TL;DR#
Many real-world applications of multi-agent reinforcement learning (MARL), such as autonomous vehicles and robot swarms, demand safe and cooperative behavior among agents. However, existing safe MARL methods often rely on a centralized value function and global state information, which limits scalability and applicability in resource-constrained systems. These methods struggle to manage the exponential growth of the state-action space and the communication overhead associated with global state sharing.
This paper introduces a novel, scalable, and theoretically-justified multi-agent constrained policy optimization method, termed Scalable MAPPO-Lagrangian (Scal-MAPPO-L). This method addresses the limitations of existing methods by employing a decentralized approach using local interactions and k-hop policies. By integrating rigorous bounds from the trust region method and the truncated advantage function, the method guarantees both safety constraints and improved reward performance. Empirical evaluation on various benchmark tasks demonstrates its effectiveness and validates the theoretical findings, showing that decentralized training with local interactions can significantly improve reward performance and maintain safety.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-agent reinforcement learning (MARL) and robotics because it offers a scalable solution for safe and cooperative multi-agent systems. The decentralized approach, avoiding reliance on global state information, makes it applicable to real-world scenarios with communication constraints. The provided theoretical guarantees and empirical results support the method’s effectiveness, opening avenues for safer and more efficient MARL applications.
Visual Insights#
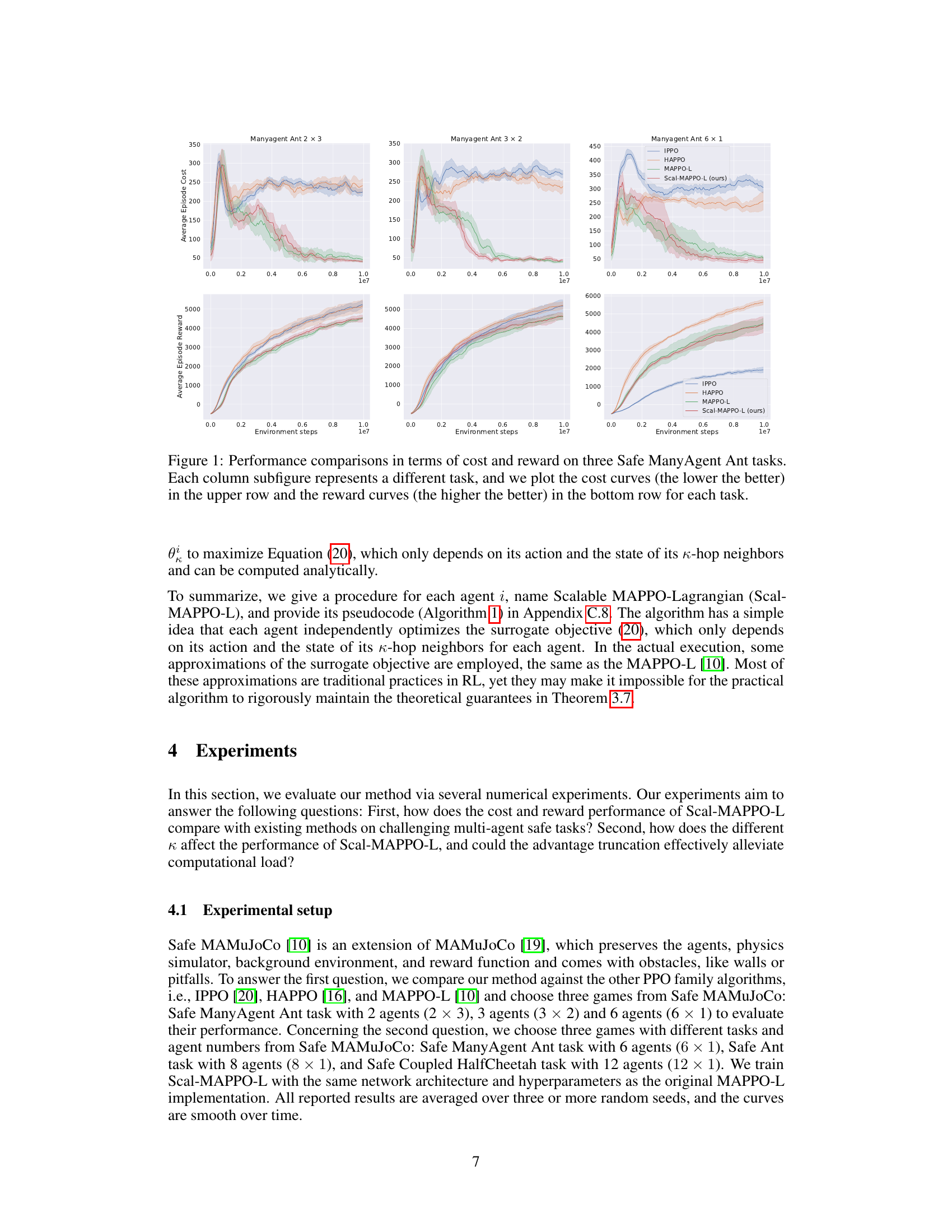
