↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are computationally expensive, and their inference speed is often limited by the size of the key-value (KV) cache. Existing KV cache compression methods struggle to achieve high compression ratios without significant loss of model accuracy. This paper introduces a novel approach called Coupled Quantization (CQ). The paper points out that existing approaches, performing quantization per channel independently, are suboptimal. This is because distinct channels within the same key/value activation embedding are highly interdependent and correlated.
CQ addresses these issues by jointly quantizing multiple channels to exploit their interdependencies. Experiments show that CQ significantly outperforms existing methods in preserving model quality while achieving 1.4-3.5x speedup in inference. Furthermore, it shows that CQ can maintain reasonable model accuracy even with KV cache quantized down to an extreme level of 1-bit per channel. This breakthrough enables the efficient deployment of larger LLMs with longer contexts, paving the way for more powerful and widely accessible AI applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because efficient LLM deployment is hindered by the massive KV cache memory requirements during inference. The research directly addresses this bottleneck, offering significant improvements to inference throughput and enabling the use of larger models and longer contexts. This has major implications for both research and practical applications of LLMs. The proposed method also opens new avenues for researching efficient quantization techniques for other deep learning models.
Visual Insights#

This figure displays the perplexity results on the WikiText-2 benchmark for two different LLMs (LLaMA-7b and LLaMA-2-13b) using 1-bit quantized key-value (KV) cache. The x-axis represents the number of coupled KV channels used in the Coupled Quantization (CQ) method. The y-axis shows the perplexity. The results show that as the number of coupled channels increases, the perplexity decreases, approaching the perplexity achieved with the uncompressed FP16 KV cache. This demonstrates the effectiveness of CQ in reducing quantization error and preserving model quality even at very low bit widths (1-bit).
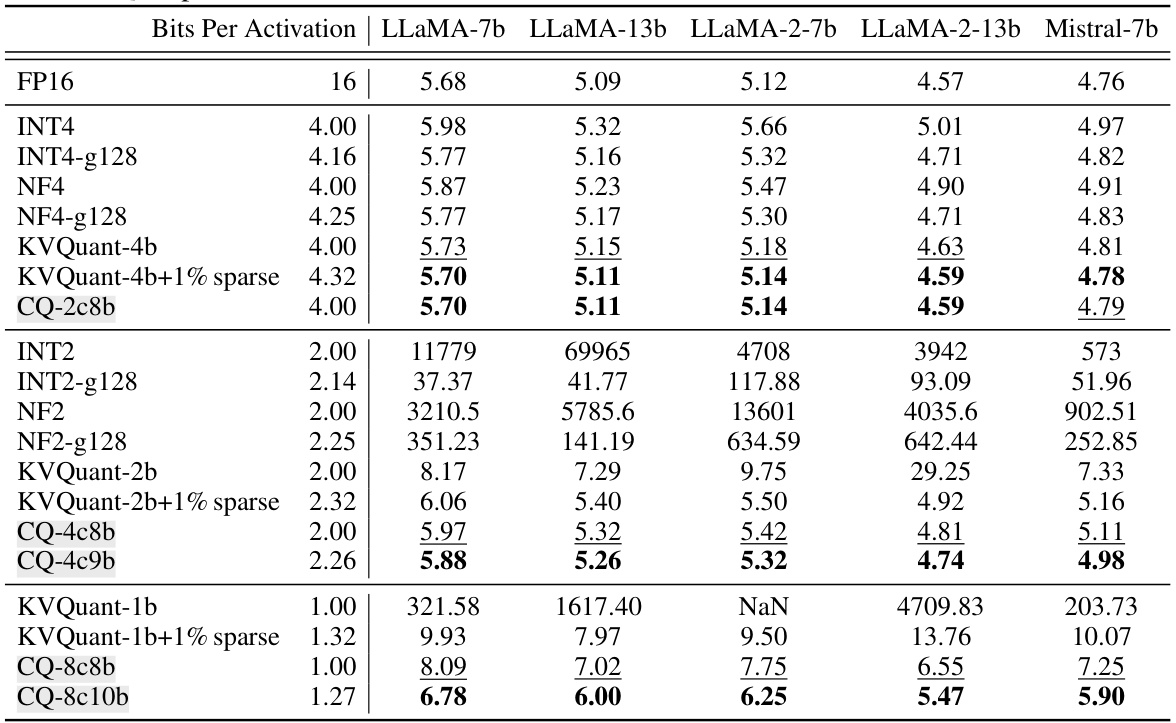
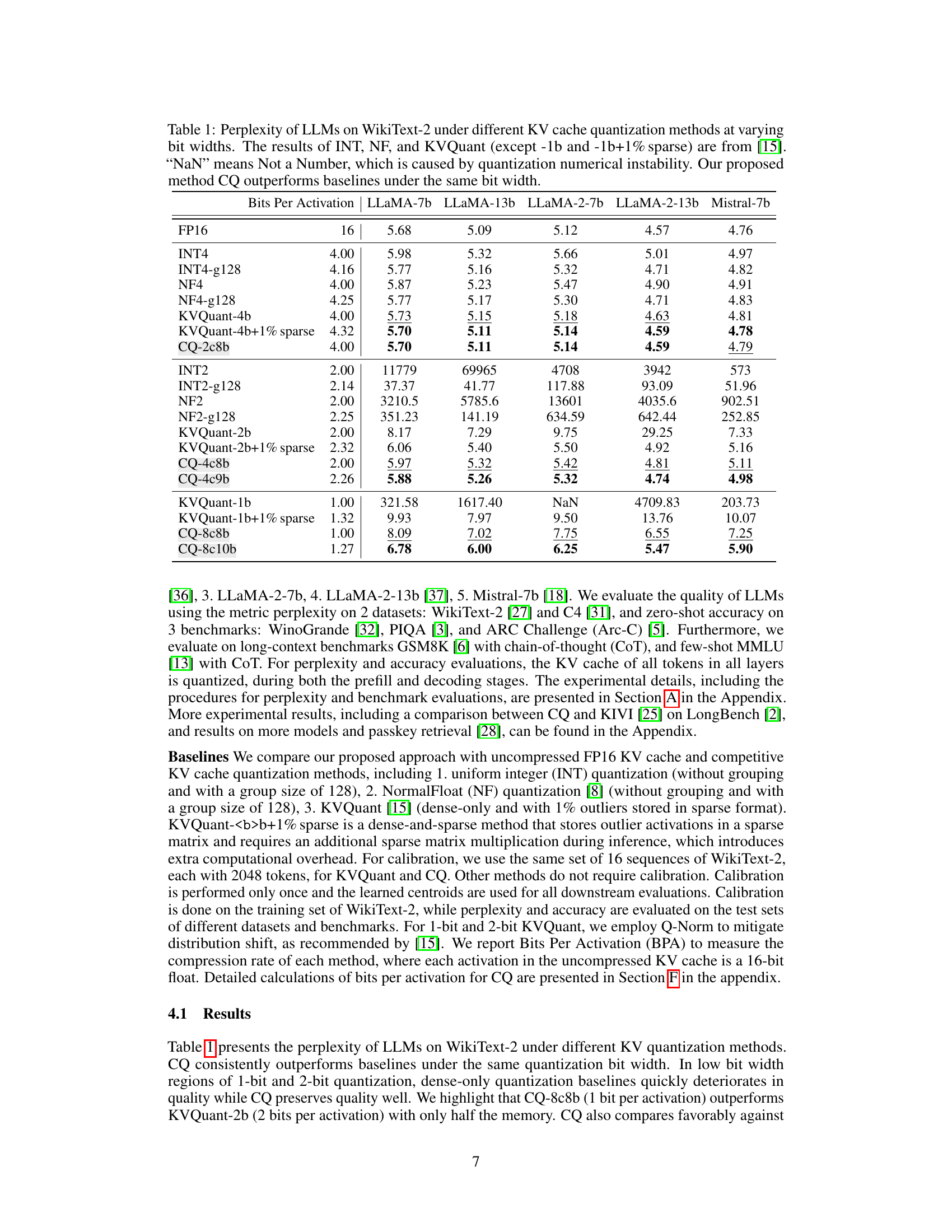
This table presents the perplexity scores achieved by various Large Language Models (LLMs) on the WikiText-2 benchmark dataset under different KV cache quantization methods and bit-widths. It compares the performance of Coupled Quantization (CQ), a novel method proposed in the paper, against existing state-of-the-art methods like INT, NF, and KVQuant. The table shows that CQ consistently achieves lower perplexity (better performance) than the competing methods across various bit-widths, demonstrating its effectiveness in improving LLM inference efficiency.
In-depth insights#
Coupled Quantization#
The proposed Coupled Quantization (CQ) method tackles the limitations of existing KV cache compression techniques by addressing the suboptimality of per-channel independent quantization. CQ leverages the inherent interdependence between different channels within key/value activation embeddings, demonstrating that jointly encoding multiple channels leads to more information-efficient quantization. This is supported by information theory analysis revealing a slower growth rate of joint entropy compared to the sum of marginal entropies, suggesting significant information redundancy when quantizing channels separately. Experiments show CQ effectively exploits these interdependencies, leading to superior performance compared to baselines at extremely low bit widths (down to 1 bit per channel), whilst maintaining reasonable model quality. This is particularly crucial for efficient large language model inference, where memory constraints are a major bottleneck. The combination of CQ with a sliding window of full-precision cached tokens further mitigates quality loss at very high compression rates. The method’s efficiency is also enhanced by optimized GPU kernels enabling efficient centroid lookups, minimizing inference latency.
