TL;DR#
Current methods for 3D content generation often suffer from “hallucinations,” producing unrealistic or inconsistent features across different viewpoints. These inconsistencies stem from relying heavily on 2D visual priors which lack geometric constraints. This problem severely limits the quality and usability of generated 3D models.
The proposed method, Hallo3D, tackles this issue by incorporating multi-modal models to detect and mitigate these hallucinations. Using a three-stage approach of generation, detection, and correction, it identifies inconsistencies across multiple views and uses this information to refine the generation process. Hallo3D significantly improves the multi-view consistency and quality of generated 3D content, demonstrating its effectiveness across various text-driven and image-driven generation frameworks. The approach is data-independent and readily integrates with existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D content generation because it directly addresses the persistent problem of hallucinations and inconsistencies in current methods. By introducing a novel, tuning-free approach that leverages multi-modal models, Hallo3D offers a significant advancement that improves both the quality and consistency of generated 3D content. This opens up new avenues for research in tackling the challenges of 3D generation, particularly in areas where view consistency and hallucination mitigation are paramount, making it highly relevant to ongoing research trends.
Visual Insights#

🔼 This figure showcases a comparison of 3D content generated using a baseline model and the proposed Hallo3D method. The ‘Janus’ problem, characterized by inconsistencies and hallucinations in multi-view 3D object generation, is prominently displayed in the baseline results. In contrast, Hallo3D demonstrates a significant improvement in generating consistent and visually accurate 3D models from various viewpoints.
read the caption
Figure 1: 3D Content Generation Results between Hallo3D (ours) and Baseline Model. Hallo3D can effectively solve the 'Janus' problem and improve the multi-view consistency of the 3D generation.

