TL;DR#
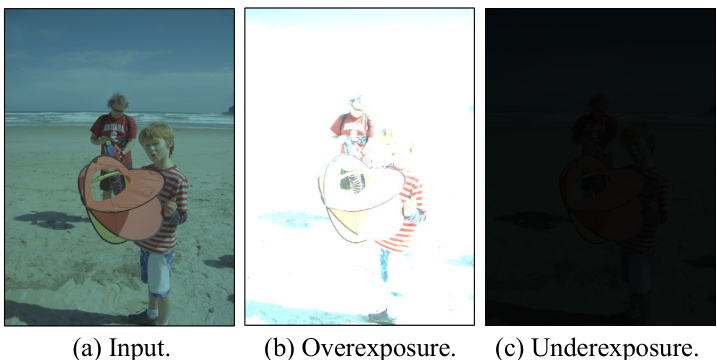
Traditional Image Signal Processors (ISPs) are often statically designed, limiting their effectiveness for computer vision tasks like object detection which demands dynamic adaptation. Existing methods for optimizing ISPs primarily focus on maximizing image quality, neglecting the impact on high-level vision tasks. This leads to suboptimal performance, particularly in dynamic scenes with varying lighting and conditions.
AdaptiveISP tackles this by employing deep reinforcement learning. It automatically generates an optimal ISP pipeline and parameters for each image to maximize object detection accuracy. This task-driven and scene-adaptive approach dynamically balances detection performance and computational cost, significantly outperforming existing methods. Experimental results across multiple datasets highlight AdaptiveISP’s superior performance and adaptability to various detection challenges.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AdaptiveISP, a novel approach for optimizing image signal processing (ISP) pipelines for object detection. It addresses the limitations of existing methods by dynamically adapting the ISP pipeline based on scene conditions, leading to improved accuracy and efficiency, especially relevant in real-time applications like autonomous driving. The proposed method using reinforcement learning to optimize the ISP pipeline opens up new avenues for research in this area, bridging the gap between image quality and computer vision task performance.
Visual Insights#
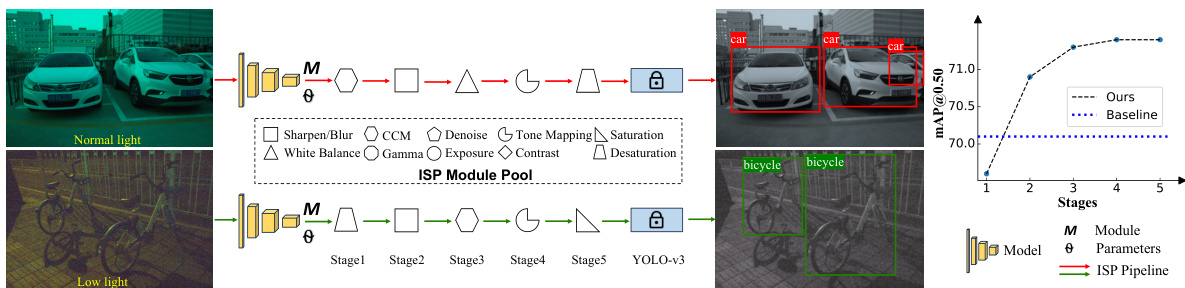
🔼 This figure illustrates the AdaptiveISP framework. AdaptiveISP takes a raw image as input and uses reinforcement learning to automatically determine the optimal Image Signal Processing (ISP) pipeline and parameters for a given object detection task. The figure shows examples of ISP pipelines generated for images under normal and low light conditions, highlighting the adaptability of the system. Quantitative results demonstrate the superior performance of AdaptiveISP compared to a baseline method with a fixed ISP pipeline.
read the caption
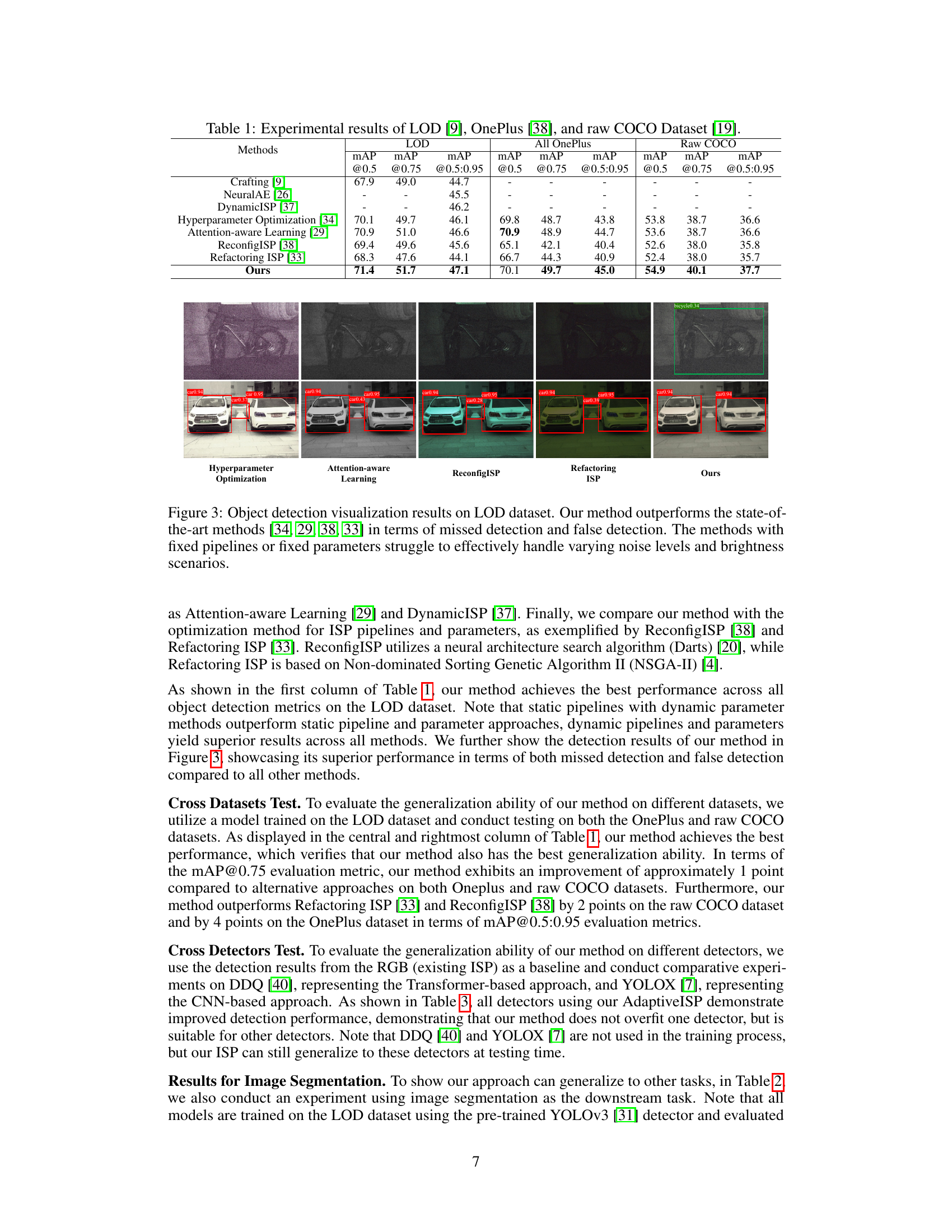
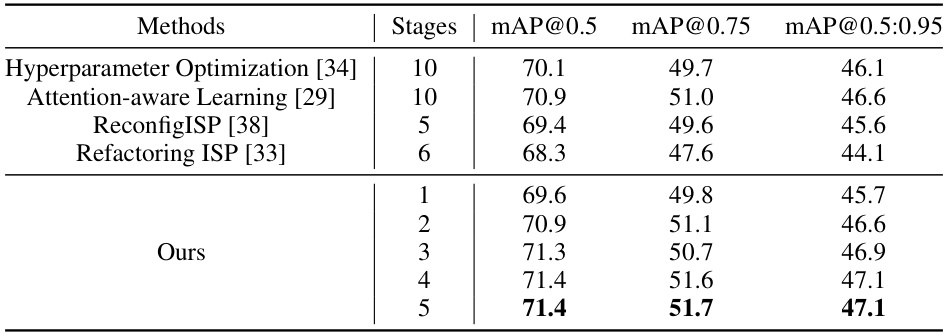
