↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Token-based image generation using non-autoregressive Transformers (NATs) has shown promise but faces challenges in efficiency. Existing NATs process all tokens uniformly, leading to redundant computation. This paper investigates the underlying mechanisms of NATs’ effectiveness.
The researchers propose EfficientNAT (ENAT) to overcome these limitations. ENAT disentangles the processing of visible and masked tokens, encoding visible tokens independently and decoding masked tokens using these encodings. It also prioritizes computation of critical tokens and maximizes reuse of pre-computed token representations. This approach significantly improves efficiency and performance on benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances the field of token-based image synthesis. By identifying and addressing critical spatial and temporal interaction patterns in existing models, the researchers achieve significant improvements in both efficiency and image quality. This research directly contributes to current trends in efficient AI model development, offering valuable insights for researchers and potential applications in various areas of image generation. The findings open up new avenues for future investigation into optimizing token-based models, potentially improving the scalability and performance of image generation systems.
Visual Insights#

This figure illustrates the progressive generation process of Non-autoregressive Transformers (NATs) for image synthesis. It begins with a completely masked image canvas (t=0), represented by grey squares. At each step, a subset of the masked tokens are decoded in parallel, revealed as light blue squares. The process iteratively continues until all tokens are revealed (t=T), forming the complete image. Finally, a pre-trained vector quantizer decoder (VQ Dec) maps the decoded token sequence to the final pixel-space image.
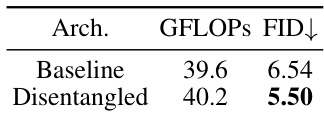
This table presents the results of an ablation study comparing the effectiveness of a baseline NAT architecture against a disentangled architecture. The baseline uses the same architecture as existing NAT models, processing visible and [MASK] tokens equally. The disentangled architecture processes them separately. The table shows that the disentangled architecture achieves a lower FID score (5.50) with a similar GFLOPS compared to the baseline (6.54). This demonstrates the effectiveness of disentangling visible and [MASK] token computations in NATs.
In-depth insights#
Token-Based Synthesis#
Token-based synthesis represents a paradigm shift in image generation, moving away from pixel-by-pixel approaches. The core idea is to break down an image into a sequence of discrete tokens, similar to words in a sentence, each carrying semantic information about the visual content. These tokens are then processed by powerful models, typically transformers, which learn to predict or generate new tokens based on the existing ones. This approach offers several advantages: efficiency, as generating tokens is often faster than manipulating individual pixels; scalability, allowing for higher resolution images; and flexibility, enabling various generation tasks like text-to-image synthesis and image editing. However, challenges remain. Effective tokenization is crucial to capture meaningful visual features, and the computational demands of large transformer models can still be significant. Furthermore, handling long-range dependencies between tokens within an image can be difficult, impacting the quality of the generated output. Future research will likely focus on improving tokenization methods, developing more efficient transformer architectures, and exploring better ways to represent and process spatial information within the token sequence.
Spatial Interactions#
Analyzing spatial interactions within a model reveals crucial insights into its inner workings. In image generation, understanding how different parts of an image influence each other during the synthesis process is essential. The interplay between visible and masked tokens in a model is particularly important, as masked tokens often rely on visible information for prediction. Investigating the attention mechanisms helps unveil how the model utilizes this spatial information to guide the generation process. Variations in attention patterns across different token types highlight the asymmetric role of visible and masked tokens. Visible tokens contribute by primarily providing information, while masked tokens gather it to make predictions. Disentangling the computational processes for these token types, as shown by the proposed ENAT model, can further improve the efficiency and performance. By prioritizing the computation of visible tokens and efficiently leveraging previous computations, the model achieves better results with reduced computational costs.
Temporal Dynamics#
Analyzing temporal dynamics in a research paper requires a deep dive into how the system’s behavior changes over time. This involves examining whether the model’s performance improves incrementally, plateaus, or degrades across different stages. Identifying key transitional points where significant shifts occur is crucial. A thoughtful analysis should consider not just the overall trend but also the rate of change, pinpointing moments of rapid improvement or decline. Moreover, investigating whether this evolution is consistent across different inputs, parameters, or environmental conditions enhances the understanding of the system’s temporal robustness. Attention should also be given to the underlying mechanisms, determining if changes in temporal dynamics are linked to specific internal components, network layers, or learning processes. Finally, understanding the relationship between temporal dynamics and other aspects of the model, such as spatial interactions or energy consumption, could reveal hidden correlations and reveal more comprehensive insights.