🔼 This table presents a quantitative comparison of different methods for text-driven 3D generation. The metrics used are CLIP-Score at various resolutions (B/32, B/16, L/14). Higher scores indicate better quality. The table compares the performance of Hallo3D against several baselines, demonstrating the improvement in generation quality achieved by Hallo3D.
read the caption
Table 1: Quantitative comparisons in text-driven 3D generation
In-depth insights#
Multimodal Hallucination#
Multimodal hallucination in 3D content generation refers to the phenomenon where inconsistencies and inaccuracies arise in the generated 3D models due to limitations in the training data or the model architecture. Large language models (LLMs) play a crucial role in detecting these hallucinations by analyzing multiple modalities (e.g., text prompts, 2D renderings) and identifying inconsistencies or conflicts among them. The ability of LLMs to understand spatial relationships and geometric structures is a key advantage in this context. By integrating LLMs into the generation pipeline, inconsistencies are pinpointed, leading to improved quality and realism. A generation-detection-correction paradigm is often employed, where an LLM assesses the generated content, flags problematic areas, and guides refinement processes to correct hallucinations. This approach significantly enhances the quality of 3D models by resolving inconsistencies across different viewpoints and addressing issues such as duplicated features or unrealistic spatial arrangements. The core challenge remains balancing the creative freedom of the generator with the need for accuracy and consistency, an area where multimodal analysis and correction techniques offer significant potential.
3D Consistency Metrics#
Establishing robust 3D consistency metrics is crucial for evaluating the quality of generated 3D content. Current methods often rely on 2D projections, which fail to capture the full complexity of 3D geometry. A truly comprehensive metric should consider multi-view consistency, assessing how well the model generates coherent views from multiple angles. Another key aspect is geometric accuracy, measuring the fidelity of the generated 3D shape against ground truth or expected structure. Furthermore, semantic consistency is critical; the generated object should faithfully represent the intended meaning and features across different viewpoints. Finally, texture and material consistency should be incorporated, ensuring that the appearance of surfaces remains uniform and realistic regardless of perspective. Developing a standardized benchmark using these combined metrics will facilitate better comparison and drive future advancements in 3D generation technology.
Tuning-Free Approach#
A ’tuning-free approach’ in the context of a research paper, likely focusing on 3D content generation, suggests a method that doesn’t require extensive hyperparameter tuning or model retraining. This is a significant advantage as it reduces the computational cost and expertise needed for implementation. The core strength lies in its adaptability and ease of integration with pre-trained models. Such an approach might leverage the capabilities of large pre-trained multimodal models to guide the generation process, using their inherent understanding of geometry and consistency to infer optimal parameters implicitly. This contrasts with methods that rely on iterative fine-tuning, which is often computationally expensive and time-consuming. A tuning-free approach implies improved accessibility, making the technology applicable to a wider range of users and applications, even those with limited computational resources or expertise in deep learning. The effectiveness of a tuning-free approach hinges on the power of the underlying pre-trained model, its ability to generalize across diverse inputs, and its robustness to various data conditions. However, it might sacrifice some level of fine-grained control compared to methods that allow for extensive parameter adjustments.
Ablation Study Analysis#
An ablation study systematically evaluates the contribution of individual components within a complex system. In the context of a 3D content generation model, an ablation study might involve removing or disabling specific modules (e.g., multi-modal hallucination detection, multi-view appearance alignment, prompt-enhanced re-consistency) to assess their impact on the overall performance. Key performance indicators (KPIs) such as multi-view consistency, visual fidelity, and alignment with prompts would be measured. The results would highlight the relative importance of each module, revealing which components are essential for achieving high-quality and consistent 3D content generation. A well-designed ablation study not only identifies crucial components but also reveals potential synergies or trade-offs between them. It provides valuable insights into the design choices and the internal workings of the model, enabling improvements in future iterations. The analysis section should interpret the quantitative and qualitative findings to provide a comprehensive understanding of each module’s contribution and how it relates to the overall goals of the research.
Future Research#
Future research directions stemming from the Hallo3D paper could explore several promising avenues. Extending Hallo3D’s capabilities to handle more complex 3D scenes and object interactions is crucial, moving beyond isolated objects to realistic environments. The current reliance on large, pre-trained multi-modal models could be addressed by investigating more efficient methods for hallucination detection and mitigation, perhaps using smaller, specialized models or incorporating novel architectural designs. Improving the efficiency of the Multi-view Appearance Alignment module would be highly beneficial, potentially through advancements in attention mechanisms or exploring alternative alignment strategies. The effectiveness of Hallo3D also depends on the quality of the input, so further investigation into robust prompt engineering techniques to minimize ambiguity and ensure consistency would be worthwhile. Finally, a more thorough investigation into the broader societal impact of high-fidelity 3D content generation is needed to address potential ethical concerns and promote responsible development and deployment of this powerful technology.
More visual insights#
More on figures

🔼 This figure shows a qualitative comparison of 3D models generated by Hallo3D and several baseline methods for text-driven generation. Three different prompts were used to generate 3D models of a flamingo, a dog statue, and a sports car. For each prompt, the figure shows renderings from multiple viewpoints (90°, 270°, 45°, 225°, 0°, 105°, 285°) for both Hallo3D and the baseline models, allowing for a visual comparison of multi-view consistency and quality. The results demonstrate that Hallo3D generates more consistent and visually appealing 3D models across different viewpoints, compared to the baseline methods.
read the caption
Figure 5: Qualitative comparison in text-driven 3D generation of Hallo3D and baseline models. To provide more straightforward comparison, we rendered both Hallo3D and the baseline models from two identical and complementary angles.

