↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) have made significant progress, but processing extensive contexts remains challenging due to the ever-growing Key-Value (KV) cache, which impacts memory and processing speed. Existing methods for compressing the KV cache often focus only on the generated text, neglecting the significant memory demands of the initial prompt. This is especially problematic for applications like chatbots, where prompts can be extremely long.
SnapKV introduces a new, fine-tuning-free method that addresses this limitation. By identifying consistent attention patterns in the model’s processing of prompts, SnapKV selectively compresses the KV cache, significantly reducing memory footprint and enhancing decoding speed without a noticeable drop in accuracy. Experiments demonstrate impressive speed and memory efficiency improvements, enabling the processing of significantly longer contexts, making LLMs more practical and scalable.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical efficiency bottleneck in LLMs—the growing Key-Value (KV) cache. By introducing SnapKV, a novel approach that compresses KV caches without needing fine-tuning, it significantly improves the speed and memory efficiency of LLMs for processing long input sequences. This opens exciting avenues for deploying large language models on resource-constrained devices and for creating more efficient and scalable applications.
Visual Insights#
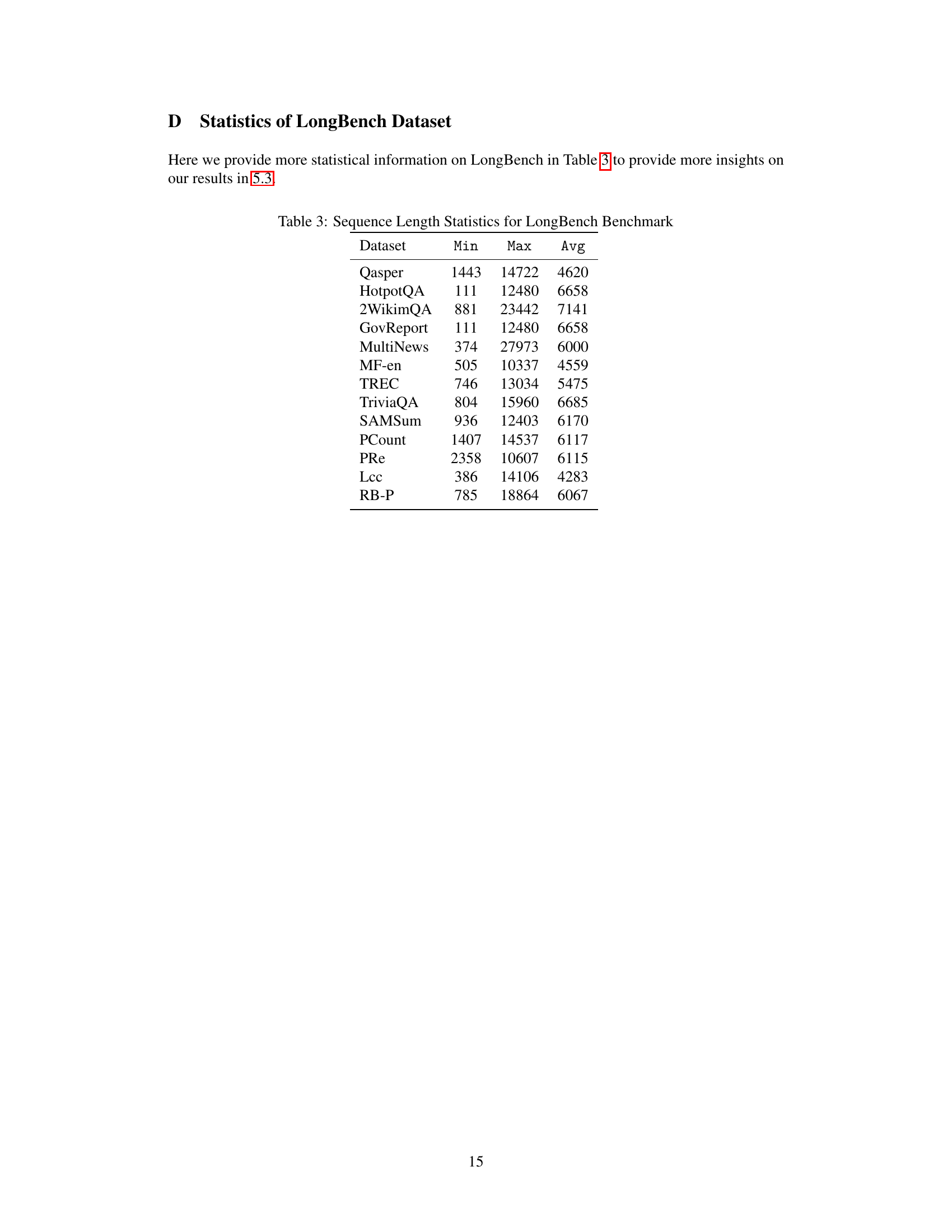
🔼 The figure illustrates the SnapKV workflow. It shows how SnapKV selects important features from the prompt (the initial input to the LLM) using a voting and selection mechanism based on an observation window at the end of the prompt. These features are then clustered and concatenated with the observation window features to create a compressed KV cache for generation, significantly reducing memory usage and improving efficiency compared to traditional methods.
read the caption
Figure 1: The graph shows the simplified workflow of SnapKV, where the orange area represents the cluster of features per head selected by SnapKV. These features are then used to form new Key-Value pairs concatenated with the features in the observation window. Together, the selected prefix and observation windows constitute the new KV cache utilized for the generation.