KV Cache Compression#
Large Language Models (LLMs) inference speed is significantly impacted by the size of the key-value (KV) cache, especially as model size and context length increase. KV cache compression techniques, therefore, are crucial for efficient LLM deployment. This paper focuses on quantization, a common compression method, but highlights its limitations at very low bit widths due to the inherent independence assumptions made in existing per-channel or per-token approaches. The core contribution is the introduction of Coupled Quantization (CQ). CQ exploits the interdependence between key/value channels, demonstrating a more information-efficient encoding and improving inference throughput significantly (1.4-3.5x) while maintaining model quality. The paper provides compelling empirical evidence of CQ’s effectiveness, particularly at the extreme compression rate of 1 bit per channel, showcasing that carefully coupling channels overcomes the sub-optimality of per-channel independent quantization.
Channel Interdependence#
The concept of ‘channel interdependence’ in the context of large language model (LLM) key/value (KV) cache quantization is crucial. The authors demonstrate that individual channels within a KV cache embedding are not independent, exhibiting significant correlation and mutual information. This interdependence suggests that treating channels as isolated units during quantization is suboptimal, leading to information redundancy and reduced compression efficiency. By acknowledging this, a coupled quantization approach can be developed, jointly encoding multiple channels to leverage their inherent relationships. This leads to more information-efficient representations, ultimately improving the compression ratio while preserving model quality. The finding fundamentally challenges existing per-channel or per-token independent quantization methods, showcasing the potential for improved LLM inference speed and memory efficiency through a more sophisticated understanding of the data’s structure.
1-bit Quantization#
The concept of “1-bit quantization” in the context of large language model (LLM) inference is a significant advancement in memory efficiency. Pushing the bit-width to 1 represents an extreme level of compression, offering substantial memory savings. The paper explores this by introducing Coupled Quantization (CQ), a technique that leverages the interdependence between channels in key/value activation embeddings. This interdependency allows for more information-efficient encoding, mitigating the sub-optimality of channel-independent quantization. The effectiveness of 1-bit quantization using CQ is validated empirically, showing that it achieves performance comparable to higher-bit quantization methods and even uncompressed baselines, with the addition of a sliding window for recent tokens in full precision. This breakthrough enables significant gains in throughput by allowing larger batch sizes without exceeding GPU memory limits, making LLMs more deployable on resource-constrained hardware. Despite the lossy nature of extreme quantization, the results suggest that CQ effectively preserves model quality. However, future research could focus on fully understanding the impact on model quality at this extreme level of compression and evaluating robustness to various factors, including adversarial attacks.
