↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Image restoration (IR) is a crucial task in computer vision, but existing deep learning methods, particularly those using Vision Transformers (ViTs), face computational challenges due to their reliance on processing all global information. The self-attention mechanism in ViTs can be computationally expensive, especially with high-resolution images, since it processes even semantically unrelated information. This paper also points out that small, semantically similar image segments are particularly useful for high-quality image restoration.
SemanIR tackles these issues by constructing a key-semantic dictionary within each transformer stage that stores only the essential semantic connections between degraded patches. This dictionary is shared among all subsequent blocks, which significantly optimizes attention calculations and leads to linear computational complexity. The proposed SemanIR achieves state-of-the-art performance on 6 IR tasks, including deblurring, JPEG artifact removal, denoising, and super-resolution, showcasing its efficacy and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and image processing. It addresses computational inefficiencies in existing Transformer-based image restoration methods by focusing on semantically relevant information. This leads to state-of-the-art performance across various restoration tasks and opens new avenues for developing more efficient and effective image restoration techniques. The novel Key-Semantic connection method is particularly impactful, offering a simpler and faster way to handle attention calculations in transformers, a significant advance for computationally-intensive tasks.
Visual Insights#

This figure compares different methods of processing image information in image restoration tasks. (a) shows the local receptive field of a CNN, which limits its ability to capture long-range dependencies. (b) shows a standard MLP/Transformer that processes the entire image as a long sequence, which can be computationally expensive. (c) shows a window-based MSA that focuses on local regions but still builds a full connection within each window. (d) demonstrates a position-fixed sparse connection, which reduces computation but might miss important long-range relationships. Finally, (e) illustrates the proposed Key-Semantic connection, which aims to find and connect semantically similar patches, regardless of their relative location, making it efficient and effective.
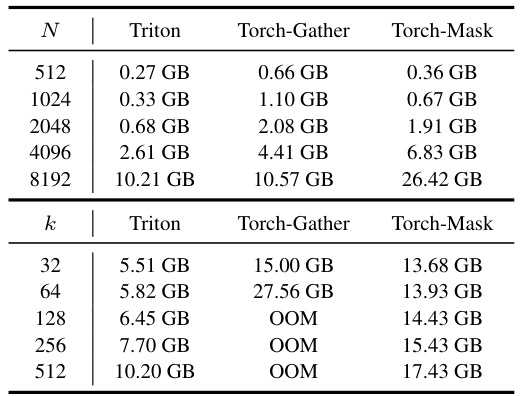
This table compares the GPU memory usage of three different implementations (Triton, Torch-Gather, and Torch-Mask) for the key-semantic attention block in the SemanIR model. The comparison is made for different numbers of tokens (N) and nearest neighbors (k). The results show that Triton uses significantly less memory than the other two methods, but it has some limitations in terms of speed and back-propagation complexity. The Torch-Gather method uses more memory than Torch-Mask, but also faces issues with large numbers of tokens. The Torch-Mask offers a good balance between efficiency and practicality.
In-depth insights#
SemanIR: Core Idea#
SemanIR’s core innovation lies in its efficient attention mechanism for image restoration. Traditional Vision Transformers (ViTs) use self-attention to consider all global image cues, leading to computational inefficiencies. SemanIR tackles this by constructing a key-semantic dictionary for each patch, identifying only its most semantically related neighbors. This dictionary is then shared across all subsequent transformer blocks within the same stage, drastically reducing the attention calculation complexity to linear. By focusing solely on semantically relevant information, SemanIR achieves state-of-the-art performance on multiple image restoration tasks while maintaining efficiency. The key is the strategic combination of sparse but meaningful connections and the efficient sharing of key semantic information, avoiding unnecessary computations on irrelevant image regions. This approach cleverly balances the global context needed for effective restoration with the efficiency demanded by high-resolution images.
KNN & Dictionary#
The core idea revolves around efficiently leveraging semantic relationships within image data for improved image restoration. A key-semantic dictionary is constructed using k-Nearest Neighbors (KNN) to identify semantically similar image patches. This sparse dictionary avoids the computational burden of considering all possible patch relationships, focusing only on the most relevant ones. The KNN approach ensures that only semantically close patches, containing valuable contextual cues, are included in the dictionary, thus improving the efficiency of attention mechanisms in the transformer network. Sharing this dictionary across transformer blocks further reduces computational complexity, allowing for linear complexity in attention calculations. This strategy is crucial for handling high-resolution images, where traditional methods suffer from quadratic complexity, making the proposed method significantly more efficient without sacrificing performance. The combination of KNN and dictionary sharing is a key innovation for efficient and effective image restoration.
