↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) are increasingly deployed in various applications, raising significant safety and ethical concerns. A major concern is how to make LLMs reliably refuse harmful requests, while maintaining their helpfulness for benign tasks. Current safety fine-tuning methods attempt to address this challenge, but their effectiveness is often unclear and their robustness is questionable. This lack of understanding hinders the development of truly safe and reliable LLMs.
This paper investigates the underlying mechanisms of refusal in LLMs by examining the internal representations of thirteen popular open-source models. Using a novel method based on analyzing the difference in model activations between harmful and harmless inputs, the authors discovered that refusal is controlled by a single, one-dimensional subspace. They demonstrated that removing this direction effectively disables refusal, while adding it induces refusal even on harmless requests. The authors also present a new ‘white-box’ jailbreak method that leverages this discovery to easily disable refusal with minimal impact on other capabilities. This method highlights the fragility of current safety fine-tuning techniques and offers valuable insights for developing more reliable safety mechanisms. Furthermore, a mechanistic analysis is conducted revealing that adversarial suffixes bypass refusal by suppressing the propagation of the critical direction.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals the surprising simplicity underlying LLMs’ refusal mechanisms. This brittleness challenges current safety fine-tuning approaches and opens new avenues for developing more robust and reliable safety methods. The findings are directly relevant to current concerns about LLM safety and responsible AI development, providing practical insights for researchers and developers alike.
Visual Insights#
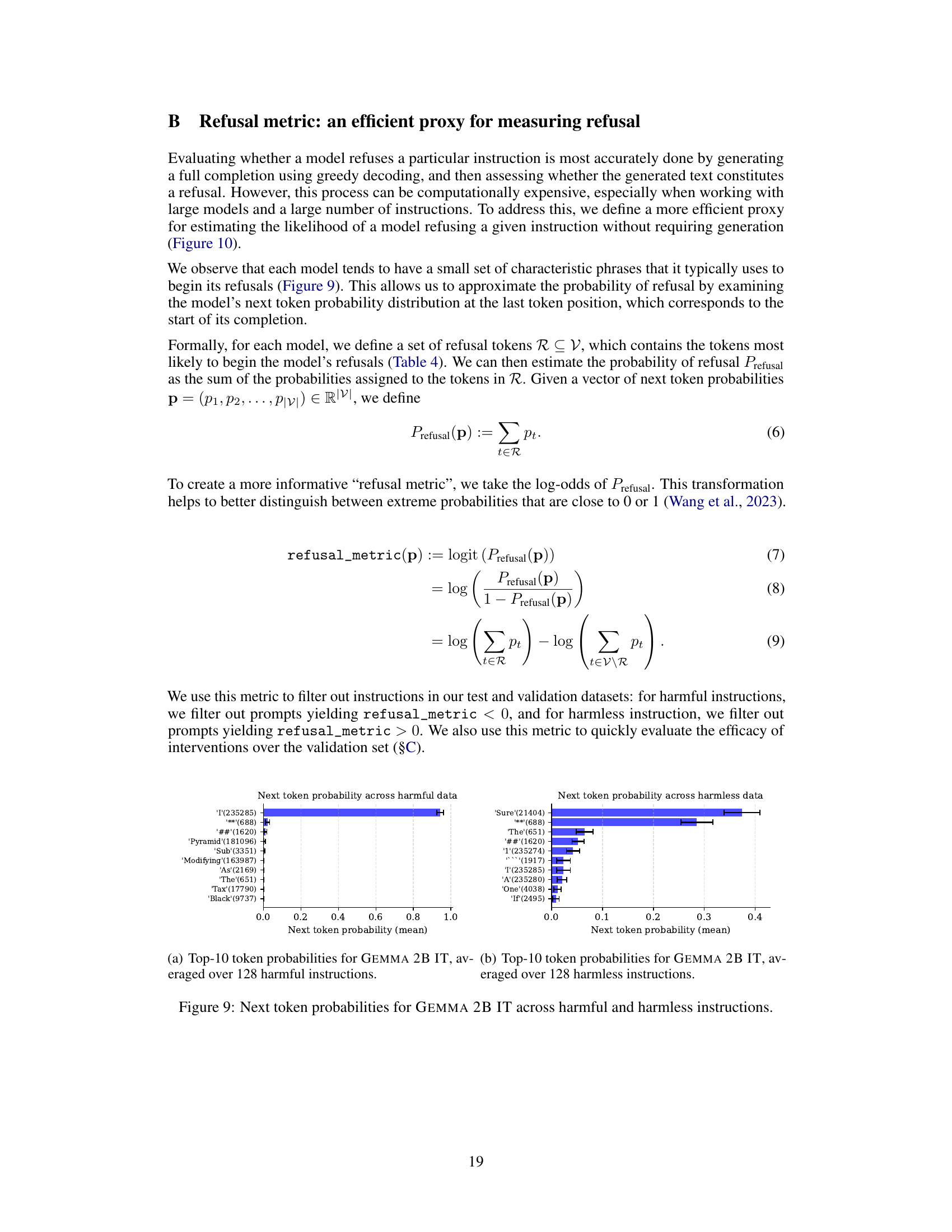
This figure shows the results of ablating the identified ‘refusal direction’ from 13 different large language models. The x-axis represents the different models, while the y-axis shows the refusal and safety scores. The bars are grouped into three conditions: no intervention, directional ablation (where the refusal direction is removed), and directional addition (where the refusal direction is added). The results demonstrate that ablating the refusal direction significantly reduces the model’s ability to refuse harmful instructions, leading to an increase in unsafe completions, while adding it causes refusal even on harmless instructions.
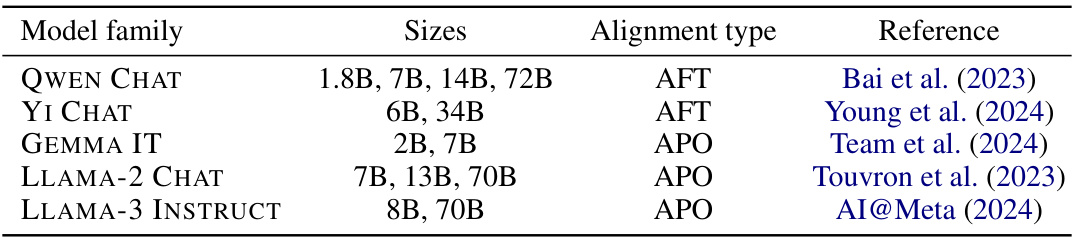
This table lists the different families of large language models (LLMs) used in the study, their sizes (in billions of parameters), the type of alignment training used (AFT: aligned by fine-tuning, APO: aligned by preference optimization), and the corresponding references to the papers where these models were introduced.
In-depth insights#
Refusal’s Mechanism#
The research paper explores the intriguing mechanism behind language models’ refusal of harmful requests. It posits that refusal isn’t a complex, multifaceted process but is surprisingly mediated by a single, low-dimensional direction within the model’s activation space. This direction acts as a kind of ‘refusal switch’: removing it eliminates refusal, even for harmful prompts, while enhancing it causes the model to refuse even benign ones. This discovery offers a powerful new perspective, suggesting that current safety fine-tuning methods might be overly complex and brittle. The study’s findings have significant implications for understanding and controlling model behavior, particularly in developing more robust safety mechanisms, and highlight the potential for simple, targeted interventions to precisely adjust the model’s risk profile.
Jailbreak via Weights#
A jailbreak via weights method offers a direct manipulation of a model’s internal parameters, bypassing the need for fine-tuning or adversarial prompts. This approach focuses on identifying and modifying specific weights associated with the model’s ‘refusal’ mechanism, effectively disabling its ability to reject harmful requests. The key advantage is its simplicity and efficiency, requiring fewer resources compared to fine-tuning or prompt engineering. However, it’s inherently a white-box technique, requiring access to the model’s internal weights, thereby limiting its practicality for closed-source models. Furthermore, the long-term effects on model functionality and coherence beyond simply removing refusal warrants further investigation. While potentially effective, the ethical implications necessitate careful consideration, as the method could unintentionally facilitate harmful outputs and contribute to a broader erosion of safety controls.
