TL;DR#
Choosing the right large language model (LLM) for a given task is crucial, but current methods usually require a lot of labeled training data. This is a major limitation since obtaining such data can be expensive and time-consuming. This paper addresses this problem by proposing a novel approach called SMOOTHIE.
SMOOTHIE offers a solution by using a weak supervision-inspired approach that doesn’t need any labeled data. It works by creating a model that analyzes the outputs from different LLMs and figures out which one performed best on each specific task. The researchers showed that their method not only improves accuracy in LLM selection but also gives quality scores that are strongly related to the actual performance of the models, a significant achievement in this field.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SMOOTHIE, a novel approach to LLM routing that doesn’t require labeled data for training, a significant improvement over existing methods. This addresses a major challenge in deploying LLMs for diverse tasks and opens up new possibilities for unsupervised LLM management and optimization. It also demonstrates that high-quality LLM selection is possible without human annotation, potentially saving significant time and resources in real-world applications.
Visual Insights#
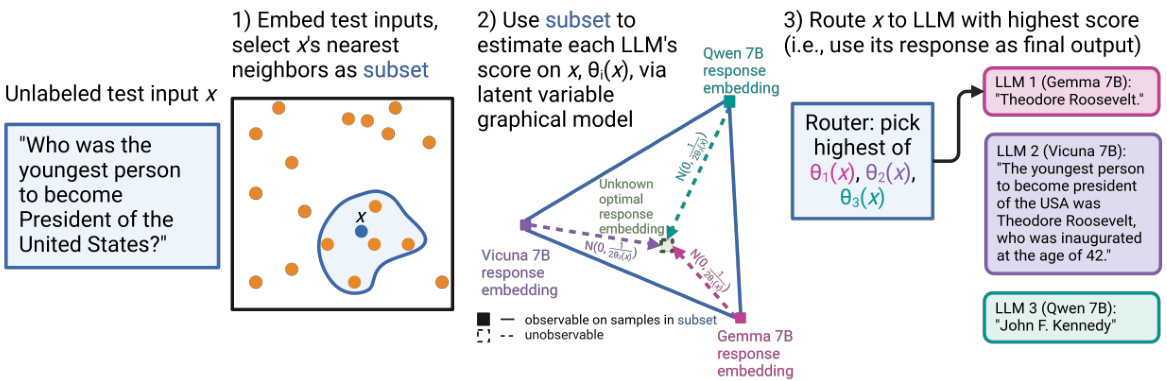
🔼 This figure illustrates the SMOOTHIE algorithm’s three main steps. First, the input text is embedded into a vector space. Then, a subset of similar samples (nearest neighbors) is selected to estimate the quality score of each LLM using a latent variable graphical model. Finally, the input text is routed to the LLM with the highest quality score, and its generated output is returned.
read the caption
Figure 1: For a given input x, SMOOTHIE estimates the quality of every LLM ensemble's generation, and uses this quality weight to route x to a single LLM.
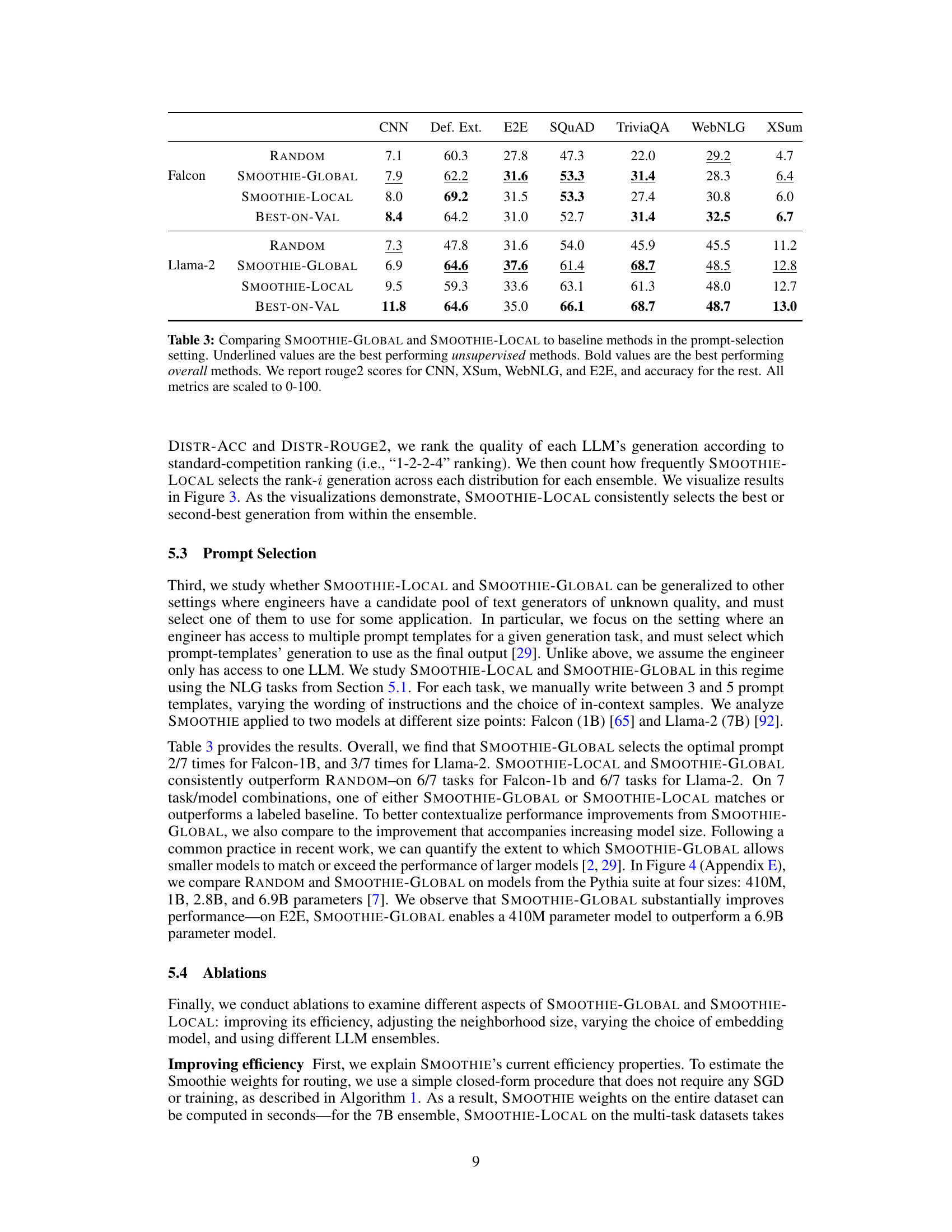
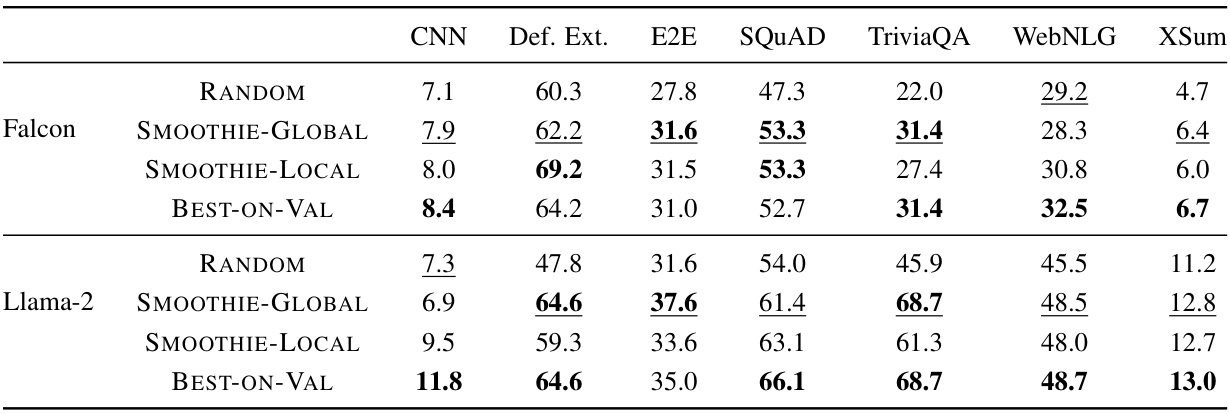
