↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open-vocabulary semantic segmentation (OVSS) is a challenging task aiming to segment novel classes without corresponding labels. Existing methods typically leverage Vision-Language Models (VLMs) alongside additional segmentation-specific networks, leading to high computational costs. This paper addresses these limitations. This paper tackles the high computational cost of existing OVSS methods. Current approaches rely on large, complex models with additional segmentation networks, resulting in high training costs and inefficient use of resources. This is especially problematic given the complexity of OVSS, which requires sophisticated techniques to handle unseen object classes. The problem is that existing methods rely on additional explicit segmentation-specific networks resulting in extensive training costs.
This research introduces Relationship Prompt Network (RPN), a novel method that uses prompt learning to enable a Vision-Language Model (VLM) to directly perform OVSS without any additional segmentation networks. RPN uses a Relationship Prompt Module (RPM) which generates relationship prompts guiding the VLM. The approach achieves state-of-the-art performance with significantly fewer parameters than existing models. This demonstrates the efficacy of prompt learning in simplifying the OVSS pipeline and highlights the potential for parameter-efficient models in computer vision.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a parameter-efficient approach to open-vocabulary semantic segmentation, a challenging problem in computer vision. It offers a novel solution that significantly reduces training costs, making it more accessible to researchers with limited resources. The method’s success in achieving state-of-the-art results with a small number of parameters opens new avenues for research in efficient model training and knowledge transfer in vision-language models.
Visual Insights#

