TL;DR#
Deep neural networks are vulnerable to adversarial examples—inputs slightly modified to cause misclassification. Evaluating robustness to minimal adversarial perturbations is crucial but computationally expensive using current methods. Inaccurate methods also exist. This limits progress in improving robustness.
This paper introduces SuperDeepFool, a new family of attacks addressing these issues. SuperDeepFool is a generalization of DeepFool, improving accuracy and efficiency. It significantly outperforms other methods in finding minimal adversarial examples, showing its effectiveness in evaluating and enhancing model robustness via adversarial training. These improvements are achieved while maintaining simplicity, making SuperDeepFool suitable for large models and advancing state-of-the-art in adversarial training.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on adversarial robustness of deep neural networks. It introduces a novel, efficient, and accurate method for generating minimal adversarial perturbations, a crucial aspect of evaluating and improving model robustness. The proposed approach not only outperforms existing methods but also opens new avenues for adversarial training and further advancements in the field.
Visual Insights#

🔼 The figure is a scatter plot showing the trade-off between the average number of gradient computations required by different minimum-norm adversarial attack methods and the mean l2-norm of the resulting perturbations. It demonstrates that the proposed SuperDeepFool (SDF) method achieves significantly smaller perturbations than other methods (DeepFool (DF), Fast Adaptive Boundary Attack (FAB), ALMA, FMN, DDN) with a comparable or even lower computational cost, highlighting its superior efficiency and accuracy.
read the caption
Figure 1: The average number of gradient computations vs the mean l2-norm of perturbations. It shows that our novel fast and accurate method, SDF, outperforms other minimum-norm attacks. SDF finds significantly smaller perturbations compared to DF, with only a small increase in computational cost. SDF also outperforms other algorithms in optimality and speed. The numbers are taken from Table 5.

