TL;DR#
Large Language Models (LLMs) are powerful but slow. Speculative decoding, which uses a draft model to predict text before final verification by the main LLM, is a promising approach to speed them up. However, current draft models often struggle with accuracy.
This paper introduces a new draft model based on Connectionist Temporal Classification (CTC). CTC helps the draft model generate more accurate predictions by considering the relationships between words, leading to higher acceptance rates. Experiments showed that this CTC-based model significantly outperformed existing methods in speed, achieving a higher acceptance rate and faster inference.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel method to accelerate large language model (LLM) inference using speculative decoding with a CTC-based draft model. This addresses a critical challenge in deploying LLMs for real-world applications where inference speed is crucial. The method’s superior performance over existing approaches and its potential for broader application make this a significant contribution to the field. It opens avenues for further research in designing more efficient draft models and exploring various CTC applications within the speculative decoding framework.
Visual Insights#
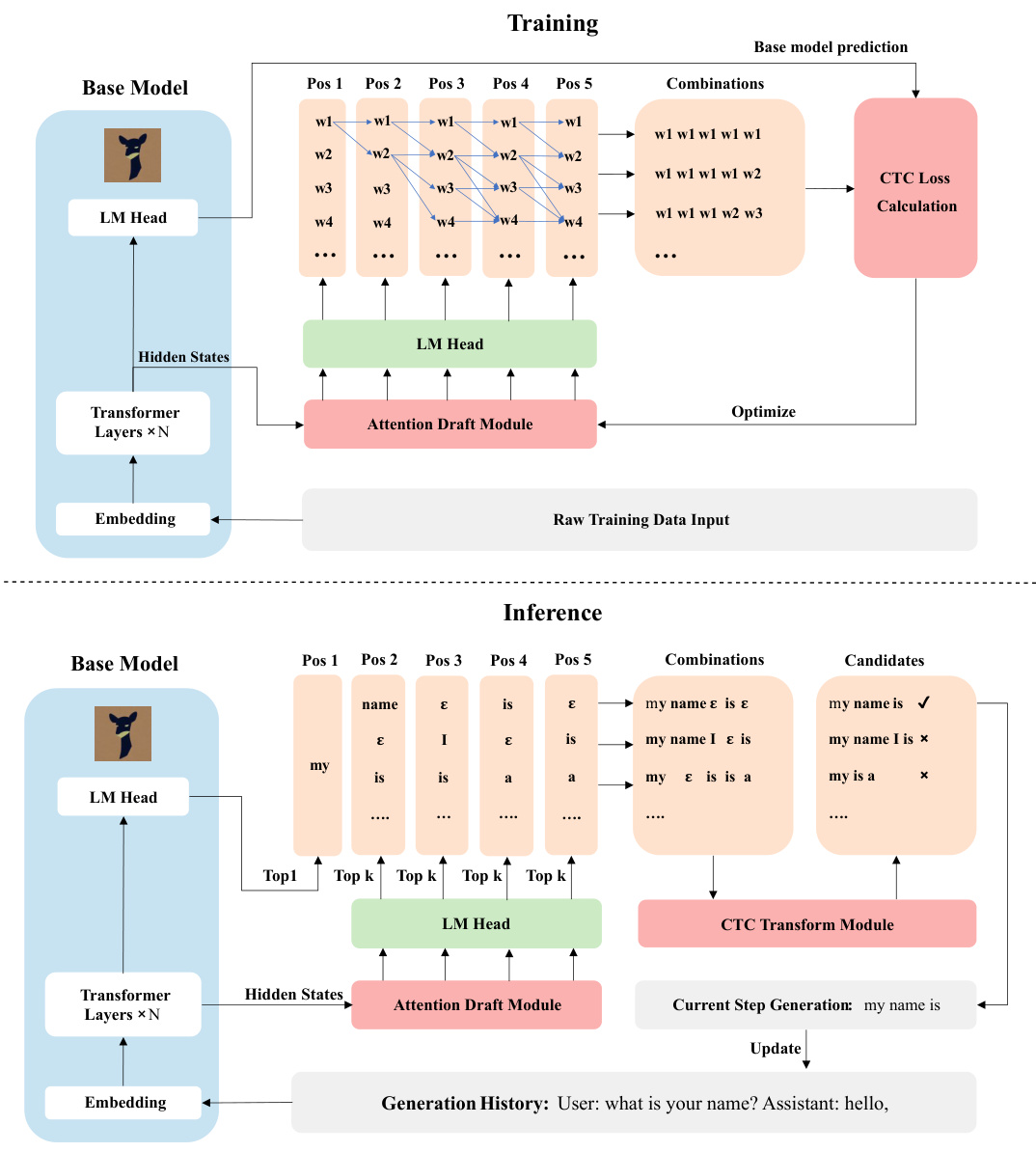
🔼 This figure illustrates the architecture and workflow of the CTC-drafter model, which is a novel approach for accelerating large language model inference. The figure shows two main parts: the training phase and the inference phase. In the training phase, the model learns to predict sequences of tokens using a connectionist temporal classification (CTC) loss function. In the inference phase, the CTC-drafter model generates candidate sequences of tokens, and these are then verified by a base language model. The overall aim of the architecture is to improve inference speed by generating higher-quality candidate sequences during the draft phase and achieving a higher acceptance rate.