This figure visualizes the relationship attention maps generated by the Relationship Prompt Network (RPN) for three different classes: an airplane, a sheep, and a train. The color intensity represents the degree of attention, with darker blue indicating low attention and darker red indicating high attention. The figure demonstrates how the attention maps become increasingly precise at the pixel level as the network processes information through its layers, highlighting the network’s ability to refine its focus on relevant image regions to determine pixel-level semantics.
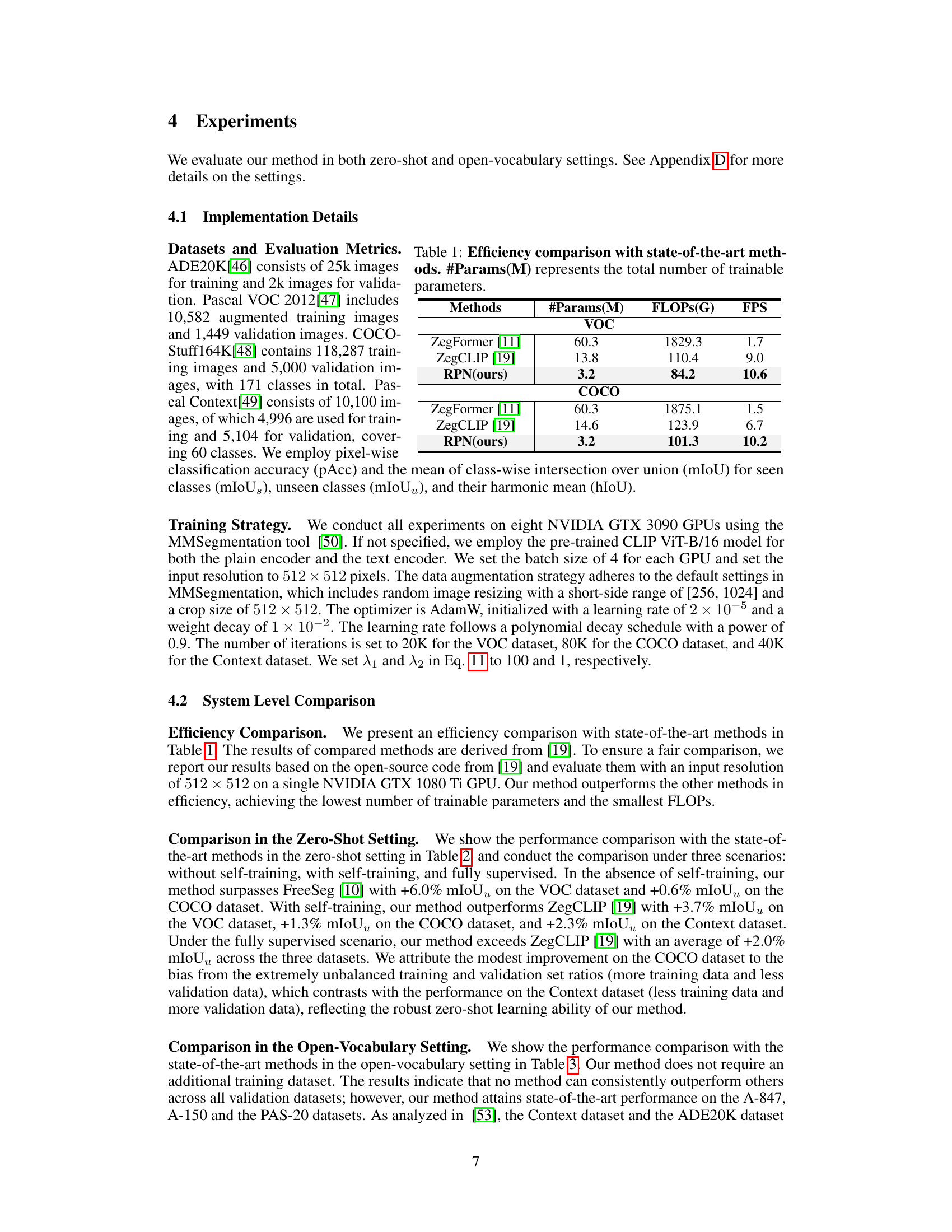
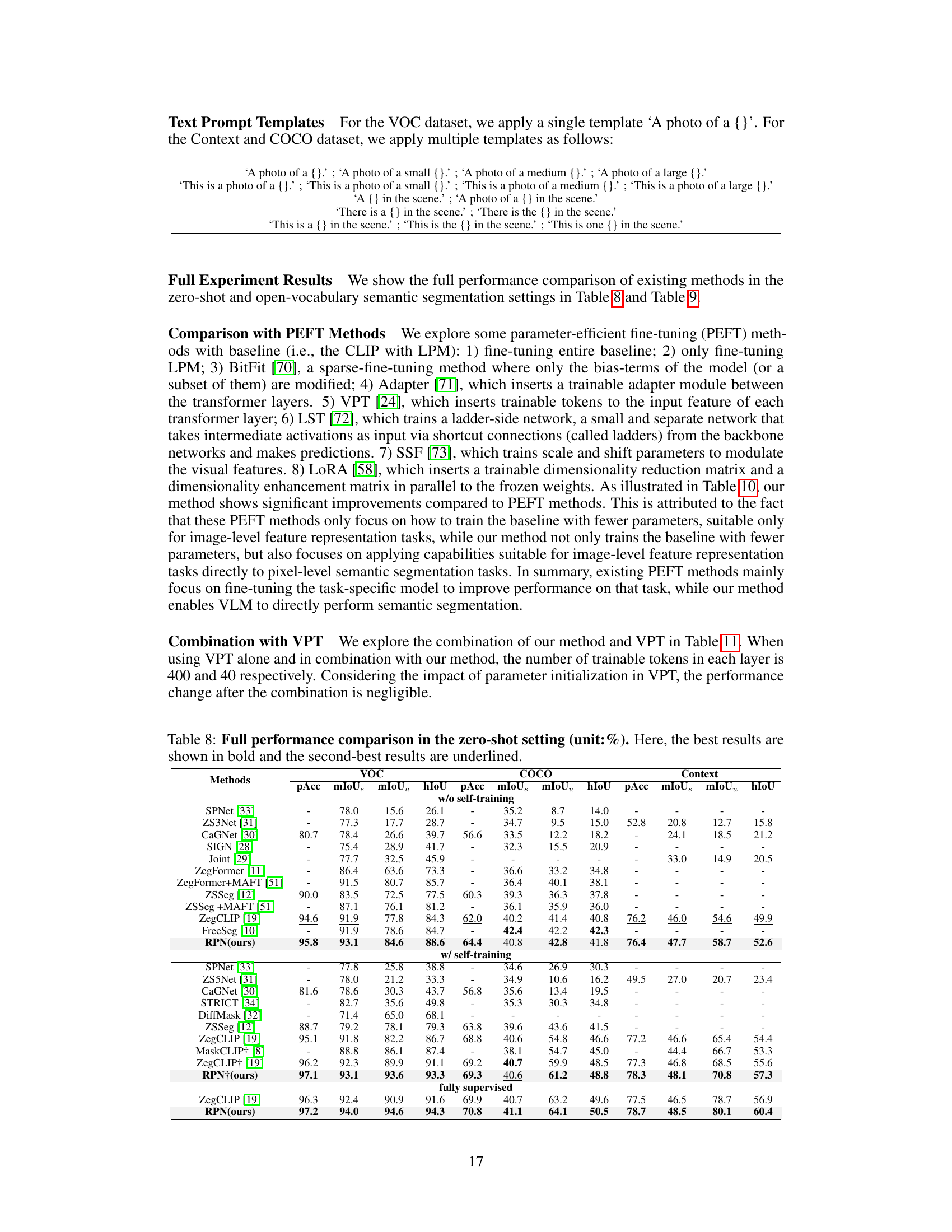
This table compares the efficiency of the proposed Relationship Prompt Network (RPN) method with two other state-of-the-art methods, ZegFormer and ZegCLIP, in terms of the number of trainable parameters (#Params), the number of floating point operations (FLOPS), and Frames Per Second (FPS) on the PASCAL VOC and COCO datasets. The results highlight the superior efficiency of RPN, which achieves comparable or better performance using significantly fewer parameters and FLOPS while maintaining a higher FPS.
In-depth insights#
Prompt Engineering#
Prompt engineering, in the context of large language models (LLMs), is the art and science of crafting effective prompts to elicit desired outputs. Careful prompt design is crucial because LLMs are highly sensitive to input phrasing. Slight variations in wording can significantly impact the quality and relevance of responses. Effective prompts often incorporate specific instructions, constraints, and examples to guide the LLM’s reasoning process. The challenge lies in understanding the underlying mechanisms of the LLM and exploiting these for optimal performance. Different prompting techniques, such as few-shot learning, chain-of-thought prompting, and self-consistency, have been developed to address specific limitations and enhance the LLM’s capabilities. Further research should focus on developing more robust and systematic prompt engineering methods, moving beyond trial-and-error approaches and establishing theoretical frameworks for understanding prompt effectiveness. This includes exploring the relationship between prompt characteristics and LLM behavior, developing automated prompt generation tools, and investigating the impact of prompt engineering on downstream applications.
VLM Adaptation#
VLM adaptation in open-vocabulary semantic segmentation (OVSS) focuses on effectively leveraging the knowledge embedded within Vision-Language Models (VLMs) for pixel-level tasks. A core challenge lies in bridging the gap between VLMs’ image-text understanding and the need for precise pixel-wise classifications. Direct adaptation methods aim to modify the VLM itself, often through prompt engineering or parameter-efficient fine-tuning techniques, to generate segmentation masks directly. This approach minimizes the need for additional, task-specific networks, reducing computational cost and complexity. Indirect adaptation methods, conversely, employ VLMs to enhance existing segmentation architectures, using the VLM’s knowledge to guide mask generation or refine pixel-level predictions. The effectiveness of each approach hinges on several factors: the choice of VLM architecture and pre-training data; the specific adaptation technique used (e.g., prompt engineering, LoRA, adapters); and the design of any auxiliary segmentation network, if used. Trade-offs between efficiency and accuracy are significant; while direct adaptation methods are computationally lighter, indirect approaches potentially yield superior performance. Future research may explore hybrid techniques, combining the benefits of both approaches for optimal results.
Efficiency Gains#
Analyzing efficiency gains in a research paper requires a multifaceted approach. A key aspect is identifying the specific techniques employed to achieve these gains. Were novel algorithms developed? Were existing methods optimized? Understanding these methods is crucial to assess their impact. The quantification of efficiency is equally important; a clear presentation of metrics like reduced computational time, memory usage, or parameter count is essential. It’s crucial to consider the context of these gains. Are they improvements over previous state-of-the-art methods? Do they represent a significant advance, or a more incremental improvement? Finally, any limitations or trade-offs associated with the efficiency gains should be discussed. For example, improved efficiency may come at the cost of reduced accuracy or increased complexity in implementation. A thorough examination of these aspects will provide a robust understanding of the actual efficiency gains reported.
Zero-Shot Results#
A zero-shot learning scenario evaluates a model’s ability to generalize to unseen classes during testing, without any prior training examples of those specific classes. Strong zero-shot performance indicates the model has learned robust, transferable features and representations from its training data. Analyzing zero-shot results requires careful consideration of the dataset’s composition, especially the balance between seen and unseen classes. Metric selection also plays a key role; for instance, focusing solely on accuracy might overlook nuanced performance differences captured by metrics like F1-score or IoU. Comparison to other methods within the zero-shot setting is essential, revealing if the model’s approach to generalization is more or less effective than existing techniques. Investigating potential biases inherent in the dataset, or limitations in the model’s architectural design that may hinder zero-shot generalization, is crucial. Overall, a thorough analysis of zero-shot results reveals how well a model generalizes beyond its training data and provides insights into its potential for broader real-world application. The results may highlight the need for further improvements or the robustness of a particular method.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the Relationship Prompt Module (RPM) to other vision tasks beyond semantic segmentation is a natural progression, potentially adapting it for tasks like object detection and instance segmentation. Investigating the impact of different large language models (LLMs) on RPN’s performance and exploring whether RPN can achieve improved results by utilizing the diverse knowledge embedded within different LLMs warrants further study. Additionally, developing more efficient training strategies for RPN, possibly through techniques like knowledge distillation or parameter-efficient fine-tuning, could significantly reduce training costs and broaden accessibility. Finally, a thorough investigation into the robustness of RPN against noisy or incomplete data, as well as evaluating its performance across a wider range of datasets, would enhance the reliability and generalizability of this approach. Incorporating diverse data augmentations or exploring alternative prompt engineering techniques could be useful in this endeavor.
More visual insights#
More on figures