🔼 This figure compares the performance of four different algorithms (IPPO, HAPPO, MAPPO-L, and Scal-MAPPO-L) on three variations of the Safe ManyAgent Ant task. Each task varies the number of agents and their arrangement. The top row shows the average episode cost for each algorithm, with lower values indicating better performance. The bottom row shows the average episode reward, where higher values are better. The shaded regions represent the standard deviation across multiple runs. The figure demonstrates that Scal-MAPPO-L achieves comparable performance to MAPPO-L while being more computationally efficient, particularly given that it does not access the global state information unlike MAPPO-L.
read the caption
Figure 1: Performance comparisons in terms of cost and reward on three Safe ManyAgent Ant tasks. Each column subfigure represents a different task, and we plot the cost curves (the lower the better) in the upper row and the reward curves (the higher the better) in the bottom row for each task.
In-depth insights#
Safe Multi-agent RL#
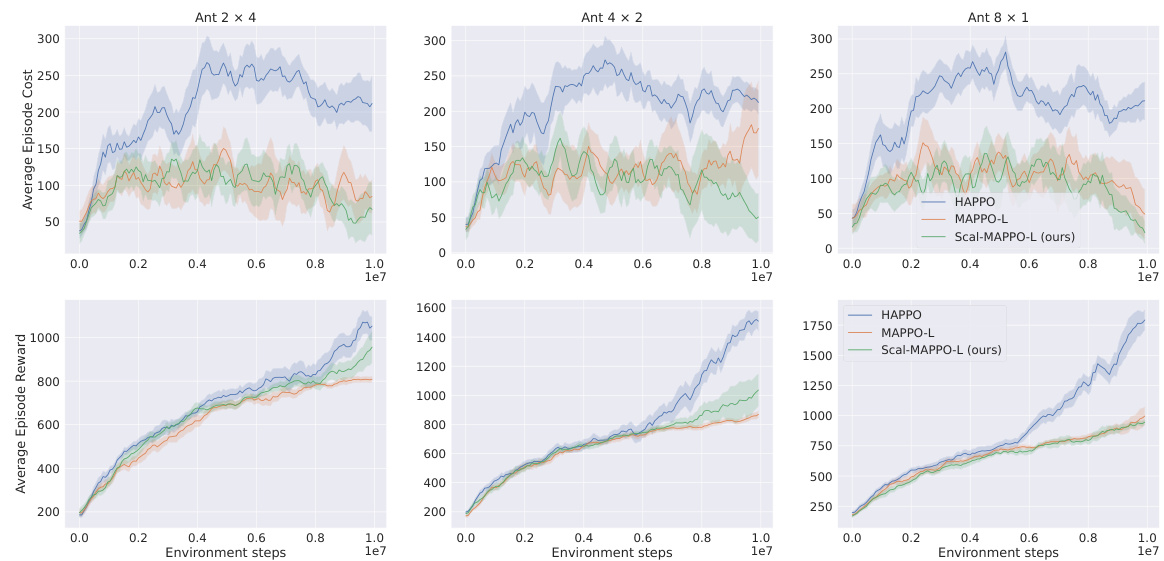
Safe multi-agent reinforcement learning (MARL) tackles the challenge of coordinating multiple agents to achieve a common goal while ensuring safety. Existing approaches often rely on centralized value functions, which become computationally intractable as the number of agents grows. This paper proposes a novel decentralized approach that uses local interactions and truncated advantage functions to overcome these limitations. By leveraging the spatial correlation decay property, the method achieves scalability and theoretical guarantees of both safety and reward improvement. Decentralized training reduces communication overhead, making it suitable for real-world applications with resource constraints. The practical algorithm, Scal-MAPPO-L, shows promising empirical results. However, the reliance on spatial correlation decay and the approximation of advantage functions are limitations; future work should investigate the robustness under various conditions and explore more sophisticated approaches for handling complex multi-agent interactions.
