↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current reinforcement learning struggles with open-ended learning and doesn’t capture the cumulative progress of human culture. This paper addresses these issues by investigating how artificial agents can accumulate cultural knowledge and skills across generations. The researchers explore the concept of cultural accumulation, emphasizing how individual learning and knowledge sharing across generations drives the evolution of capabilities.
The study introduces two models to demonstrate cultural accumulation in reinforcement learning: in-context accumulation (faster, knowledge-based learning) and in-weights accumulation (slower, skill-based learning). Both models demonstrate sustained improvements in performance across multiple generations, surpassing the performance of single-lifetime learning agents with similar total experience. The results show that a balance between social learning and individual discovery is critical for achieving cultural accumulation, offering a significant step towards creating more advanced and adaptable AI systems that can learn and evolve more effectively, resembling human culture more closely.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and related fields because it introduces a novel approach to cultural accumulation in reinforcement learning, a significant advancement with implications for creating more adaptable and robust AI systems. The work also highlights the importance of balancing social learning with independent discovery for effective cultural accumulation, opening new research avenues to explore for the development of open-ended and emergent learning systems that mimic human-like capabilities.
Visual Insights#
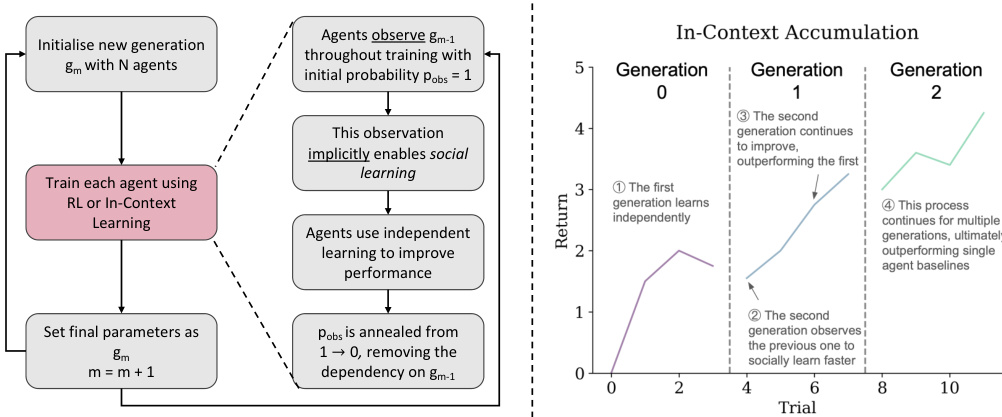
The figure consists of two parts. The left panel is a flowchart illustrating the process of cultural accumulation in reinforcement learning. It shows how a new generation of agents is initialized, trained using RL or in-context learning while observing the previous generation (social learning), and how their final parameters are set as the basis for the next generation. The right panel is a plot showing the performance of agents over multiple generations. Each line represents a generation; the later generations achieve higher returns (performance) than the earlier ones, showcasing the improvement through cultural accumulation. This demonstrates that the agents learn and improve cumulatively across generations, exceeding the performance of single-lifetime learning agents.

This table compares the authors’ work to previous research in reinforcement learning, highlighting the unique contributions of their approach. It shows how their work integrates the benefits of both Generational Training (for overcoming local optima in open-ended tasks) and implicit third-person social learning (a more general approach than explicit imitation learning). The table emphasizes that their method uniquely combines these two techniques to achieve cultural accumulation.
In-depth insights#
Cultural Accumulation#
The concept of cultural accumulation, explored in the context of reinforcement learning, examines how knowledge and skills are transmitted and improved upon across generations of agents. Unlike traditional reinforcement learning which focuses on individual lifetime learning, this approach emphasizes the propagation of successful strategies and innovations through time. The authors explore two models of cultural accumulation: in-context accumulation, where learning happens through observation and interaction within a single episode and in-weights accumulation, which occurs via the updating of weights across multiple generations. This is analogous to humans accumulating knowledge and skills. Emergent cultural accumulation is shown in both models, with subsequent generations surpassing the performance of single-lifetime agents, demonstrating the potential for RL agents to exhibit cultural evolution. The research highlights the importance of balancing independent learning with social learning to prevent over-reliance on prior generations and achieve continued advancement.