🔼 This table compares the performance of SMOOTHIE-GLOBAL against a random baseline and a best-performing model selected using a small labeled validation set across seven different natural language generation (NLG) tasks, using two different ensembles of LLMs (3B and 7B parameter models). The results show SMOOTHIE-GLOBAL’s ability to identify high-performing LLMs without using labeled data, frequently matching or exceeding the performance of the model selected using labeled data. Metrics are scaled to 0-100 for easy comparison.
read the caption
Table 1: Comparing SMOOTHIE-GLOBAL to baseline methods on different ensembles across NLG datasets. Underlined values are the best performing unsupervised methods. Bold values are the best performing overall methods. We report rouge2 scores for CNN, XSum, WebNLG, and E2E, and accuracy for the rest. All metrics are scaled to 0-100.
In-depth insights#
LLM Quality Score#
The concept of “LLM Quality Score” is crucial for effective language model routing. The paper explores methods to estimate this score without labeled data, a significant challenge in the field. A key aspect is the need for a sample-conditional approach. A global quality score for an LLM might not capture its performance across various input types. Therefore, the paper proposes a latent variable graphical model to estimate sample-specific quality scores, treating the LLM outputs as “voters” on the true, unobserved output. This model allows for efficient estimation using embedding differences between the outputs and the true output, thereby capturing performance variability. A crucial element of this methodology is that it’s unsupervised, relying solely on the LLM outputs for each input, not requiring any labeled validation data. This methodology presents a valuable contribution to the field by offering a more practical and data-efficient way to route inputs to the most suitable LLMs, effectively addressing the problem of LLM selection for diverse tasks.