🔼 This figure illustrates the Hallo3D pipeline, which consists of three core modules: Multi-View Appearance Alignment, Multi-Modal Hallucination Detection, and Prompt-Enhanced Re-Consistency. The pipeline uses multi-view renderings of a 3D object as input. LSDS (Score Distillation Sampling) is used with an attention mechanism to align appearances across views. A large multi-modal model (LMM) detects inconsistencies in the renderings, which are used as enhanced negative prompts in a second stage of 2D diffusion to correct these. The loss function LCG is used for the training process.
read the caption
Figure 3: Illustration of our pipeline. We jointly optimize our model using LSDS and LCG. For LSDS, we identify a focal view from multi-view renderings based on the camera pose, utilizing it as the keys (K) and values (V) to align all the four images using attention. This process harmonizes the appearance and feeds the output into the 2D Diffusion on the left, which plays a crucial role in refining the noise prediction. For LCG, we query hallucinations and inconsistencies in the rendering using an LMM and apply the results, outputted as enhanced negative prompt, to the following image optimization process to re-consistent a high-quality image. We calculate the LCG based on the differences between the two images, thereby enhancing the consistency of the 3D content.
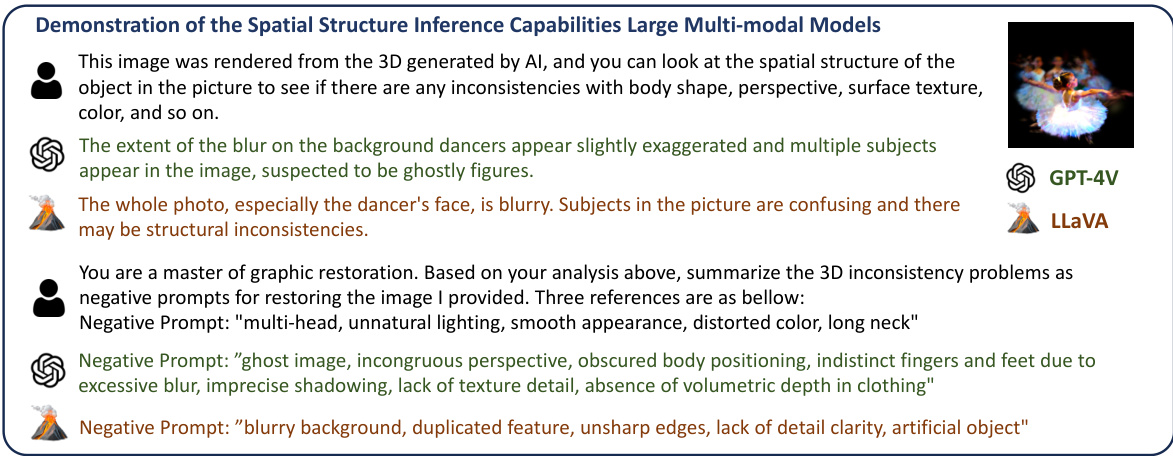
🔼 This figure showcases a multi-modal approach for identifying inconsistencies in 3D-generated images using large multi-modal models (LMMs). The example shows how an LLM (LLaVA and GPT-4V) is able to analyze a 3D rendering and provide concise negative prompts to correct identified issues such as blurry features, structural inconsistencies, and duplicated elements. This demonstrates the LMM’s capacity for spatial reasoning and its usefulness in refining 3D generation processes.
read the caption
Figure 4: A multi-modal case study for evaluating the capabilities of LMMs in 3D generation tasks. The first round of dialogue demonstrates that LMMs can infer structural consistency from 3D rendered images, while the second round shows that LMMs can respond in specific formats, allowing us to subsequently identify the negative prompts output using regular expressions.