Scalable MAPPO-L#
Scalable MAPPO-L presents a novel approach to safe multi-agent reinforcement learning (MARL), addressing the scalability limitations of existing methods. It decouples the policy optimization process, allowing each agent to update its policy based on local interactions rather than relying on a global state. This decentralized approach reduces computational complexity and communication overhead, making it suitable for large-scale systems. The algorithm integrates trust region bounds and truncated advantage function bounds to ensure both safety constraints and policy improvement, providing theoretical guarantees. Sequential updates further enhance the algorithm’s efficiency by avoiding non-stationary issues associated with simultaneous policy updates. Empirical evaluations demonstrate Scalable MAPPO-L’s effectiveness and improved scalability across various benchmark tasks, highlighting its potential as a practical solution for real-world MARL applications.
Spatial Decay Impact#
The concept of “Spatial Decay Impact” in multi-agent reinforcement learning (MARL) centers on how an agent’s actions and observations are affected by distance from other agents. Spatial decay assumes that influence diminishes exponentially with distance, reducing the computational burden of modeling global interactions. This is crucial for scalability, as global state representations in MARL grow exponentially with the number of agents, rendering many approaches impractical for large systems. By exploiting spatial decay, decentralized algorithms become feasible, where each agent only needs to consider a limited neighborhood of other agents. However, the effectiveness of this approach hinges on the accuracy of the spatial decay assumption, and the choice of neighborhood size (K-hop) is a critical parameter affecting the balance between computational efficiency and performance. Stronger spatial decay allows for smaller neighborhoods, simplifying computations but potentially sacrificing some information about the global state. Conversely, weaker spatial decay necessitates larger neighborhoods, increasing computation but potentially leading to better decision-making due to more comprehensive information. The success of any spatial decay-based MARL method therefore depends critically on the precise characterization of the spatial correlation in the problem domain.
Decentralized Training#
Decentralized training in multi-agent reinforcement learning (MARL) offers a compelling alternative to centralized approaches by enabling agents to learn independently using only local observations. This paradigm is particularly attractive for large-scale systems or those with communication constraints, where global information exchange is impractical. The key challenge in decentralized training lies in addressing the non-stationarity inherent in the learning process, as each agent’s policy changes dynamically, affecting the environment experienced by others. This necessitates methods robust to this instability, potentially using techniques like independent Q-learning (IQL) or independent actor-critic (IAC). While these approaches offer simplicity, they often struggle with suboptimal performance due to the lack of coordination among agents. Networked MARL approaches offer a middle ground, allowing for limited communication between neighboring agents, which can improve coordination and mitigate some non-stationarity issues. However, these methods introduce complexities in managing communication and ensuring convergence. Recent research focuses on leveraging spatial correlation decay, a property where the influence of distant agents diminishes exponentially, enabling scalability in decentralized training. This concept is foundational for efficient algorithms that can still achieve good performance with limited information exchange. Decentralized training in MARL requires careful consideration of communication structures, algorithm design, and theoretical analysis to ensure efficient and robust learning while maintaining safety and overall system performance. The ongoing research seeks to further refine methods for handling non-stationarity, optimize communication strategies, and provide stronger theoretical guarantees for convergence and optimality.