RL Model of Culture#
Reinforcement learning (RL) offers a powerful framework for modeling cultural evolution. An RL model of culture could represent individual agents as RL agents learning to maximize rewards in an environment shaped by cultural norms and practices. Social learning, where agents learn by observing and imitating others, is crucial, and could be modeled through mechanisms like reward shaping or imitation learning. Inter-generational transmission is key; an RL model should capture how cultural knowledge and skills are passed from one generation to the next, possibly via mechanisms such as teacher-student interactions or the inheritance of learned policies. Emergent cultural phenomena, such as the development of shared norms or technologies, could arise from the interactions of multiple RL agents. The balance between exploration and exploitation is a critical aspect of both individual and cultural learning and should be reflected in the model’s design. The model’s complexity would depend on the specific aspect of culture being studied, but should incorporate the dynamic interplay between individual learning, social interactions, and generational change. Validating such a model would require comparing its predictions to observations of real-world cultural processes.
Generational Training#
Generational training, in the context of reinforcement learning, presents a powerful paradigm shift from traditional single-lifetime learning approaches. Instead of optimizing an agent’s performance within a single lifespan, it focuses on evolving a population of agents across multiple generations. Each generation learns from the successes and failures of its predecessors, creating a cumulative knowledge transfer. This iterative process mirrors the way cultural evolution works in humans and other species. Unlike simple imitation or knowledge distillation, generational training allows for a more sophisticated interplay between exploration and exploitation. New generations can inherit knowledge, reducing the need for excessive exploration, while still retaining the ability to discover new techniques and overcome limitations of previous strategies. This approach holds immense potential for solving complex problems requiring extended learning timescales, as the cumulative knowledge and skill acquisition can lead to faster progress and more robust solutions than single-agent, single-lifetime methods. Key aspects to consider when designing generational training systems are the mechanisms for knowledge transfer between generations (explicit instruction, observation, etc.), balancing exploration and exploitation within each generation, and designing effective fitness functions that promote beneficial knowledge accumulation.
In-Context Learning#
In-context learning, a crucial aspect of this research, demonstrates how agents leverage past experiences within a single episode to enhance performance. The key insight is the integration of social learning where the model observes and learns from previous generations’ actions before independently performing the task. This approach, unlike traditional methods which train for entire lifetimes, highlights how knowledge can be effectively acquired and utilized within shorter timescales. A significant finding is that this in-context learning leads to cultural accumulation where successive generations outperform single-lifetime learners, emphasizing the cumulative power of learning within context. The study also examines the interplay between social and independent learning, demonstrating that a balance is crucial for optimal performance. Excessive reliance on previous generation’s behavior, however, can hinder independent exploration, potentially limiting progress. The success of in-context learning points towards more efficient and open-ended learning systems by incorporating elements of cultural learning, potentially mirroring human learning processes.
Future of AI Culture#
The future of AI culture hinges on bridging the gap between individual and collective learning. While current AI excels at individual tasks, mimicking human cultural accumulation—the iterative refinement of knowledge across generations—remains a significant challenge. Future research should focus on developing AI systems capable of nuanced social learning, efficiently balancing imitation and innovation, and demonstrating emergent cultural accumulation. Open-ended learning environments that allow for the sustained exploration and refinement of capabilities are crucial. Furthermore, ethical considerations must be paramount; AI cultural evolution should be designed to promote beneficial outcomes and avoid potential biases or unintended consequences. Understanding how AI agents can collaborate effectively, exchange information efficiently, and adapt to diverse environments will be vital for creating truly robust and open-ended AI systems. The ultimate goal is an AI that exhibits cumulative cultural progress, generating novel solutions and outperforming individual agents over time, mirroring the impressive trajectory of human civilization.