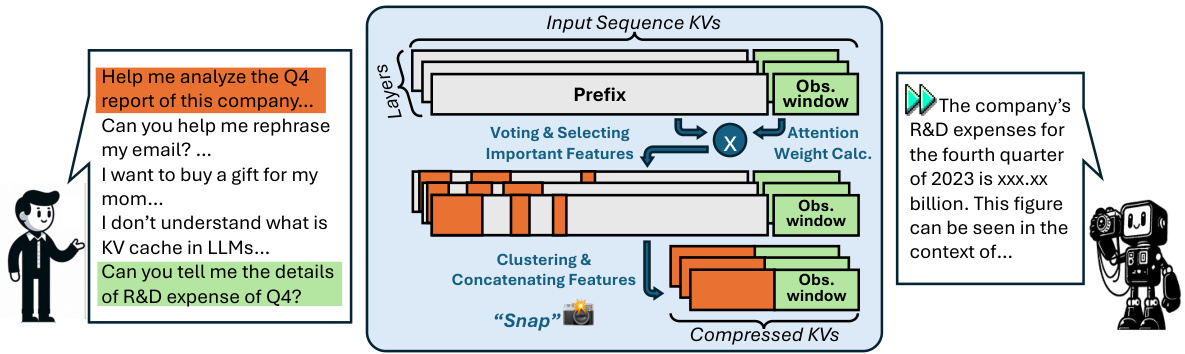
🔼 This table presents a comparison of the performance of SnapKV and H2O, two different KV cache compression techniques, across various Large Language Models (LLMs) using the LongBench benchmark. It shows the accuracy scores achieved by each method on 16 different tasks within the LongBench benchmark, allowing for a comprehensive comparison of their effectiveness across a range of LLMs and tasks. Note that the table includes various configurations of SnapKV and H2O.
read the caption
Table 1: Performance comparison of SnapKV and H2O across various LLMs on LongBench.
In-depth insights#
SnapKV: Core Idea#
SnapKV’s core idea centers on efficiently minimizing large language model (LLM) memory usage during long-context processing. It leverages the observation that attention heads consistently focus on specific prompt features, even during generation. SnapKV identifies these key features from an ‘observation window’ at the prompt’s end. By selecting and clustering these crucial features, it compresses the key-value (KV) cache, significantly reducing memory footprint and decoding latency without substantial accuracy loss. This innovative, fine-tuning-free approach offers a practical solution for handling extensive contexts in LLMs, enhancing both speed and efficiency for real-world applications. The method’s effectiveness stems from its ability to predict important features before generation, streamlining the process and avoiding unnecessary computation.
Attention Patterns#
Analysis of attention patterns in LLMs reveals consistent focusing on specific prompt features during generation. This suggests that the model identifies key information early on. A crucial observation is that these important features often reside within a predictable ‘observation window’ at the end of the prompt. This consistent pattern allows for efficient compression of the key-value (KV) cache, a significant memory bottleneck in LLMs, without a substantial drop in accuracy. Exploiting this pattern, methods such as SnapKV can significantly improve speed and memory efficiency, enabling LLMs to handle much longer contexts. The robustness of this attention behavior across various datasets and prompts highlights the potential for more efficient LLM architectures based on early identification of crucial information within the input. This research underscores the value of understanding and utilizing inherent model behavior to create more practical and scalable large language models.
SnapKV Algorithm#
The SnapKV algorithm is an innovative approach to efficiently minimize the Key-Value (KV) cache size in large language models (LLMs) without sacrificing accuracy. It leverages the observation that attention heads consistently focus on specific prompt features during generation, identifying these crucial features from an ‘observation window’ at the end of the prompt. SnapKV uses a voting mechanism and clustering to select and group these important features, creating compressed KV pairs that significantly reduce computational overhead and memory footprint, especially when processing long input sequences. This method is particularly effective for scenarios where prompts (rather than generated responses) dominate memory usage, such as in chatbots or agent systems. Crucially, SnapKV requires no fine-tuning, making it readily adaptable to existing LLMs and offering significant improvements in decoding speed and memory efficiency without substantial accuracy loss. The algorithm demonstrates effectiveness on various datasets, showcasing the potential for practical applications in handling longer contexts, particularly within resource-constrained environments.
Pooling’s Impact#
Pooling, in the context of the SnapKV algorithm for efficient large language model (LLM) processing, plays a crucial role in enhancing the accuracy of crucial feature selection from the input prompt. The algorithm identifies significant attention features in an observation window of the input and then uses pooling (a dimensionality reduction technique) to aggregate those features. This aggregation step is vital because it clusters related features, increasing the accuracy of identifying important information and thereby improving the effectiveness of the compressed KV cache. Without pooling, simply selecting top-k features risks compromising important contextual information, potentially leading to inaccurate response generation. Pooling’s impact is thus twofold: it enhances the efficiency of the feature selection process and simultaneously preserves the contextual integrity of the input prompt, contributing significantly to the success of the SnapKV method in achieving comparable performance with greatly reduced memory consumption and increased speed.
Future Works#
Future work could explore several promising avenues. Extending SnapKV’s applicability to a wider range of LLMs and tasks is crucial, evaluating its performance on models with different architectures and training objectives. Investigating the optimal design of the observation window and pooling strategy through more extensive experimentation is also important, exploring the interplay between window size, kernel size, and model characteristics. Furthermore, research into the theoretical underpinnings of attention allocation patterns could yield significant insights into LLM behavior and inform more efficient compression techniques. Finally, combining SnapKV with other optimization strategies, such as quantization and pruning, holds the potential for even greater memory and computational efficiency gains. A comprehensive evaluation on a broader set of benchmark datasets would also strengthen the findings.