EfficientNAT Design#
The EfficientNAT design is a novel approach to token-based image synthesis that significantly improves upon existing Non-autoregressive Transformers (NATs). It leverages two key insights: disentangled spatial interactions and maximally reused temporal computations. Spatially, EfficientNAT separates the processing of visible and masked tokens, allowing for independent encoding of visible tokens and using those encodings to inform the decoding of masked tokens. This asymmetry addresses the inherent imbalance in the information flow between visible and masked tokens in traditional NATs. Temporally, EfficientNAT prioritizes computations on the most critical tokens, namely those newly revealed in each step, while reusing previously computed token representations to avoid redundant calculations. This strategy of computation reuse dramatically reduces the computational cost while retaining the overall performance, resulting in a much more efficient model. The model also incorporates a self-cross attention mechanism for efficient information integration between visible and masked tokens. These combined optimizations yield a significant improvement in speed and efficiency without compromising image quality, making EfficientNAT a highly effective and practical approach for token-based image generation.
Future Enhancements#
Future enhancements for this research could involve exploring diverse data modalities beyond images, such as video or 3D point clouds, to assess the model’s generalizability and robustness. Investigating the impact of different tokenization strategies on model performance is also crucial. Furthermore, developing more efficient attention mechanisms or exploring alternative architectures could significantly reduce computational costs. Addressing potential biases in the training data and exploring techniques to enhance fairness and inclusivity are also essential. Finally, a thorough investigation into the model’s scalability and its performance with larger datasets and higher-resolution images is necessary to fully realize its potential for real-world applications.
More visual insights#
More on figures

This figure shows the results of an ablation study on four types of spatial interactions in NATs. The study investigates the impact of different attention mechanisms on the model’s performance. By removing different attention mechanisms, the researchers observed a significant drop in performance when removing [M] to [V] attention, indicating that this interaction is crucial for the model. Removing the other attention mechanisms resulted in less significant performance drops.
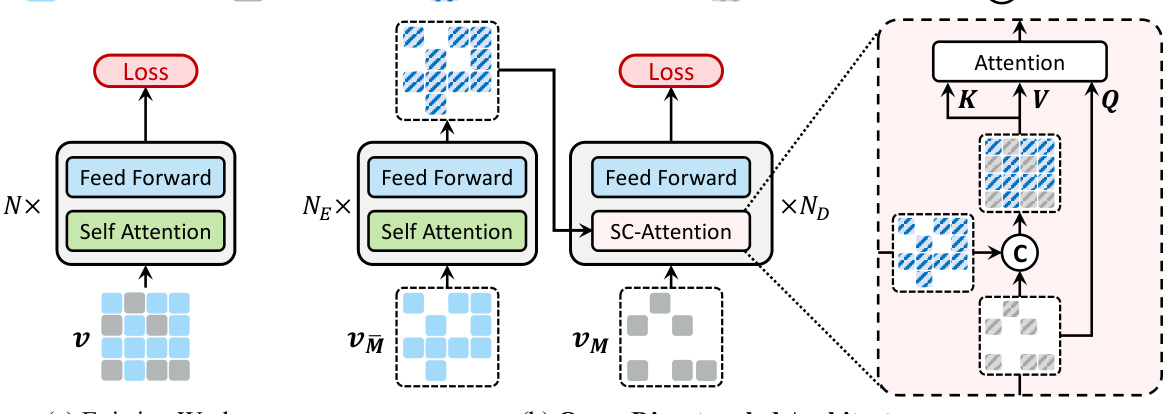
This figure compares the existing NATs architecture with the proposed ENAT architecture. The existing approach processes visible tokens and masked tokens uniformly, while ENAT’s disentangled architecture independently encodes visible tokens. These encoded visible token features are then integrated into the decoding process for the masked tokens using SC-Attention. This allows for more efficient computation and better performance.