Routing Strategies#
Effective routing strategies in multi-capability language model (LLM) systems are crucial for optimal performance. The core challenge lies in dynamically selecting the most suitable LLM for each input sample, given that different LLMs excel at different tasks. Supervised methods, while accurate, require extensive labeled data, a significant limitation. Unsupervised approaches, such as the SMOOTHIE method described in the provided text, aim to overcome this data hurdle by leveraging latent variable models and embedding representations of LLM outputs to infer sample-dependent quality scores for each LLM. SMOOTHIE’s success highlights the potential of weak supervision techniques for effective, data-efficient LLM routing. Future research should explore alternative unsupervised methods, possibly incorporating task embeddings or more sophisticated probabilistic models to enhance routing accuracy and efficiency further. The selection of appropriate embedding techniques is also a critical aspect requiring further investigation; the choice of embeddings significantly impacts the accuracy of the quality scores. Ultimately, robust and adaptive routing strategies are essential for unlocking the full potential of diverse LLM ensembles in real-world applications.
Unsupervised Approach#
An unsupervised approach to LLM routing offers a compelling alternative to supervised methods by eliminating the need for labeled data. This significantly reduces the engineering effort and cost associated with data annotation, a major bottleneck in many machine learning applications. The core idea revolves around creating a latent variable model to infer the quality of each LLM’s output on a given sample, using only the observable LLM outputs. This usually involves techniques like weak supervision, where the outputs are treated as noisy ‘votes’ on the true, unobserved output. By modeling the distribution of embedding vector differences between LLM outputs and the estimated true output, the model can estimate sample-specific quality scores for each LLM. The inherent challenge lies in accurately estimating the quality scores without ground truth, requiring sophisticated modeling assumptions and robust estimation techniques to handle the noise inherent in LLM outputs. The routing decision is then made by selecting the LLM with the highest estimated quality score for the input sample. A key advantage is its applicability to diverse datasets and tasks, making it a more flexible and adaptable solution compared to supervised approaches that might overfit to a specific dataset or task. However, the effectiveness heavily depends on the quality of the LLM outputs and the suitability of the chosen latent variable model and embeddings. This approach might not always match the performance of supervised baselines that leverage labeled data; further research and investigation are crucial to understand its limitations and explore optimization strategies to improve its accuracy.
Model Limitations#
The paper’s findings, while promising, are limited by several key model constraints. SMOOTHIE’s reliance on a diagonal covariance matrix in its Gaussian graphical model is a simplification, neglecting potential dependencies between LLM outputs. This assumption might not hold true across all datasets and tasks, impacting the accuracy of quality score estimations. Furthermore, the approach currently disregards the computational cost of different LLMs, focusing solely on output quality. In real-world scenarios, cost-effectiveness is a crucial factor that needs to be incorporated. The method’s performance is intrinsically linked to the quality of embedding vectors; therefore, the choice of embedding model can significantly impact results. Exploration of alternative embeddings and their comparative effectiveness is necessary for a more robust and widely applicable solution. Finally, the paper highlights the possibility that SMOOTHIE’s embedding-based approach may not fully capture the semantic nuances of LLM outputs, potentially overlooking critical aspects of textual similarity. Addressing these limitations is crucial for advancing the practical application and generalizability of the unsupervised LLM routing technique.
Future Directions#
Future research could explore extending SMOOTHIE’s capabilities to handle more complex scenarios, such as those involving multiple languages or modalities. Investigating the impact of different embedding methods and exploring ways to incorporate explicit cost considerations into the routing process are also important avenues. Furthermore, a deeper understanding of how SMOOTHIE’s performance scales with the number of LLMs and the size of the dataset is crucial, along with developing methods for more efficient quality estimation. Finally, a thorough investigation into the robustness and generalizability of SMOOTHIE across diverse tasks and datasets is needed, along with a careful examination of potential biases in the generated outputs. Addressing these issues would enhance SMOOTHIE’s practical applicability and broaden its impact.
More visual insights#
More on figures

🔼 This figure presents three boxplots summarizing the performance of SMOOTHIE-GLOBAL. The leftmost boxplot (a) shows the distribution of Spearman’s rank correlation coefficients between the learned quality scores and the ground truth performance across seven different natural language generation tasks and for both 3B and 7B model ensembles. The two boxplots on the right show the distribution of win-rate improvements achieved by SMOOTHIE-GLOBAL over a random baseline for AlpacaEval. Specifically, boxplot (b) displays the standard win-rate and boxplot (c) shows the win-rate after a length control.
read the caption
Figure 2: (a) Spearman’s rank correlation coefficient between SMOOTHIE-GLOBAL weights and ground-truth LLM performance for 3B and 7B ensembles across NLG tasks. (b) SMOOTHIE-GLOBAL’s improvement over RANDOM by win-rate on AlpacaEval. (c) SMOOTHIE-GLOBAL’s improvement over RANDOM by length-controlled win-rate on AlpacaEval.
