↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Training large language models requires significant computational resources, particularly memory. Current methods often necessitate model sharding, offloading, or per-layer gradient updates, limiting the scalability and accessibility of large model training. Quantization and low-rank adaptation are promising techniques for reducing these memory demands. However, challenges remain in effectively applying these methods during pretraining, where randomly initialized weights hinder their effectiveness.
LoQT, a novel method proposed in this paper, tackles these challenges. By using gradient-based tensor factorization to initialize low-rank trainable weight matrices and periodically merging them into quantized full-rank weight matrices, LoQT enables efficient training of quantized models. This approach is suitable for both pretraining and fine-tuning, as demonstrated through experiments on language modeling and downstream tasks. LoQT achieved significant memory efficiency, training models up to 7B parameters on a 24GB GPU and a 13B parameter model with per-layer gradient updates, all while maintaining competitive performance to existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel method, LoQT, for efficiently training large quantized language models on consumer-grade hardware. This addresses a critical limitation in current large language model training and opens up new avenues for research and development in more memory-efficient and cost-effective AI model training. The method’s success in training a 13B parameter model on a single 24GB GPU is particularly significant and demonstrates its potential impact on democratizing access to large model training resources.
Visual Insights#

This figure compares the memory usage of different methods for training a 13B parameter Llama model with a rank of 1024 on an RTX 4090 GPU. The methods compared are: Adam (standard optimizer), GaLore (low-rank optimizer), LoQT (low-rank adapters for quantized training), and variations using 8-bit Adam and per-layer gradient updates. The bars represent the memory usage for each component: optimizer states, model weights, forward activations, gradients, and unknown memory. The figure highlights that LoQT significantly reduces memory usage compared to the other methods, especially when combined with 8-bit Adam and per-layer updates. The red dashed line indicates the 24GB VRAM limit of a typical consumer-grade GPU. The figure demonstrates the feasibility of training large language models with LoQT on consumer hardware.

