TL;DR#
Multispectral video semantic segmentation (MVSS) is gaining traction due to its capability of improving segmentation under difficult visual conditions. However, the existing MVSS datasets suffer from limited amounts of data and annotation sparsity, hindering the development of robust algorithms. This paper tackles these challenges by introducing two key contributions: a new benchmark dataset, MVUAV, and a novel semi-supervised learning baseline, SemiMV.
MVUAV, captured by UAVs, provides a unique bird’s-eye view and encompasses various lighting conditions and semantic categories, addressing the data scarcity issue. SemiMV utilizes a cross-collaborative consistency learning module and a denoised temporal aggregation strategy to enhance model performance with limited labeled data. Extensive evaluations on MVSeg and MVUAV demonstrated that SemiMV outperforms state-of-the-art methods, showcasing the efficacy of the proposed approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in semantic segmentation due to its introduction of a new, high-quality benchmark dataset (MVUAV) captured from a unique UAV perspective. The semi-supervised learning approach presented (SemiMV) also offers a novel way to leverage the limited amount of annotated data, improving the overall performance and efficiency of MVSS models. This significantly advances the field and opens new avenues for investigation in multispectral video analysis. The combination of dataset and new method will accelerate the development and evaluation of advanced MVSS algorithms.
Visual Insights#
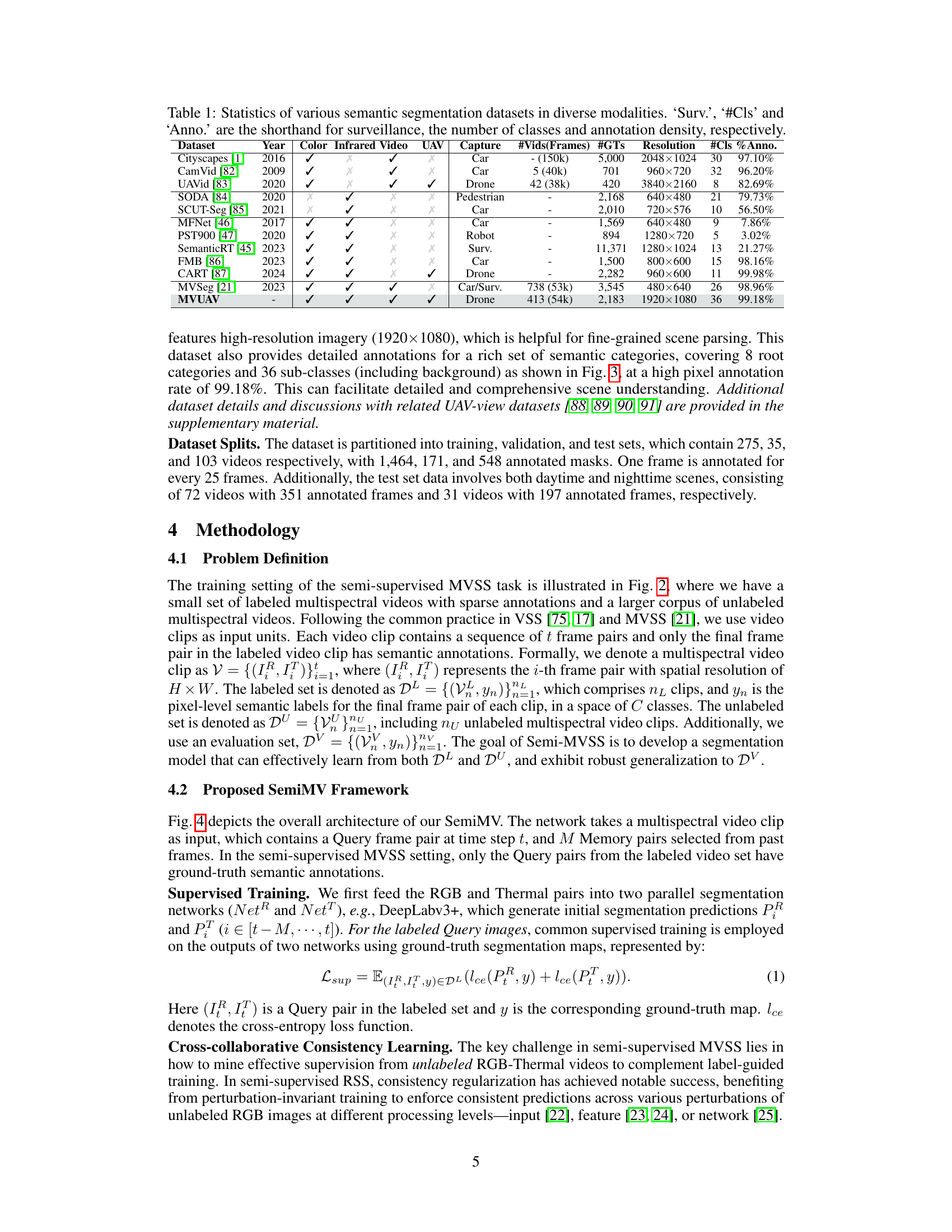
🔼 This figure illustrates the difference in viewpoint between the existing MVSeg dataset and the newly proposed MVUAV dataset. (a) shows a schematic of the data acquisition process, highlighting that MVSeg uses an eye-level perspective while MVUAV uses an oblique bird’s-eye view from a UAV. (b) and (c) provide visual examples of data from both datasets, showcasing RGB and thermal video frames alongside their corresponding semantic annotations. The difference in viewpoint and the broader range of scenes captured by MVUAV are visually apparent.
