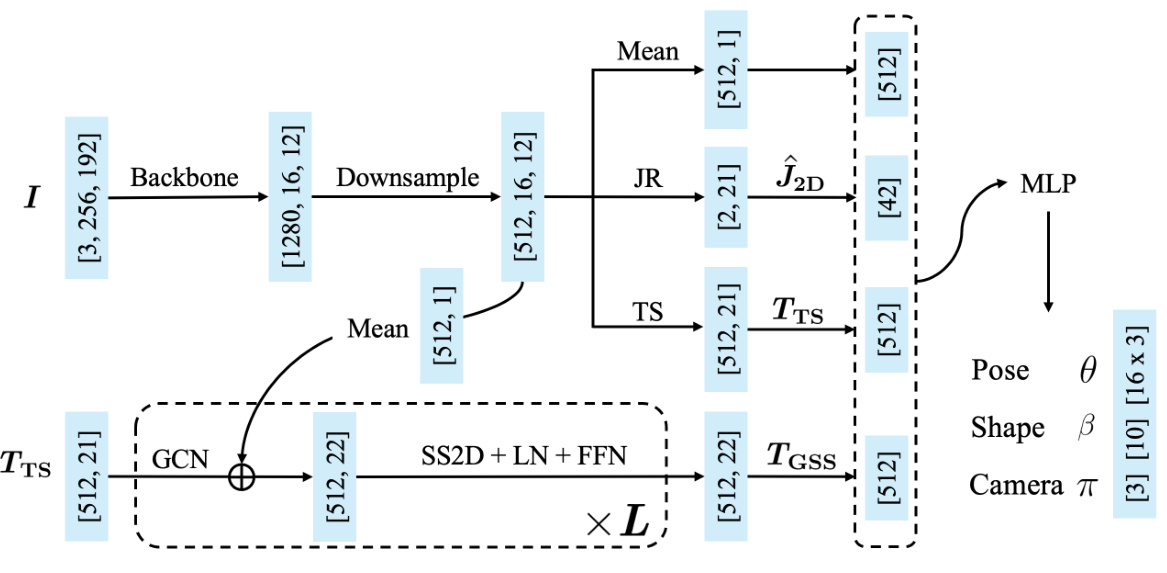
🔼 This figure shows the architecture of the Hamba model. The input image is processed by a backbone network to extract tokens, which are then downsampled. A joint regressor predicts 2D hand joints, which are used by a token sampler to select relevant tokens. These tokens are fed into graph-guided state space (GSS) blocks, which incorporate graph convolutional networks (GCNs) to model the spatial relationships between hand joints and state space modeling to learn the joint spatial sequences. The output of the GSS blocks, along with global mean tokens, are then fused and used to regress the final MANO parameters (pose, shape, and camera parameters).
read the caption
Figure 3: Overview of Hamba's architecture. Given a hand image I, tokens are extracted via a trainable backbone model and downsampled. We design a graph-guided SSM as a decoder to regress hand parameters. The hand joints (J2D) are regressed by Joints Regressor (JR) and fed into the Token Sampler (TS) to sample tokens (Trs). The joint spatial sequence tokens (TGss) are learned by the Graph-guided State Space (GSS) blocks. Inside each GSS block, the GCN network takes Trs as input and its output is concatenated with the mean down-sampled tokens. GSS leverages graph learning and state space modeling to capture the joint spatial relations to achieve robust 3D reconstruction.

🔼 This figure compares three different scanning methods used in 3D hand reconstruction: (a) Attention-based methods which compute the correlation across all image patches, leading to a high number of tokens. (b) The bidirectional scan, which uses two paths for scanning, and therefore has lower complexity. (c) The proposed graph-guided bidirectional scan (GBS) which leverages graph learning with fewer tokens to achieve more effective state space modeling. The GBS is illustrated as two snakes scanning forward and backward.
read the caption
Figure 2: Motivation. Visual comparisons of different scanning flows. (a) Attention methods compute the correlation across all patches leading to a very high number of tokens. (b) Bidirectional scans follow two paths, resulting in less complexity. (c) The proposed graph-guided bidirectional scan (GBS) achieves effective state space modeling leveraging graph learning with a few effective tokens (illustrated as scanning by two snakes: forward and backward scanning snakes).