Efficiency Gains#
The research paper highlights significant efficiency gains achieved by strategically sharing key semantic information within a transformer-based image restoration framework. This approach, unlike traditional methods that process all global cues indiscriminately, focuses attention on semantically related image components. By constructing a sparse key-semantic dictionary and sharing it across transformer blocks, the computational complexity is reduced from quadratic to linear, especially beneficial for high-resolution images. This linear complexity is a major breakthrough, enabling faster processing and reduced memory footprint. The key-semantic dictionary significantly improves computational efficiency without sacrificing accuracy, as demonstrated by the state-of-the-art performance achieved across various image restoration tasks. The efficiency gains are further enhanced by leveraging optimized attention mechanisms, utilizing Triton for inference, and employing efficient training strategies. The method successfully balances efficiency and accuracy, making it a promising advancement in efficient image restoration.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a model to understand their impact on overall performance. In image restoration, this often involves removing or modifying specific modules (e.g., attention mechanisms, specific layers, loss functions) to observe the resulting changes in metrics such as PSNR and SSIM. A well-designed ablation study will isolate the effect of each component, enabling researchers to identify key factors driving success and potential areas for improvement. For instance, analyzing the impact of different attention mechanisms may reveal whether global context or local details are more critical for the task, guiding future model design. Furthermore, comparing various training strategies (e.g., different optimization algorithms, loss functions, data augmentation techniques) within the ablation study provides insights into optimal training approaches. The results of ablation studies offer valuable insights into model architecture, informing design choices and aiding in future research and development.
Future of SemanIR#
The “Future of SemanIR” holds exciting possibilities. Improving efficiency remains a key goal; exploring more efficient attention mechanisms and optimized KNN algorithms could significantly reduce computational costs, making SemanIR suitable for even higher-resolution images and real-time applications. Expanding its capabilities is another avenue; SemanIR’s architecture could be adapted for other low-level vision tasks such as video restoration and 3D image processing. Further research could investigate enhanced semantic understanding by integrating advanced techniques like graph neural networks or knowledge graphs, allowing SemanIR to discern more nuanced relationships between image patches. Addressing limitations of the current approach, such as the need for separate models for different IR tasks, is crucial. Developing a unified model that handles multiple degradation types would greatly broaden its applicability. Ultimately, the future success of SemanIR will depend on its ability to deliver improved performance and broader usability while maintaining its core strengths of efficient semantic attention and linear computational complexity.
More visual insights#
More on figures
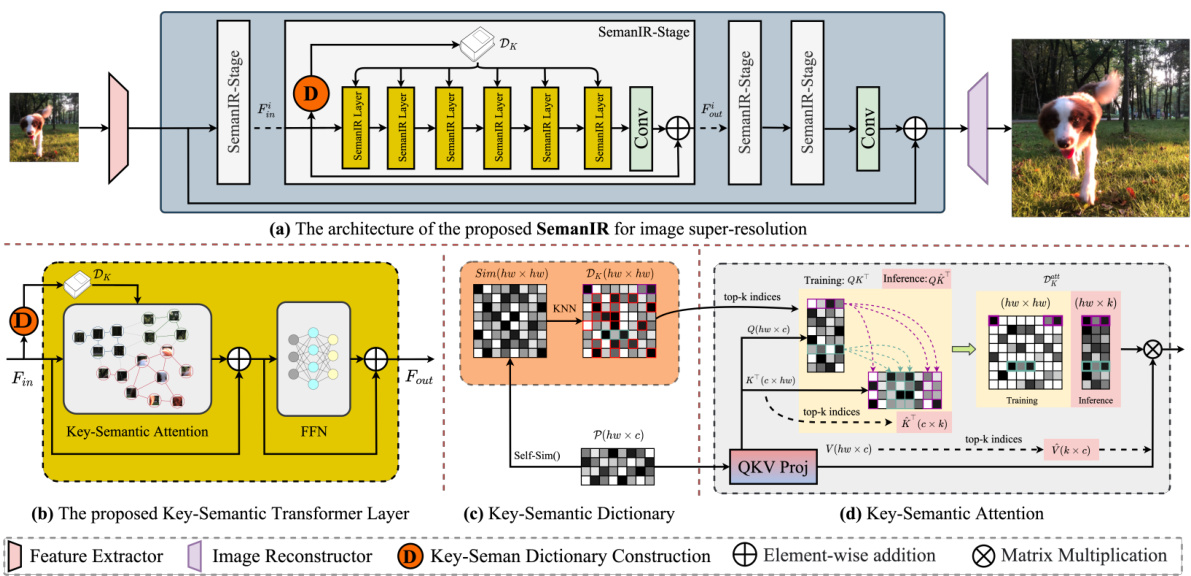
This figure illustrates the overall architecture of the proposed SemanIR model for image restoration. It showcases the main components: a convolutional feature extractor, the core SemanIR module (which can be either columnar or U-shaped, depending on the task), and an image reconstructor. The figure also zooms into the key-semantic transformer layer, detailing the key-semantic dictionary construction and the key-semantic attention mechanism. The example (c) and (d) demonstrate how the sparse key-semantic dictionary is constructed using KNN for a limited set of semantically related patches instead of a full connectivity and how this dictionary is used for the attention mechanism to reduce computational cost.

This figure shows the impact of the k parameter (number of nearest neighbors) on the attention mechanism’s performance in SemanIR. It displays activation maps for different k values, illustrating how the model focuses on semantically related regions as k increases. The results demonstrate a balance, where increasing k beyond a certain point includes less relevant regions, highlighting the effectiveness of the key-semantic dictionary in focusing attention on semantically meaningful components.