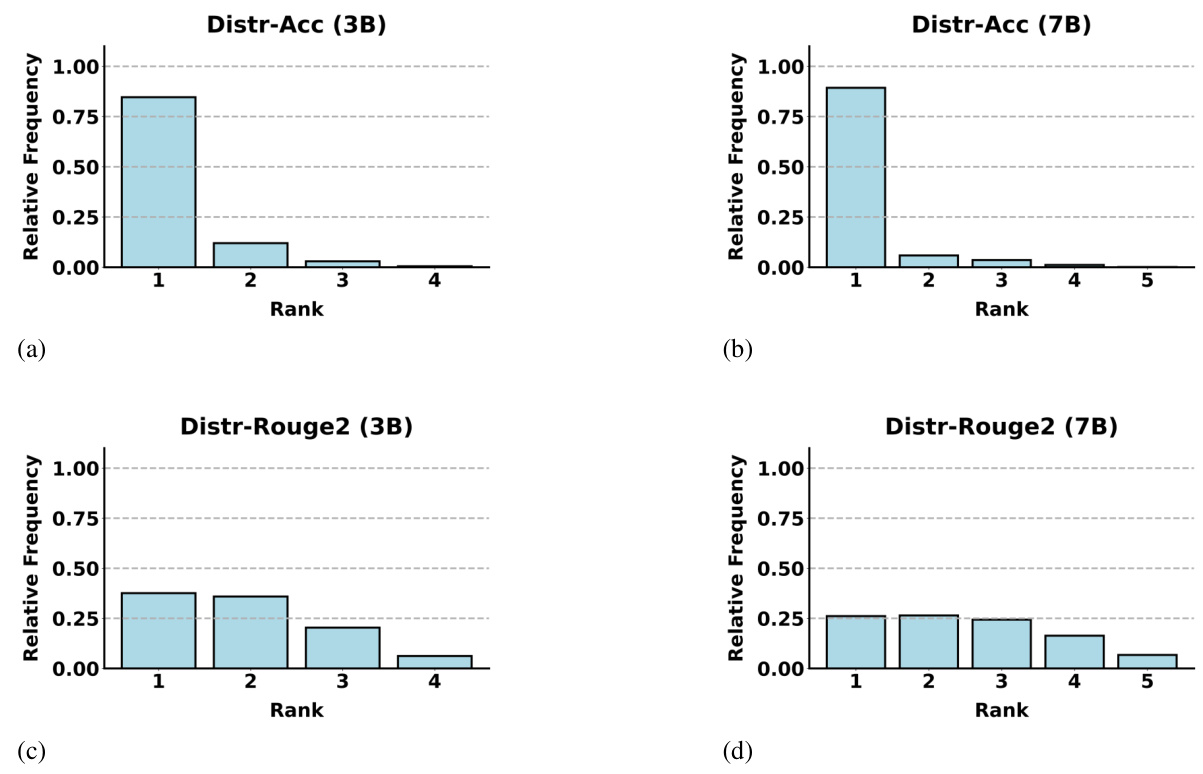
🔼 This figure shows the distribution of the rank of the LLM selected by SMOOTHIE-LOCAL for each sample in the DISTR-ACC and DISTR-ROUGE2 datasets. The x-axis represents the rank (1 being the best performing LLM), and the y-axis represents the relative frequency of selecting that rank. The figure visually demonstrates the performance of SMOOTHIE-LOCAL by showing how often it selects the highest-performing or near-highest-performing LLMs for each sample, indicating that its sample-specific scoring is effective.
read the caption
Figure 3: On DISTR-ACC and DISTR-ROUGE2, we measure how frequently SMOOTHIE-LOCAL selects the i-th best generation across the ensemble, for both the 3B and 7B ensembles.
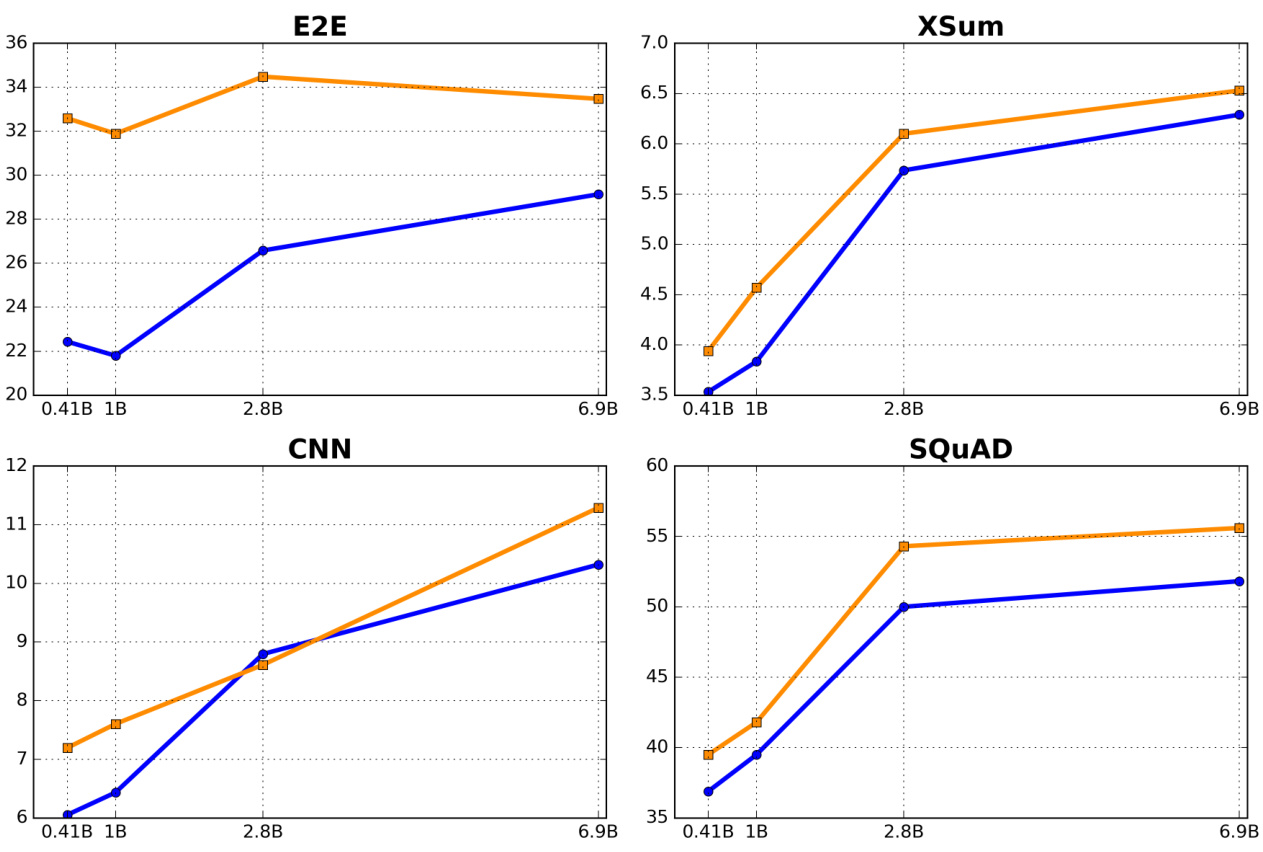
🔼 This figure compares the performance of two methods, RANDOM and SMOOTHIE-GLOBAL, for prompt selection using different sized language models from the Pythia suite. The x-axis represents the size of the language models used (0.41B, 1B, 2.8B, and 6.9B parameters), while the y-axis represents the performance achieved, measured using either ROUGE-2 scores or accuracy, depending on the specific task. The blue line shows the results for the RANDOM method, while the orange line shows the results for the SMOOTHIE-GLOBAL method. The figure helps to visualize how the performance of both methods changes with the increase in language model size across various natural language generation tasks, allowing for a direct comparison of their performance.
read the caption
