TL;DR#
Knowledge-based question answering (KBQA) often relies on expensive large language models (LLMs). Current methods struggle to balance accuracy and cost effectively. Different models excel in different knowledge domains, making model selection challenging and time-consuming.
The paper introduces “Coke,” a cost-efficient KBQA strategy. Coke uses a multi-armed bandit approach, cleverly combining LLMs and smaller, knowledge graph-based models (KGMs). A context-aware policy selects the best model for each question, dynamically balancing exploration and exploitation to optimize accuracy within a budget. Extensive experiments demonstrate Coke’s success, significantly improving the cost-accuracy trade-off compared to existing approaches, showcasing significant cost reduction while maintaining or improving accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the high cost of using large language models (LLMs) in knowledge-based question answering (KBQA) by proposing a cost-efficient strategy. It offers a novel solution to balance accuracy and cost, which is crucial for real-world applications of LLMs in resource-constrained environments. The research opens new avenues for optimizing LLM usage, particularly in specialized domains needing domain expertise, and pushes the boundaries of efficient model selection techniques. This is highly relevant to the current trends in AI research focusing on responsible and cost-effective AI solutions.
Visual Insights#
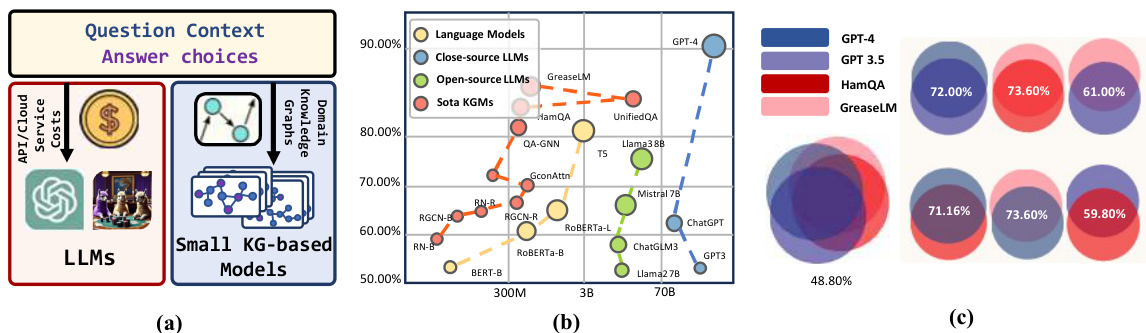
🔼 This figure provides a comparison of Large Language Models (LLMs) and smaller Knowledge Graph based Models (KGMs) for Knowledge-Based Question Answering (KBQA). Panel (a) shows a schematic overview of the two approaches. Panel (b) is a scatter plot showing the relationship between model accuracy and the number of parameters for various models. This highlights the trade-off between accuracy and computational cost. Panel (c) uses Venn diagrams to illustrate the overlap in predictions made by different models on the OpenBookQA benchmark dataset. This demonstrates that different models excel at different types of questions.
read the caption
Figure 1: A sketched overview of LLMs and small KGMs in (a) We visualize the Acc./Param size of both pipelines of models in (b) The overlaps among different model predictions are shown in (c).
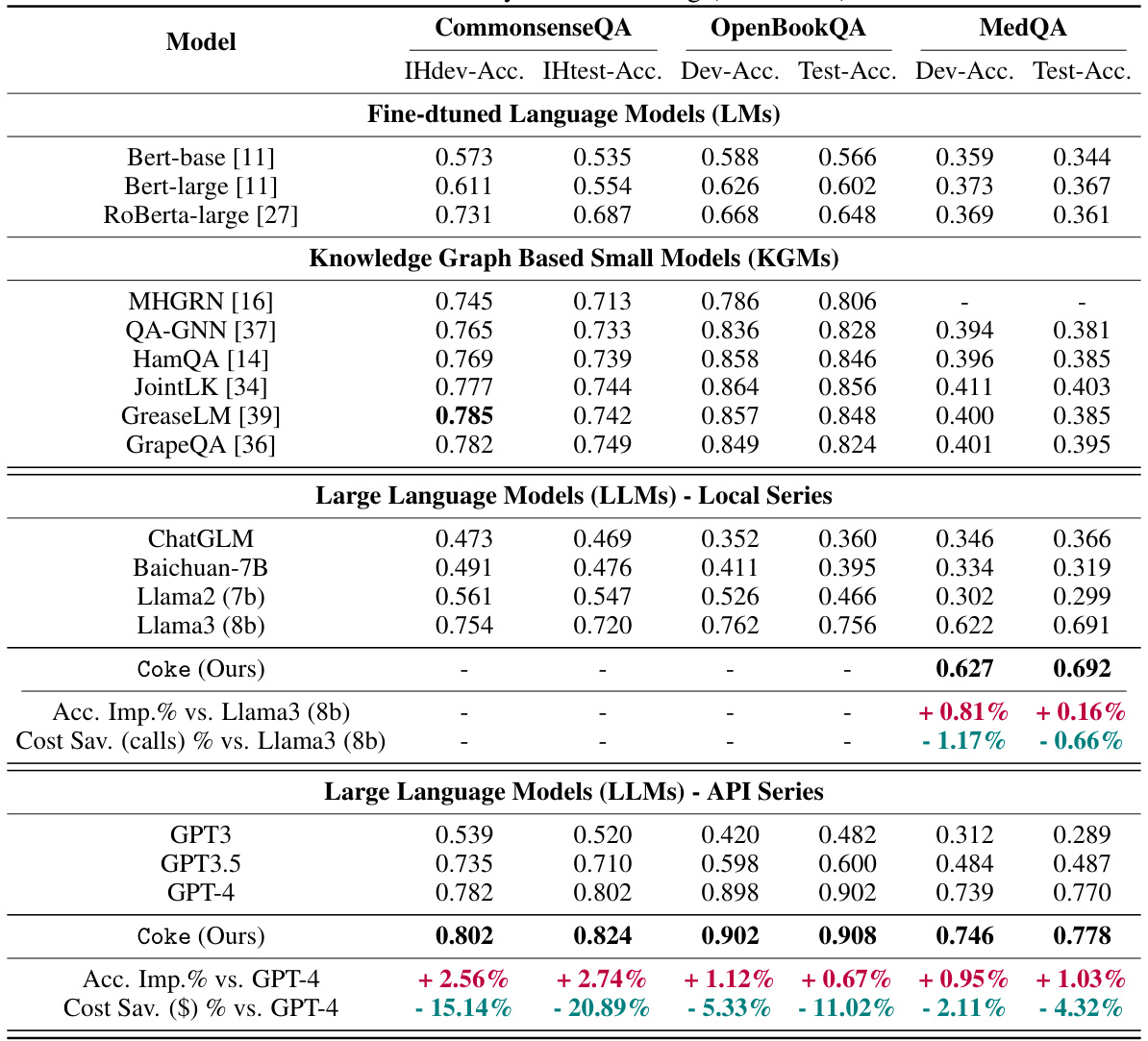