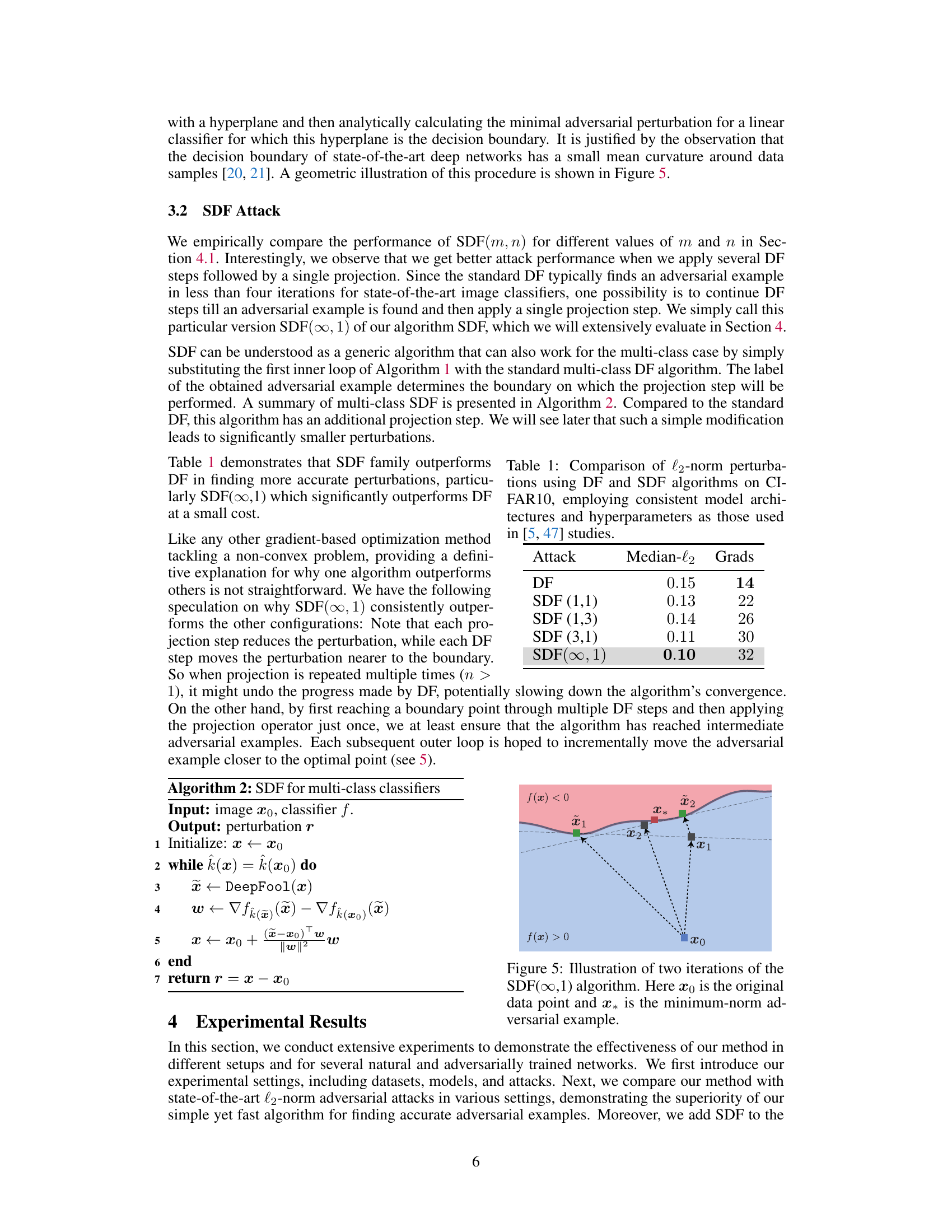
🔼 This table compares the performance of the DeepFool (DF) algorithm and the proposed SuperDeepFool (SDF) algorithms in finding adversarial perturbations for images from the CIFAR-10 dataset. It shows the median l2-norm of the perturbations found and the average number of gradient computations required by each algorithm, demonstrating the efficiency and effectiveness of the SDF method.
read the caption
Table 1: Comparison of l2-norm perturbations using DF and SDF algorithms on CIFAR10, employing consistent model architectures and hyperparameters as those used in [5, 47] studies.
In-depth insights#
Minimal Attack Geo#
The heading ‘Minimal Attack Geo’ suggests a focus on the geometric properties of minimal adversarial attacks against machine learning models. This line of research likely explores how small, targeted perturbations (minimal attacks) interact with the model’s decision boundaries in the feature space (geometry). A key aspect would be identifying the geometric characteristics of these minimal attacks—are they concentrated along specific directions, or do they show randomness? Understanding this geometry can unveil vulnerabilities in the model’s design, allowing for improved attack strategies or more robust model architectures. The research may also quantify the impact of these attacks in terms of their magnitude and the resulting misclassification rates, and analyze the relationship between the geometric properties of the attacks and their effectiveness in fooling the model. The study might focus on creating novel attack algorithms exploiting this geometric information for improved efficiency or effectiveness compared to existing attack methods.
SuperDeepFool Algo#
The SuperDeepFool algorithm presents a novel approach to generating minimal adversarial perturbations. It cleverly builds upon the DeepFool method, enhancing its efficiency and accuracy. The core innovation lies in incorporating an additional projection step, which strategically guides the perturbation vector toward the optimal solution. This ensures that the generated perturbations are more accurately aligned with the decision boundary’s normal vector. The algorithm’s parameter-free nature and computational efficiency are key strengths, making it suitable for evaluating large models and practical applications like adversarial training. While it shows improvement over DeepFool, further research could explore extensions to handle various Lp-norms and targeted attacks, further solidifying its position as a leading minimal adversarial attack method.
Adversarial Training#
Adversarial training is a crucial technique to enhance the robustness of machine learning models, particularly deep neural networks, against adversarial attacks. The core idea is to augment the training dataset with adversarial examples, which are carefully crafted inputs designed to mislead the model. By training the model on these adversarial examples alongside the original clean data, the model learns to be less susceptible to such manipulations. This process improves the model’s generalization ability and reduces its vulnerability to real-world perturbations, making it more reliable and secure in practical applications. However, effective adversarial training is computationally expensive, requiring the generation of high-quality adversarial examples and careful consideration of the training hyperparameters. Different adversarial attack methods yield varying levels of effectiveness in generating such examples, making the selection of an appropriate attack strategy critical for successful adversarial training. Furthermore, the trade-off between robustness and standard accuracy should always be considered, as excessively focusing on robustness might compromise the model’s performance on standard inputs. Research continually explores new and improved adversarial training methods to address the computational limitations and achieve a better balance between robustness and accuracy. Ultimately, adversarial training is a valuable tool for building more resilient models, but its complexity requires ongoing research and careful implementation.
AA++ Efficiency Boost#
The heading ‘AA++ Efficiency Boost’ suggests a significant improvement in the computational efficiency of AutoAttack (AA), a robust adversarial attack evaluation method. The core idea likely involves integrating a faster, more efficient adversarial attack algorithm within the AA framework. This new algorithm likely replaces or augments existing components of AA, significantly reducing the computational cost while maintaining the effectiveness of AA in identifying adversarial examples. The ‘++’ likely indicates an enhanced or improved version, suggesting an incremental improvement on the original AA. The implications are significant for researchers and practitioners, as it allows for faster and more scalable evaluation of model robustness, accelerating the development and deployment of more robust AI systems. The detailed analysis would uncover how this efficiency gain is achieved, whether through algorithmic improvements, optimized implementation techniques, or a combination of both. A thorough exploration would also highlight the trade-offs, if any, between speed and the strength or coverage of the attack, emphasizing the impact this has on the overall robustness measurement.
Future Research#
Future research directions stemming from this work on minimal adversarial attacks could profitably explore several avenues. Extending the SuperDeepFool (SDF) algorithm to handle targeted attacks and other lp-norms beyond l2 is crucial. This would broaden its applicability and enhance its utility as a general-purpose tool for evaluating adversarial robustness. Further investigation into the geometric properties of deep networks and their relationship to minimal adversarial perturbations is warranted. Understanding this relationship could lead to improved attack and defense strategies. Additionally, a deeper theoretical analysis of SDF’s convergence properties is needed. While empirical results demonstrate its effectiveness, formal guarantees would enhance its credibility and usefulness. Finally, applying SDF to other domains beyond image classification is an important direction. The principles behind SDF could be adapted to other machine learning tasks, expanding its impact on AI safety and security.
More visual insights#
More on figures
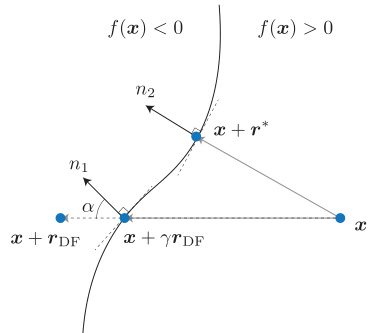
🔼 This figure illustrates two key properties of the minimal adversarial perturbation, r*, which is the smallest perturbation that changes the classification of an input x. First, the point x + r* lies on the decision boundary, which is the set of points where the classifier’s output is ambiguous. Second, the perturbation vector r* is orthogonal (perpendicular) to the decision boundary at the point x + r*. This geometric interpretation is important for understanding the proposed SuperDeepFool attack, which aims to find perturbations that are close to this optimal solution.
read the caption
Figure 2: Illustration of the optimal adversarial example x + r* for a binary classifier f; the example lies on the decision boundary (set of points where f(x) = 0) and the perturbation vector r* is orthogonal to this boundary.