Figure 4: We compare RANDOM (blue) and SMOOTHIE-GLOBAL (orange) for prompt-selection on different sized models in the Pythia suite. The x-axis denotes model size, and the y-axis denotes performance (either rouge2 or accuracy).

🔼 This figure shows the performance of SMOOTHIE-LOCAL on the DISTR-ACC dataset as a function of the neighborhood size (n0). The x-axis represents different neighborhood sizes, and the y-axis represents the accuracy score. The plot demonstrates how the accuracy changes as more or fewer nearest neighbors are considered when estimating LLM quality scores. Two lines are shown, likely representing the 3B and 7B model ensembles. It is evident that performance is highest at n0 = 1 and gradually decreases as n0 increases. This indicates the importance of considering a small, sample-specific neighborhood when making LLM quality score estimations for effective routing.
read the caption
Figure 5: We measure how SMOOTHIE-LOCAL’s performance on DISTR-ACC changes as n0 changes.
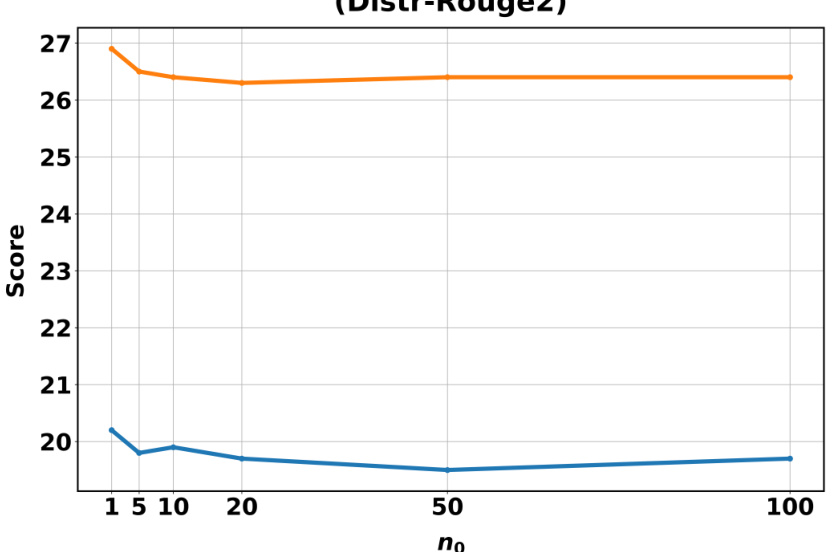
🔼 This figure shows the performance of SMOOTHIE-LOCAL on the DISTR-ROUGE2 dataset as the neighborhood size parameter (no) varies. The x-axis represents different values of no, and the y-axis shows the corresponding score. The figure illustrates how the model’s performance is affected by the number of nearest neighbors considered during the quality score estimation. Different line colors may represent different model sizes or configurations.
read the caption
Figure 6: We measure how SMOOTHIE-LOCAL’s performance on DISTR-ROUGE2 changes as no changes.