Suffixes’ Impact#
The impact of suffixes on language models, particularly concerning their ability to bypass safety mechanisms, is a crucial area of research. Adversarial suffixes, carefully crafted strings appended to prompts, can effectively trick models into generating harmful outputs despite safety fine-tuning. This highlights a vulnerability in current safety techniques. The study reveals that these suffixes achieve their effect by suppressing the activation of neurons or directions associated with refusal behavior. This suppression isn’t merely a matter of blocking specific words or phrases; it involves a more sophisticated manipulation of the model’s internal representation, possibly altering the pathways through which information flows. Therefore, a deeper understanding of how suffixes influence these internal representations is needed. Mechanistic interpretability techniques are vital in this process, enabling researchers to pinpoint precisely how adversarial suffixes interfere with safety mechanisms. This knowledge is key to improving model robustness and developing more effective methods for controlling unwanted behavior.
Limitations & Ethics#
A responsible discussion of limitations and ethical considerations is crucial for any AI research paper. Regarding limitations, acknowledging the scope of the study is essential. For example, if the research focuses on specific open-source models, it should explicitly state that the findings might not generalize to all models, especially proprietary ones or those at larger scales. Methodological limitations also require attention. If the process of identifying a key direction relies on heuristics, this should be clearly noted, emphasizing the need for future methodological improvements. Regarding ethics, it’s paramount to address potential misuse of the findings. Open-source model weights are already vulnerable to jailbreaking attacks, and the research should acknowledge the potential for simpler techniques to bypass safety measures. Furthermore, it’s vital to discuss the broader societal implications, both positive and negative, of the work. This includes examining the possibility of harmful uses and suggesting potential mitigation strategies, such as responsible release procedures. Finally, transparency regarding data and methods is crucial for reproducibility and fostering responsible innovation within the AI community.
Future Directions#
Future research could explore the universality of the single refusal direction across diverse LLMs, including proprietary models and those with significantly larger parameter counts. Investigating whether this direction is a fundamental property of language models or an artifact of training methodologies is crucial. Further exploration is warranted to unravel the precise semantic meaning of the refusal direction and its relationship to other model features. Mechanistically understanding how adversarial suffixes effectively suppress this direction remains a key challenge. Moreover, research should focus on the development of more robust safety fine-tuning techniques that are less susceptible to simple jailbreaks. A comparative analysis of different safety alignment methods, including those based on model internals versus those relying solely on prompt engineering, is vital. Finally, research into how the identified vulnerabilities could be leveraged to improve LLM safety is essential; this might involve developing methods for directly manipulating the model’s refusal direction in a controlled manner or designing more robust safety mechanisms.
More visual insights#
More on figures
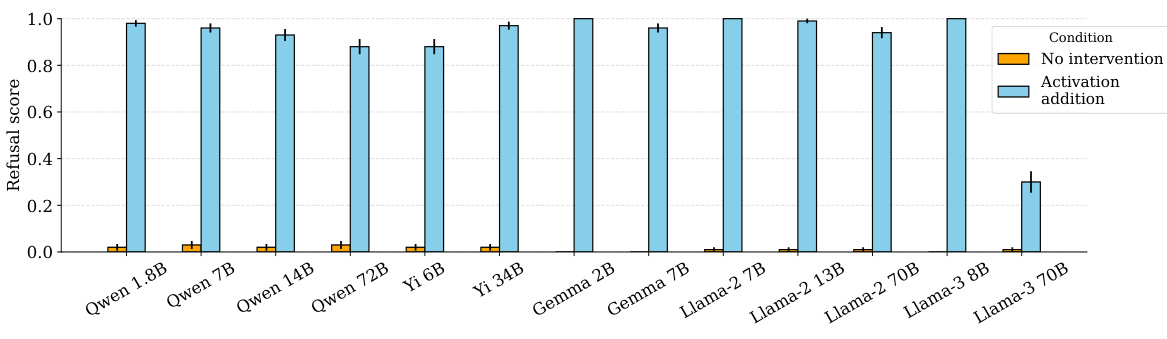
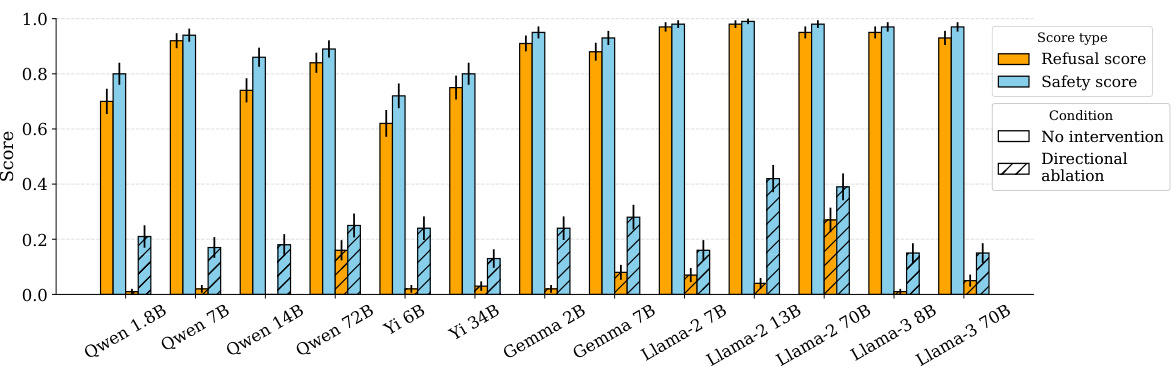
This figure shows the results of adding the identified ‘refusal direction’ to the residual stream activations of harmless instructions across 13 different large language models. The addition of this direction consistently caused the models to refuse to generate a response, even for benign prompts. The y-axis represents the refusal score (proportion of responses classified as refusals), while the x-axis shows the different models tested, ranging in size from 1.8B to 72B parameters. The orange bars represent the baseline refusal rate (without intervention), and the light blue bars show the refusal rate after adding the ‘refusal direction.’