Figure 1: AdaptiveISP takes a raw image as input and automatically generates an optimal ISP pipeline {M} and the associated ISP parameters {Θ} to maximize the detection performance for any given pre-trained object detection network with deep reinforcement learning. AdapativeISP achieved mAP@0.5 of 71.4 on the dataset LOD dataset, while a baseline method [34] with a fixed ISP pipeline and optimized parameters can only achieve mAP@0.5 of 70.1. Note that AdaptiveISP predicts the ISP for the image captured under normal light requires a CCM module, while the ISP for the image captured under low light requires a Desaturation module.
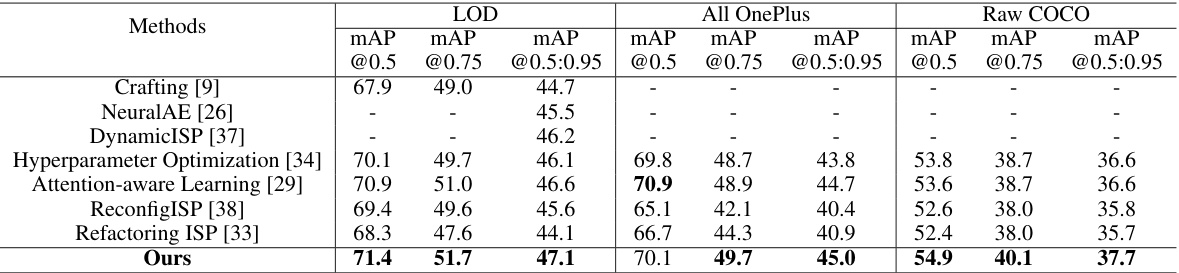
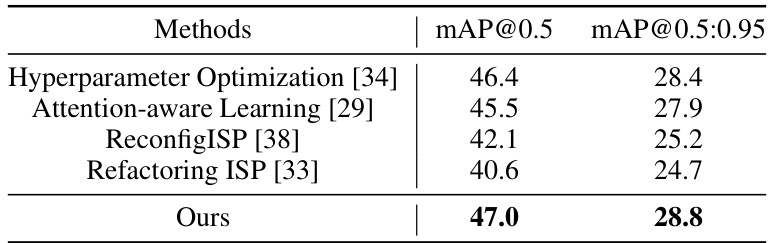
🔼 This table presents a comparison of the proposed AdaptiveISP method against several state-of-the-art methods for object detection on three different datasets: LOD, OnePlus, and raw COCO. The table shows the mean Average Precision (mAP) at different Intersection over Union (IoU) thresholds (@0.5, @0.75, and @0.5:0.95), providing a comprehensive evaluation of the methods’ performance under various conditions and datasets.
read the caption
Table 1: Experimental results of LOD [9], OnePlus [38], and raw COCO Dataset [19].
In-depth insights#
Adaptive ISP Design#
Adaptive ISP design represents a significant advancement in computer vision, moving beyond fixed image signal processing pipelines. The core idea is to dynamically adjust the ISP pipeline based on the input image and the specific task, such as object detection. This adaptability is crucial for handling diverse lighting conditions and scene complexities, improving the performance of downstream tasks. This approach typically leverages machine learning, such as reinforcement learning or deep learning, to learn optimal ISP configurations for different image characteristics. A key challenge lies in balancing accuracy and computational efficiency, as more complex pipelines generally yield better accuracy but come at higher computational cost. Therefore, algorithms often employ strategies to minimize unnecessary processing, focusing on the most critical aspects of the task at hand. Effective adaptive ISP design not only enhances downstream tasks, but also manages computational cost effectively, making the system suitable for real-time applications and resource-constrained environments.