More visual insights#
More on figures
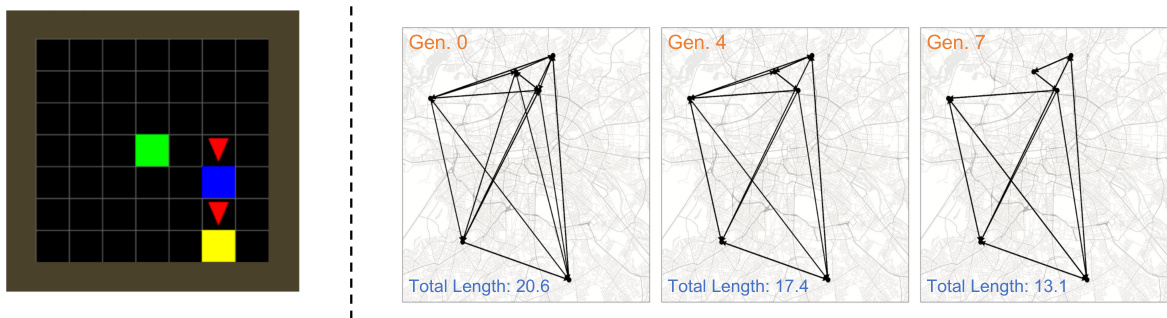
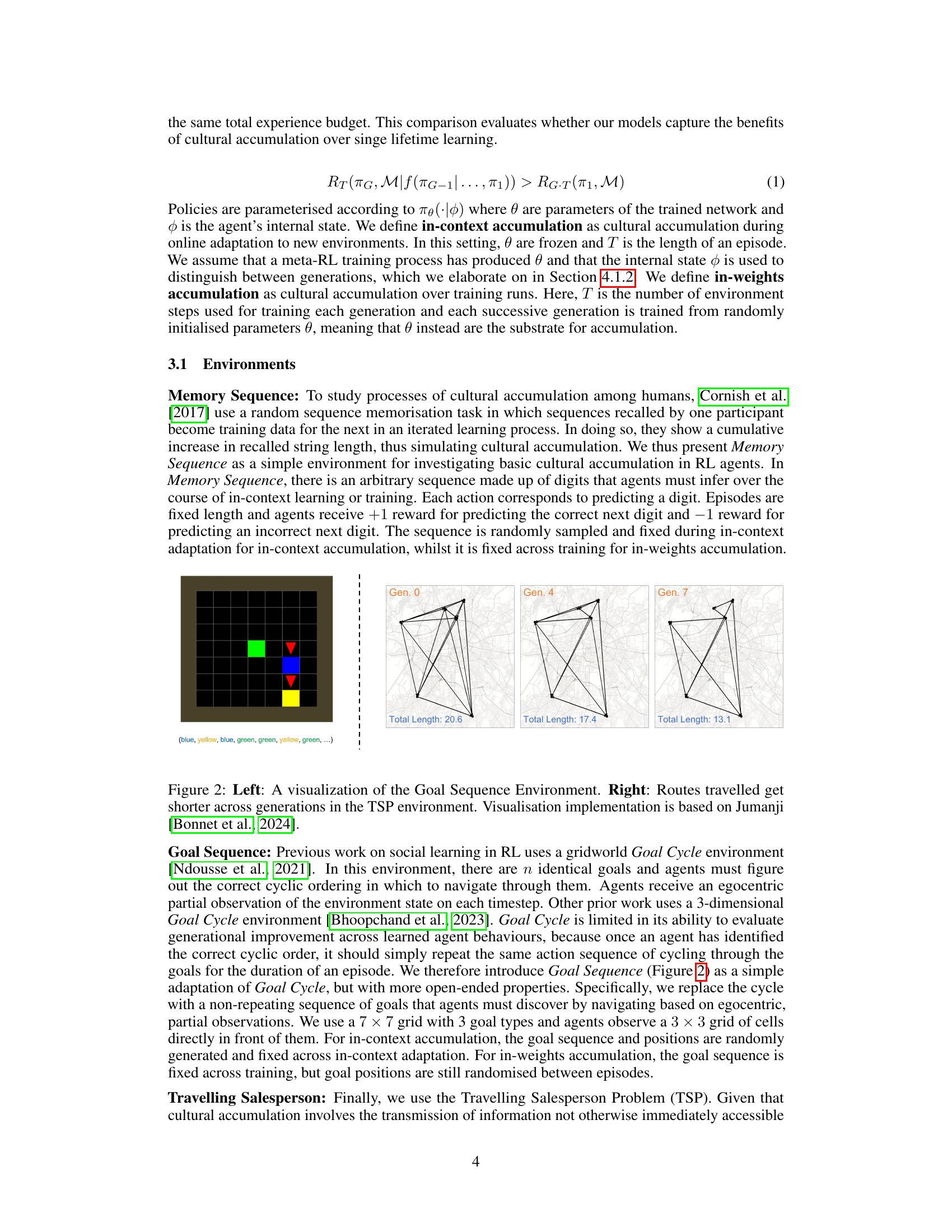
The figure demonstrates the Goal Sequence environment (left) and the improvement in the solutions of the Traveling Salesperson Problem (TSP) across generations (right). The Goal Sequence environment shows a grid with goals of different colors, where agents need to learn the correct sequence to visit the goals. The TSP visualization shows how the route length decreases over generations, illustrating the accumulation of cultural knowledge improving the efficiency of solutions across generations.