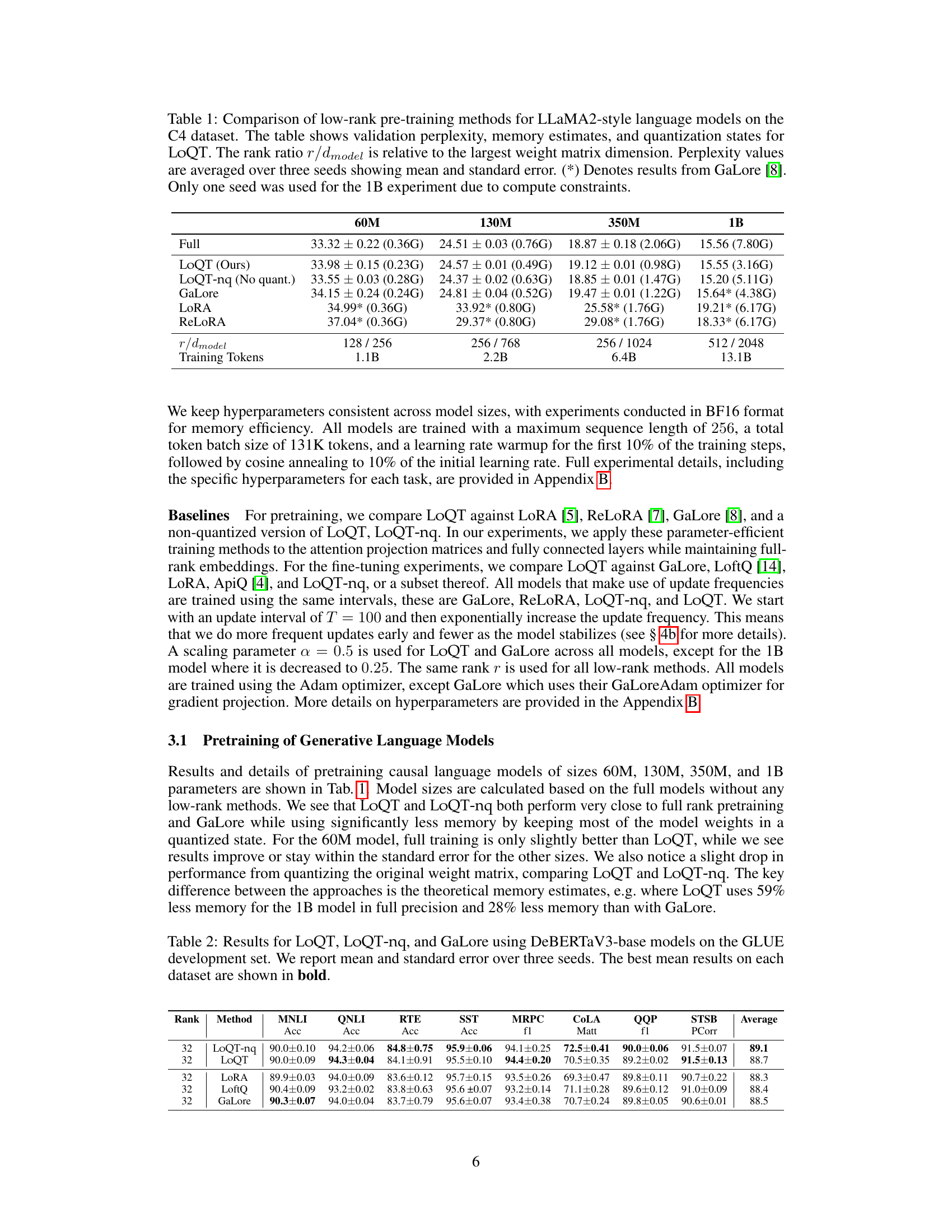
This table compares the performance of various low-rank pre-training methods (LoQT, LoQT without quantization, GaLore, LORA, ReLORA) on LLaMA2-style language models, trained on the C4 dataset. It shows validation perplexity (a measure of model accuracy), memory usage, and the model’s quantization state (whether or not quantization was used). The table highlights LoQT’s efficiency in memory usage while achieving comparable performance to full-rank models.
In-depth insights#
LoQT: Low-Rank Quantization#
LoQT: Low-Rank Adapters for Quantized Training is a novel method for efficiently training quantized large language models. It addresses the memory constraints of training massive models on consumer-grade hardware by employing low-rank weight matrices and periodic merging, thereby reducing the memory footprint of both the model parameters and optimizer states. The method leverages gradient-based tensor factorization to initialize low-rank trainable weight matrices, which are then periodically merged into quantized full-rank weight matrices. This approach is applicable to both pretraining and fine-tuning, leading to significant memory savings without sacrificing performance. LoQT’s effectiveness is demonstrated across various model sizes and tasks, highlighting its potential to democratize large-scale language model training by making it accessible on more readily available hardware. The use of quantization further enhances memory efficiency.
Memory-Efficient Training#
The research paper explores memory-efficient training methods for large language models (LLMs), a critical challenge given their substantial memory demands. Low-rank adapters are strategically employed to reduce the number of trainable parameters, while quantization techniques minimize the memory footprint of weights. A key innovation is the periodic merging of low-rank updates into full-rank quantized weight matrices, efficiently accumulating substantial adjustments without requiring full-precision weight storage. This combination of methods allows training of LLMs with billions of parameters on consumer-grade hardware, highlighting a significant advancement in overcoming computational constraints for developing and deploying LLMs. Exponentially increasing update intervals further enhance efficiency by adapting the frequency of updates to match the model’s convergence trajectory.