This figure compares our proposed method with existing VLM-based methods for open-vocabulary semantic segmentation (OVSS). Our method directly adapts the Vision-Language Model (VLM) using prompt learning to produce segmentation results without needing additional segmentation-specific networks like mask proposal networks or semantic decoders. Existing methods, conversely, rely on these additional networks, leading to higher training costs and more parameters. The diagram visually highlights this key difference: our method is simpler, more efficient, and directly uses prompt learning for OVSS, while existing approaches rely on the VLM to guide extra segmentation networks through feature adaptation or knowledge distillation.

This figure presents the overall architecture of the Relationship Prompt Network (RPN). It shows the flow of image and text data through four main components: a frozen ViT-based encoder for image features enhanced with relationship prompts, a frozen CLIP text encoder for class embeddings, the Relationship Prompt Module (RPM) generating pixel-level prompts, and finally, the Linear Projection Module (LPM) that produces the final open-vocabulary semantic segmentation (OVSS) results. The figure highlights the integration of prompt learning directly within the VLM to achieve OVSS without additional segmentation-specific networks.
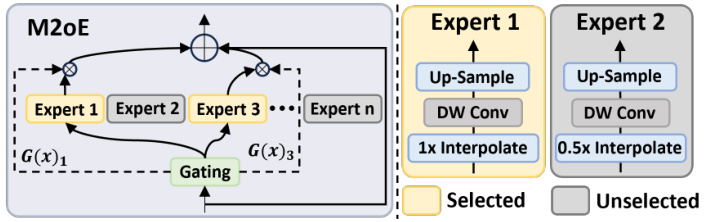
This figure illustrates the architecture of the Multi-scale Mixture-of-Experts (M20E) block. The M20E block is a component of the Relationship Prompt Module (RPM), which is designed to aggregate patch embeddings from different scales. It consists of several expert networks (Expert 1, Expert 2, …, Expert n), each processing the input at a different scale. A gating network dynamically selects the outputs from these experts, based on the input features. The selected expert’s output is then passed through additional layers (Up-sample, DW Conv, Interpolation) before being used for the next stage. The figure visually depicts how the gating network routes information to the selected experts according to the input, thereby achieving multi-scale feature aggregation.
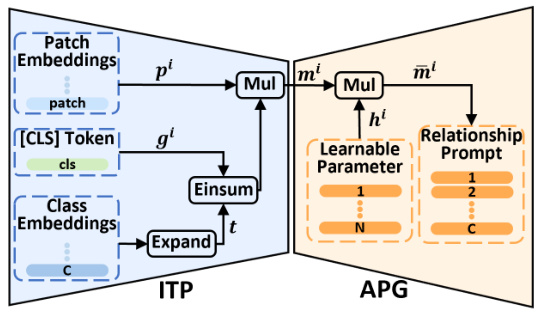
This figure shows the architecture of the Image-to-Pixel Semantic Attention (ITP) block and the Adaptive Prompt Generation (APG) block. The ITP block takes the class embeddings and the image embeddings as input and generates a relationship attention map. This map is then used by the APG block to generate a relationship prompt. The relationship prompt is a vector that is used to guide the plain encoder of the Vision-Language Model (VLM) to generate pixel-level semantic embeddings. This is crucial to perform pixel-level semantic segmentation.
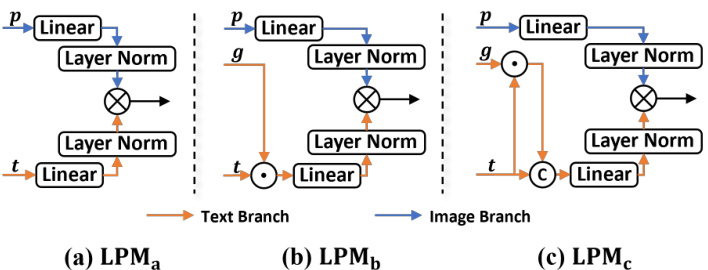
This figure presents three different designs for the Linear Projection Module (LPM) used in the Relationship Prompt Network (RPN). Each design has an image branch and a text branch, each with a linear layer and a normalization layer. The image branch processing remains the same across all three designs. The differences lie in how the text branch processes the last class embedding(s), which are input to the linear layer of the text branch in LPMa, LPMb processes the Hadamard product between the last class embedding and the last [CLS] token before inputting to the linear layer and LPMc concatenates the Hadamard product and the last class embedding before inputting to the linear layer. The figure highlights the different ways that the image and text branch embeddings are combined to produce the segmentation results.

This figure visualizes the relationship attention maps generated by the Relationship Prompt Network (RPN) at different layers. The color intensity represents the attention level, with darker red indicating higher attention and darker blue indicating lower attention. The maps show increasing precision in pixel-level semantic information as the layer depth increases. Three example images (airplane, sheep, and train) are shown alongside their corresponding attention maps.

This figure compares the proposed Relationship Prompt Network (RPN) method with existing VLM-based methods for open-vocabulary semantic segmentation. The RPN method directly uses a Vision-Language Model (VLM) with prompt learning to produce segmentation results, eliminating the need for additional segmentation-specific networks like mask proposal networks and semantic decoders used in existing methods. The existing methods leverage VLMs but require extra networks and thus are more computationally expensive. The key difference is that RPN is more straightforward and parameter-efficient, achieving state-of-the-art performance with fewer parameters.

This figure illustrates the motivation behind the design of the Relationship Prompt Module (RPM). It compares different prompt tuning methods: (a) the standard LoRA method, (b) a VLM-adapted version of LoRA, (c) the proposed VLM relationship prompt method, and (d) a detailed breakdown of the components (IPT and APG) used in (c). The figure highlights the differences in how these methods interact with the frozen VLM weights, explaining why the RPM approach is more effective for open-vocabulary semantic segmentation.