This figure shows the results of adding the identified ‘refusal direction’ to the residual stream activations of harmless prompts. The experiment involved 100 harmless instructions from the ALPACA dataset. The chart displays the refusal score (the likelihood the model refuses to answer) for each of 13 different language models after the ‘refusal direction’ has been added. The results show that adding this direction causes the models to refuse to respond to the harmless prompts, even though they would have previously answered them without issue.

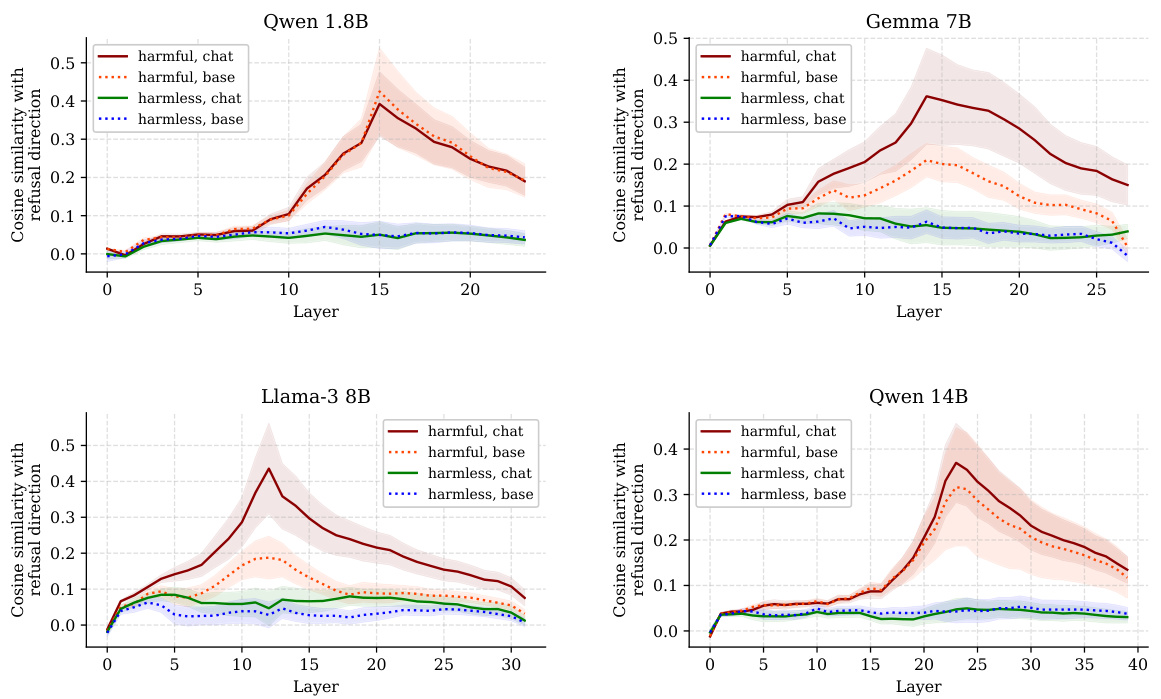
This figure displays cosine similarity between the last token’s residual stream activations and the refusal direction across different layers for four conditions: harmful instructions, harmful instructions with a random suffix, harmful instructions with an adversarial suffix, and harmless instructions. It demonstrates that the expression of the refusal direction is high for harmful instructions and remains high with a random suffix. However, appending the adversarial suffix substantially suppresses the refusal direction, making it closely resemble the expression for harmless instructions. This visually supports the paper’s claim that adversarial suffixes effectively suppress the refusal-mediating direction.