RL-Based Optimization#
Reinforcement learning (RL) presents a powerful paradigm for optimizing complex systems, and its application to the domain of image signal processing (ISP) is particularly promising. RL’s ability to learn optimal strategies in dynamic and uncertain environments aligns perfectly with the challenges posed by real-world imaging conditions. An RL-based approach to ISP optimization would involve framing the task as a Markov Decision Process (MDP), where the agent (RL algorithm) selects ISP parameters (actions) based on the current image state (observations), aiming to maximize a reward function reflecting image quality or downstream task performance. This approach could automatically adapt to variations in lighting, scene content, and other factors, leading to superior image processing in diverse conditions. The design of the reward function is crucial; it needs to accurately capture the desired image characteristics. A key challenge involves managing the computational cost of RL training, which can be substantial. Efficient RL algorithms and careful problem formulation are essential to ensure practical applicability. Exploration-exploitation strategies must be carefully balanced to ensure both the discovery of effective ISP parameters and their efficient utilization in real-world settings. The success of RL-based ISP optimization hinges on the careful integration of domain-specific knowledge within the RL framework to guide the learning process.
Task-Driven ISPs#
Task-driven ISPs represent a paradigm shift in image signal processing, moving away from the traditional focus on perceptual image quality towards optimization for specific downstream computer vision tasks. Instead of aiming for generally pleasing images, task-driven ISPs tailor their image processing pipeline and parameters to enhance the performance of a target application, such as object detection or image recognition. This targeted approach acknowledges that the ideal image for human viewing may differ significantly from the optimal image for machine vision. A key advantage is the potential for improved accuracy and efficiency in computer vision systems. By directly optimizing the ISP for the task, task-driven methods can reduce computational overhead and improve the overall system performance. However, designing task-driven ISPs presents unique challenges. Determining the appropriate metrics for optimization and effectively balancing the trade-offs between image quality and task performance remain open research problems. Furthermore, the adaptability of such ISPs across diverse imaging conditions and scene variations needs to be thoroughly investigated.
Efficiency Tradeoffs#
The concept of “Efficiency Tradeoffs” in the context of AdaptiveISP is crucial. The system dynamically balances detection accuracy and computational cost. This is achieved by controlling a parameter (λ) which weighs the importance of computation time in the reward function of the reinforcement learning process. A higher λ penalizes longer ISP pipelines, pushing the model to prioritize speed, potentially at the cost of some accuracy. Conversely, a lower λ emphasizes accuracy, potentially leading to more computationally expensive pipelines. This flexible approach makes AdaptiveISP suitable for various scenarios; real-time applications might benefit from a higher λ to prioritize speed, while applications where accuracy is paramount could use a lower λ. The presented results demonstrate that AdaptiveISP successfully navigates this tradeoff, achieving state-of-the-art performance with a computationally efficient design. This dynamic adaptation is a key advantage, surpassing fixed-pipeline methods that cannot adjust to varying scene complexities.
Future Work: Scalability#
Future work on scalability for AdaptiveISP should prioritize addressing its computational demands, especially for high-resolution images and complex scenes. Exploring efficient network architectures and pruning techniques can reduce the model’s size and inference time. Parallel processing strategies could be investigated to distribute the computational load across multiple cores or GPUs. Adaptive computation is another potential direction, dynamically adjusting the ISP pipeline complexity based on scene demands and computational resources. This could involve techniques like early-exiting or selective module activation. Quantization techniques could minimize memory footprint and improve energy efficiency. Ultimately, scalability improvements are crucial for deploying AdaptiveISP in real-world, resource-constrained applications.
More visual insights#
More on figures

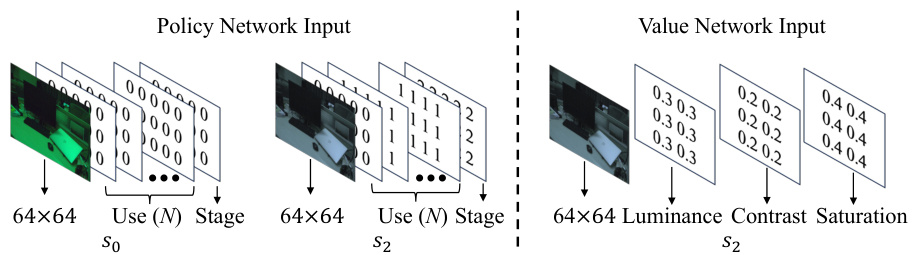
🔼 This figure illustrates the AdaptiveISP framework. The ISP configuration process is modeled as a Markov Decision Process (MDP). At each stage, a CNN-based policy network takes the current image state as input and outputs the optimal ISP module and its parameters (action). A CNN-based value network estimates the value of the state. The YOLOv3 object detection model provides a reward based on the detection performance after applying the chosen ISP module. The actor-critic algorithm is used to train both the policy and value networks, optimizing the entire system to select an optimal sequence of ISP modules for maximum detection accuracy.
read the caption
Figure 2: Overview of our method. The ISP configuration process is conceptualized as a Markov Decision Process, where a CNN-based policy network predicts the selection of ISP modules and their parameters. Concurrently, a CNN-based value network estimates the state value. The YOLO-v3 [31] is employed to calculate the reward for the current policy. The entire system is optimized using the actor-critic algorithm [15, 23].