read the caption
Figure 1: (a) Viewpoint diversity of the existing MVSeg dataset [21] and the new MVUAV dataset. (b) & (c) Representative samples from the MVSeg & MVUAV datasets, where RGB videos, thermal videos, and the corresponding semantic annotations are visualized.
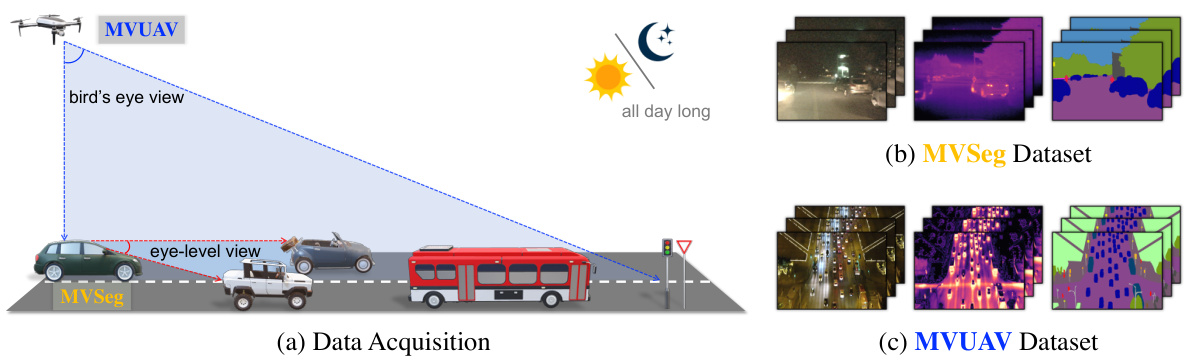
🔼 This table compares various semantic segmentation datasets across different modalities (RGB, Infrared, Video, and UAV). It shows the year the dataset was published, the types of imagery included (color, infrared, video), whether the data was collected using UAVs, the type of capture, the number of videos and frames, the number of ground truth annotations, the resolution of the images, the number of classes, and the annotation density. This allows for comparison of the datasets’ scale, scope, and annotation effort.
read the caption
Table 1: Statistics of various semantic segmentation datasets in diverse modalities. 'Surv.', '#Cls' and 'Anno.' are the shorthand for surveillance, the number of classes and annotation density, respectively.
In-depth insights#
MVUAV Dataset#
The MVUAV dataset represents a substantial contribution to the field of multispectral video semantic segmentation (MVSS). Its key strength lies in its unique perspective, offering oblique bird’s-eye-view imagery captured by UAVs, a significant departure from the predominantly eye-level viewpoints of existing datasets like MVSeg. This novel perspective provides a richer, more holistic context for segmentation tasks. The dataset’s diversity in lighting conditions (day/night) further enhances its value, enabling the development and evaluation of robust algorithms capable of handling varied visual conditions. The inclusion of over 30 semantic categories and a high annotation rate ensures the dataset’s suitability for training sophisticated deep learning models. However, the challenges inherent in MVUAV, such as large-scale variations and complex scenes, present opportunities to push the boundaries of current MVSS methodologies. The availability of this dataset will undoubtedly accelerate research progress and foster the development of more advanced and versatile MVSS techniques.