🔼 This table presents a comparison of the performance of the proposed ‘Coke’ method against several state-of-the-art baselines on three benchmark datasets (CommonsenseQA, OpenBookQA, and MedQA). The comparison considers two key metrics: inferential accuracy (percentage of correctly answered questions) and cost savings (reduction in API fees for LLMs). It breaks down the results for various model categories: fine-tuned Language Models (LMs), Knowledge Graph Based Small Models (KGMs), and Large Language Models (LLMs) with both local and API series. The table shows the dev and test accuracy for each model and dataset, and also calculates percentage improvements in accuracy and cost savings compared to the best performing baseline models (Llama3 and GPT-4).
read the caption
Table 1: Performance comparison among state-of-the-art baselines and Coke on three benchmark datasets in terms of both inferential accuracy and cost saving ($ API fees).
In-depth insights#
Cost-Efficient KBQA#
Cost-efficient knowledge-based question answering (KBQA) is a crucial area of research because traditional KBQA methods can be computationally expensive, especially when dealing with large knowledge graphs and complex queries. The integration of large language models (LLMs) offers significant potential for improving accuracy but introduces substantial cost concerns. The challenge lies in balancing the improved accuracy of LLMs with their high computational cost. This necessitates strategies that efficiently leverage the strengths of both LLMs and smaller, more cost-effective knowledge graph embedding models (KGMs). A cost-efficient KBQA system must intelligently select the most appropriate model for each query, considering factors like query complexity and the availability of relevant knowledge in the respective models. This requires sophisticated techniques for model selection, potentially employing methods like multi-armed bandits, to minimize calls to expensive LLMs while maximizing the overall accuracy. Successful cost-efficient KBQA strategies will be highly adaptable, capable of dynamically adjusting their model selection based on real-time cost and accuracy trade-offs. Furthermore, research should focus on developing methods that can evaluate and optimize for both accuracy and cost simultaneously, moving beyond simple metrics and focusing on holistic cost-benefit analysis. The ultimate goal is to create robust KBQA systems that provide high accuracy at a fraction of the cost of current approaches, making knowledge-based question answering accessible to a wider range of applications.