🔼 This figure shows a comparison of object detection results on the Low-light Object Detection (LOD) dataset. The top row shows images with varying lighting and noise conditions. The bottom row shows the corresponding object detection results using different methods, including the proposed AdaptiveISP and several state-of-the-art baselines. The results highlight AdaptiveISP’s superior performance, particularly in handling challenging lighting conditions and noise.
read the caption
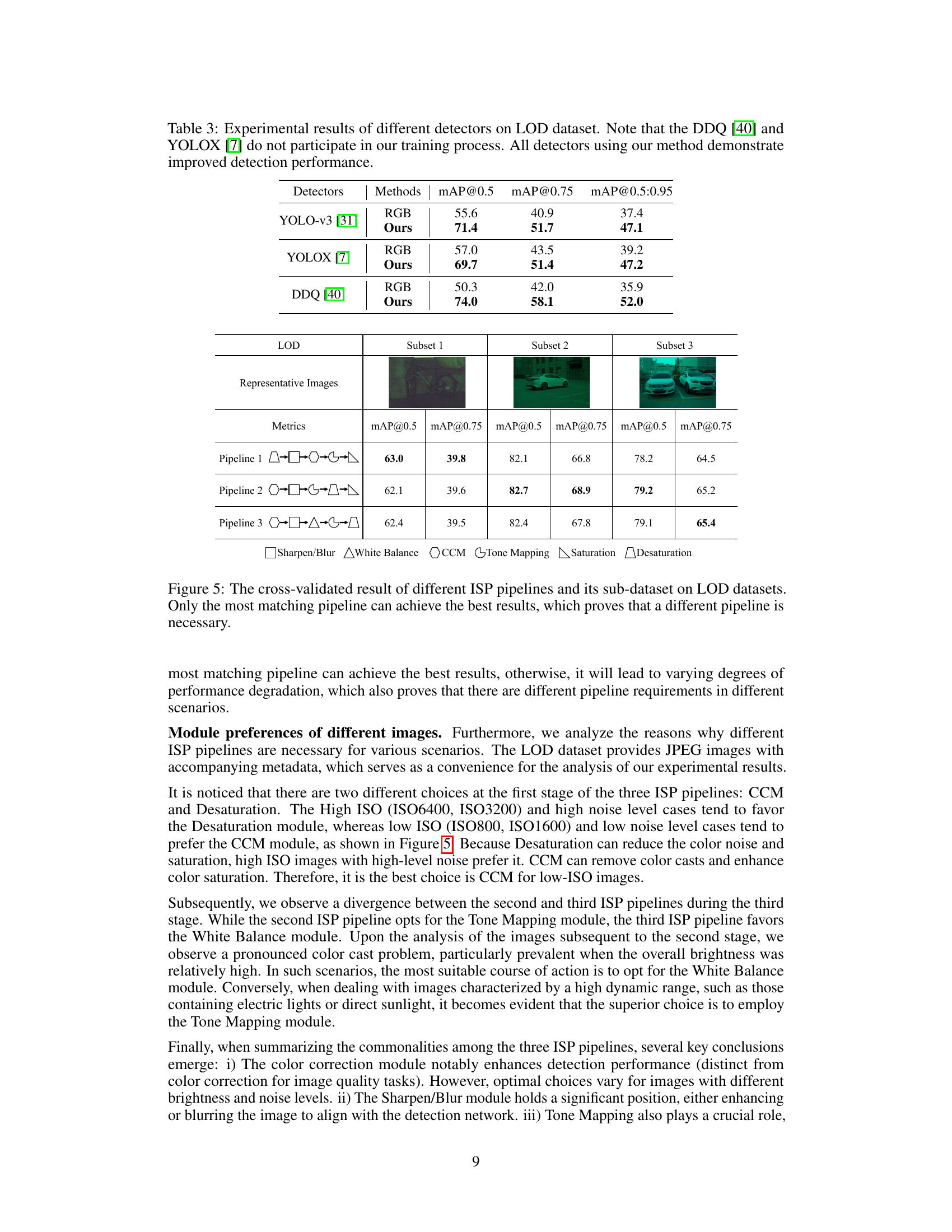
Figure 3: Object detection visualization results on LOD dataset. Our method outperforms the state-of-the-art methods [34, 29, 38, 33] in terms of missed detection and false detection. The methods with fixed pipelines or fixed parameters struggle to effectively handle varying noise levels and brightness scenarios.

🔼 This figure visualizes the object detection results of different methods on the Low-Light Object Detection (LOD) dataset. The top row shows images with a kite, and the bottom row shows images of a bridge. Each column represents a different method: Hyperparameter Optimization, Attention-aware Learning, ReconfigISP, Refactoring ISP, and the proposed AdaptiveISP method. The figure demonstrates that AdaptiveISP significantly outperforms the other methods in accurately detecting objects, even in challenging low-light conditions with varying noise and brightness levels. Methods with fixed ISP pipelines or fixed parameters are shown to struggle with these conditions.
read the caption
Figure 3: Object detection visualization results on LOD dataset. Our method outperforms the state-of-the-art methods [34, 29, 38, 33] in terms of missed detection and false detection. The methods with fixed pipelines or fixed parameters struggle to effectively handle varying noise levels and brightness scenarios.

🔼 This figure illustrates the AdaptiveISP framework. AdaptiveISP takes a raw image as input and uses deep reinforcement learning to automatically determine the optimal ISP pipeline and parameters for a given object detection task. The figure shows that AdaptiveISP dynamically adjusts its pipeline based on the input image (e.g., using a CCM module for normal lighting and a Desaturation module for low light), outperforming a baseline approach with a fixed ISP pipeline. The chart on the right shows the improvement in mean average precision (mAP) at IoU=0.5 as the number of ISP stages increases.
read the caption
Figure 1: AdaptiveISP takes a raw image as input and automatically generates an optimal ISP pipeline {M} and the associated ISP parameters {Θ} to maximize the detection performance for any given pre-trained object detection network with deep reinforcement learning. AdapativeISP achieved mAP@0.5 of 71.4 on the dataset LOD dataset, while a baseline method [34] with a fixed ISP pipeline and optimized parameters can only achieve mAP@0.5 of 70.1. Note that AdaptiveISP predicts the ISP for the image captured under normal light requires a CCM module, while the ISP for the image captured under low light requires a Desaturation module.

