↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) and Vision Transformers (ViTs) are computationally expensive due to their quadratic time complexity in the number of tokens. Recent work tried to address this by merging similar tokens using methods based on Bipartite Soft Matching (BSM), but these often suffer from sensitivity to token splitting and potential damage to informative tokens. This presents a significant drawback, limiting the efficiency gains that are possible.
To overcome these limitations, the authors propose PITOME (Protect Informative Tokens before Merging). PITOME employs a novel energy score metric to identify and protect informative tokens, improving the selection process for merging. Experiments on various tasks (image classification, image-text retrieval, visual question answering) demonstrate that PITOME achieves state-of-the-art performance while reducing FLOPs by 40-60% compared to baselines. Furthermore, PITOME is theoretically shown to preserve spectral properties, providing a strong theoretical foundation for its efficacy.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel token merging method, PITOME, that significantly accelerates Transformer models without substantial accuracy loss. This addresses a critical challenge in the field, enabling faster and more efficient processing of large datasets for various applications. The theoretical analysis and strong empirical results demonstrate the method’s effectiveness and open up new avenues of research into more efficient Transformer architectures.
Visual Insights#

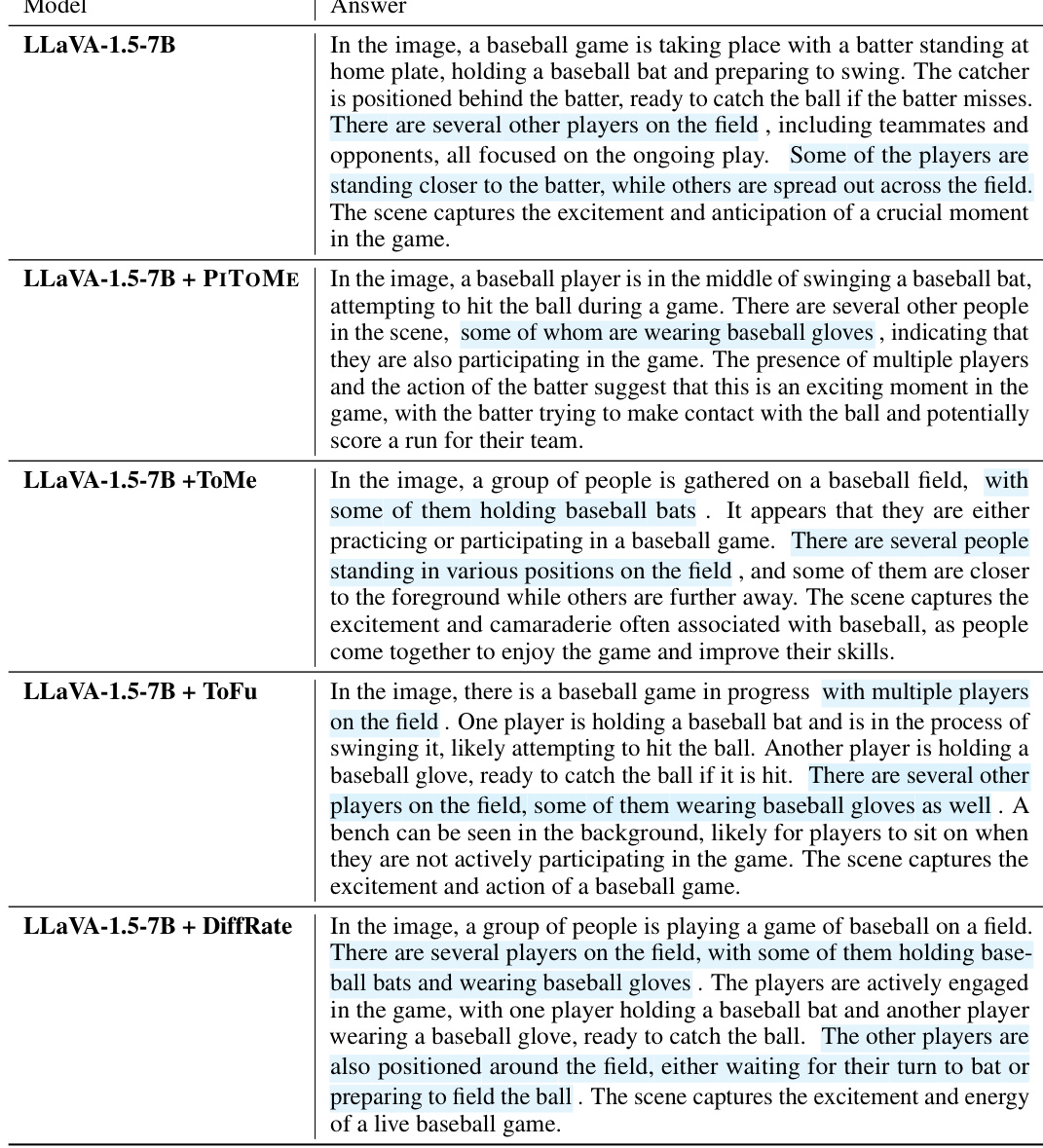
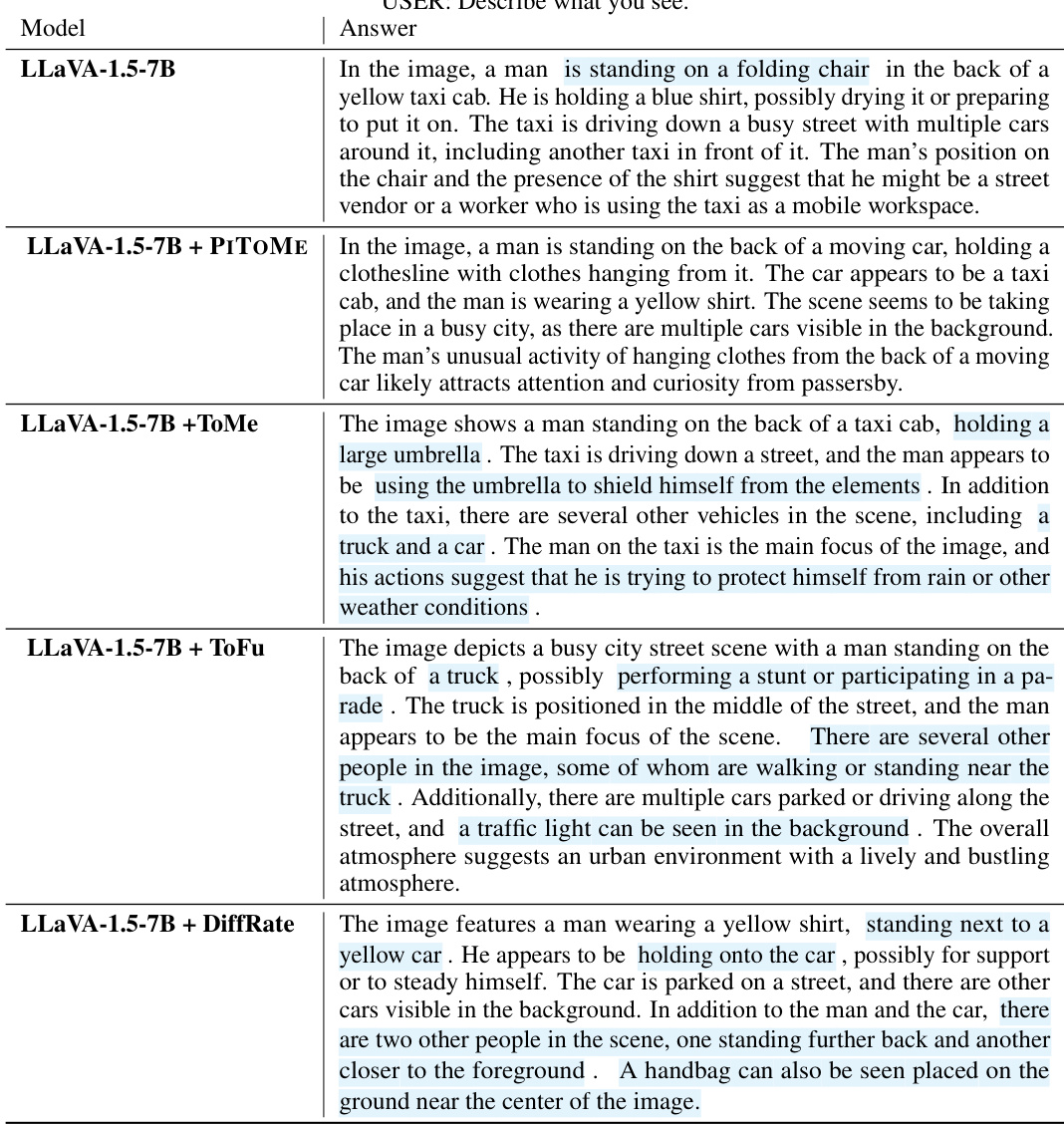
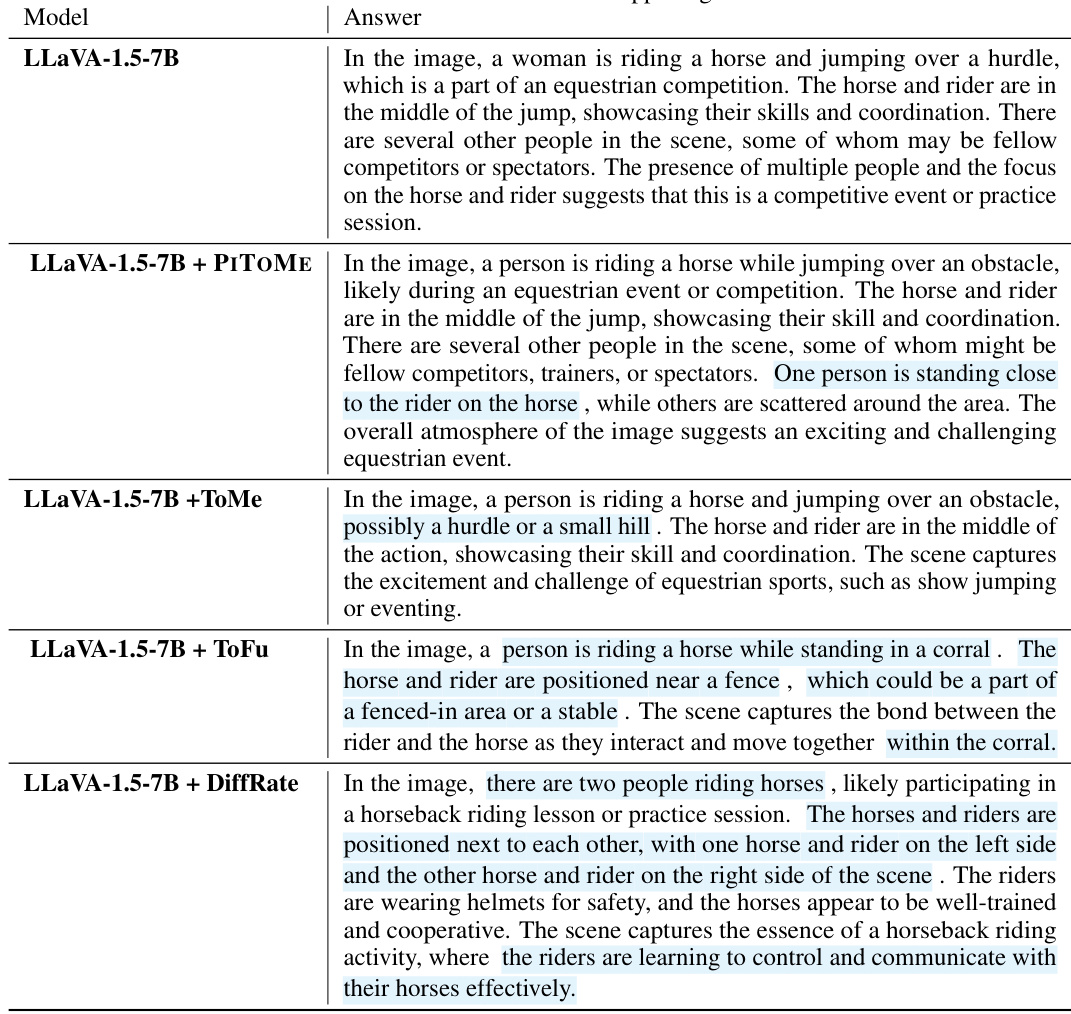
This figure compares four different token merging methods: ViT-base 384 (original), PITOME (proposed method), ToMe, and DiffRate. Each method is visualized using a color-coded representation of merged image patches. The green arrows highlight instances where ToMe and DiffRate incorrectly merge dissimilar tokens, a problem avoided by PITOME. PITOME preserves the relative positions of tokens with high attention scores (indicated by cyan borders) better than the alternative methods, thus maintaining a more accurate representation of the original image.