More visual insights#
More on figures
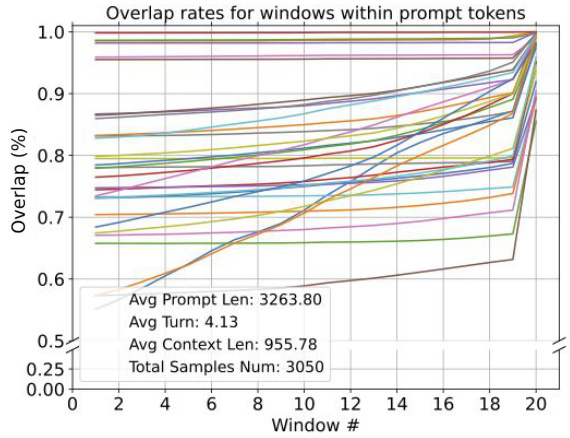
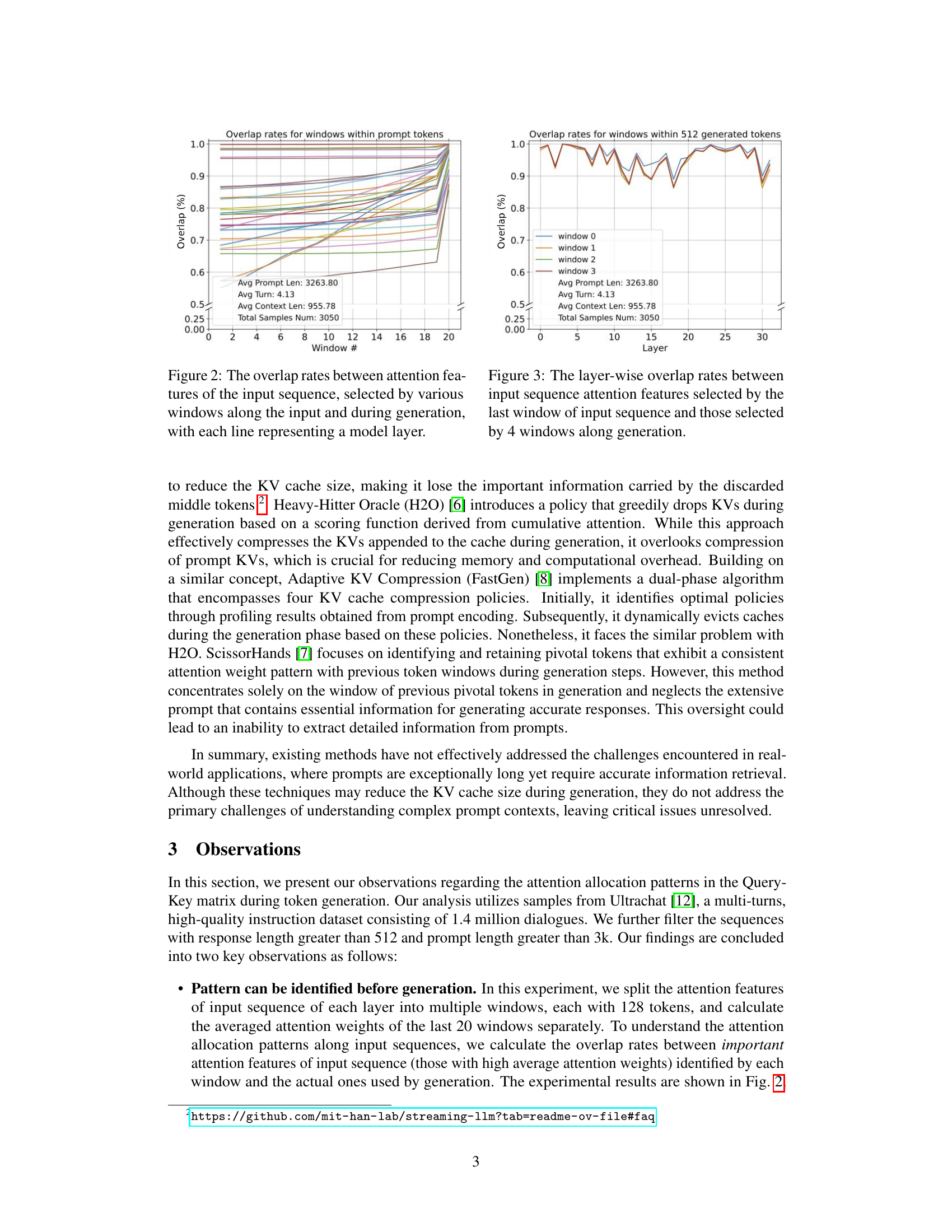
🔼 This figure shows the consistency of attention patterns in LLMs. It plots the overlap rate between attention features selected by different windows within the input prompt sequence and the actual attention features used during generation. Each line represents a different layer in the LLM, demonstrating that the attention patterns identified by the last window of the input sequence are highly consistent with the patterns observed during generation. This suggests that the LLM focuses on specific features early in the process, which is the basis for the SnapKV algorithm.
read the caption
Figure 2: The overlap rates between attention features of the input sequence, selected by various windows along the input and during generation, with each line representing a model layer.