Ablation Study#
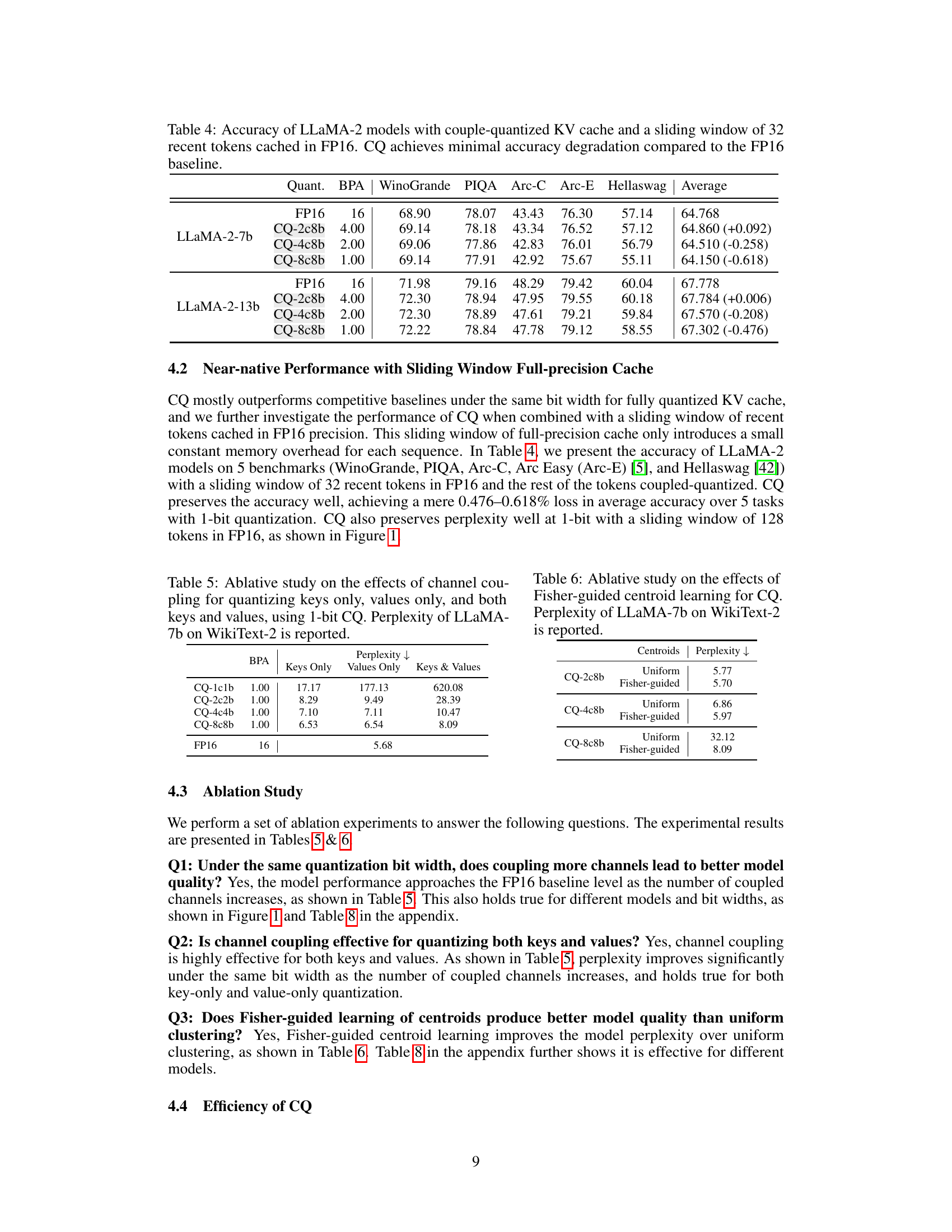
An ablation study systematically removes or alters components of a proposed method to assess their individual contributions. In the context of this research paper, an ablation study on coupled quantization would likely involve experiments testing different aspects of the method. This might include varying the number of coupled channels, comparing different centroid learning techniques (uniform versus Fisher-guided), or evaluating the impact of applying coupled quantization to only keys or values, rather than both. The results would quantify the effect of each component on model quality (e.g., perplexity) and efficiency (e.g., throughput). A strong ablation study should demonstrate that the combined effects of all components are critical for the method’s superior performance, and that removing or changing any single component leads to a significant degradation. This kind of analysis helps isolate the core contributions of the coupled quantization method, distinguishing what’s essential from what’s peripheral, and providing strong evidence for the effectiveness of the proposed technique. The ablation study would ideally be presented in a clear and easily interpretable format, potentially including tables and/or figures that showcase the effects of removing/altering each component.
More visual insights#
More on figures

This figure demonstrates the interdependency of channels within key/value embeddings. Subfigure (a) shows that the joint entropy of multiple channels grows slower than the sum of their individual entropies, indicating that jointly quantizing channels is more efficient. Subfigure (b) visually confirms this with correlation matrices showing high interdependence between channels.