Future Work: Safety#
Future research in safe multi-agent reinforcement learning (MARL) should prioritize addressing scalability challenges in real-world applications. Current methods often rely on centralized value functions or global state information, limiting their applicability to large-scale systems. Decentralized approaches that leverage local interactions and spatial correlation decay offer promising avenues for scalability, but require further investigation. Theoretical guarantees for decentralized training algorithms need to be strengthened, especially concerning the convergence and stability of policy updates under safety constraints. Robustness to model uncertainty and noisy environments is critical, demanding more research into uncertainty quantification and robust optimization techniques. Finally, exploring novel safety mechanisms beyond constraints and penalties could enhance the reliability and trustworthiness of safe MARL agents, potentially integrating concepts from formal methods or control theory.
More visual insights#
More on figures

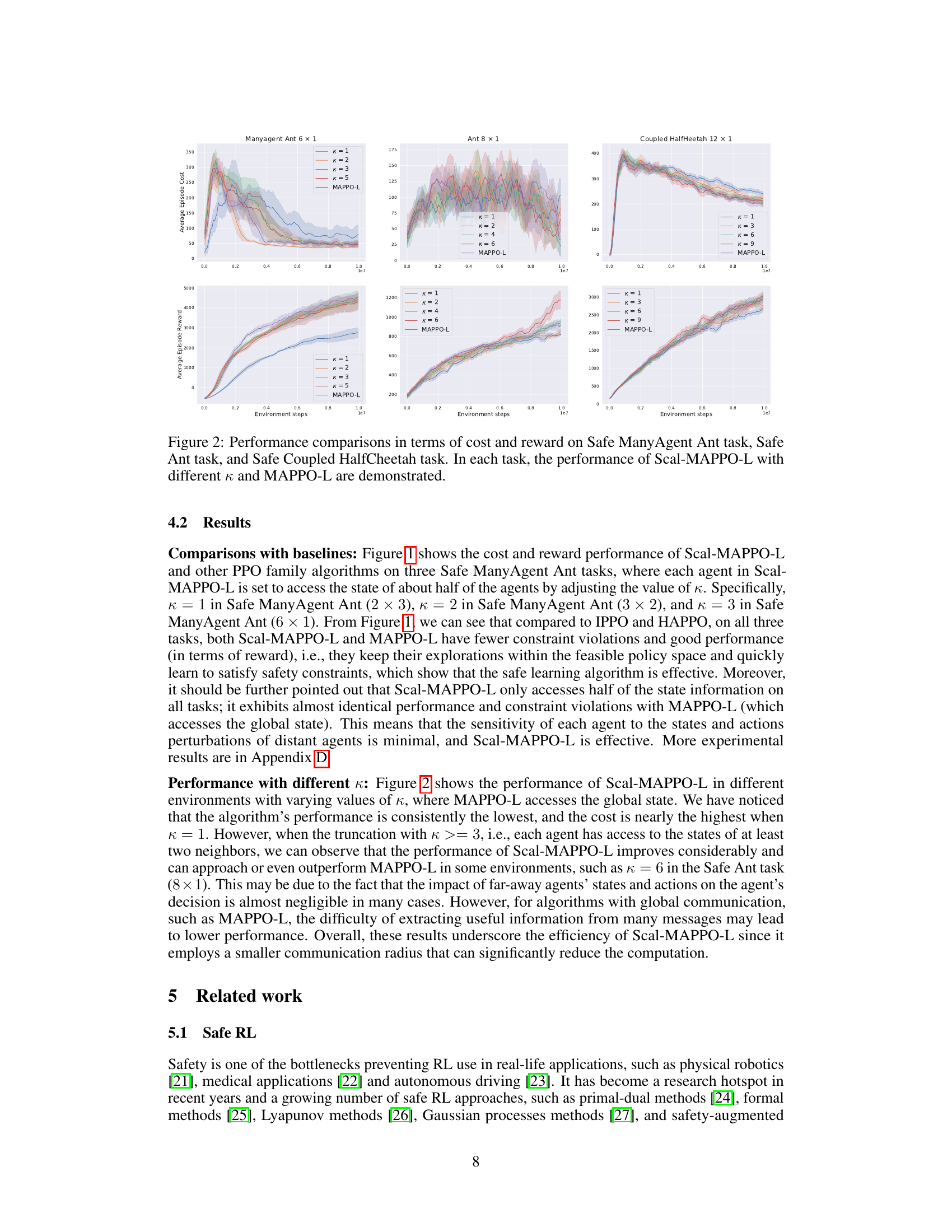
🔼 This figure compares the performance of Scal-MAPPO-L with different values of K (the number of neighboring agents considered) against the performance of MAPPO-L (which considers the global state) on