This figure presents a qualitative comparison of the proposed Relationship Prompt Network (RPN) against a baseline method for open-vocabulary semantic segmentation. It shows several example images with their corresponding ground truth segmentations, the segmentation results produced by the RPN method, and the segmentation results of the baseline. The comparison highlights the RPN’s ability to accurately segment unseen classes (tree, frisbee, grass, and road), demonstrating its effectiveness in open-vocabulary semantic segmentation. The differences in segmentation quality between RPN and baseline underscore the improvements achieved by integrating the Relationship Prompt Module.

This figure shows a qualitative comparison of the proposed Relationship Prompt Network (RPN) method with a baseline method on the task of open-vocabulary semantic segmentation. The comparison is made for four images, each containing objects from unseen classes. For each image, there are four sub-images showing: (a) The original image; (b) The ground truth segmentation mask; (c) The segmentation mask produced by the RPN method; (d) The segmentation mask produced by the baseline method. The color legend identifies the unseen classes.
More on tables
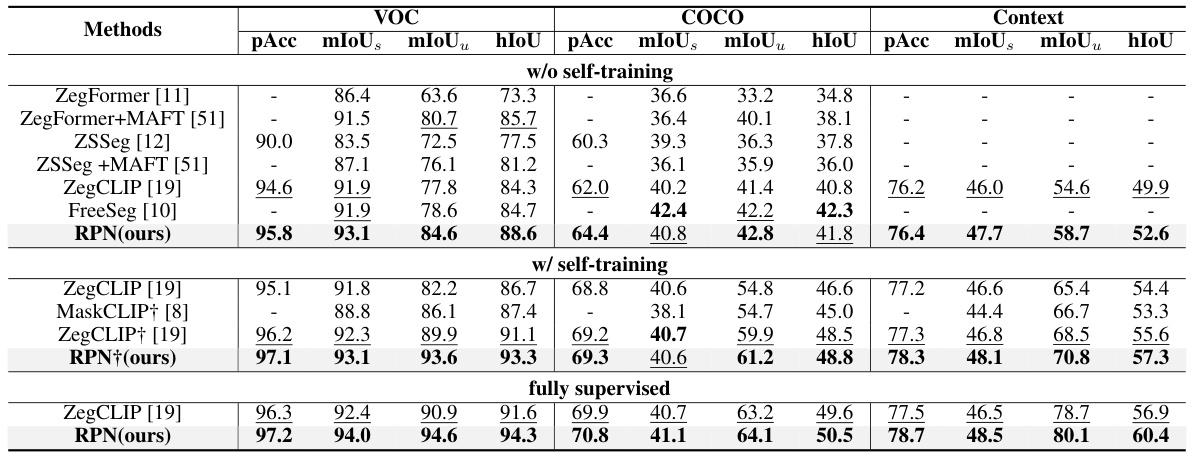
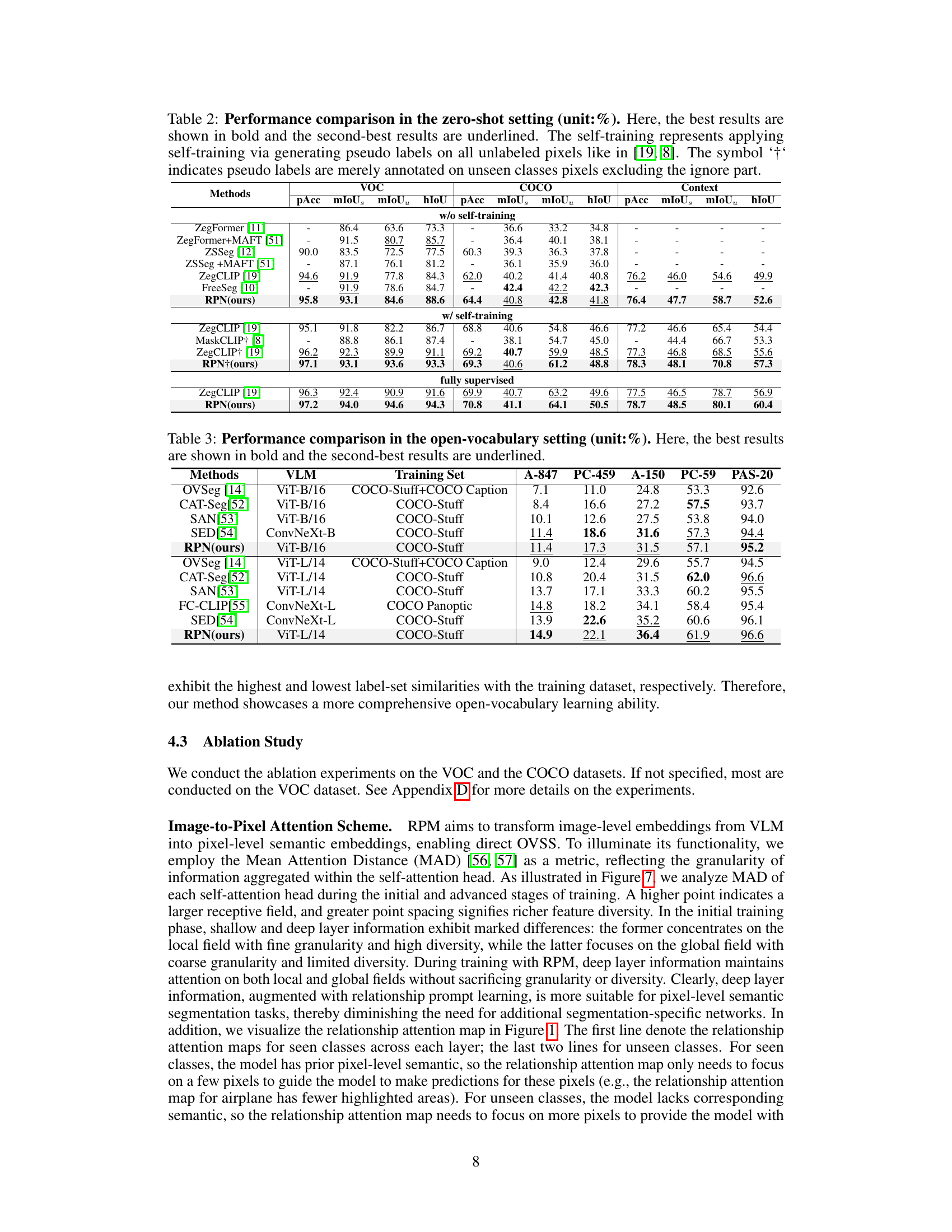
This table compares the performance of different methods for zero-shot semantic segmentation on three datasets: VOC, COCO, and Context. The comparison is done with and without self-training, showing pixel accuracy (pAcc), mean Intersection over Union (mIoU) for seen classes (mIoUs), unseen classes (mIoUu), and harmonic mean of IoU (hIoU). The results highlight the effectiveness of the proposed RPN method, especially when self-training is employed.
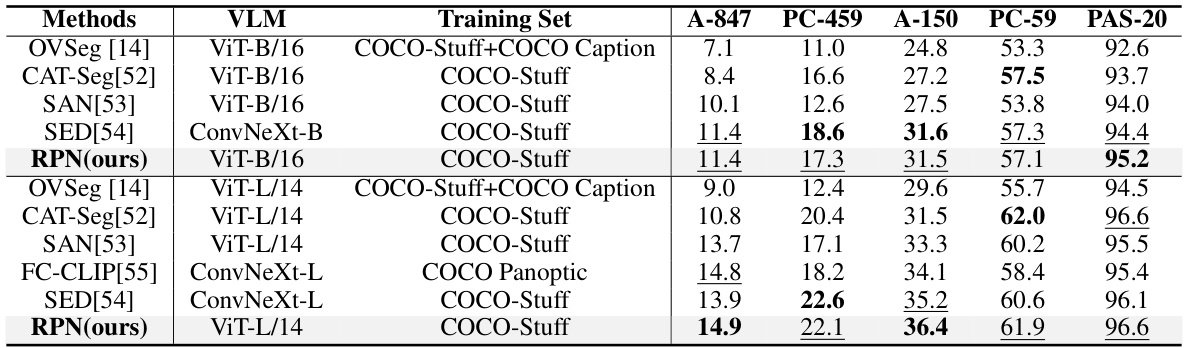