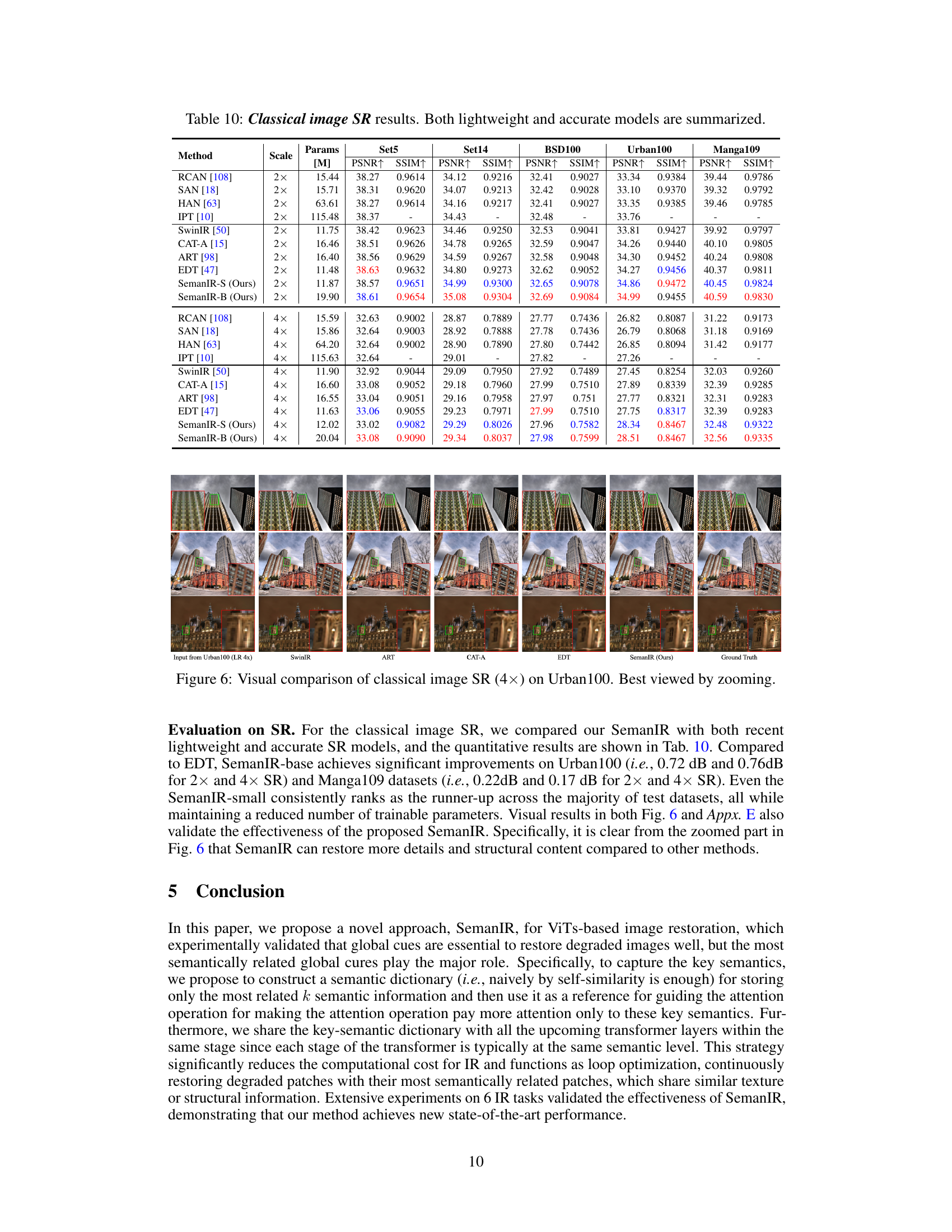
This figure compares the visual results of different super-resolution (SR) methods on the Urban100 dataset, specifically at a 4x upscaling factor. It showcases the input low-resolution (LR) images and the results produced by SwinIR, ART, CAT-A, EDT, and the proposed SemanIR method. The ground truth high-resolution (HR) images are also included for comparison. The images are displayed in a way that allows for a direct visual comparison of the different methods. Zooming in on the image is recommended for better analysis.