three different safe multi-agent reinforcement learning tasks. The plots show the average episode cost and reward over time for each algorithm and different K values. This helps to demonstrate the impact of the local information constraint and the effectiveness of the proposed Scal-MAPPO-L algorithm in achieving both high reward and satisfying safety constraints.
read the caption
Figure 2: Performance comparisons in terms of cost and reward on Safe ManyAgent Ant task, Safe Ant task, and Safe Coupled HalfCheetah task. In each task, the performance of Scal-MAPPO-L with different K and MAPPO-L are demonstrated.
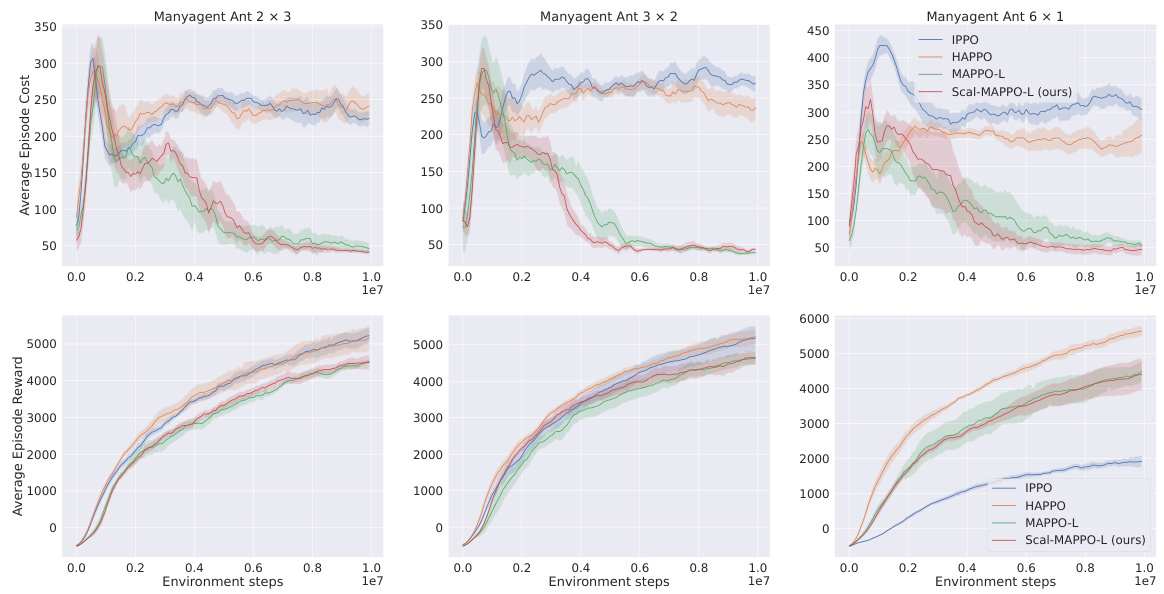
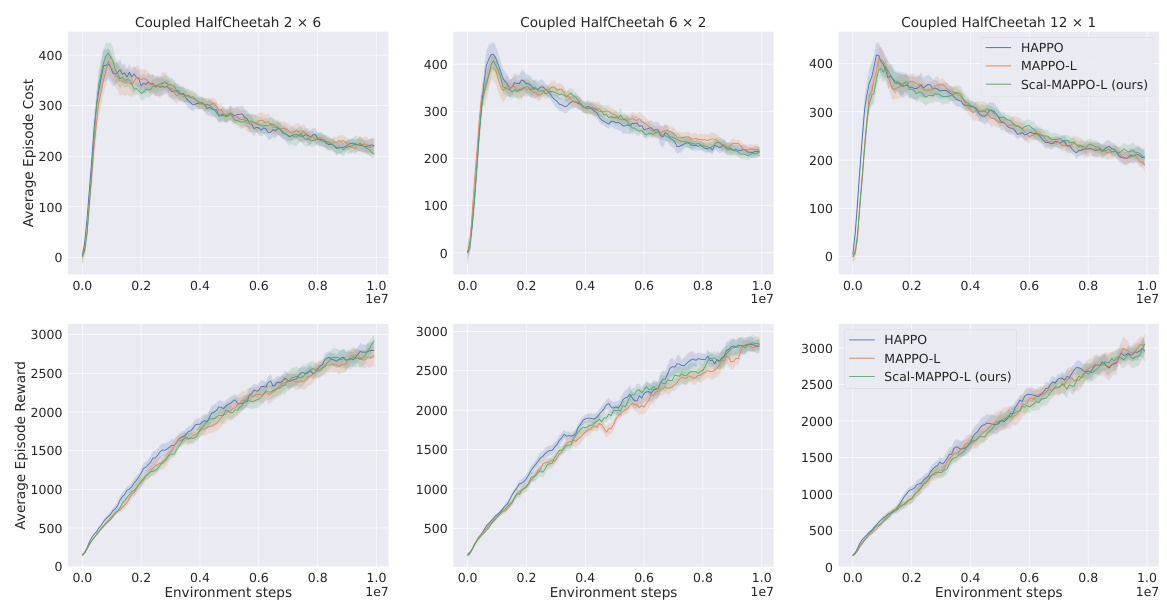
🔼 This figure compares the performance of four different multi-agent reinforcement learning algorithms (IPPO, HAPPO, MAPPO-L, and Scal-MAPPO-L) on three variations of the Safe ManyAgent Ant task. The plots show both the average episode cost and the average episode reward for each algorithm over the course of training. Lower cost is better and higher reward is better. The results demonstrate that the Scal-MAPPO-L algorithm, which is proposed by the authors, achieves comparable or better performance while only accessing local state information, unlike the other algorithms which access more global information.
read the caption
Figure 1: Performance comparisons in terms of cost and reward on three Safe ManyAgent Ant tasks. Each column subfigure represents a different task, and we plot the cost curves (the lower the better) in the upper row and the reward curves (the higher the better) in the bottom row for each task.
🔼 This figure compares the performance of four different multi-agent reinforcement learning algorithms (IPPO, HAPPO, MAPPO-L, and Scal-MAPPO-L) on three variations of the Safe ManyAgent Ant task. Each task varies in the number of agents and their arrangement. The top row displays the average cost incurred during training, with lower values indicating better performance. The bottom row showcases the average reward obtained, where higher values signify better performance. The results visually demonstrate Scal-MAPPO-L’s comparable or superior performance in terms of both cost and reward compared to the other algorithms, especially considering its decentralized nature.
read the caption
Figure 1: Performance comparisons in terms of cost and reward on three Safe ManyAgent Ant tasks. Each column subfigure represents a different task, and we plot the cost curves (the lower the better) in the upper row and the reward curves (the higher the better) in the bottom row for each task.
Full paper#