read the caption
Figure 1: Illustration of CTC-drafter model training and inference strategy.

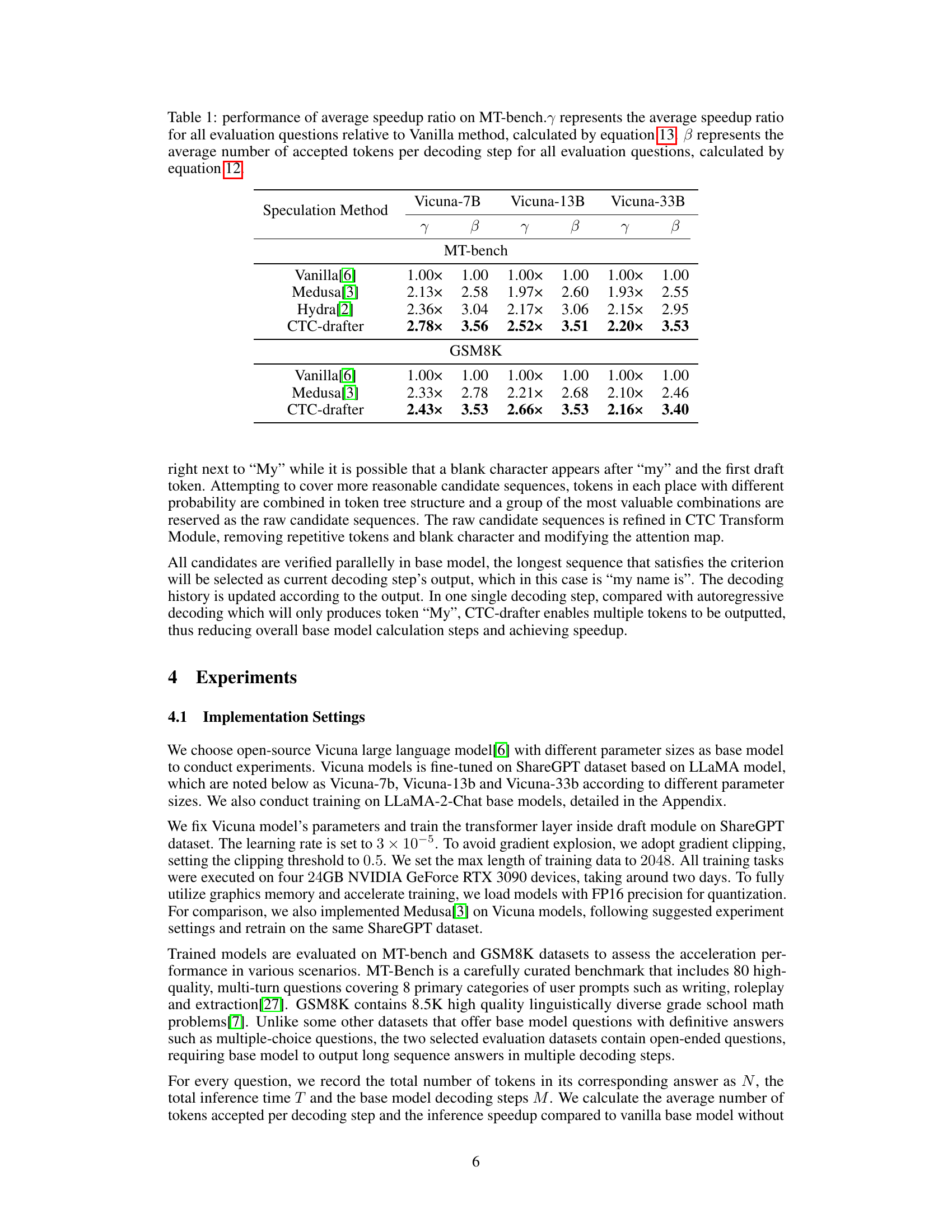
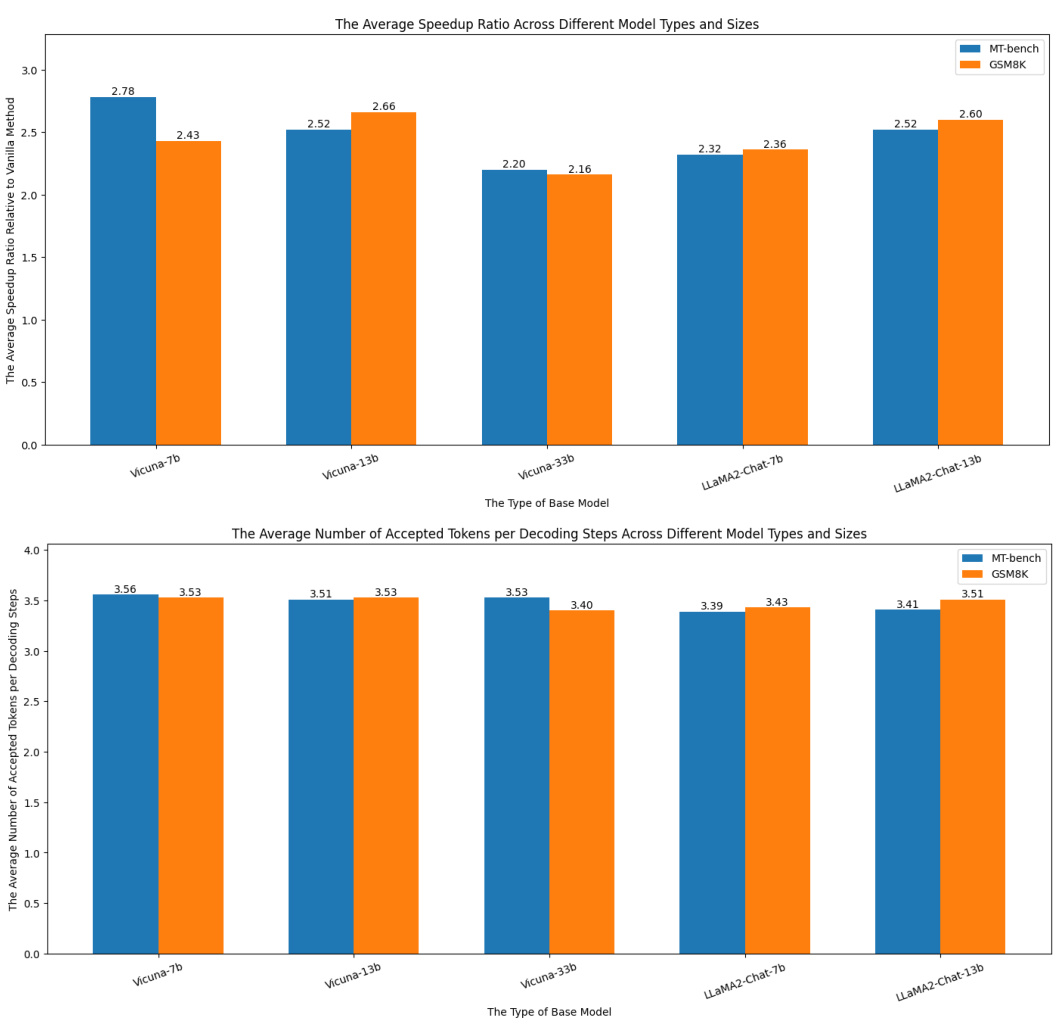
🔼 This table presents the average speedup and the average number of accepted tokens per decoding step achieved by different speculative decoding methods on the MT-bench benchmark, using various sizes of Vicuna language models. The speedup is calculated relative to a vanilla (autoregressive) decoding method. The results highlight the performance improvements of CTC-drafter compared to existing methods like Medusa and Hydra.
read the caption
Table 1: performance of average speedup ratio on MT-bench. represents the average speedup ratio for all evaluation questions relative to Vanilla method, calculated by equation 13. B represents the average number of accepted tokens per decoding step for all evaluation questions, calculated by equation 12.