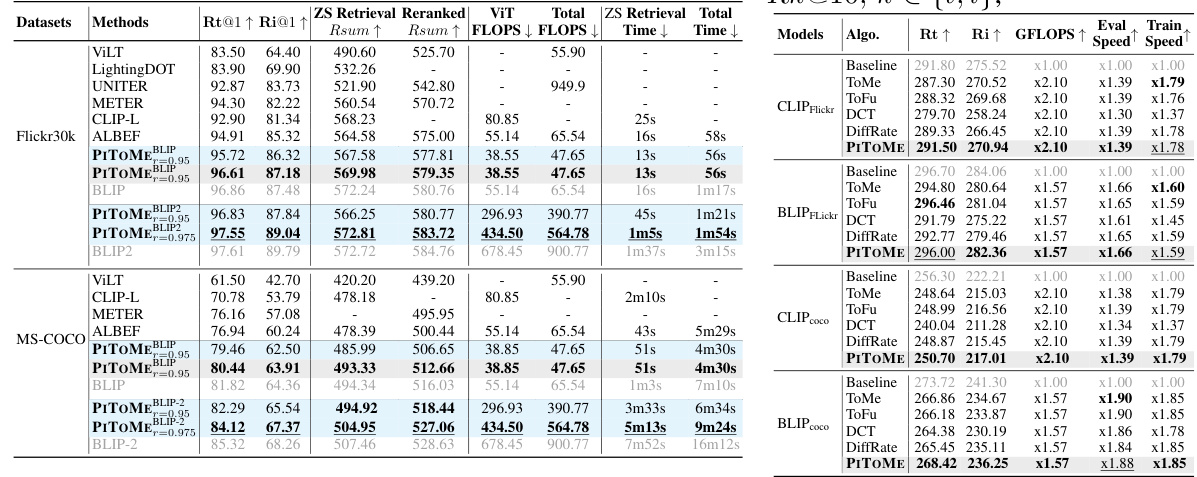
This table presents a comparison of the image-text retrieval performance of PITOME against other state-of-the-art methods on Flickr30k and MSCOCO datasets, using different backbone models (CLIP, ALBEF, BLIP). It shows Recall@k scores (a measure of retrieval accuracy), FLOPS (floating point operations - a measure of computational cost), and speed improvements. Results are shown both for off-the-shelf (no retraining) and retrained models. PITOME consistently achieves top performance with significant reductions in computational cost and improved speed.
In-depth insights#
Token Merge Methods#
Token merging methods aim to accelerate Transformer models by reducing computational costs. Early methods, like those based on Bipartite Soft Matching (BSM), focused on merging similar tokens, but suffered from sensitivity to token splitting strategies and the risk of merging informative tokens. PITOME addresses these drawbacks by introducing an energy score, prioritizing the preservation of informative tokens. This approach, inspired by spectral graph theory, identifies large clusters of similar tokens as high-energy and suitable for merging, preserving low-energy, unique tokens. The theoretical underpinnings of PITOME demonstrate its ability to preserve spectral properties of the original token space, ensuring that the merging operation doesn’t significantly distort the information encoded in the token representations. Unlike methods requiring retraining, PITOME offers a more efficient, plug-and-play approach for accelerating Transformer performance.
PITOME Algorithm#
The PITOME algorithm is a novel token merging approach designed to accelerate vision transformers while preserving crucial information. Unlike previous methods that rely heavily on simple similarity metrics, PITOME incorporates an energy score that identifies informative tokens, prioritizing their retention during the merging process. This energy score leverages spectral graph theory, analyzing token clusters to distinguish between high-energy (redundant) and low-energy (informative) groups. The algorithm then uses a weighted average to merge similar high-energy tokens, effectively reducing computational costs while aiming to maintain model accuracy. A key advantage is its robustness to various token splitting strategies, a common weakness of other token merging methods. Theoretical analysis suggests that PITOME maintains spectral properties of the original token space, further supporting its effectiveness. The method is particularly effective in later layers of the transformer, where merging less important tokens poses a lower risk of harming performance.
Spectral Insights#
A section titled “Spectral Insights” in a research paper would likely delve into the mathematical analysis of the proposed method, focusing on its effects in the frequency domain. This might involve demonstrating how the algorithm preserves or modifies the spectral properties (eigenvalues and eigenvectors) of the input data. The key insight would be to establish a connection between the algorithm’s actions in the spatial domain (e.g., token merging) and its implications in the spectral domain. This connection could be formally proven through theorems and lemmas, highlighting the algorithm’s ability to maintain specific spectral characteristics while accelerating computations. The analysis would likely draw upon concepts from spectral graph theory and linear algebra, potentially showing the robustness of the method to noise or variations in the input. A crucial aspect would be to compare the spectral properties of the original data and the processed data, quantifying the level of preservation achieved. By revealing these spectral properties, this section would solidify the theoretical grounding of the proposed algorithm, demonstrating its effectiveness and providing a deeper understanding of its behavior beyond empirical observations.
Experiment Results#
A thorough analysis of the ‘Experiment Results’ section would involve a critical examination of the methodologies used, the datasets employed, and the metrics chosen to evaluate performance. Detailed descriptions of the experimental setup, including hyperparameters, training procedures, and hardware specifications, are crucial for reproducibility. The presentation of results should be clear and concise, using appropriate visualizations such as graphs and tables to effectively communicate key findings. Statistical significance should be rigorously assessed and reported, along with error bars or confidence intervals to demonstrate the reliability of results. Furthermore, a discussion on the limitations and potential biases associated with both the methodology and datasets is important, adding robustness to the reported findings. Comparisons to related works or state-of-the-art approaches must be presented to put the findings in context and establish the novelty of the research. Finally, a careful interpretation of results is needed, avoiding overstated claims and acknowledging any unexpected observations or limitations encountered during the experimentation process. The overall quality and depth of the analysis of experimental results significantly impact the credibility and potential impact of the research paper.
Future Works#
The ‘Future Works’ section of a research paper on accelerating transformers offers exciting avenues for investigation. Extending PITOME to generative tasks like image generation or segmentation is crucial, requiring the development of an effective unmerging mechanism in the decoder. Addressing the computational complexity of the energy score function by exploring sparse graph constructions for large inputs is essential for scalability. A promising area is developing a differentiable learning mechanism to automatically optimize the token merging rate (r), thus enhancing robustness and performance. Finally, rigorous experimentation across diverse downstream tasks and deeper investigation into the theoretical guarantees of spectral preservation are vital to validate the broader applicability and efficacy of the proposed method.
