↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing aerial visual localization methods often rely on complex, high-resolution 3D maps, which are expensive to create, maintain, and store. These maps also raise privacy concerns. This is problematic for applications like drone navigation, where resource constraints are significant. This paper addresses these issues by proposing LoD-Loc.
LoD-Loc uses Level of Detail (LoD) 3D maps, which are significantly smaller and less detailed than traditional textured 3D maps, offering advantages in terms of size and privacy. The method cleverly aligns predicted wireframes from a neural network with projected wireframes from the LoD map to estimate the drone’s pose. LoD-Loc demonstrates excellent performance and introduces two new datasets with LoD maps and ground truth data, advancing the state-of-the-art and making significant contributions to the field of aerial visual localization.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to aerial visual localization that addresses the limitations of existing methods. LoD-Loc offers improved efficiency, privacy, and scalability, making it highly relevant for drone applications and advancing the state-of-the-art in visual localization. It also introduces two new datasets, furthering research in this area. The study opens avenues for exploring more efficient and privacy-preserving mapping and localization techniques.
Visual Insights#

The figure shows a schematic of the LoD-Loc method. A drone takes a query image of a scene. The scene is represented by a low-detail (LoD) 3D map which is easier to acquire and maintain than high-detail maps. LoD-Loc uses the wireframe (edges of buildings etc.) from the LoD map to estimate the position and orientation (pose) of the drone. The sensor provides an initial, coarse estimate of the pose. The LoD-Loc method refines this estimate by aligning the predicted wireframe from a neural network to the wireframe projected from the LoD map.
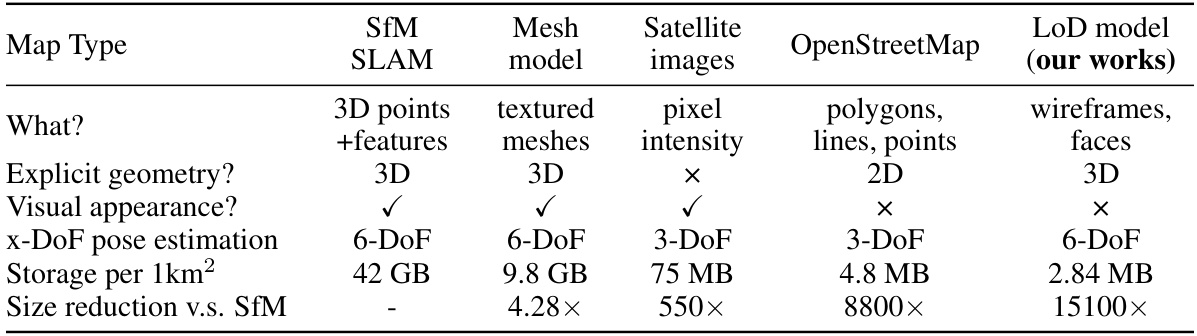
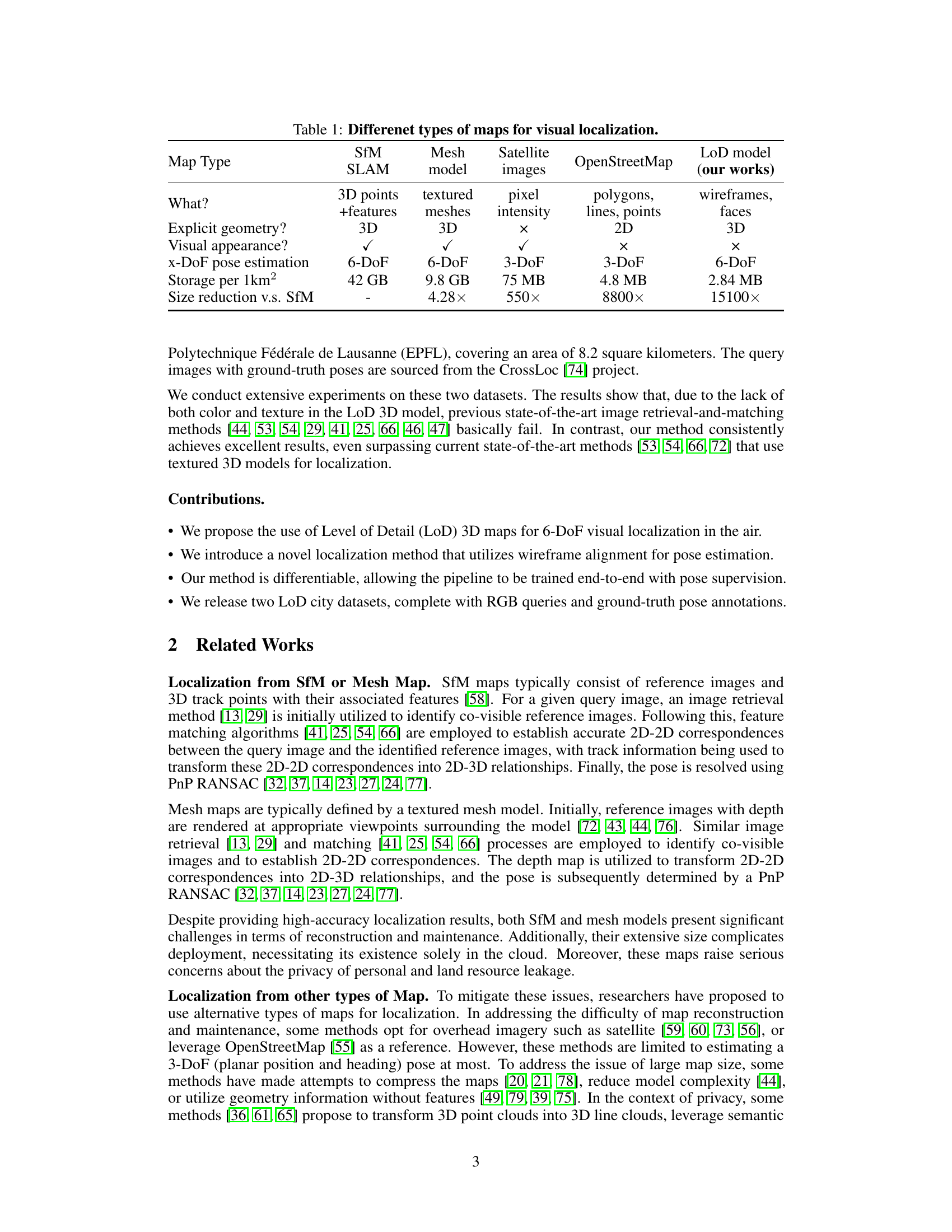
This table compares different types of maps used for visual localization, including SfM, Mesh, Satellite images, OpenStreetMap, and the LoD model used in the proposed method. For each map type, it lists what is explicitly represented (e.g., 3D points, textured meshes, pixels), whether explicit 3D geometry is present, the presence of visual appearance (texture or intensity information), the degrees of freedom (DoF) that can be estimated for camera pose, the storage size per square kilometer, and the size reduction factor compared to SfM-based maps. The LoD model is highlighted as the method proposed in this paper, emphasizing its advantages of 3D geometry, reduced storage requirements, and the ability to estimate a full 6-DoF camera pose.
In-depth insights#
LoD Map Benefits#
Leveraging Level of Detail (LoD) 3D maps for aerial visual localization offers compelling advantages. Reduced map size is a crucial benefit, enabling on-device processing and reducing storage demands, unlike bulky textured 3D models. This lightweight nature is particularly important for resource-constrained aerial platforms like drones. Furthermore, the inherent privacy-preserving characteristics of LoD maps are significant. By abstracting details and focusing on building outlines, they mitigate concerns regarding the disclosure of sensitive information about the localized area, making them a policy-friendly alternative. The ease of acquisition and maintenance is another key factor. LoD maps can be generated using readily available technologies like remote sensing, leading to less expensive and more easily updated maps compared to labor-intensive methods required for high-resolution 3D models. These combined benefits of reduced size, privacy protection, and efficient maintenance make LoD maps a powerful tool for advancing aerial visual localization.
Wireframe Alignment#
Wireframe alignment, in the context of 3D map-based visual localization, presents a novel approach to aerial pose estimation. Instead of relying on complex textured 3D models, this method leverages the skeletal structure of a Level of Detail (LoD) 3D map, reducing computational cost and storage requirements while enhancing privacy. The core idea is to align the wireframe predicted by a neural network from a query image with the wireframe projected from the LoD map, given a coarse pose estimate. This alignment process, often formulated as a cost function measuring the degree of correspondence between predicted and projected wireframes, forms the basis for pose hypothesis scoring and refinement. The use of a differentiable cost function allows for end-to-end training, optimizing both the feature extraction and pose estimation networks. This approach is particularly advantageous for aerial applications given the inherent ease of acquiring and maintaining LoD maps compared to textured 3D models. The hierarchical implementation with multi-scale feature extraction and uncertainty-based sampling further refines accuracy and efficiency.