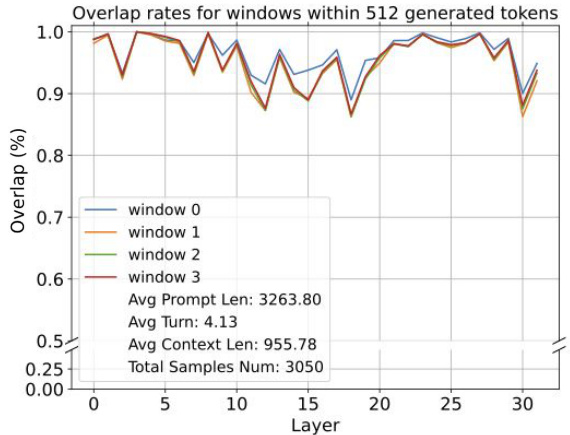
🔼 This figure shows the layer-wise overlap rates between the attention features selected by the last window of the input sequence and those selected by four windows during the generation process. The x-axis represents the layer number, and the y-axis represents the overlap rate (percentage). Each colored line corresponds to a different window during generation (window 0, window 1, window 2, window 3). The high overlap rates across layers suggest that the attention focus on important input features remains relatively consistent throughout the generation process.
read the caption
Figure 3: The layer-wise overlap rates between input sequence attention features selected by the last window of input sequence and those selected by 4 windows along generation.
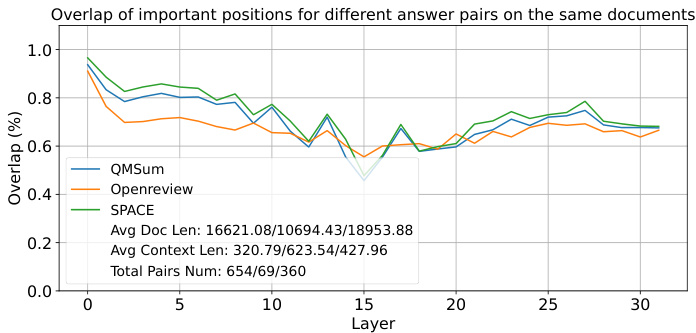
🔼 This figure shows the layer-wise overlap of important positions used by different question-answer pairs within the same dataset. The x-axis represents the layer number, and the y-axis represents the overlap percentage. Three datasets (QMSum, Openreview, and SPACE) are shown, each represented by a different colored line. The graph demonstrates the consistency of important attention features across different question-answer pairs within a dataset, even across different layers of the model. This consistency supports the claim that LLMs know what information is important before generation begins.
read the caption
Figure 4: The layer-wise overlap of important positions utilized by different question-answer pairs in the same dataset.
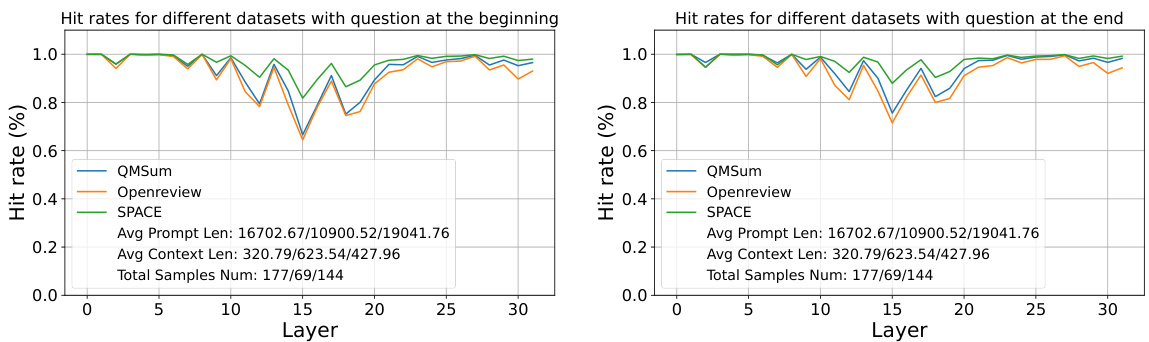
🔼 This figure shows the layer-wise average hit rate of important positions used by prompts containing questions placed at the beginning versus the end of the prompts. The hit rate represents the percentage of important attention features successfully selected by the observation window. The x-axis shows the layer number, and the y-axis represents the hit rate. Different colored lines correspond to different datasets (QMSum, Openreview, SPACE). The average prompt length, average context length, and the total number of samples used in the experiment are indicated in the legend.
read the caption
Figure 5: The layer-wise average hit rate of important positions used by prompts with questions at the beginning and the end.

🔼 This figure shows the results of the Needle-in-a-Haystack test, which evaluates the ability of a model to find a short sentence (’needle’) within a long document (‘haystack’). The x-axis represents the length of the document, and the y-axis represents the location of the needle within the document. The results show that SnapKV allows the model to process much longer documents (up to 380k tokens) than the baseline, with only a small decrease in accuracy.
read the caption
Figure 6: Needle-in-a-Haystack test performance comparison on single A100-80GB GPU, native HuggingFace implementation with only a few lines of code changed. The x-axis denotes the length of the document ('haystack') from 1K to 380K tokens; the y-axis indicates the position that the 'needle' (a short sentence) is located within the document. For example, 50% indicates that the needle is placed in the middle of the document. Here LWMChat with SnapKV is able to retrieve the needle correctly before 140k and with only a little accuracy drop after. Meanwhile, the original implementation encounters OOM error with 33k input tokens (white dashed line).