🔼 This figure shows a histogram visualizing the ranks of the language models (LLMs) selected by the SMOOTHIE-GLOBAL method across various natural language generation (NLG) tasks. The data is broken down by two different ensemble sizes (3B and 7B parameter LLMs), highlighting the frequency with which SMOOTHIE-GLOBAL selects the top-ranked, second-ranked, and so on, LLMs. The distribution indicates how often SMOOTHIE-GLOBAL accurately identifies the highest performing model.
read the caption
Figure 8: We construct a histogram over the rank of the LLM selected by SMOOTHIE-GLOBAL across both the 3B and 7B ensembles, for 7 NLG tasks.
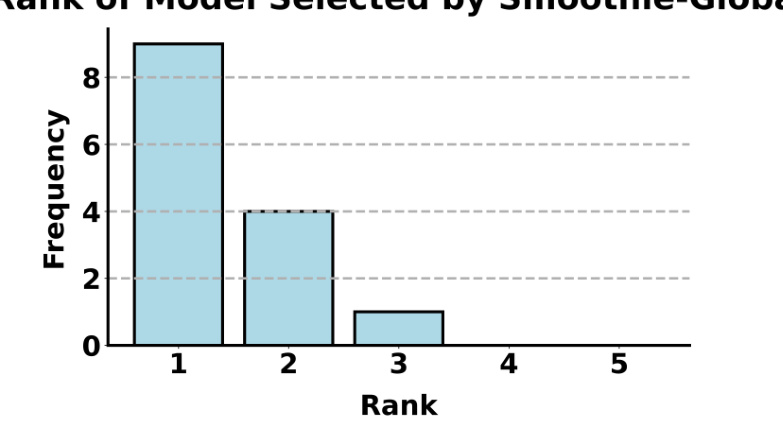
🔼 This figure shows the distribution of the ranking of the LLM selected by SMOOTHIE-GLOBAL across 7 different NLG tasks for both the 3B and 7B ensembles of LLMs. The x-axis represents the rank of the selected LLM (1 being the best-performing LLM in the ensemble for a task), while the y-axis shows the frequency of that rank appearing across the 7 tasks. The distribution is heavily weighted toward rank 1, indicating that SMOOTHIE-GLOBAL frequently selects the best-performing LLM in the ensemble.
read the caption
Figure 8: We construct a histogram over the rank of the LLM selected by SMOOTHIE-GLOBAL across both the 3B and 7B ensembles, for 7 NLG tasks.
More on tables

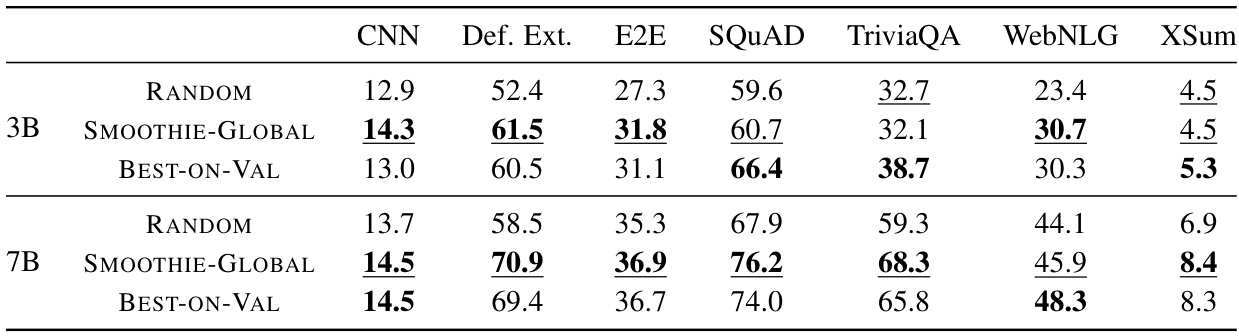
🔼 This table compares the performance of SMOOTHIE-LOCAL against several baseline methods (RANDOM, PAIRRM, LABELED-KNN, BEST-MODEL, SMOOTHIE-GLOBAL) on two multi-task datasets (DISTR-ACC, DISTR-ROUGE2) using two different ensembles of LLMs (3B and 7B). The results show SMOOTHIE-LOCAL’s superior performance, even surpassing supervised methods.
read the caption
Table 2: Comparing SMOOTHIE-LOCAL to baseline methods on the 3B and 7B ensembles for multi-task distributions. DISTR-ACC and DISTR-ROUGE2 are measured with accuracy and rouge2 respectively. Bold values indicate the best performing method for each dataset and model size. Metrics are scaled to 0-100.
🔼 This table presents the results of comparing SMOOTHIE-GLOBAL and SMOOTHIE-LOCAL against baseline methods for prompt selection on different tasks. It demonstrates the performance improvement achieved by the proposed methods, especially in terms of accuracy and ROUGE-2 scores, compared to random selection and a labeled data-based baseline.
read the caption
Table 3: Comparing SMOOTHIE-GLOBAL and SMOOTHIE-LOCAL to baseline methods in the prompt-selection setting. Underlined values are the best performing unsupervised methods. Bold values are the best performing overall methods. We report rouge2 scores for CNN, XSum, WebNLG, and E2E, and accuracy for the rest. All metrics are scaled to 0-100.