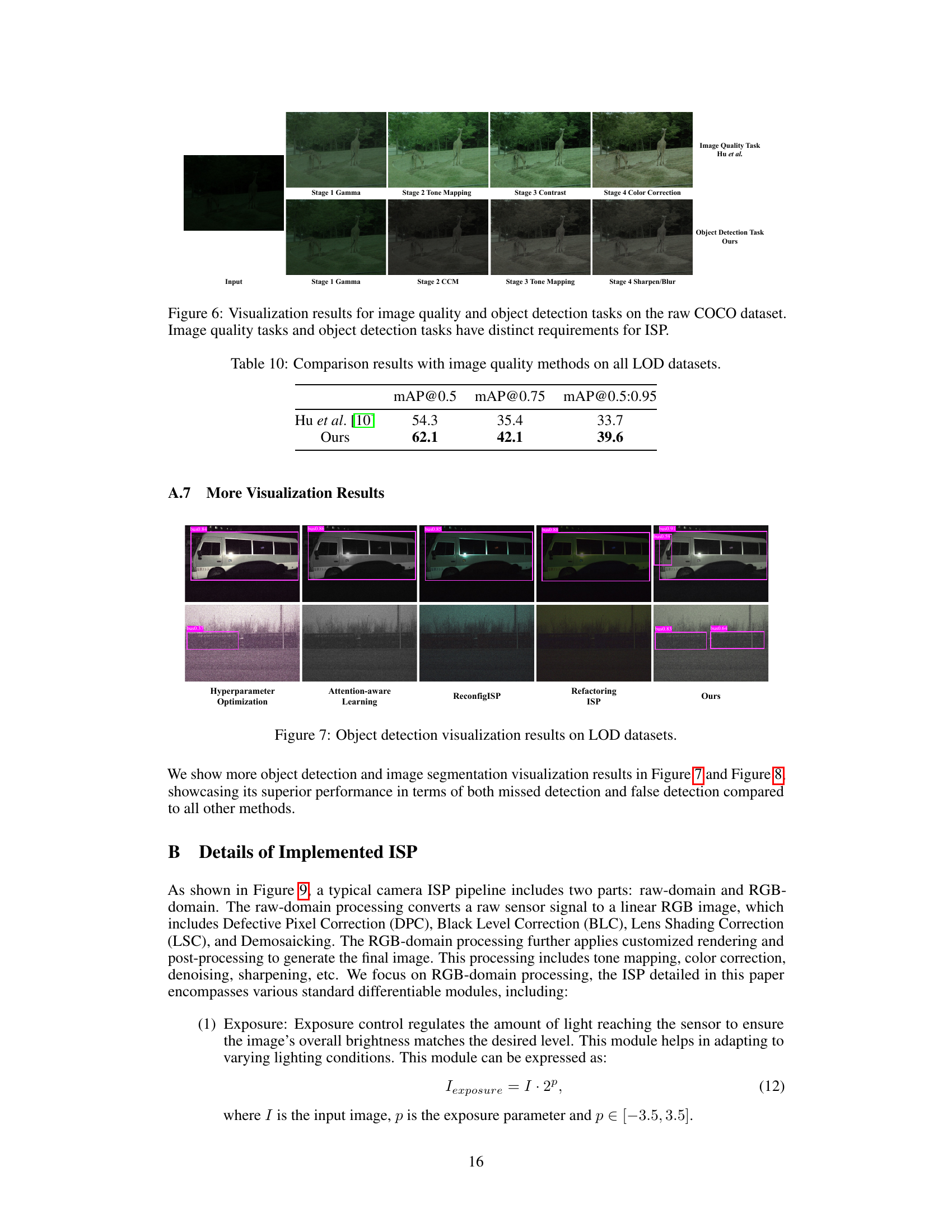
🔼 This figure shows a comparison of image processing pipelines for image quality and object detection tasks. The top row demonstrates the steps of a pipeline optimized for image quality, starting from a raw input image and progressing through gamma correction, tone mapping, contrast adjustment, and color correction. The resulting image exhibits enhanced visual appeal. The bottom row shows the steps for a pipeline designed for object detection, starting with the same raw input. This pipeline employs different modules, namely Gamma correction, CCM, tone mapping, and sharpen/blur. The output in this case is optimized for effective object detection rather than visual appeal. The key takeaway is that different computer vision tasks (image quality versus object detection) require distinct image signal processing (ISP) pipelines.
read the caption
Figure 6: Visualization results for image quality and object detection tasks on the raw COCO dataset. Image quality tasks and object detection tasks have distinct requirements for ISP.

🔼 This figure visualizes object detection results on the Low-light Object Detection (LOD) dataset. It compares the performance of AdaptiveISP against several state-of-the-art methods. The results show that AdaptiveISP significantly reduces missed and false detections compared to other methods that use fixed ISP pipelines or parameters. This improved performance is particularly noticeable in scenarios with varying levels of noise and brightness, highlighting AdaptiveISP’s adaptability to dynamic lighting conditions.
read the caption
Figure 3: Object detection visualization results on LOD dataset. Our method outperforms the state-of-the-art methods [34, 29, 38, 33] in terms of missed detection and false detection. The methods with fixed pipelines or fixed parameters struggle to effectively handle varying noise levels and brightness scenarios.

🔼 This figure visualizes the object detection results of different methods on the LOD dataset. It highlights the superior performance of the proposed AdaptiveISP method compared to four state-of-the-art baselines (Hyperparameter Optimization [34], Attention-aware Learning [29], ReconfigISP [38], and Refactoring ISP [33]). The visualization shows that AdaptiveISP achieves better results in terms of both missed and false detections, especially in challenging scenarios with varying noise levels and brightness. The baselines, using fixed pipelines or parameters, struggle to accurately detect objects under these varied conditions, demonstrating the advantage of AdaptiveISP’s dynamic adaptation.
read the caption
Figure 3: Object detection visualization results on LOD dataset. Our method outperforms the state-of-the-art methods [34, 29, 38, 33] in terms of missed detection and false detection. The methods with fixed pipelines or fixed parameters struggle to effectively handle varying noise levels and brightness scenarios.