🔼 This figure compares different adversarial attack methods based on the number of gradient computations needed and the resulting perturbation norm (l2). It shows that the proposed method (SDF) achieves significantly smaller perturbations with similar computational cost compared to existing methods like DeepFool (DF), making it a faster and more efficient attack.
read the caption
Figure 1: The average number of gradient computations vs the mean l2-norm of perturbations. It shows that our novel fast and accurate method, SDF, outperforms other minimum-norm attacks. SDF finds significantly smaller perturbations compared to DF, with only a small increase in computational cost. SDF also outperforms other algorithms in optimality and speed. The numbers are taken from Table 5.
🔼 The figure compares the average number of gradient computations required by various minimum-norm adversarial attacks against the mean l2-norm of the perturbations they produce. The results demonstrate that the proposed method (SDF) outperforms existing methods in both effectiveness (smaller perturbations) and computational efficiency (fewer gradient computations).
read the caption
Figure 1: The average number of gradient computations vs the mean l2-norm of perturbations. It shows that our novel fast and accurate method, SDF, outperforms other minimum-norm attacks. SDF finds significantly smaller perturbations compared to DF, with only a small increase in computational cost. SDF also outperforms other algorithms in optimality and speed. The numbers are taken from Table 5.

🔼 This figure illustrates two key properties of the minimal adversarial perturbation, r*, in a binary classification scenario. First, it shows that the point x + r* (the adversarial example) lies directly on the decision boundary, which is the line separating the two classes (where f(x) = 0). Second, it demonstrates that the perturbation vector r* is orthogonal (perpendicular) to the decision boundary at the point x + r*. This orthogonality is a key geometrical characteristic of minimal adversarial perturbations.
read the caption
Figure 2: Illustration of the optimal adversarial example x + r* for a binary classifier f; the example lies on the decision boundary (set of points where f(x) = 0) and the perturbation vector r* is orthogonal to this boundary.

🔼 This figure compares the average number of gradient computations required by different minimum-norm adversarial attack methods against the mean l2-norm of the resulting adversarial perturbations. The SuperDeepFool (SDF) method is shown to be superior, achieving smaller perturbations with a comparable computational cost to DeepFool (DF).
read the caption
Figure 1: The average number of gradient computations vs the mean l2-norm of perturbations. It shows that our novel fast and accurate method, SDF, outperforms other minimum-norm attacks. SDF finds significantly smaller perturbations compared to DF, with only a small increase in computational cost. SDF also outperforms other algorithms in optimality and speed. The numbers are taken from Table 5.

🔼 The figure shows a graph comparing the average number of gradient computations needed by different minimum-norm adversarial attack methods against the mean L2-norm of the resulting perturbations. It demonstrates that the proposed SuperDeepFool (SDF) method is superior to other methods like DeepFool (DF), achieving smaller perturbations with a comparable computational cost.
read the caption
Figure 1: The average number of gradient computations vs the mean ℓ2-norm of perturbations. It shows that our novel fast and accurate method, SDF, outperforms other minimum-norm attacks. SDF finds significantly smaller perturbations compared to DF, with only a small increase in computational cost. SDF also outperforms other algorithms in optimality and speed. The numbers are taken from Table 5.
More on tables
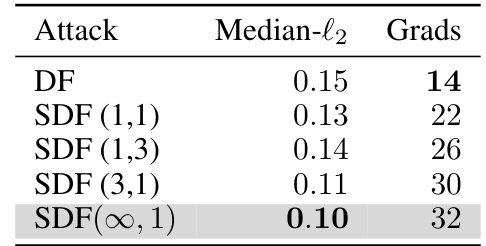
🔼 This table compares the median l2-norm of adversarial perturbations and the number of gradient computations required by different attack algorithms (DF and various SDF variants) on the CIFAR-10 dataset. Consistent model architectures and hyperparameters were used across all algorithms for a fair comparison. The results show that SDF(∞,1) achieves the smallest perturbations but with a slightly higher computational cost compared to DF.
read the caption
Table 1: Comparison of l2-norm perturbations using DF and SDF algorithms on CIFAR10, employing consistent model architectures and hyperparameters as those used in [5, 47] studies.