This figure shows the U-shaped architecture of SemanIR used for image restoration tasks except for image super-resolution. It consists of a feature extractor, multiple SemanIR stages at different scales (downsampling and upsampling), and an image reconstructor. Each SemanIR stage contains several key-semantic transformer layers to extract and share key semantic information for efficient image restoration. The U-shape design allows the model to capture both local and global features, leading to improved performance.
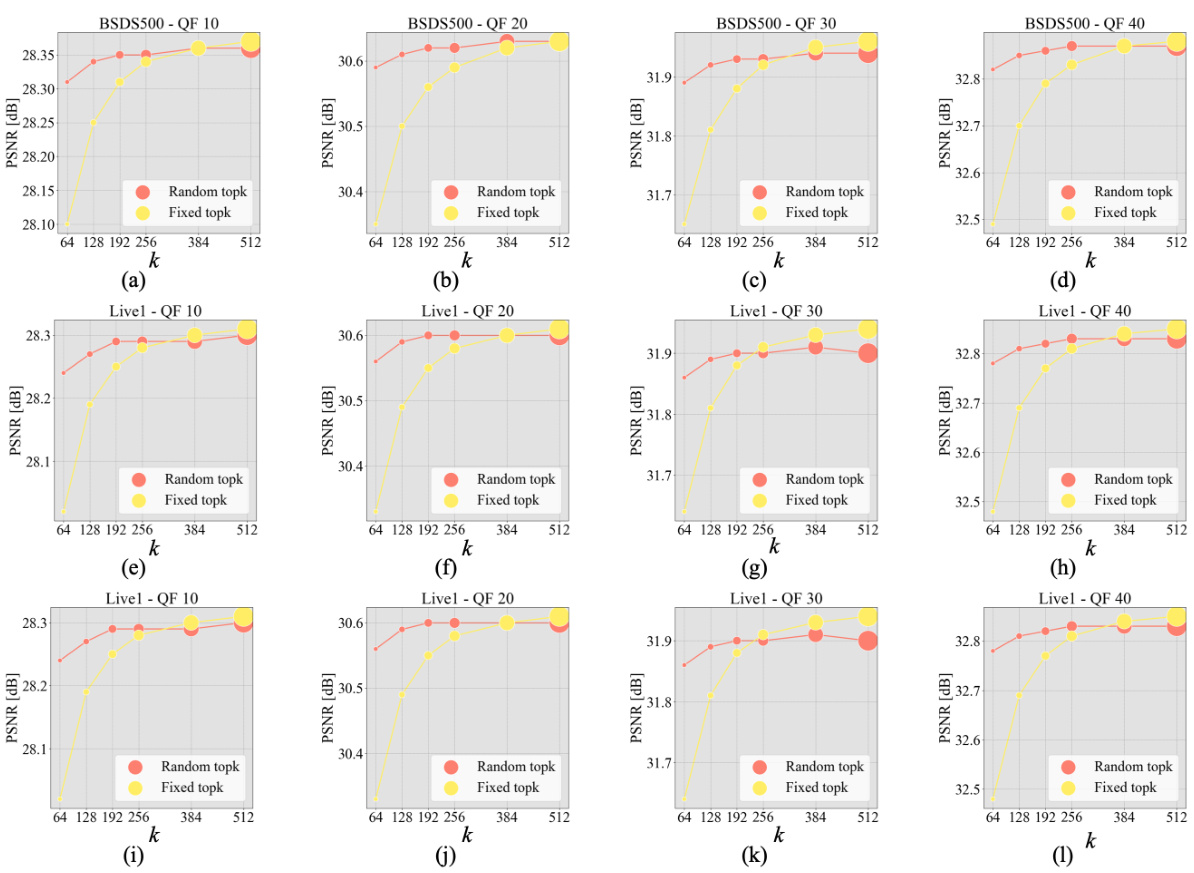
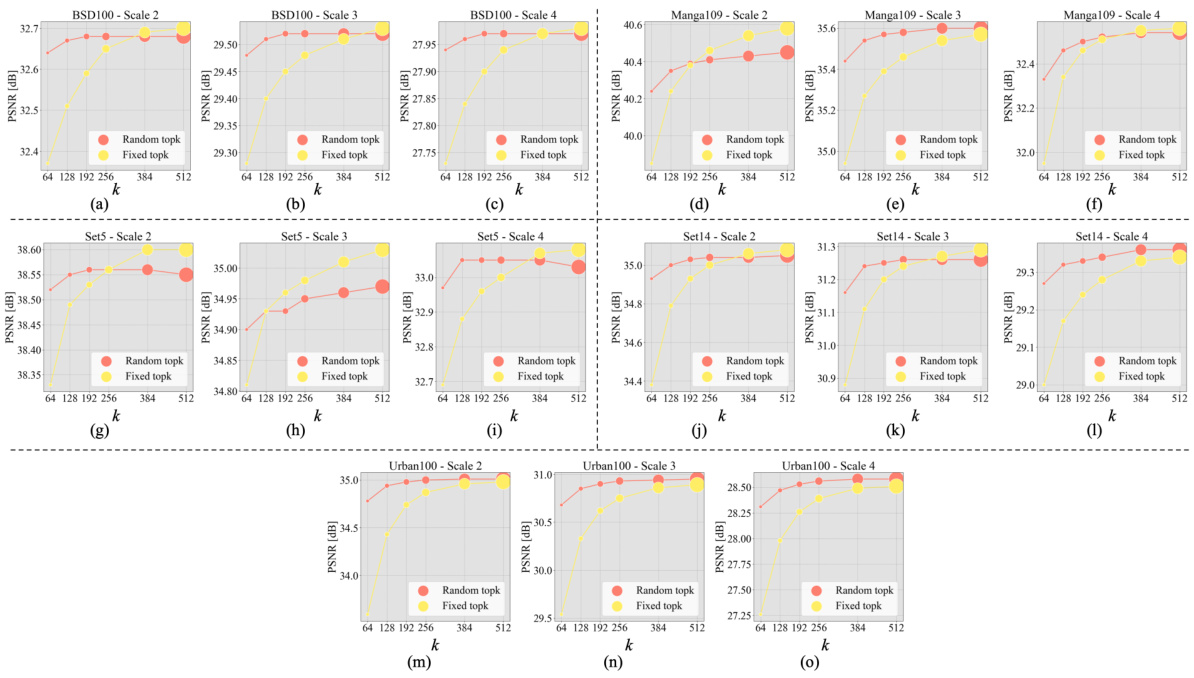
This figure shows the impact of the parameter ‘k’ (number of nearest neighbors) on the performance of the SemanIR model for four different image restoration tasks: color image denoising, gray image denoising, color image JPEG compression artifact removal, and gray image JPEG compression artifact removal. Each subplot displays the PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) scores achieved by SemanIR using different ‘k’ values (64, 128, 192, 256, 384, 512) during inference. The size of each circle in the plot corresponds to the number of FLOPs (floating-point operations) used. This helps visualize the tradeoff between performance and computational cost.