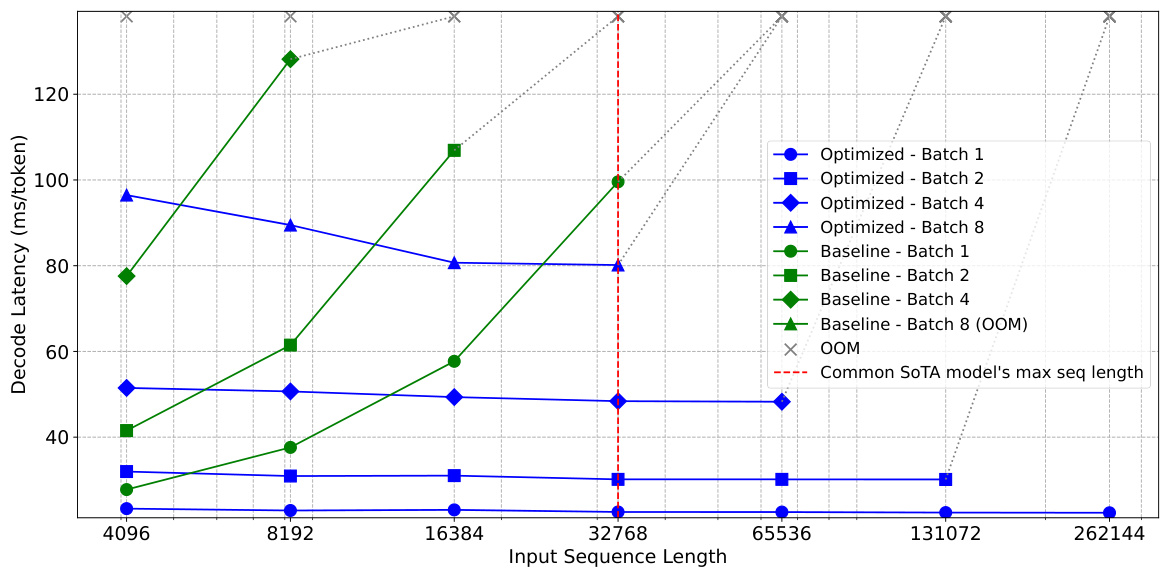
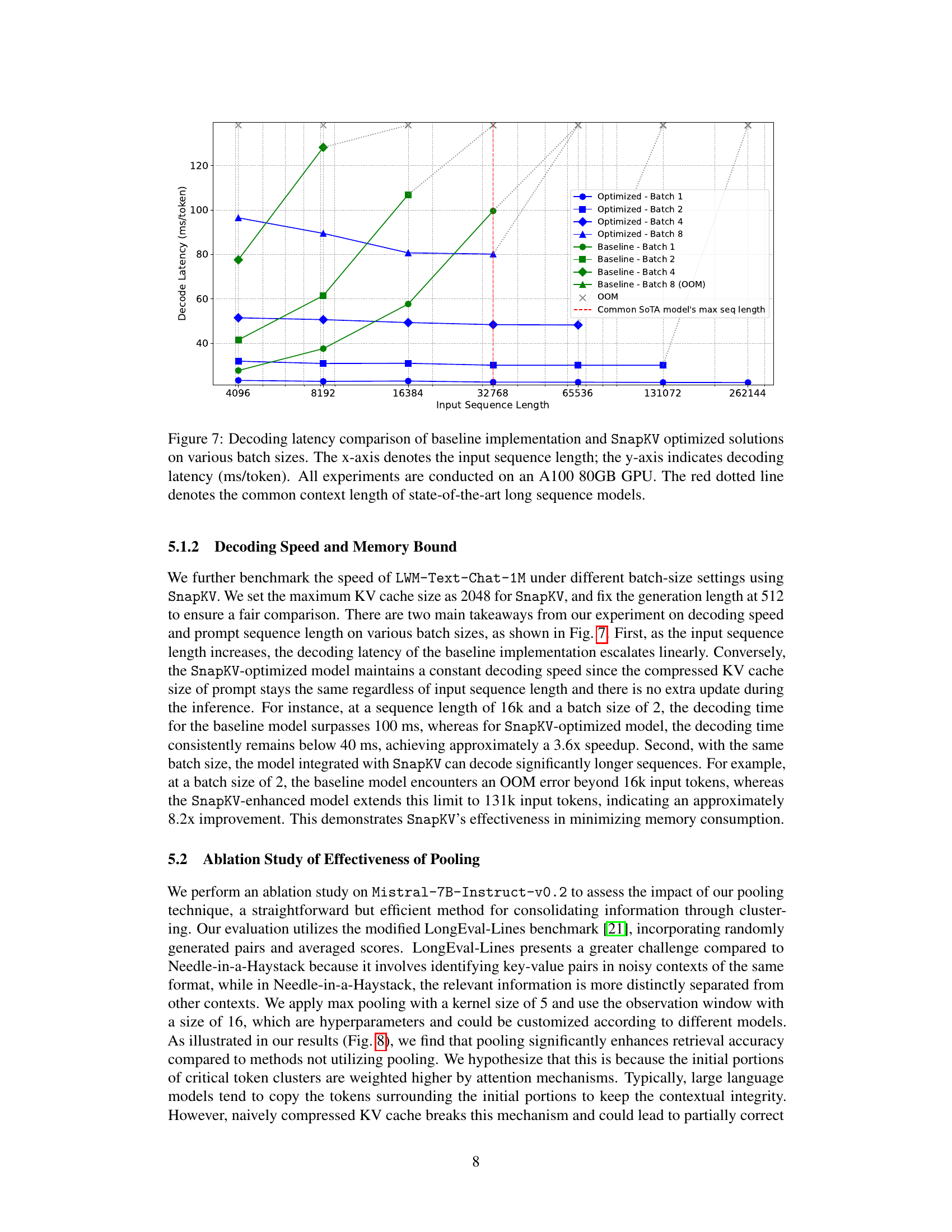
🔼 This figure compares the decoding latency (in milliseconds per token) of a baseline LLM model and the same model optimized using SnapKV, across various input sequence lengths and batch sizes. It shows how SnapKV maintains a nearly constant latency even as the input sequence length increases, whereas the baseline latency grows linearly, ultimately exceeding memory limits (OOM). The red line indicates the typical maximum input length for state-of-the-art models. The results demonstrate the improved decoding speed and memory efficiency of SnapKV.
read the caption
Figure 7: Decoding latency comparison of baseline implementation and SnapKV optimized solutions on various batch sizes. The x-axis denotes the input sequence length; the y-axis indicates decoding latency (ms/token). All experiments are conducted on an A100 80GB GPU. The red dotted line denotes the common context length of state-of-the-art long sequence models.