This table presents a comparison of different methods for open-vocabulary semantic segmentation. The methods are evaluated on several datasets (A-847, PC-459, A-150, PC-59, PAS-20) using various Vision Language Models (VLMs) and training sets. The table highlights the performance of each method in terms of pixel-wise accuracy, showcasing the relative strengths and weaknesses of different approaches in handling unseen classes during the segmentation process. The best and second best results for each dataset are highlighted for easy comparison.
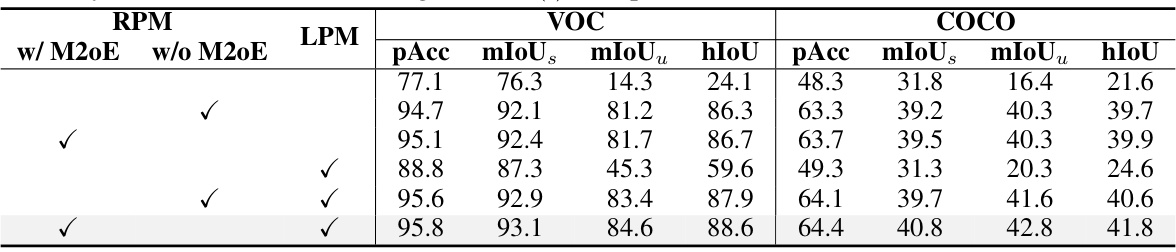
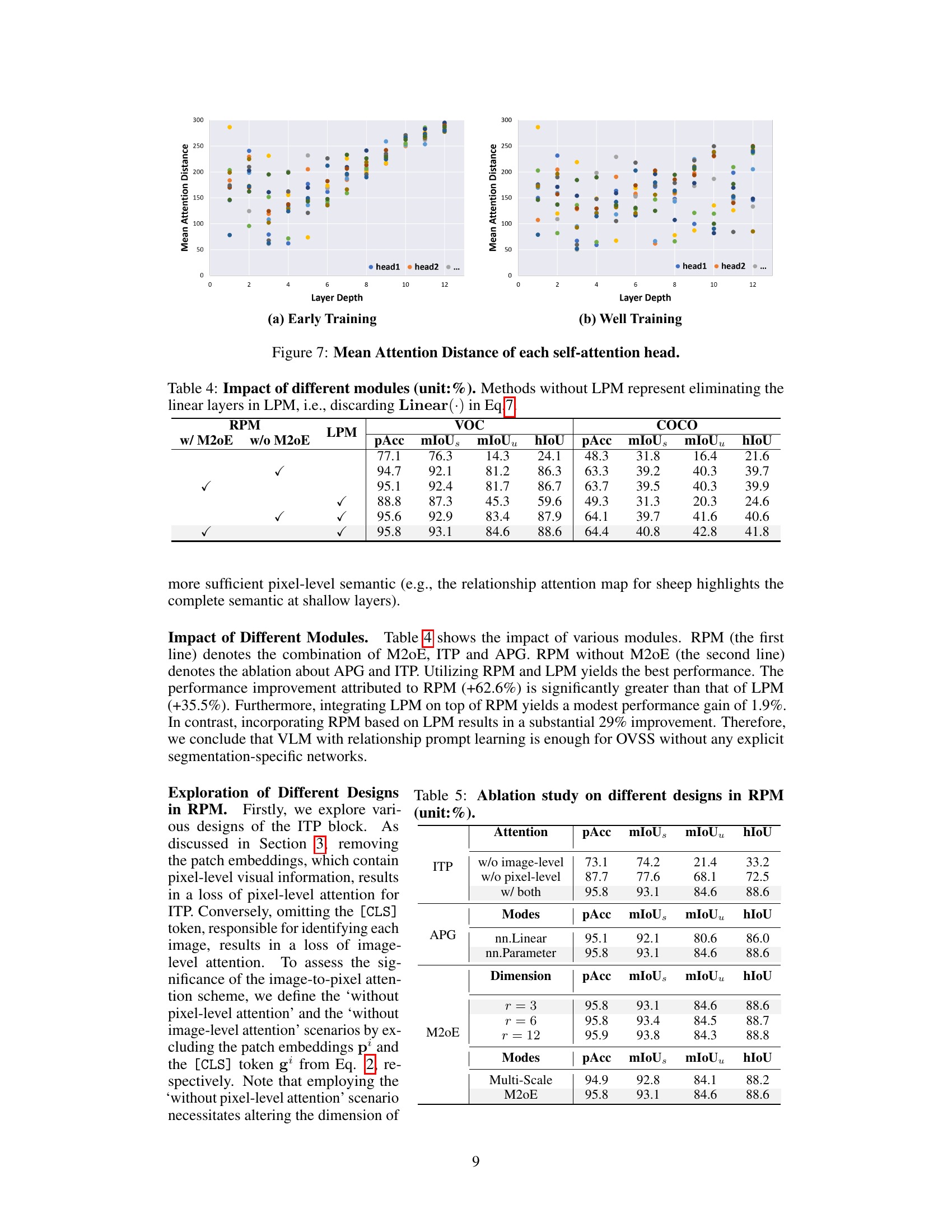
This table presents the ablation study on the impact of different modules in the proposed Relationship Prompt Network (RPN). It compares the performance of the RPN with different combinations of the Relationship Prompt Module (RPM) components (M20E, ITP, APG) and the Linear Projection Module (LPM). The results show the contribution of each module and the overall impact of combining them. Removing LPM leads to a significant decrease in performance, while removing M20E leads to a moderate decrease. The results demonstrate that RPM is essential for high performance.
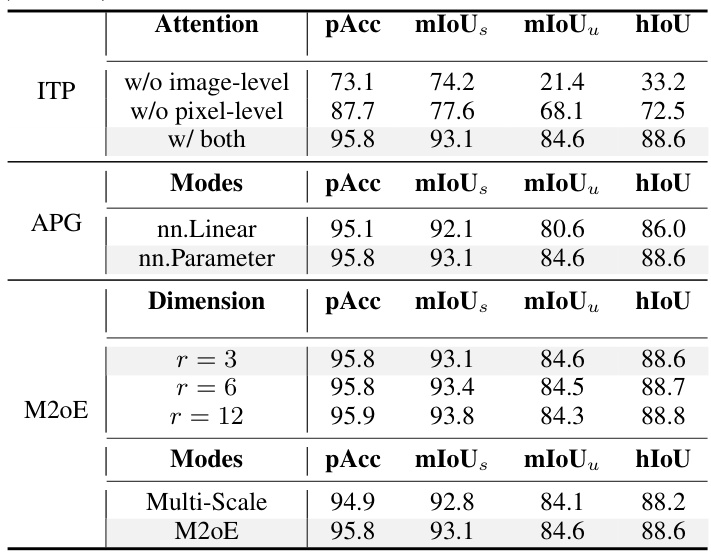
This table presents the ablation study of different designs within the Relationship Prompt Module (RPM). It explores the impact of removing image-level or pixel-level attention from the Image-to-Pixel Semantic Attention (ITP) block, the effect of using different activation functions (nn.Linear vs. nn.Parameter) in the Adaptive Prompt Generation (APG) block, and the impact of varying the dimension (r) and using different modes (Multi-Scale vs. M20E) in the Multi-scale Mixture-of-Experts (M20E) block. The results show the impact of each component on the overall performance (pAcc, mIoUs, mIoUu, hIoU).