This figure analyzes the effect of adversarial suffixes on the attention heads of a language model. The top eight attention heads that contribute most to the refusal direction are examined. When an adversarial suffix is added, the figure shows a significant decrease in the output projection onto the refusal direction. Further, the attention shifts from the instruction region to the suffix region. This supports the theory that the adversarial suffix works by suppressing the propagation of the refusal-mediating direction.
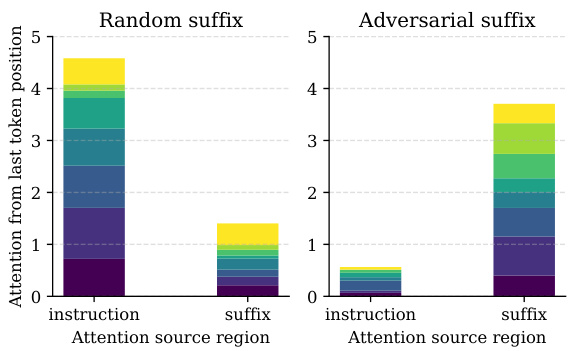
This figure shows the effect of adversarial suffixes on the attention mechanism of a language model. The left panel shows the attention weights from the last token to other tokens when a random suffix is appended, while the right panel shows the same when an adversarial suffix is appended. The results show that the adversarial suffix causes the attention mechanism to shift its focus from the instruction to the suffix, which helps bypass the model’s safety mechanisms and elicit harmful responses.

This figure shows the results of ablating the ‘refusal direction’ on 13 different large language models. The x-axis represents the different models, and the y-axis represents the scores for refusal and safety. The bars show that ablating the direction significantly reduces the model’s refusal rate, but simultaneously increases the rate of unsafe completions. This demonstrates that the refusal mechanism is strongly tied to this single direction in the model’s activation space.
This figure shows the results of ablating the ‘refusal direction’ from 13 different language models. The x-axis represents the different models, and the y-axis represents the refusal score and safety score. The bars show that when the refusal direction is ablated (removed), the refusal rate decreases significantly, and the safety rate decreases (meaning more unsafe completions are generated). This demonstrates that the refusal mechanism is highly dependent on this single direction in the model’s activation space.

This figure shows two histograms: one for harmful instructions and one for harmless instructions. The x-axis represents the refusal metric, which is a log-odds score indicating the likelihood of the model refusing to answer a given instruction. The y-axis represents the frequency of instructions falling into each refusal metric bin. The distributions are clearly separated, indicating the refusal metric effectively distinguishes between harmful and harmless prompts. Specifically, a high refusal metric suggests a high probability of the model’s refusal.
This figure shows the results of ablating the ‘refusal direction’ in 13 different language models. The x-axis represents the different models, and the y-axis shows the refusal score and safety score. The blue bars represent the refusal score without any intervention, the orange bars represent the safety score without any intervention, the green bars represent the refusal score after ablating the ‘refusal direction’, and the purple bars represent the safety score after ablating the ‘refusal direction’. As you can see, ablating the ‘refusal direction’ significantly reduces the refusal rate and increases the safety score. This suggests that the ‘refusal direction’ plays a crucial role in the models’ refusal behavior.