Quantization Strategies#
Effective quantization strategies are crucial for deploying large language models (LLMs) on resource-constrained devices. Post-training quantization (PTQ) methods offer a balance between simplicity and performance, but their accuracy may suffer compared to quantization-aware training (QAT) approaches. QAT methods integrate quantization into the training process, allowing the model to adapt to lower precision representations. Full quantization approaches optimize both forward and backward passes, maximizing efficiency but potentially complicating training and impacting accuracy. Choosing the right strategy often involves trade-offs between model size, memory usage, and computational efficiency. Low-rank adaptation methods are combined with quantization in some approaches, further reducing the parameter count and the memory footprint. The choice of quantization strategy depends heavily on the specific application and the available resources, with a careful evaluation of its impact on accuracy needed.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In this context, an ablation study on a large language model (LLM) might involve removing different elements like quantization, error compensation, or the exponentially increasing update schedule. The goal is to isolate the impact of each component on the overall model performance, such as validation perplexity. By observing the changes in performance after removing each feature, researchers can understand the specific role of each component and determine which ones are essential for achieving optimal results. Such a study might reveal that while quantization significantly reduces memory usage, it may come at the cost of slight performance degradation unless error compensation mechanisms are included. Therefore, a well-designed ablation study is crucial for understanding the trade-offs involved in optimizing LLMs and identifying which techniques are most effective in balancing performance and resource constraints. It helps guide future model development and design by highlighting the indispensable aspects of the architecture.
Future of LoQT#
The future of LoQT (Low-Rank Adapters for Quantized Training) looks promising, given its demonstrated ability to efficiently pretrain large language models on consumer-grade hardware. Further research could explore expanding LoQT’s applicability to other model architectures, beyond the LLMs showcased in the paper. Investigating the impact of different quantization techniques and their interplay with low-rank factorization is crucial. Optimizing the update schedule and exploring alternative low-rank decomposition methods could further boost performance. Addressing the trade-off between model size, rank, and quantization precision is also key; finding the optimal balance for various hardware constraints will be essential for wider adoption. Finally, a comprehensive analysis of the method’s limitations and potential biases is crucial, especially regarding fairness and robustness, before widespread deployment.
More visual insights#
More on figures

This figure illustrates the LoQT training process. It consists of three main steps that are periodically repeated: 1. Initialization: Low-rank factors P and B are initialized using the singular value decomposition (SVD) of the gradient of the dequantized model weights (VW). P is quantized (Pq), and B is calculated to minimize the difference between the quantized and original weight matrices (Wq and W, respectively). 2. Training: Only matrix B is trained while keeping Pq and Wq fixed and quantized. This training happens over an exponentially increasing interval until T_i. 3. Merging: The low-rank factors Pq and B are merged into the quantized weight matrix Wq to create an updated weight matrix for the next cycle. This process of training and merging repeats until the model training is complete. This iterative process reduces memory usage by optimizing only a low-rank component while maintaining quantized model weights.

This figure presents ablation studies on the impact of different factors on model performance. The left subplot shows the effect of various quantization strategies on perplexity. The right subplot analyzes the influence of different update interval schedules (fixed vs. exponentially increasing) on perplexity. The results illustrate the importance of error compensation and exponentially increasing update intervals for achieving comparable performance to models without quantization.
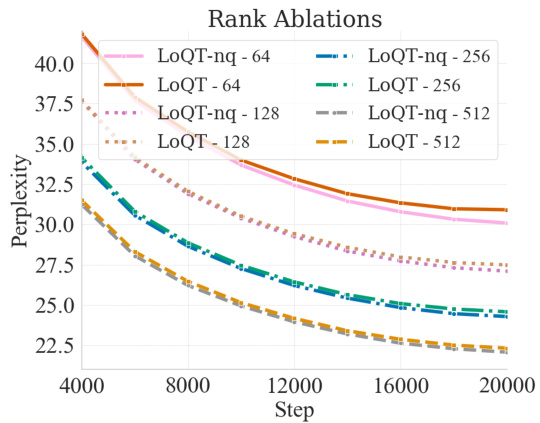
This figure displays the validation perplexity over training steps for different ranks using LoQT-nq (non-quantized) and LoQT (quantized). An exponentially increasing update frequency is used, starting at 100 steps and increasing with a factor of 1.2 per interval. The results show similar trajectories for quantized and non-quantized models across various ranks (64, 128, 256, 512), indicating that LoQT maintains comparable performance to LoQT-nq even with quantization. However, a divergence is seen at rank 64, suggesting a minimum rank threshold for effective quantization.