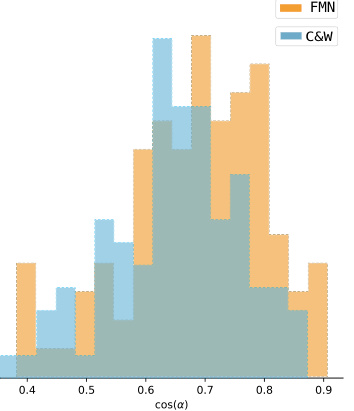
🔼 This table presents the results of an experiment comparing the orthogonality of perturbation vectors obtained from different attack methods (DF and variants of SDF) on three different models trained on the CIFAR-10 dataset. The cosine similarity between the perturbation vector (r) and the gradient at the perturbed point (∇f(x+r)) is used as a metric to quantify orthogonality, higher values indicating greater orthogonality. The table helps demonstrate the effectiveness of SDF in producing perturbation vectors closer to being orthogonal to the decision boundary.
read the caption
Table 2: The cosine similarity between the perturbation vector(r) and ∇ f(x + r). We performed this experiment on three models trained on CIFAR10.
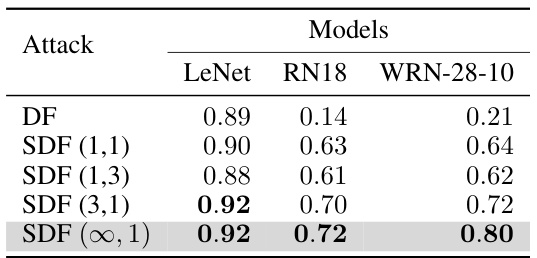
🔼 This table presents the cosine similarity between the perturbation vector (r) and the gradient at x + r (∇f(x+r)) for different attack methods (DF and various SDF configurations) across three different model architectures (LeNet, ResNet18, and WRN-28-10) trained on the CIFAR-10 dataset. A higher cosine similarity indicates a stronger alignment of the perturbation vector with the gradient, suggesting a more optimal perturbation closer to the decision boundary. The results show that SDF consistently achieves higher cosine similarity values compared to DF, particularly for more complex models.
read the caption
Table 2: The cosine similarity between the perturbation vector(r) and ∇f(x + r). We performed this experiment on three models trained on CIFAR10.
🔼 This table compares the performance of several iterative adversarial attacks (DF, ALMA, DDN, FAB, FMN, C&W, and SDF) on an adversarially trained IBP model for the MNIST dataset. It shows the fooling rate (FR), median l2-norm of perturbations, and the number of gradient computations required by each attack. The results highlight the trade-off between attack effectiveness and computational cost.
read the caption
Table 3: We evaluate the performance of iteration-based attacks on MNIST using IBP models, noting the iteration count in parentheses. Our analysis focuses on the best-performing versions, highlighting their significant costs when encountered powerful robust models.