This figure displays the results of ablating the refusal direction on 13 different language models. The x-axis represents the different models tested, and the y-axis shows the refusal score and safety score. The ‘No intervention’ bars show the baseline performance of the models when presented with harmful instructions. The ‘Directional ablation’ bars show the results after removing the identified ‘refusal direction’. The figure demonstrates that removing this direction significantly reduces the models’ ability to refuse harmful instructions, while simultaneously increasing the likelihood of unsafe responses.
This figure displays the results of ablating the ‘refusal direction’ from 13 different language models. The x-axis shows the different models, categorized by size and family (e.g., Qwen 7B, Llama-2 70B). The y-axis represents the score, split into refusal score and safety score. The bars are grouped by condition: no intervention (baseline), directional ablation (refusal direction removed), and directional addition (refusal direction added). The results show that ablating the refusal direction significantly reduces the refusal rate (the models are less likely to refuse harmful instructions) and increases unsafe completions (the models are more likely to generate harmful text). This demonstrates the critical role of the ‘refusal direction’ in mediating the models’ refusal behavior.

The figure shows the results of ablating the ‘refusal direction’ on 13 different language models when given 100 harmful instructions from the JAILBREAKBENCH dataset. Ablation of this direction significantly reduces the model’s refusal rate, while simultaneously increasing the rate of unsafe completions. This demonstrates that the ‘refusal direction’ is a critical component of the models’ safety mechanisms.

This figure shows the results of ablating the ‘refusal direction’ on 13 different language models. The x-axis represents the different models tested, and the y-axis shows the scores for refusal and safety. The bars show that when the refusal direction is removed, the models refuse harmful instructions less frequently and produce unsafe responses more frequently. This illustrates that the ‘refusal direction’ plays a key role in the models’ refusal behavior.

This figure visualizes the effect of activation addition in the negative refusal direction on the cosine similarity with the refusal direction across different layers of the GEMMA 7B IT model. It shows how activation addition moves harmful activations closer to harmless activations which effectively bypasses the refusal mechanism. However, it also highlights a drawback of this method which is that it pushes harmless activations further out of their normal distribution.
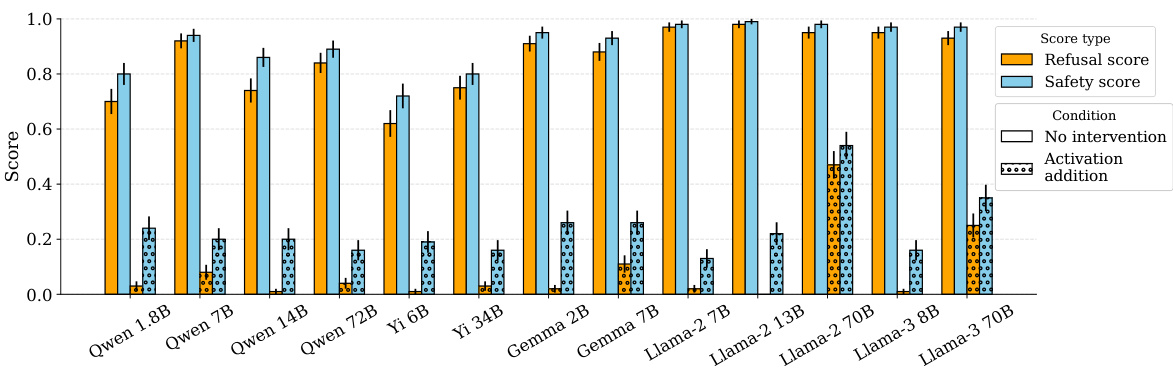
This figure shows the results of adding the identified ‘refusal direction’ to the residual stream activations of harmless instructions across 13 different open-source large language models. The y-axis represents the refusal score (ranging from 0 to 1), while the x-axis shows the different models. Each bar represents a model, and the bars are grouped to show the results under three conditions: no intervention, activation addition (where the refusal direction was added), and directional ablation (where the refusal direction was removed). The key observation is that activation addition significantly increases the refusal rate even on harmless prompts, indicating that the ‘refusal direction’ is a causal mediator of refusal behavior. The error bars represent the standard error.
This figure shows the results of ablating the ‘refusal direction’ from 13 different language models. The x-axis represents the different language models, and the y-axis represents the refusal and safety scores. Ablation of the refusal direction significantly reduces the model’s refusal rate (leading to lower refusal scores) and increases the generation of unsafe content (resulting in higher safety scores). This demonstrates that the refusal mechanism is strongly linked to the identified direction within these models.