The figure on the left is a flowchart that illustrates the process of cultural accumulation in reinforcement learning. It shows how a new generation of agents is initialized, observes the previous generation, trains using either reinforcement learning or in-context learning, and ultimately improves upon the previous generation. The observation of the previous generation implicitly enables social learning. The process iterates, leading to improvements over multiple generations. The right panel shows a plot visualizing the performance of agents across multiple generations demonstrating that the performance improves over time (generations) showcasing in-context cultural accumulation.
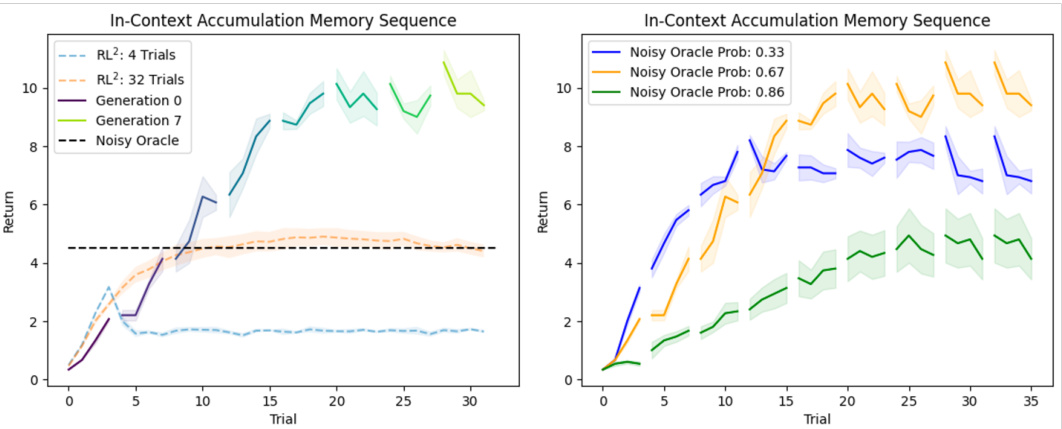