🔼 This figure shows a qualitative comparison of 3D model generation results using Hallo3D and four baseline methods (GaussianDreamer, SJC, DreamFusion-IF, and Magic3D). Three different prompts were used to generate 3D models of a flamingo, a dog statue, and a sports car. Each model is shown from two different viewpoints (90°/270°, 45°/225°, and 285°/105°). The comparison highlights Hallo3D’s ability to generate more consistent and realistic 3D models across different viewpoints, compared to the baseline methods.
read the caption
Figure 5: Qualitative comparison in text-driven 3D generation of Hallo3D and baseline models. To provide a more straightforward comparison, we rendered both Hallo3D and the baseline models from two identical and complementary angles.
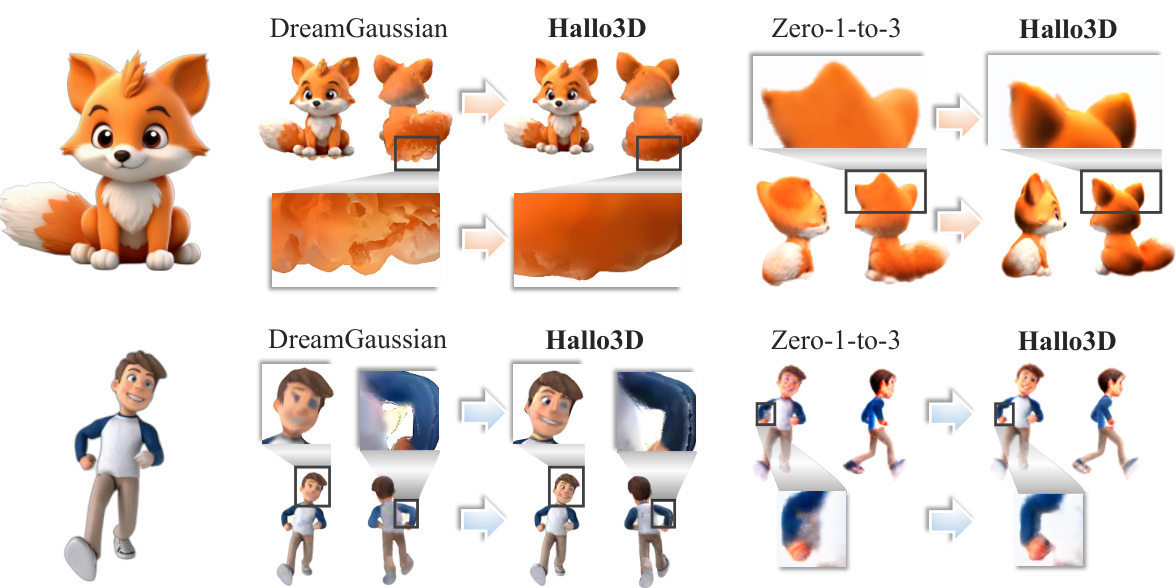
🔼 This figure shows a qualitative comparison of image-driven 3D generation results between Hallo3D and two baseline methods (DreamGaussian and Zero-1-to-3). Two examples are shown: a cartoon fox and a cartoon person. For each model and example, multiple views are provided, highlighting the differences in the quality and consistency of the generated 3D models across different viewpoints. The magnified details emphasize the improvements in view consistency and visual quality achieved by Hallo3D compared to the baseline methods.
read the caption
Figure 6: Qualitative comparison in image-driven 3D generation of Hallo3D and baseline models. To facilitate a more direct comparison, we rendered both Hallo3D and the baseline models from two complementary angles and magnified specific details.

🔼 This figure presents an ablation study of the Hallo3D method. It shows the impact of removing each of the three core components: Multi-view Appearance Alignment (A), Multi-modal Hallucination Detection (B), and Prompt-Enhanced Re-consistency (C). The results for two different prompts are visualized, illustrating the effect of each component on the final 3D model generation.
read the caption
Figure 7: Ablation study of our method. In the figure, module A represents Multi-view Appearance Alignment in Sec. 3.2, module B stands for Multi-modal Hallucination Detection in Sec. 3.3, and module C denotes Prompt-Enhanced Re-Consistency in Sec. 3.4. We conducted ablation studies on each of these three modules respectively.

🔼 This figure shows the loss curves for both LCG (consistency loss) and LSDS (score distillation sampling loss) during the training process. It also displays the CLIP-Score, a metric evaluating the quality of the generated images, with and without LCG. The plot illustrates the relationship between these losses and the resulting image quality, demonstrating the effect of the proposed consistency loss (LCG) on the overall quality of the 3D model generation.
read the caption
Figure 8: Loss curves for LCG and LSDS, along with the CLIP-Score curves with and without LCG.