This figure illustrates the inference process of ENAT, showing how it builds upon the disentangled architecture from Figure 3b. Instead of encoding all tokens at each step, ENAT prioritizes newly decoded tokens, reusing the previously computed features for computational efficiency. The diagram shows the flow of information between steps, highlighting the reuse of features from the previous step to enhance the current step’s decoding process.

This figure illustrates the ENAT model’s architecture. It builds upon the disentangled architecture from Figure 3b by reusing previously computed features. Only newly decoded tokens are encoded, and the model efficiently integrates previously extracted features to supplement information. This reduces computation, making the process more efficient.
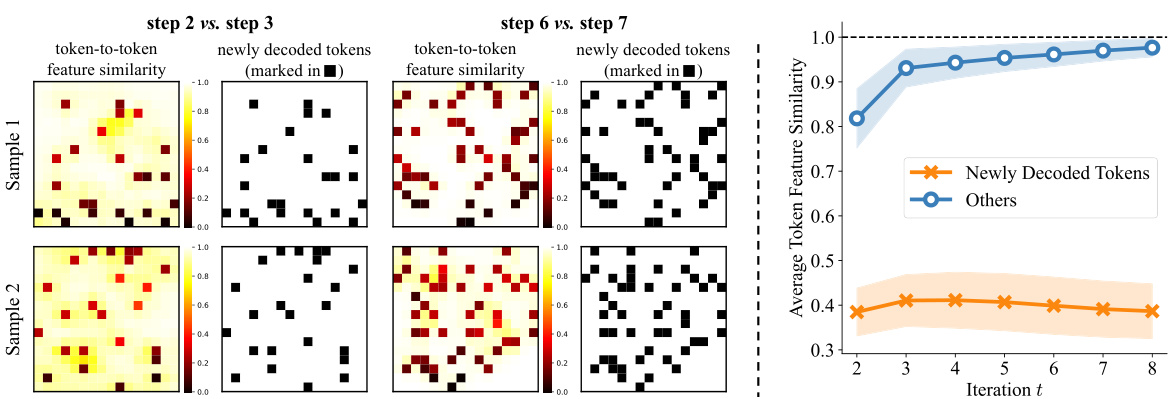
