↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-modal contrastive representation (MCR) learning aims to align diverse modalities within a shared space. Existing methods heavily rely on large-scale, high-quality paired data and expensive training, limiting their applicability to more than three modalities. A recent method, C-MCR, attempts to address this by connecting pre-trained spaces via overlapping modalities; however, it still faces challenges in building unified embedding spaces, especially with more modalities and often loses information in the process.
Ex-MCR overcomes these limitations by proposing a training-efficient and paired-data-free approach. It extends one modality’s space into another, rather than mapping both to a new space, thereby preserving semantic alignment in the original space. Experiments show that Ex-MCR achieves comparable or superior performance to existing methods on various tasks, demonstrating its efficacy and scalability in handling multiple modalities without relying on paired data. The method also showcases emergent semantic alignment between extended modalities (e.g., audio and 3D).
Key Takeaways#
Why does it matter?#
This paper is important because it presents Ex-MCR, a novel method for efficient and paired-data-free multi-modal contrastive representation learning. It addresses the limitations of existing methods by extending, rather than connecting, pre-trained spaces, resulting in improved performance and scalability. This approach has significant implications for various applications, such as audio-visual, 3D-image-text retrieval and object classification, and opens new avenues for research in efficient multi-modal learning.
Visual Insights#
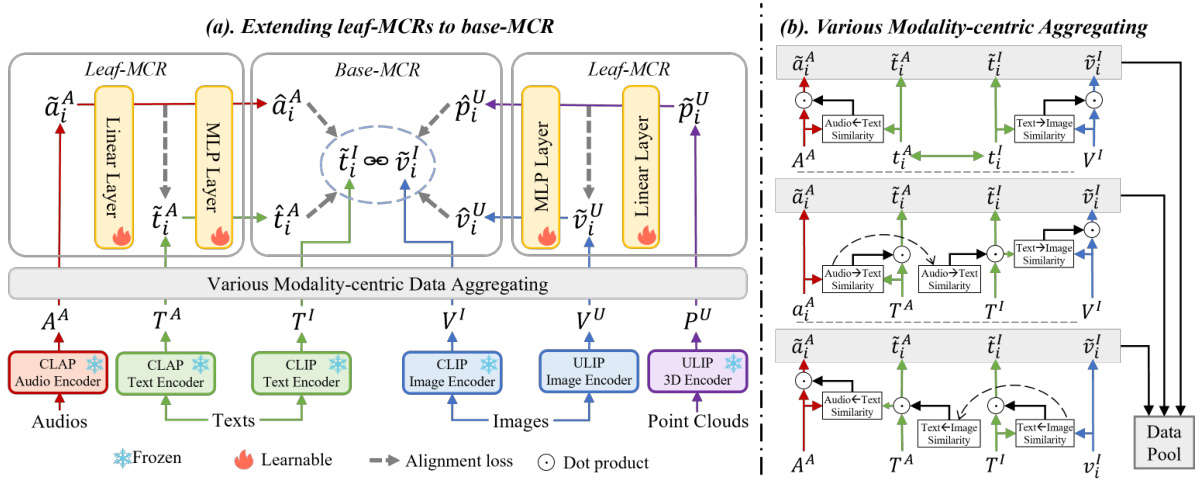
This figure illustrates the architecture of Ex-MCR, a method for extending multi-modal contrastive representations. Panel (a) shows how leaf spaces (pre-trained models for specific modalities) are extended into a base space (a pre-trained model for a set of overlapping modalities) using projectors and preserving alignment. The base space is kept frozen during training. Panel (b) details the various modality-centric aggregating process, which involves iteratively using modalities as queries to find and aggregate semantically similar embeddings from other modalities to create a comprehensive data pool for training.