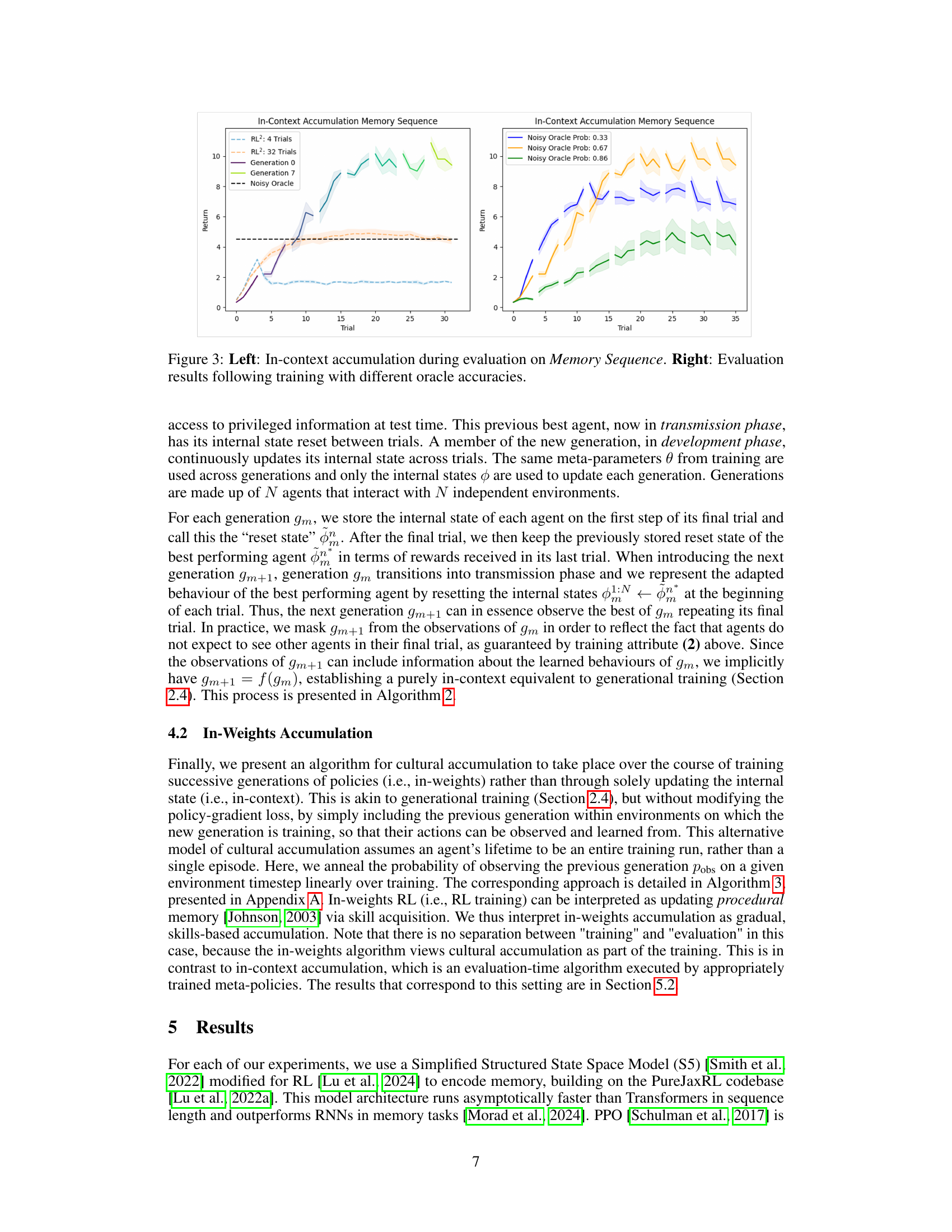
This figure presents the results of in-context accumulation experiments conducted on the Memory Sequence task. The left panel shows the performance of agents trained with in-context accumulation compared to single-lifetime baselines (RL2 trained for 4 and 32 trials). The results indicate that agents with in-context accumulation outperform baselines, achieving higher returns across trials and generations. The right panel shows the results of experiments with varying oracle accuracies (0.33, 0.67, and 0.86). This panel illustrates the impact of oracle reliability on the performance of in-context learning agents. Agents trained with less noisy oracles tend to perform better.