This figure visualizes the similarity of token features between consecutive steps in the image generation process of NATs. (a) shows heatmaps for two example image generations, comparing steps 2&3 and 6&7. The heatmaps highlight which tokens changed significantly between steps, revealing that these changes primarily occur around the newly decoded tokens. (b) presents an aggregated view showing the average similarity between steps across many generations, confirming that similarity decreases more for newly decoded tokens than other tokens between steps.
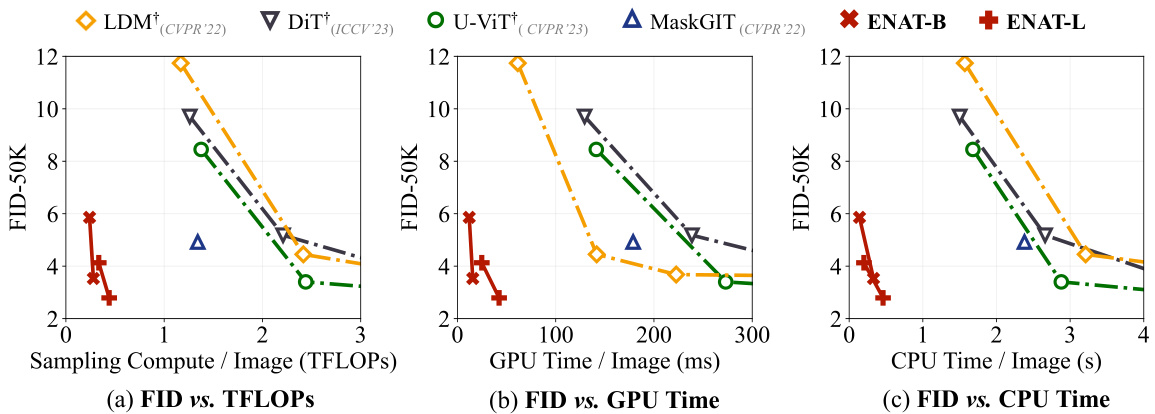
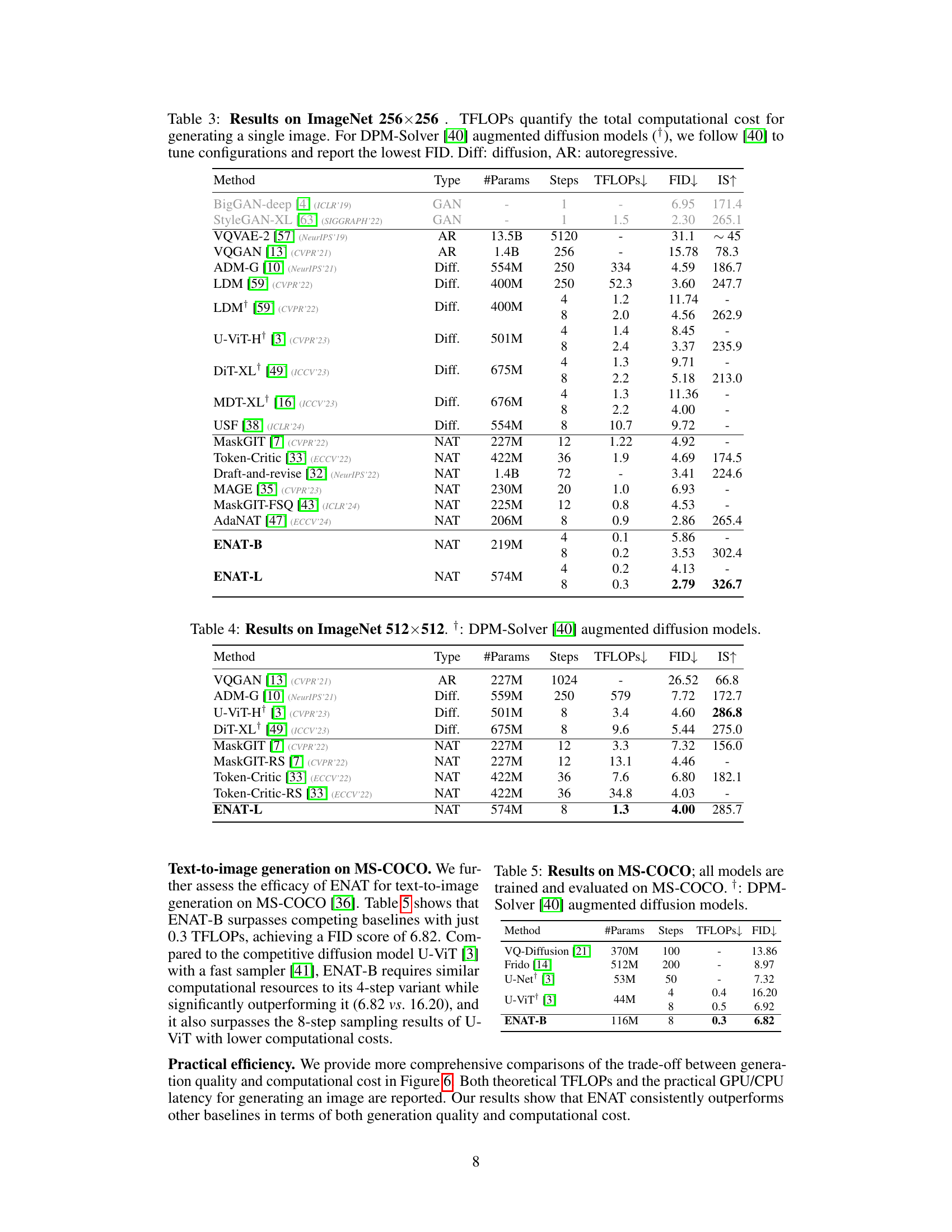
This figure demonstrates the practical efficiency of ENAT by comparing its performance with other state-of-the-art generative models across three metrics: FID (Fréchet Inception Distance), GPU time, and CPU time. It shows that ENAT achieves superior performance with significantly reduced computational costs, as indicated by lower FID scores and shorter processing times on both GPU and CPU.