🔼 This figure illustrates the architecture of the proposed Hamba model. It shows the flow of data from the input image through various modules including a backbone, token sampler, graph convolutional network, and state space blocks, finally culminating in the regression of MANO parameters for 3D hand reconstruction. The figure highlights the key components: the Joints Regressor (JR) which predicts 2D joints, the Token Sampler (TS) that selects informative tokens, the Graph-guided State Space (GSS) blocks that learn spatial relationships, and a fusion module that combines global and local features.
read the caption
Figure 3: Overview of Hamba's architecture. Given a hand image I, tokens are extracted via a trainable backbone model and downsampled. We design a graph-guided SSM as a decoder to regress hand parameters. The hand joints (J2D) are regressed by Joints Regressor (JR) and fed into the Token Sampler (TS) to sample tokens (Trs). The joint spatial sequence tokens (TGss) are learned by the Graph-guided State Space (GSS) blocks. Inside each GSS block, the GCN network takes Trs as input and its output is concatenated with the mean down-sampled tokens. GSS leverages graph learning and state space modeling to capture the joint spatial relations to achieve robust 3D reconstruction.

🔼 This figure shows a detailed architecture of the Hamba model, highlighting the different components and their interactions. The input is a hand image which undergoes feature extraction via a backbone network and downsampling. A Joint Regressor (JR) predicts 2D hand joints used by a Token Sampler (TS) to select relevant tokens. These tokens, representing spatial joint relationships, are processed through Graph-guided State Space (GSS) blocks incorporating Graph Convolutional Networks (GCNs) and State Space modeling. A fusion module combines the GSS outputs with global features before final MANO parameter regression.
read the caption
Figure 3: Overview of Hamba's architecture. Given a hand image I, tokens are extracted via a trainable backbone model and downsampled. We design a graph-guided SSM as a decoder to regress hand parameters. The hand joints (J2D) are regressed by Joints Regressor (JR) and fed into the Token Sampler (TS) to sample tokens (Trs). The joint spatial sequence tokens (TGss) are learned by the Graph-guided State Space (GSS) blocks. Inside each GSS block, the GCN network takes Trs as input and its output is concatenated with the mean down-sampled tokens. GSS leverages graph learning and state space modeling to capture the joint spatial relations to achieve robust 3D reconstruction.

🔼 This figure shows several examples of 3D hand reconstruction results from the proposed Hamba model on various challenging in-the-wild images. These examples demonstrate the robustness of the Hamba model in handling various real-world conditions such as hand-object interactions, diverse skin tones, varied viewpoints and lighting conditions, and even highly challenging images such as paintings and animations.
read the caption
Figure 1: In-the-wild visual results of Hamba. Hamba achieves significant performance in various in-the-wild scenarios, including hand interaction with objects or hands, different skin tones, different angles, challenging paintings, and vivid animations.

🔼 This figure showcases the robustness of the Hamba model in various real-world scenarios. It highlights the model’s ability to accurately reconstruct 3D hand meshes even in challenging conditions such as hand-object interactions, diverse skin tones, varying viewpoints and lighting, and complex backgrounds. The images demonstrate Hamba’s superior performance compared to existing state-of-the-art methods.
read the caption
Figure 1: In-the-wild visual results of Hamba. Hamba achieves significant performance in various in-the-wild scenarios, including hand interaction with objects or hands, different skin tones, different angles, challenging paintings, and vivid animations.

🔼 This figure shows several examples of 3D hand reconstruction results from the Hamba model. The images demonstrate the model’s ability to accurately reconstruct hands in a variety of challenging real-world conditions, including those with significant occlusion, varying lighting, and different hand poses and interactions with objects. The diversity of scenarios highlights the robustness and generalizability of the proposed Hamba method.
read the caption
Figure 1: In-the-wild visual results of Hamba. Hamba achieves significant performance in various in-the-wild scenarios, including hand interaction with objects or hands, different skin tones, different angles, challenging paintings, and vivid animations.
More on tables

🔼 This table presents a quantitative comparison of the proposed Hamba model with state-of-the-art (SOTA) 3D hand reconstruction models on the FreiHAND benchmark dataset. The table includes various performance metrics, such as PA-MPJPE (Procrustes Aligned Mean Per Joint Position Error), PA-MPVPE (Procrustes Aligned Mean Per Vertex Position Error), F@5mm (F-score at 5mm threshold), F@15mm (F-score at 15mm threshold), AUCj (Area Under the Curve for joint accuracy), and AUCv (Area Under the Curve for mesh accuracy). The results are presented for both the original model and the model using test-time augmentation (TTA), highlighting the best and second best results.
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.