This figure displays the impact of the k parameter (number of nearest neighbors) on the performance of the SemanIR model for four different image restoration tasks: color image denoising, grayscale image denoising, color image JPEG compression artifact removal, and grayscale image JPEG compression artifact removal. Each subfigure shows a plot of PSNR (Peak Signal-to-Noise Ratio) against different values of k during inference. Two training strategies, fixed top-k and random top-k, are compared. The size of the circles in the plot represents the FLOPs (floating point operations), illustrating the computational cost associated with each k value.
This figure shows the U-shaped architecture used in SemanIR for image restoration tasks other than image super-resolution. It illustrates the flow of data through different stages, including feature extraction, multiple SemanIR stages (with downsampling and upsampling), and final image reconstruction. The use of U-shape structure enables the network to capture multi-scale features and contextual information for more accurate restoration.
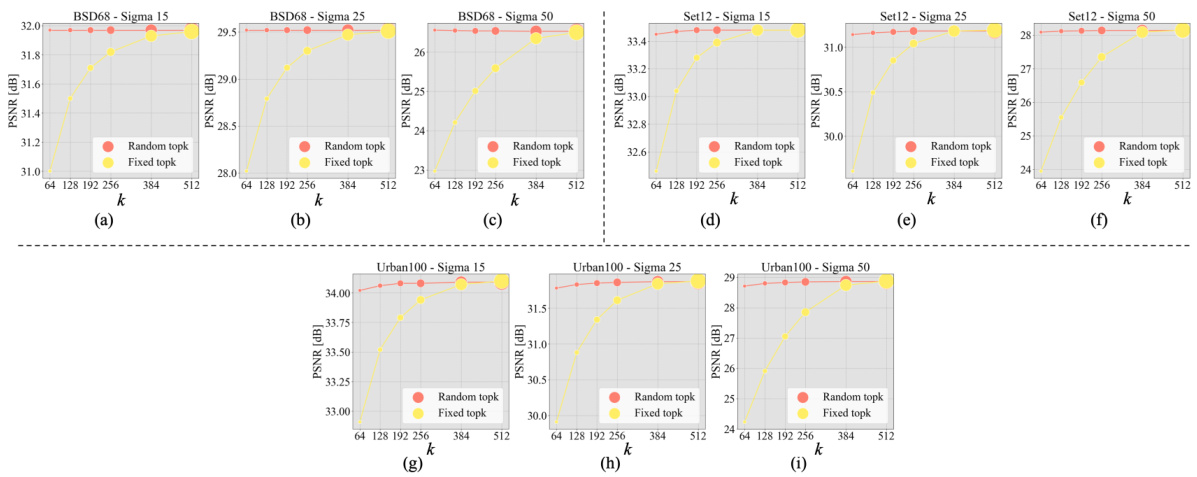
This figure shows the impact of the hyperparameter k (number of nearest neighbors) on the performance of the SemanIR model across different inference k values. Four subfigures represent results for different image restoration tasks (color image denoising, gray image denoising, color image JPEG compression artifact removal, and gray image JPEG compression artifact removal). Each subfigure shows PSNR and SSIM scores as a function of k for both fixed top-k and random top-k training strategies. The size of the circles in the graphs corresponds to the number of FLOPs (floating-point operations) required for each k value, visually representing the computational cost.
This figure shows the overall architecture of SemanIR, a novel image restoration method using key-semantic information sharing in transformers. It highlights the main components: a convolutional feature extractor, the key-semantic transformer layers (with a detailed view of a single layer showing key-semantic dictionary construction and attention mechanism), and an image reconstructor. The figure illustrates the columnar architecture used for image super-resolution (SR) and mentions a U-shaped architecture used for other image restoration (IR) tasks (detailed in Appendix A.2).

This figure shows a visual comparison of image restoration results for images degraded by adverse weather conditions (AWC). The comparison includes the input image (Raining Input), results from three state-of-the-art methods (RESCAN, All-in-One, TransWeather), and the results from the proposed SemanIR method. The green boxes highlight specific regions of interest, demonstrating how each method handles different aspects of AWC degradation. Zooming in is recommended to fully appreciate the detail.

This figure shows the architecture of the proposed SemanIR model for image restoration. It consists of three main parts: a convolutional feature extractor, the main body (SemanIR) for learning representations, and an image reconstructor. The main body can be columnar (for super-resolution) or U-shaped (for other tasks, shown in Appendix A.2). Part (b) details a SemanIR transformer layer, showing how key-semantic dictionaries are constructed (c) and used in attention calculations (d) to focus on only semantically related image patches.