This figure showcases several example images generated by the ENAT-L model. The images span both the ImageNet 256x256 and 512x512 datasets, demonstrating the model’s ability to produce high-quality images at different resolutions. Each image represents a successful image generation from the model after 8 generation steps.

The figure shows the comparison between existing NATs architecture and the proposed ENAT architecture. The existing NATs process visible tokens and [MASK] tokens equally. The proposed ENAT disentangles the computations of visible and [MASK] tokens. Visible tokens are encoded independently. [MASK] tokens are decoded based on the fully encoded visible tokens. A SC-Attention mechanism is used to improve performance.
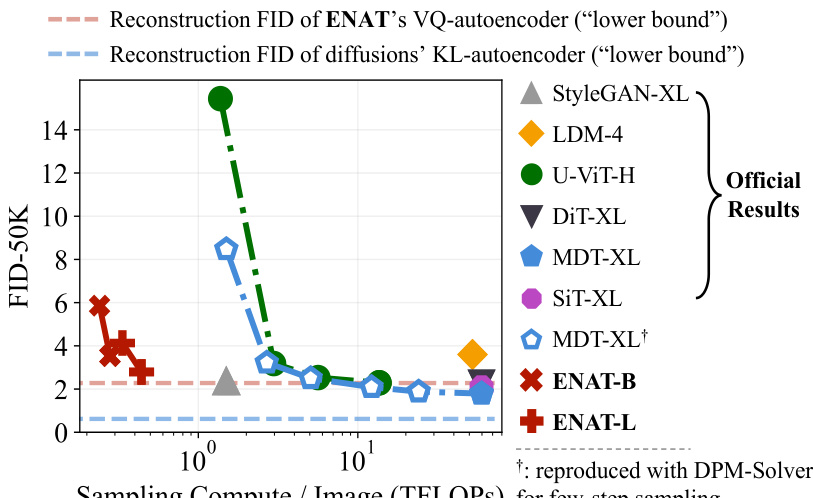
This figure compares the performance of ENAT with other state-of-the-art image generation models on ImageNet 256x256 dataset. The x-axis represents the total computational cost (in TFLOPs) required to generate a single image, and the y-axis shows the Fréchet Inception Distance (FID) score, a measure of image quality. The lower the FID score, the better the image quality. The figure demonstrates that ENAT achieves superior performance (lower FID) with significantly lower computational cost (lower TFLOPs) compared to other methods. The baseline results are taken from their original papers, with the exception of the MDT results which have been reproduced using DPM-Solver for fair comparison.

This figure shows several examples of images generated by the ENAT-L model. The images are from the ImageNet dataset, with resolutions of 256x256 and 512x512 pixels. The model was trained using 8 generation steps. The figure aims to showcase the visual quality and diversity of images generated by the proposed ENAT model.
More on tables
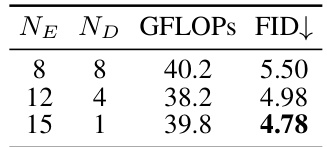
This ablation study investigates the impact of computation allocation between visible and masked tokens on the performance of ENAT. By varying the number of encoder (NE) and decoder (ND) layers for visible and masked tokens respectively, while maintaining a roughly constant computational cost (GFLOPs), the impact on FID score is evaluated. The results demonstrate that prioritizing computation for visible tokens significantly improves performance.