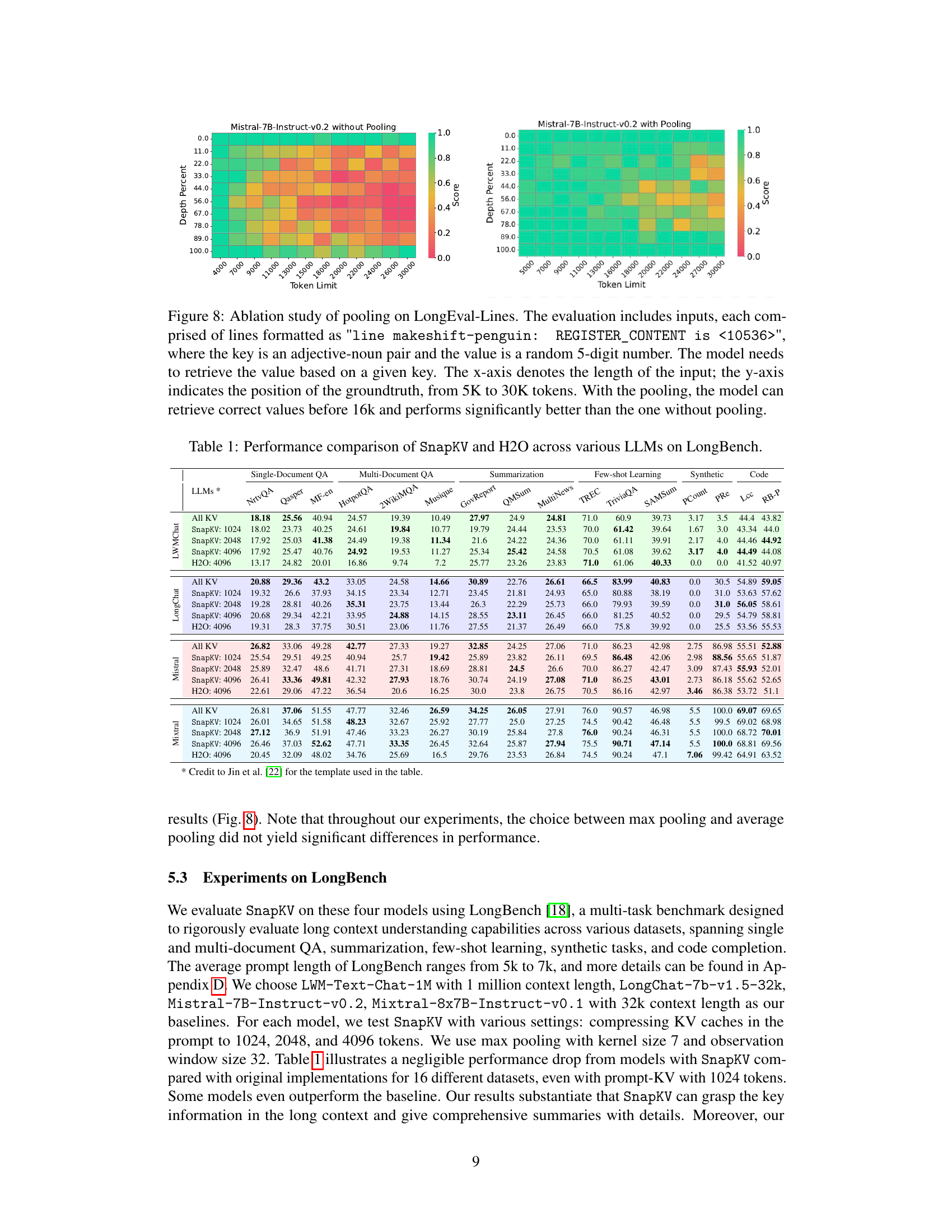
🔼 This figure shows the ablation study of the pooling mechanism within the SnapKV algorithm, using the LongEval-Lines benchmark dataset. The heatmaps compare the performance of the Mistral-7B-Instruct-v0.2 model with and without pooling. The x-axis represents the input length, and the y-axis shows the position of the ground truth value. The color intensity reflects the accuracy. The results demonstrate that pooling significantly improves the model’s ability to accurately retrieve information, especially when dealing with longer input sequences.
read the caption
Figure 8: Ablation study of pooling on LongEval-Lines. The evaluation includes inputs, each comprised of lines formatted as 'line makeshift-penguin: REGISTER_CONTENT is <10536>', where the key is an adjective-noun pair and the value is a random 5-digit number. The model needs to retrieve the value based on a given key. The x-axis denotes the length of the input; the y-axis indicates the position of the groundtruth, from 5K to 30K tokens. With the pooling, the model can retrieve correct values before 16k and performs significantly better than the one without pooling.