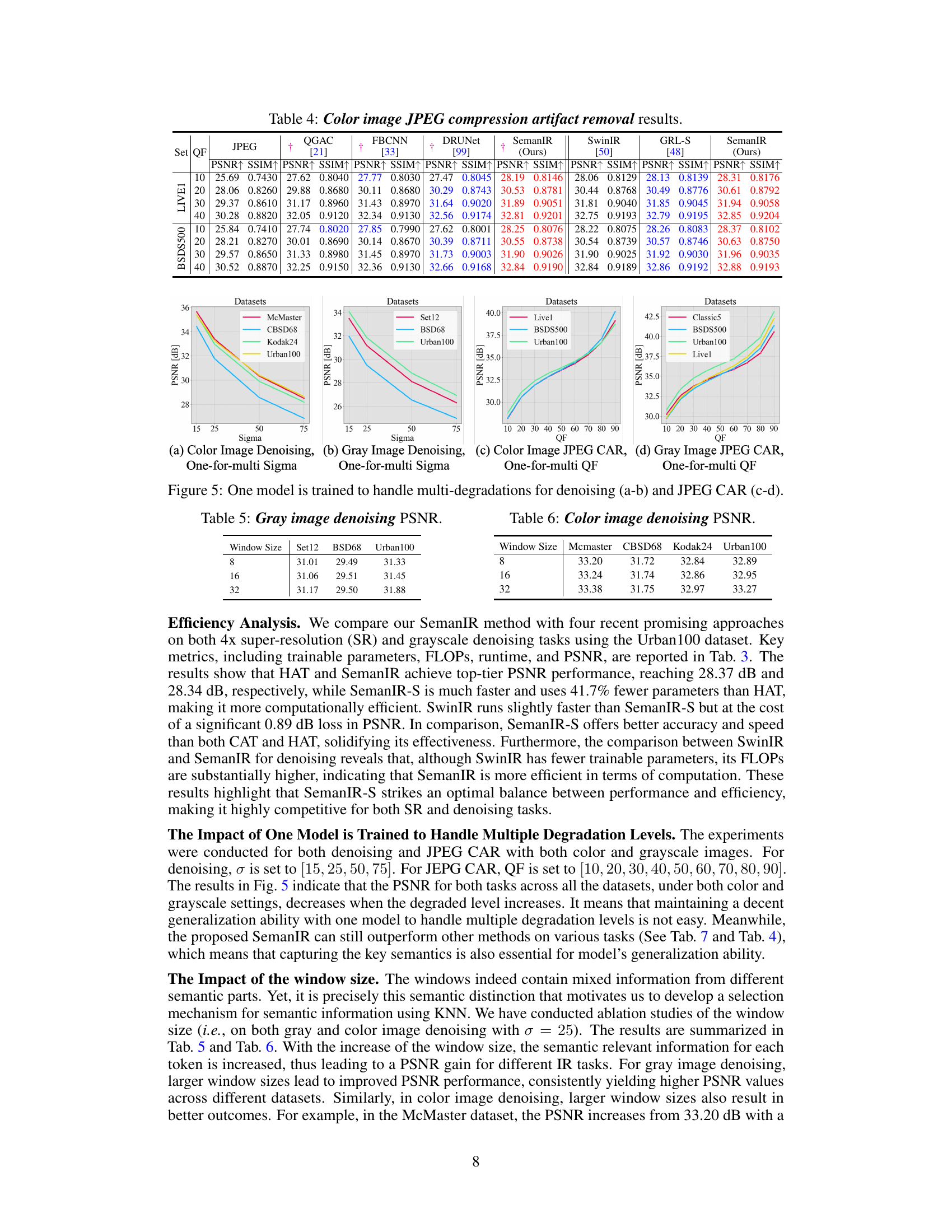
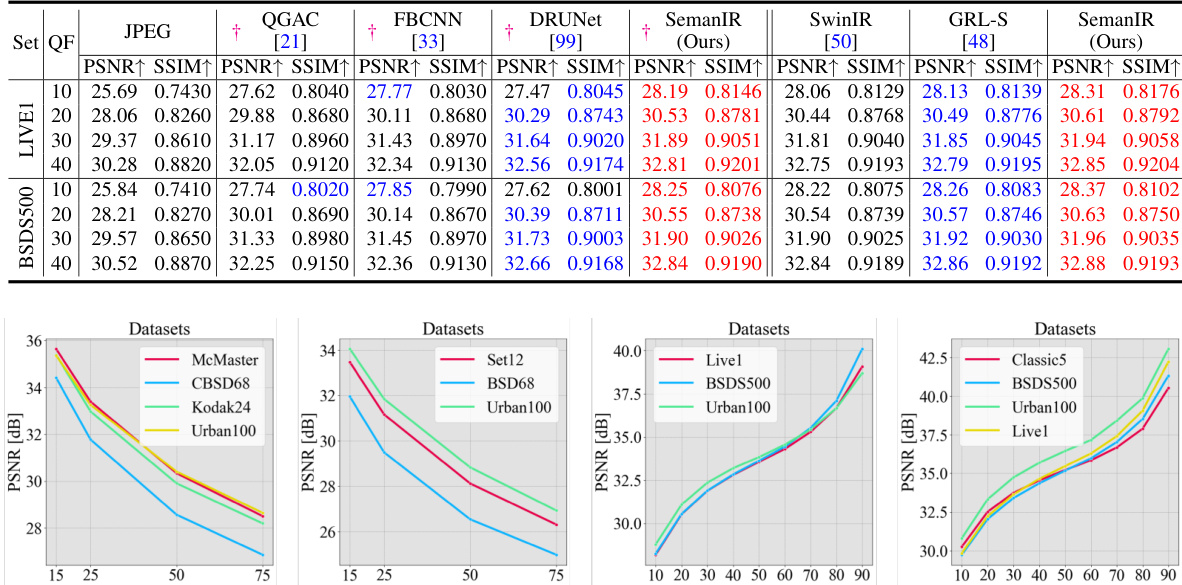
This figure compares the performance of different methods (DRUNet, SwinIR, GRL, and SemanIR) on the task of JPEG compression artifact removal. The results are shown for six different images from the Urban100 dataset. Each row represents a different image, and the columns show the original image, results from each method, and the ground truth. The figure highlights the effectiveness of SemanIR in restoring image quality and reducing compression artifacts.