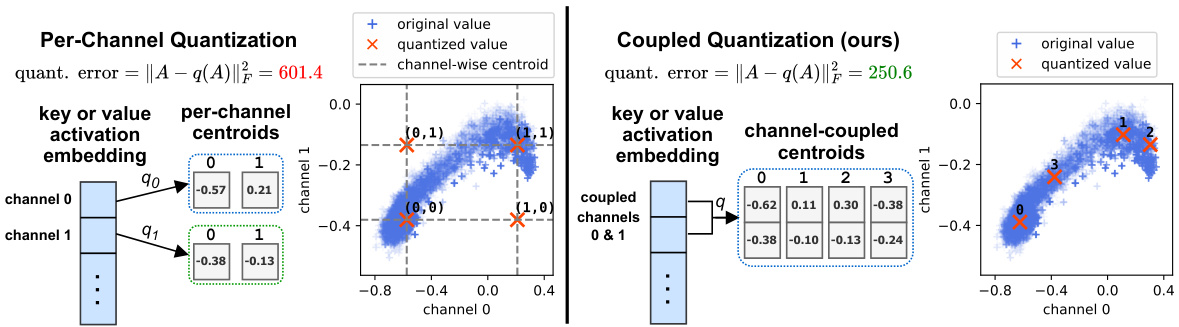
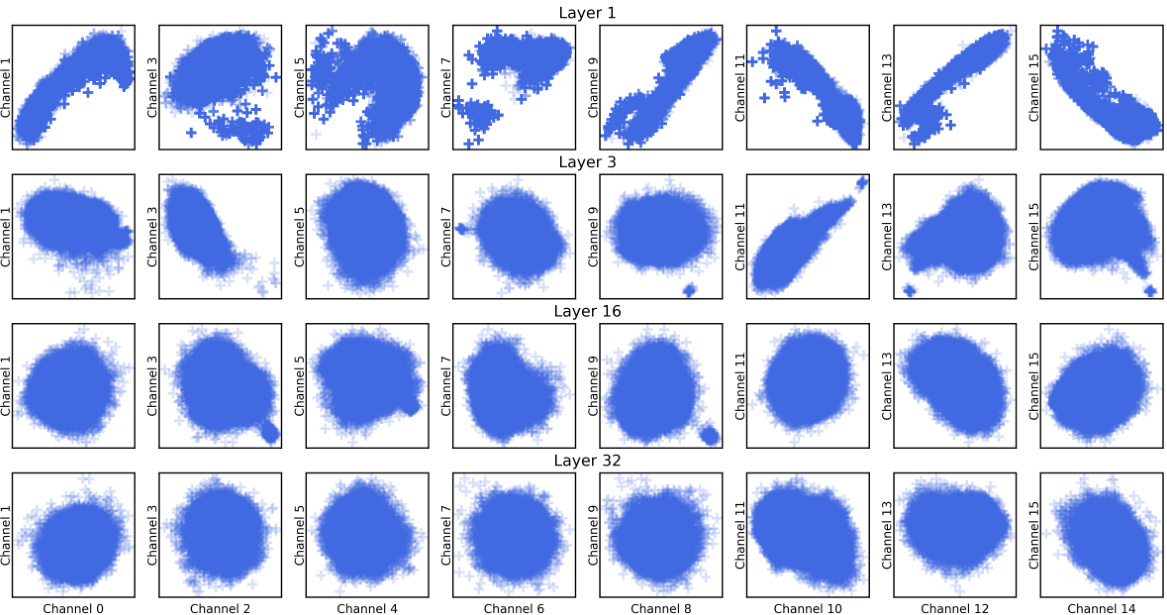
This figure compares per-channel quantization and coupled quantization methods using 1-bit quantization on the first two channels of the first layer key activation embeddings of the LLaMA-7b model. It demonstrates that coupled quantization leverages the interdependency between channels to achieve lower quantization errors, resulting in improved model quality and efficiency.
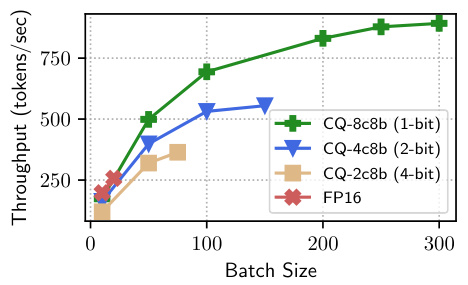
This figure shows the decoding throughput (tokens per second) of the LLaMA-2-7b model using different KV cache quantization methods against the uncompressed FP16 baseline. The x-axis represents the batch size, and the y-axis represents the throughput. The results show that CQ achieves significantly higher throughput than FP16, especially at lower bit-widths (1-bit and 2-bit). The increasing throughput with increasing batch size plateaus at different points for each quantization scheme, suggesting that memory capacity becomes the limiting factor at various batch sizes depending on the level of compression.
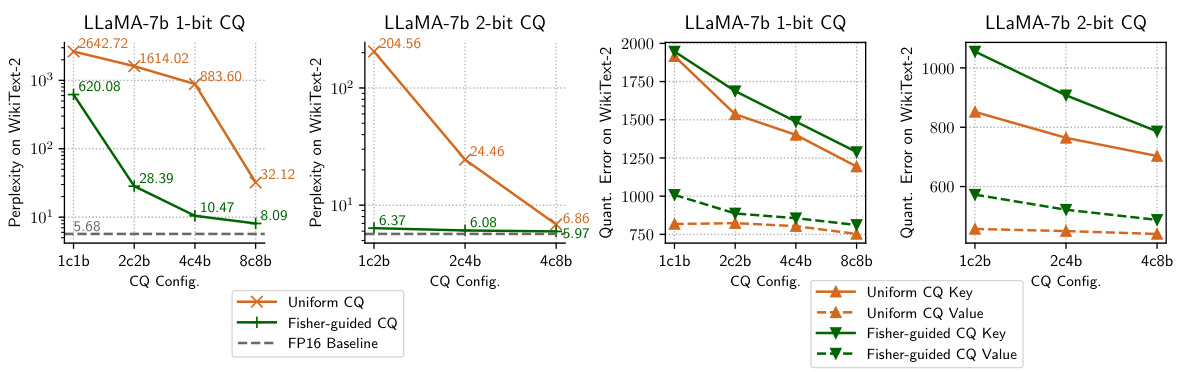
This figure shows the perplexity of two LLMs (LLaMA-7b and LLaMA-2-13b) on the WikiText-2 dataset when using 1-bit quantized key-value (KV) cache. The perplexity is plotted against the number of coupled KV channels. The results show that as the number of coupled channels increases, the perplexity decreases, approaching the performance achieved with uncompressed FP16 KV cache. This indicates that coupled quantization is more effective than independent quantization at very low bit-widths.

This figure demonstrates the interdependence of channels within key/value activation embeddings. Subfigure (a) shows that the joint entropy of multiple channels increases at a slower rate than the sum of their individual entropies, suggesting that coupled quantization is more efficient. Subfigure (b) displays correlation matrices, visually showing the high linear dependency between different channels within the key and value embeddings.

This figure demonstrates the interdependence of channels within key/value activation embeddings. Panel (a) shows that the joint entropy of multiple channels increases at a slower rate than the sum of their individual entropies, indicating that joint quantization is more efficient. Panel (b) displays correlation matrices, visually confirming high linear dependency between channel pairs.