This figure compares the memory usage of different methods for training a 13B parameter Llama model with a rank of 1024. The methods compared include using Adam (a standard optimizer), GaLore (a low-rank optimizer), and LoQT (the proposed method in the paper) with and without 8-bit Adam and per-layer gradient updates. The figure visually demonstrates the significant memory savings achieved by LoQT, especially when combined with 8-bit Adam and per-layer updates, showcasing its effectiveness in training large models on hardware with limited memory.

This figure shows the ablation study of LoQT on a 130 million parameter model. It compares different configurations including: only quantizing weights (Wq), quantizing both weights and projection matrix (Wq, Pq), adding error compensation (EC), using exponentially increasing update intervals (EI), and a control group with no quantization (No Q). The x-axis represents the training step, and the y-axis represents the validation perplexity. The results demonstrate that exponentially increasing update intervals and error compensation significantly improve the model’s performance, especially for quantized models.
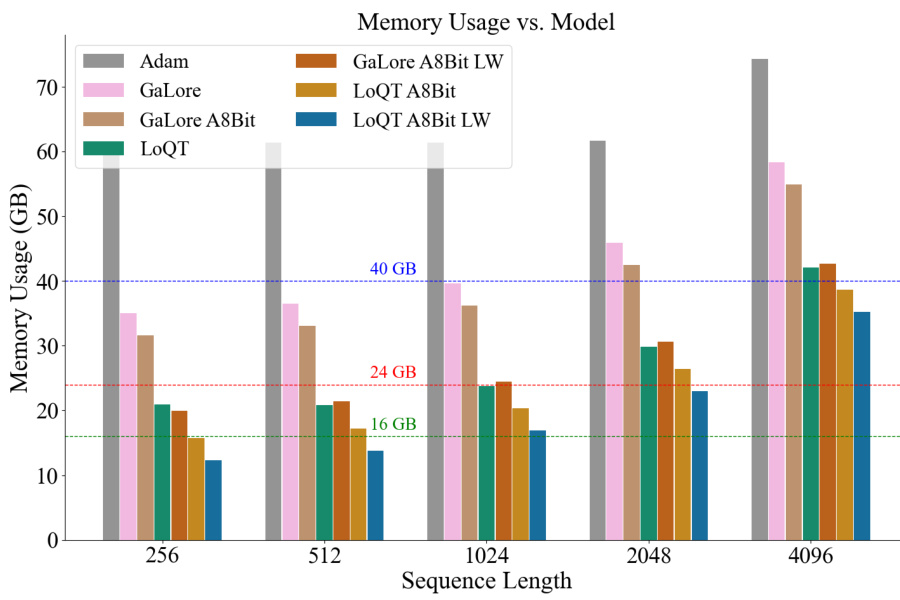
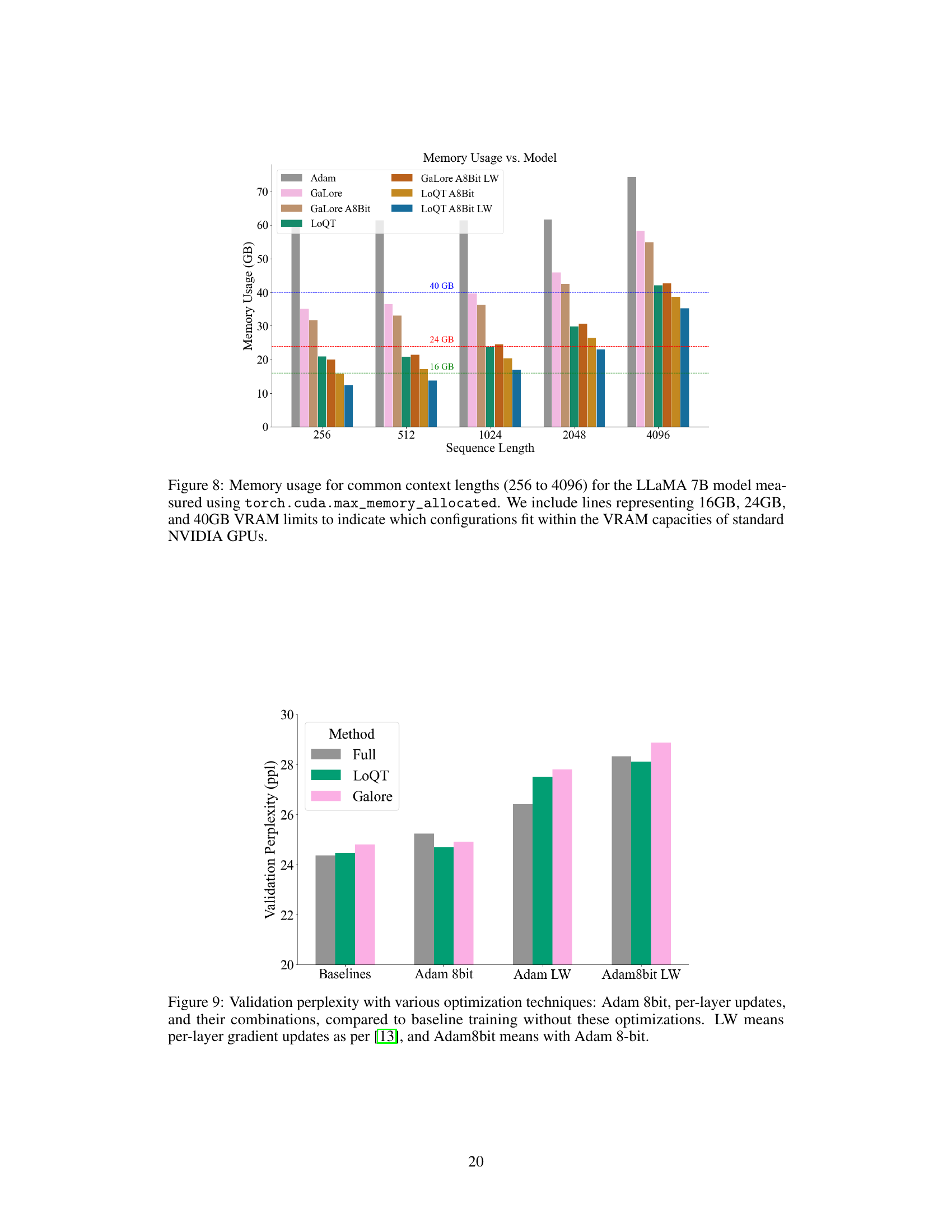