Hierarchical Pose#
A hierarchical pose estimation approach in visual localization offers a multi-resolution strategy to efficiently and accurately determine the pose of a camera or sensor. It leverages a coarse-to-fine refinement process, starting with a rough initial pose estimate obtained from readily available sensor data or a global localization method. Subsequent levels progressively refine this estimate using increasingly fine-grained information and computational steps. This approach can mitigate computational complexity by limiting the search space at each level, resulting in significant efficiency gains. The hierarchy could involve processing low-resolution features and pose hypotheses at early stages, gradually integrating higher-resolution data and more sophisticated refinement methods to reduce computational cost and improve accuracy. Successful implementation relies on robust feature extraction, accurate cost volume generation, and effective optimization at each level to ensure the hierarchical refinement maintains consistency and enhances localization precision. Addressing ambiguity and noise at coarser levels through careful selection and weighting of pose hypotheses is critical, ensuring stability and accurate final pose estimation. The balance between computational cost and accuracy is a key design challenge for this method.
Dataset Contribution#
The paper’s dataset contribution is significant, offering two novel datasets crucial for advancing aerial visual localization research. The UAVD4L-LoD dataset, with its 2.5 square kilometers of coverage and detailed LoD3.0 models, addresses the lack of high-quality annotated data in this domain. Similarly, the Swiss-EPFL dataset, covering 8.18 square kilometers and using LoD2.0 models, provides a valuable additional resource, particularly for studying performance variations based on different map details. The release of both datasets, including accompanying RGB images and ground-truth pose annotations, promotes reproducibility, facilitates algorithm comparison, and opens up new avenues for exploring visual localization challenges. The use of varied map types (LoD3.0 and LoD2.0) also allows for insightful analyses of model performance under diverse data characteristics. This is a key step towards building a more robust and mature field, as publicly accessible datasets are essential for accelerating future developments.
Future of LoD-Loc#
The future of LoD-Loc hinges on several key advancements. Improving the neural wireframe prediction is crucial; more robust and accurate models will enhance pose estimation, especially in challenging conditions. Expanding the dataset with more diverse scenes and LoD levels is vital for better generalization and handling of varying environments. Addressing the limitations of relying solely on wireframes would significantly broaden its applicability. Integrating texture information or semantic scene understanding would allow for richer feature extraction and more robust matching. Furthermore, exploring efficient hardware acceleration is necessary for real-time performance in resource-constrained aerial platforms. Finally, investigating the potential of multi-sensor fusion with LiDAR or IMU data could further enhance accuracy and reliability, making LoD-Loc a robust and versatile solution for aerial visual localization.
More visual insights#
More on figures

This figure provides an overview of the two datasets used in the paper: UAVD4L-LoD and Swiss-EPFL. The left side shows the Level of Detail (LoD) 3D models for each dataset, highlighting the difference in detail levels between LoD 2.0 and LoD 3.0. The right side displays example query images from each dataset, showcasing the variety of aerial scenes captured by drones.

This figure provides a visual overview of the LoD-Loc method, showing its three main stages. First, a CNN extracts multi-level features from the query image. Second, a cost volume is created to identify the pose with the highest probability, using projected wireframes from the 3D LoD model. Finally, a Gauss-Newton method refines this pose for higher accuracy. The process is hierarchical, refining the pose estimate progressively.