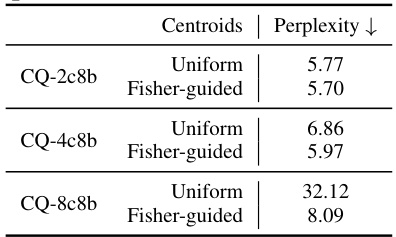
This figure shows the results of applying different coupled quantization configurations on the LLaMA-7b model using the WikiText-2 dataset. It compares the perplexity (a measure of how well the model predicts the next word) and quantization error for different configurations of coupled channels and centroid learning methods (uniform vs. Fisher-guided). The results demonstrate that increasing the number of coupled channels and using Fisher-guided centroid learning improves model performance by reducing perplexity and quantization error, indicating more efficient information encoding. The y-axis represents perplexity and quantization error, while the x-axis shows different coupled quantization configurations.

This figure shows the results of experiments on the LLaMA-7b model using WikiText-2 dataset. It compares different configurations of Coupled Quantization (CQ), focusing on the impact of the number of coupled channels and the centroid learning method (uniform vs. Fisher-guided). The plots show that increasing the number of coupled channels generally leads to lower perplexity and quantization errors, indicating improved model performance. The use of Fisher-guided centroid learning also appears beneficial, further enhancing model quality.
More on tables
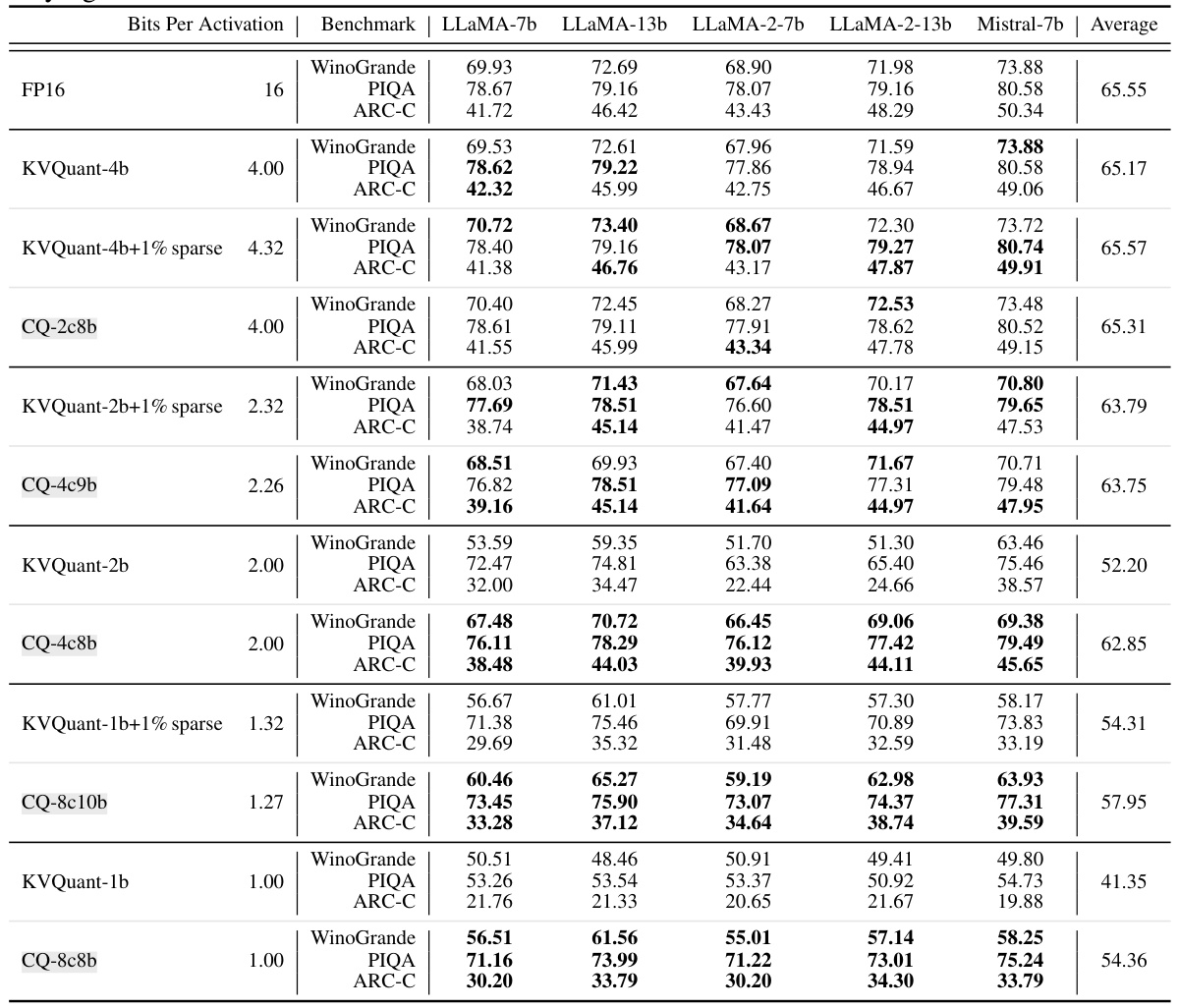
This table presents the perplexity scores achieved by several Large Language Models (LLMs) on the WikiText-2 benchmark dataset under various KV cache quantization methods and bit widths. It compares the performance of the proposed Coupled Quantization (CQ) method against existing methods like INT, NF, and KVQuant. The table highlights CQ’s superior performance in maintaining model quality even at extremely low bit widths, where other methods suffer from numerical instability or significant quality degradation.