This figure compares the memory usage of LoQT with various baselines (Adam, GaLore, and Adam 8-bit) for different model sizes and sequence lengths. The ‘LW’ designation indicates the use of per-layer gradient updates, a technique that reduces memory requirements during training. The 8-bit versions of Adam and GaLore represent the use of 8-bit precision for these optimizers, further conserving memory. Horizontal lines indicate standard VRAM capacities of 16GB, 24GB, and 40GB to illustrate which configurations fit within the capabilities of different GPUs.
This figure compares the memory usage of LoQT against several baseline methods (Adam, Adam 8-bit, Adam with per-layer weight updates, GaLore, and GaLore with per-layer updates and 8-bit Adam) for different model sizes (1B, 3B, 7B, and 13B parameters). It demonstrates that LoQT consistently uses less memory than the baselines, especially when combined with per-layer updates and 8-bit Adam. The reduction in memory usage is significant, highlighting LoQT’s efficiency in training large language models.
More on tables

This table compares the performance of various low-rank pretraining methods (LoQT, LoQT without quantization, GaLore, LoRA, and ReLoRA) on LLaMA2-style language models using the C4 dataset. It shows validation perplexity, memory usage estimations, and quantization configurations. The results highlight LoQT’s memory efficiency while maintaining competitive performance compared to other methods.