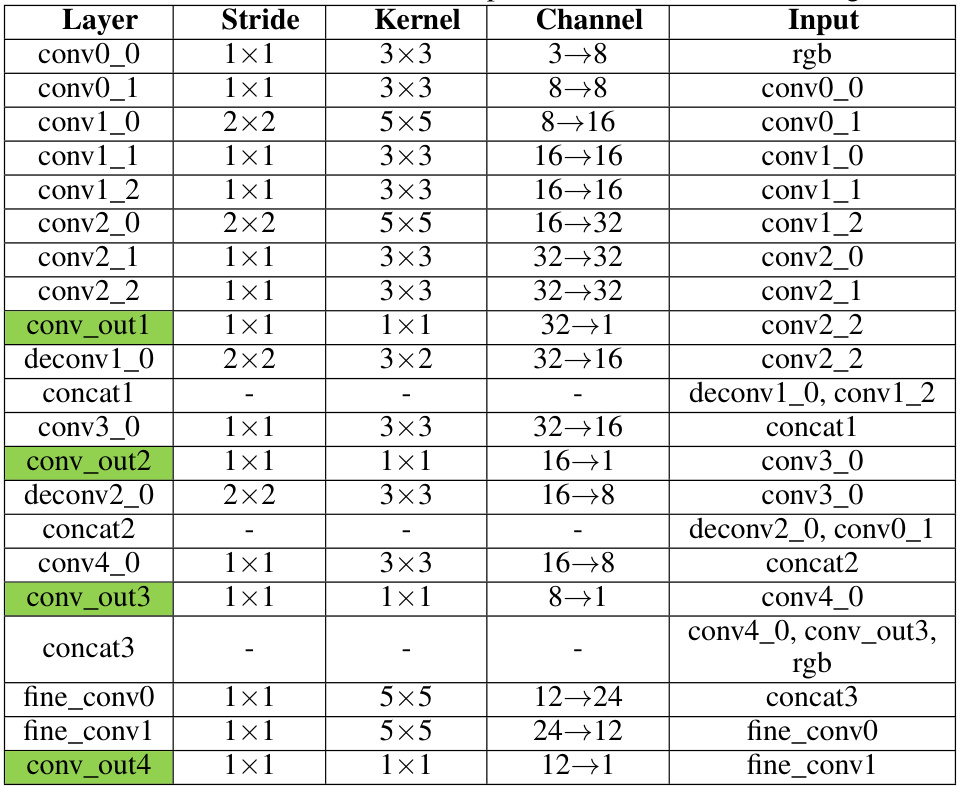
This figure visualizes the feature maps generated by the multi-scale feature extractor at different levels (Level 1, Level 2, Level 3) for both LoD 3.0 and LoD 2.0 datasets. Each level’s feature map shows a progressively finer representation of the wireframe structure extracted from the query image. The ‘Refine’ column shows the final refined feature map after post-processing. The varying degrees of fineness illustrate the effectiveness of the multi-scale approach in capturing wireframe details at different levels of granularity.

This figure shows the flight paths of the UAV during data collection for the UAVD4L-LoD dataset. The left panel displays the planned flight path (‘in-Traj’), which is a structured, zig-zag pattern covering roughly half the map area. The right panel shows the less structured, free-form flight path (‘out-of-Traj’) which covered a wider area of the map more randomly.

This figure provides a high-level overview of the LoD-Loc method. It shows the three main stages of the process: feature extraction using a convolutional neural network, pose selection from a cost volume based on the alignment of projected and predicted wireframes, and pose refinement using a differentiable Gauss-Newton method. The figure illustrates the flow of data through each stage and highlights the key components involved in achieving accurate 6-DoF pose estimation.

This figure shows a comparison of the projected wireframes onto query images using both sensor-estimated poses (Priors) and ground-truth poses (GT). It visually demonstrates the accuracy of the pose estimation by showing how well the projected wireframes align with the actual building edges in the images. The left side displays the in-Traj. (trajectory-based) results, while the right shows out-of-Traj. (free-flight) results, allowing for a comparison between different flight scenarios.

This figure shows examples of query images from the Swiss-EPFL dataset that were either mislabeled (top row) or selected (bottom row) after manual inspection. The mislabeled images show a poor alignment between the projected wireframe and the actual building structures in the RGB image. This indicates that the ground truth pose information associated with these images is inaccurate. In contrast, the selected images demonstrate good alignment, suggesting accurate ground truth pose data. The manual selection process helps to improve the quality and reliability of the dataset by removing images with erroneous pose labels.

This figure shows a comparison of RGB and depth maps generated from two different types of 3D models: mesh-based and LoD-based. The mesh-based models provide detailed textures and depth information, while the LoD-based models offer simplified wireframe representations with less detailed depth information. This visual comparison highlights the key difference in the level of detail between these two map types, which is a crucial aspect of the paper’s approach to aerial visual localization.
This figure provides a visual overview of the two datasets used in the LoD-Loc research. The left panel displays the Level of Detail (LoD) 3D models used for localization, showcasing the difference in detail between LoD2.0 (from Swiss-EPFL, showing building height and roof) and LoD3.0 (from UAVD4L-LoD, including additional structural elements like side pillars). The right panel shows examples of query images captured by drones, offering a visual representation of the dataset’s scene variety.

This figure provides a visual overview of the two datasets used in the paper: UAVD4L-LoD and Swiss-EPFL. The left side displays the LoD models (Level of Detail 3D city maps), showcasing the different levels of detail available in each dataset. The LoD2.0 model (from Swiss-EPFL) shows basic building outlines and roof information, while the LoD3.0 model (from UAVD4L-LoD) includes more detailed information such as building height, roof structure, and side pillars. The right side shows example query images (captured by drones), illustrating the variety of scenes and perspectives included in both datasets.

This figure shows examples where baseline methods (UAVD4L and CadLoc) failed to retrieve relevant images even with a narrowed search scope. The failures are attributed to challenges in handling repetitive textures and cross-modal inconsistencies between the query images and the reference images in the database.

This figure shows examples where baselines (CadLoc and UAVD4L) fail to match images. The failures highlight the challenges posed by variations in viewpoint and differences in data modality (e.g., textured meshes versus wireframes) when trying to establish accurate correspondences for localization.