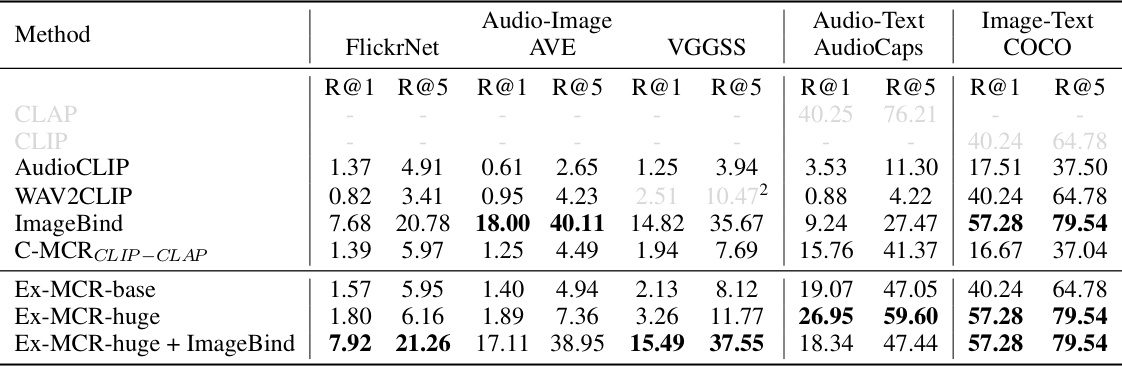
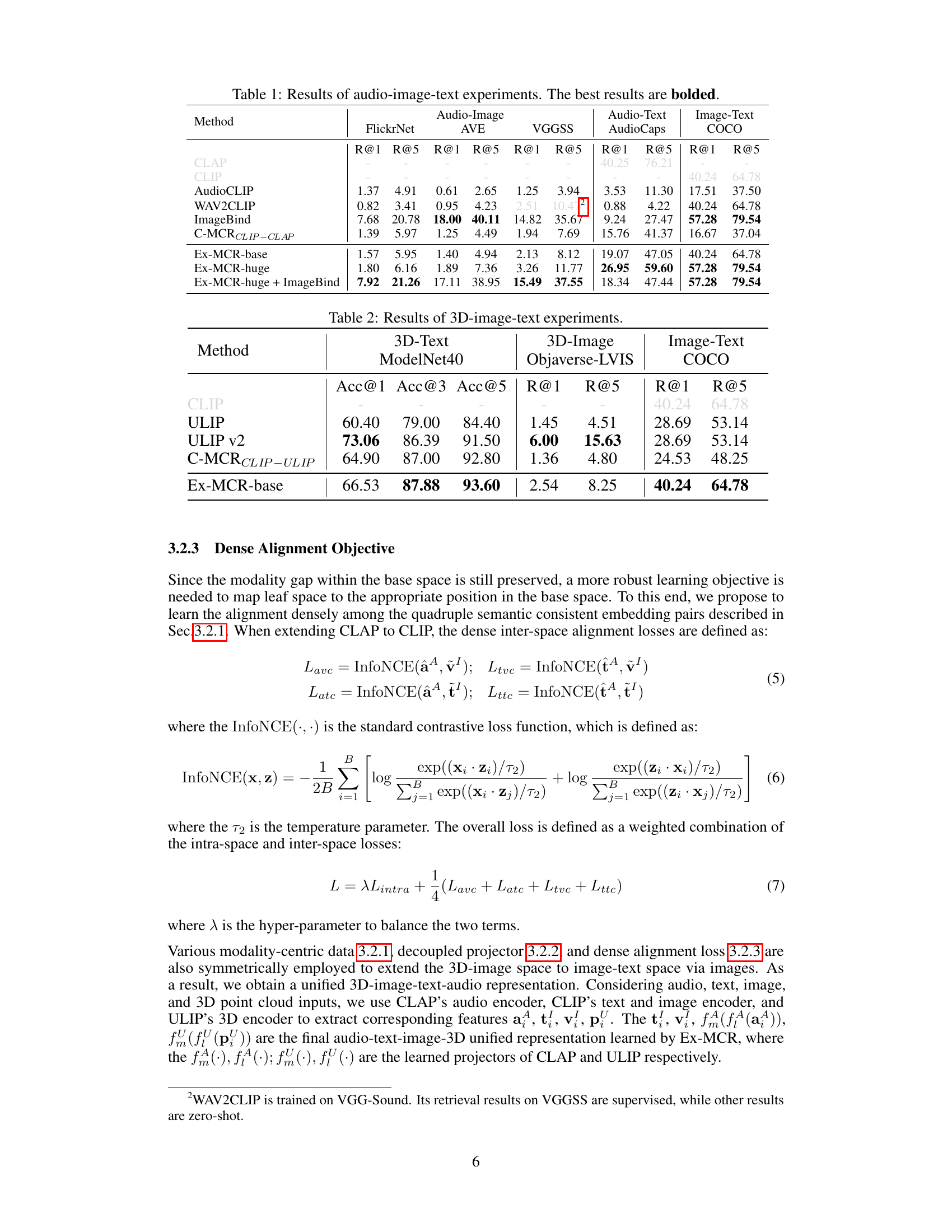
This table presents the results of audio-image-text experiments comparing different methods. The performance is measured by Recall@1 and Recall@5 for audio-image, audio-text, and image-text retrieval tasks on three datasets: FlickrNet, AVE, and COCO. The best results for each metric and dataset are shown in bold. The methods compared include CLAP, CLIP, AudioCLIP, WAV2CLIP, ImageBind, C-MCR, and Ex-MCR (with two versions, base and huge, and a combination with ImageBind).