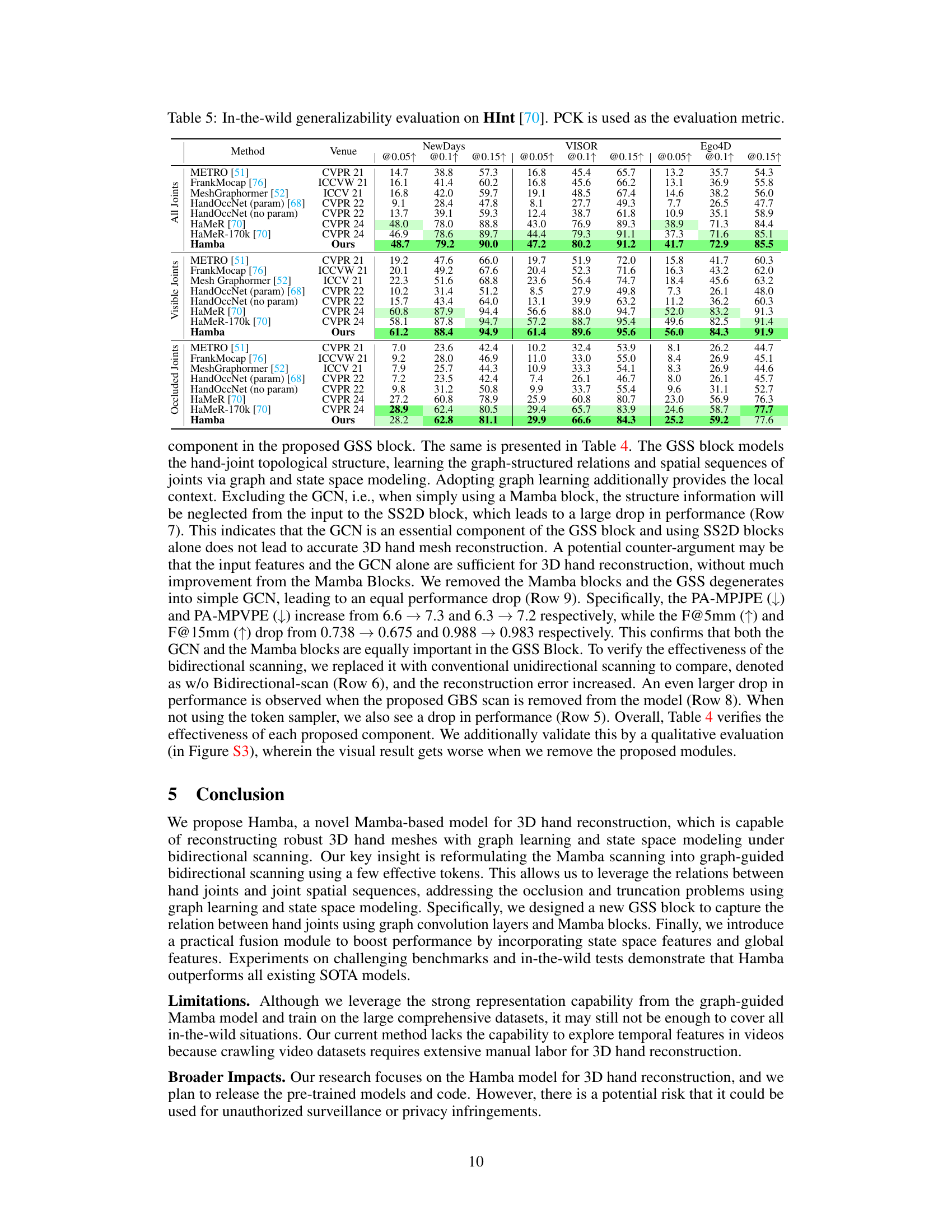
🔼 This table presents a quantitative comparison of the proposed Hamba model with state-of-the-art 3D hand reconstruction models on the HO3Dv3 benchmark. The table includes the method name, venue of publication, PA-MPJPE, PA-MPVPE, F@5mm, F@15mm, AUCj, and AUCv metrics. Lower values for PA-MPJPE and PA-MPVPE, and higher values for F@5mm, F@15mm, AUCj, and AUCv indicate better performance.
read the caption
Table 3: Comparison with SOTAs on HO3Dv3 [30] benchmark. We only list SOTAs that reported on HO3Dv3.
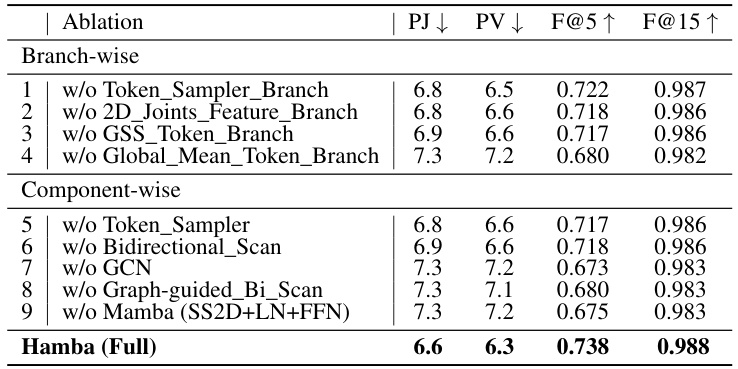
🔼 This table presents a quantitative comparison of the proposed Hamba model with state-of-the-art (SOTA) 3D hand reconstruction models on the FreiHAND benchmark dataset. It shows the performance of various methods in terms of PA-MPJPE (Procrustes Aligned Mean Per Joint Position Error), PA-MPVPE (Procrustes Aligned Mean Per Vertex Position Error), F@5mm (F-score at 5mm threshold), and F@15mm (F-score at 15mm threshold). The table highlights the best and second-best results for each metric, indicating Hamba’s superior performance compared to other SOTA methods.
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.
🔼 This table compares the performance of the proposed Hamba model with other state-of-the-art (SOTA) methods on the FreiHAND dataset. It provides quantitative results in terms of PA-MPJPE (Procrustes Aligned Mean Per Joint Position Error), PA-MPVPE (Procrustes Aligned Mean Per Vertex Position Error), F@5mm (F-score at 5mm threshold), and F@15mm (F-score at 15mm threshold). The table notes whether methods used stacked structures or test-time augmentation, and highlights the top two performing methods for each metric.
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.