This figure provides an overview of the two datasets used in the paper: UAVD4L-LoD and Swiss-EPFL. The left side displays the different levels of detail (LOD) in the 3D models used for each dataset, showing that the LoD3.0 model (UAVD4L-LoD) provides more detailed building information than the LoD2.0 model (Swiss-EPFL). The right side shows example query images captured by drones in various scenes, illustrating the types of aerial imagery used for localization in the study. This highlights the different levels of detail in the maps and the variety of scenarios represented in the datasets.
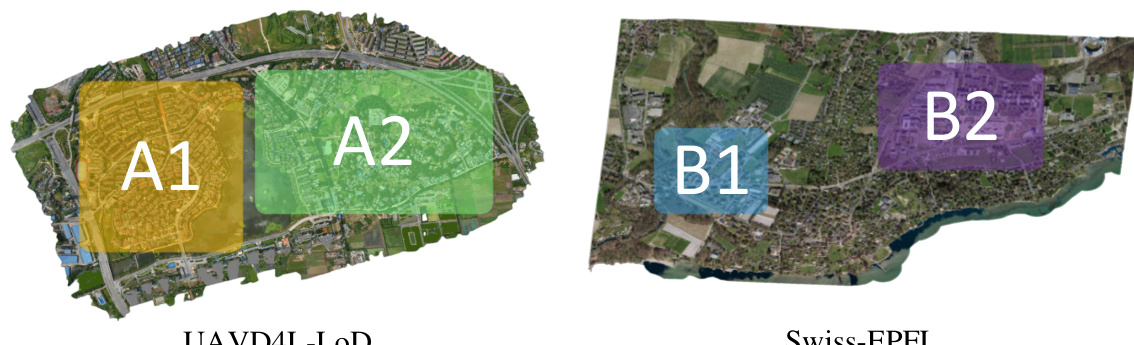
This figure shows the regions used for training and testing in the UAVD4L-LoD and Swiss-EPFL datasets. The UAVD4L-LoD dataset is divided into two regions (A1 and A2), represented by yellow and green boxes respectively. The Swiss-EPFL dataset is also divided into two regions (B1 and B2), represented by light blue and purple boxes respectively. The different colors and symbols help to visually distinguish the different regions used for training and evaluating the model’s performance.
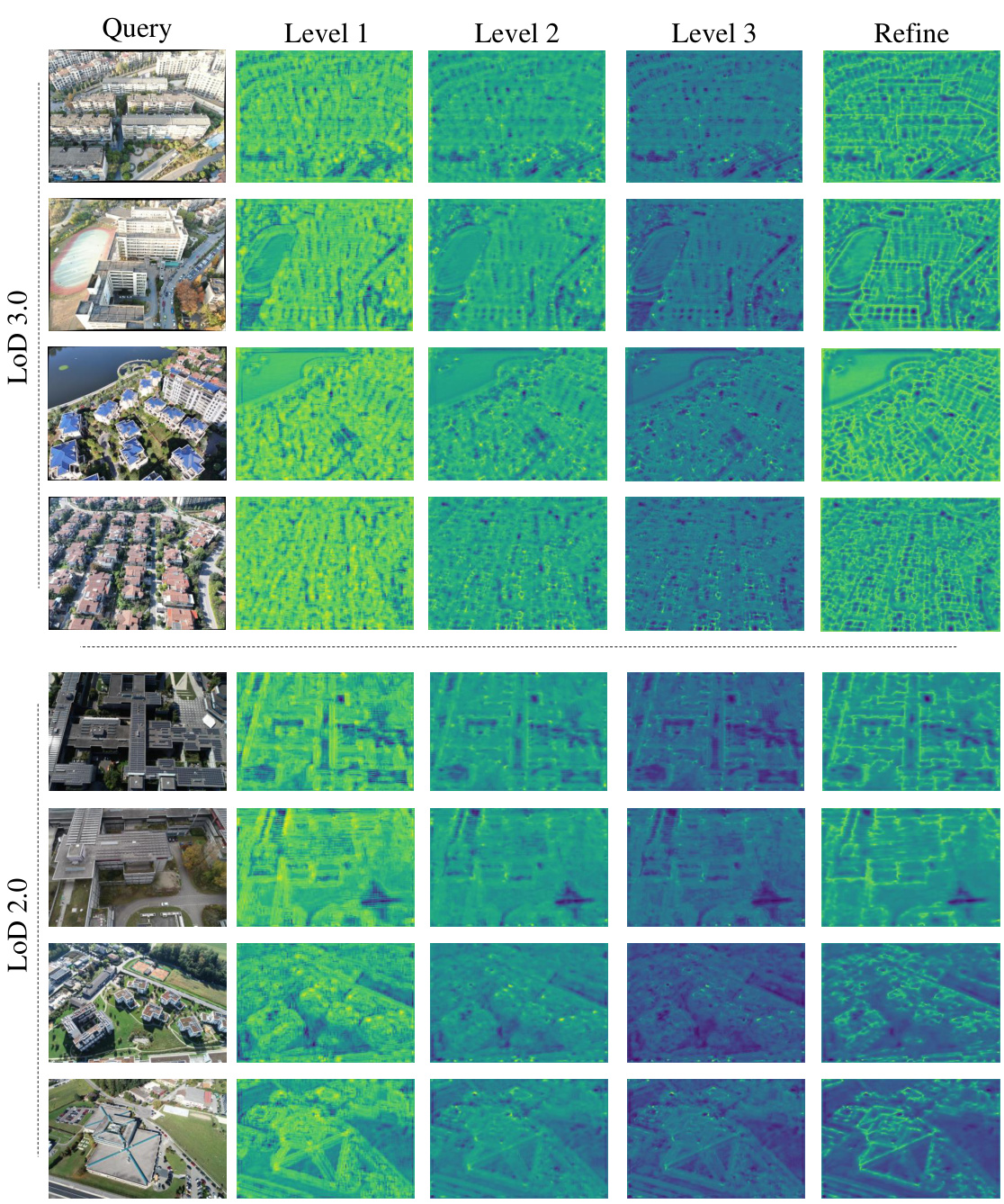
This figure visualizes the feature maps generated by the multi-scale feature extractor at different levels (Level 1, Level 2, Level 3) of the LoD-Loc model. The query images are shown for comparison. The feature maps are single-channel images where pixel intensity represents the likelihood of a wireframe. The figure illustrates how the network progressively refines its wireframe extraction, with finer details captured at deeper levels. This showcases the hierarchical nature of the feature extraction process in LoD-Loc, enhancing its accuracy and efficiency in wireframe detection.