In-depth insights#
Multimodal Contrastive Learning#
Multimodal contrastive learning (MCL) aims to learn joint representations for multiple modalities (e.g., image, text, audio) by maximizing the agreement between different views of the same data. A core concept is contrastive learning, which learns by pushing together embeddings from different views of the same data point while pulling apart those from different data points. MCL leverages the strengths of each modality, creating richer, more robust representations than unimodal methods. However, challenges remain: handling misaligned or missing data across modalities and scaling effectively to a large number of modalities pose significant hurdles. Efficient training strategies are crucial, given the potential computational cost of training models on multimodal data. Future directions include exploring novel architectures optimized for efficiency and robustness, and developing methods to handle incomplete or noisy multimodal data more effectively, particularly in handling real-world scenarios where perfect alignment isn’t always guaranteed. Ultimately, successful MCL opens the door to powerful applications in areas like cross-modal retrieval, generation, and understanding.
Extending MCR#
The concept of “Extending MCR” suggests a significant advancement in multi-modal contrastive representation learning. Instead of simply connecting pre-trained spaces, as in previous C-MCR methods, this approach focuses on extending one modality’s representation space into another. This is crucial because it avoids the information loss inherent in mapping both modalities onto a completely new space. By extending one space into another, semantic alignment within the original space is better preserved, leading to more robust and effective multi-modal representations. The proposed method leverages the intrinsic alignment present in pre-trained spaces, making it efficient and suitable for handling more than three modalities, unlike previous approaches. This space extension technique addresses a critical limitation of earlier methods, paving the way for more comprehensive and scalable multi-modal learning. The benefits include significantly lower training costs and reduced reliance on large-scale, high-quality paired data. This extension methodology shows promise in effectively preserving semantic relationships and creating unified representations for diverse modalities, thus improving performance in various downstream tasks.
Data-Free Alignment#
Data-free alignment in multi-modal learning tackles the challenge of aligning representations from different modalities without relying on paired training data. This approach is crucial for efficiency and scalability, especially when dealing with numerous modalities or limited resources. The core idea revolves around leveraging existing pre-trained models and their inherent semantic alignments. By cleverly exploiting overlapping modalities as bridges, these methods can transfer alignment knowledge from well-trained spaces to less-explored ones, reducing the need for extensive paired data collection and training. A key aspect is the design of effective mechanisms to preserve semantic relationships within the original spaces while establishing new links between non-overlapping ones. This often involves specialized architectures and loss functions that carefully guide the alignment process. While highly promising, data-free alignment is not without its limitations; its success hinges on the quality and type of pre-trained models, and it might struggle to capture nuanced relationships if the initial spaces aren’t sufficiently aligned. The exploration of more robust and generalizable techniques for data-free alignment is a key area for future research.
Unified Representation#
The concept of “Unified Representation” in multi-modal learning aims to create a shared embedding space where information from different modalities (e.g., text, image, audio) can be meaningfully integrated and compared. Effective unified representation is crucial because it enables models to understand the relationships and correlations between various data types, going beyond the limitations of unimodal processing. The challenge lies in finding a suitable representation that captures the essence of each modality while allowing for seamless integration and preventing information loss. Methods for achieving unified representation often involve contrastive learning, where similar instances from different modalities are pushed closer together in the embedding space, while dissimilar instances are pushed further apart. However, this process can be computationally expensive and highly reliant on large paired datasets. Therefore, research focuses on developing efficient and data-frugal approaches, such as techniques that leverage pre-trained models or utilize pseudo-labels. Ultimately, a successful unified representation facilitates cross-modal reasoning, enabling applications such as zero-shot learning, multimodal retrieval, and generation tasks. Future directions will likely involve exploring more sophisticated architectures and loss functions, and addressing issues related to scalability and data bias.