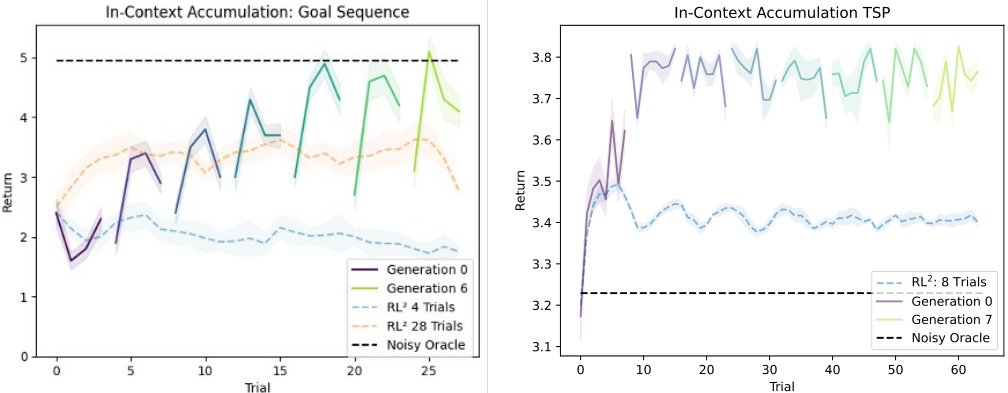
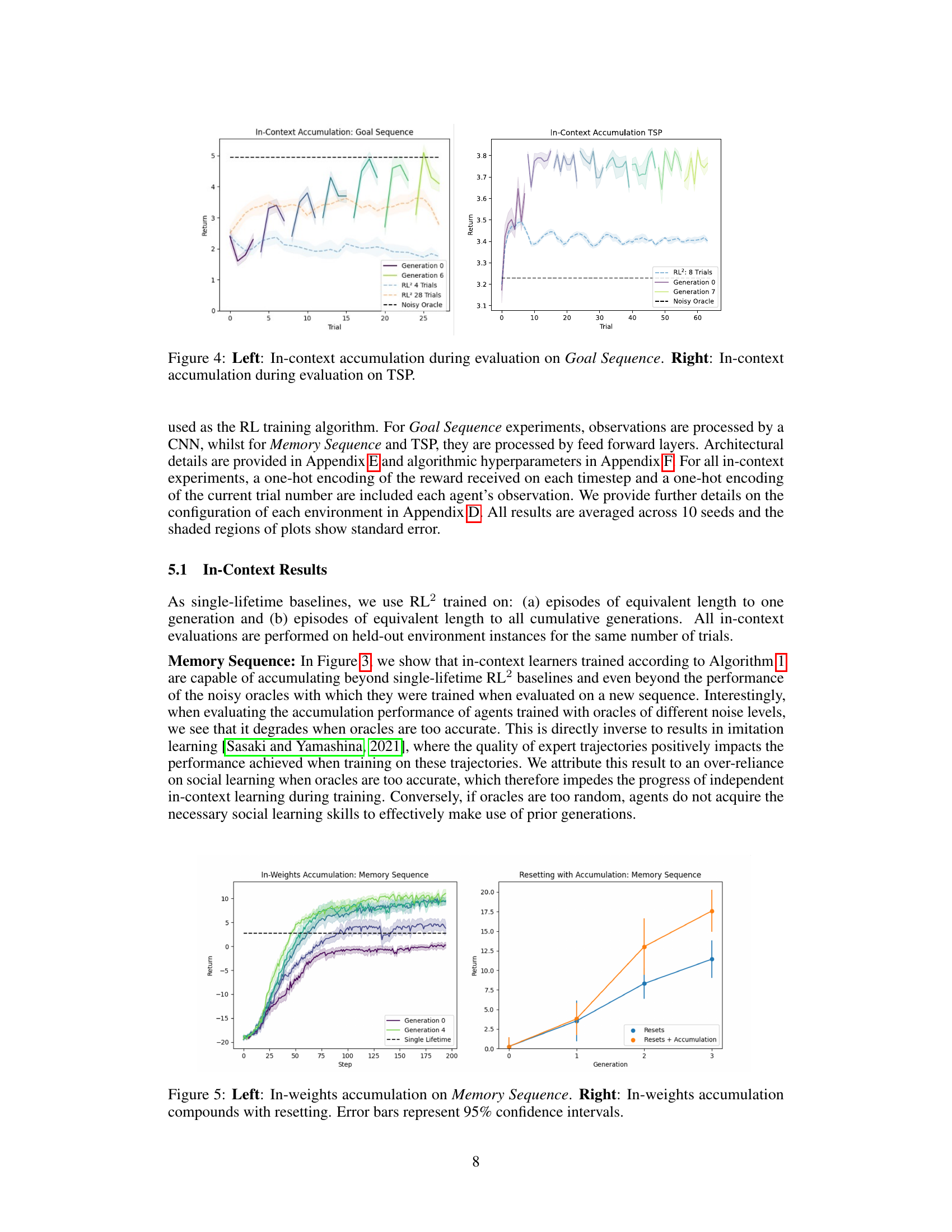
This figure visualizes the results of in-context accumulation experiments on two different tasks: Goal Sequence and Traveling Salesperson Problem (TSP). The left panel shows the performance of agents across seven generations (0 to 6) on the Goal Sequence task, compared to single-lifetime baselines (RL2 with 4 and 28 trials). A noisy oracle is also included as a reference. The right panel displays similar results for the TSP task, showing performance across eight generations (0 to 7). Both panels illustrate how in-context learning leads to sustained performance gains across generations.