Multi-Armed Bandit#
The core of this research paper revolves around employing a Multi-Armed Bandit (MAB) framework to address the challenge of cost-efficient knowledge-based question answering (KBQA) using Large Language Models (LLMs). The MAB approach elegantly tackles the problem of balancing accuracy and cost, which are often competing objectives in LLMs. Each arm represents a different model, either a lightweight Knowledge Graph based Model (KGM) or a computationally expensive LLM. The algorithm learns to select the most appropriate model for each incoming question, optimizing for both accuracy and minimal LLM usage. A key innovation is the cluster-level Thompson Sampling, which efficiently guides the exploration-exploitation trade-off between LLMs and KGMs. Context-aware policies further refine model selection by considering the specific semantic nuances of each question. By incorporating cost regret, the method ensures that failures don’t excessively drain the budget. The MAB framework effectively learns to dynamically allocate resources, maximizing accuracy while minimizing LLM-related expenses. This approach stands out by directly integrating cost as a key factor within the optimization process itself, rather than treating it as a separate metric.
Context-Aware Policy#
A context-aware policy in a knowledge-based question answering (KBQA) system is crucial for efficient and accurate model selection. Instead of using a single model for all questions, a context-aware approach analyzes the question’s content (e.g., using embeddings from a language model) to identify its key characteristics and choose the most suitable model from a pool of candidates (LLMs and KGMs). This is essential because different models excel in handling various types of questions and knowledge domains. The policy dynamically balances exploration and exploitation, learning from past successes and failures to optimize both inferential accuracy and cost. This intelligent selection mechanism leads to improved performance by leveraging the strengths of diverse models while mitigating their individual weaknesses and reducing unnecessary computational costs associated with less suitable models. A key aspect is the design of a reward function which guides the learning process, incentivizing the selection of models that provide accurate answers at a low cost, effectively navigating the trade-off between accuracy and efficiency. Furthermore, a context-aware policy could incorporate additional context such as user preferences or question history for even more personalized and refined model selection.
Pareto Frontier Shift#
The concept of “Pareto Frontier Shift” in the context of a research paper likely refers to improvements achieved in a multi-objective optimization problem. Specifically, it suggests that a proposed method or algorithm has successfully navigated a trade-off between two or more conflicting objectives, resulting in a new optimal solution that surpasses previous benchmarks. This usually involves improving one metric while not significantly worsening the others, thus shifting the Pareto frontier. In the given research paper focusing on knowledge-based question answering (KBQA), the Pareto frontier likely represents the trade-off between accuracy and cost. A Pareto frontier shift would thus signify that the new model achieves higher accuracy at a lower cost than previous state-of-the-art models. This is a significant contribution because it implies both improved performance and increased efficiency, offering a better balance between desirable properties. The analysis of this shift would include quantitative metrics demonstrating the extent of improvement, allowing for a comparison against existing methods and highlighting the practical implications of the enhanced efficiency and effectiveness of the proposed model.
Future Research#