Future Directions#
Future research should prioritize extending Ex-MCR’s capabilities to handle even more modalities, potentially incorporating diverse data types like sensor readings or physiological signals. Investigating alternative loss functions beyond the dense contrastive loss employed could lead to more robust and efficient alignment. Exploring the use of larger and more sophisticated pre-trained models as base spaces would be crucial to further improve performance, especially on complex tasks involving nuanced semantic relationships. Further research could delve into analyzing the emergent semantic alignments between extended modalities to gain a deeper understanding of the mechanisms underlying Ex-MCR’s success. Finally, rigorous benchmarking against a wider array of tasks and datasets would solidify its practical value and highlight areas needing further improvement.
More visual insights#
More on figures

This figure illustrates the Ex-MCR pipeline. Panel (a) shows how leaf spaces (containing modalities not present in the base space) are extended into the base space via an overlapping modality. The base space remains frozen. Panel (b) details the method used when extending the audio-text space, showing the iterative querying of texts, audio, and images to generate semantically consistent embeddings, and how these are combined to create the modality-centric data pool.

This figure illustrates the Ex-MCR pipeline. Panel (a) shows how leaf spaces (containing modalities not shared between the leaf and base spaces) are extended into a base space (a pre-trained model like CLIP) through an overlapping modality. Panel (b) details the ‘Various Modality-centric Aggregating’ strategy, where audio, text, and image data are used iteratively as queries to find related embeddings from other modalities to improve alignment and build a comprehensive representation.
More on tables
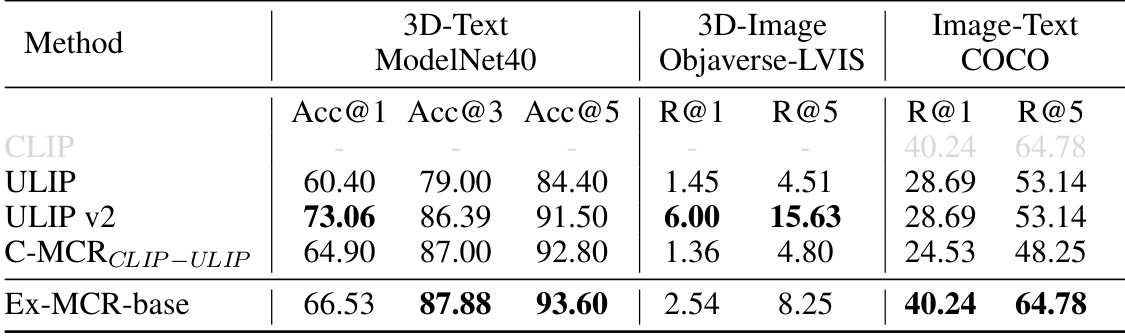
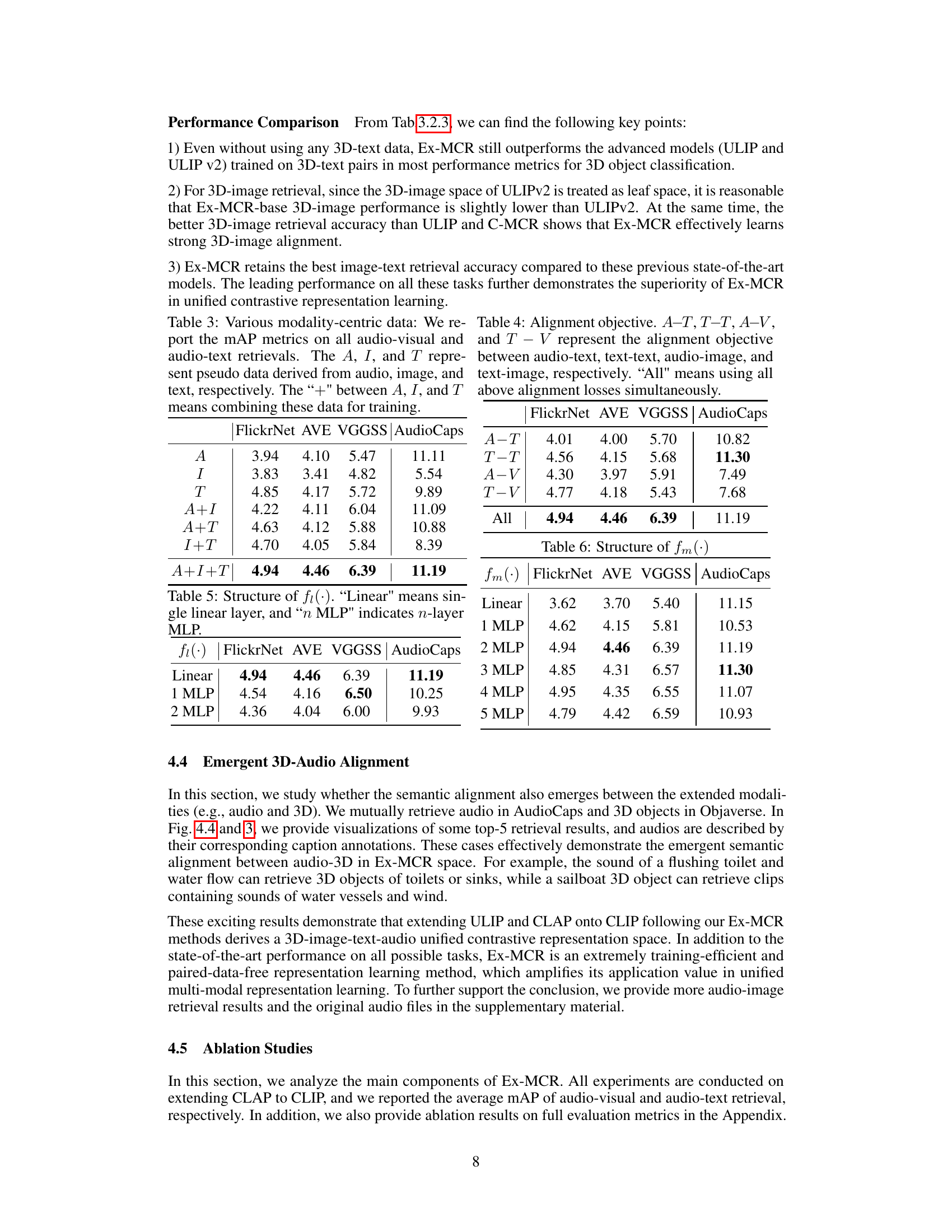
This table presents the results of experiments evaluating the performance of different methods on 3D-image-text tasks. It compares several methods (CLIP, ULIP, ULIP v2, C-MCRCLIP-ULIP, and Ex-MCR-base) across three metrics: 3D-Text (ModelNet40 dataset, using Acc@1, Acc@3, and Acc@5), 3D-Image (Objaverse-LVIS dataset, using R@1 and R@5), and Image-Text (COCO dataset, using R@1 and R@5). The metrics assess the accuracy and retrieval performance of each method in various aspects of 3D and image-text understanding. Ex-MCR-base is shown to be competitive with or exceeding the state-of-the-art methods, especially for image-text tasks.

This table presents ablation study results on the structure of the projector fi(·), which is responsible for aligning modalities within the leaf space. It compares the performance of using a single linear layer versus multiple-layer perceptrons (MLPs) with varying numbers of layers (1, 2). The results are presented in terms of mean Average Precision (mAP) and Recall@5 (R@5) metrics across four datasets: FlickrNet, AVE, VGGSS, and AudioCaps.