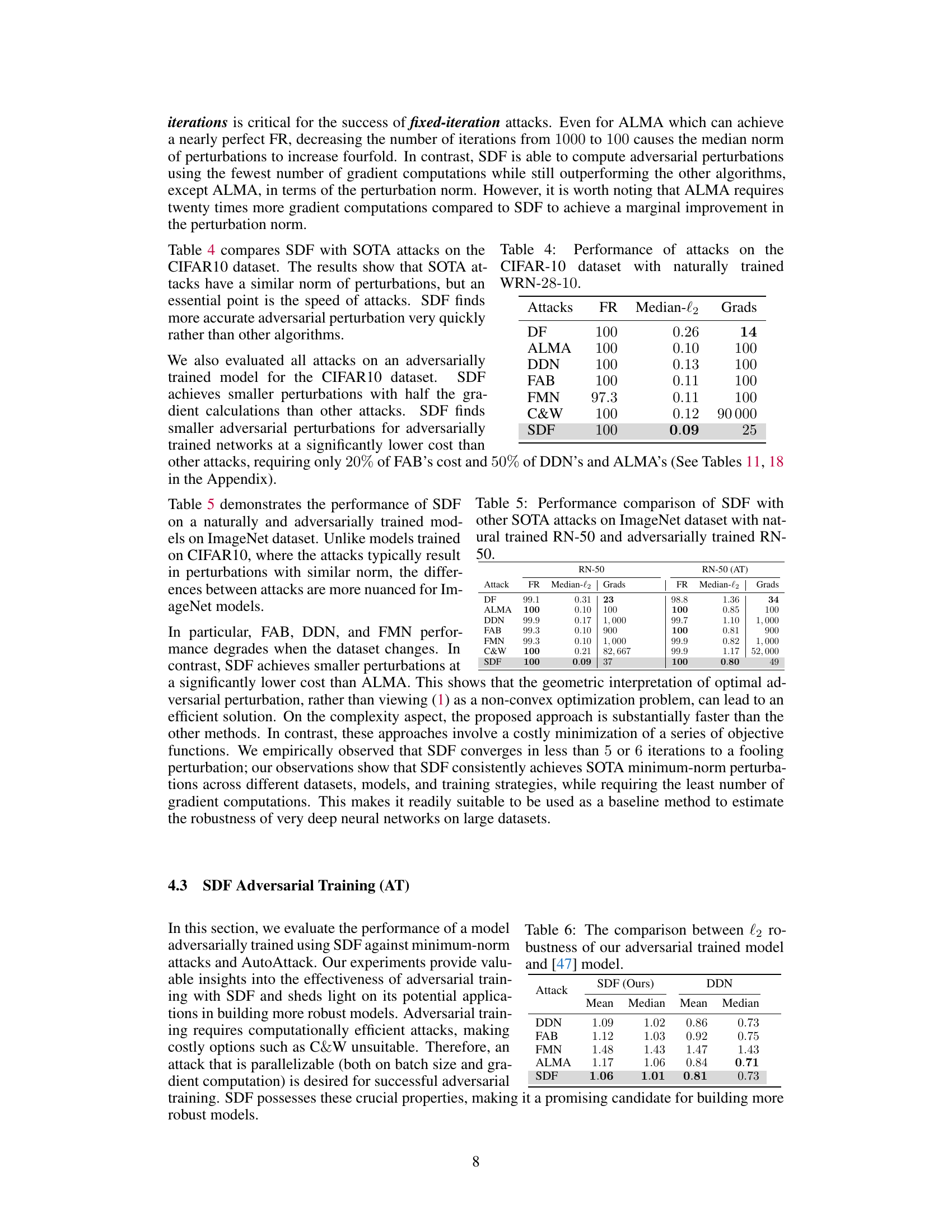
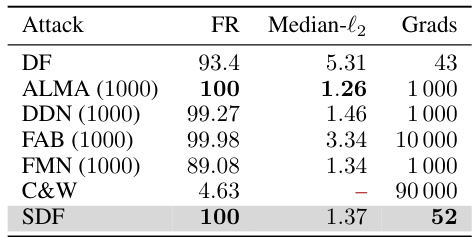
🔼 This table compares the performance of different attack methods (DF, ALMA, DDN, FAB, FMN, C&W, and SDF) on a naturally trained Wide Residual Network (WRN-28-10) model using the CIFAR-10 dataset. The metrics shown are the fooling rate (FR), the median l2-norm of the perturbations, and the number of gradient computations required. The results demonstrate that SDF outperforms other methods in achieving a high fooling rate with a significantly smaller median perturbation and fewer gradient computations.
read the caption
Table 4: Performance of attacks on the CIFAR-10 dataset with naturally trained WRN-28-10.
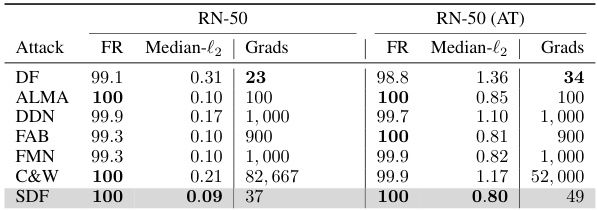
🔼 This table compares the performance of the SuperDeepFool (SDF) attack against other state-of-the-art (SOTA) minimum l2-norm attacks on the ImageNet dataset. It shows the fooling rate (FR), median l2-norm of the perturbations, and the number of gradient computations required for both a naturally trained ResNet-50 (RN-50) model and an adversarially trained RN-50 model. The results demonstrate SDF’s superior performance in terms of finding smaller perturbations while requiring fewer computations.
read the caption
Table 5: Performance comparison of SDF with other SOTA attacks on ImageNet dataset with natural trained RN-50 and adversarially trained RN-50.

🔼 This table compares the l2 robustness of an adversarially trained model using the SDF attack with the model from the paper [47]. The comparison uses several different attacks (DDN, FAB, FMN, ALMA, and SDF) to assess the median and mean l2-norms of the adversarial perturbations obtained by each attack. The results show the impact of the adversarial training method used on the robustness of the model against these various attacks.
read the caption
Table 6: The comparison between l2 robustness of our adversarially trained model and [47] model.

🔼 This table compares the average input curvature of three adversarially trained models: a standard model, a model trained using DDN, and a model trained using SDF. The input curvature is a measure of the non-linearity of the model’s decision boundary. Lower curvature generally corresponds to higher robustness against adversarial attacks. The table shows that the SDF adversarially trained model exhibits significantly lower input curvature than the other two models.
read the caption
Table 7: Average input curvature of AT models. According to the measures proposed in [52].

🔼 This table compares the robust accuracy of six adversarially trained models on CIFAR-10 against two versions of the AutoAttack (AA) method: the original AA and a faster version called AA++. It shows the clean accuracy, robust accuracy under AA, the number of gradient computations needed for AA, robust accuracy under AA++, and the gradient computations for AA++. The results demonstrate that AA++ achieves similar robust accuracy to AA but with significantly fewer gradient computations, highlighting its increased efficiency.
read the caption
Table 8: Analysis of robust accuracy for various defense strategies against AA++ and AA with ε = 0.5 for six adversarially trained models on CIFAR10. All models are taken from the RobustBench library [12].