Future research directions stemming from this cost-efficient knowledge-based question answering (KBQA) strategy using large language models (LLMs) could explore several promising avenues. Extending Coke to handle more complex question types, such as those requiring multi-step reasoning or integrating external information beyond knowledge graphs, is crucial. Improving the context-aware policy via more sophisticated techniques like reinforcement learning or incorporating external knowledge sources could further enhance accuracy. The current model relies on pre-trained embeddings; exploring fine-tuning or adapting embeddings specifically for KBQA could yield significant gains. A major limitation is the dependence on existing model quality; future work should investigate developing new models specifically optimized for cost-effectiveness within the KBQA framework. Finally, investigating the generalizability of Coke across various domains and languages and evaluating its performance on low-resource settings is essential to broaden its practical applicability.
More visual insights#
More on figures

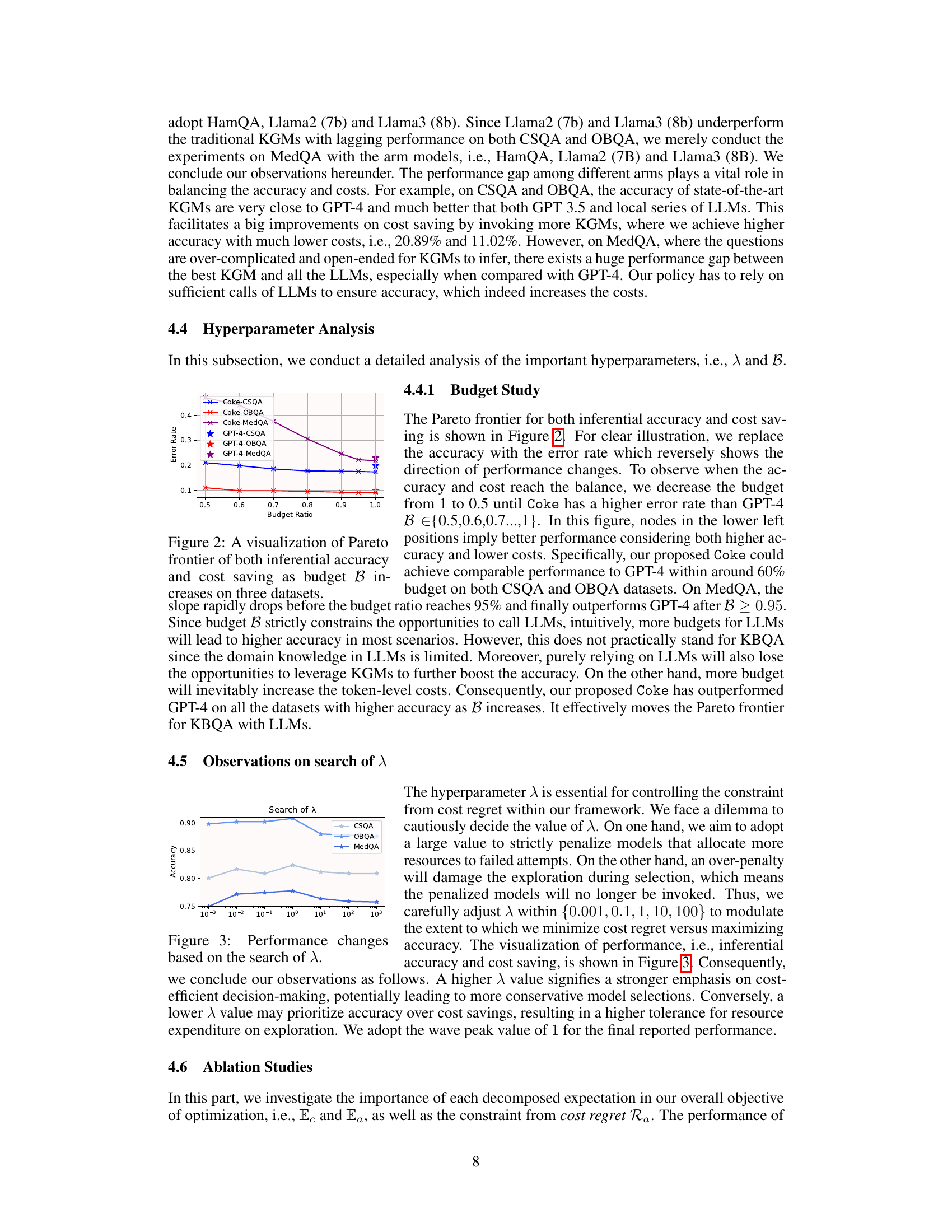
🔼 This figure shows the Pareto frontier for both inferential accuracy (represented as error rate) and cost saving as the budget (B) varies. Points on the lower-left are better, indicating higher accuracy and lower cost. The plot shows how the proposed Coke method compares to GPT-4 on three benchmark datasets (CommonsenseQA, OpenBookQA, and MedQA) across different budget ratios. The curves illustrate the trade-off between accuracy and cost, demonstrating how Coke achieves a balance.
read the caption
Figure 2: A visualization of Pareto frontier of both inferential accuracy and cost saving as budget B increases on three datasets.

🔼 This figure shows how the performance of the model (accuracy) changes as the hyperparameter λ is varied. The x-axis represents the value of λ, while the y-axis shows the accuracy achieved on three different datasets: CSQA, OBQA, and MedQA. The plot illustrates the impact of λ on the balance between exploration and exploitation in the model’s decision-making. A suitable value of λ needs to be selected to achieve a balance between accuracy and cost efficiency.
read the caption
Figure 3: Performance changes based on the search of λ.

🔼 This figure provides a 3D visualization of the selection regret across three datasets (CommonsenseQA, OpenBookQA, and MedQA) as the number of iterations (k) increases. The selection regret represents the difference between the expected reward of the best arm (model) and the selected arm in each iteration. The visualization helps illustrate how the regret evolves and converges over time, offering insights into the model’s performance and the effectiveness of the selection strategy. The x-axis represents the number of iterations, the y-axis represents the number of arms (models), and the z-axis shows the selection regret. The color gradient shows the magnitude of the regret.
read the caption
Figure 4: A 3D toy visualization of the selection regret on three datasets as iteration k goes.

🔼 This figure visualizes the model selection process of the proposed Coke framework on three datasets: CommonsenseQA, OpenBookQA, and MedQA. Each subplot represents a dataset and shows a heatmap illustrating the number of times each model (HamQA, ChatGPT, GPT-4) was selected within specific ranges of iterations (k). The color intensity indicates the frequency of selection, with darker colors representing more frequent selections. This visualization showcases how Coke balances exploration (trying different models) and exploitation (using the best-performing models) over time. The transitions from lighter to darker shades within each subplot show the progression of the model selection process, indicating how Coke learns and adapts its strategy as more questions are answered.
read the caption
Figure 5: A case study of the model selection on three domain-specific datasets as k goes. The color changes from deep to shallow indicates an exploration process, while an exploitation reversely.
Full paper#