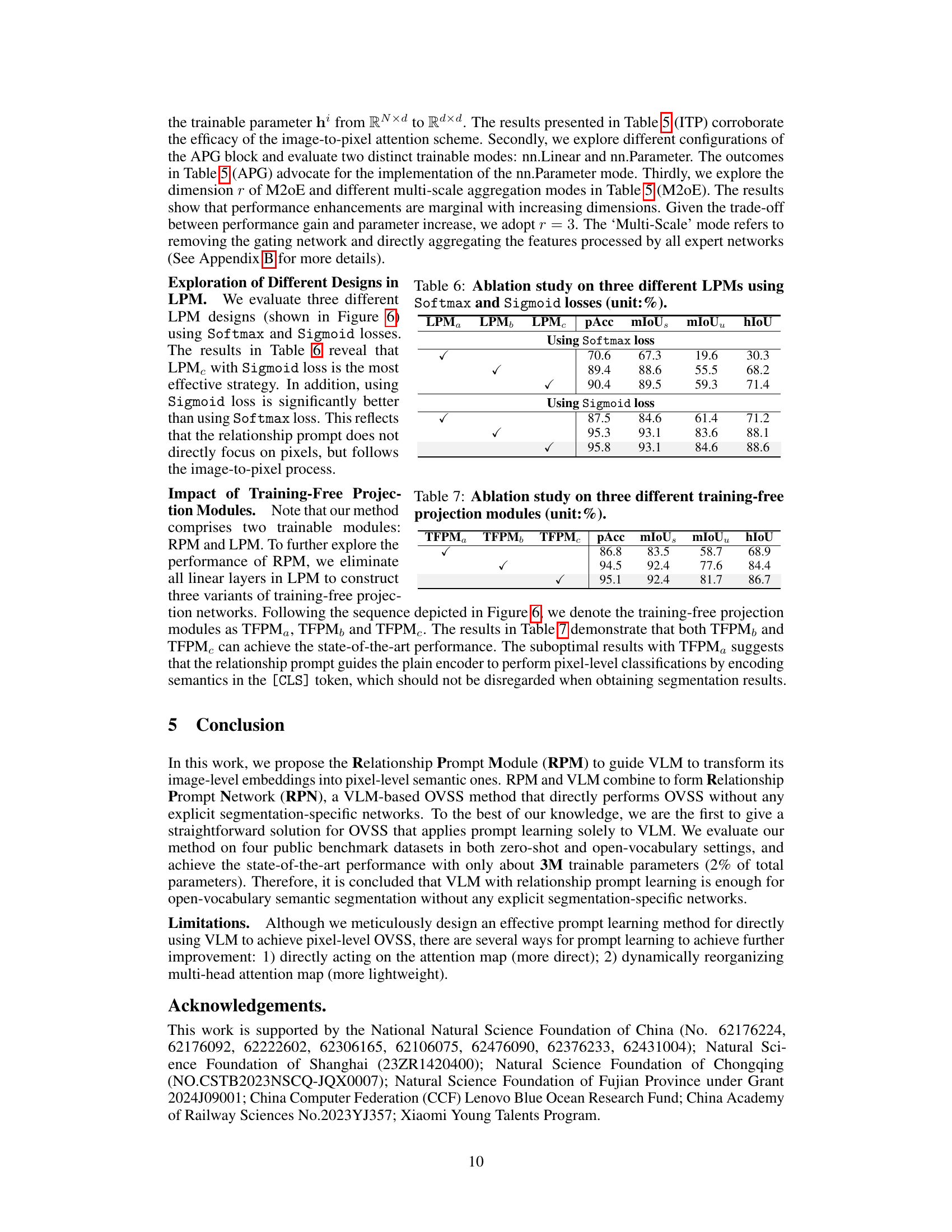
This table presents the ablation study on three different Linear Projection Module (LPM) designs, namely LPMa, LPMb, and LPMC, using two different loss functions: Softmax and Sigmoid. Each LPM design is evaluated using both loss functions, showcasing the impact of the LPM design and loss function on the performance metrics: pixel accuracy (pAcc), mean Intersection over Union for seen classes (mIoUs), mean Intersection over Union for unseen classes (mIoUu), and their harmonic mean (hIoU). The results highlight the effectiveness of LPMc with the Sigmoid loss, achieving the best performance across all metrics.