This figure shows the visualization of predictions at different levels of the LoD-Loc method. It displays how the projected wireframes, generated using predicted poses at each level (Priors, Level 1, Level 2, Level 3, Refine), align more accurately with the edges of buildings in the query images as the process progresses. The results are shown separately for the UAVD4L-LoD and Swiss-EPFL datasets.
More on tables
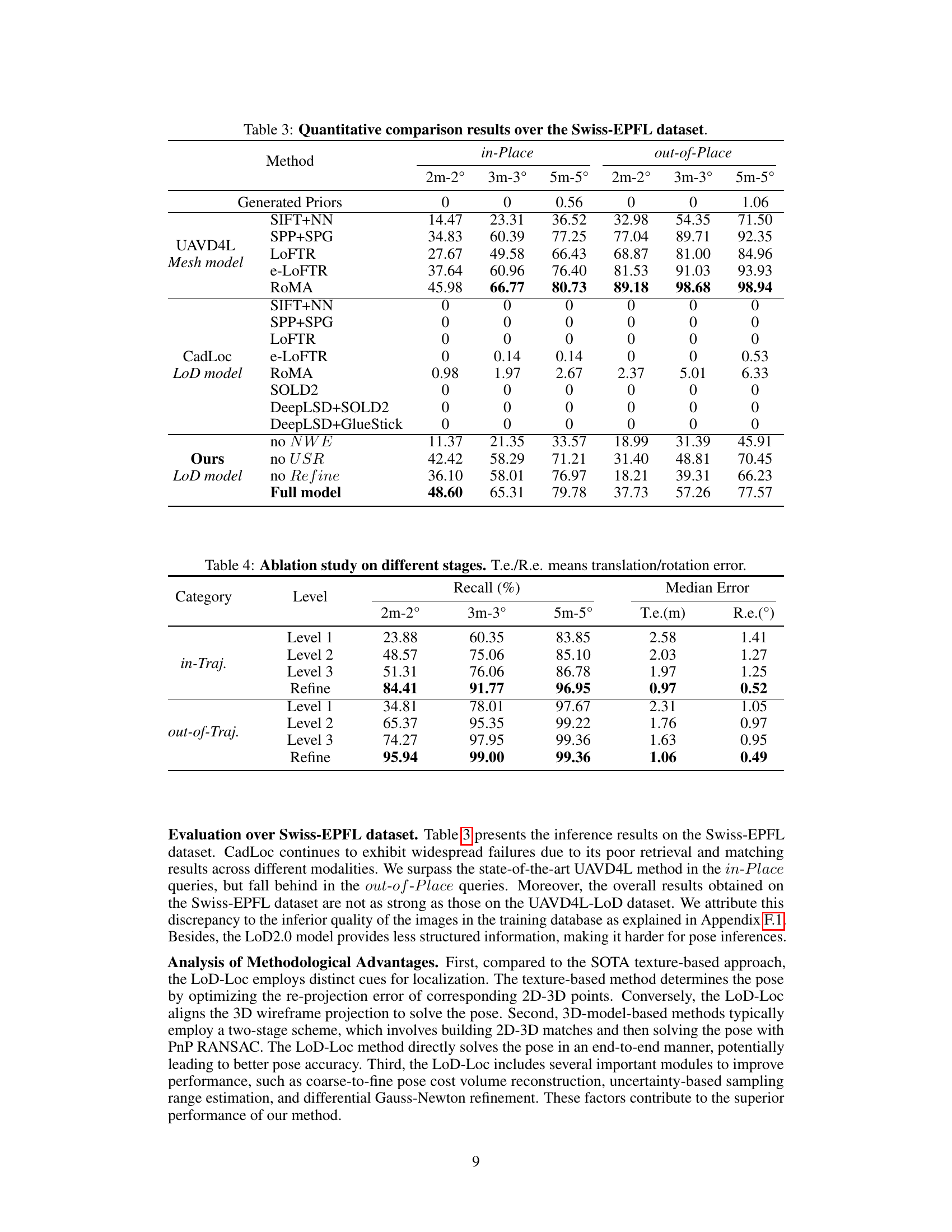
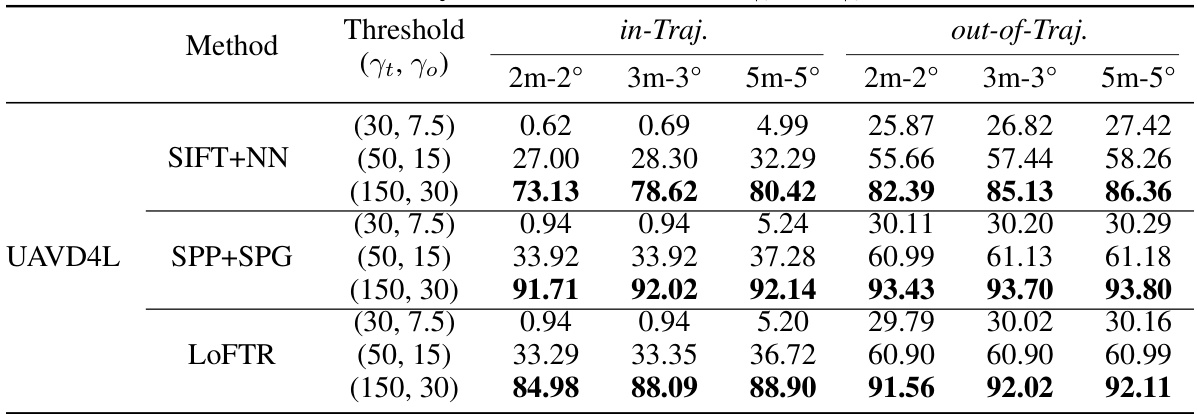
This table presents a quantitative comparison of the proposed LoD-Loc method against several baselines on the UAVD4L-LoD dataset. The baselines represent various combinations of feature extractors and matchers, categorized by the type of map used (mesh model or LoD model). The table shows the recall rate (percentage of correctly localized poses) at different thresholds of position and orientation error (2m-2°, 3m-3°, and 5m-5°). Separate results are given for ‘in-trajectory’ and ‘out-of-trajectory’ queries, indicating the robustness of the method across different flight patterns.
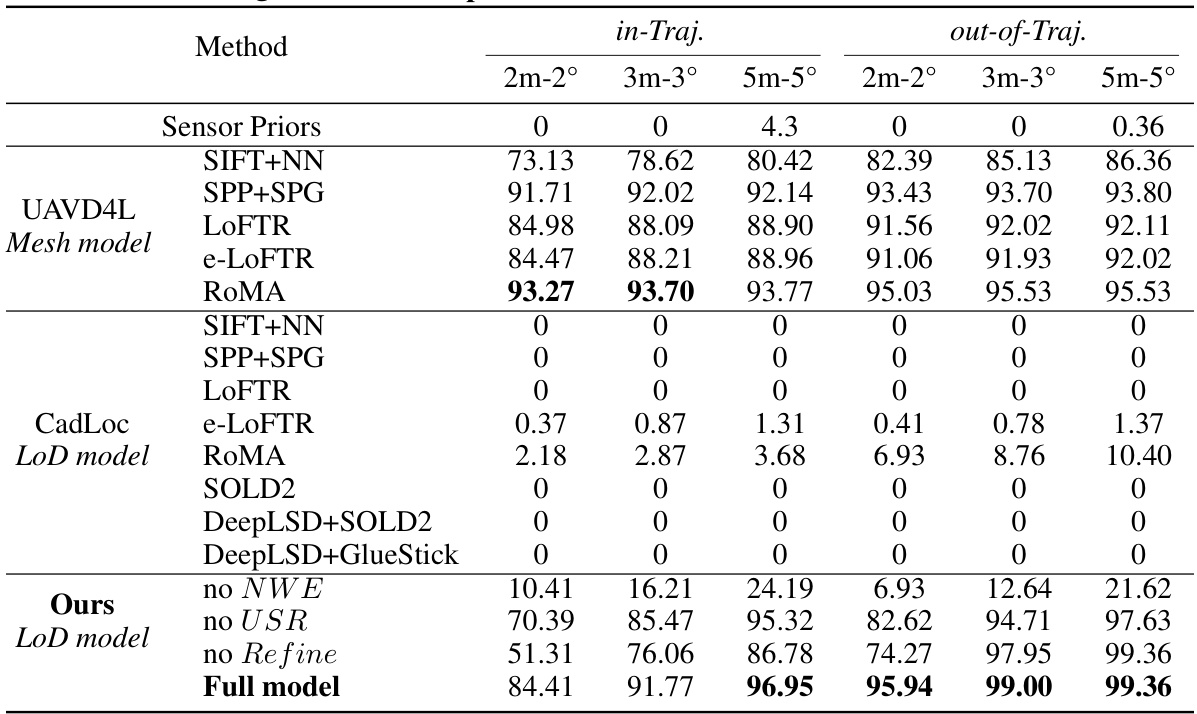