This figure illustrates the architecture of the proposed SemanIR model for image restoration. It consists of three main components: a convolutional feature extractor, the main body of SemanIR (which can be either columnar or U-shaped depending on the task), and an image reconstructor. The columnar architecture is used for image super-resolution, while the U-shaped architecture is used for other image restoration tasks such as deblurring and denoising. The figure also shows a detailed view of the key-semantic transformer layer, highlighting the key-semantic dictionary construction and the attention mechanism.

This figure shows the U-shaped architecture used in SemanIR for image restoration tasks. It illustrates the flow of image features through convolutional layers, multiple SemanIR stages at different scales (downsampled and upsampled), and the final image reconstruction stage. This architecture is specifically used for JPEG CAR, image denoising, image demosaicking, IR in adverse weather conditions (AWC), and image deblurring. The arrows depict downsampling and upsampling operations, while symbols represent element-wise addition and concatenation.

This figure illustrates the architecture of the proposed SemanIR model for image restoration. It consists of three main components: a convolutional feature extractor, the main body (SemanIR) for representation learning which uses a columnar architecture for image super-resolution (SR) and a U-shaped architecture for other image restoration tasks, and an image reconstructor. The figure also shows details of the key-semantic transformer layer, including the key-semantic dictionary construction and the attention mechanism.

This figure shows a visual comparison of different image super-resolution (SR) methods on the Urban100 dataset at a scaling factor of 4x. It compares the results of SwinIR, ART, CAT-A, EDT, and SemanIR, highlighting the visual differences in terms of detail and structural preservation. It demonstrates the effectiveness of SemanIR in achieving a high-quality SR result.
More on tables
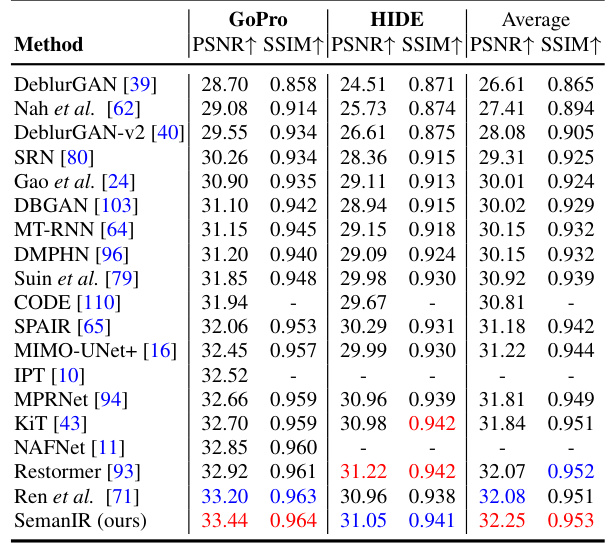
This table presents the results of single-image motion deblurring experiments. The GoPro dataset was used for training the models. The table compares various methods by their performance on the GoPro and HIDE datasets, measured using PSNR and SSIM metrics. Higher PSNR and SSIM values indicate better deblurring performance.

This table presents the quantitative results of single-image motion deblurring experiments. The GoPro dataset was used for training the models. The results are compared against several state-of-the-art methods, showing the PSNR and SSIM values achieved on the GoPro and HIDE test datasets. Higher PSNR and SSIM values generally indicate better image quality.