🔼 This table compares the performance of SMOOTHIE-GLOBAL against other methods (random selection and a method using a small labeled validation set) on several natural language generation tasks. It shows that SMOOTHIE-GLOBAL performs competitively with or better than the methods using labeled data, even though it requires no labels for training. Performance is measured using ROUGE-2 for summarization and data-to-text tasks and accuracy for other tasks, all scaled to 0-100 for easier comparison.
read the caption
Table 1: Comparing SMOOTHIE-GLOBAL to baseline methods on different ensembles across NLG datasets. Underlined values are the best performing unsupervised methods. Bold values are the best performing overall methods. We report rouge2 scores for CNN, XSum, WebNLG, and E2E, and accuracy for the rest. All metrics are scaled to 0-100.

🔼 This table compares the performance of SMOOTHIE-GLOBAL against unsupervised and supervised baselines on seven different natural language generation (NLG) tasks. It shows the performance (rouge2 scores or accuracy) of three methods: SMOOTHIE-GLOBAL (an unsupervised method proposed in the paper), a random selection baseline (RANDOM), and a supervised baseline trained on a small validation set (BEST-ON-VAL). The results are reported for two different ensembles of LLMs (3B and 7B parameter models). The table highlights the superior performance of SMOOTHIE-GLOBAL, especially compared to the unsupervised baseline, demonstrating its effectiveness in identifying high-performing LLMs without labeled data.
read the caption
Table 1: Comparing SMOOTHIE-GLOBAL to baseline methods on different ensembles across NLG datasets. Underlined values are the best performing unsupervised methods. Bold values are the best performing overall methods. We report rouge2 scores for CNN, XSum, WebNLG, and E2E, and accuracy for the rest. All metrics are scaled to 0-100.

🔼 This table compares the performance of SMOOTHIE-GLOBAL against two baseline methods (RANDOM and BEST-ON-VAL) across seven different natural language generation (NLG) tasks using two different ensembles of LLMs (3B and 7B parameter models). It shows the accuracy or ROUGE-2 scores for each method, demonstrating the effectiveness of SMOOTHIE-GLOBAL in identifying high-performing LLMs, even without labeled data. Underlined values represent the best performance among unsupervised methods, while bold values highlight the best overall performance.
read the caption
Table 1: Comparing SMOOTHIE-GLOBAL to baseline methods on different ensembles across NLG datasets. Underlined values are the best performing unsupervised methods. Bold values are the best performing overall methods. We report rouge2 scores for CNN, XSum, WebNLG, and E2E, and accuracy for the rest. All metrics are scaled to 0-100.
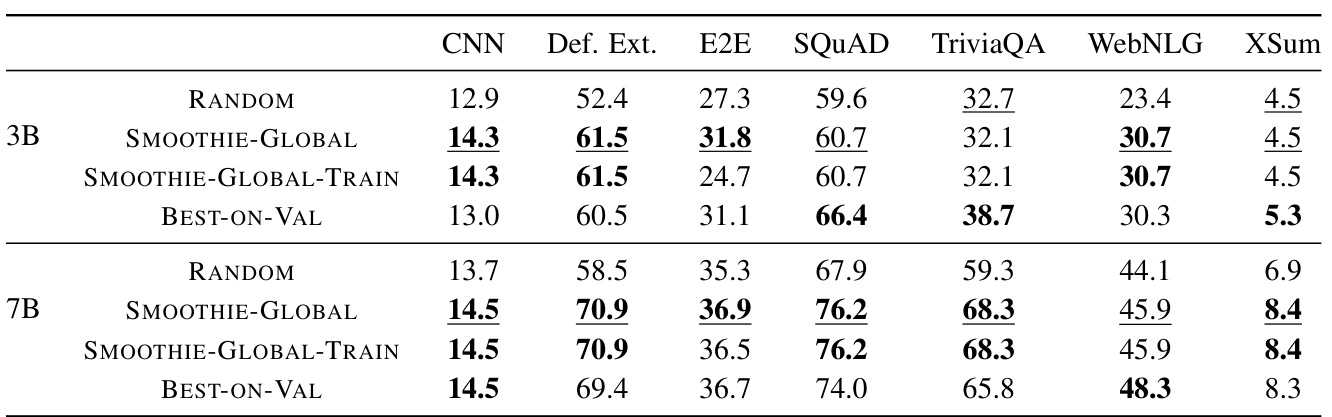
🔼 This table compares the performance of SMOOTHIE-GLOBAL against two baselines (RANDOM and BEST-ON-VAL) across seven different natural language generation (NLG) tasks. For each task, two ensembles of LLMs (one with 3B parameter models and the other with 7B parameter models) are used. The RANDOM baseline represents the average performance of the ensemble, while BEST-ON-VAL represents the performance of the best-performing model in the ensemble chosen using a small amount of labeled validation data. The table reports performance using ROUGE-2 scores for summarization and data-to-text generation tasks, and accuracy scores for all other tasks. All scores are normalized to a 0-100 scale. The best unsupervised and overall results for each task and ensemble size are highlighted.
read the caption
Table 1: Comparing SMOOTHIE-GLOBAL to baseline methods on different ensembles across NLG datasets. Underlined values are the best performing unsupervised methods. Bold values are the best performing overall methods. We report rouge2 scores for CNN, XSum, WebNLG, and E2E, and accuracy for the rest. All metrics are scaled to 0-100.