🔼 This figure compares the results of Hallo3D against two other methods (Perp-Neg and Debias) for improving the consistency of 3D generation. The results show that Hallo3D achieves a slightly higher CLIP-Score, indicating better overall image quality and consistency compared to the baseline and the other two methods. The visualization shows several renderings from different viewpoints for each method, highlighting the differences in quality and consistency.
read the caption
Figure 9: Comparison experiments with Perp-Neg and Debias.

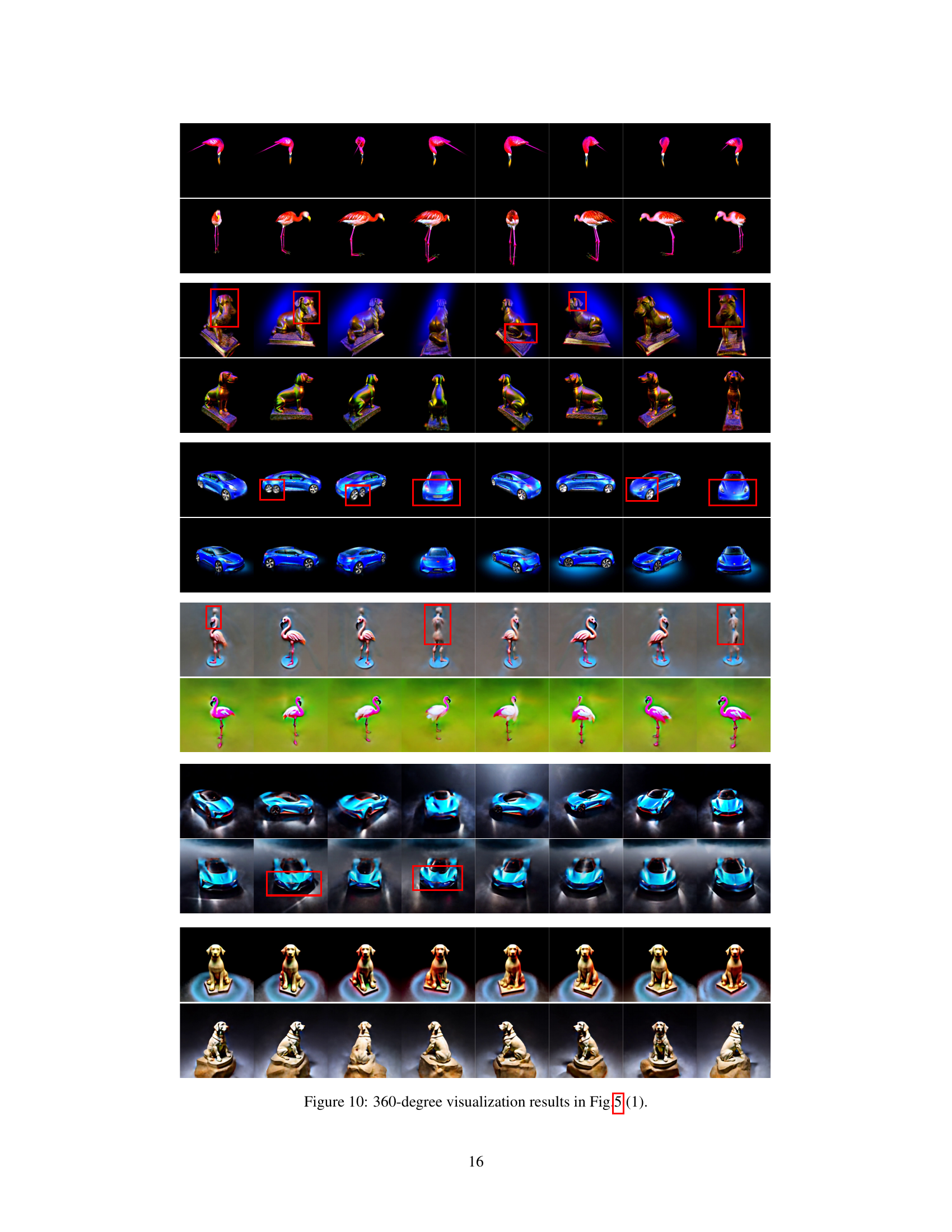
🔼 This figure shows a 360-degree visualization of the 3D models generated by Hallo3D and baseline models for three different prompts from Figure 5. Each row represents a different object (flamingo, dog statue, and sports car) and the images show the 3D renderings from multiple viewpoints around the object. The red boxes highlight specific areas or inconsistencies for comparison.
read the caption
Figure 10: 360-degree visualization results in Fig.5 (1).