🔼 This figure compares the generation latency in milliseconds per token for three different methods: Medusa with SnapKV, Medusa alone, and a baseline method (HuggingFace’s naive decoding). The x-axis represents the prompt length in thousands of tokens, while the y-axis shows the latency. The graph demonstrates that Medusa with SnapKV significantly reduces latency compared to Medusa alone and the baseline, especially as the prompt length increases.
read the caption
Figure 9: Comparison of generation latency (ms/token). The baseline is the Huggingface implementation of naive decoding.
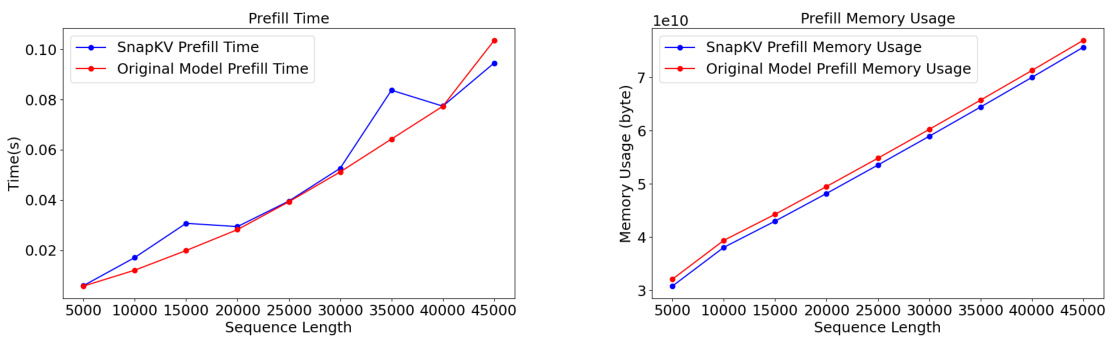
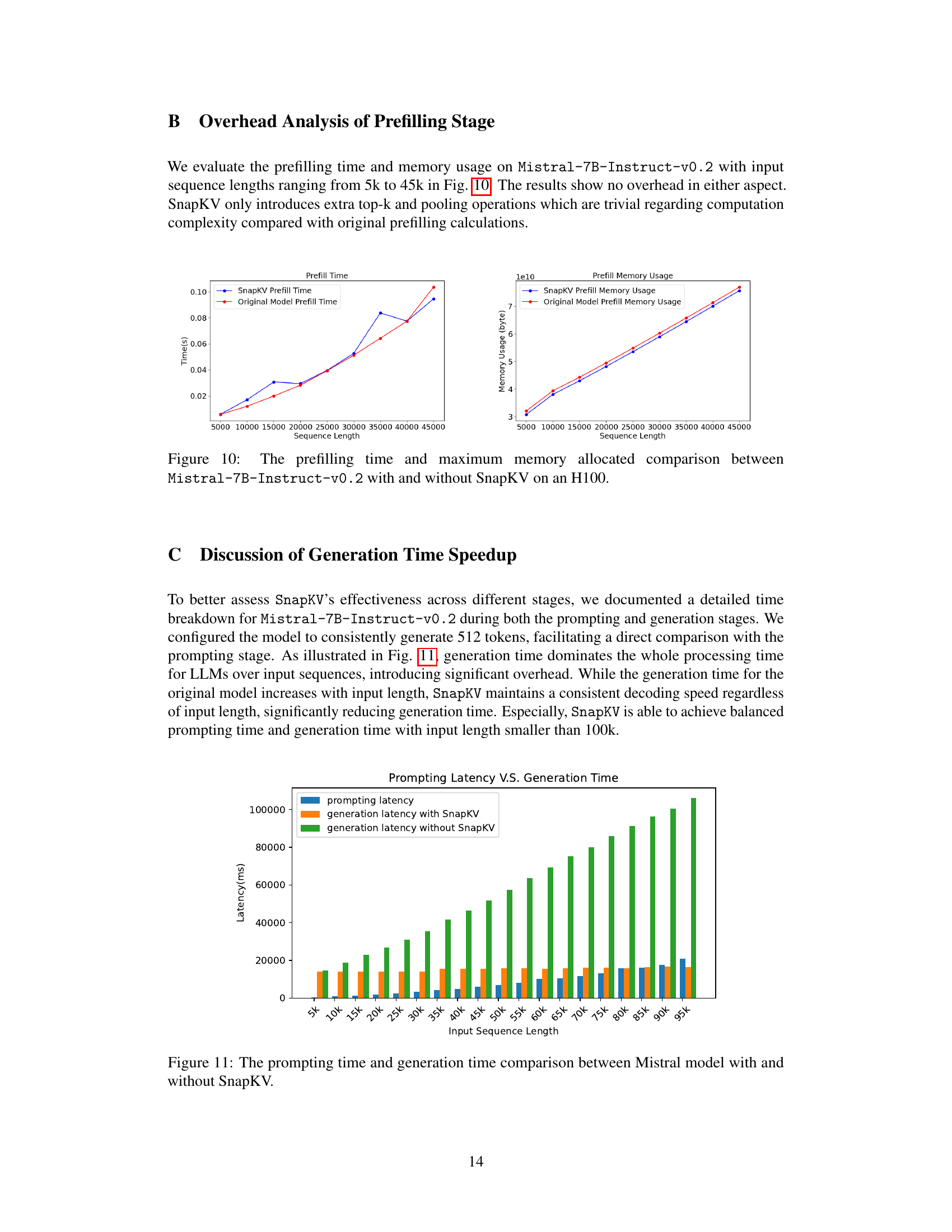
🔼 This figure compares the prefilling time and maximum memory usage between the original Mistral-7B-Instruct-v0.2 model and the same model using SnapKV on an H100 GPU. It shows the performance for input sequences ranging from 5,000 to 45,000 tokens. The results demonstrate that SnapKV introduces minimal overhead in terms of both prefilling time and memory consumption, even for very long sequences.
read the caption
Figure 10: The prefilling time and maximum memory allocated comparison between Mistral-7B-Instruct-v0.2 with and without SnapKV on an H100.