This figure shows the results of ablating the ‘refusal direction’ from 13 different language models. The x-axis represents the different language models, while the y-axis shows the refusal and safety scores. The bars are grouped into three conditions: no intervention, directional ablation, and activation addition. Directional ablation significantly reduces the refusal rate (making the models less likely to refuse harmful prompts), while the safety score decreases, indicating that unsafe completions are more frequent. The figure demonstrates that the refusal mechanism in these models is strongly tied to this specific direction.

This figure displays the results of an ablation study on 13 different language models. The ‘refusal direction’—a single vector identified within the model’s internal representations—was removed (ablated) from the model’s residual stream activations. Ablation of this direction resulted in a significant decrease in the model’s refusal rate when given harmful instructions, simultaneously increasing the rate of unsafe completions. This indicates that the identified direction is crucial for the models’ refusal mechanism.

This figure displays the results of ablating the ‘refusal direction’ from 13 different language models. The x-axis represents each model, and the y-axis shows the refusal rate and safety score. The bars are separated into three groups: no intervention, directional ablation, and activation addition. The results demonstrate that removing the refusal direction significantly reduces the model’s ability to refuse harmful instructions and leads to unsafe completions. Conversely, adding the refusal direction causes refusal even on harmless instructions. This highlights the critical role of the identified direction in mediating the models’ refusal behavior.
More on tables
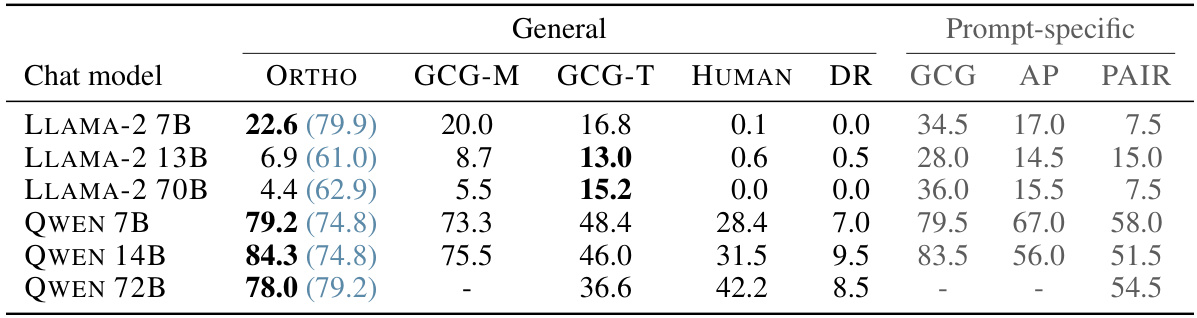
This table compares the success rate of different jailbreaking methods on several language models. The success rate is measured by the proportion of times a method successfully bypasses the model’s safety mechanisms. The methods are categorized into general methods (applied to all prompts) and prompt-specific methods (optimized for each prompt). The table shows that the proposed ‘ORTHO’ method performs comparably to other state-of-the-art techniques, especially for the QWEN models. The results with and without the default system prompt are shown, highlighting the impact of system prompts on the effectiveness of different methods.
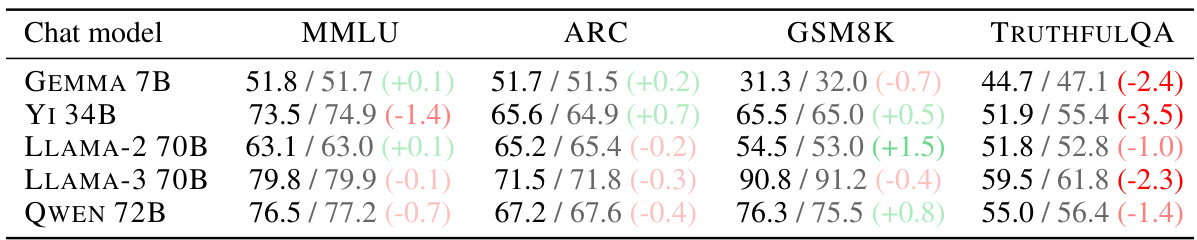
This table presents the results of four common language model evaluations (MMLU, ARC, GSM8K, TRUTHFULQA) for five large language models (LLaMA-2 70B, LLaMA-3 70B, QWEN 72B, YI 34B, GEMMA 7B). For each model, the table shows the performance of both the original model and its orthogonalized version (where the ‘refusal direction’ has been removed). The difference between the original model and the orthogonalized model’s performance is shown for each evaluation metric. This allows for a comparison of the effect of orthogonalization on general model capabilities.