🔼 This figure shows a qualitative comparison of 3D models generated by Hallo3D and several baseline methods for three different text prompts. Each row represents a different prompt, showing the results of each method from two different viewpoints (90 and 270 degrees for the first example, 45 and 225 degrees for the second example, and 105 and 285 degrees for the third example). The images demonstrate that Hallo3D produces more consistent and higher-quality 3D models than the baseline methods, especially in terms of multi-view consistency. For example, in the ‘flamingo’ example, the baseline methods produce models with inconsistent details across different viewpoints, while the Hallo3D model has a high level of consistency. This figure supports the paper’s claim that Hallo3D can significantly improve the quality and consistency of generated 3D content by mitigating the hallucinations common with 2D pretrained models.
read the caption
Figure 5: Qualitative comparison in text-driven 3D generation of Hallo3D and baseline models. To provide a more straightforward comparison, we rendered both Hallo3D and the baseline models from two identical and complementary angles.
More on tables

🔼 This table presents the results of a user study conducted to evaluate the performance of Hallo3D and several baseline models in text-driven 3D generation. Three metrics were used to assess the generated 3D models: Multi-view Consistency (measuring consistency across multiple viewpoints), Overall Quality (assessing the overall quality of the 3D model), and Alignment with Prompt (measuring how well the generated model aligns with the text prompt). The table shows the average scores for each model across these three metrics, indicating the relative performance of Hallo3D compared to the baselines.
read the caption
Table 2: User study in text-driven 3D generation

🔼 This table presents the results of a user study comparing the performance of Hallo3D and baseline methods (DreamGaussian and Zero-1-to-3) in image-driven 3D generation. Three metrics are evaluated: Multi-view Consistency (measuring the visual consistency across multiple views), Overall Quality (assessing the overall quality of the generated 3D model), and Alignment with Prompt (evaluating how well the generated model aligns with the input image prompt). Higher scores indicate better performance. The results show that Hallo3D generally outperforms the baseline methods across all three metrics.
read the caption
Table 3: User study in image-driven 3D generation

🔼 This table presents a quantitative comparison of the proposed Hallo3D method against two baseline methods, DreamGaussian and Zero-1-to-3, for image-driven 3D generation. The metrics used for comparison are CD (Chamfer Distance), Vol. IoU (Volume Intersection over Union), PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Lower values are better for CD and LPIPS, while higher values are preferred for Vol. IoU, PSNR, and SSIM. The table shows the performance of each method across all five metrics, highlighting the relative strengths and weaknesses of Hallo3D compared to the baselines.
read the caption
Table 4: Quantitative comparisons in image-driven 3D generation

🔼 This table presents a quantitative comparison of the Hallo3D model and its ablated versions against a baseline model for image-driven 3D generation. The metrics used are CLIP-Score B/32↑, CLIP-Score B/16↑, and CLIP-Score L/14↑. The ablated versions remove different components of the Hallo3D model (Multi-view Appearance Alignment, Multi-modal Hallucination Detection, and Prompt-Enhanced Re-consistency) to assess their individual contributions to the overall performance. Higher scores indicate better performance.
read the caption
Table 4: Quantitative comparisons in image-driven 3D generation

🔼 This table shows the time consumption of two baseline models (GaussianDreamer and DreamFusion) and the additional time introduced by Hallo3D. It demonstrates that Hallo3D adds overhead, but that the added time is relatively small compared to the total runtime of the baselines.
read the caption
Table 6: The time consumption introduced by Hallo3D.
Full paper#