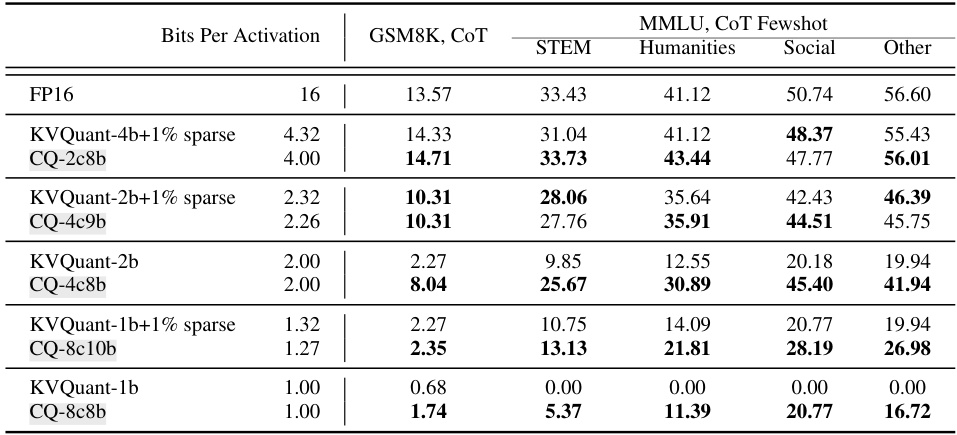
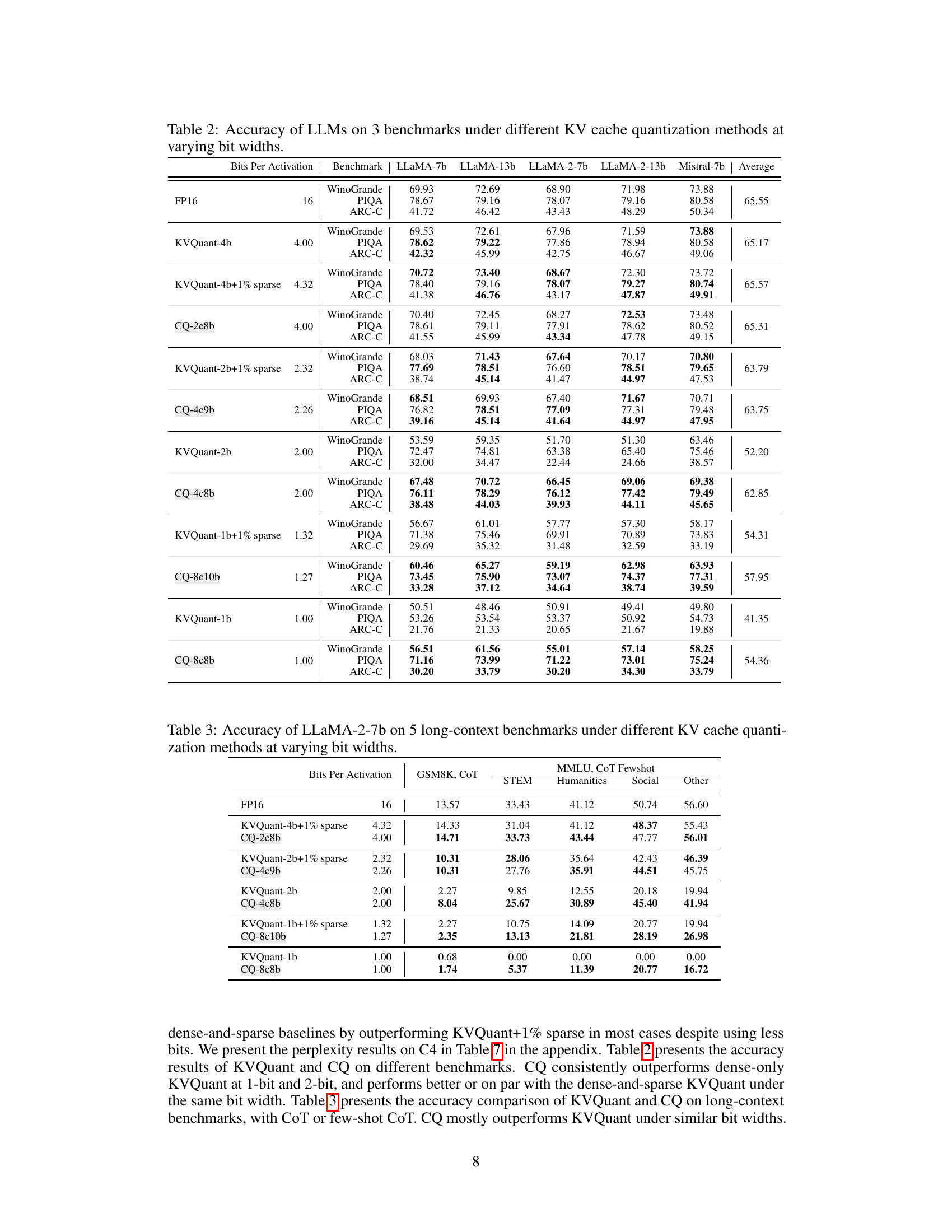
This table presents the results of evaluating the accuracy of the LLaMA-2-7b language model on five long-context benchmarks (GSM8K, STEM, Humanities, Social, and Other) using different KV cache quantization methods at various bit widths. The benchmarks assess different aspects of long-context understanding. The bit width represents the level of compression applied to the KV cache. The table shows how the accuracy changes based on the quantization method and bit-width. FP16 is the full precision baseline, while other rows represent different quantization techniques, comparing their accuracy at different compression levels.