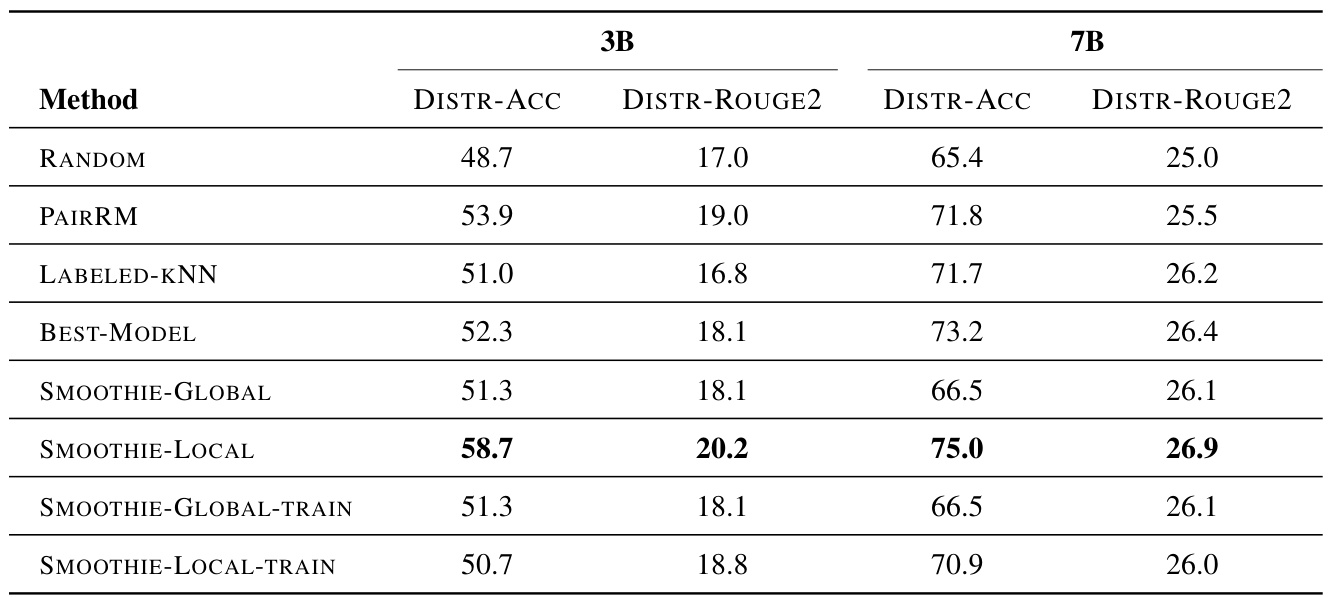
🔼 This table compares the performance of SMOOTHIE-LOCAL against several baseline methods for multi-task routing on two different ensemble sizes (3B and 7B parameters). The performance metrics used are accuracy (DISTR-ACC) and ROUGE2 score (DISTR-ROUGE2), representing different task types. The table highlights the superior performance of SMOOTHIE-LOCAL, even compared to methods that utilize labeled data.
read the caption
Table 2: Comparing SMOOTHIE-LOCAL to baseline methods on the 3B and 7B ensembles for multi-task distributions. DISTR-ACC and DISTR-ROUGE2 are measured with accuracy and rouge2 respectively. Bold values indicate the best performing method for each dataset and model size. Metrics are scaled to 0-100.

🔼 This table compares the performance of SMOOTHIE-LOCAL against several baseline methods (RANDOM, PAIRRM, LABELED-KNN, and BEST-MODEL) on two multi-task datasets (DISTR-ACC and DISTR-ROUGE2) using two different ensembles of LLMs (3B and 7B). The metrics used are accuracy (DISTR-ACC) and ROUGE2 (DISTR-ROUGE2), scaled to a 0-100 range. Bold values highlight the best-performing method in each category.
read the caption
Table 2: Comparing SMOOTHIE-LOCAL to baseline methods on the 3B and 7B ensembles for multi-task distributions. DISTR-ACC and DISTR-ROUGE2 are measured with accuracy and rouge2 respectively. Bold values indicate the best performing method for each dataset and model size. Metrics are scaled to 0-100.

🔼 This table presents the results of the MixInstruct experiment, comparing the performance of SMOOTHIE-GLOBAL against a random baseline. The metric used is the ChatGPT-Rank, a lower score indicating better performance. SMOOTHIE-GLOBAL demonstrates a significant improvement over random selection.
read the caption
Table 10: Results for SMOOTHIE-GLOBAL and baselines on MixInstruct.

🔼 This table presents the accuracy results of three different methods on the GSM8K dataset: RANDOM (randomly selecting a model), BEST-ON-VAL (selecting the best-performing model on a validation set), and SMOOTHIE-GLOBAL (the proposed method). The accuracy scores are scaled to a range of 0-100 for easier comparison. The results show the relative performance of SMOOTHIE-GLOBAL compared to baselines on a reasoning intensive task.
read the caption
Table 11: Results for SMOOTHIE-GLOBAL and baselines on GSM8K. We report accuracy, with scores scaled to 0–100.
Full paper#