More visual insights#
More on figures
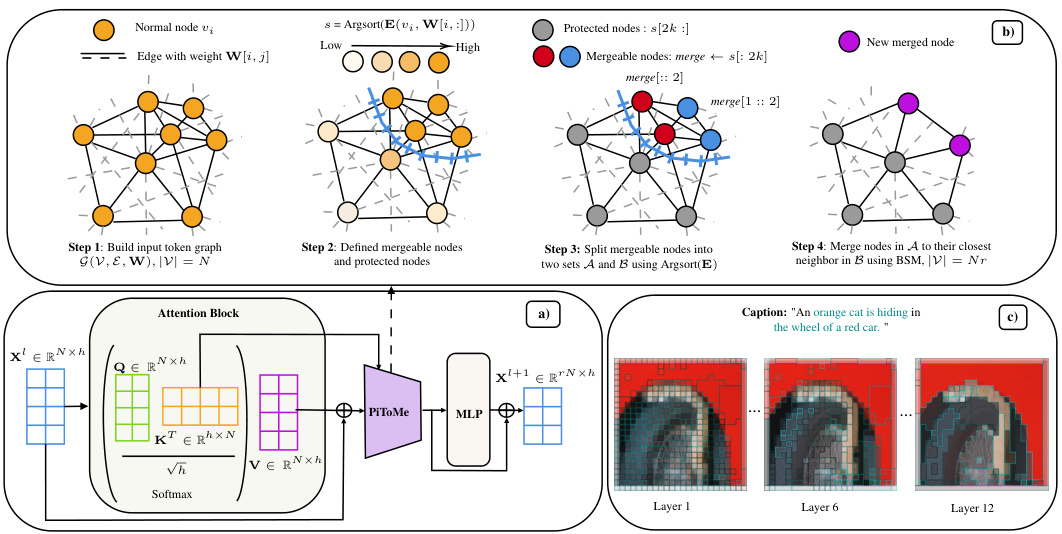
This figure illustrates the PITOME algorithm’s integration into a transformer block (a), the process of identifying mergeable and protective tokens using energy scores (b), and the gradual merging of tokens within each block (c). Panel (a) shows PITOME’s placement within the transformer architecture. Panel (b) details the steps involved in assigning energy scores to tokens, identifying mergeable and protected tokens, and then splitting the mergeable tokens into two sets (A and B) for merging using the Bipartite Soft Matching (BSM) algorithm. Panel (c) visually demonstrates the merging of tokens across different layers of the ViT architecture.

This figure compares the performance of PITOME against other merging/pruning methods on image-text retrieval tasks using various backbones. The x-axis represents the number of floating-point operations (FLOPS), and the y-axis represents the recall sum (sum of recall@1, recall@5, and recall@10 for both image and text retrieval). The plot shows that PITOME consistently outperforms other methods across different backbones and datasets, achieving near-perfect recall scores while maintaining a smaller FLOPS count.
This figure compares the performance of PITOME against other merging and pruning methods on image-text retrieval tasks. It shows Recall@k scores (k=1,5,10 for both images and texts) for different models (CLIP, ALBEF, BLIP) and datasets (Flickr30k and MS-COCO) with varying FLOPS. The recall sum is used as an overall performance measure, with higher values representing better performance. The plots demonstrate that PITOME consistently outperforms other methods, especially as the number of merged tokens increases (lower FLOPS).
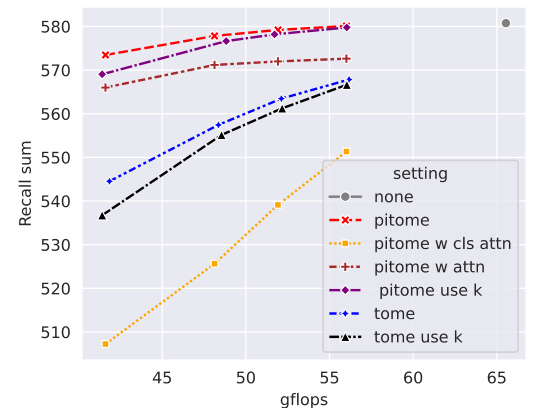
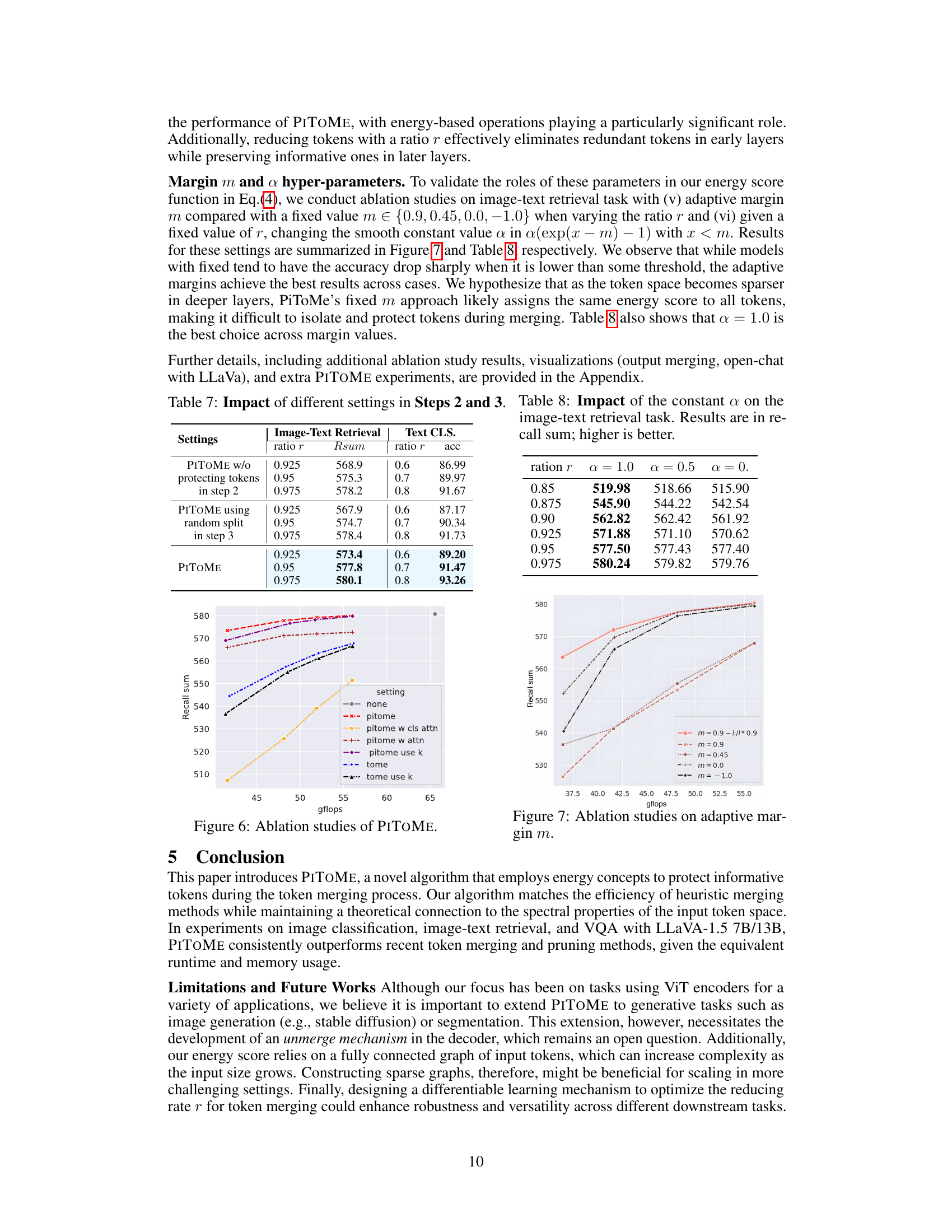
The figure shows the ablation study results for PITOME, comparing its performance against various settings. Specifically, it compares PITOME against versions that do not protect informative tokens, utilize random token splitting instead of energy-based ordering, use attention scores instead of the proposed energy score, and use a fixed number of removed tokens per layer instead of a ratio. The x-axis represents the number of GFLOPs used, while the y-axis represents the recall sum. The plot demonstrates the contribution of each component to PITOME’s performance.