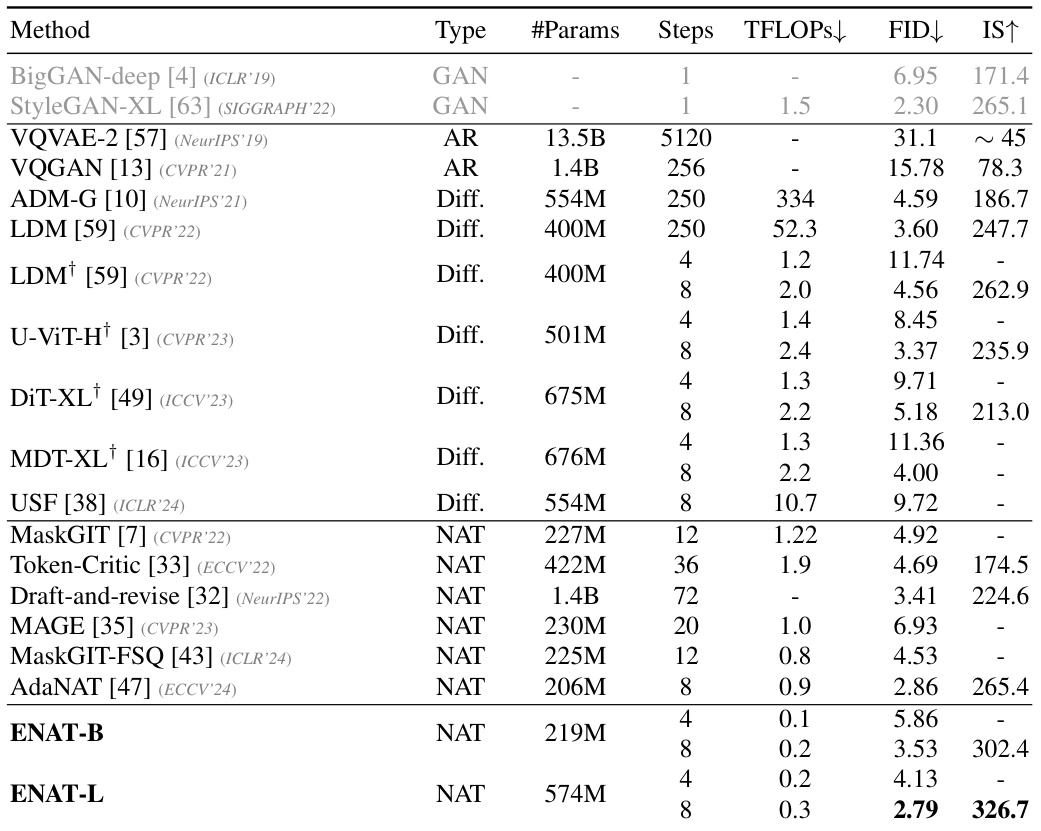
This table compares the performance of ENAT with other generative models on the ImageNet 256x256 dataset. It shows various metrics including the number of parameters, the number of steps in the generation process, the computational cost (in TFLOPs), the Fréchet Inception Distance (FID), and the Inception Score (IS). Lower FID values indicate better image quality, while higher IS values indicate greater diversity. The table highlights that ENAT achieves superior performance with significantly lower computational cost compared to other methods.
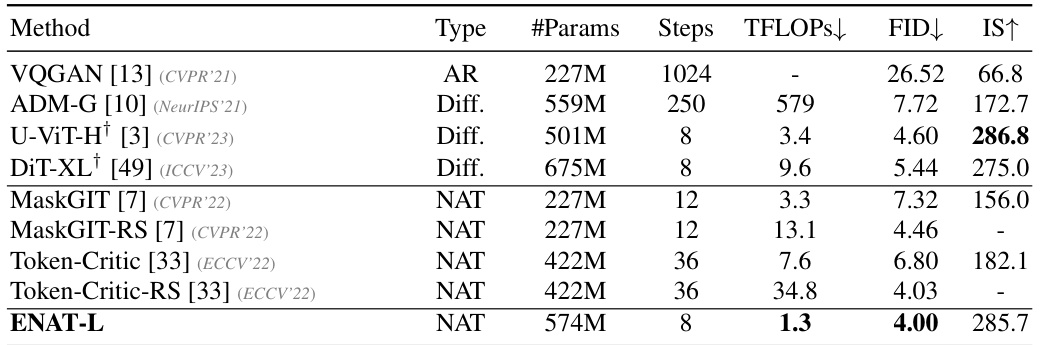
This table presents the results of various image generation models on the ImageNet 512x512 dataset. It compares different model types (Autoregressive, Diffusion, and Non-autoregressive Transformers), the number of parameters, the number of steps used in the generation process, the total computational cost in TeraFLOPS, the Frechet Inception Distance (FID) score, and the Inception Score (IS). Lower FID indicates better image quality, and higher IS indicates better diversity. The † symbol indicates that the DPM-Solver method was used for augmented diffusion models. This table highlights that EfficientNAT (ENAT) achieves competitive results with lower computational costs compared to other state-of-the-art methods.