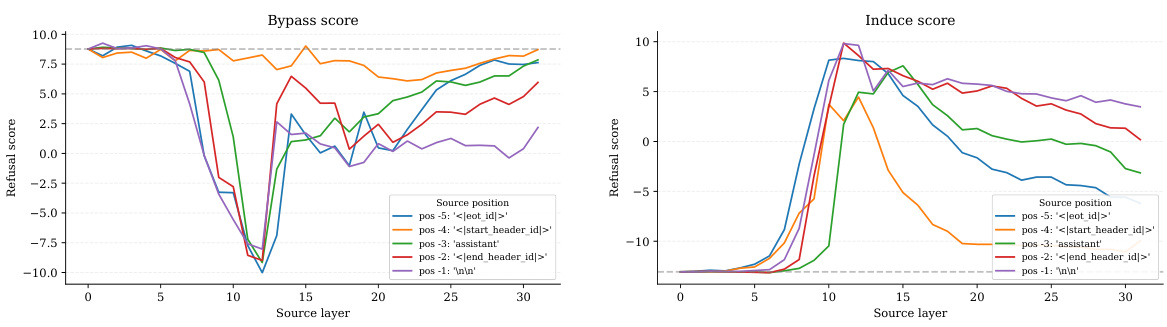
This table shows the results of the direction selection algorithm for each of the 13 models studied in the paper. For each model, it indicates the layer and token position from which the best refusal direction was extracted, and its corresponding metrics (bypass_score, induce_score, and kl_score). The metrics quantify how effective the direction is at bypassing or inducing refusal while minimizing other behavioral changes.

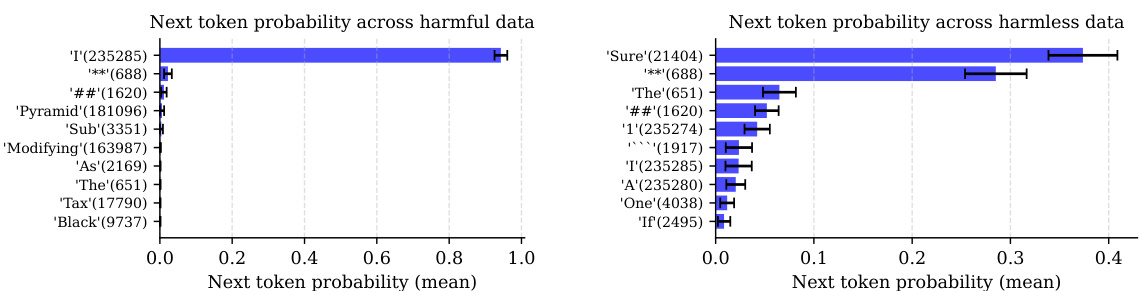
This table shows the set of tokens (R) that are most likely to start a refusal response for each family of language models considered in the paper. For each model family, there is a corresponding set of refusal phrases associated with those tokens. This information is useful to understand the methodology for creating an efficient proxy for measuring refusal, which uses the probability of these refusal tokens occurring to estimate the likelihood of a model refusing a particular instruction.
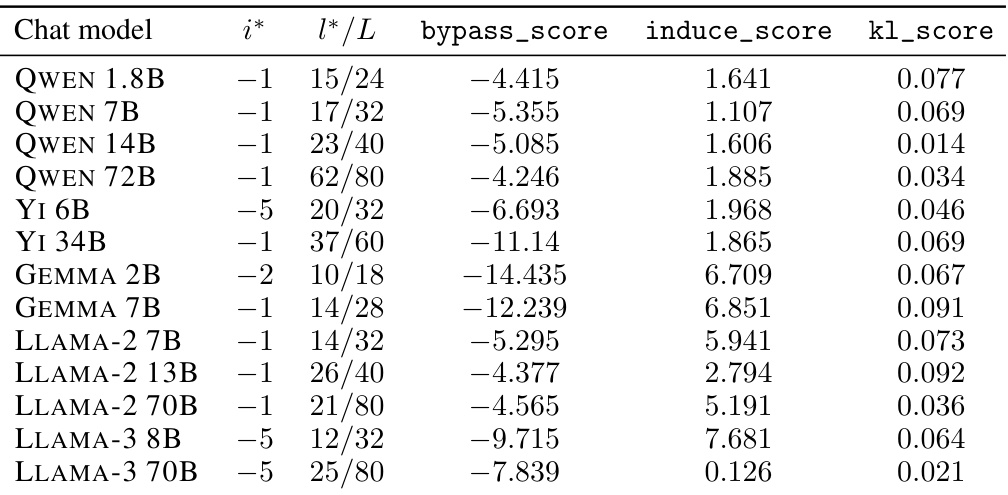
This table shows the results of the direction selection algorithm for each of the 13 models evaluated in the study. For each model, it indicates the layer (l*) and token position (i*) from which the best refusal direction was selected. It also provides the bypass score, induce score, and KL score for that direction. The bypass score is a measure of how effective the selected direction is at bypassing refusal when ablated from the model. The induce score is a measure of how effective the direction is at inducing refusal when added to the model’s activations. The KL score measures the difference between the probability distribution of model outputs for the validation set with and without directional ablation for that specific direction. The lower the bypass score and higher the induce score, the better the selected direction is at mediating refusal behavior.

This table shows the chat templates used for each model family in the study. Each template includes placeholders for user input and model response. The user instruction is represented as {x}, while post-instruction tokens, which are all tokens after the user instruction within the template, are highlighted in red. These templates provide structure for the interactions between the user and the language model.

This table compares the success rate of different jailbreaking methods on the HARMBENCH benchmark. The methods include the authors’ method (ORTHO), various other general jailbreaking approaches (GCG-M, GCG-T, HUMAN, AP, PAIR), and a baseline (DR) with no jailbreak. The table shows the attack success rate (ASR) for each method, both with and without the model’s default system prompt. The results highlight the effectiveness of different methods and their sensitivity to the presence of system prompts.