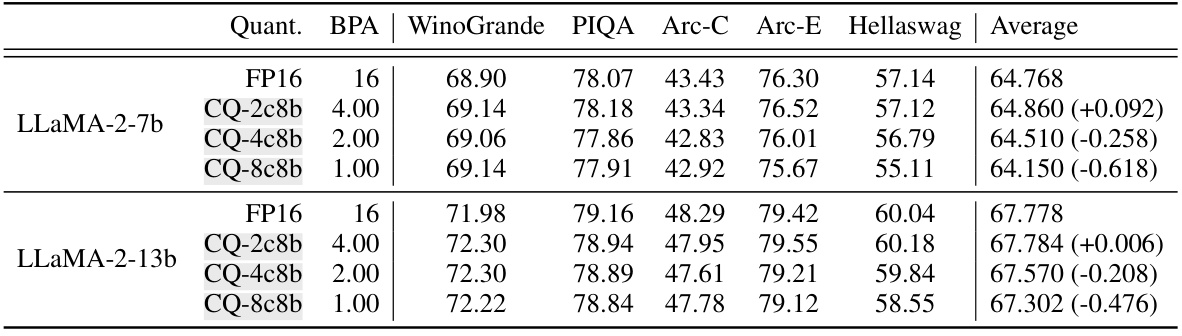
This table presents the accuracy results of two LLaMA-2 models (7B and 13B) evaluated on five downstream tasks (WinoGrande, PIQA, Arc-C, Arc-E, Hellaswag) under different KV cache quantization methods. The quantization methods include FP16 (full precision), and three variations of Coupled Quantization (CQ) with different bit-widths (4-bit, 2-bit, and 1-bit) using a sliding window of 32 recent tokens cached in FP16. The table demonstrates the effect of Coupled Quantization on model accuracy and its ability to maintain near-native performance even with extreme quantization levels (1-bit). The numbers in parentheses show the percentage change in average accuracy compared to the FP16 baseline for each model.
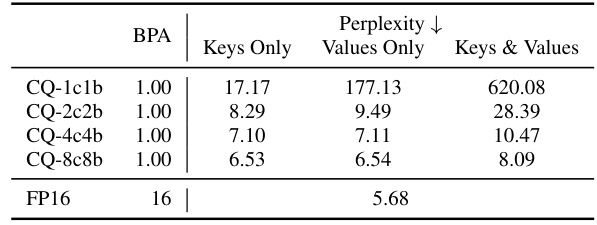
This table presents the results of an ablation study that investigates the impact of applying Coupled Quantization (CQ) to different parts of the Large Language Model (LLM). Specifically, it explores the effects of using CQ on only the keys, only the values, or both keys and values, within the KV cache. The results are measured using perplexity on the WikiText-2 dataset, providing a quantitative assessment of the impact of channel coupling on model performance. The bit width for all configurations is 1-bit.
This table presents the perplexity scores achieved by several Large Language Models (LLMs) on the WikiText-2 benchmark dataset using different Key-Value (KV) cache quantization methods. The models were evaluated across a range of bit widths for the KV cache quantization (from 16-bit down to 1-bit). Different quantization techniques are compared, including INT, NF, KVQuant, and the authors’ proposed Coupled Quantization (CQ). The table shows that CQ consistently outperforms the other methods at all bit widths, maintaining better quality even at very low bit depths, which indicates that their method is more efficient for compressing the KV cache.

This table presents the perplexity scores achieved by various Large Language Models (LLMs) on the WikiText-2 benchmark when using different Key-Value (KV) cache quantization methods. The methods compared include various integer quantization techniques (INT), NormalFloat quantization (NF), and KVQuant. The proposed Coupled Quantization (CQ) method is also included. Perplexity is a measure of how well a model predicts a text sequence, with lower scores indicating better performance. The table shows perplexity results for different bit depths (bits per activation), ranging from 16 bits (full precision) down to 1 bit. The results demonstrate that CQ generally outperforms the other methods, especially at lower bit depths, suggesting that it is an effective technique for compressing KV caches while maintaining model quality.

This table presents the results of an ablation study on two different LLMs, Mistral-7b and LLaMA-2-13b, to evaluate the effect of varying the number of coupled channels and the use of Fisher-guided centroids in Coupled Quantization (CQ). The experiment was performed using 2-bit quantization on the WikiText-2 dataset. Results show that perplexity generally decreases as the number of coupled channels increases, and that the use of Fisher-guided centroids further improves model performance.

This table presents the perplexity scores achieved by various Large Language Models (LLMs) on the WikiText-2 benchmark when using different Key-Value (KV) cache quantization methods. It compares the performance of several baseline methods (INT, NF, KVQuant) against the proposed Coupled Quantization (CQ) method at different bit-widths (1, 2, 4, 16 bits). Lower perplexity indicates better model performance. The table highlights CQ’s superior performance across various bit-widths and its ability to maintain reasonable performance even at extremely low bit-widths (1 bit), where other methods struggle.