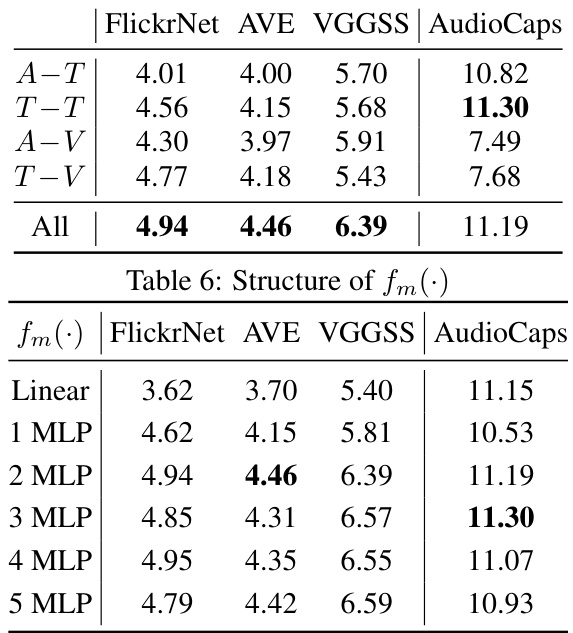
This table presents the ablation study results on the structure of the fm(·) projector within the Ex-MCR model. The fm(·) projector is responsible for inter-space alignment, mapping the leaf space embeddings to the base space. The table shows the performance (mAP and R@5) on four different datasets (FlickrNet, AVE, VGGSS, and AudioCaps) using various structures for fm(·), ranging from a simple linear layer to a multi-layer perceptron (MLP) with up to 5 layers. The results indicate the optimal number of layers in the MLP for best performance across the different datasets.
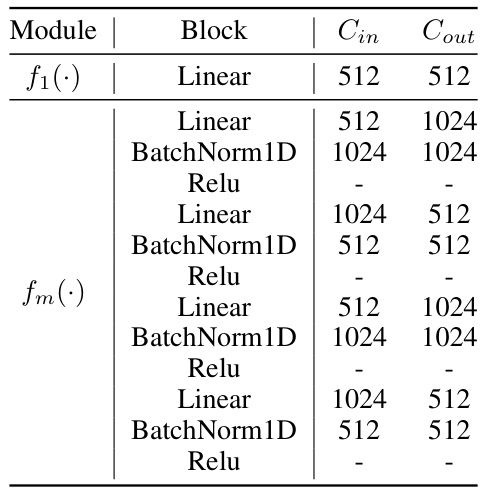
This table shows the detailed architecture of the two projectors used in the Ex-MCR model. The table specifies the layers (Linear, BatchNorm1D, Relu) and their input and output dimensions (Cin, Cout) for each projector, f1 and fm. Projector f1 focuses on intra-space alignment, while fm focuses on inter-space alignment.
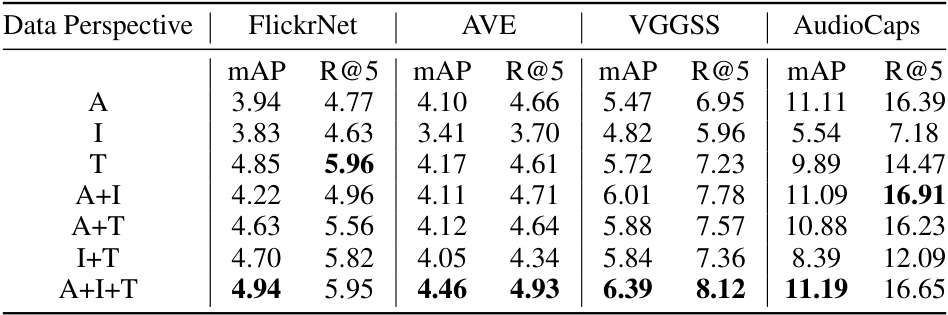
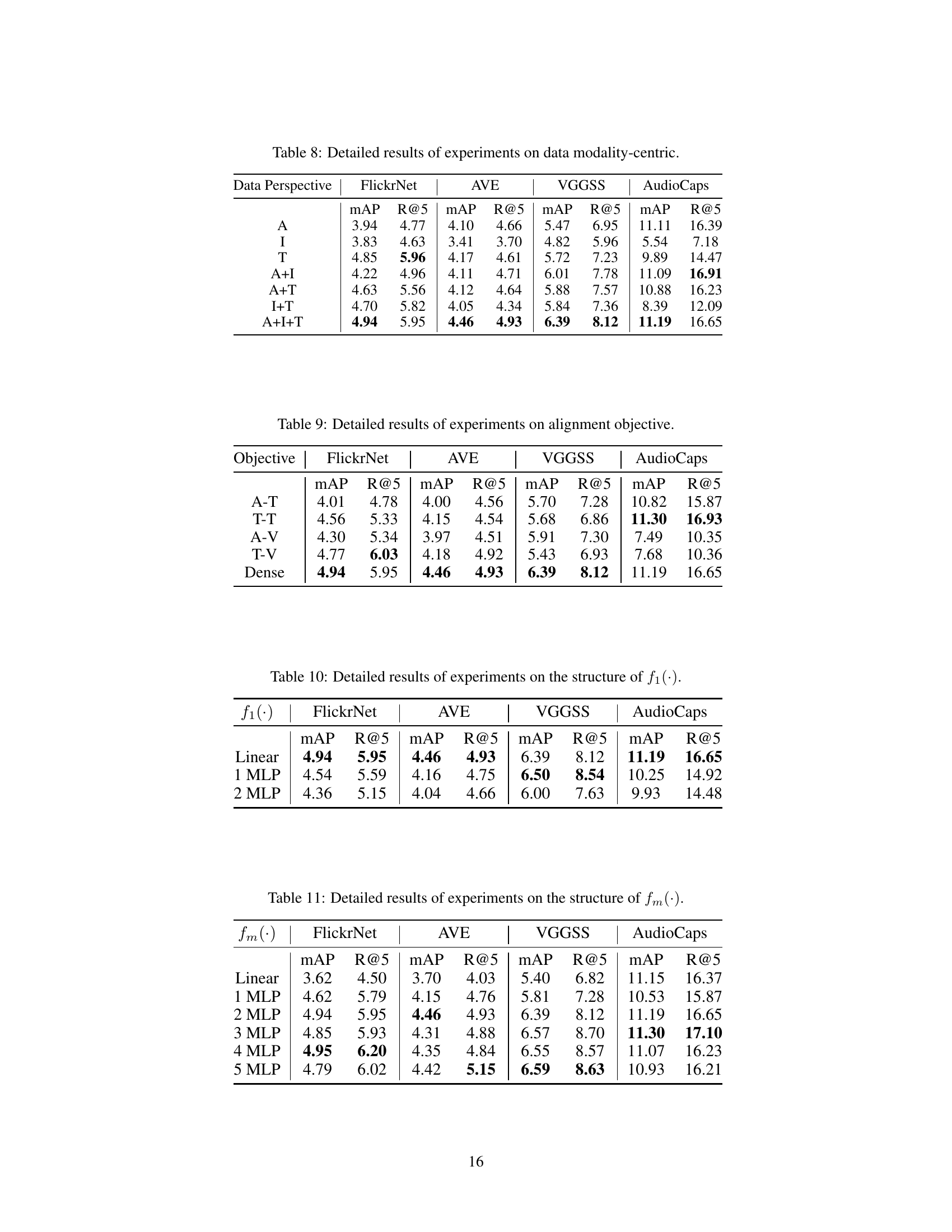