This table presents a quantitative comparison of different visual localization methods on the UAVD4L-LoD dataset. It compares the performance of various methods, including those using textured mesh models (UAVD4L) and LoD models (CadLoc), against the proposed LoD-Loc method. The comparison is based on recall rates at different accuracy thresholds (2m-2°, 3m-3°, and 5m-5°), distinguishing between ‘in-trajectory’ and ‘out-of-trajectory’ query images. The results show the effectiveness of the LoD-Loc approach, particularly when compared to methods that rely on more complex 3D models.
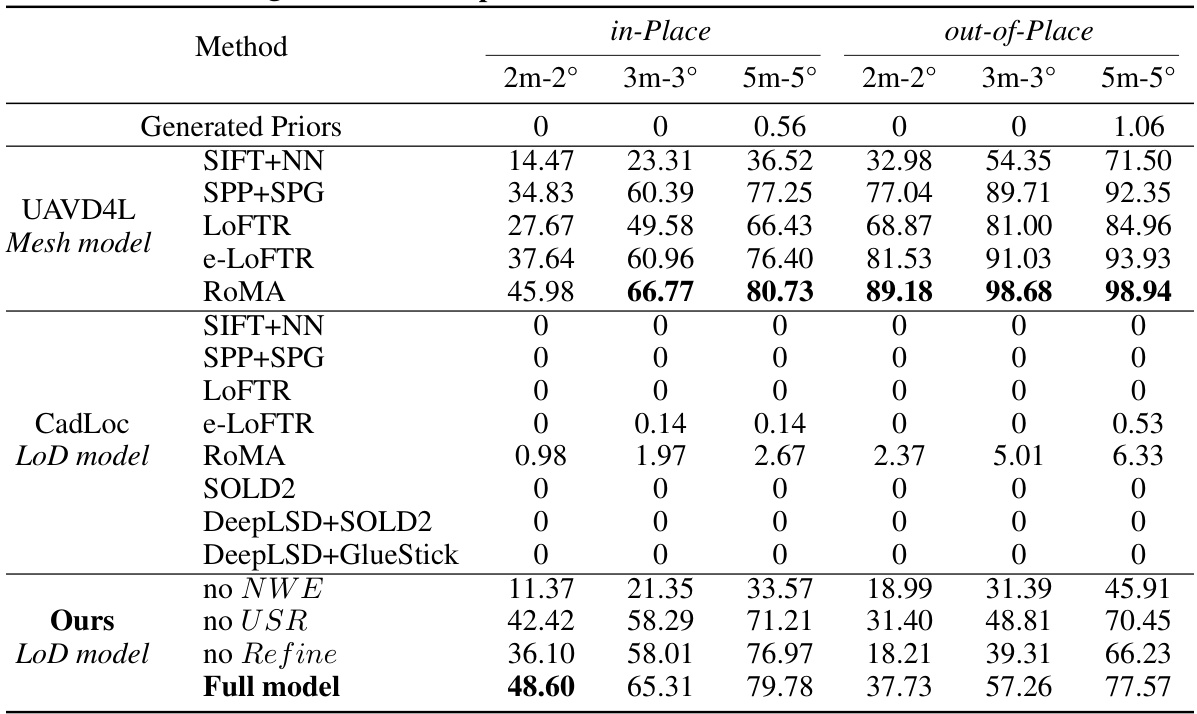
This table presents a quantitative comparison of different visual localization methods on the UAVD4L-LoD dataset. It compares the performance of various methods, including baselines using different feature extractors and matchers (SIFT, SPP+SPG, LOFTR, e-LOFTR, RoMA), and the proposed LoD-Loc method with several ablative variations. The comparison is done using metrics such as recall at different thresholds (2m-2°, 3m-3°, 5m-5°), for both in-trajectory and out-of-trajectory queries. This allows for a comprehensive evaluation of the proposed LoD-Loc’s performance relative to state-of-the-art methods.