This table presents the ablation study of three different training-free projection modules (TFPMs). The TFPMs are variants of the Linear Projection Module (LPM) that do not contain any trainable parameters. The table shows the performance (pAcc, mIoUs, mIoUu, and hIoU) achieved by each TFPM variant, indicating the impact of each module on the overall model’s performance in semantic segmentation.

This table compares the performance of various methods on three datasets (VOC, COCO, and Context) in a zero-shot semantic segmentation setting. It shows pixel accuracy (pAcc), mean IoU (mIoUs), mean IoU for unseen classes (mIoUu), and harmonic mean IoU (hIoU). Results are presented for three scenarios: without self-training, with self-training (using pseudo labels on unseen classes), and fully supervised. The table highlights the relative performance of different methods under each scenario and dataset.

This table compares the performance of different methods on three datasets (VOC, COCO, and Context) in a zero-shot semantic segmentation setting. The results are broken down by several metrics: Pixel Accuracy (pAcc), mean Intersection over Union for seen classes (mIoUs), mean Intersection over Union for unseen classes (mIoUu), and harmonic mean of IoU (hIoU). The table further shows the results with and without self-training, and with fully supervised training, offering a comprehensive comparison under various conditions.
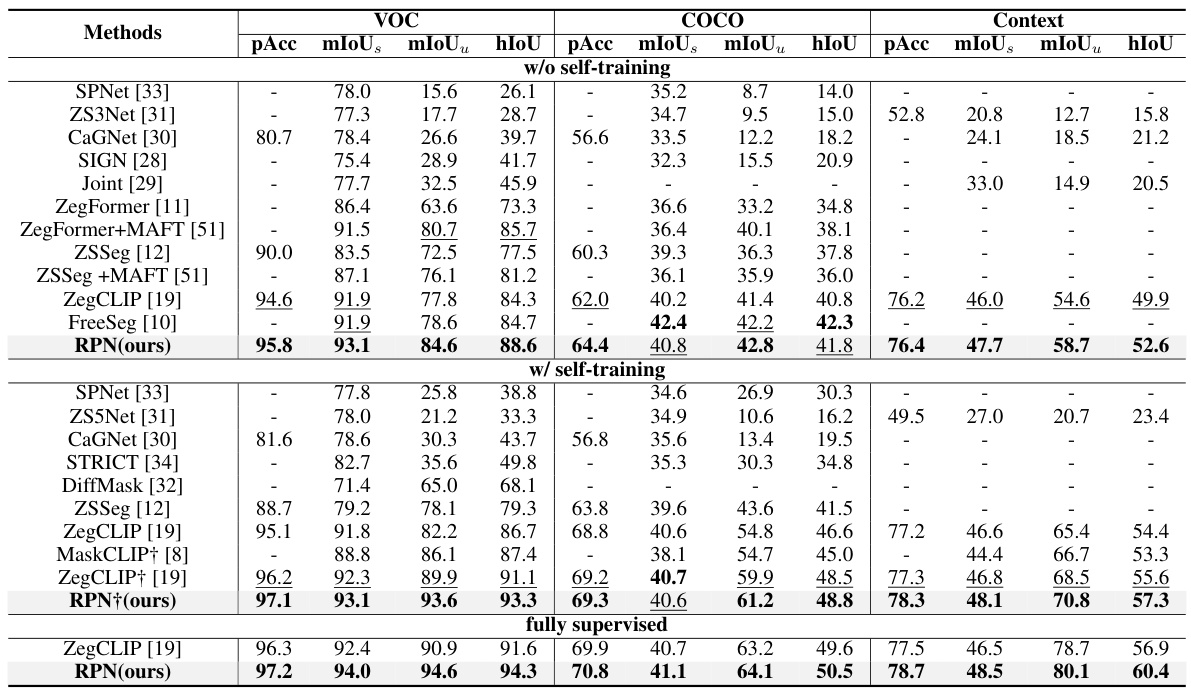
This table presents a comparison of different methods’ performance in a zero-shot semantic segmentation setting. The metrics used are pixel accuracy (pAcc), mean Intersection over Union for seen classes (mIoUs), mean IoU for unseen classes (mIoUu), and harmonic mean IoU (hIoU). The comparison is done across three datasets (VOC, COCO, and Context) and includes results with and without self-training. The self-training approach involves generating pseudo labels for unseen classes to improve model performance. Results are also provided for a fully supervised scenario for comparison.

This table compares the performance of different methods for open-vocabulary semantic segmentation on various datasets. The methods are evaluated based on their performance using Vision Language Models (VLMs) and different training sets. The results are presented as mean Intersection over Union (mIoU) scores for several classes in each dataset. The table highlights the effectiveness of the proposed method compared to existing state-of-the-art techniques.

This table compares the performance of the proposed Relationship Prompt Network (RPN) method against various parameter-efficient fine-tuning (PEFT) methods. The baseline is the CLIP model with Linear Projection Module (LPM). The table shows the performance (pAcc, mIoU, mIoUu, hIoU) on the VOC and COCO datasets for each method, along with the number of trainable parameters (#Params(M)). This allows for a direct comparison of efficiency and effectiveness between different approaches to adapting the CLIP model for semantic segmentation.

This table presents the results of combining the proposed Relationship Prompt Network (RPN) method with Visual Prompt Tuning (VPT). It compares the performance (pAcc, mIoUs, mIoUu, hIoU) on the VOC and COCO datasets, showing that adding VPT to RPN does not significantly improve performance while increasing the number of trainable parameters.