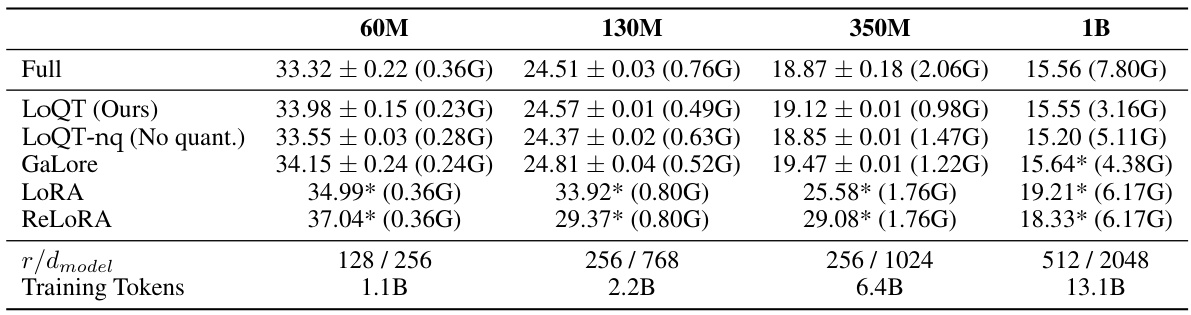
This table compares the performance of various low-rank pre-training methods for large language models on the C4 dataset. It shows the validation perplexity, estimated memory usage, and whether quantization was used for each method. The table includes results for models of different sizes (60M, 130M, 350M, and 1B parameters) and provides a rank ratio relative to the model’s largest weight matrix. Perplexity is averaged over three trials (except for the 1B model, which used only one due to computational constraints). Results marked with an asterisk (*) represent data taken from the GaLore paper.

This table compares the performance of several low-rank pre-training methods on the C4 dataset using LLaMA2-style language models. It presents key metrics including validation perplexity (a measure of how well the model predicts the next word in a sequence), memory usage estimates, and the quantization level used (e.g., whether the model weights were quantized to lower precision for reduced memory footprint). The results are averaged across multiple training runs to provide a more reliable comparison.

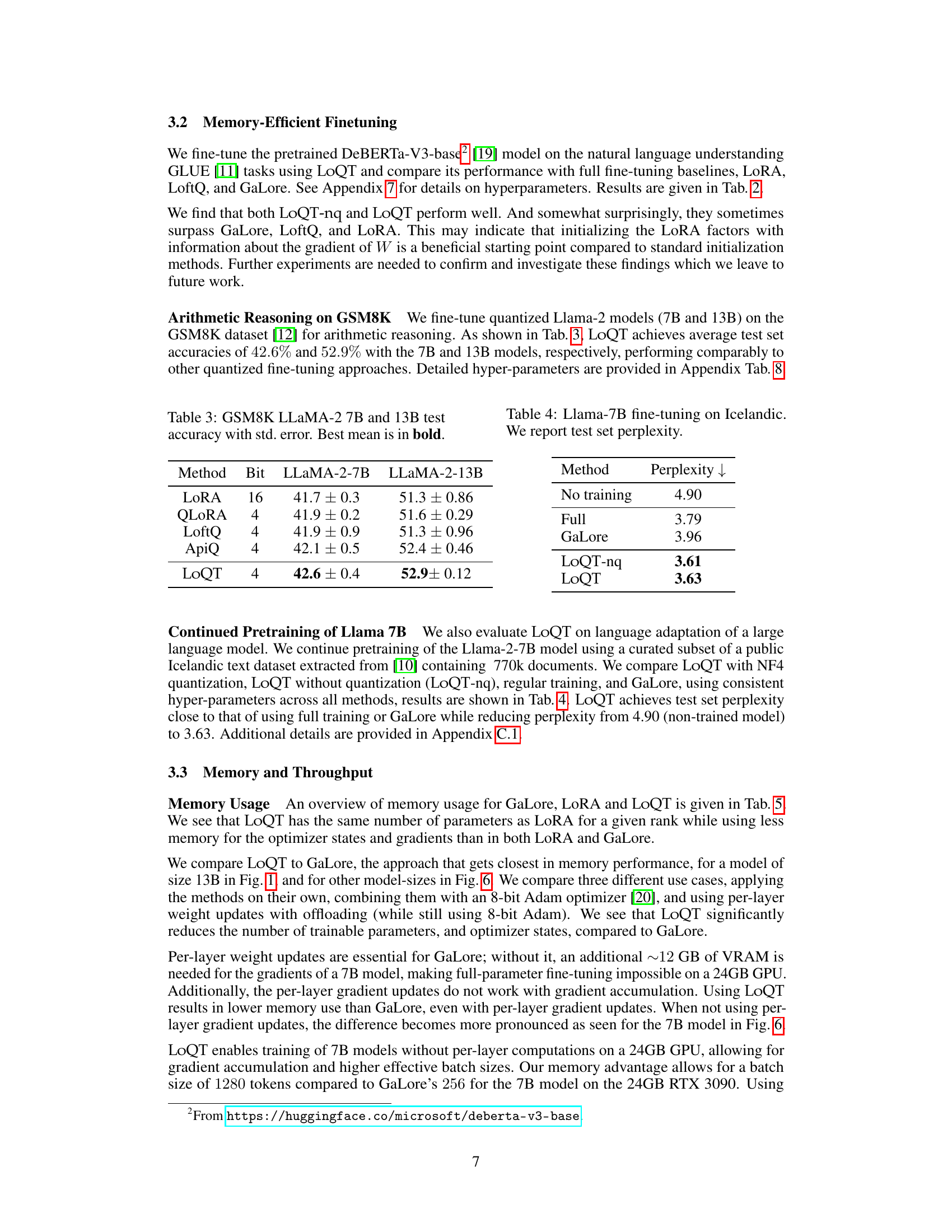
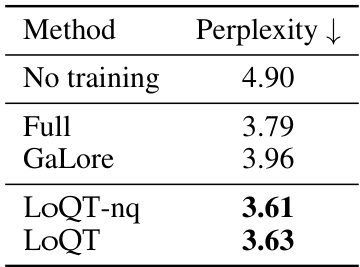