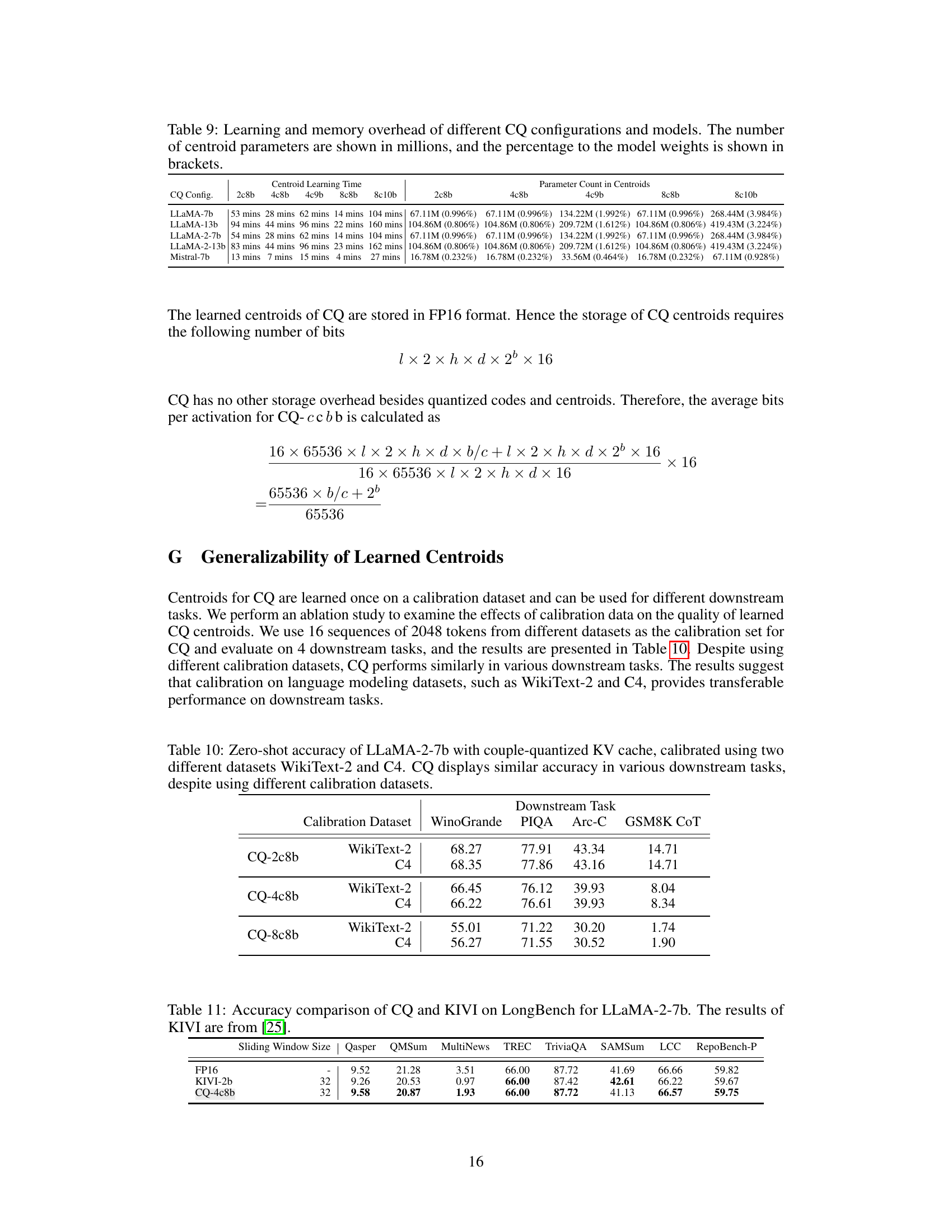
This table shows the zero-shot accuracy of the LLaMA-2-7b model on several downstream tasks. The model uses coupled quantization (CQ) for its key-value cache, and the table explores how using different calibration datasets (WikiText-2 and C4) affects the model’s performance. The results demonstrate that the CQ method is relatively robust and provides consistent performance across different tasks despite changes in the calibration dataset.

This table compares the performance of Coupled Quantization (CQ) and KIVI, another KV cache quantization method, on the LongBench benchmark using the LLaMA-2-7b model. It shows the accuracy (success rate) for various tasks across different sliding window sizes (32 tokens cached in full precision). The table helps demonstrate the relative performance of CQ compared to a competitive baseline method in preserving accuracy under quantization.
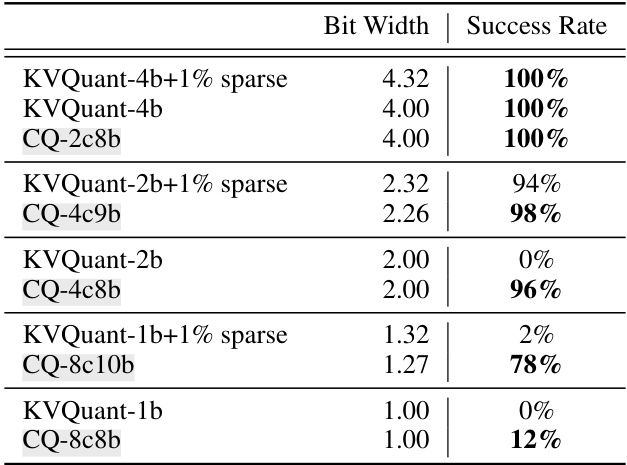
This table compares the performance of Coupled Quantization (CQ) and KVQuant in a passkey retrieval task using the LLaMA-2-7b model. It shows the success rate of retrieving the passkey at different bit-widths (levels of quantization). The maximum context length is 4096.

This table shows the perplexity scores achieved by various LLMs (LLaMA-7b, LLaMA-13b, LLaMA-2-7b, LLaMA-2-13b, Mistral-7b) on the WikiText-2 benchmark using different KV cache quantization methods and bit widths. The methods include Integer Quantization (INT), NormalFloat Quantization (NF), KVQuant, and the proposed Coupled Quantization (CQ). Perplexity is a measure of how well a language model predicts a sample; lower perplexity indicates better performance. The table highlights that CQ consistently outperforms other methods at the same bit width, demonstrating its effectiveness in preserving model quality even at very low bit-widths (1-bit). Note that ‘NaN’ (Not a Number) indicates numerical instability, highlighting the superior stability of CQ.

This table presents the perplexity scores achieved by various Large Language Models (LLMs) on the WikiText-2 benchmark under different KV cache quantization methods. It compares the performance of Coupled Quantization (CQ), a novel method introduced in the paper, against existing methods (INT, NF, and KVQuant) across various bit depths (1, 2, 4, 16 bits per activation). The table shows that CQ consistently achieves lower perplexity scores (indicating better performance) compared to the baselines at all bit widths. The presence of ‘NaN’ values highlights the numerical instability issues that can arise with some of the existing quantization methods at extremely low bit-widths.
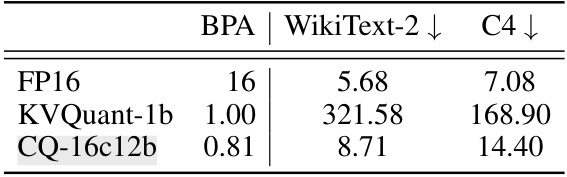
This table presents the perplexity scores achieved by various Large Language Models (LLMs) on the WikiText-2 benchmark dataset. The models were tested with different KV cache quantization methods and varying bit-widths (the number of bits used to represent each value). The table compares the performance of the proposed Coupled Quantization (CQ) method against existing methods (INT, NF, and KVQuant), demonstrating CQ’s superior performance at preserving model quality even under very low bit-widths, thereby achieving high compression.

This table presents the perplexity scores achieved by several Large Language Models (LLMs) on the WikiText-2 benchmark dataset under various KV cache quantization methods. Different bit widths (representing different levels of compression) are tested for each method. The table compares the performance of Coupled Quantization (CQ), the method proposed in the paper, against existing methods (INT, NF, KVQuant). The results highlight that CQ consistently outperforms the baselines, particularly at lower bit widths where other methods suffer from numerical instability.
Full paper#