In-depth insights#
CTC Draft Model#
The proposed CTC Draft Model offers a novel approach to accelerating Large Language Model (LLM) inference. By leveraging Connectionist Temporal Classification (CTC), it aims to overcome the limitations of traditional non-autoregressive draft models which often suffer from low acceptance rates due to neglecting correlations between generated tokens. The CTC framework inherently models these dependencies, leading to higher-quality draft sequences and a higher likelihood of acceptance by the base LLM. This is crucial because the overall speedup achieved through speculative decoding is directly impacted by both the draft model’s speed and the acceptance rate. The paper suggests that by strengthening these inter-token relationships during the drafting phase, the model produces better candidates, thus directly contributing to faster inference. The use of CTC is a key innovation, differentiating this approach from existing methods and potentially leading to more robust and efficient LLM inference acceleration.
Speculative Decoding#
Speculative decoding is a powerful technique accelerating Large Language Model (LLM) inference. It introduces a draft model that generates candidate sequences, which are then verified by the base LLM. This approach is fundamentally different from traditional autoregressive decoding, which generates tokens one by one. The speed of inference depends on the draft model’s speed and the acceptance rate of its drafts. Improving the acceptance rate is key to performance gains. Methods like using non-autoregressive models as drafters offer speed but often sacrifice accuracy. The research paper explores strategies to improve the quality of draft sequences through methods like utilizing a CTC-based model, strengthening correlations between tokens, and achieving higher acceptance rates and thus faster inference speeds. The approach highlights a trade-off between speed and accuracy, emphasizing the importance of balancing both for practical applications.
Inference Speedup#
The research paper explores inference acceleration for Large Language Models (LLMs) by employing speculative decoding with a novel CTC-based draft model. The core idea is to enhance the speed of inference by improving the acceptance rate of draft tokens generated by a faster draft model, rather than solely focusing on the draft model’s speed. The CTC-based draft model strengthens correlations between draft tokens, resulting in higher-quality candidate sequences and a higher acceptance rate by the base LLM. This approach addresses the inherent trade-off between draft model speed and accuracy. Experimental results demonstrate that the proposed method achieves a significantly higher acceptance rate compared to existing approaches, leading to faster inference speeds across various LLMs and datasets. The effectiveness is shown through improvements in both speedup ratio and the average number of accepted tokens per decoding step, highlighting the practical benefits of the proposed method for accelerating LLM inference in real-world applications. A key contribution is the introduction of the CTC algorithm to the speculative decoding framework, which is novel and contributes to improvements in both the quality and speed of draft generation.
Ablation Studies#
Ablation studies systematically remove or deactivate components of a model to understand their individual contributions. In this context, it would involve selectively disabling parts of the proposed CTC-based draft model or its training process (e.g., removing the CTC loss function, altering the attention mechanism within the draft module, using a different verification strategy) to isolate their impact on the overall performance (speed and acceptance rate). By observing how performance changes after each ablation, the researchers would gain insights into the relative importance and effectiveness of each component. For instance, removing the CTC loss might reveal its contribution to generating high-quality draft sequences, while altering the attention mechanism would indicate its role in capturing long-range dependencies. Similarly, experimenting with alternate verification methods would highlight the contribution of the current verification strategy to the speedup. The results of these experiments would ideally reveal whether the key design choices were critical for the success of the proposed model or whether simpler alternatives could achieve comparable performance. This rigorous methodology increases confidence in the results and demonstrates the model’s robustness by showing which components are essential to its functionality and which are dispensable or replaceable.