Semi-Supervised MVSS#
The concept of “Semi-Supervised MVSS” (Multispectral Video Semantic Segmentation) introduces a paradigm shift in approaching video segmentation. By leveraging both labeled and unlabeled data, it addresses the critical limitation of insufficient annotated multispectral video datasets. This approach is particularly relevant due to the high cost and time associated with manual pixel-wise annotation in multispectral data, where RGB and thermal information need to be analyzed together. The semi-supervised method enhances the efficiency and robustness of the model, making it more practical for real-world applications. Consistency regularization techniques, possibly involving cross-modal consistency learning between RGB and thermal data, are likely to be employed to enforce agreement between predictions from labeled and unlabeled data. The efficacy of the semi-supervised strategy is highly dependent on the quality and quantity of both the labeled and unlabeled data, with careful consideration for handling noise and variations present in real-world scenarios.
C3L Consistency#
The core idea behind C3L consistency is to leverage the inherent multimodality of RGB-Thermal data for improved semi-supervised learning in Multispectral Video Semantic Segmentation (MVSS). Instead of relying solely on labeled data, C3L utilizes the consistency between predictions from RGB and Thermal streams to generate pseudo-labels for unlabeled data. This cross-modal consistency acts as a form of self-supervision, where each modality guides the learning of the other. A key innovation is the inclusion of a cross-modal collaboration module within C3L, designed to mitigate potential errors arising from individual modality inconsistencies. This approach allows the algorithm to better handle noisy or incomplete data, a common issue in semi-supervised learning. Ultimately, C3L consistency aims to boost performance by effectively harnessing the rich information contained within unlabeled RGB-T video data, leading to more robust and accurate MVSS models. The method tackles the challenge of sparse annotations in MVSS datasets by smartly incorporating unlabeled data into the training process for better generalization.
Denoised Memory#
The concept of “Denoised Memory” in the context of semi-supervised multispectral video semantic segmentation is crucial for effectively leveraging temporal information from past video frames. The challenge lies in the unreliability of memory features due to a lack of ground-truth supervision for unlabeled frames. A key innovation is the introduction of a reliability estimation strategy, integrated into a temporal aggregation module, that mitigates potential noise. This strategy likely involves a mechanism to identify and down-weight unreliable features based on learned cross-modal consistency, perhaps using a metric like Kullback-Leibler divergence. By denoising the memory features and selectively retrieving reliable information, the model can improve the accuracy of predictions for the current frame. The denoised memory approach is particularly relevant in semi-supervised settings, where the scarcity of labeled data makes effective utilization of unlabeled data essential. Ultimately, the “Denoised Memory” component enhances the overall robustness and accuracy of the semantic segmentation by providing a more reliable temporal context.
Future of MVSS#
The future of Multispectral Video Semantic Segmentation (MVSS) appears bright, driven by the increasing availability of high-quality multispectral sensors and the growing demand for robust scene understanding in challenging conditions. Further research into more sophisticated semi-supervised and self-supervised learning techniques will be crucial to overcome the data scarcity issue that currently hinders progress. Developing more diverse and comprehensive datasets, particularly those that capture a wider range of environments and scenarios, is critical. Improving the efficiency and scalability of MVSS algorithms will enable real-time applications in areas like autonomous navigation and environmental monitoring. Advanced fusion techniques that effectively combine RGB and thermal data remain an important area of investigation. Finally, exploring the potential of MVSS in conjunction with other sensor modalities like LiDAR and radar holds promise for even more comprehensive scene understanding.
More visual insights#
More on figures

🔼 This figure illustrates the data used for training the SemiMV model. It shows two sets of RGB-Thermal video clips. The left side shows a small number of clips with sparse annotations (only the last frame in each clip is annotated). The right side shows a large number of unlabeled video clips. This semi-supervised learning approach uses the labeled data to guide the learning process for the unlabeled data, improving efficiency and potentially performance.
read the caption
Figure 2: Illustration of training examples in semi-supervised MVSS setting, where a limited amount of sparsely labeled RGB-Thermal (RGBT) videos and massive unlabeled ones are utilized.