This table presents the mean average precision (mAP) and Recall@5 (R@5) metrics for audio-image-text retrieval experiments. Different combinations of modality-centric data (audio only, image only, text only, and various combinations thereof) were used to train the model. The results show the impact of using various modality-centric data on the performance of the audio-image-text retrieval task across different datasets (FlickrNet, AVE, VGGSS, and AudioCaps). The table allows for analysis of which types of data are most effective and whether combinations of data improve performance.
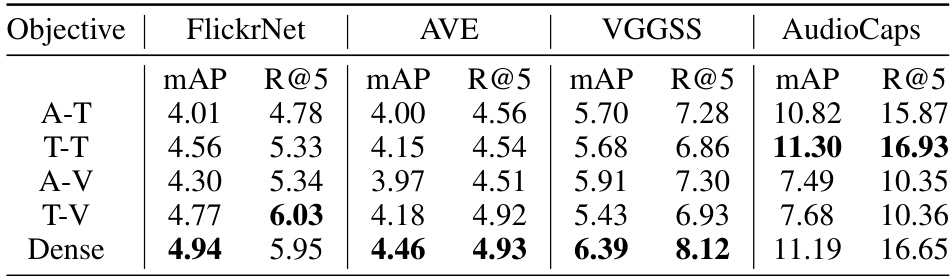
This table presents the mean average precision (mAP) and Recall@5 (R@5) for different alignment objectives used in the Ex-MCR model. The objectives include aligning audio and text (A-T), text and text (T-T), audio and image (A-V), text and image (T-V), and a dense alignment approach that considers multiple modalities simultaneously (Dense). The results are evaluated on four datasets: FlickrNet, AVE, VGGSS, and AudioCaps, showcasing the effectiveness of each alignment strategy on different audio-visual retrieval tasks.