This table presents a quantitative comparison of different visual localization methods on the UAVD4L-LoD dataset. It shows the recall rate at different accuracy thresholds (2m-2°, 3m-3°, and 5m-5°) for both in-trajectory and out-of-trajectory queries. The methods compared include various baselines using different feature extractors and matchers, as well as the proposed LoD-Loc method with different configurations (full model, no neural wireframe estimation, no uncertainty sampling range estimation, and no pose refinement). The results demonstrate the superior performance of the proposed LoD-Loc method, especially in out-of-trajectory scenarios.

This table compares different types of maps used for visual localization, including SfM, Mesh, Satellite, OpenStreetMap, and LoD models. For each map type, it lists what the map represents (e.g., 3D points, textured meshes, pixels), whether it has explicit 3D geometry, the visual appearance (texture), the degrees of freedom (DoF) for pose estimation, the storage size per square kilometer, and the size reduction compared to Structure from Motion (SfM). The table highlights the advantages of LoD models in terms of size, ease of acquisition and maintenance, and privacy.
This table compares different types of maps used for visual localization, including SfM, Mesh, Satellite, OpenStreetMap, and LoD models. The comparison covers aspects such as the type of 3D representation used (points, meshes, pixels, polygons, wireframes), whether explicit geometry is present, visual appearance (texture), the degrees of freedom in pose estimation, and the storage size per square kilometer. The LoD model is highlighted as the method proposed in the paper, emphasizing its smaller size and suitability for aerial localization.
This table presents a quantitative comparison of different visual localization methods on the UAVD4L-LoD dataset. It compares the performance of various methods (using different map types and feature extraction techniques) across different recall thresholds (2m-2°, 3m-3°, and 5m-5°), evaluating both in-trajectory and out-of-trajectory localization accuracy. The methods are categorized by the type of map used (mesh model or LoD model). The table highlights the superior performance of the proposed LoD-Loc method, especially when compared to other approaches using LoD maps.

This table presents a quantitative comparison of different visual localization methods on the UAVD4L-LoD dataset. It compares the performance of several baselines (using various feature extractors and matchers) against the proposed LoD-Loc method. The results are broken down by different recall thresholds (2m-2°, 3m-3°, 5m-5°) for both in-trajectory and out-of-trajectory query images. This allows for a comprehensive evaluation of accuracy and robustness under various conditions.
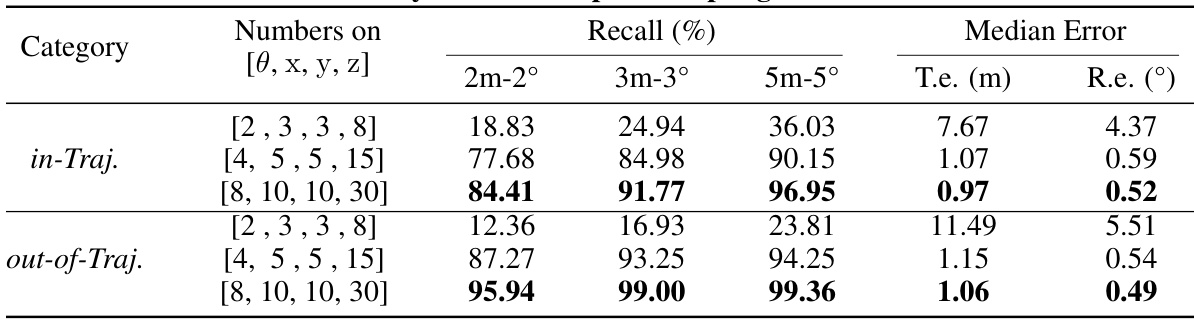
This table presents the results of an ablation study conducted on the LoD-Loc model. The study varied the number of pose samples used during the pose selection stage. The results are presented for two categories: in-trajectory (in-Traj.) and out-of-trajectory (out-of-Traj.). For each sampling scheme, the table reports the recall at different thresholds (2m-2°, 3m-3°, and 5m-5°), as well as the median translation error (T.e.) and rotation error (R.e.). The results show how the accuracy changes as the sampling density changes.
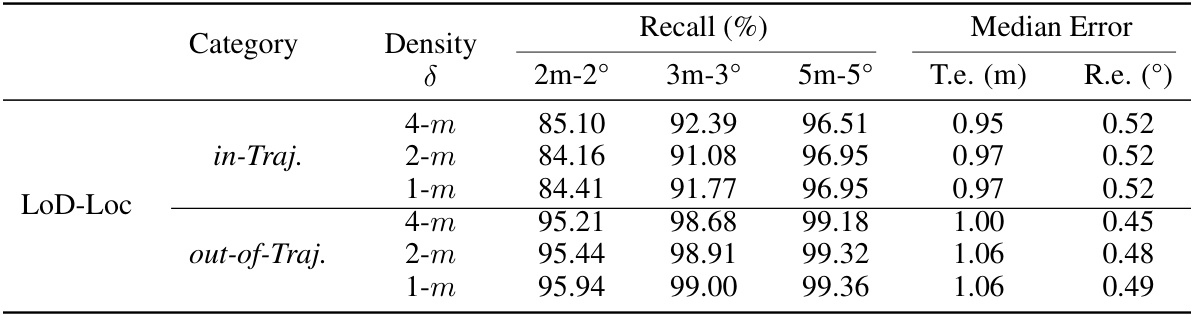
This ablation study analyzes the impact of different wireframe sampling densities on the localization performance of the LoD-Loc method. It examines three densities: 4 meters per wireframe, 2 meters per wireframe, and 1 meter per wireframe, assessing their effects on the recall rate at different thresholds (2m-2°, 3m-3°, 5m-5°) and median translation/rotation errors. The results help determine the optimal sampling density for balancing accuracy and computational efficiency.