🔼 This figure illustrates the AdaptiveISP framework. It takes a raw image as input and uses deep reinforcement learning to automatically determine the optimal Image Signal Processor (ISP) pipeline and parameters for object detection. The optimal pipeline dynamically adapts based on image characteristics (e.g., lighting conditions). The figure shows examples of ISP pipelines generated for images under different lighting conditions, highlighting the adaptive nature of the system. Performance is shown to improve over existing state-of-the-art approaches.
read the caption
Figure 1: AdaptiveISP takes a raw image as input and automatically generates an optimal ISP pipeline {M} and the associated ISP parameters {Θi} to maximize the detection performance for any given pre-trained object detection network with deep reinforcement learning. AdapativeISP achieved mAP@0.5 of 71.4 on the dataset LOD dataset, while a baseline method [34] with a fixed ISP pipeline and optimized parameters can only achieve mAP@0.5 of 70.1. Note that AdaptiveISP predicts the ISP for the image captured under normal light requires a CCM module, while the ISP for the image captured under low light requires a Desaturation module.
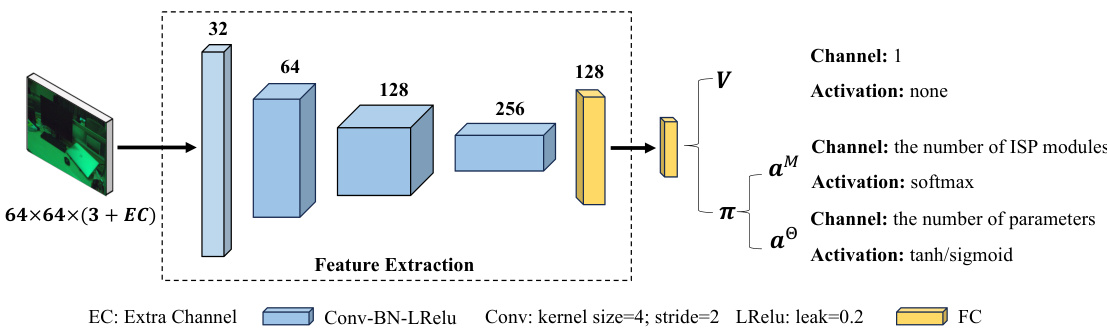
🔼 This figure shows the architecture of both the policy and value networks used in the AdaptiveISP method. The policy network predicts the selection of ISP modules and their parameters, while the value network estimates the state value. Both networks utilize convolutional layers (Conv-BN-LReLU) to extract features from the input image, with the number of channels increasing at each convolutional layer. The input to the networks includes the image features (64x64x3) and additional information provided via the extra channel (EC). The policy network outputs the probabilities of selecting different ISP modules (softmax activation) and the associated parameters (tanh/sigmoid activation), while the value network outputs a single scalar representing the state value. The specific number of channels in the output layer is determined by the number of ISP modules and the number of parameters per module, respectively.
read the caption
Figure 10: The network architecture of the policy and value network in our method. The extra channel (EC) represents additional input that needs to be supplemented.
🔼 This figure illustrates the AdaptiveISP framework. It takes a raw image as input and uses deep reinforcement learning to automatically generate an optimal image signal processing (ISP) pipeline and parameters. The generated pipeline is tailored to maximize the object detection performance for a given pre-trained object detection network. The figure demonstrates AdaptiveISP’s adaptability to different lighting conditions (normal and low light), showcasing its ability to dynamically adjust the ISP pipeline and parameters to improve performance. The results show improved mean Average Precision (mAP) compared to a baseline method using a fixed ISP pipeline and optimized parameters.
read the caption
Figure 1: AdaptiveISP takes a raw image as input and automatically generates an optimal ISP pipeline {M} and the associated ISP parameters {Θi} to maximize the detection performance for any given pre-trained object detection network with deep reinforcement learning. AdapativeISP achieved mAP@0.5 of 71.4 on the dataset LOD dataset, while a baseline method [34] with a fixed ISP pipeline and optimized parameters can only achieve mAP@0.5 of 70.1. Note that AdaptiveISP predicts the ISP for the image captured under normal light requires a CCM module, while the ISP for the image captured under low light requires a Desaturation module.
🔼 This figure illustrates the AdaptiveISP architecture and its process. It shows how AdaptiveISP takes a raw image as input and uses deep reinforcement learning to automatically determine the optimal ISP pipeline (sequence of modules) and its parameters for a given object detection task. The example shows different optimal pipelines (and parameters) for images taken in normal and low light. AdaptiveISP outperforms a fixed ISP baseline by achieving a higher mean Average Precision (mAP) at 0.5 IoU threshold.
read the caption
Figure 1: AdaptiveISP takes a raw image as input and automatically generates an optimal ISP pipeline {M} and the associated ISP parameters {Θ} to maximize the detection performance for any given pre-trained object detection network with deep reinforcement learning. AdapativeISP achieved mAP@0.5 of 71.4 on the dataset LOD dataset, while a baseline method [34] with a fixed ISP pipeline and optimized parameters can only achieve mAP@0.5 of 70.1. Note that AdaptiveISP predicts the ISP for the image captured under normal light requires a CCM module, while the ISP for the image captured under low light requires a Desaturation module.
More on tables
🔼 This table presents the performance comparison of different methods on the raw COCO dataset for image segmentation task. The mAP@0.5 and mAP@0.5:0.95 metrics are used to evaluate the performance. The methods compared include Hyperparameter Optimization [34], Attention-aware Learning [29], ReconfigISP [38], Refactoring ISP [33], and the proposed AdaptiveISP method. The results show that AdaptiveISP achieves the best performance, outperforming other methods in both metrics.
read the caption
Table 2: Image Segmentation results on raw COCO datasets [19].