🔼 This table compares the proposed Hamba model with other state-of-the-art 3D hand reconstruction models on the FreiHAND dataset. The metrics used are PA-MPJPE, PA-MPVPE, F@5mm, and F@15mm, measuring the error in millimeters. The table highlights the best and second-best results, and notes which methods used stacked structures or test-time augmentation (TTA).
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.

🔼 This table compares the performance of the proposed method, Hamba, against other state-of-the-art (SOTA) methods on the FreiHAND dataset. The evaluation metrics used are PA-MPJPE (Procrustes Aligned Mean Per Joint Position Error), PA-MPVPE (Procrustes Aligned Mean Per Vertex Position Error), F@5mm (F-score at 5mm threshold), and F@15mm (F-score at 15mm threshold). The table highlights the superior performance of Hamba, particularly when considering the smaller number of tokens used (indicated by *). It also notes when other methods used test-time augmentation (TTA), a technique that can improve results but isn’t always used in testing.
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.

🔼 This table presents a quantitative comparison of the proposed Hamba model with state-of-the-art (SOTA) 3D hand reconstruction models on the FreiHAND dataset. The metrics used for comparison include PA-MPJPE (Procrustes Aligned Mean Per Joint Position Error), PA-MPVPE (Procrustes Aligned Mean Per Vertex Position Error), F@5mm (F-score at 5mm threshold), and F@15mm (F-score at 15mm threshold). The table also notes whether models used stacked structures or test-time augmentation (TTA) and highlights the best and second-best performing models.
read the caption
Table 1: Comparison with SOTAs on FreiHAND dataset [111]. *Stacked Structure; †used Test-Time Augmentation (TTA). Best scores highlighted Green, while second best are highlighted Light Green PA-MPJPE and PA-MPVPE are measured in mm. -: Info not reported by model.
Full paper#