This table presents the performance comparison of using different pre-trained weights (ViT, MAE, and CLIP) for the plain encoder in the proposed Relationship Prompt Network (RPN). The results are shown in terms of pixel accuracy (pAcc), mean IoU for seen classes (mIoUs), mean IoU for unseen classes (mIoUu), and harmonic mean IoU (hIoU) for both VOC and COCO datasets. It demonstrates the effect of different pre-training strategies on the model’s performance in open-vocabulary semantic segmentation.
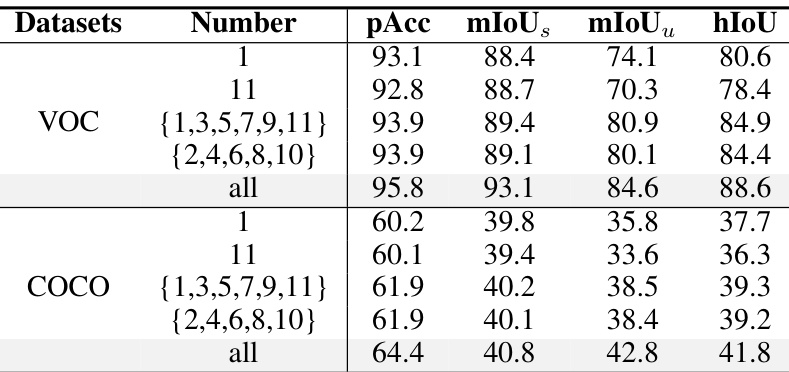
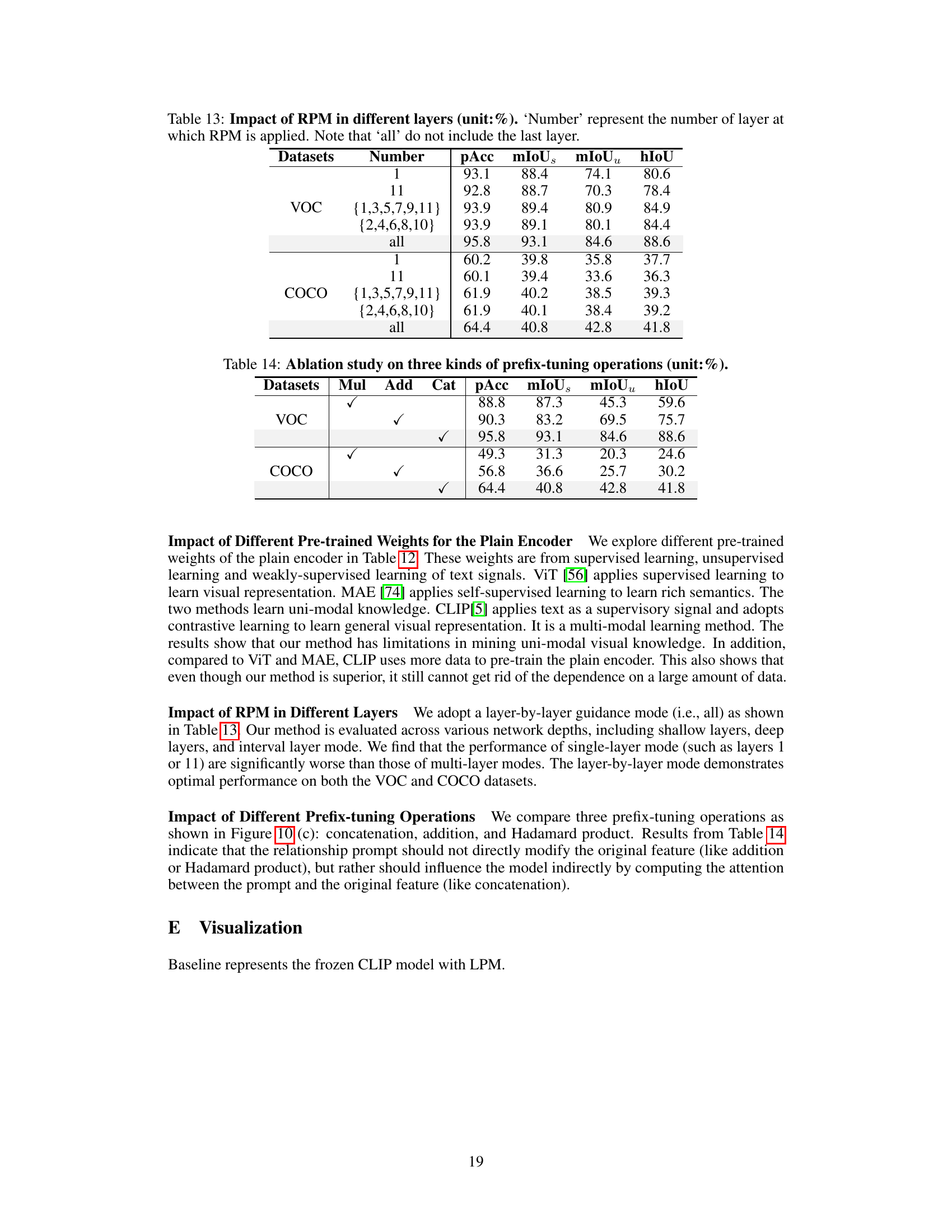
This ablation study investigates the impact of applying the Relationship Prompt Module (RPM) at different layers of the vision language model. It shows the performance of applying RPM at different layers (1, 11, {1,3,5,7,9,11}, {2,4,6,8,10}, and all) on two datasets (VOC and COCO). The results indicate that applying RPM at multiple layers significantly improves performance compared to applying it at a single layer.
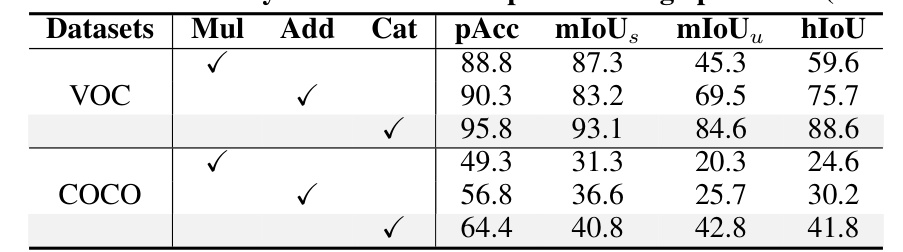
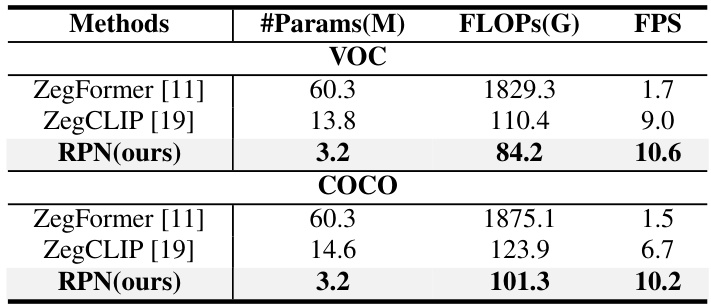
This table presents the ablation study of three different prefix-tuning operations (multiplication, addition, and concatenation) used in the Relationship Prompt Module (RPM). It shows the impact of each operation on the performance metrics (pAcc, mIoUs, mIoUu, hIoU) for both VOC and COCO datasets. The results demonstrate that concatenation is the most effective operation, yielding the best performance across all metrics and both datasets.
Full paper#