This figure compares the performance of PITOME against other token merging and pruning methods on three different backbones for image-text retrieval task. The x-axis represents the number of floating point operations (gflops), and the y-axis represents the recall sum which is a metric showing the effectiveness of the models in image-text retrieval. The curves indicate that PITOME consistently outperforms the others, achieving almost perfect recall scores across different models and datasets.
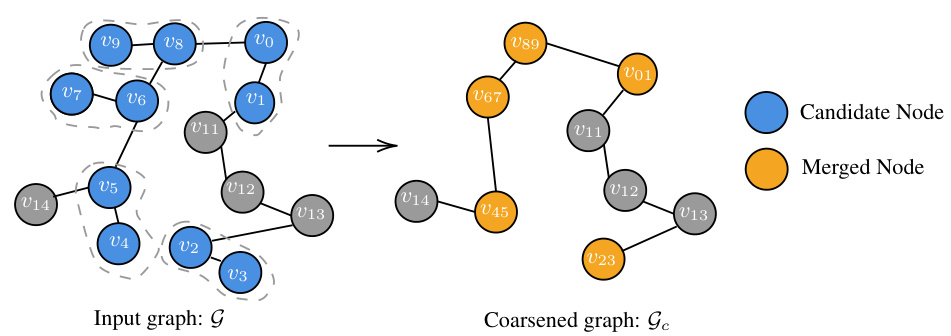
This figure illustrates the process of token merging as a graph coarsening operation. The input graph G shows individual tokens (nodes) and their relationships (edges). The tokens highlighted in blue are considered as ‘candidate nodes’ for merging, while gray nodes are less important or unique. After the merging process, as shown in the coarsened graph Gc, several candidate nodes are merged into a new node (orange), which effectively summarizes the information from the merged nodes, resulting in a smaller, more concise graph representation of the original token space.

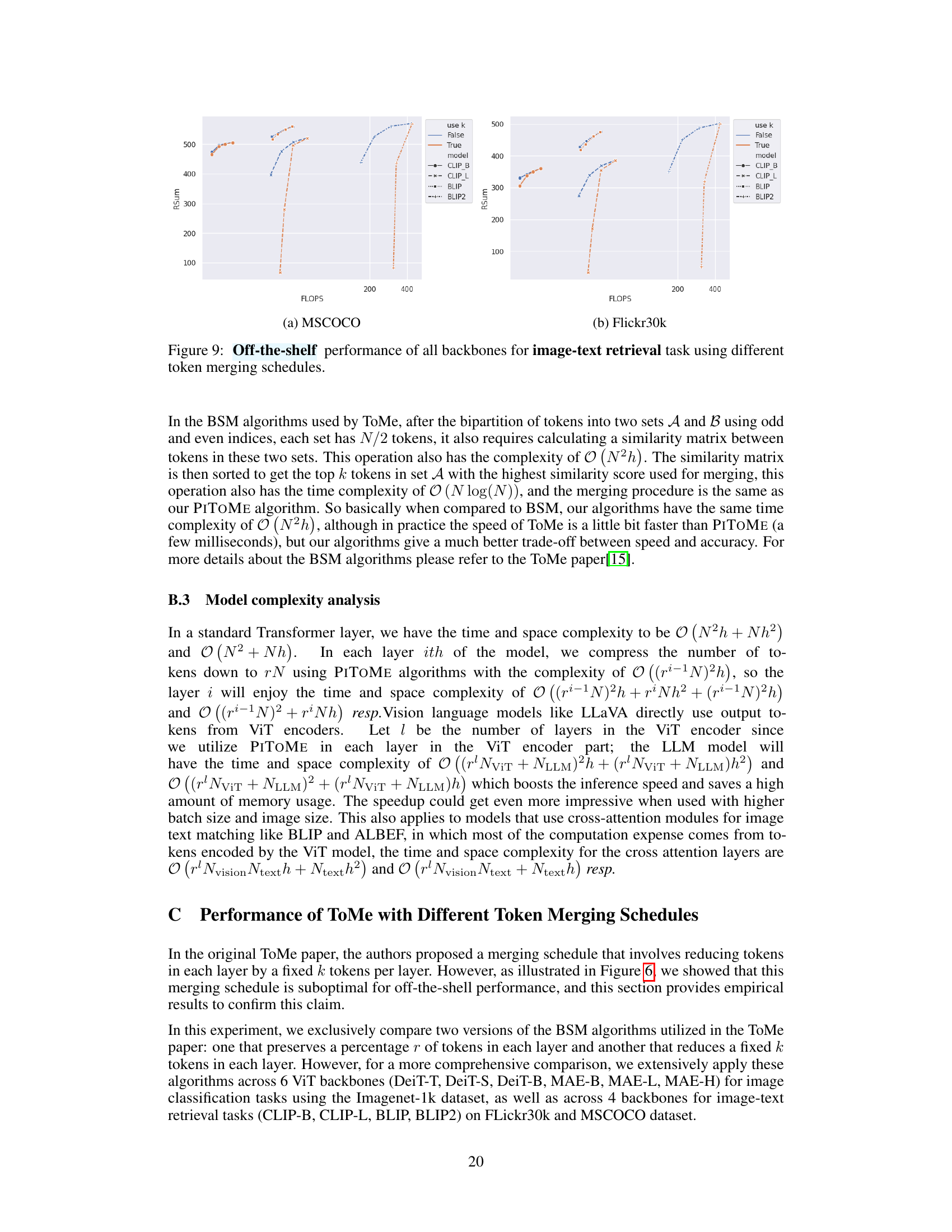
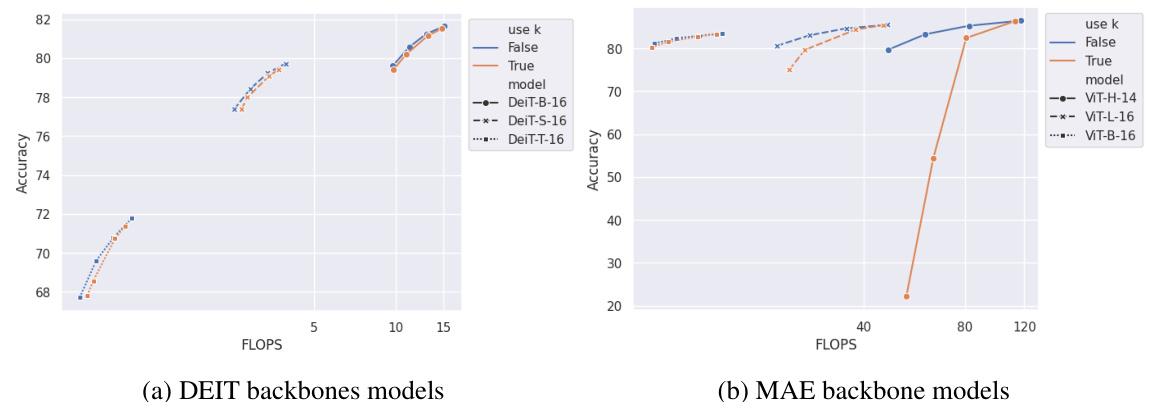
This figure compares the performance of different token merging schedules on image-text retrieval tasks using various backbones (CLIP-B, CLIP-L, BLIP, BLIP2). It shows the Recall sum (a metric combining recall@1, recall@5, and recall@10 for both image and text retrieval) against the number of floating point operations (FLOPS). The comparison highlights the impact of using a fixed number of tokens to merge versus using a ratio to determine the number of tokens to merge across layers. It suggests that using a ratio-based approach is superior for off-the-shelf performance in most cases.