This table presents the results of fine-tuning quantized Llama-2 models (7B and 13B parameters) on the GSM8K dataset for arithmetic reasoning. It compares the test set accuracy of LoQT against several other methods (LoRA, QLoRA, LoftQ, ApiQ), showing the performance in terms of accuracy and standard error. The best-performing method for each model size is highlighted in bold.
This table compares the performance of various low-rank pre-training methods (LoQT, LoQT-nq, GaLore, LoRA, ReLORA) on LLaMA2-style language models using the C4 dataset. It presents validation perplexity, memory usage estimates, and quantization configurations for each method across four different model sizes (60M, 130M, 350M, and 1B parameters). The results highlight the memory efficiency and performance trade-offs of different approaches, especially LoQT’s ability to achieve comparable performance to full-rank training while significantly reducing memory.
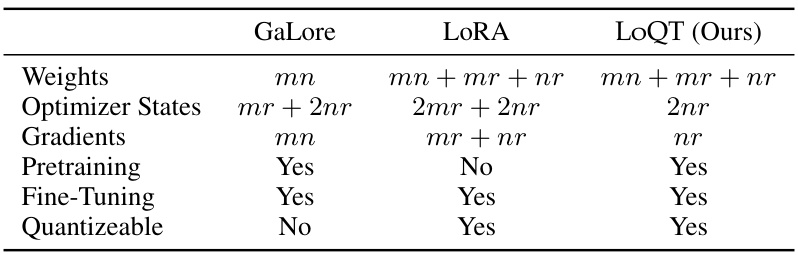
This table compares the performance of various low-rank pre-training methods on LLaMA2-style language models using the C4 dataset. It shows validation perplexity (a measure of model accuracy), estimated memory usage, and whether quantization was used. The rank ratio indicates the relative size of the low-rank approximation. Perplexity is averaged across multiple training runs to account for random variation, and the GaLore results marked with an asterisk are taken from a previous study. Due to computational limitations, only a single training run was performed for the 1B parameter model.