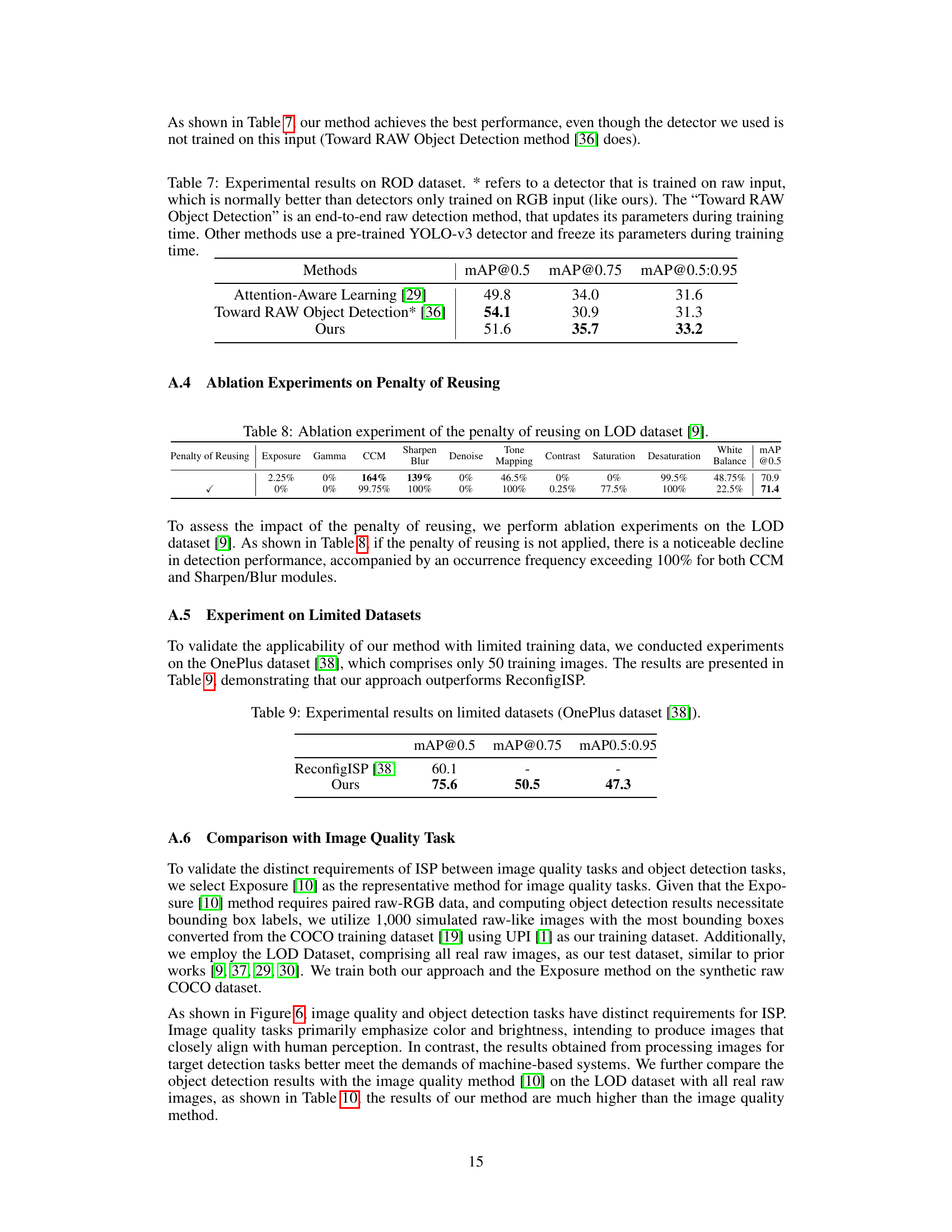
🔼 This table presents ablation study results on the impact of computational cost on the performance of the AdaptiveISP model. It shows the effect of different penalty coefficients (λc) on the selection of ISP modules and the overall performance (mAP@0.5, mAP@0.75, mAP@0.5:0.95) and total processing time. A λc of 0.0 prioritizes accuracy, while increasing λc emphasizes efficiency. The table demonstrates the trade-off between accuracy and speed achievable by AdaptiveISP by adjusting the λc parameter.
read the caption
Table 4: Experimental results considering computational cost on LOD dataset [9]. λc = 0.0 represents the accuracy-oriented, λc = 0.1 stands for efficiency-oriented. The total time represents the average running time of each sample. The efficiency-oriented method has a significant reduction in the average running time for each sample, which is accompanied by a slight decrease in performance. As λc increases, our method tends to favor faster-executing modules.
🔼 This table presents a comparison of the proposed AdaptiveISP method against several state-of-the-art ISP methods on three different datasets: LOD (low-light object detection), OnePlus (real-world low-light object detection), and raw COCO (synthetic raw images). The evaluation metric is mean Average Precision (mAP) calculated at different Intersection over Union (IoU) thresholds (0.5, 0.75, and 0.5:0.95). The results demonstrate the superior performance of AdaptiveISP in terms of object detection accuracy across all datasets and metrics.
read the caption
Table 1: Experimental results of LOD [9], OnePlus [38], and raw COCO Dataset [19].

🔼 This table presents the ablation study results on the necessity of using an Image Signal Processor (ISP) for object detection. It compares the performance of YOLO-v3 trained directly on raw images versus YOLO-v3 with the proposed AdaptiveISP method on the raw COCO dataset. The results demonstrate a significant performance improvement when using AdaptiveISP, highlighting the importance of ISP processing for object detection tasks.
read the caption
Table 6: Ablation experiment of the necessity of ISP on raw COCO dataset [19].