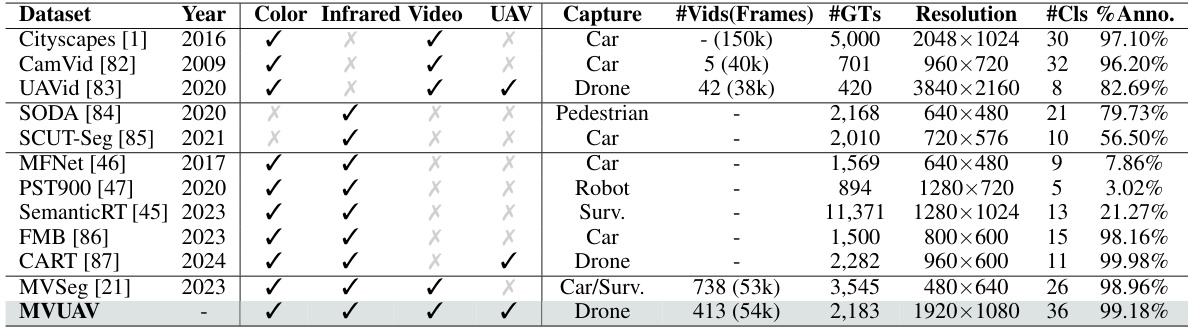
🔼 This figure presents the taxonomic system of the MVUAV dataset, showing the distribution of annotated frames across different object categories and infrastructure types. The visualization is a circular chart where each slice represents a category and the length corresponds to the number of frames. A second part shows example frames from the dataset, showcasing RGB, thermal and annotation layers, with examples provided for both daytime and nighttime conditions to highlight the dataset’s variety. The examples show the oblique bird’s-eye view perspective offered by UAV capture and the diversity of real-world scenes included.
read the caption
Figure 3: Illustrations of the proposed MVUAV dataset. (a) Taxonomic system and its histogram distribution showing the number of annotated frames across different categories. (b) Examples of multispectral UAV videos and corresponding annotations in both daytime and nighttime scenarios.
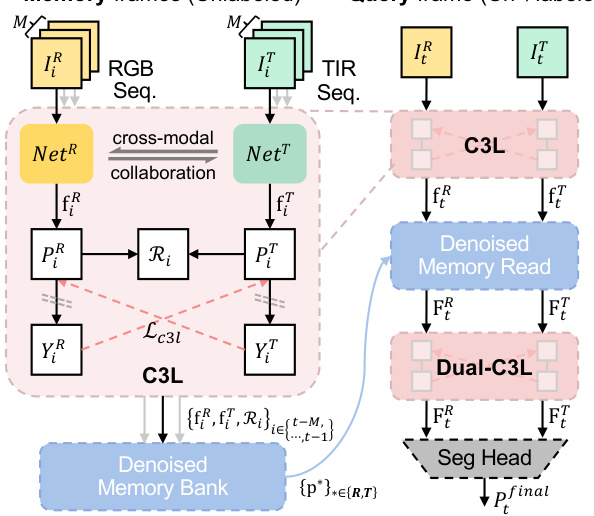
🔼 This figure illustrates the architecture of the proposed SemiMV framework for semi-supervised multispectral video semantic segmentation. It shows how RGB and thermal image sequences are processed through parallel networks. The Cross-collaborative Consistency Learning (C3L) module leverages both labeled and unlabeled data to improve segmentation performance. A denoised memory read module incorporates temporal information from previous frames, improving prediction accuracy. The final segmentation mask is produced by a dual-C3L loss and a segmentation head.
read the caption
Figure 4: Overview of proposed method. For simplicity, the supervised losses are omitted. The C3L loss Lc3l (Eq. 2) aims to learn from unlabeled RGB-Thermal pairs. The DMR is responsible for integrating temporal information from the denoised memory bank to update query features. A dual-C3L loss (Eq. 7) is further applied to regularize updated query features. Finally, a segmentation head predicts the final mask Pfinal. The dotted \ means stop gradient.
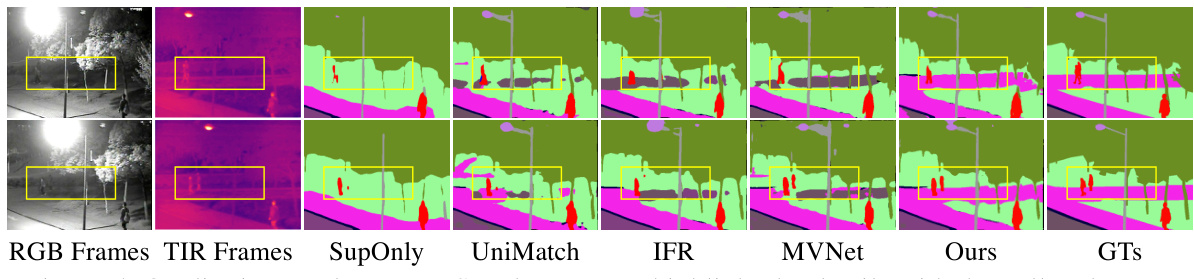
🔼 This figure compares the qualitative results of different semantic segmentation methods on the MVSeg dataset. The top row shows RGB and thermal infrared (TIR) frames of a scene, followed by the segmentation results of several methods (SupOnly, UniMatch, IFR, MVNet, Ours) and the ground truth (GTs). Yellow boxes highlight areas where the methods differ, showcasing the relative performance and capabilities of each model in detail, specifically in low-light conditions.
read the caption
Figure 5: Qualitative results on MVSeg dataset. We highlight the details with the yellow boxes.