Future Works#
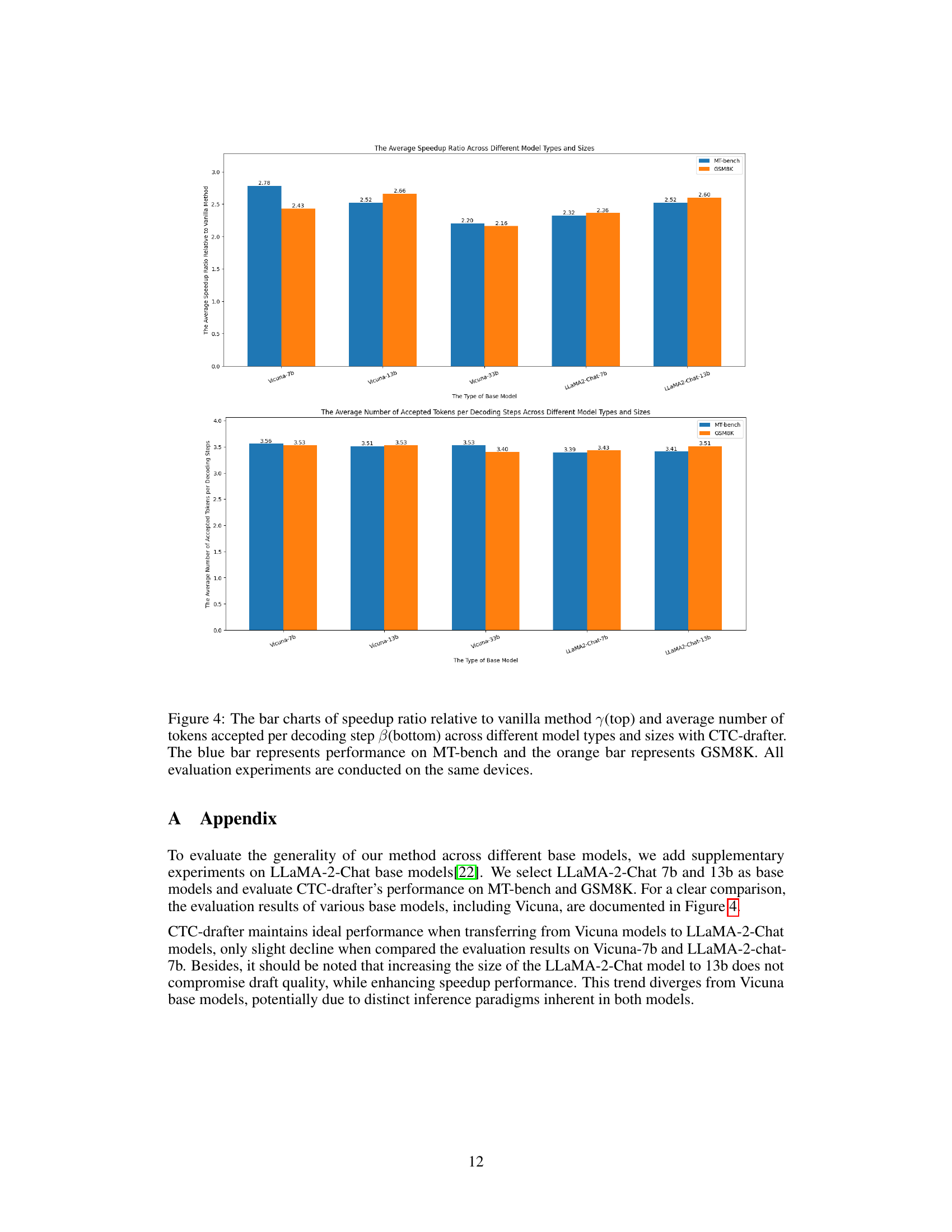
The paper’s discussion on “Future Works” would benefit from a more concrete and detailed exploration of several key areas. Addressing the limitations of the CTC-based draft model, such as its dependence on the quality of the base model and potential challenges in handling complex or nuanced language, is crucial. Exploring alternative architectures, possibly incorporating other sequence modeling techniques beyond CTC, to enhance the robustness and generalizability of the draft model is also highly recommended. Furthermore, a deeper dive into optimization strategies is warranted. Investigating advanced methods for balancing the speed and accuracy trade-offs inherent in speculative decoding, and exploring different verification criteria beyond the currently employed method, could significantly improve performance. Finally, a broader empirical evaluation is needed. Testing the approach on a wider range of tasks and datasets, with a more comprehensive analysis of the results, would strengthen the claims of the paper and establish a stronger foundation for future research in LLM inference acceleration. Investigating the effects of different base model sizes and the scaling behavior of the approach would be particularly valuable.