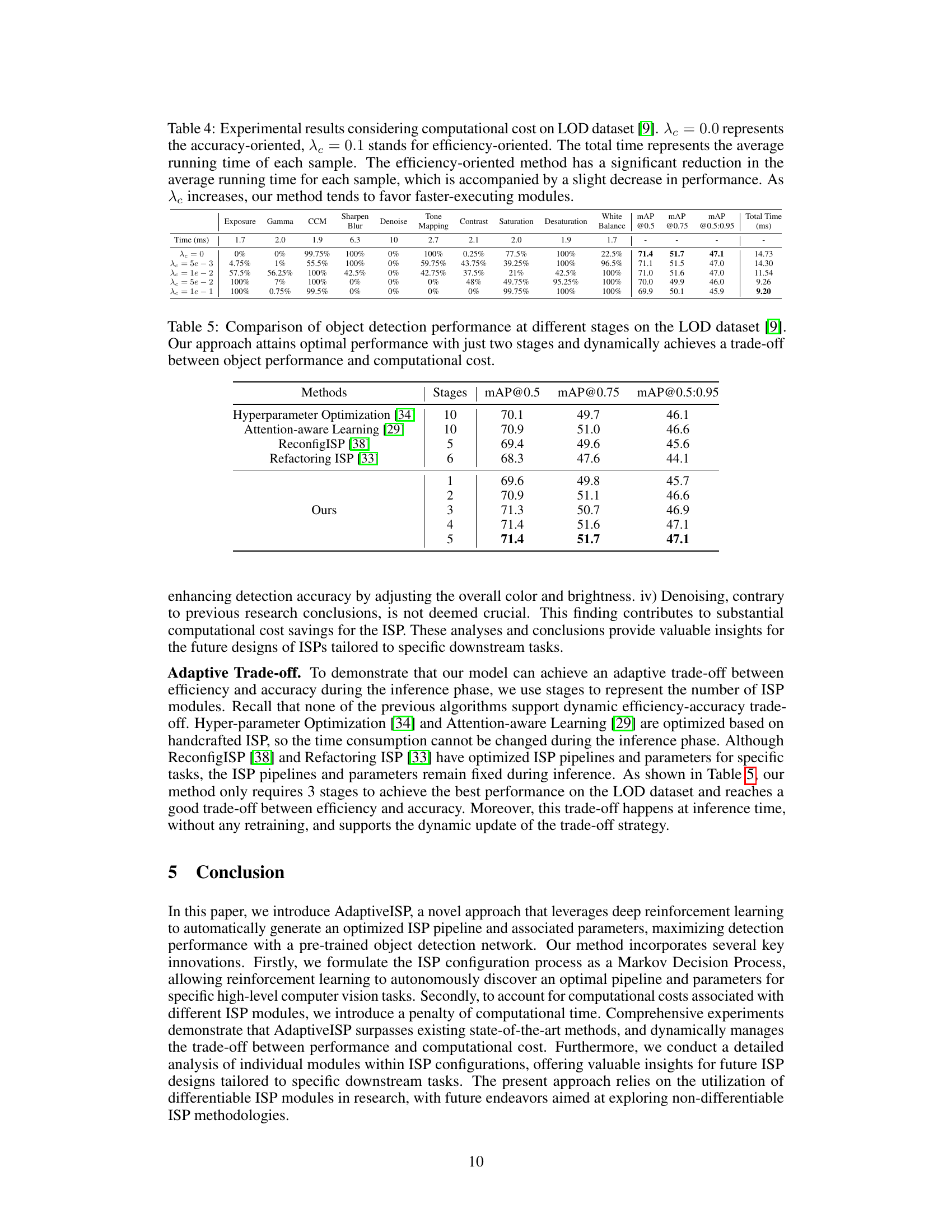
🔼 This table presents the experimental results on the ROD dataset for object detection. It compares three methods: Attention-Aware Learning, Toward RAW Object Detection (which is an end-to-end method trained directly on raw data, giving it an advantage), and the proposed AdaptiveISP method. The table shows the mean Average Precision (mAP) at different IoU thresholds (0.5, 0.75, and 0.5:0.95). The results indicate the performance of each method on the dataset.
read the caption
Table 7: Experimental results on ROD dataset. * refers to a detector that is trained on raw input, which is normally better than detectors only trained on RGB input (like ours). The 'Toward RAW Object Detection' is an end-to-end raw detection method, that updates its parameters during training time. Other methods use a pre-trained YOLO-v3 detector and freeze its parameters during training time.

🔼 This table presents ablation study results on the effect of considering computational cost in the model. It shows the impact of different penalty coefficients (λc) on the selection frequency of various ISP modules and the overall performance (mAP@0.5). The results demonstrate a trade-off between computational efficiency and accuracy. A higher λc leads to a shorter ISP pipeline with lower computational cost but slightly reduced accuracy.
read the caption
Table 4: Experimental results considering computational cost on LOD dataset [9]. λc = 0.0 represents the accuracy-oriented, λc = 0.1 stands for efficiency-oriented. The total time represents the average running time of each sample. The efficiency-oriented method has a significant reduction in the average running time for each sample, which is accompanied by a slight decrease in performance. As λc increases, our method tends to favor faster-executing modules.

🔼 This table presents the comparison of the proposed AdaptiveISP method against the ReconfigISP [38] method on the OnePlus dataset [38], which has a limited number of training images. The results are shown for mAP@0.5, mAP@0.75, and mAP@0.5:0.95, demonstrating the superior performance of AdaptiveISP even with limited training data.
read the caption
Table 9: Experimental results on limited datasets (OnePlus dataset [38]).

🔼 This table compares the performance of the proposed AdaptiveISP method against a state-of-the-art image quality method (Hu et al. [10]) on the LOD dataset. The comparison uses three standard metrics for object detection: mean Average Precision (mAP) at IoU thresholds of 0.5, 0.75, and the range 0.5-0.95. AdaptiveISP demonstrates significantly improved performance across all metrics compared to the image quality method, highlighting the superior effectiveness of the AdaptiveISP approach for object detection tasks.
read the caption
Table 10: Comparison results with image quality methods on all LOD datasets.
Full paper#