🔼 This table compares the effectiveness of adding a line search step to the DeepFool (DF) and SuperDeepFool (SDF) algorithms. It shows the median l2-norm of adversarial perturbations found by each algorithm, both with and without the line search, on four different models: one regularly trained model and three adversarially trained models. The results demonstrate how the line search impacts the performance of each algorithm in finding minimal adversarial perturbations.
read the caption
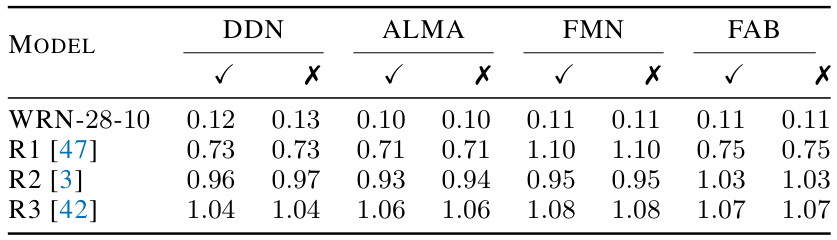
Table 9: Comparison of the effectiveness of line search on the CIFAR10 data for SDF and DF. We use one regularly trained model S (WRN-28-10) and three adversarially trained models (shown with R1 [47], R2 [3] and R3 [42]). ✓ and X indicate the presence and absence of line search respectively.
🔼 This table compares the impact of adding a line search step to four different minimum-norm adversarial attack algorithms (DDN, ALMA, FMN, FAB) on three adversarially trained models and one normally trained model on the CIFAR-10 dataset. The results show that for DDN and ALMA, the line search provides only a marginal improvement. However, for FMN and FAB, the line search does not significantly improve the attacks because these algorithms already incorporate a line search as part of their procedures. The table demonstrates the effect of a line search on the effectiveness of minimum-norm adversarial attacks on different models, highlighting that its impact is highly dependent on the algorithm’s design.
read the caption
Table 10: Comparison of the effectiveness of line search on the CIFAR-10 data for other attacks. Line search effects are a little for DDN and ALMA. For FMN and FAB because they use line search at the end of their algorithms (they remind this algorithm as a binary search and final search, respectively), line search does not become effective.
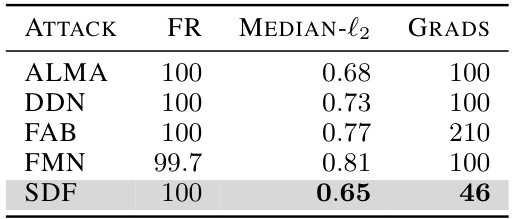
🔼 This table compares the performance of the SuperDeepFool (SDF) attack against other state-of-the-art minimum-l2 norm attacks on an adversarially trained PreActResNet-18 model using the CIFAR-10 dataset. It shows the fooling rate (FR), median l2 perturbation norm, and the number of gradient computations required for each attack. The results indicate that SDF achieves a comparable fooling rate with a significantly smaller median l2 perturbation and far fewer gradient computations than the other methods.
read the caption
Table 11: Comparison of SDF with other state-of-the-art attacks for median l2 on CIFAR-10 dataset for adversarially trained network (PRN-18 [42]).

🔼 This table presents the robustness results of adversarially trained models on the CIFAR-10 dataset against the l∞-norm AutoAttack (AA). The experiment was conducted on 1000 samples for each epsilon (ε) value, comparing the performance of a model adversarially trained using the DeepFool (DF) method against one trained with the SuperDeepFool (SDF) method. The results showcase the robustness (in terms of percentage) of each model against the attack for different epsilon values.
read the caption
Table 12: Robustness results of adversarially trained models on CIFAR-10 with l∞-AA. We perform this experiment on 1000 samples for each ɛ.