This figure compares different token merging methods, highlighting the advantages of PITOME. It shows how PITOME avoids incorrect merges and preserves tokens with high attention scores, unlike other methods. The visualization uses color-coded patches to represent merged tokens.
This figure compares different token merging methods: PITOME, ToMe, and DiffRate. Each method’s output is visualized on a sample image, with patches of the same color representing merged tokens. Green arrows indicate incorrect merges avoided by PITOME. The figure highlights that PITOME, unlike other methods, preserves the spatial relationship and attention scores of the tokens, achieving similar results to a standard ViT-base 384 model. This suggests PITOME is superior because it avoids merging important tokens.

This figure compares different token merging methods, highlighting the advantages of PITOME. It shows how different algorithms merge similar image patches (represented by color), with green arrows indicating incorrect merges that PITOME avoids. The figure also demonstrates that PITOME maintains the relative positions of important tokens, shown by cyan borders, offering better proportionality compared to other methods.

This figure compares three different token merging methods: PITOME, ToMe, and DiffRate. Each method is shown applied to the same image, represented as a grid of patches. Patches of the same color indicate that those patches have been merged together by the algorithm. Green arrows point out instances where ToMe and DiffRate incorrectly merged patches, while PITOME avoids these mistakes. The cyan borders highlight patches with high attention scores. PITOME is shown to preserve the relative positions of these high-attention score patches more accurately than the other methods, mimicking the ViT-base 384 model.

This figure compares different token merging methods: PITOME, ToMe, and DiffRate. Each method is applied to the same image, and the resulting merged token patches are color-coded. Green arrows highlight instances where ToMe and DiffRate incorrectly merge patches that are visually distinct, a problem avoided by PITOME. PITOME successfully preserves important tokens with high attention scores (shown with cyan borders), maintaining image structure more closely than the other methods.

This figure compares different token merging methods: PITOME, ToMe, and DiffRate. It highlights how PITOME avoids incorrect merges (shown by green arrows) and preserves the positional information of important tokens (those with high attention scores, indicated by cyan borders) better than the other methods. The result from PITOME is more similar to the original ViT-base 384 model.

This figure compares different token merging methods: PITOME, ToMe, and DiffRate. It highlights the effectiveness of PITOME in preserving the positional information of important tokens (high attention scores) while avoiding incorrect merges, unlike the other methods. The color-coding shows which image patches are merged together by each algorithm.

This figure compares different token merging methods, highlighting the advantages of PITOME (ours) over existing methods like ToMe and DiffRate. PITOME avoids incorrect merging and preserves tokens with high attention scores, demonstrating its ability to maintain more of the original information.

This figure compares token merging methods: PITOME, ToMe, and DiffRate. Different colors represent groups of merged tokens. Green arrows show incorrect merges made by ToMe and DiffRate, which PITOME avoids. Cyan borders highlight tokens with high attention scores; PITOME preserves their positions better than the other methods, maintaining a spatial structure similar to the original ViT-base 384.

This figure compares different token merging methods, highlighting PITOME’s advantage in accuracy. Different color patches represent merged tokens. Green arrows point out incorrect merges in other methods which are avoided by PITOME, while the preservation of tokens with high attention scores (cyan borders) shows PITOME’s proportionality to ViT-base 384.
More on tables
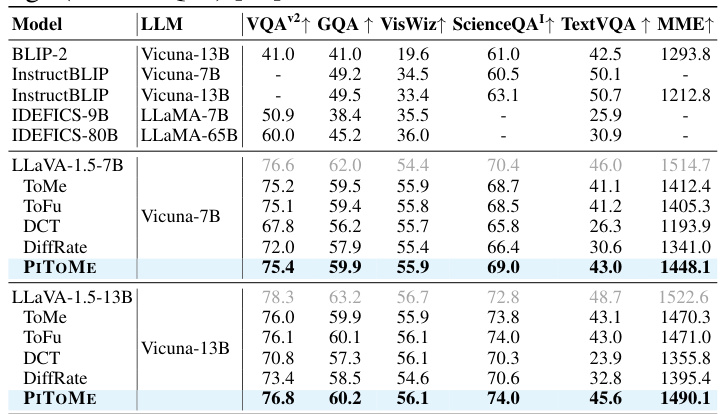
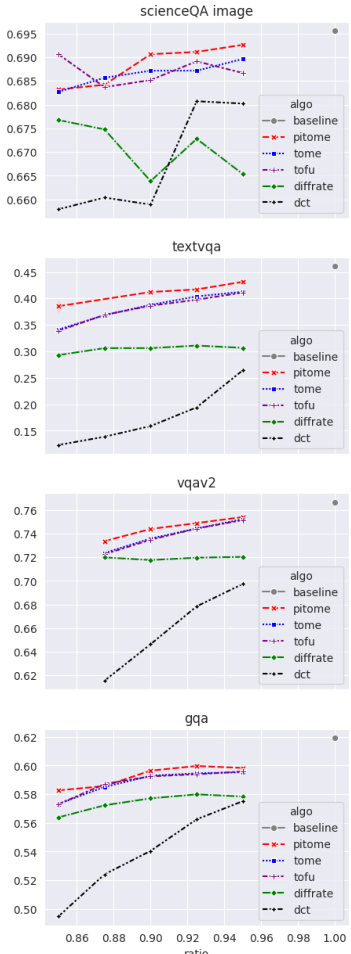
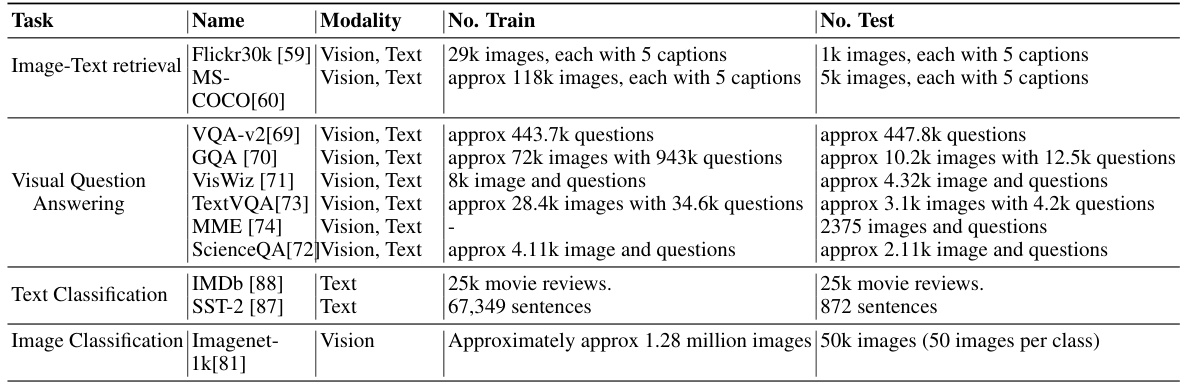
This table compares the off-the-shelf performance of the PITOME algorithm against several baseline methods on six different visual question answering (VQA) datasets. The results show the accuracy scores obtained using two different LLAVA models (LLaVA-1.5-7B and LLaVA-1.5-13B) before and after applying various token merging techniques. The performance is measured across various metrics relevant for VQA datasets.