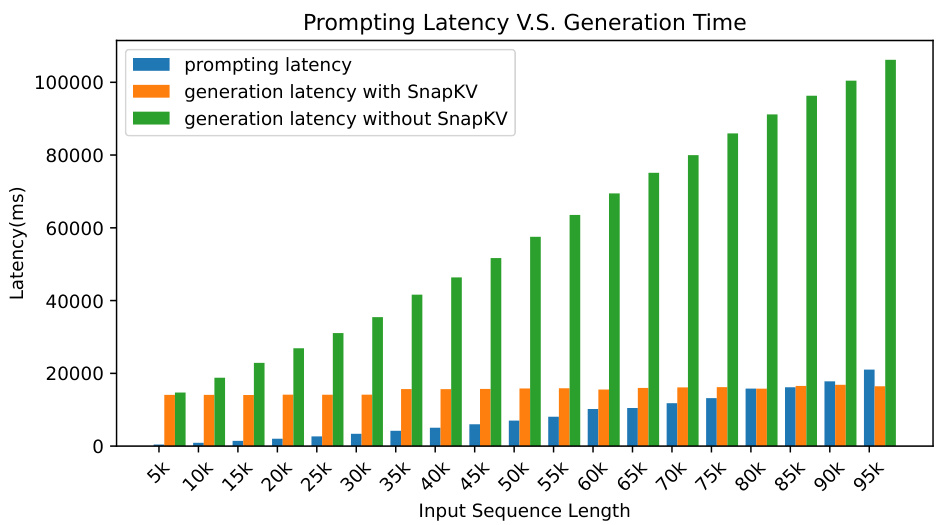
🔼 This figure compares the prompting time and generation time of the Mistral model with and without SnapKV for varying input sequence lengths. It shows that while prompting time increases relatively slowly with input length, the generation time for the standard model increases dramatically. SnapKV maintains a nearly constant generation time regardless of input length, significantly reducing the overall processing time. The speed advantage of SnapKV is more pronounced for longer input sequences.
read the caption
Figure 11: The prompting time and generation time comparison between Mistral model with and without SnapKV.
🔼 This figure showcases the results of a Needle-in-a-Haystack test, comparing the performance of the original HuggingFace implementation and the SnapKV-enhanced version on an A100-80GB GPU. The test evaluates the ability of the models to locate a short sentence (’needle’) within a long document (‘haystack’) of varying lengths (1K to 380K tokens). The x-axis represents the document length, and the y-axis shows the location of the ’needle’ within the document. The results demonstrate that SnapKV significantly improves the model’s ability to retrieve the needle, even at extremely long document lengths, while the original implementation runs out of memory (OOM) at just 33K tokens.
read the caption
Figure 6: Needle-in-a-Haystack test performance comparison on single A100-80GB GPU, native HuggingFace implementation with only a few lines of code changed. The x-axis denotes the length of the document ('haystack') from 1K to 380K tokens; the y-axis indicates the position that the 'needle' (a short sentence) is located within the document. For example, 50% indicates that the needle is placed in the middle of the document. Here LWMChat with SnapKV is able to retrieve the needle correctly before 140k and with only a little accuracy drop after. Meanwhile, the original implementation encounters OOM error with 33k input tokens (white dashed line).
More on tables
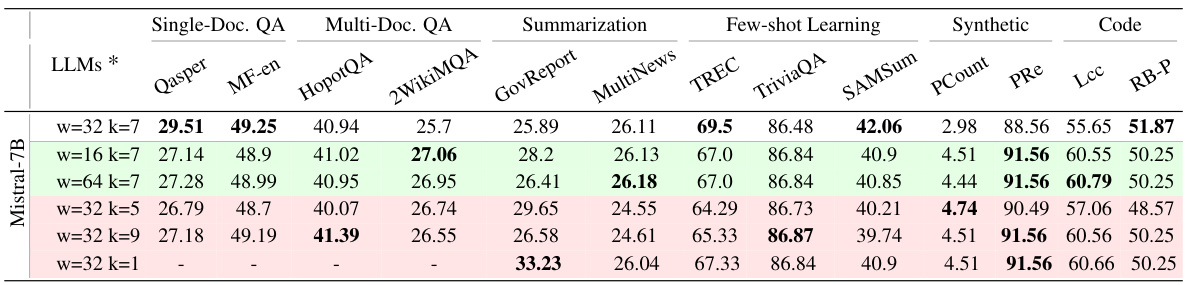
🔼 This table presents a comparison of the performance of SnapKV and H2O across sixteen different tasks within the LongBench benchmark. The results are broken down by different LLMs (Large Language Models) and various KV cache sizes. The table shows the effectiveness of SnapKV compared to H2O in maintaining comparable accuracy across several tasks, while improving efficiency by compressing the KV cache.
read the caption
Table 1: Performance comparison of SnapKV and H2O across various LLMs on LongBench.
🔼 This table presents a comparison of the performance of SnapKV and H2O, two different KV cache compression methods, across various Large Language Models (LLMs) using the LongBench benchmark. It shows the effectiveness of each method across a variety of tasks, including single and multi-document question answering, summarization, few-shot learning, and code generation, highlighting the improvements in accuracy and efficiency achieved by SnapKV.
read the caption
Table 1: Performance comparison of SnapKV and H2O across various LLMs on LongBench.
Full paper#