🔼 This table presents the robustness results of adversarially trained models (DDN and SDF) on the CIFAR-10 dataset against l2-norm Auto-Attack (AA). The models’ robustness is evaluated across different perturbation levels (ε = 0.3, 0.4, 0.5, 0.6). The results showcase the performance of the adversarially trained models against the l2-AA attack, and the natural accuracy for comparison.
read the caption
Table 13: Robustness results of adversarially trained models on CIFAR-10 with l2-AA. We perform this experiment on 1000 samples for each ε.
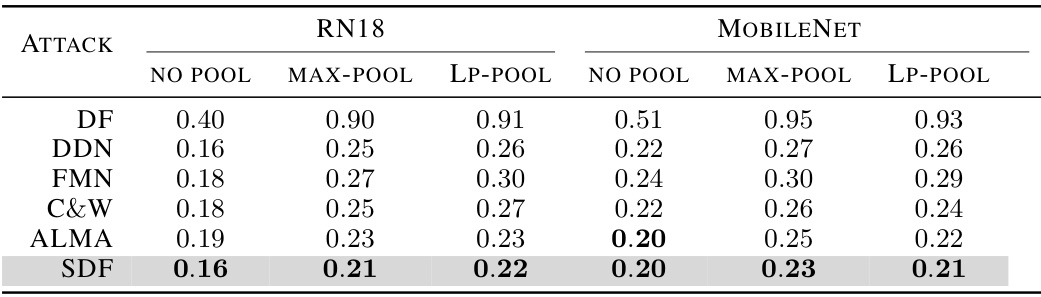
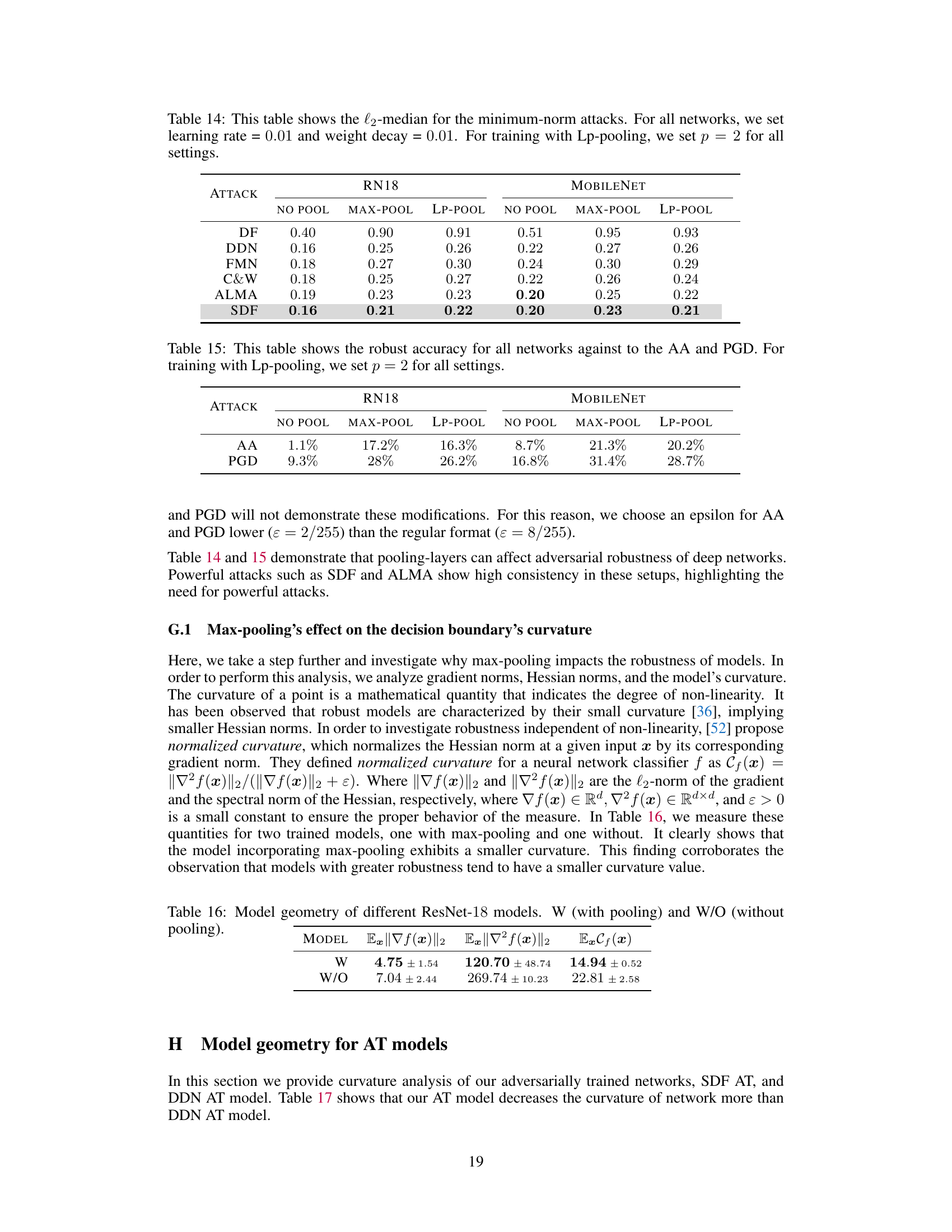
🔼 This table compares the median l2-norm of perturbations achieved by different minimum-norm attacks (DF, DDN, FMN, C&W, ALMA, and SDF) on two different network architectures (ResNet-18 and MobileNet). The comparison is done for networks trained without pooling, with max-pooling, and with Lp-pooling (p=2). The values represent the median l2-norm of the adversarial perturbations found by each attack method.
read the caption
Table 14: This table shows the l2-median for the minimum-norm attacks. For all networks, we set learning rate = 0.01 and weight decay = 0.01. For training with Lp-pooling, we set p = 2 for all settings.

🔼 This table compares the robust accuracy of different models (RN18 and MobileNet) against two types of adversarial attacks (AA and PGD). It shows the impact of using different pooling techniques (no pooling, max-pooling, and Lp-pooling) on the model’s robustness. The results illustrate how the choice of pooling layer affects the model’s resilience to adversarial examples.
read the caption
Table 15: This table shows the robust accuracy for all networks against to the AA and PGD. For training with Lp-pooling, we set p = 2 for all settings.