This table compares the performance of different low-rank pre-training methods for large language models on the C4 dataset. It shows validation perplexity (a measure of model accuracy), estimated memory usage, and whether quantization was used. Results are shown for models of various sizes (60M, 130M, 350M, and 1B parameters). The table highlights LoQT’s performance and memory efficiency relative to other methods, particularly in the context of quantization.

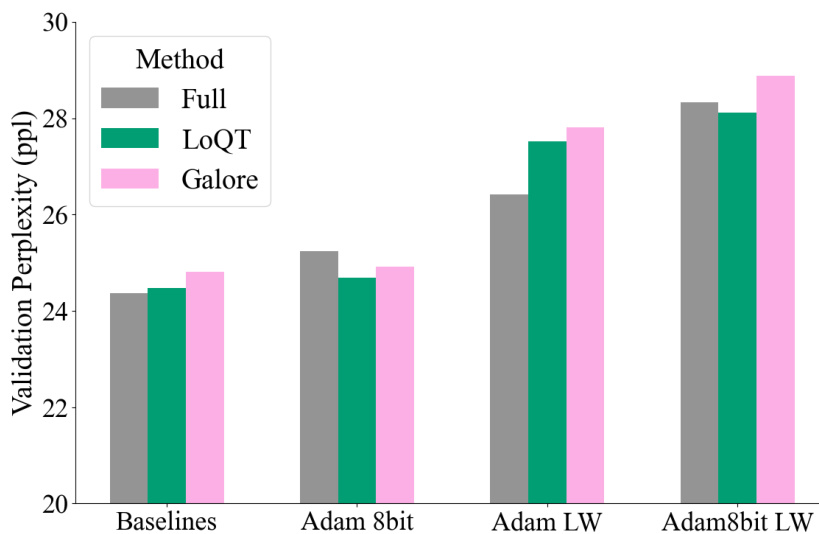
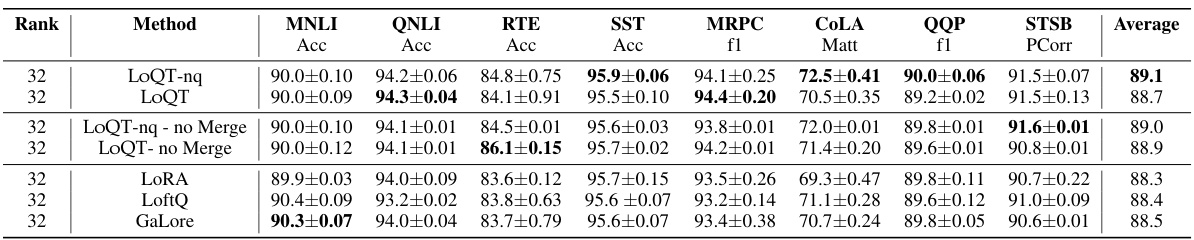
This table presents the results of fine-tuning experiments on the GLUE benchmark using three different methods: LoQT, LOQT-nq (a non-quantized version of LoQT), and GaLore. The table shows the accuracy scores achieved by each method on various GLUE tasks. The best performing method for each task is highlighted in bold. The results are averaged over three independent runs and standard errors are included to show the variability of the results.

This table compares the performance of LoQT with other low-rank pre-training methods for LLaMA2-style language models trained on the C4 dataset. It shows validation perplexity (a measure of model accuracy), memory usage estimates, and whether quantization was used. The results highlight LoQT’s memory efficiency compared to other methods, especially when using quantization.
This table compares the performance of several low-rank pre-training methods for large language models on the C4 dataset. It shows key metrics for different model sizes (60M, 130M, 350M, and 1B parameters), including validation perplexity (a measure of model performance), memory usage, and whether quantization was used. The results highlight the memory efficiency of the LoQT method while demonstrating its competitive performance compared to other approaches like LoRA and GaLore. The table also provides details on the rank of the low-rank matrices used relative to the model size and the number of training tokens used for each experiment.
Full paper#