More visual insights#
More on figures
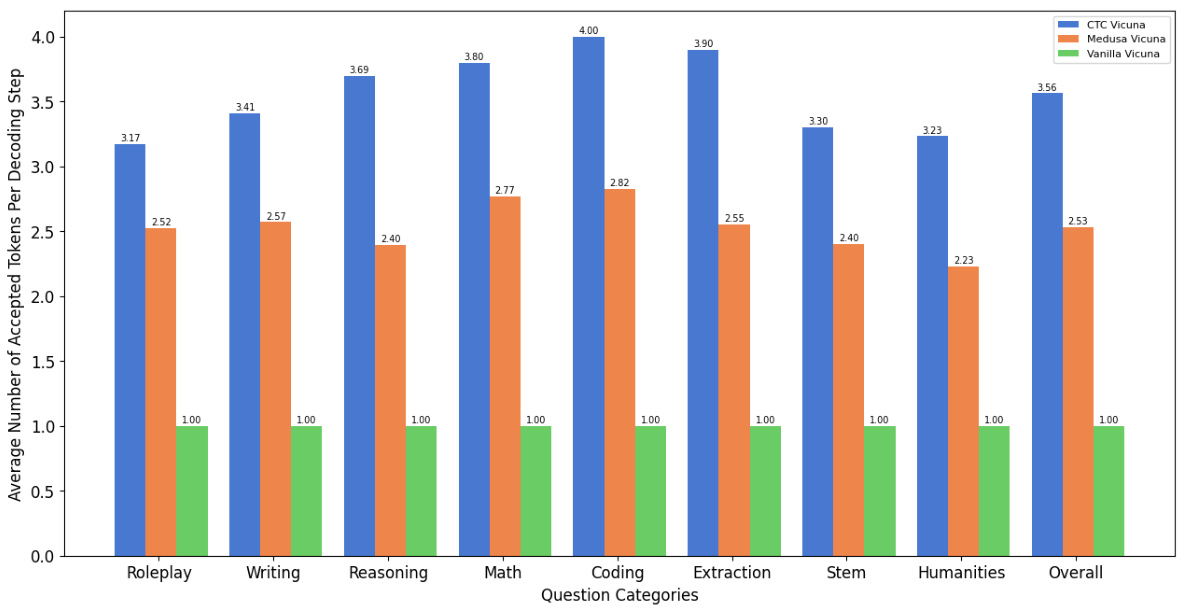
🔼 This figure shows the average number of tokens accepted per decoding step for different question categories in the MT-bench dataset. Three methods are compared: CTC-drafter (blue), Medusa (orange), and Vanilla (green). The results are shown for Vicuna-7B, but the trends are consistent across different Vicuna model sizes (7B, 13B, 33B). The chart illustrates the relative performance of each method across various question types, indicating how effectively each approach predicts multiple tokens simultaneously.
read the caption
Figure 2: Average number of tokens accepted per decoding step in different question categories on MT-bench, with Vicuna-7B as base model. The performance on Vicuna-13B and Vicuna-33B is consistent with this result. The blue color represents CTC-drafter method, orange color represents Medusa method and green color represents baseline. All evaluation experiments are conducted on the same device.

🔼 This figure illustrates the architecture and training/inference procedures of the proposed CTC-drafter model. The training process shows the base model’s output feeding into an attention draft module that generates draft tokens using the CTC algorithm. These tokens are combined, and the resulting sequences are used to calculate the CTC loss. The inference process similarly shows how the draft tokens are generated from the base model using the attention draft module, these tokens undergo CTC transformation, and candidate sequences are produced to improve speed and accuracy.
read the caption
Figure 1: Illustration of CTC-drafter model training and inference strategy.
🔼 This figure illustrates the architecture and training/inference processes of the CTC-drafter model. The training process shows how the base model’s hidden states are fed into an attention draft module, which uses a CTC loss function to predict probability distributions of draft tokens. These draft tokens are then combined to create candidate sequences that are verified by the base model. The inference process is similar, but instead of training, the draft module generates candidates that are verified and accepted or rejected by the base model. This allows for faster inference compared to traditional methods.
read the caption
Figure 1: Illustration of CTC-drafter model training and inference strategy.
Full paper#