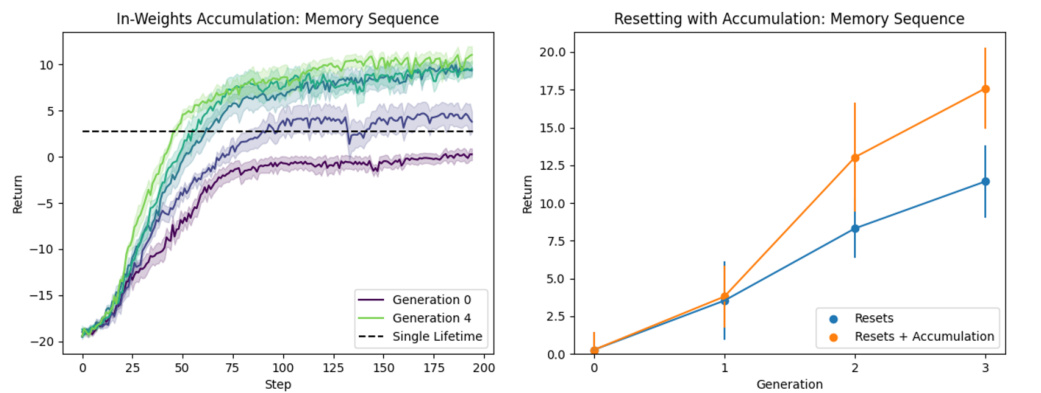
This figure presents the results of in-weights accumulation experiments on the Memory Sequence task. The left panel shows the cumulative return over training steps for four generations (0-4) compared to a single-lifetime agent. It demonstrates that the in-weights accumulation method leads to a significant improvement over the single-lifetime baseline in terms of cumulative returns, showcasing the advantages of cultural accumulation where learning is spread across multiple generations. The right panel illustrates the performance increase when the in-weights accumulation method is combined with layer resetting during training. This combination provides an additional boost to performance, indicating that resetting network layers can enhance the benefits of cultural accumulation. Error bars in both plots provide confidence intervals around the mean, indicating the reliability of results.

This figure presents the results of in-weights accumulation experiments on the Memory Sequence task. The left panel shows the learning curves for multiple generations of agents trained using the in-weights method. It demonstrates that performance improves over generations, exceeding the performance of a single-lifetime agent trained for an equivalent total number of steps. The right panel further explores the benefit of combining in-weights accumulation with resetting of the agent’s network parameters. This panel shows that resetting enhances the accumulation effect, leading to even greater performance improvements compared to single-lifetime training and in-weights accumulation alone. Error bars indicate the 95% confidence intervals.