This table presents a detailed breakdown of the performance of different projector structures (f1(·)) used in the Ex-MCR model. It compares the performance using a linear layer, a single Multilayer Perceptron (MLP) layer, and a 2-layer MLP. The metrics used for evaluation are mean Average Precision (mAP) and Recall@5 (R@5) across four different datasets: FlickrNet, AVE, VGGSS, and AudioCaps. This helps determine the optimal complexity for the f1(·) module in achieving a balance between performance and efficiency.
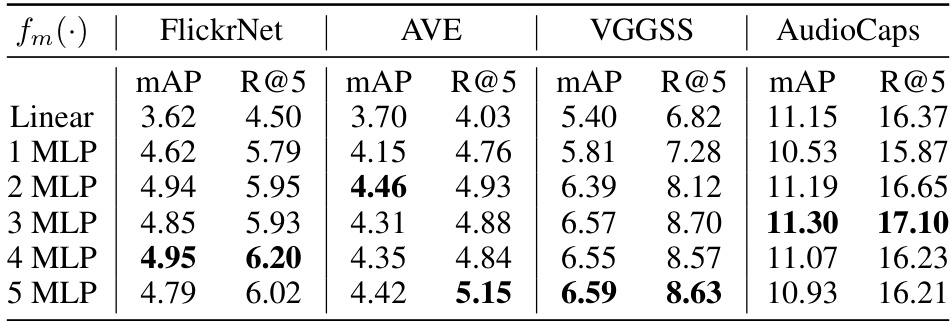
This table presents the ablation study results focusing on the structure of the inter-space alignment projector, fm(·), in the Ex-MCR model. It shows the performance (mAP and R@5) on four different datasets (FlickrNet, AVE, VGGSS, AudioCaps) for different numbers of MLP layers in the fm(·) module. The results indicate how the number of layers impacts the model’s performance in audio-image-text retrieval.
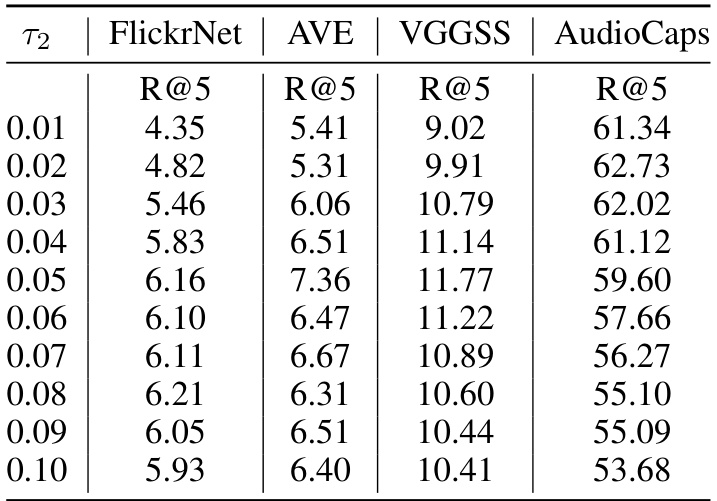
This table presents the results of ablation experiments conducted to determine the optimal value for the hyperparameter τ2. The results are presented in terms of Recall@5 (R@5) for various datasets including FlickrNet, AVE, VGGSS, and AudioCaps. Each row represents a different value of τ2, showing the impact of this parameter on the model’s performance across different datasets.

This table presents the ablation study results on the hyperparameter λ, which balances the intra-space and inter-space alignment losses in the Ex-MCR model. It shows the impact of different λ values on the retrieval performance (measured by R@5) across four datasets: FlickrNet, AVE, VGGSS, and AudioCaps. The results help to determine an optimal value for λ that yields the best performance.
Full paper#