This table presents the results of an ablation study conducted to evaluate the impact of different stages in the proposed LoD-Loc method on localization performance. The study varies the number of levels in the multi-scale feature extraction process, and whether the pose refinement step is included. Results are reported as recall percentages at different error thresholds (2m-2°, 3m-3°, 5m-5°) and as median translation and rotation errors.
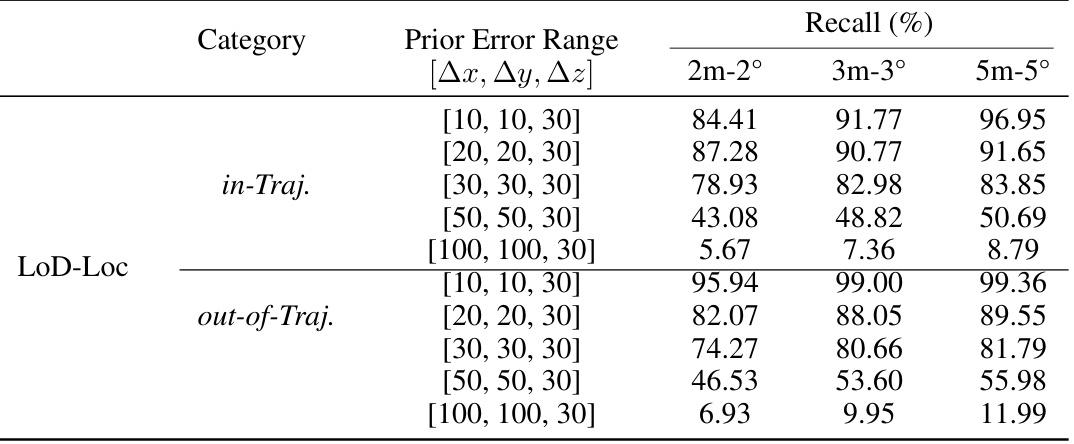
This table presents a quantitative comparison of different visual localization methods on the UAVD4L-LoD dataset. The methods are categorized into three groups: sensor priors (methods using only sensor data), UAVD4L (methods using a textured mesh model), and CadLoc (methods using a LoD model). The performance of each method is evaluated using three metrics (2m-2°, 3m-3°, 5m-5°), representing the recall rate at different pose error thresholds. The table shows the performance of the proposed LoD-Loc method, as well as ablation studies (removing the neural wireframe estimation, uncertainty sampling range, or refinement step) to demonstrate the contributions of each component.
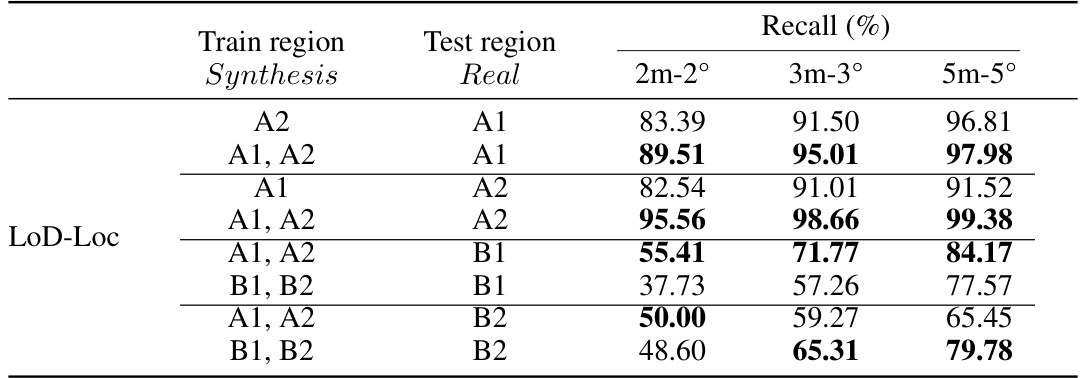
This table presents a quantitative comparison of different methods for visual localization on the UAVD4L-LoD dataset. It compares the performance of various methods, including baselines using different types of maps (mesh model and LoD model) and feature extractors, against the proposed LoD-Loc method. The performance is evaluated using three metrics (2m-2°, 3m-3°, and 5m-5°), representing the recall rate at different accuracy thresholds for pose estimation. The table is split into two parts: ‘in-Traj.’ and ‘out-of-Traj.’, indicating results for sequences captured during trajectory-based flights and free-flight scenarios respectively. It showcases the superior performance of LoD-Loc compared to state-of-the-art methods, particularly in challenging ‘out-of-Traj’ scenarios.
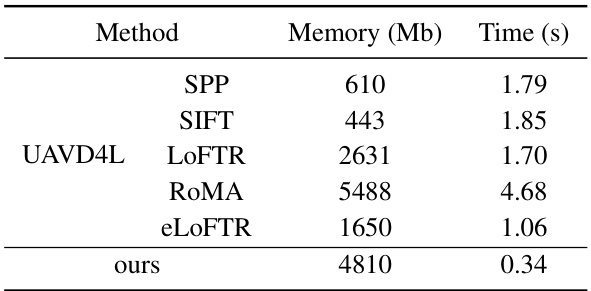
This table compares different types of maps used for visual localization, highlighting their characteristics such as the type of 3D representation (points, meshes, images, polygons, lines, wireframes), explicit geometry, visual appearance, degrees of freedom (DoF) for pose estimation, storage size per square kilometer, and size reduction compared to Structure from Motion (SfM) maps. It shows that LoD models offer a good balance between accuracy and efficiency.
Full paper#