This table compares the efficiency of SemanIR with other state-of-the-art image restoration methods on the Urban100 dataset. The metrics used for comparison include the number of parameters (Params), floating point operations (FLOPs), runtime, and peak signal-to-noise ratio (PSNR). The results show that SemanIR achieves competitive PSNR performance while being faster and using fewer parameters than some comparable methods, highlighting its efficiency.
This table presents the results of single-image motion deblurring experiments. The GoPro dataset was used for training the models. The table shows the performance (PSNR and SSIM) of various methods on the GoPro and HIDE datasets, indicating how well each method can deblur images. Higher PSNR and SSIM values suggest better deblurring performance.
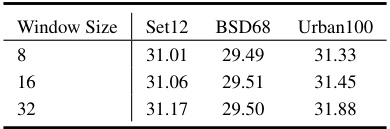
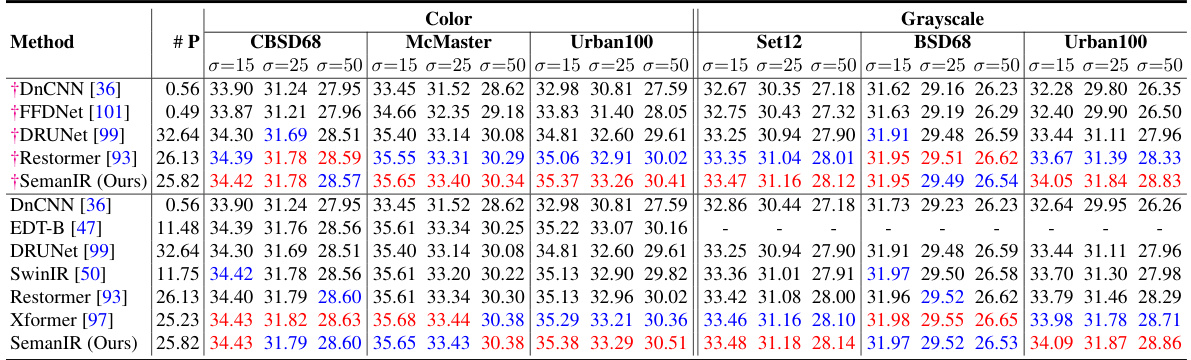
This table presents the Peak Signal-to-Noise Ratio (PSNR) values for gray image denoising. The PSNR is a metric used to evaluate the quality of reconstructed images compared to the ground truth, with higher values indicating better quality. The table shows the PSNR values for three different datasets (Set12, BSD68, Urban100) and three different window sizes (8, 16, 32).
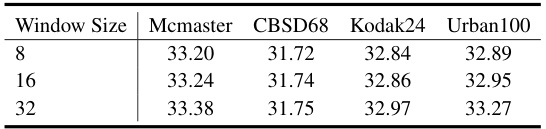
This table presents the Peak Signal-to-Noise Ratio (PSNR) results for color image denoising on four datasets (Mcmaster, CBSD68, Kodak24, Urban100) using three different window sizes (8, 16, 32). It demonstrates the impact of window size on denoising performance.
This table presents the quantitative results of single image motion deblurring experiments using the GoPro dataset for training. It compares the performance of SemanIR against other state-of-the-art methods on two standard metrics, PSNR and SSIM, across different datasets (GoPro and HIDE). The table shows the PSNR and SSIM scores achieved by each method, allowing for a direct comparison of their performance in deblurring images.

This table presents the quantitative results for image restoration in adverse weather conditions. Specifically, it compares the performance of several different methods (pix2pix, HRGAN, SwinIR, MPRNet, All-in-One, TransWea, and SemanIR) on three different datasets representing various adverse weather conditions: Test1 (rain+fog), SnowTest100k-L (snow), and RainDrop (raindrops). The primary metric used for comparison is PSNR (Peak Signal-to-Noise Ratio), which measures the quality of the restored image.
This table presents the quantitative results for image restoration in adverse weather conditions. The results are reported for three different datasets: Test1 (rain+fog), SnowTest100k-L, and RainDrop. The metrics used are PSNR. The comparison methods include pix2pix [31], DesnowNet [52], AttGAN [66], MMNet [38], DDR [88], HRGAN [45], JSTASR [12], Quan [68], DeepJoint [26], SwinIR [50], MPRNet [94], RLDDR [29], DRUNet [99], All-in-One [46], RNAN [109], TransWea. [83], GRL [48], and SemanIR (Ours).

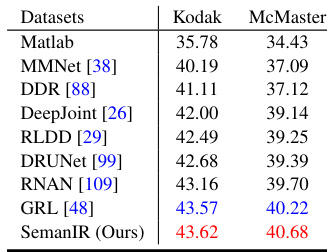
This table presents the performance of various classical image super-resolution (SR) models on four benchmark datasets (Set5, Set14, BSD100, and Urban100), along with the Manga109 dataset. The results are categorized by model, upscaling factor (2x or 4x), number of parameters, and Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) scores for each dataset. The table distinguishes between lightweight and accurate models, providing a comprehensive comparison of different SR approaches.

This table shows the number of SemanIR stages and the number of SemanIR layers within each stage for two different architectures: Archi-V1 (columnar shape) and Archi-V2 (U-shape). Archi-V1 is used for image super-resolution, while Archi-V2 is used for other image restoration tasks. The table provides details for two SemanIR variations: SemanIR-small and SemanIR-base, along with a breakdown of down stages, up stages, and a final stage for the U-shaped architecture.

This table compares the GPU memory usage of three different implementations (Triton, Torch-Gather, Torch-Mask) of the key-graph attention block in the SemanIR model. It shows how memory consumption varies with different numbers of tokens (N) and nearest neighbors (k). The results demonstrate that the Triton implementation has a smaller memory footprint than the other two, although it sacrifices some performance. This section provides insights into the efficiency of various attention mechanisms.
Full paper#