🔼 This table presents a comparison of the geometric properties of two ResNet-18 models: one trained with max-pooling and another trained without. The properties compared include the average L2-norm of the gradient (||∇f(x)||2), the average spectral norm of the Hessian (||∇²f(x)||2), and the average normalized curvature (Cf(x)). The results show that the model trained with max-pooling exhibits significantly smaller values for all three properties, indicating a smoother decision boundary.
read the caption
Table 16: Model geometry of different ResNet-18 models. W (with pooling) and W/O (without pooling).

🔼 This table presents a comparison of the model geometry for regular, DDN adversarially trained, and SDF adversarially trained models. It shows the average l2 norm of the gradient (||∇f(x)||2), the average l2 norm of the Hessian (||∇²f(x)||2), and the average normalized curvature (Cf(x)). The normalized curvature is a measure of the local non-linearity around data points, and lower values indicate greater robustness. The results demonstrate that the SDF adversarially trained model achieves significantly lower values for all three metrics, indicating improved robustness.
read the caption
Table 17: Model geometry for regular and adversarially trained models.

🔼 This table compares the performance of the DeepFool (DF) attack and the proposed SuperDeepFool (SDF) attack in finding minimal l2-norm adversarial perturbations on the CIFAR10 dataset. Consistent model architectures and hyperparameters were used for a fair comparison, following the methodology of previous studies ([5, 47]). The table shows the median l2-norm of the perturbations and the number of gradient computations required by each method.
read the caption
Table 1: Comparison of l2-norm perturbations using DF and SDF algorithms on CIFAR10, employing consistent model architectures and hyperparameters as those used in [5, 47] studies.
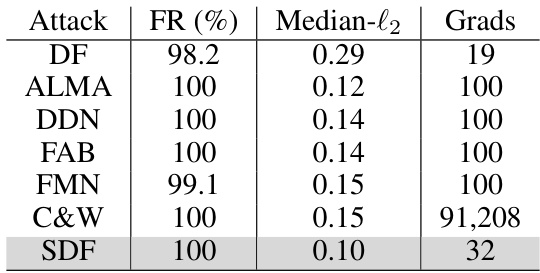
🔼 This table presents a comparison of the median l2-norm of adversarial perturbations and the number of gradient computations required by different attack algorithms on the CIFAR-10 dataset. The algorithms compared include DeepFool (DF) and several variants of SuperDeepFool (SDF). The results show that SDF consistently finds significantly smaller perturbations than DF, with only a modest increase in computational cost.
read the caption
Table 1: Comparison of l2-norm perturbations using DF and SDF algorithms on CIFAR10, employing consistent model architectures and hyperparameters as those used in [5, 47] studies.

🔼 This table presents the results of evaluating several adversarial attacks (ALMA, DDN, FAB, FMN, C&W, and SDF) on a naturally trained SmallCNN model using the MNIST dataset. The table shows the fooling rate (FR), the median l2-norm of the adversarial perturbations, and the number of gradient computations required for each attack. The results highlight the relative performance of different attack methods in terms of effectiveness and computational efficiency.
read the caption
Table K: We show the result of evaluating adversarial attacks on naturally trained SmallCNN on MNIST dataset.

🔼 This table compares the runtime of different adversarial attacks (ALMA, DDN, FAB, FMN, C&W, and SDF) on a Wide ResNet-28-10 (WRN-28-10) model trained on the CIFAR-10 dataset. It shows the runtime in seconds and the median l2-norm of the generated adversarial perturbations for both a naturally trained model and a model adversarially trained using the R1 method from [44]. The table highlights the significantly faster runtime of SDF compared to other methods, especially the computationally expensive Carlini & Wagner (C&W) attack.
read the caption
Table 18: Runtime comparison for adversarial attacks on WRN-28-10 architecture trained on CIFAR10, for both naturally trained model and adversarially trained models.

🔼 This table compares the performance of the modified SDF (SDFe) with other state-of-the-art attacks (DF, FMN, FAB) on two pre-trained robust networks (M1 and M2) on the CIFAR-10 dataset. The results show that SDFe outperforms other algorithms in discovering smaller perturbations. The metrics reported include the median l∞-norm of perturbations, the fooling rate (FR), and the number of gradient computations required.
read the caption
Table 19: Performance of SDFe on two robust networks trained on CIFAR-10 dataset.

🔼 This table presents the performance comparison of targeted and untargeted adversarial attacks (DDN, FMN, and SDF) on a standard-trained Wide Residual Network 28-10 model for CIFAR-10 dataset. The evaluation metrics include fooling rate (FR), mean L2 perturbation norm, median L2 perturbation norm, and the number of gradient computations (Grads). The results show that while the targeted attacks perform similarly in terms of FR, SDF achieves a significantly lower number of gradient computations.
read the caption
Table 20: Performance of targeted SDF on a standard trained WRN-28-10 on CIFAR-10, measured using 1000 random samples.
Full paper#