More on tables

🔼 This table presents a quantitative comparison of different semantic segmentation models on the MVSeg dataset. It shows the performance of both fully supervised and semi-supervised methods under various data splits (1/16, 1/8, 1/4, and 1/2 of the training data labeled). The results are reported as mean Intersection over Union (mIoU) and illustrate the impact of semi-supervised learning on improving the segmentation performance. Semi-supervised methods consistently outperform their fully supervised counterparts, showcasing the effectiveness of leveraging unlabeled data. SemiMV, the proposed method, achieves the best performance across all data splits.
read the caption
Table 2: Quantitative evaluation on the MVSeg dataset. SupOnly stands for the model trained on the labeled data.
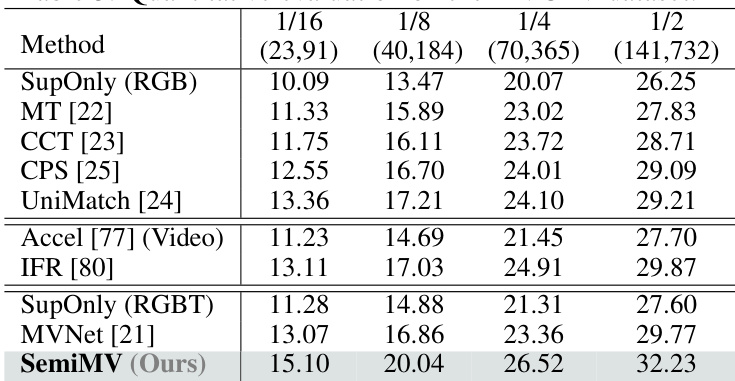
🔼 The table presents the quantitative results on the MVSeg dataset, comparing various semi-supervised and supervised semantic segmentation models under different data partition protocols (1/16, 1/8, 1/4, and 1/2). The methods include several semi-supervised methods (MT, CCT, CPS, UniMatch, Accel, IFR) and the proposed SemiMV method, in addition to supervised baselines using RGB or RGB-T data. The results are presented in terms of mIoU.
read the caption
Table 2: Quantitative evaluation on the MVSeg dataset. SupOnly stands for the model trained on the labeled data.
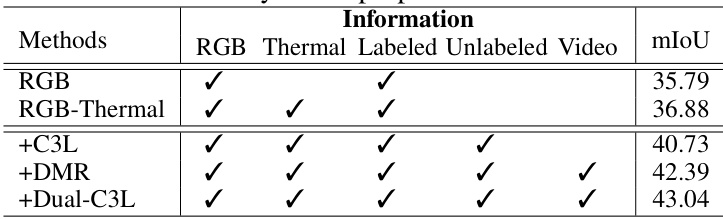
🔼 This table presents the ablation study results of the proposed SemiMV framework. It shows the impact of different components (RGB, Thermal, C3L, DMR, Dual-C3L) on the model’s performance (mIoU) when trained with labeled and unlabeled data. The results demonstrate the effectiveness of each component in improving the model’s ability to utilize both labeled and unlabeled data for semi-supervised semantic segmentation.
read the caption
Table 4: Ablation study of the proposed SemiMV framework.
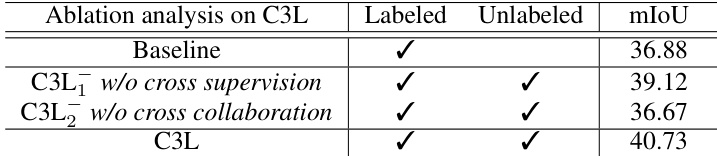
🔼 This table presents the ablation study of the Cross-collaborative Consistency Learning (C3L) module. It compares the performance of the baseline model against three variants of the C3L module: one without cross supervision, one without cross-modal collaboration, and the full C3L module. The results demonstrate the importance of both cross supervision and cross-modal collaboration for effective semi-supervised learning in the MVSS task.
read the caption
Table 5: Ablation analysis of our C3L module.

🔼 This table presents the ablation study of the Cross-collaborative Consistency Learning (C3L) module. It compares the performance of the C3L module with and without cross-supervision and cross-collaboration on the MVSeg dataset. The results show that both cross-supervision and cross-collaboration are crucial for the performance of the C3L module.
read the caption
Table 5: Ablation analysis of our C3L module.
Full paper#