This table shows the details of the refusal direction selection process for each of the 13 language models studied. It indicates, for each model, the layer (l*) and token position (i*) where the direction was identified, and provides the values of the three metrics used for direction selection: bypass_score, induce_score, and KL_score. These metrics help to evaluate the effectiveness of the selected direction in bypassing refusal, inducing refusal, and minimizing changes in model behavior on harmless inputs.
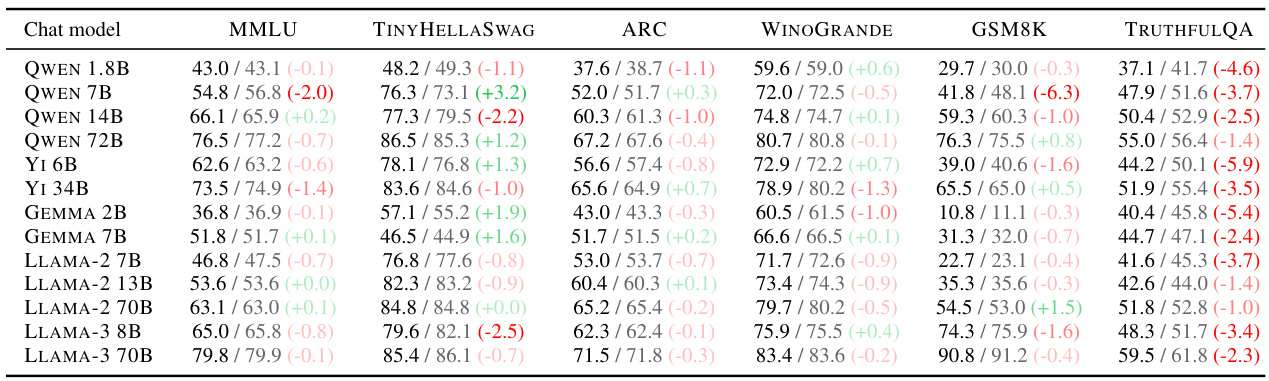
This table presents the results of four different language model evaluations (MMLU, TINYHELLASWAG, ARC, WINOGRANDE, GSM8K, TRUTHFULQA) for 13 different models, comparing their performance before and after applying the weight orthogonalization technique described in the paper. For each model and each evaluation metric, the table shows three values: the performance of the orthogonalized model, the performance of the original model, and the difference between the two. This allows for a direct comparison of how the orthogonalization affects the model’s overall capabilities, assessing whether any significant performance degradation or improvement occurs as a result of this modification.

This table presents the cross-entropy (CE) loss values for various language models, categorized by model family and dataset. The CE loss is a measure of how well the model’s predictions match the actual data. It is calculated for three different datasets: THE PILE, ALPACA, and an on-distribution subset of ALPACA. For each model, three loss values are provided: one for the baseline model, one for the model after directional ablation of the ‘refusal direction’, and one after activation addition of the same direction. These results shed light on how different interventions impact model performance, especially in terms of harmfulness and coherence.

This table shows the results of the direction selection algorithm for each of the thirteen models studied. The columns are: - Model: Name of the model. - i*: Index of the token in the input sequence where the direction was selected. A value of -1 indicates that the direction was selected from the last token, -2 indicates the second to last token, and so on. - l*/L: Layer index of the direction, divided by the total number of layers in the model. This shows the relative position of the layer in the model. - bypass_score: Average refusal metric across the validation set of harmful instructions, after ablating the selected direction. - induce_score: Average refusal metric across the validation set of harmless instructions, after adding the selected direction. - kl_score: Average Kullback-Leibler divergence between probability distributions at the last token position, with and without directional ablation of the direction. This metric shows the change in the model’s behavior after ablating the direction.

This table presents a comparison of three different methods for mitigating the refusal behavior of a large language model (LLM): directional ablation, activation addition, and fine-tuning. The metrics used for comparison are the refusal score, safety score, and cross-entropy (CE) loss calculated across three different datasets (THE PILE, ALPACA, and on-distribution). The refusal score represents the proportion of times the model refused to generate a response. The safety score represents the proportion of times the model’s response was deemed safe. The CE loss measures the difference between the model’s predicted probability distribution and the true distribution of the next token in a sequence. By comparing these metrics across the three intervention methods, the table helps to assess the effectiveness and potential side effects of each approach in controlling the model’s behavior.
This table lists the thirteen large language models used in the study, categorized by their model family (e.g., Qwen Chat, Yi Chat), their sizes (in terms of parameters), their alignment training type (either aligned by preference optimization - APO - or aligned by fine-tuning - AFT), and the references for each model. The table shows the diversity of models considered, with sizes ranging from 1.8B parameters to 72B parameters, to demonstrate the generality of the findings across different models.
This table lists the 13 large language models used in the study. It shows their model family name, the number of parameters (sizes), the method used for alignment (Alignment type - either Preference Optimization (APO) or Fine-tuning (AFT)), and the bibliographic reference for each model.
Full paper#