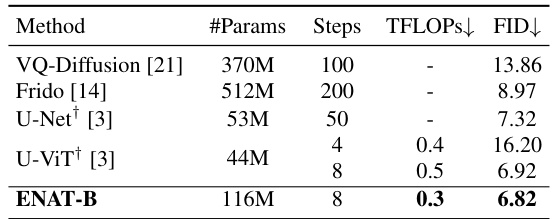
This table compares the performance of different image generation models on the MS-COCO dataset for text-to-image generation. It shows the number of parameters, number of generation steps, computational cost (TFLOPs), and FID score for each model. The table highlights the superior performance of ENAT-B in terms of FID score while maintaining a very low computational cost.
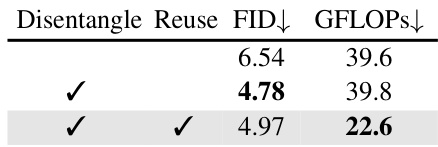
This table presents ablation studies performed on the ImageNet 256x256 dataset using the ENAT-S model with 8 generation steps. It demonstrates the impact of the disentangled architecture and computation reuse mechanisms on the model’s performance. FID (Fréchet Inception Distance) and GFLOPs (floating point operations) are used to measure the performance and computational cost respectively. The default setting is marked in gray, allowing for easy comparison between different configurations.

This table presents ablation study results on ImageNet 256x256, using ENAT-S with 8 generation steps as the baseline. It evaluates the impact of different design choices on the model’s performance, measured by FID (Fréchet Inception Distance) and GFLOPs (giga floating-point operations). The modifications tested include the disentangled architecture, reuse mechanism, SC-Attention, and various choices about which token features to reuse and which layers’ features to reuse. The results show how these choices affect the FID score and computational cost of the model.
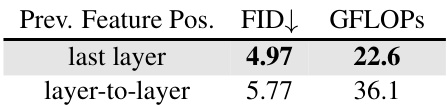
This table presents ablation studies performed on the ImageNet 256x256 dataset using the ENAT-S model with 8 generation steps. It investigates the impact of different design choices within the ENAT architecture on model performance, measured by FID-50K and computational cost (GFLOPS). The default ENAT-S configuration is shown in gray, and the table shows variations in FID and GFLOPS when specific architectural components are removed or modified. The experiments assess the impact of the disentangled architecture, the computation reuse mechanism, the choice of attention mechanism (SC-Attention vs. self and cross-attention), and the selection of layers to reuse features from. The results highlight the relative importance of different ENAT components for achieving efficient and effective image generation.
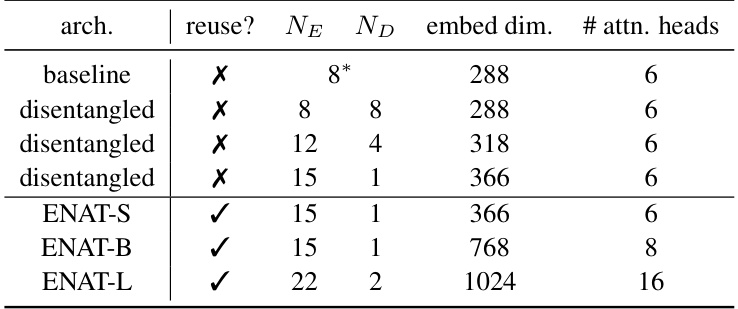
This table presents the detailed configurations of all NAT models used in the paper. It lists the number of encoder layers (NE), decoder layers (ND), the dimension of hidden states (embed dim.), and the number of attention heads (#attn. heads) for each model. It also notes whether the model uses the computation reuse technique (‘reuse?’) and indicates that in conventional NAT models, the encoder layers are shared for both visible and [MASK] token decoding.
This table presents the detailed configurations of all NAT models used in the paper. It lists the number of encoder and decoder layers, the dimensionality of the hidden states, and the number of attention heads for each model. The table highlights whether the encoder layers are shared (in conventional NATs) or separated (in ENAT).
Full paper#