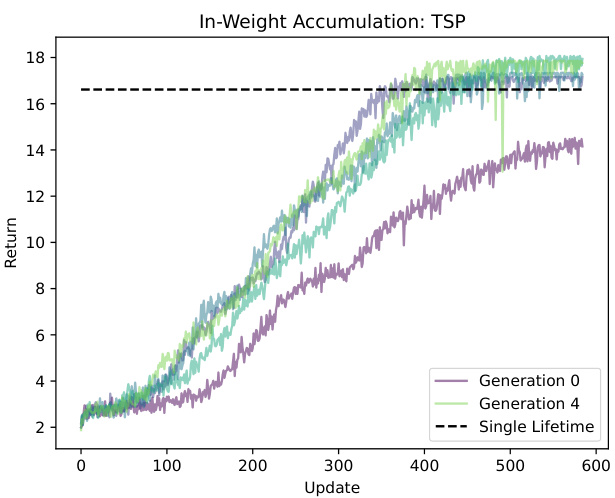
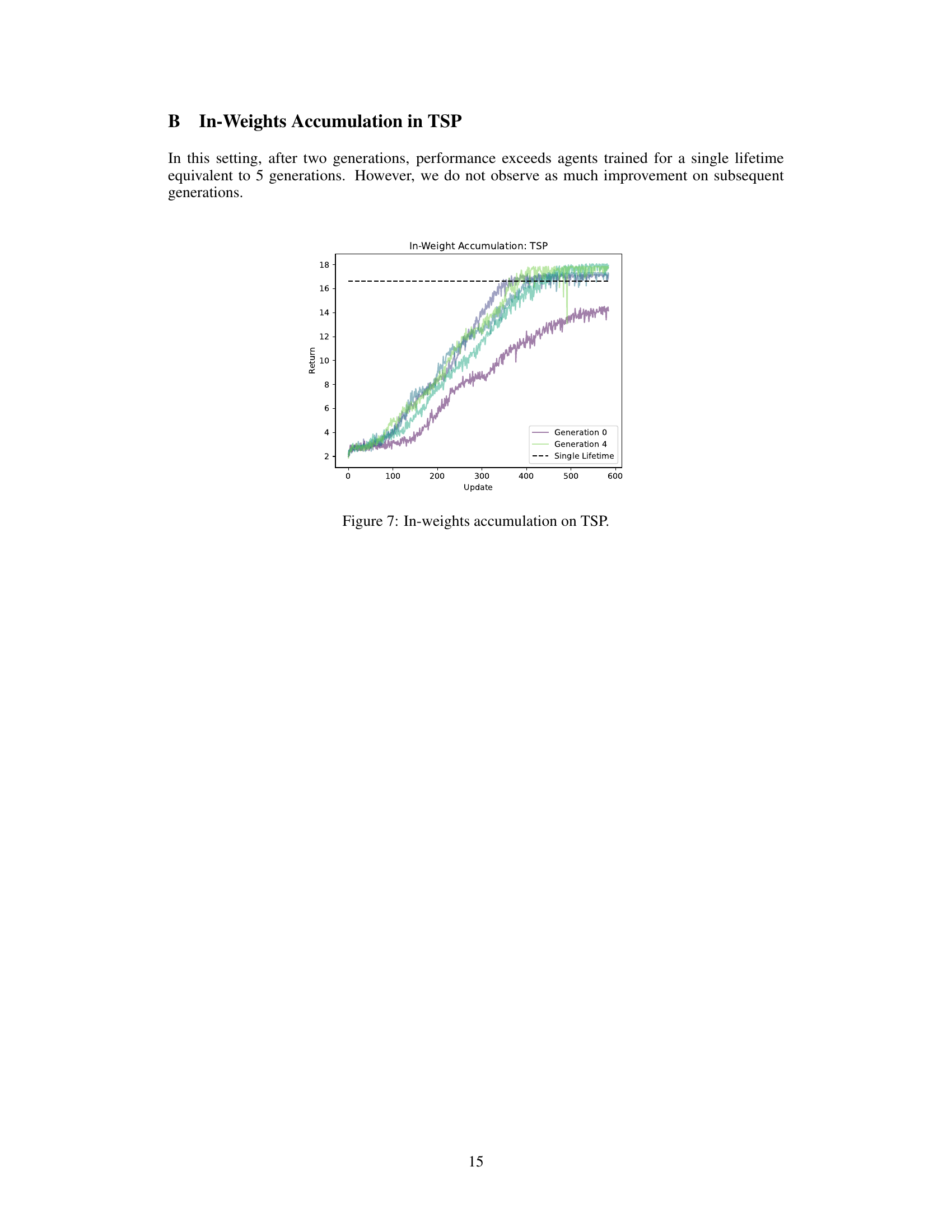
This figure shows the results of in-weights accumulation on the Traveling Salesperson Problem (TSP). It compares the performance of agents trained across multiple generations (generations 0 and 4 shown) against a single-lifetime baseline. The x-axis represents the training step or update, and the y-axis represents the accumulated return. The plot demonstrates that after two generations, the performance of the in-weights accumulation model surpasses that of a single-lifetime trained agent, indicating the effectiveness of the cultural accumulation approach. However, improvements beyond two generations are less pronounced.
Full paper#