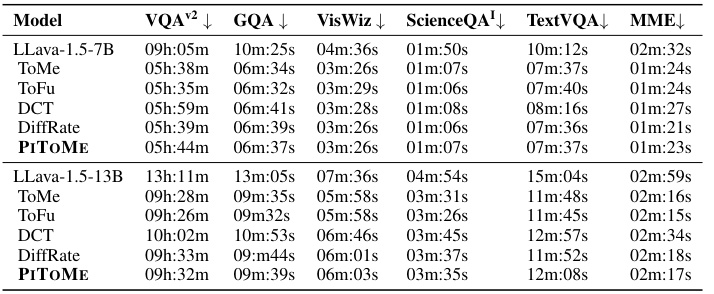
This table presents the inference time of two different sizes of LLaVA models (LLaVA-1.5-7B and LLaVA-1.5-13B) when performing visual question answering tasks. The inference times are measured using both V100 and A100 GPUs for various VQA datasets including VQA-v2, GQA, VizWiz, ScienceQA, TextVQA, and MME. The table shows the model’s inference speed across different datasets and hardware configurations. The results highlight the effect of model size and GPU type on the inference time.
This table presents a comparison of the performance of PITOME against other state-of-the-art methods for image classification on the ImageNet-1k dataset. The comparison includes both off-the-shelf performance (without retraining) and performance after retraining. Different ViT backbones (ViT-T, ViT-S, ViT-B, ViT-L, ViT-H) are used, along with other advanced architectures and merging/pruning methods. The table shows accuracy, FLOPs (floating point operations), and training speedup for each model.
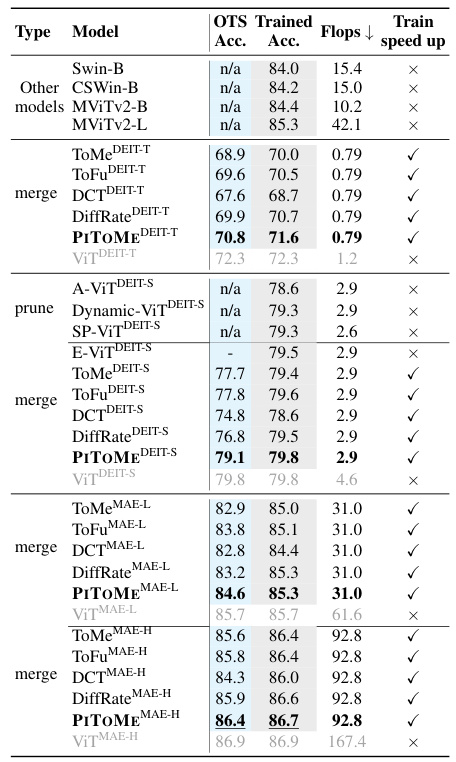
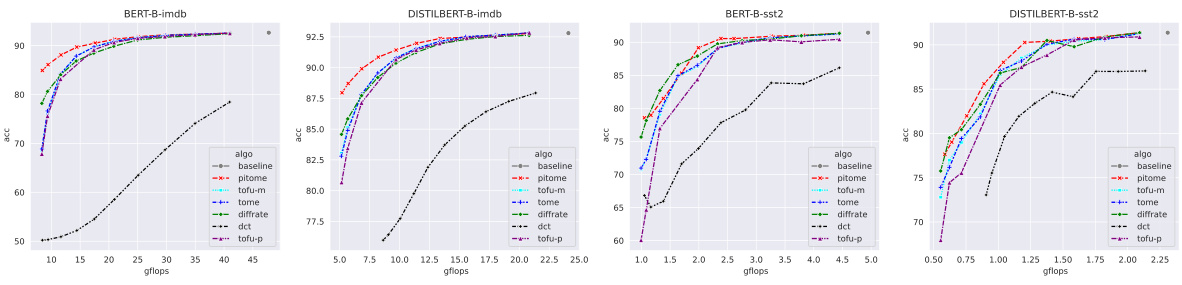
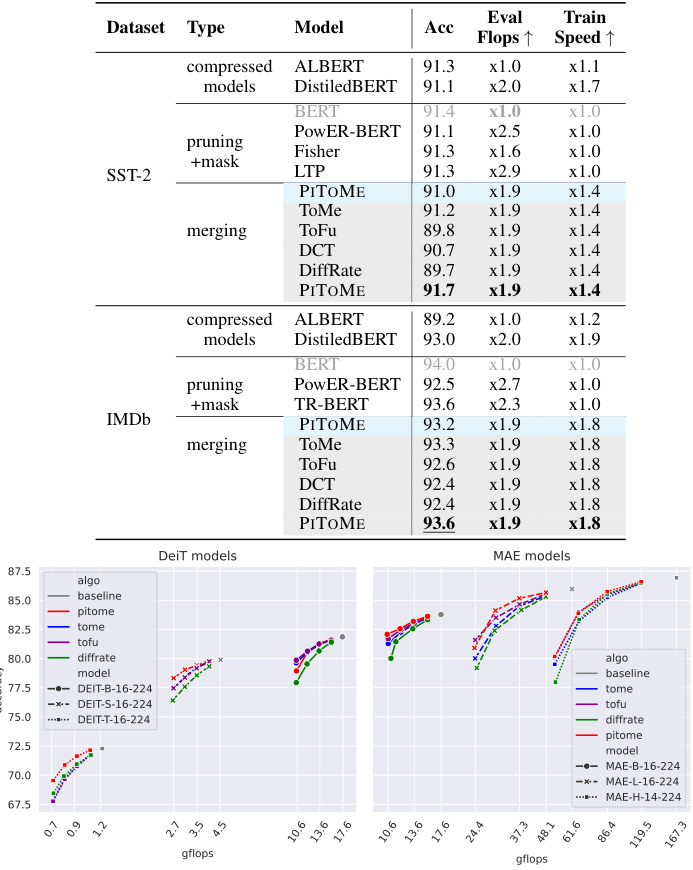
This table presents a comparison of PITOME’s performance against other state-of-the-art methods for image classification on the ImageNet-1k dataset using various ViT backbones. It shows both the off-the-shelf accuracy and accuracy after retraining, along with the FLOPs (floating-point operations) and speed-up achieved by each method. The table is organized by ViT backbone type and then by the different methods including ToMe, ToFu, DiffRate, and PITOME. The results highlight PITOME’s superior performance in terms of accuracy and FLOPs reduction with minimal performance degradation compared to other methods. It also demonstrates that PITOME training is faster than its counter parts.
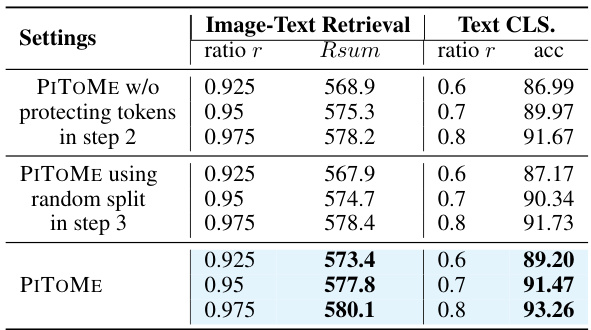
This table presents the ablation study results for the PITOME algorithm. It shows the impact of removing the token protecting step (Step 2) and using random split in the merging step (Step 3) on the performance of image-text retrieval and text classification tasks. The results are evaluated using Recall Sum for image-text retrieval and accuracy for text classification, with different ratios of remaining tokens (r). The table demonstrates that both steps are crucial for PITOME’s performance and that using a random split instead of an ordered approach significantly reduces performance.

This table presents the ablation study results on the impact of the constant ( \alpha ) on the performance of the proposed PITOME algorithm for image-text retrieval. Different values of ( \alpha ) (1.0, 0.5, and 0.0) are tested with varying ratios ( r ) of remaining tokens. The recall sum, which is the sum of recall@1, recall@5, recall@10 for both image and text retrieval, is used as the evaluation metric. Higher recall sum indicates better performance. The results show the impact of the smoothing constant ( \alpha ) on the algorithm performance for various token compression ratios.
This table presents the results of image-text retrieval experiments using three different backbone models (CLIP, ALBEF, and BLIP) on two datasets (Flickr30k and MSCOCO). It compares the performance of PITOME (both with and without retraining) against other state-of-the-art merging or pruning methods. The metrics used are Recall@k (R@1, R@5, R@10, and Ri@1, Ri@5, Ri@10), FLOPS, and speedup. The results show PITOME outperforms other methods while significantly reducing FLOPS and improving speed.

This table presents the performance comparison of PITOME with and without retraining on image-text retrieval tasks using various models (CLIP, BLIP, ALBEF) and datasets (Flickr30k, MSCOCO). The results show that PITOME significantly outperforms the baselines in terms of recall metrics (R@1, R@5, R@10), while achieving substantial reductions in FLOPS and inference times, demonstrating its efficiency in accelerating the retrieval process.
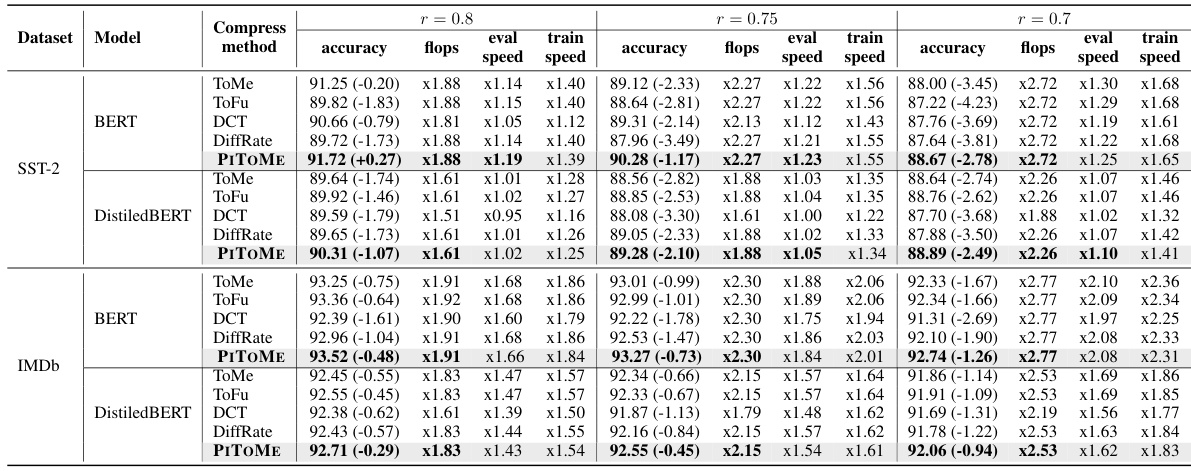
This table presents a comparison of the performance of PITOME against several baseline algorithms in text classification tasks using two different models (BERT and DistilBERT) and two datasets (SST-2 and IMDB). It shows the accuracy, FLOPS (floating-point operations), and speedup achieved by each method with different compression ratios (r=0.8, r=0.75, r=0.7). The results demonstrate PITOME’s improved performance and efficiency compared to other approaches.
This table compares the performance of PITOME against other state-of-the-art methods for image-text retrieval tasks using various models (CLIP, ALBEF, BLIP) on two datasets (Flickr30k and MSCOCO). The results highlight PITOME’s superior performance (achieving state-of-the-art results) while significantly reducing computational cost (FLOPS) and inference time. It shows results for both off-the-shelf (no retraining) and retrained models, demonstrating improvements in both scenarios.
This table compares the performance of PITOME against other state-of-the-art methods on image-text retrieval tasks using different backbone models (CLIP, ALBEF, BLIP). It shows the recall@k (a measure of retrieval accuracy), FLOPS (floating-point operations, reflecting computational cost), and speedup achieved by each method. The results highlight PITOME’s superior performance and efficiency gains in both off-the-shelf and retrained scenarios.
This table presents the results of image-text retrieval experiments using three different backbone models (CLIP, ALBEF, and BLIP) on two datasets (Flickr30k and MSCOCO). It compares the performance of PITOME (both with and without retraining) against other state-of-the-art methods. The metrics used are recall@k, FLOPS (floating-point operations), and speedup. The results demonstrate PITOME’s superior performance and efficiency gains compared to the base models and other existing methods.
Full paper#